The New York Times has a daily online game called Letter Boxed (the link is behind a paywall; the game is also described here), presented on a square as follows:
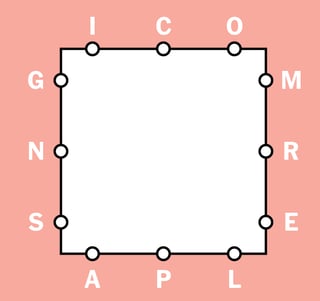
You are given 4 groups of 3 letters (each group corresponds to one side on the picture); no letter appears twice. The aim of the game is to find words made of those 12 letters (and those letters only) such that:
- Each word is at least 3 letters long;
- Consecutive letters cannot be from the same side;
- The last letter of a word becomes the first letter of the next word;
- All letters are used at least once (letters can be reused).
In this challenge, you are given the letters and a list of words. The goal is to check whether the list of words is a valid Letter Boxed solution.
Input
Input consists of (1) 4 groups of 3 letters and (2) a list of words. It can be in any suitable format.
Output
A truthy value if the list of words is a valid solution to the Letter Boxed challenge for those 4×3 letters, and a falsey value otherwise.
Test cases
Groups of letters={{I,C,O}, {M,R,E}, {G,N,S}, {A,P,L}}.
Truthy values
- PILGRIMAGE, ENCLOSE
- CROPS, SAIL, LEAN, NOPE, ENIGMA
Falsey values
- PILGRIMAGE, ECONOMIES (can't have CO since they are on the same side)
- CROPS, SAIL, LEAN, NOPE (G and M have not been used)
- PILGRIMAGE, ENCLOSURE (U is not one of the 12 letters)
- ENCLOSE, PILGRIMAGE (last letter of 1st word is not first letter of 2nd word)
- SCAMS, SO, ORGANISE, ELOPE (all words must be at least 3 letters long).
Note that in this challenge, we do not care whether the words are valid (part of a dictionary).
Scoring:
This code-golf, lowest score in bytes wins!
no letter appears twice\$\endgroup\$[]and0are falsey. Can we output either, or must our output be consistent? \$\endgroup\$