We have a performance problem with SQL Server (2008 R2) Full text search. When we have additional where conditions to full-text search condition, it gets too slow.
Here is my simplified query:
SELECT * FROM Calls C WHERE (C.CallTime BETWEEN '2013-08-01 00:00:00' AND '2013-08-07 00:00:00') AND CONTAINS(CustomerText, '("efendim")') Calls table's primary key is CallId (int, clustered index) and also Calls table indexed by CallTime. We have 16.000.000 rows and CustomerText is about 10KB for each row.
When I see execution plan, first it finds full-text search resultset and then joins with Calls table by CallId. Because of that, if first resultset has more rows, query gets slower (over a minute).
This is the execution plan:
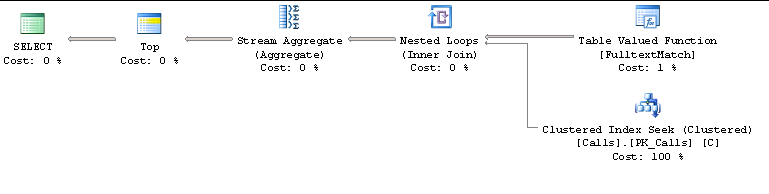
When I run where conditions seperately, it returns 360.000 rows for CallTime condition:
SELECT COUNT(*) FROM Calls C WHERE (C.CallTime BETWEEN '2013-08-01 00:00:00' AND '2013-08-07 00:00:00') and 1.200.000 rows for Contains condition:
SELECT COUNT(*) FROM Calls C WHERE CONTAINS(AgentText, '("efendim")') What can I do to increase performance of my query?
containstableto see if it makes difference in execution time.