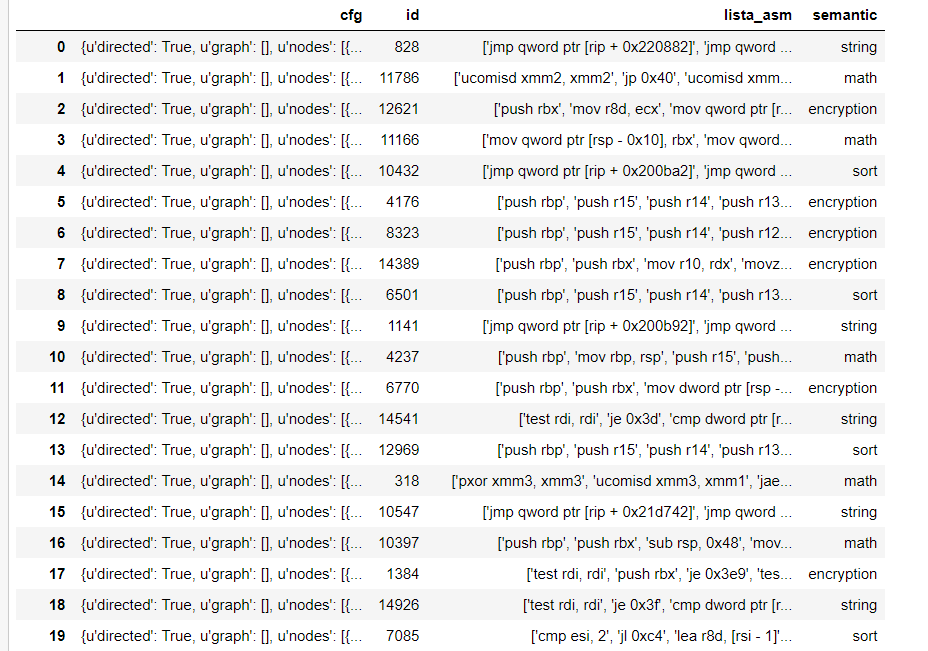
I have the following dataset which is a .json file:
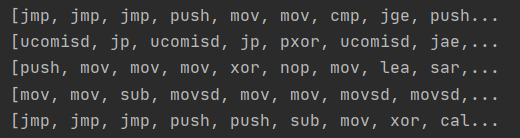
and I would like to get the first word for every string inside lista_asm, so I would like to get: jmp,push,uncomisd,...etc
what I am doing to do this is the following:
dataFrame['opcodes'] = dataFrame['lista_asm'].apply(lambda x:[i.split()[0] for i in x]) but it gives me back the following error message:
3589 else: 3590 values = self.astype(object).values -> 3591 mapped = lib.map_infer(values, f, convert=convert_dtype) 3592 3593 if len(mapped) and isinstance(mapped[0], Series): pandas/_libs/lib.pyx in pandas._libs.lib.map_infer() <ipython-input-18-5506b5721bf1> in <lambda>(x) ----> 1 dataFrame['opcodes'] = dataFrame['lista_asm'].apply(lambda x:[i.split()[0].strip() for i in x]) IndexError: list index out of range I don't understand what is wrong. Can somebody please help me?
[EDIT]Trying the code:
dataFrame['opcodes'] = dataFrame['lista_asm'].apply(lambda x:x[0].split(" ",2)[0]) and adding :
df = dataFrame[["opcodes", "semantic"]].copy() df I get:
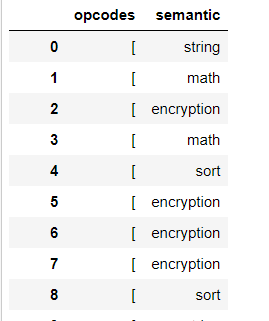
what I would like to get is a list of the type [push,mov,..] and this for every row.
It seems like when I do x[0] it does not return the first element of the list, but returns the pharentesis, which is weird. Am I doing something wrong which I don't see?
My objective is to pre-process this dataset in order to feed features to my model, but I haveing hard times in doing so.