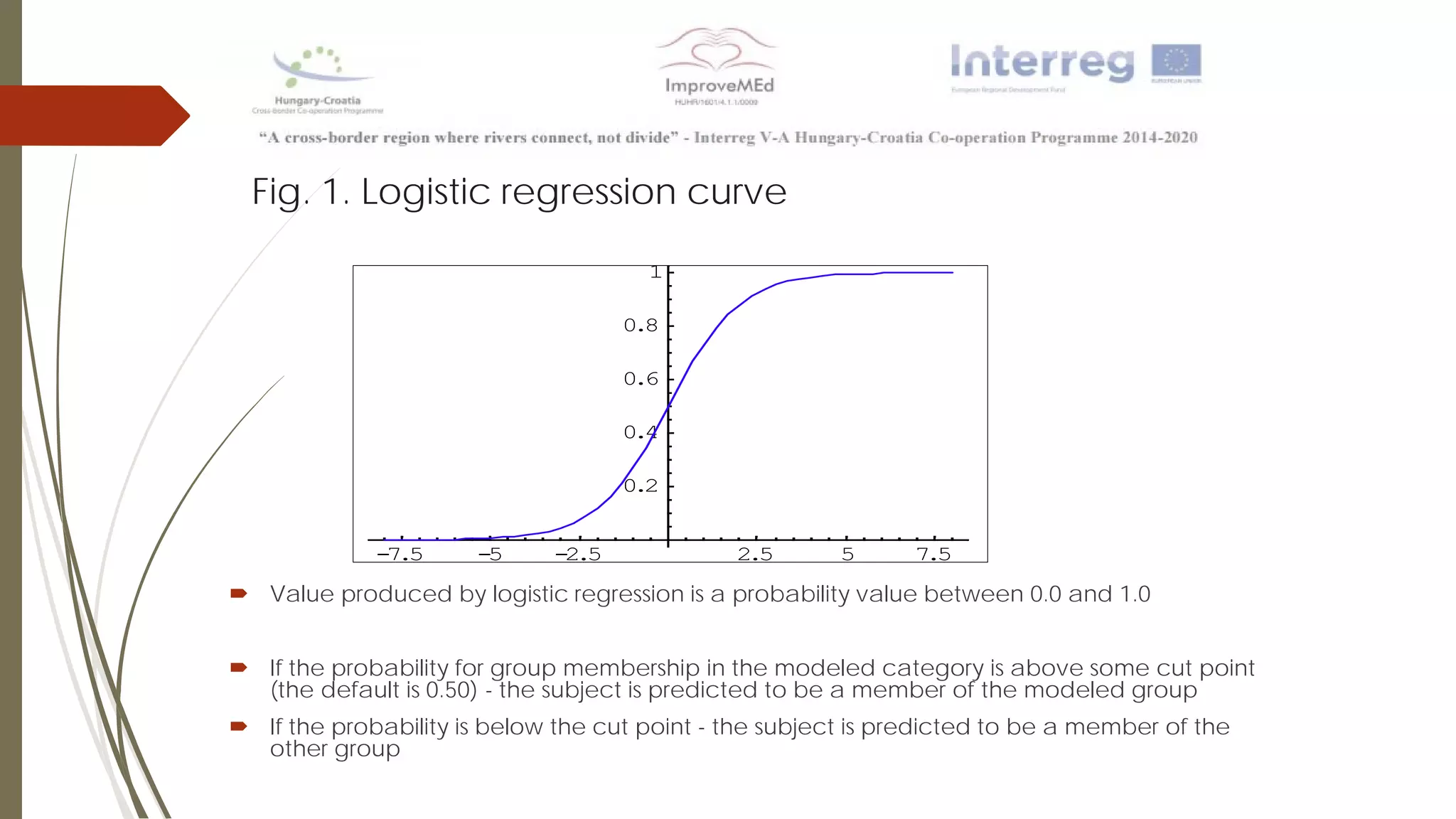
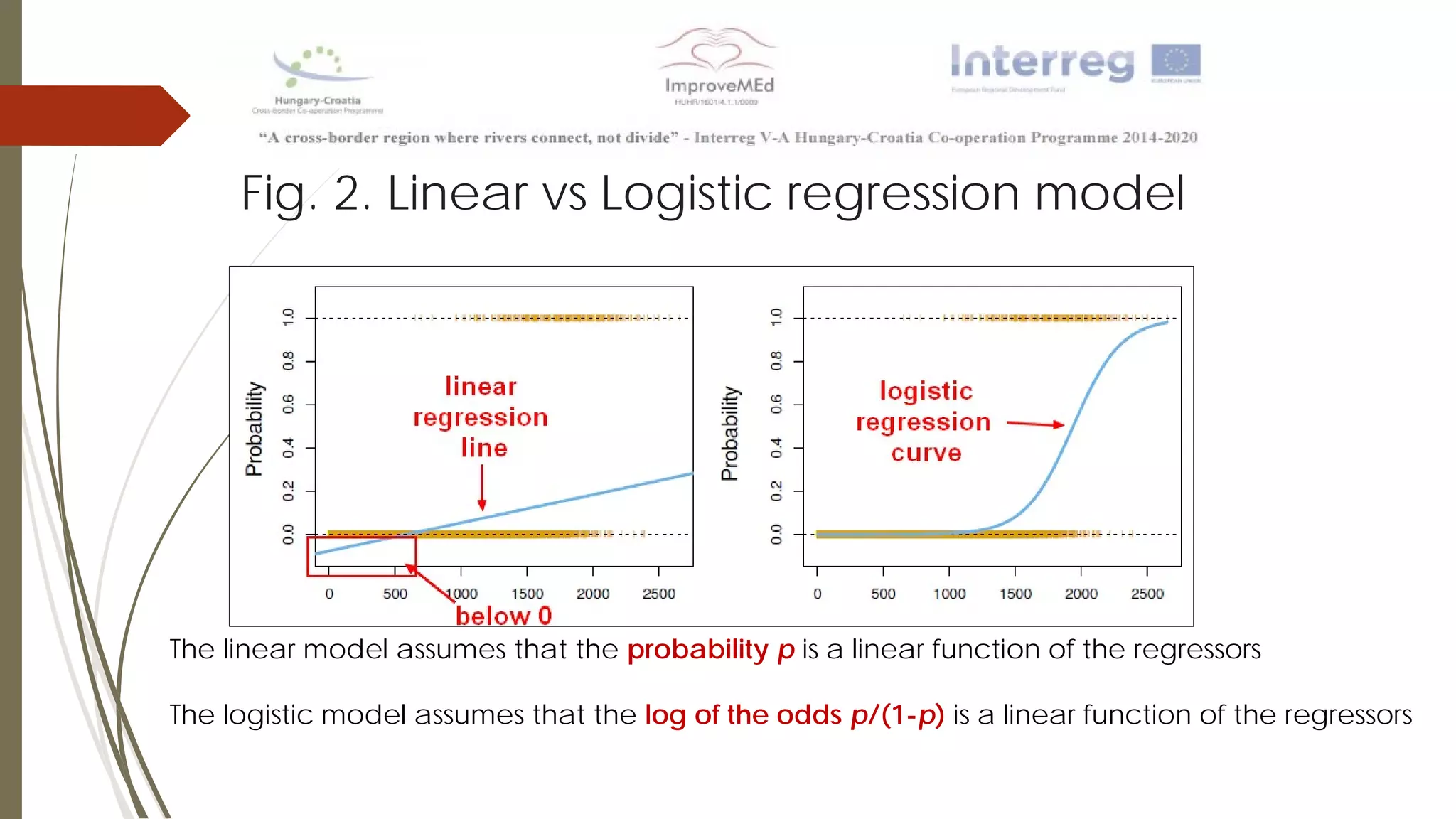
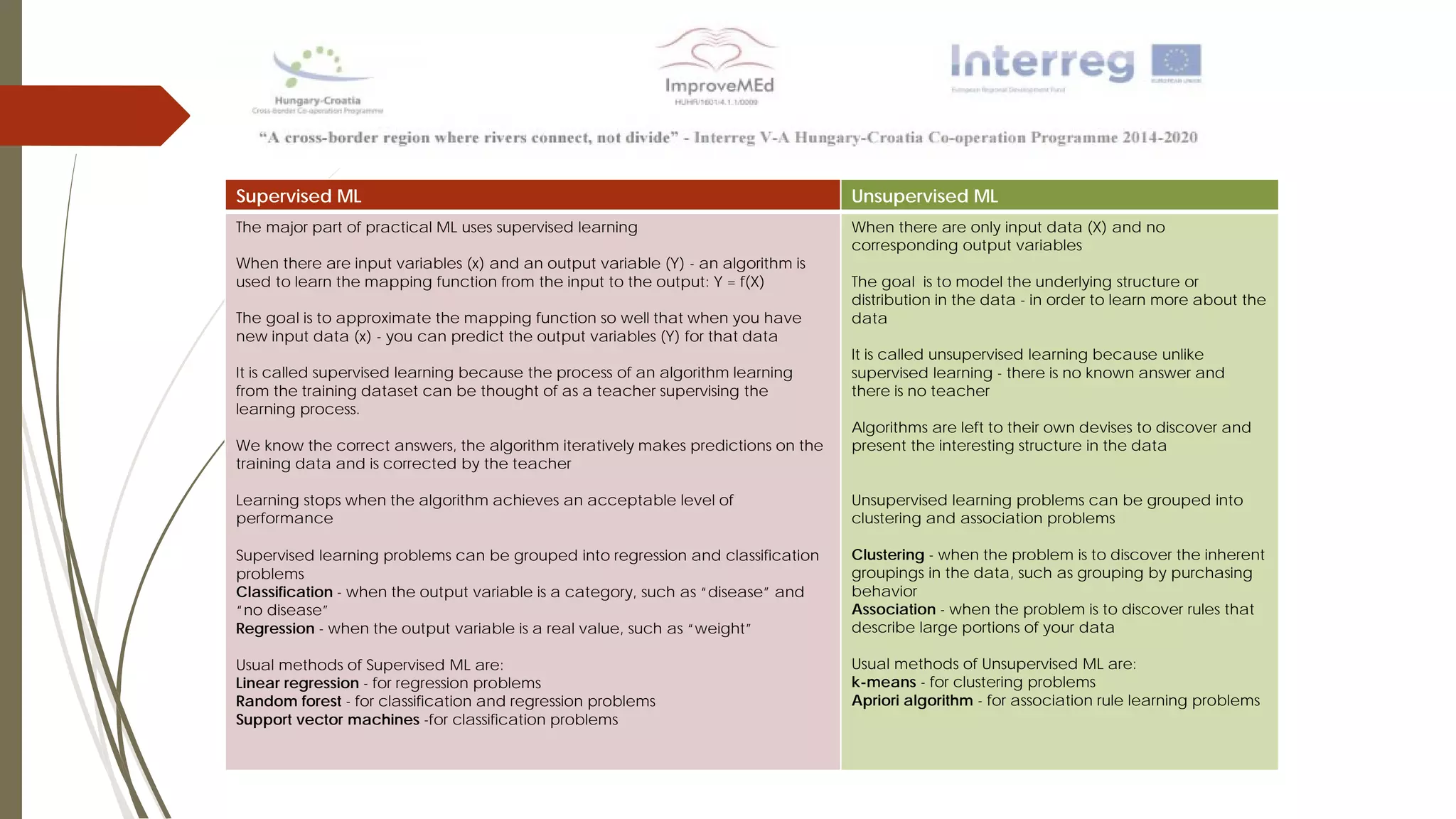
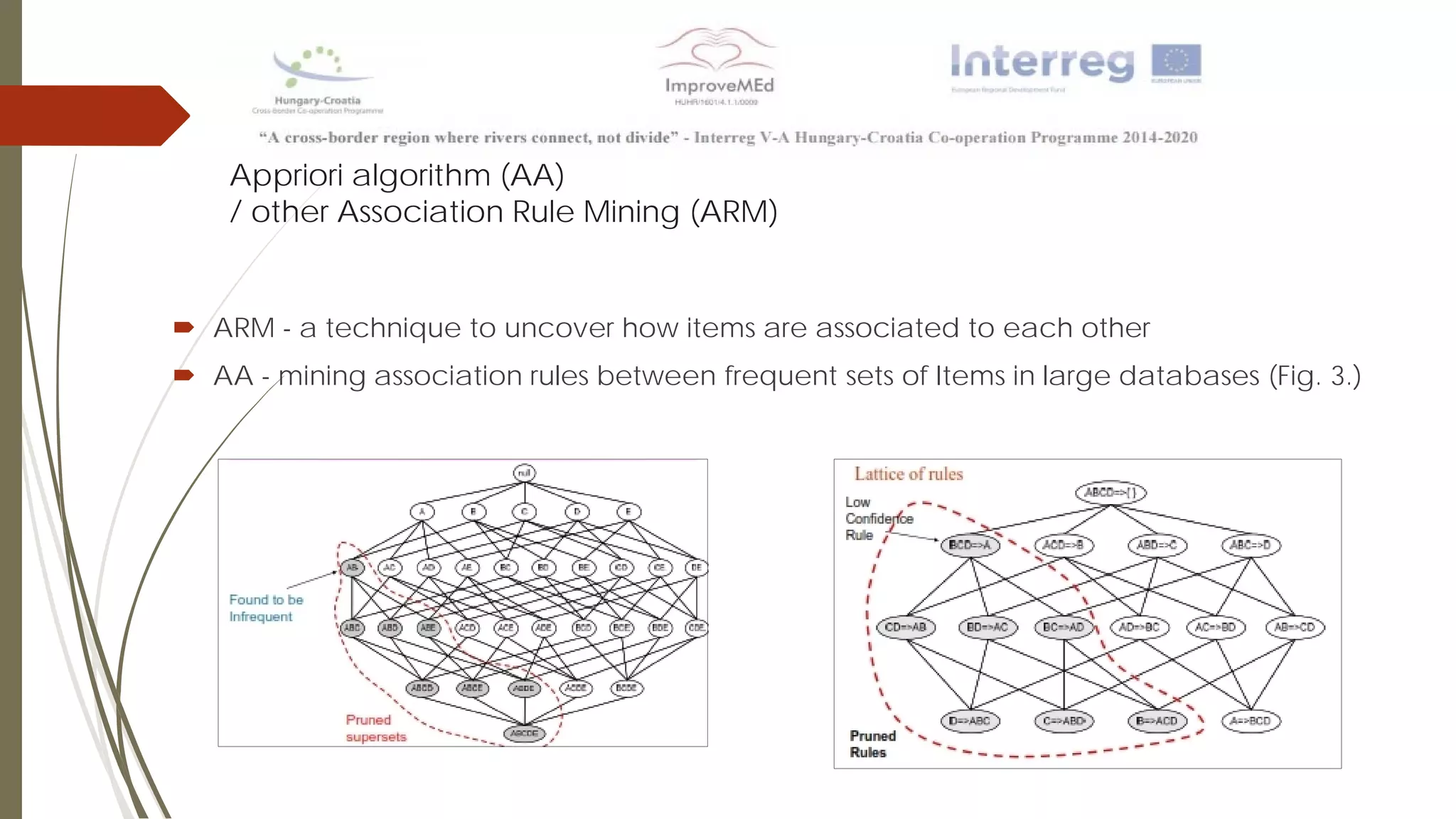
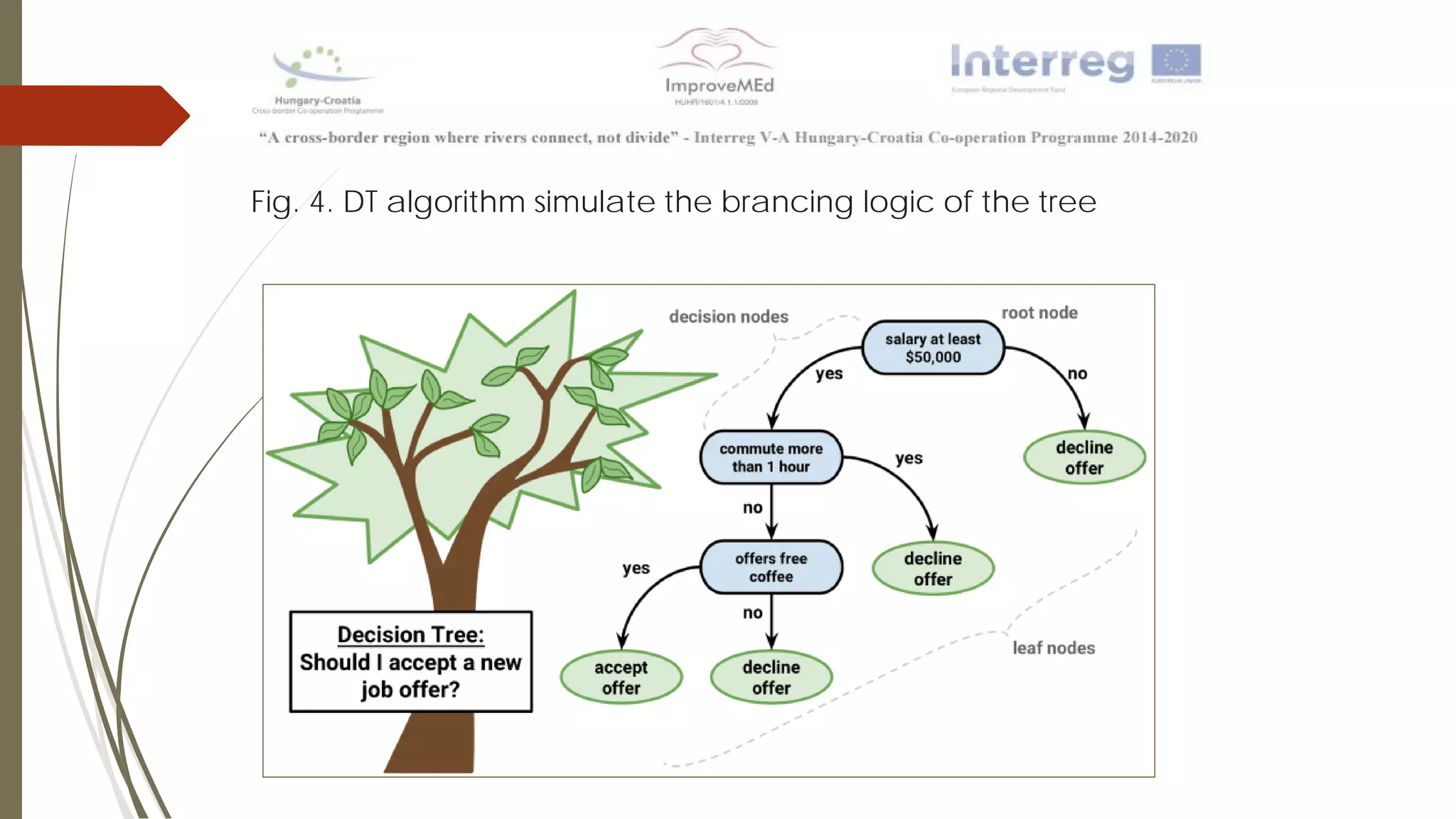
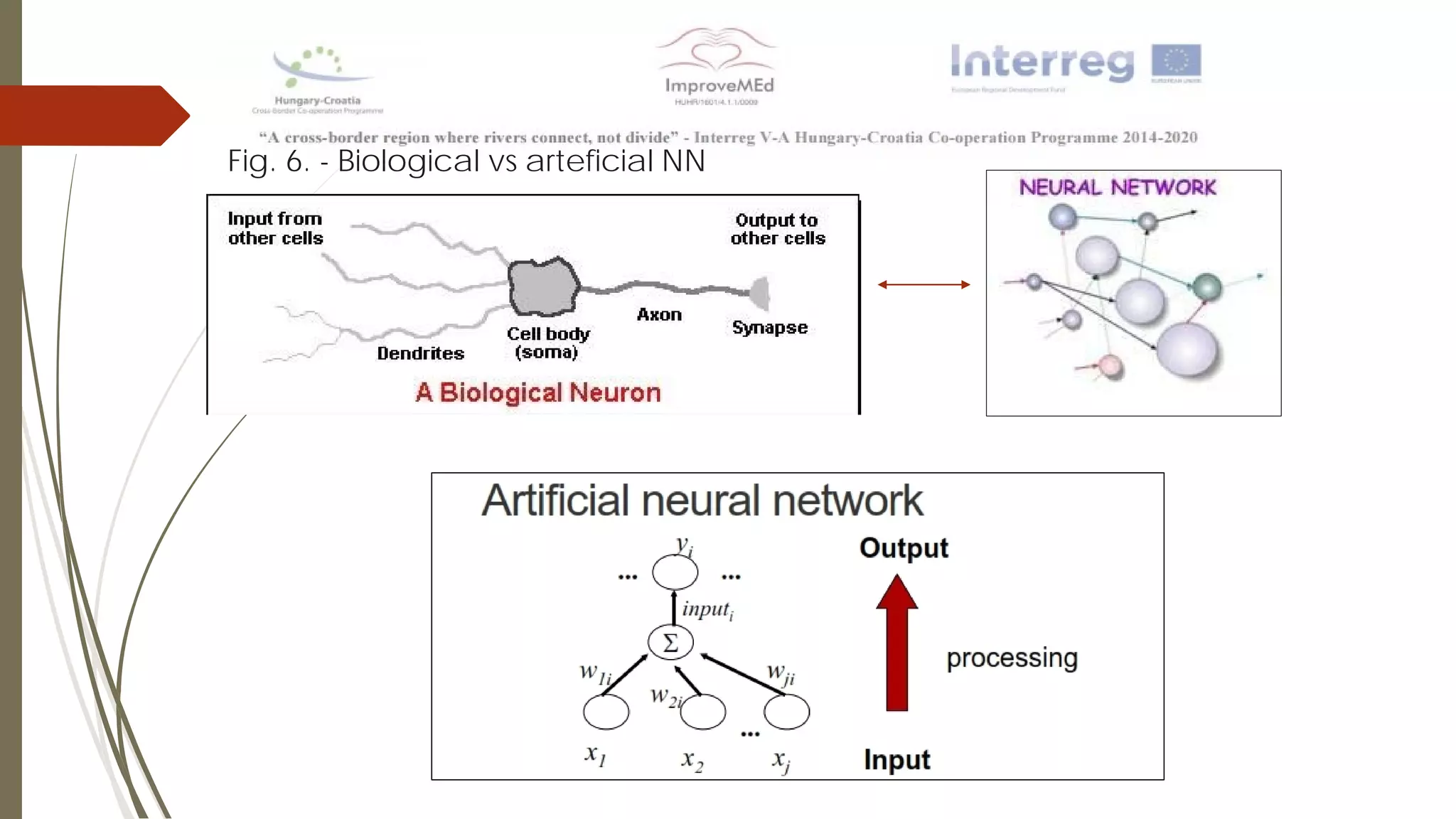
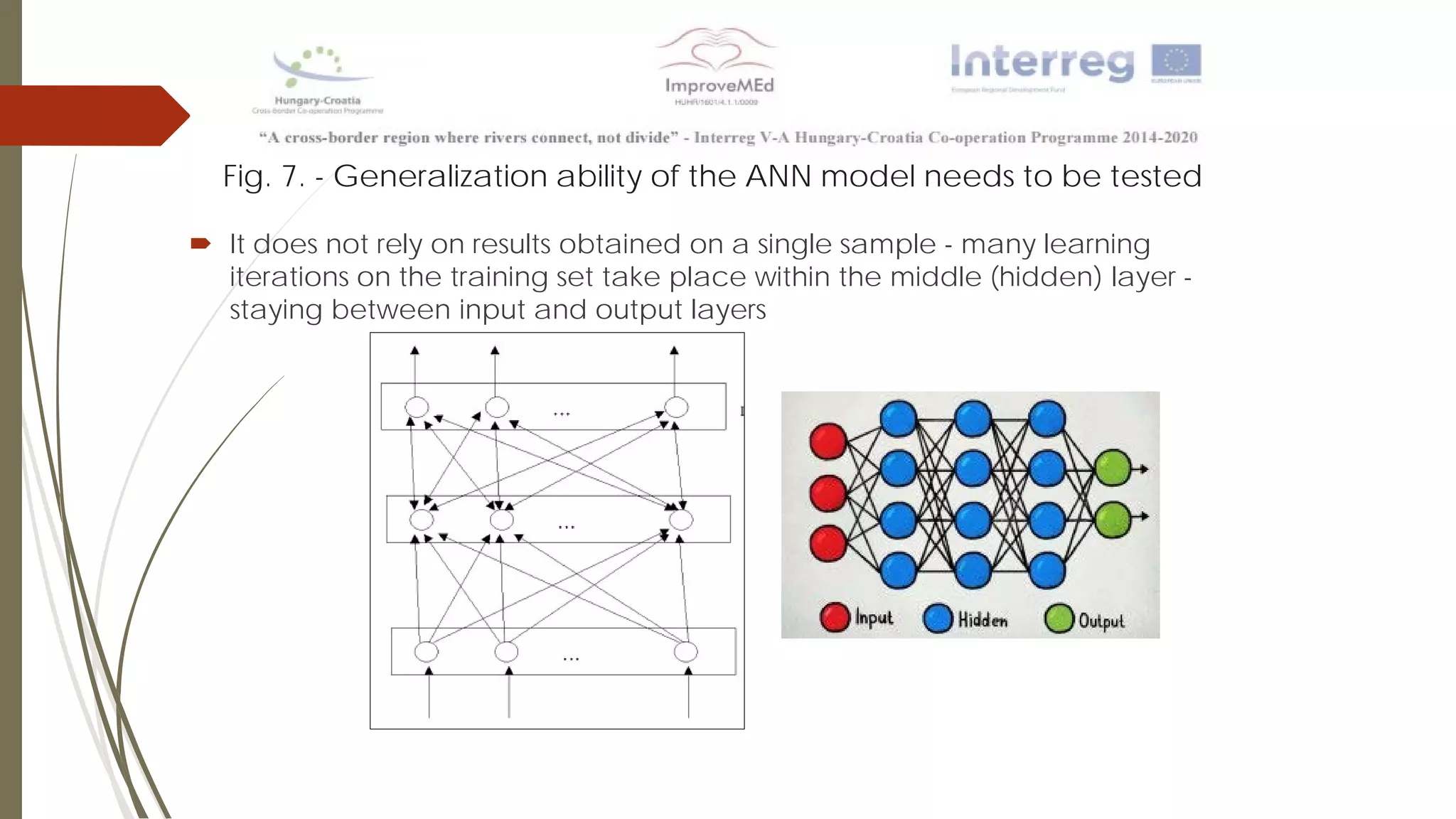
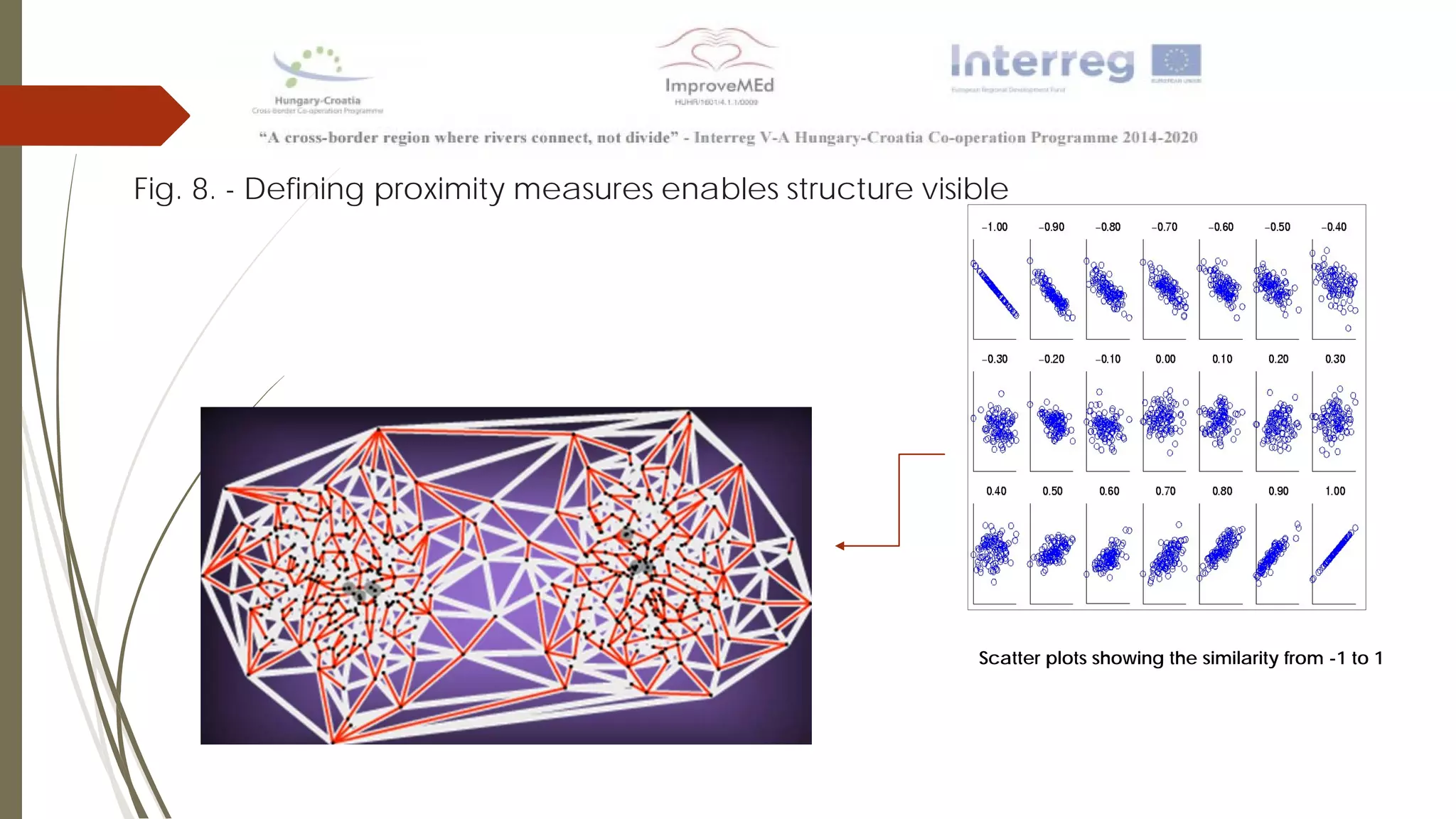
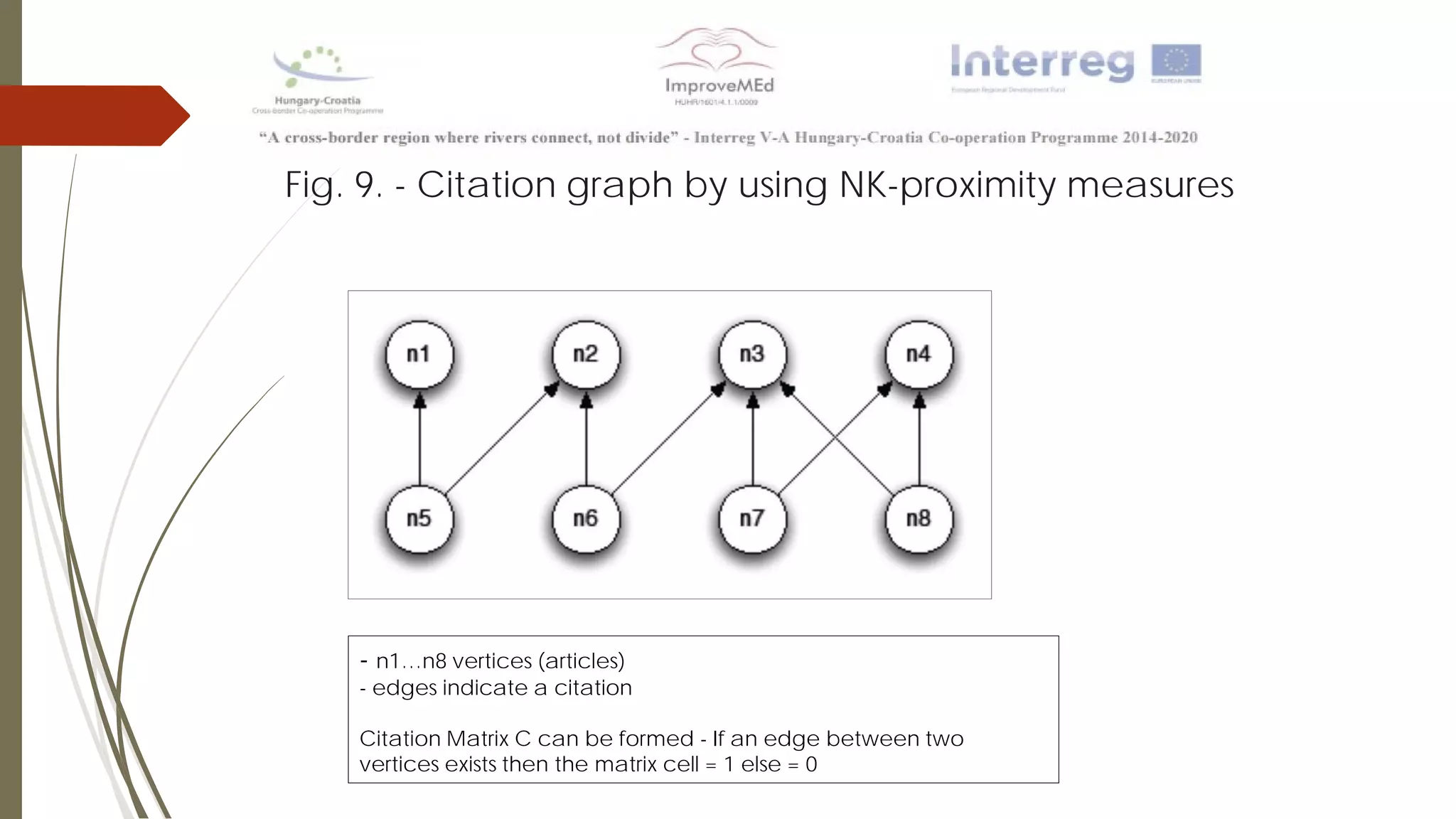
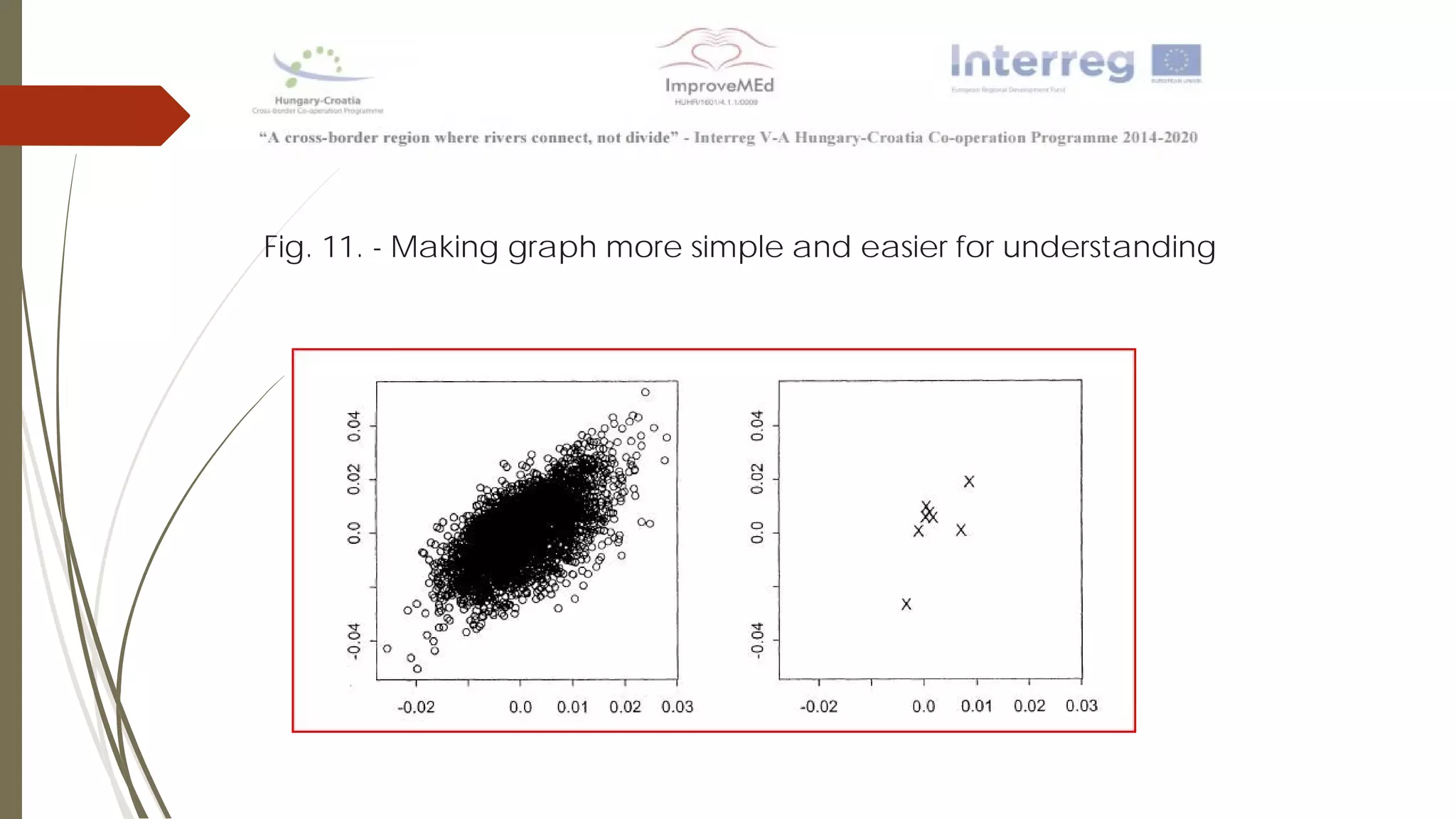
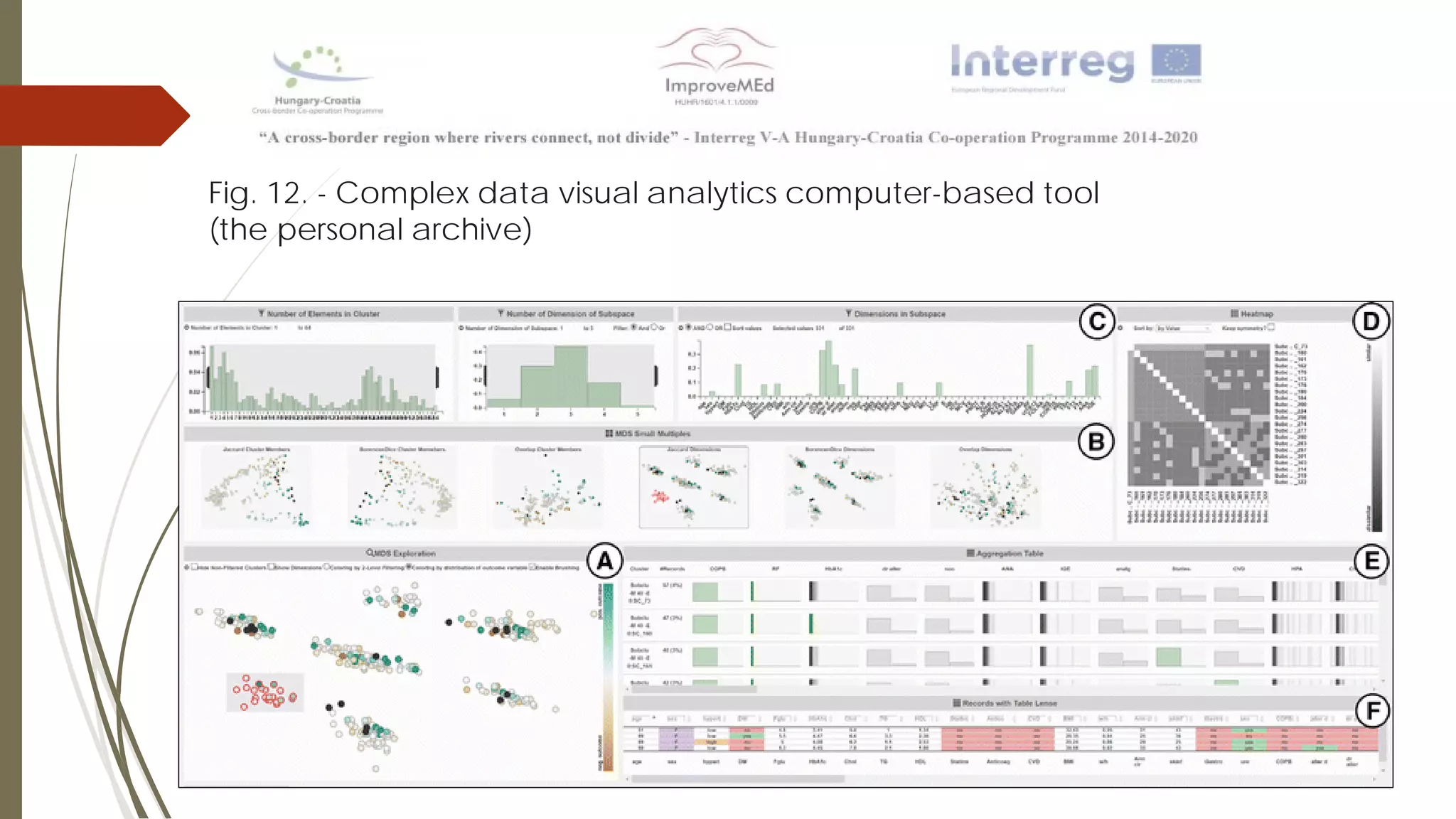
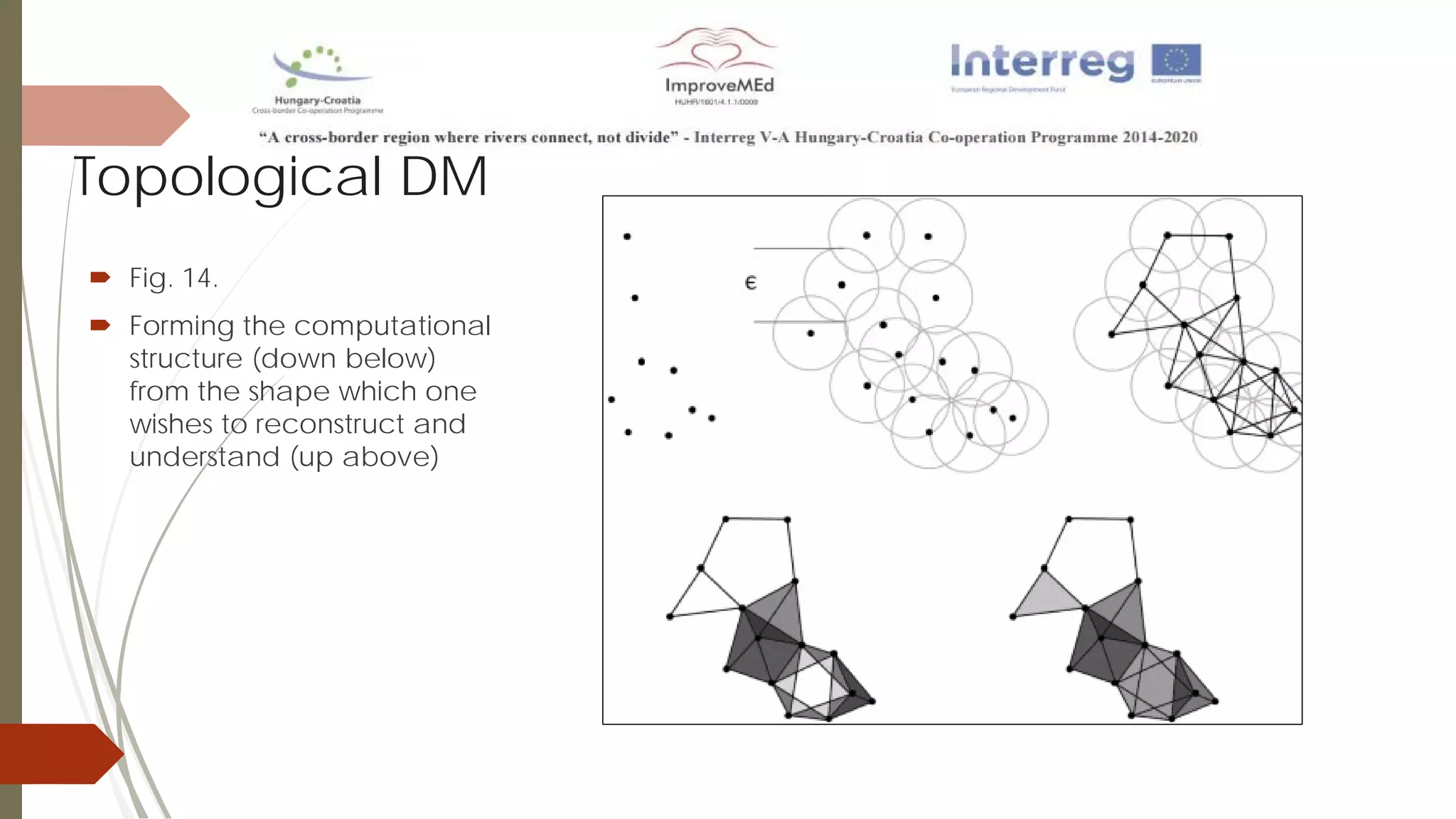
The document discusses various data mining methods. It describes data mining as seeking patterns within large databases. Common data mining methods mentioned include clustering, regression, rule extraction, and data visualization. Machine learning algorithms often used for health data include logistic regression, support vector machines, decision trees, and neural networks. The document also discusses newer techniques like graph-based data mining, topological data mining, and data visualization for exploring complex data.