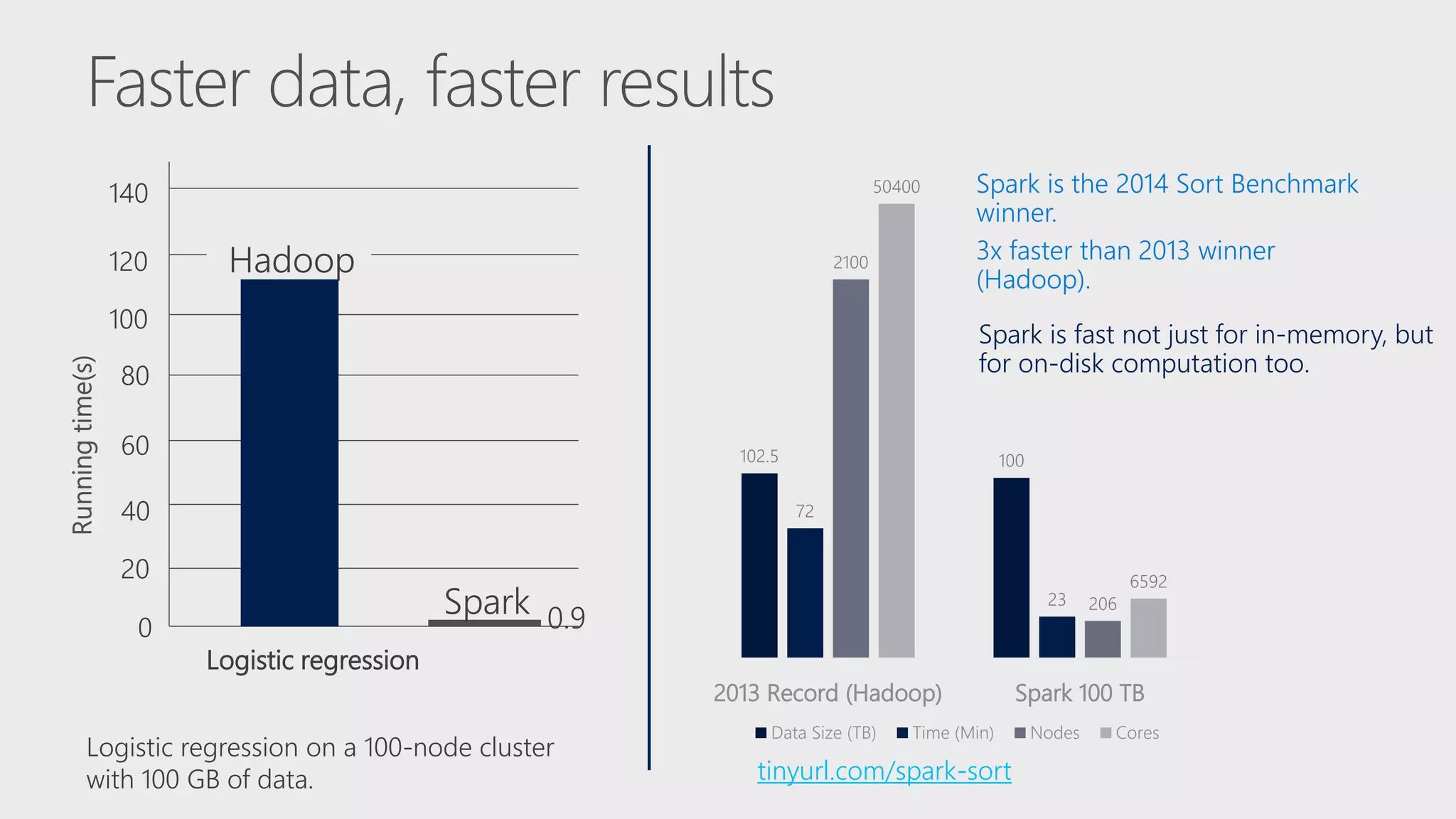
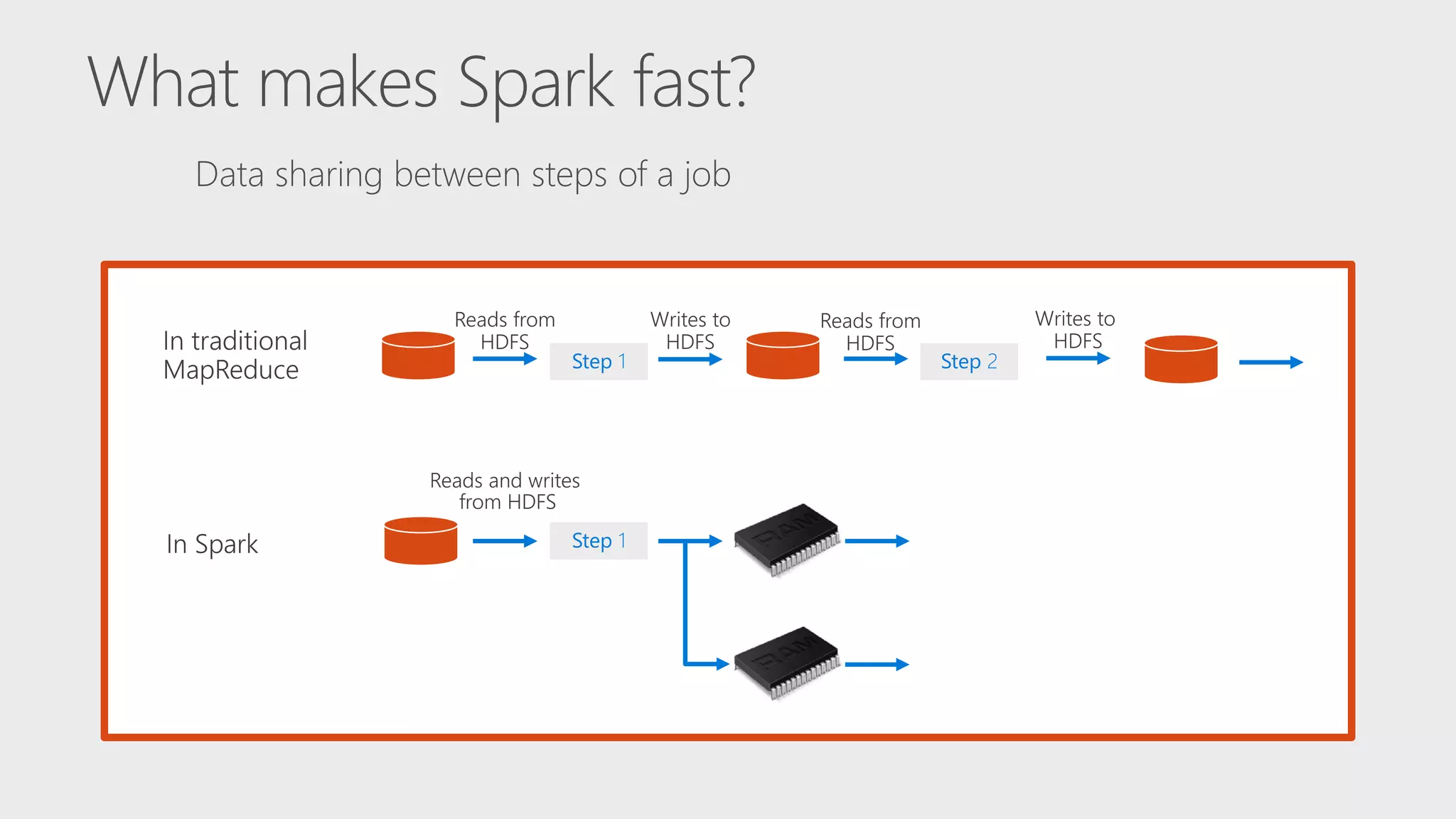
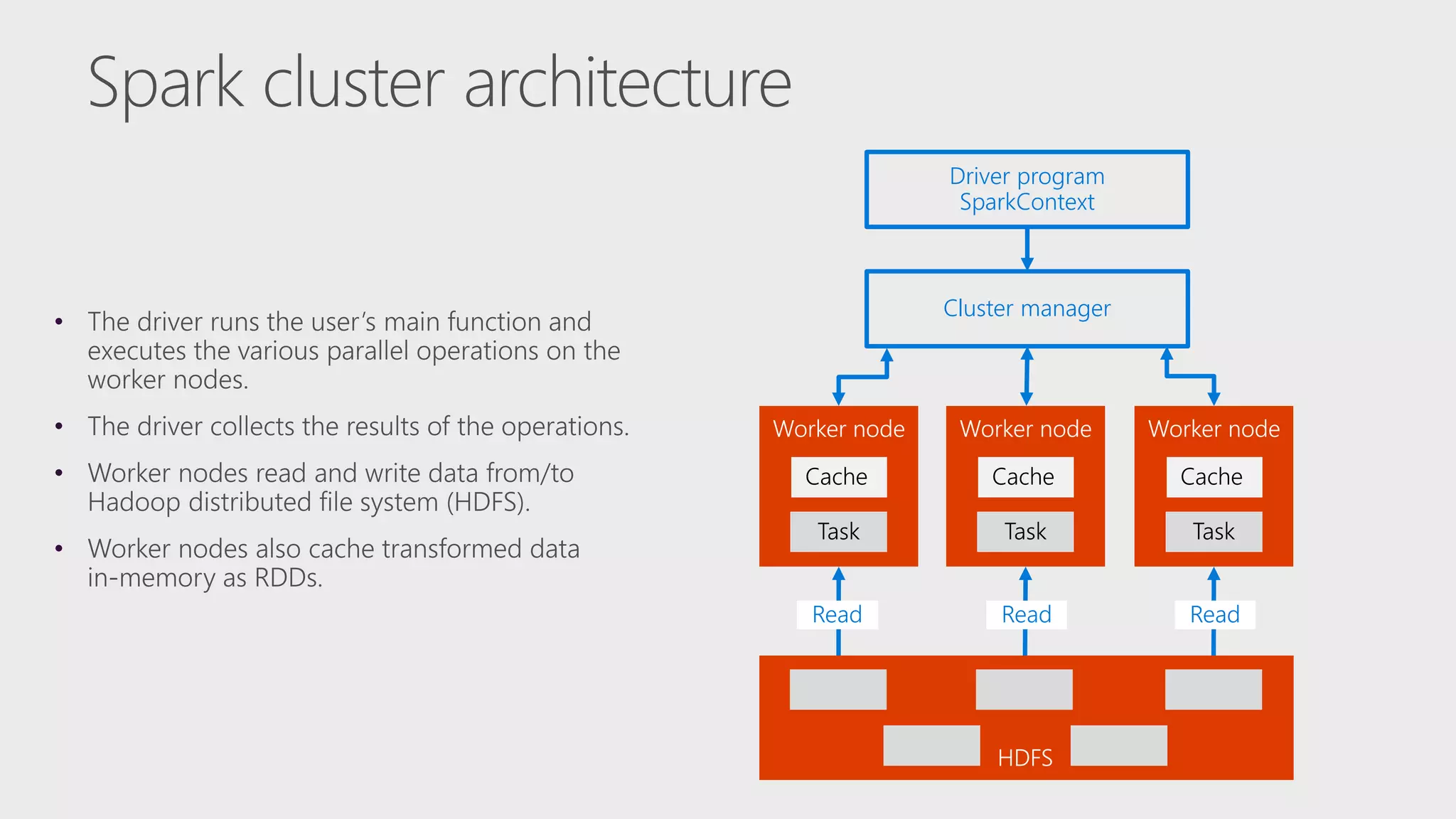
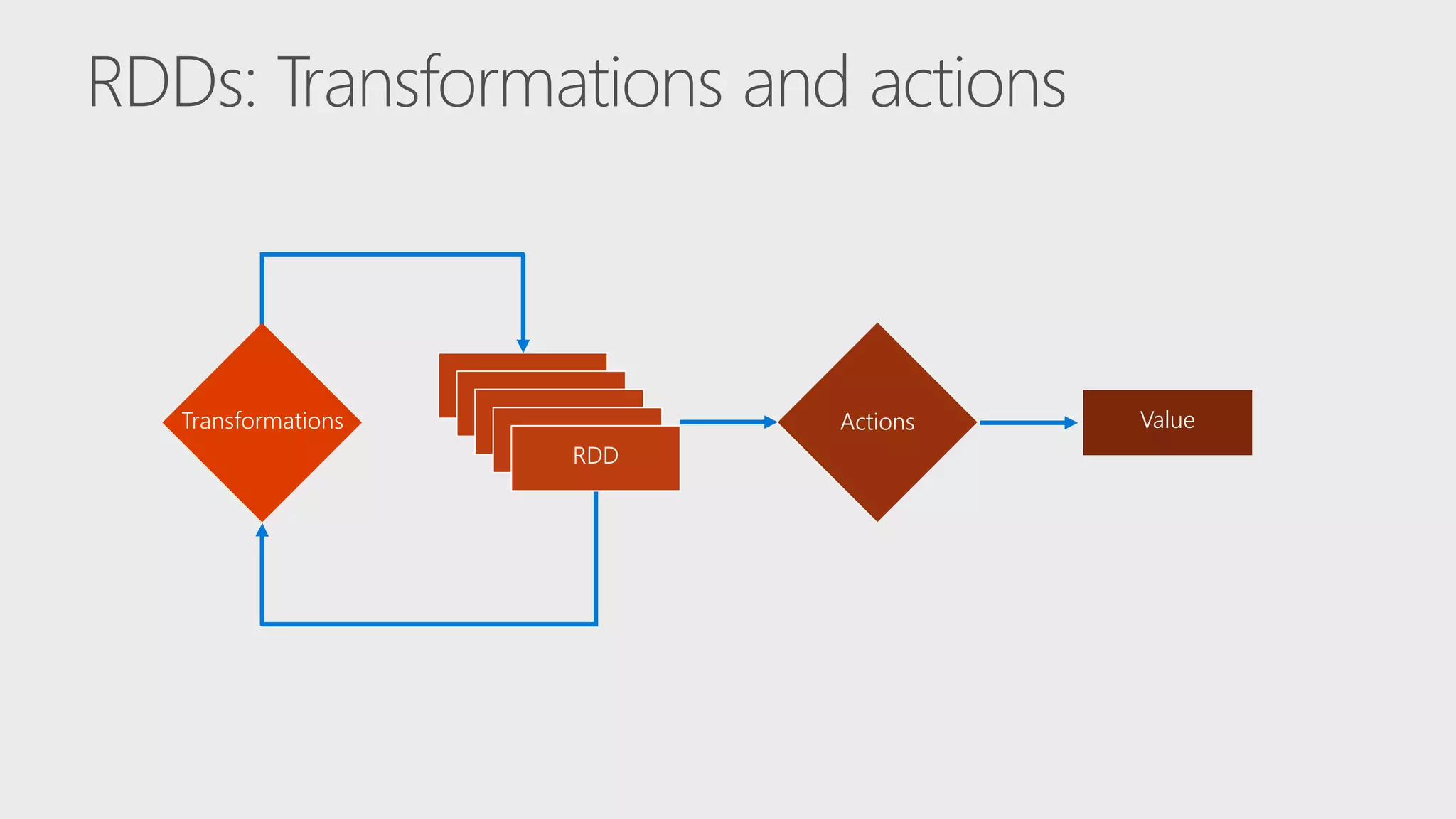
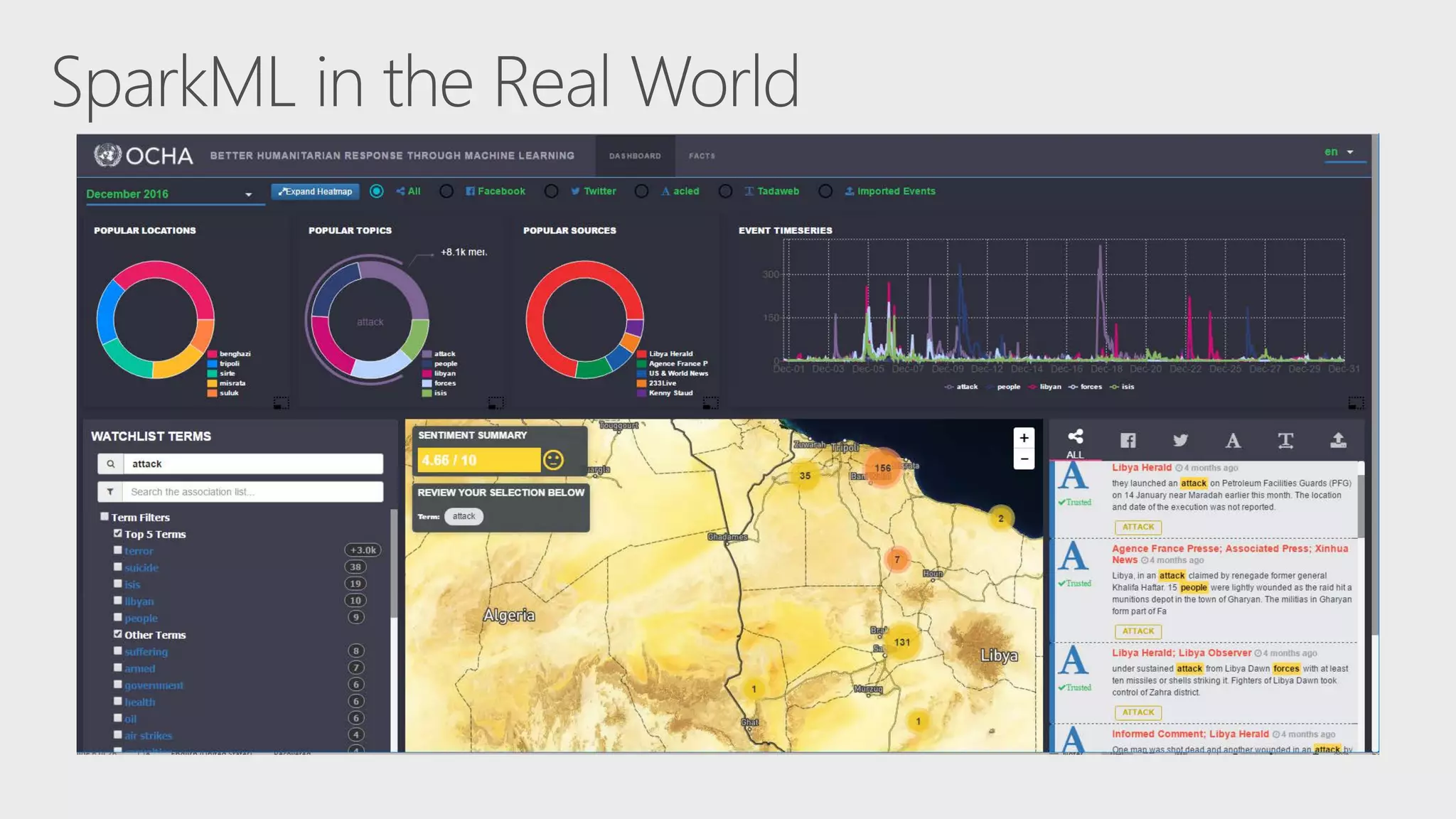
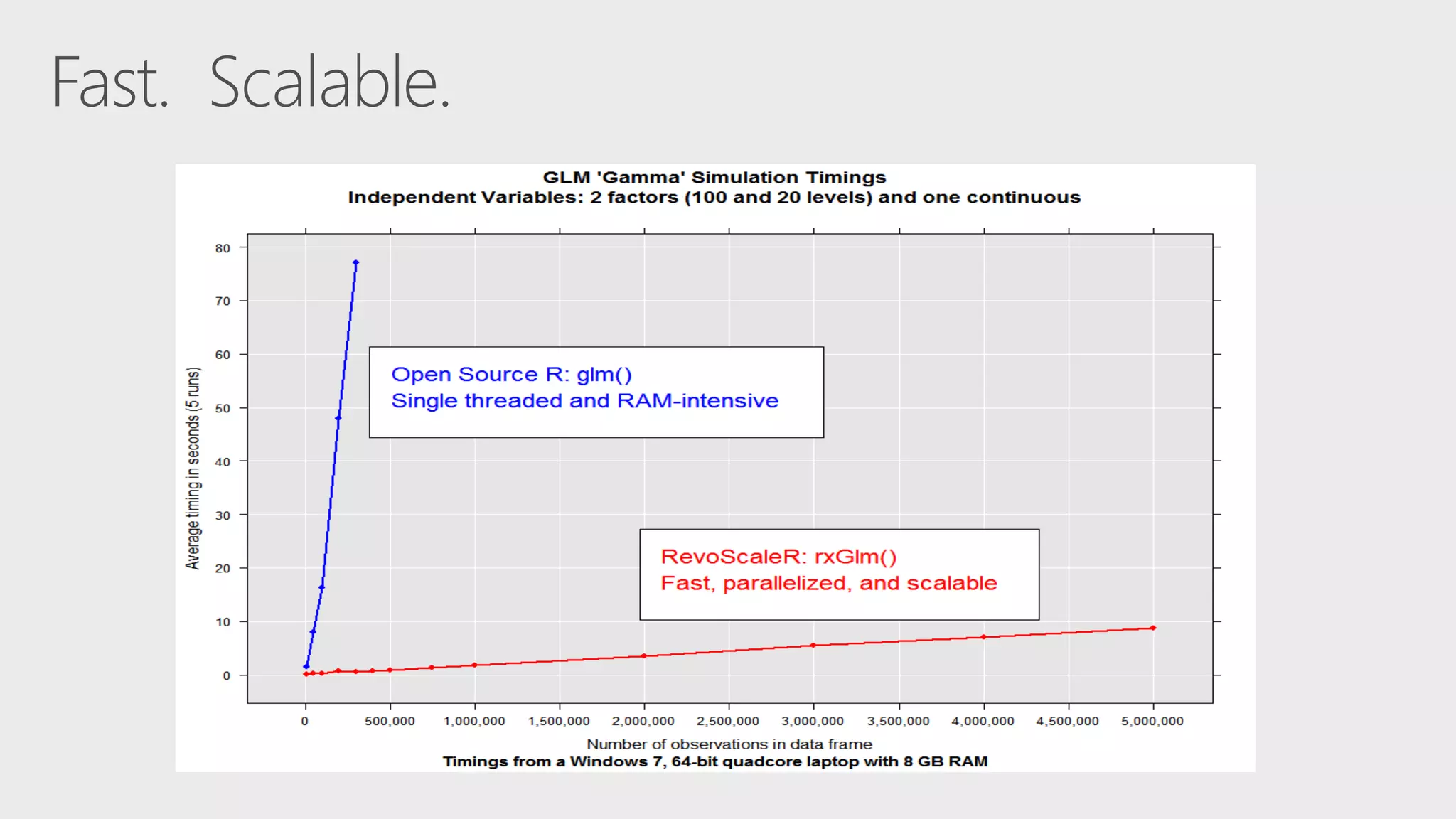
The document describes Apache Spark, an open-source parallel data processing framework optimized for big data analytics, detailing its core engine, capabilities in streaming and machine learning, and comparisons to Hadoop's performance. It highlights practical implementations of data processing, including examples of logistic regression and topic modeling using Spark's APIs. Additionally, it emphasizes developer productivity features and performance metrics within the Spark ecosystem.





























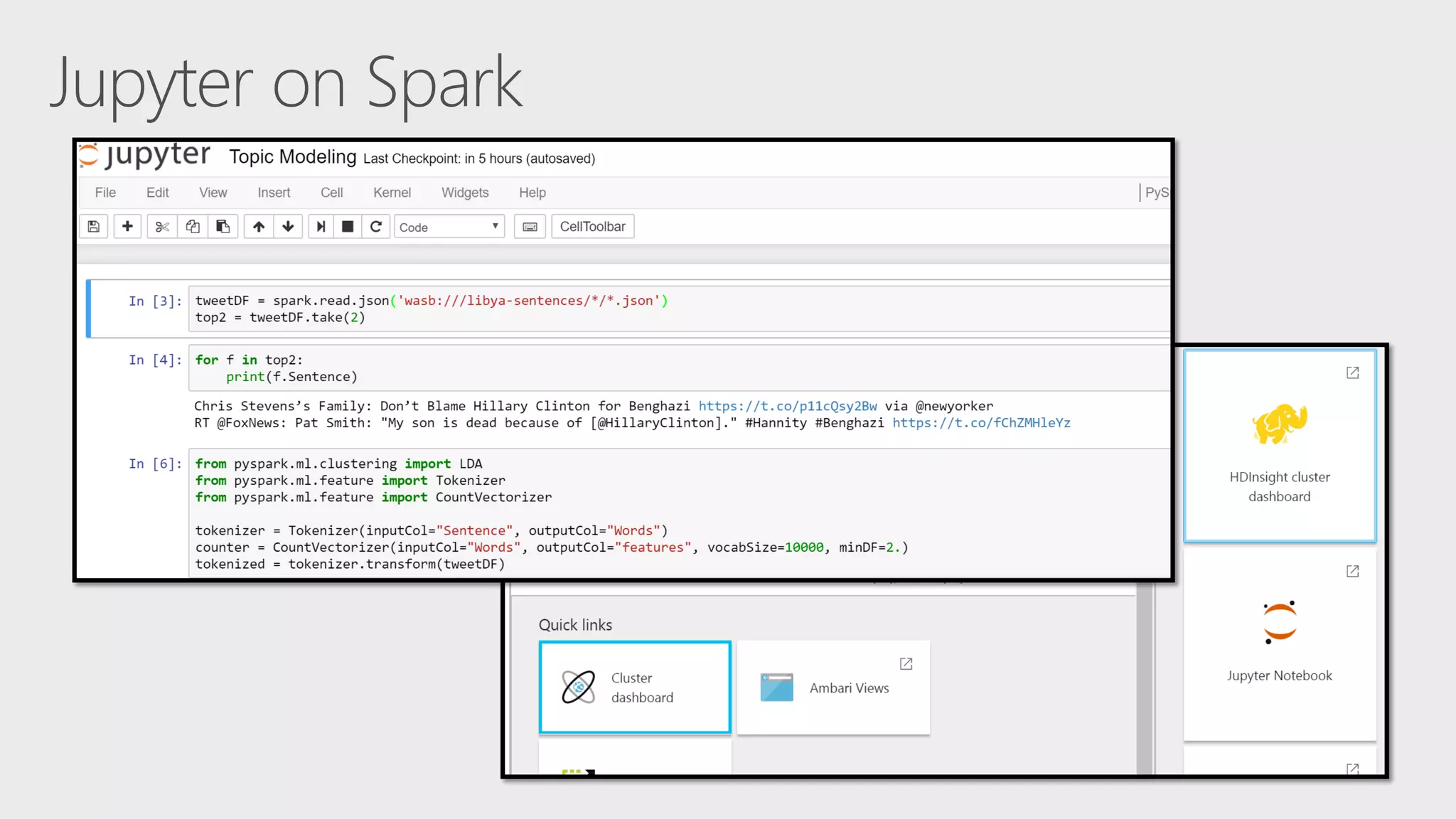
![tweetDF = spark.read.json('wasb:///libya-sentences/*/*.json') tokenizer = Tokenizer(inputCol="Sentence", outputCol="Words") counter = CountVectorizer(inputCol="Words", outputCol="features", vocabSize=10000, minDF=2.) lda = LDA(k=10, maxIter=10) pipeline = Pipeline(stages=[tokenizer, counter, lda]) model = pipeline.fit(tweetDF) topics = model.describeTopics(3) topics.show(truncate=False) ldaScored = model.transform(tweetDF)](https://image.slidesharecdn.com/ai04-170602095343/75/AI04-Scaling-Machine-Learning-to-Big-Data-Using-SparkML-and-SparkR-34-2048.jpg)









![tweetDF = spark.read.json('wasb:///libya-sentences/*/*.json') tweetDF = tweetDF[tweetDF.Language == 'en'] tokenizer = Tokenizer(inputCol="Sentence", outputCol="Words") enSW = StopWordsRemover.loadDefaultStopWords('english') + ['rt', '-', '&', ''] swr = StopWordsRemover(inputCol="Words", outputCol="Filtered", stopWords=enSW) tokenized = tokenizer.transform(tweetDF) filtered = swr.transform(tokenized) counter = CountVectorizer(inputCol="Filtered", outputCol=“rawFeatures", vocabSize=10000, minDF=2.) countModel = counter.fit(filtered) counted = countModel.transform(filtered)](https://image.slidesharecdn.com/ai04-170602095343/75/AI04-Scaling-Machine-Learning-to-Big-Data-Using-SparkML-and-SparkR-48-2048.jpg)
![idf = IDF(inputCol="rawFeatures", outputCol="features") idfModel = idf.fit(counted) idfScaled = idfModel.transform(counted) gbt = GBTClassifier(labelCol="label", featuresCol="features", maxIter=10) # 80/20 train/test split train, test = labeled.randomSplit([0.8, 0.2], seed=1337) model = gbt.fit(train)](https://image.slidesharecdn.com/ai04-170602095343/75/AI04-Scaling-Machine-Learning-to-Big-Data-Using-SparkML-and-SparkR-50-2048.jpg)

![%%local %matplotlib inline from sklearn.metrics import roc_curve,auc prob = predResults['prediction'] fpr, tpr, thresholds = roc_curve(predResults['label'], prob, pos_label=1); roc_auc = auc(fpr, tpr) plt.figure(figsize=(5,5)); plt.plot(fpr, tpr, label='ROC curve (area = %0.2f)' % roc_auc) plt.plot([0, 1], [0, 1], 'k--'); plt.xlim([0.0, 1.0]); plt.ylim([0.0, 1.05]) plt.xlabel('False Positive Rate'); plt.ylabel('True Positive Rate') plt.title('ROC Curve'); plt.legend(loc="lower right") plt.show()](https://image.slidesharecdn.com/ai04-170602095343/75/AI04-Scaling-Machine-Learning-to-Big-Data-Using-SparkML-and-SparkR-52-2048.jpg)



![[AI04] Scaling Machine Learning to Big Data Using SparkML and SparkR](https://image.slidesharecdn.com/ai04-170602095343/75/AI04-Scaling-Machine-Learning-to-Big-Data-Using-SparkML-and-SparkR-57-2048.jpg)