-
-
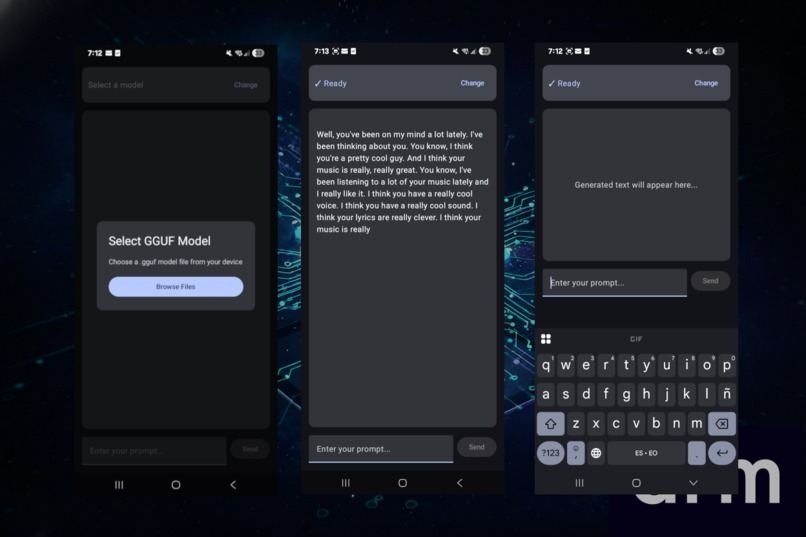
Screenshots of the sample app
-
Repository of the code, open source of course
-
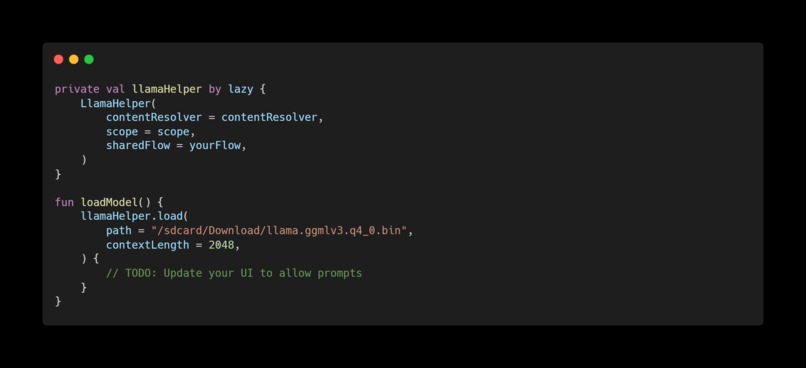
Simple and fast initialization of a gguf model from local files
-
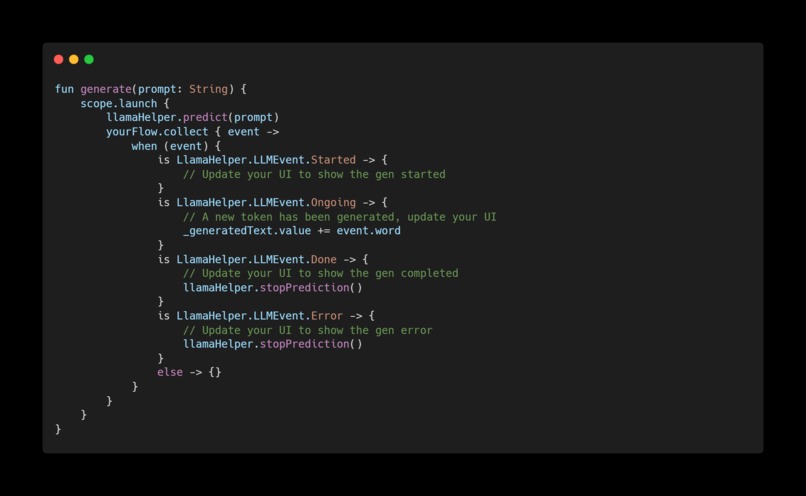
Very few lines of codes needed to implement AI inference on your android app
Inspiration
The mobile AI landscape had a critical gap: while several libraries existed for running LLM inference on Android, none were built with modern Kotlin idioms or contemporary Android development patterns in mind. Existing solutions felt like relics from a different era—difficult to integrate, poorly documented, and fighting against rather than embracing Kotlin's coroutine-based async model.
As Arm processors in mobile devices became increasingly powerful, I saw an opportunity: create a truly modern SDK that would make local AI inference on Arm-based Android devices as simple as making a network call. By forking and extensively refactoring existing projects, Kotlin-LlamaCpp was born—designed from the ground up for the way Android developers actually work today.
What it does
Kotlin-LlamaCpp empowers mobile developers to integrate powerful AI capabilities directly into their Arm-based Android apps with minimal effort.
The SDK provides:
- Simple, idiomatic Kotlin API for LLM inference
- Hardware-optimized performance leveraging Arm CPU features
- Streaming token generation using Kotlin Flow for responsive UIs
- Complete lifecycle management integrated with Android ViewModels and coroutines
- Offline-first AI - no internet required, complete user privacy
- Production-ready memory management with context shifting for long conversations
Developers can go from zero to running a local language model in their app with just a few lines of code—something that previously required days of native code integration and debugging.
How we built it
The project involved bridging three distinct technical domains:
1. Native Layer Optimization
We started with llama.cpp, the high-performance C++ inference engine, and refactored it specifically for mobile use:
- Stripped unnecessary features to reduce binary size
- Optimized for Arm64 architecture with targeted compiler flags
- Updated memory allocation to comply with Android's 16KB page requirements
2. JNI Bridge Architecture
Created a carefully designed JNI layer that:
- Exposes C++ functions to Kotlin safely
- Manages memory lifecycle between garbage-collected Kotlin and manual C++
- Handles thread safety for concurrent inference calls
- Minimizes marshalling overhead for performance
3. Modern Kotlin API
Built a developer-friendly API layer featuring:
- Kotlinx Coroutines integration - Inference runs on background dispatchers without blocking
- Flow-based streaming - Tokens emit as they're generated for real-time UI updates
- Lifecycle awareness - Automatic cleanup when ViewModels are destroyed
- Suspension functions - Natural async/await patterns Kotlin developers expect
Challenges we ran into
1. Time-Consuming LLM Testing
Testing language model inference is brutally slow. Each test run could take minutes, and debugging required isolating issues across three layers (Kotlin → JNI → C++). A single memory leak could manifest hours into a conversation, making reproduction difficult.
2. Obscure Native Crashes
JNI crashes don't provide helpful stack traces. Segfaults in the native layer would simply crash the app with cryptic logs. We had to instrument extensive logging, use address sanitizers, and methodically trace through memory management to find issues.
Accomplishments that we're proud of
Making AI Inference Accessible
We created a library that collapses what used to be days of integration work into minutes. Developers can now add local AI to their apps as easily as they'd add any other dependency.
Thousands of Developer Hours Saved
By abstracting away the complexity of native code, JNI bridges, and inference engine internals, we've eliminated the need for every Android developer to become a C++ expert just to add AI features.
Production-Ready Privacy
We've enabled a new class of privacy-first AI applications. Medical apps, financial tools, personal assistants—all can now process sensitive data without ever sending it to the cloud.
Open Source Foundation
Released under MIT license, this library can become a building block for the entire Android AI ecosystem, letting developers focus on innovation rather than infrastructure.
What we learned
Native C/C++ Development
Coming from a Kotlin/Android background, diving deep into C++ memory management, pointer arithmetic, and the llama.cpp codebase was a significant learning curve. We gained expertise in:
- Manual memory management
- CMake build systems and cross-compilation
LLM Inference Mechanics
Working at the engine level taught us:
- How transformer models actually process tokens
- KV cache management strategies
- Quantization trade-offs (Q4 vs Q5 vs Q8)
- Context window management and shifting algorithms
Mobile Performance Engineering
We learned to balance:
- Inference speed vs battery drain
- Memory usage vs context length
- Binary size vs feature completeness
- Thermal throttling considerations
What's next for Kotlin-LlamaCpp
Near-term Goals
1. Enhanced Developer Experience
- Pre-built model downloader with progress callbacks
- Comprehensive sample apps showcasing different use cases
2. Performance Improvements
- Further Arm optimization using latest CPU features
- Reduced cold-start latency
- Smaller binary size through modular architecture
3. Extended Model Format Support
The goal is simple: make Arm-based devices the best platform for running AI, period. No cloud required, no privacy compromises, no ongoing costs—just powerful AI in your users' hands.
Built With
- android
- android-studio
- c
- compose
- kotlin
- kotlinx
- makefile


Log in or sign up for Devpost to join the conversation.