TextRecognize[] accepts an undocumented Option "SegmentationMode". The allowed values are:
?Image`ExternalOCRDump`$TextRecognizeSegmentationModes { {{3, "Fully automatic page segmentation, but no OSD. (Default)"}}, {{4, "Assume a single column of text of variable sizes"}}, {{6, "Assume a single uniform block of text"}}, {{7, "Treat the image as a single text line"}}, {{8, "Treat the image as a single word"}}, {{10, "Treat the image as a single character"}} }
Of course in this case we want to use mode 7:
im = Import@"https://i.sstatic.net/cPRrY.png" TextRecognize[im, "SegmentationMode" -> 7]
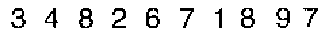
(* "3482671897" *)
And that's it.
Now, if you don't want to use undocumented options, you've to know that TextRecognize[] works much better if you first adjust the spacing between characters:
im = Import@"https://i.sstatic.net/cPRrY.png"
a = ConstantArray[1 , Last@ImageDimensions@im]; newImage = Image@Transpose[Transpose[ImageData@im] //. {x__, Longest[a..], y__} :> {x, a, a, y}]
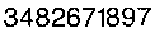
TextRecognize@newImage (* "3482671897" *)
Note that we are replacing the variable length vertical white strips with a minimum of 3 pixels wide with a standard separator of two pixels, as you can see here:
Image@Transpose[Transpose[ ImageData@im] //. {x__, b : Longest[a..], y__} :> {x, 0 b, y}]

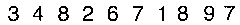 ;
;