I have a rather large dataset comprised of Association of Associations. For better or worse, I've converted this into a Dataset. Here is a simplified version of that dataset:
testdb = Dataset[<| "First" -> <| "LOCATION" -> GeoPosition[{40.1151, -88.2737}, "NAD27"], "TYPE" -> "A", "DATA1" -> Range[10], "DATA2" -> {0.8, 0.5, 0.2, 0.4, 0.5, 0.8, 0.75, 0.15, 0.95, 0.4}|>, "Second" -> <| "LOCATION" -> GeoPosition[{40.1123, -89.110}, "NAD27"], "TYPE" -> "B", "DATA1" -> Range[2, 11], "DATA2" -> {0.3, 0.2, 0.24, 0.44, 0.2, 0.81, 0.76, 0.72, 0.88, 0.44}|>, "Third" -> <| "LOCATION" -> GeoPosition[{40.1123, -89.110}, "NAD27"], "TYPE" -> "B", "DATA1" -> Range[4, 13], "DATA2" -> {0.66, 0.65, 0.21, 0.92, 0.51, 0.44, 0.23, 0.77, 0.85, 0.11}|>|>] 
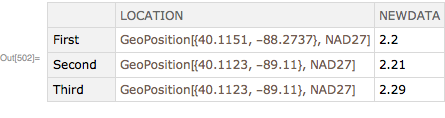
My end goal is to have a resulting dataset of {"LOCATION","NEWDATA"} where NEWDATA is the total of "DATA2" for corresponding values of "DATA1" between 5 and 8 (5<=x<=8).
So for the example above, the result would be:

The true dataset is of length 824 with nested datasets of 20,000 elements, so speed in selecting and summing is needed. And while I could do this using Normal, Cases, and the like, my thought was that the Query method would be quicker.