Downloaded 122 times














The document provides a comprehensive overview of big data, its implications for various sectors, and the challenges associated with processing and analyzing it, including the need for advanced statistical methods and computing resources. It outlines the role of data science, highlighting the blend of statistical, machine learning, and domain knowledge required to derive insights from big data. A growing demand for analytics talent and the projected economic impact of data science on revenue are also discussed, emphasizing the emergence of data science hubs outside traditional tech centers.
Colleen M. Farrelly introduces the presentation.
Big Data is defined by volume, variety, and velocity, transforming various sectors as predicted.
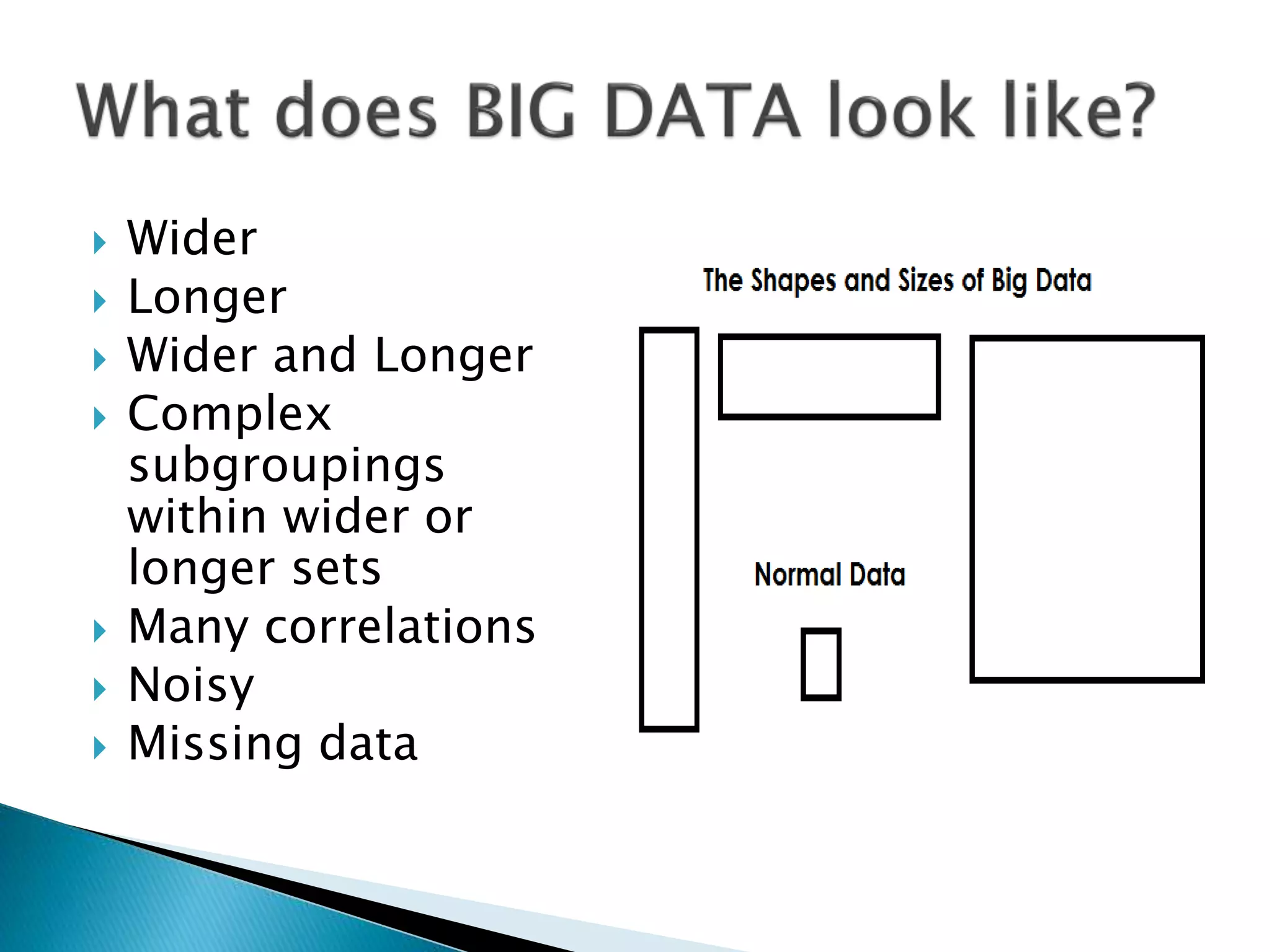
Big Data presents complex issues like correlations, noise, missing data, and computational/storage challenges.
Discusses the need for more computing resources, new statistical methods, and their limitations.
Overview of tools like Hadoop, MapReduce, SQL/NoSQL, R, and their application for data processing.
Key areas include statistics, mathematics, and machine learning for effective data analysis.
Data scientists combine expertise to extract insights from data, influencing decisions in various domains.
Steps include problem discussion, data preparation, analysis, and synthesis of actionable insights.
Profiles the educational and technical background needed for data scientists in various fields.
Examples of companies hiring data scientists, showcasing a diverse employment landscape.
Projected revenue from data science insights and the importance of analytics talent across industries.