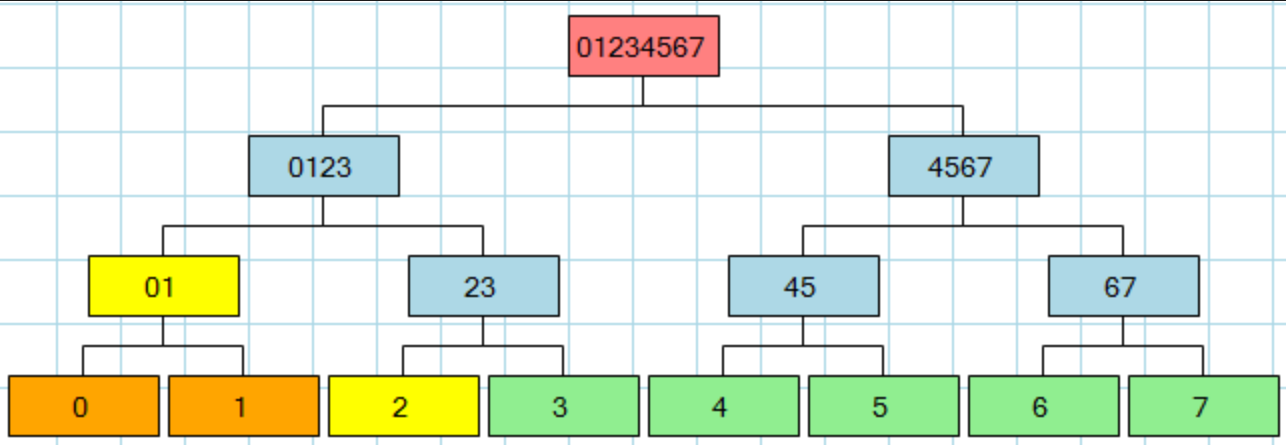
Suppose we have 8 transactions in a block X as follows and we know every node's hash value of the whole Merkle tree (that is, including intermediary nodes such as 45). Then if someone claims transaction t exists in X and it's located at 6. To verify this, we only need to look up hash values at 7, 45, 0123 and hash up to the top and compare with Merkle root 01234567.
I assume (based on this) Merkle tree is faster than hashing the concatenation of TXID0 ~ TXID7 directly is because hash algorithm runs faster on small files (even run it ~log(N) times) than on a large file (i.e., concatenation of N TXIDs, N is 8 here) at one time.
But reading this post, it seems that only Merkle root and N TXIDs are stored in a block and we have to recreate tree structure every time we verify a transaction, which would actually run hash functions ~N times instead of ~log(N) times (if I was correct mathematically).
My questions are:
- Does hash
~Ntimes still faster than hash one time onNconcatenated hash values?- Why is Merkle tree not stored? Is it due to storage consideration?