I just came across an exercise which is to find a regular expression for the following automaton, such that the regular expression and the automaton generate the same language.
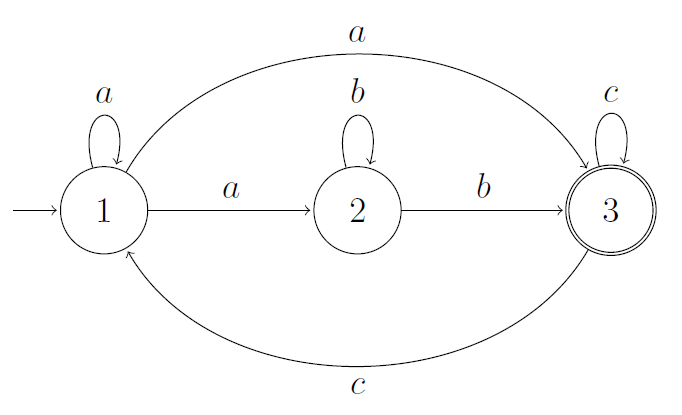
One solution presents the following expression:
$\qquad \displaystyle r_A = a^+b^+(c\mid ca^*b^+)^*$
However, can this be true? I think not, because the all words created from the regular expression will have at least one $b$ in it, whereas the automaton accepts words without $b$, such as $aaa$.
What is your opinion?