![]()
![]()
公众号文章:文本分类之Text-CNN/RNN/RCNN算法原理及工程实现
公众号文章:一篇文章带你走进词向量并掌握Word2Vec
本仓库不再维护欢迎使用功能更全的text_classifier_torch实现任务
该项目是基于Tensorflow2.3的文本分类任务,通过直接配置可支持:
- TextCNN/TextRNN/TextRCNN/Transformer/Bert/AlBert/DistilBert基本分类模型的训练
- TextCNN/TextRNN/TextRCNN/Transformer的token可选用词粒度/字粒度
- Word2Vec特征增强后接TextCNN/TextRNN/TextRCNN/Transformer
- 支持Attention-TextCNN/TextRNN
- FGM和PGD两种对抗方法的引入训练
- 对比学习方法R-drop引入
- 支持二分类和多分类,支持FocalLoss
- 保存为pb文件可供部署
- 项目代码支持交互测试和批量测试,批量测试可以观察错误分布和分析bad case
- python 3.7.10
- tensorflow-gpu==2.3.0
- tensorflow-addons==0.15.0
- tqdm==4.50.2
- gensim==3.8.3
- jieba==0.42.1
- pandas==1.1.3
- scikit-learn==0.23.2
- transformers==4.6.1
- texttable==1.6.4
| 日期 | 版本 | 描述 |
|---|---|---|
| 2018-12-01 | v1.0.0 | 初始仓库 |
| 2020-10-20 | v2.0.0 | 重构项目 |
| 2020-10-26 | v2.1.0 | 加入F1、Precise、Recall分类指标,计算方式支持macro、micro、average、binary |
| 2020-11-26 | v2.3.1 | 加入focal loss用于改善标签分布不平衡的情况 |
| 2020-11-19 | v2.4.0 | 增加每个类别的指标,重构指标计算逻辑 |
| 2021-03-02 | v2.5.0 | 使用Dataset替换自己写的数据加载器来加载数据 |
| 2021-03-15 | v3.0.0 | 支持仅使用TextCNN/TextRCNN进行数据训练(基于词粒度的token,使用随机生成的Embedding层) |
| 2021-03-16 | v3.1.0 | 支持取用Word2Vec的词向量后接TextCNN/TextRCNN进行数据训练;在log中打印配置 |
| 2021-03-17 | v3.1.1 | 根据词频过滤一部分频率极低的词,不加入词表 |
| 2021-04-25 | v3.1.6 | 通过配置可选GPU和CPU进行训练 |
| 2021-06-17 | v3.2.0 | 增加字粒度的模型训练预测 |
| 2021-09-27 | v3.3.0 | 增加测试集的批量测试 |
| 2021-11-01 | v4.0.0 | 增加对抗训练,目前支持FGM和PGD两种方式;增加Bert微调分类训练;更换demo数据集 |
| 2021-11-24 | v4.2.0 | 增加Transformer模型做文本分类、增加对比学习方法r-drop |
| 2022-04-22 | v5.0.0 | 批量测试打印bad_case以及预测混淆情况、文件夹检查、配置里面不再自己定义标签顺序、各类预训练模型支持 |
部分头条新闻数据集
在config.py中配置好各个参数,文件中有详细参数说明
配置好下列参数
classifier_config = { # 模型选择 # 传统模型:TextCNN/TextRNN/TextRCNN/Transformer # 预训练模型:Bert/DistilBert/AlBert/RoBerta/Electra/XLNet 'classifier': 'TextCNN', # 若选择Bert系列微调做分类,请在pretrained指定预训练模型的版本 'pretrained': 'bert-base-chinese', # 训练数据集 'train_file': 'data/train_dataset.csv', # 验证数据集 'val_file': 'data/val_dataset.csv', # 测试数据集 'test_file': 'data/test_dataset.csv', # 引入外部的词嵌入,可选word2vec、Bert # word2vec:使用word2vec词向量做特征增强 # 不填写则随机初始化的Embedding 'embedding_method': '', # token的粒度,token选择字粒度的时候,词嵌入(embedding_method)无效 # 词粒度:'word' # 字粒度:'char' 'token_level': 'word', # 去停用词,路径需要在上面的word2vec_config中配置,仅限非预训练微调使用 'stop_words': True, # 是否去掉特殊字符 'remove_special': True, # 不外接词嵌入的时候需要自定义的向量维度 'embedding_dim': 300, # 存放词表的地方 'token_file': 'data/word-token2id', # 类别列表 'classes': ['家居', '时尚', '教育', '财经', '时政', '娱乐', '科技', '体育', '游戏', '房产'], # 模型保存的文件夹 'checkpoints_dir': 'model/textcnn', # 模型保存的名字 'checkpoint_name': 'textcnn', # 使用Textcnn模型时候设定卷集核的个数 'num_filters': 64, # 学习率 # 微调预训练模型时建议更小,设置5e-5 'learning_rate': 0.0005, # 优化器选择 # 可选:Adagrad/Adadelta/RMSprop/SGD/Adam/AdamW 'optimizer': 'Adam', # 训练epoch 'epoch': 100, # 最多保存max_to_keep个模型 'max_to_keep': 1, # 每print_per_batch打印 'print_per_batch': 100, # 是否提前结束 'is_early_stop': True, # 是否引入attention # 注意:textrcnn不支持 'use_attention': False, # attention大小 'attention_size': 300, 'patient': 8, 'batch_size': 256, 'max_sequence_length': 300, # 遗忘率 'dropout_rate': 0.5, # 隐藏层维度 # 使用textrcnn、textrnn和transformer中需要设定 # 使用transformer建议设定为2048 'hidden_dim': 256, # 编码器个数(使用transformer需要设定) 'encoder_num': 1, # 多头注意力的个数(使用transformer需要设定) 'head_num': 12, # 若为二分类则使用binary # 多分类使用micro或macro 'metrics_average': 'micro', # 类别样本比例失衡的时候可以考虑使用 'use_focal_loss': False, # 使用标签平滑 # 主要用在预训练模型微调,直接训练小模型使用标签平滑会带来负面效果,慎用 'use_label_smoothing': False, 'smooth_factor': 0.1, # 是否使用GAN进行对抗训练 'use_gan': False, # 目前支持FGM和PGD两种方法 # fgm:Fast Gradient Method # pgd:Projected Gradient Descent 'gan_method': 'pgd', # 对抗次数 'attack_round': 3, # 使用对比学习,不推荐和对抗方法一起使用,效率慢收益不大 'use_r_drop': False } 配置完参数之后开始训练模型
# [train_classifier, interactive_predict, test, save_model, train_word2vec, train_sif_sentence_vec] mode = 'train_classifier' - 训练结果
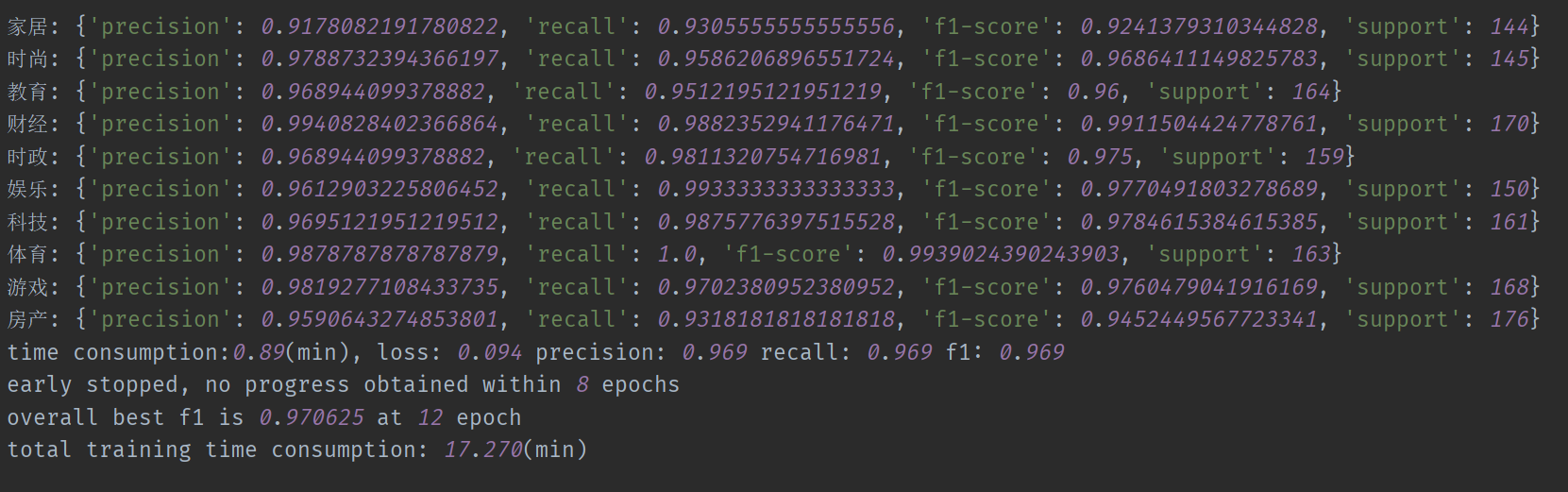
训练好模型直接可以开始测试,可以进行交互测试也可以批量测试
- 交互测试
# [train_classifier, interactive_predict, test, save_model, train_word2vec, train_sif_sentence_vec] mode = 'interactive_predict' 交互测试结果
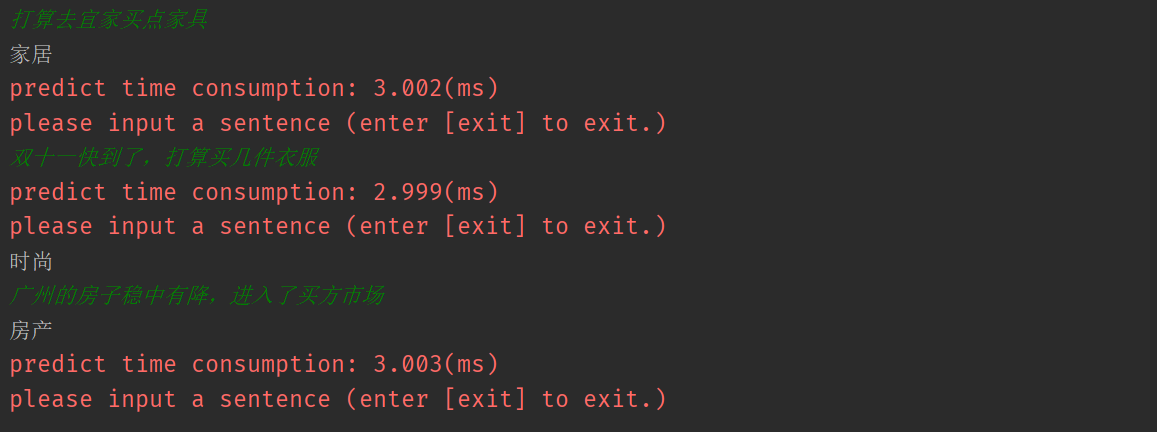
- 批量测试
在测试数据集配置上填和训练/验证集文件同构的文件地址
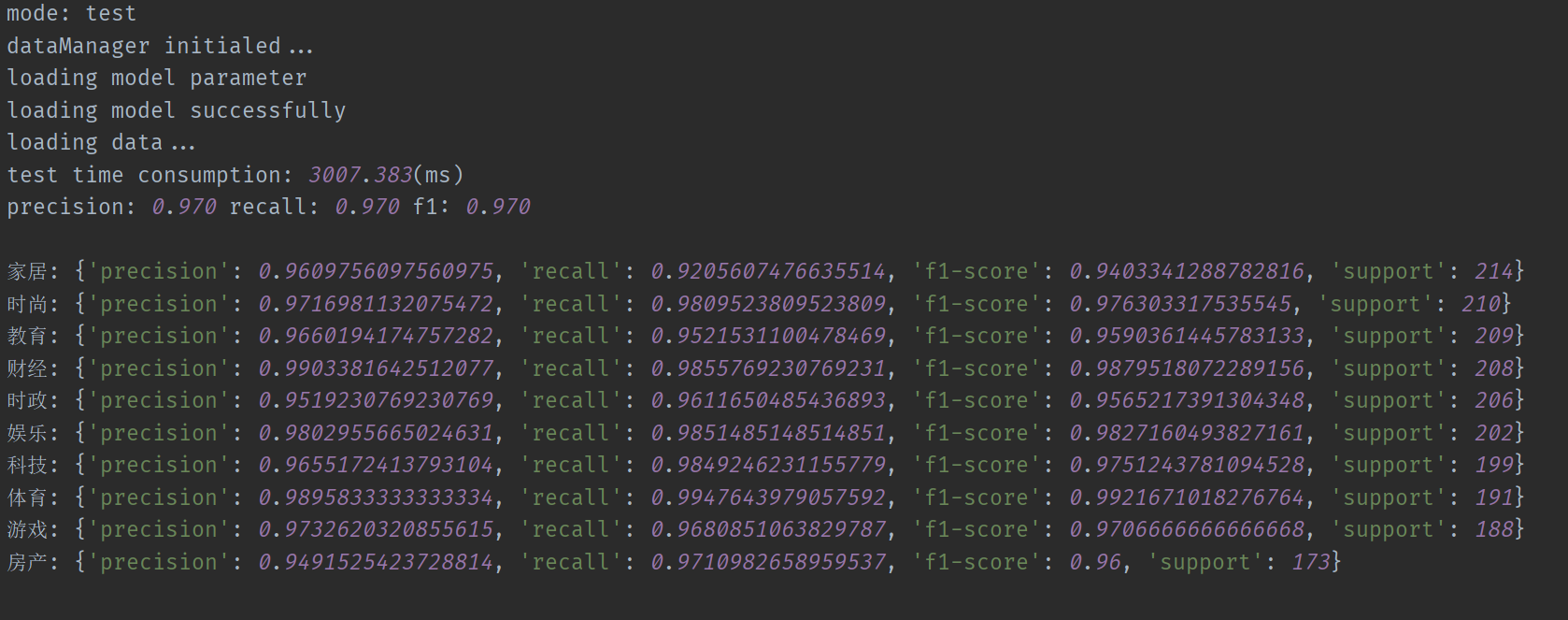
# 测试数据集 'test_file': 'data/test_dataset.csv', 模式设定为测试模式
# [train_classifier, interactive_predict, test, save_model, train_word2vec, train_sif_sentence_vec] mode = 'test' 批量测试结果
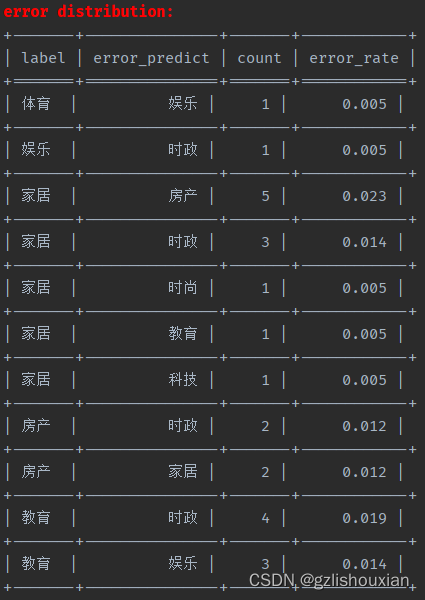
批量测试完会给出各个标签混淆的分布
批量测试完同时会给出一份bad_case文件,方便更细致的纠正标签和判断模型效果

在config.py中的mode中配置好词向量训练的相关参数,并在mode中选择train_word2vec并运行:
word2vec_config = { 'stop_words': 'data/w2v_data/stop_words.txt', # 停用词(可为空) 'train_data': 'data/w2v_data/dataset.csv', # 词向量训练用的数据 'model_dir': 'model/word2vec_model', # 词向量模型的保存文件夹 'model_name': 'word2vec_model.pkl', # 词向量模型名 'word2vec_dim': 300, # 词向量维度 'min_count': 3, # 最低保留词频大小 # 选择skip-gram和cbow 'sg': 'cbow' } # [train_classifier, interactive_predict, test, save_model, train_word2vec, train_sif_sentence_vec] mode = 'train_word2vec' 相关问题欢迎在公众号反馈:
