I have a retail dataset. I am trying to identify groups of products which are generally bought within a span of few days or on the same days (consider multiple store visits). For example - If someone is doing a painting DIY project at their house, they'd buy paints, paint rollers, painters tape, putty, putty knife etc, before and during the project.
My dataset looks like below:
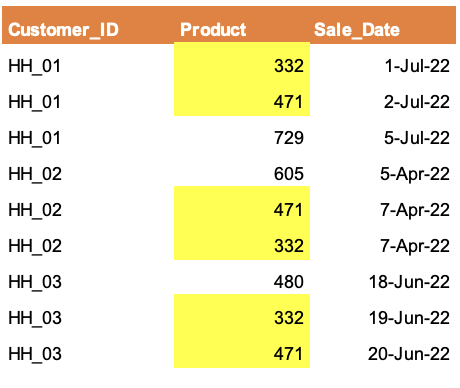
Above, you could see that products #332 & #471 were bought within few days by all the 3 customers. So these products are kind of associated. This suggests that customers who are doing a project X, they tend to buy #332 & #471 together. At the end of the day, I want to divide the product universe in few product clusters, where each cluster could be identified as some kind of project, something like below.
The way I am thinking to perform this is by:
- Performing Apriori. Get lifts for {A => B}
- Use lifts to create a m x m matrix, each data value will be a lift, m = number of products (in my case ~200)
- Standardize, and perform PCA to reduce dimension (to 5 or 6)
- Perform k-means on m x n dataframe. This would give me products who have similar lifts towards the same products.
I am not sure if there are other techniques. Please let me know if anyone has experience working on similar use cases or have any suggestions. (PS: I have done clustering of customers using RFM, but RFM can't be applied here since it'll be a grouping of products and not customers)