Your surprising results are related to the Regular Expression Quantifier *.
Consider:
[a-z]*
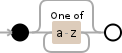
Debuggex Demo
Vs:
[a-z]+
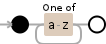
Debuggex Demo
Consider as another example that I think is more illustrative of what you are seeing:
>>> re.findall(r'[a-z]*', '123456789') ['', '', '', '', '', '', '', '', '', '']
There are no characters in the set [a-z] in the string 123456789. Yet, since * means 'zero or more', all character positions 'match' by not matching any characters at that position.
For example, assume you just wanted to test if there were any letters in a string, and you use a regex like so:
>>> re.search(r'[a-z]*', '1234') <_sre.SRE_Match object at 0x1069b6988> # a 'match' is returned, but this is # probably not what was intended
Now consider:
>>> re.findall(r'[a-z]*', '123abc789') ['', '', '', 'abc', '', '', '', '']
Vs:
>>> re.findall(r'([a-z])*', '123abc789') ['', '', '', 'c', '', '', '', '']
The first pattern is [a-z]*. The part [a-z] is a character class matching a single character in the set a-z unless modified; the addition of * quantifier will greedily match as many characters as possible if more than zero -- hence the match of 'abc' but will also allow zero characters to be a match (or a character outside the character set to match the position since 0 is a match).
The addition of a grouping in ([a-z])* effectively reduces the match in the quantified set back to a single character and the last character matched in the set is returned.
If you want the effect of grouping (say in a more complex pattern) use a non capturing group:
>>> re.findall(r'(?:[a-z])*', '123abc789') ['', '', '', 'abc', '', '', '', '']
*to+and possibly you wont get the empty ones (i'm not a python dev tho)