Downloaded 85 times


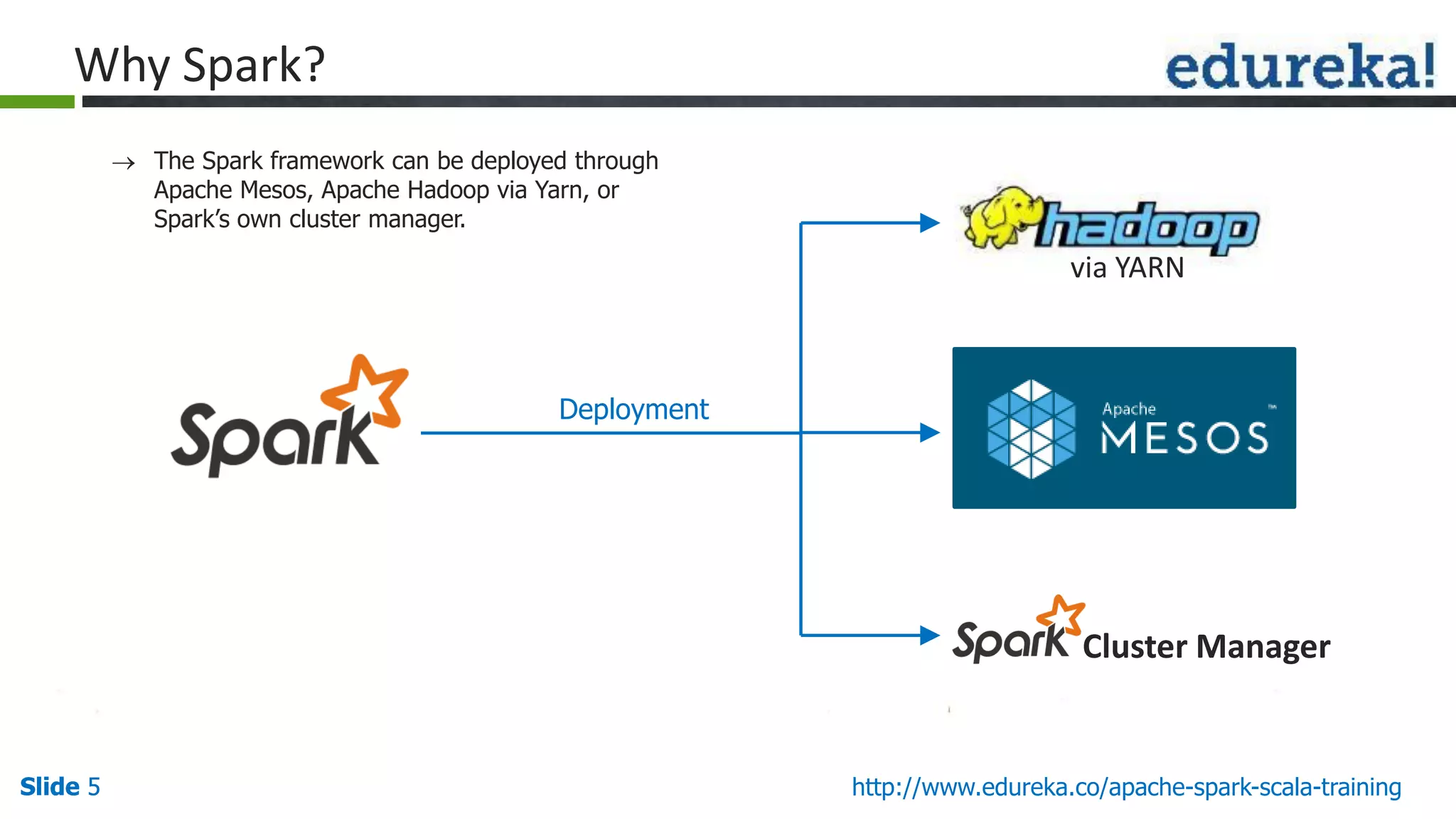
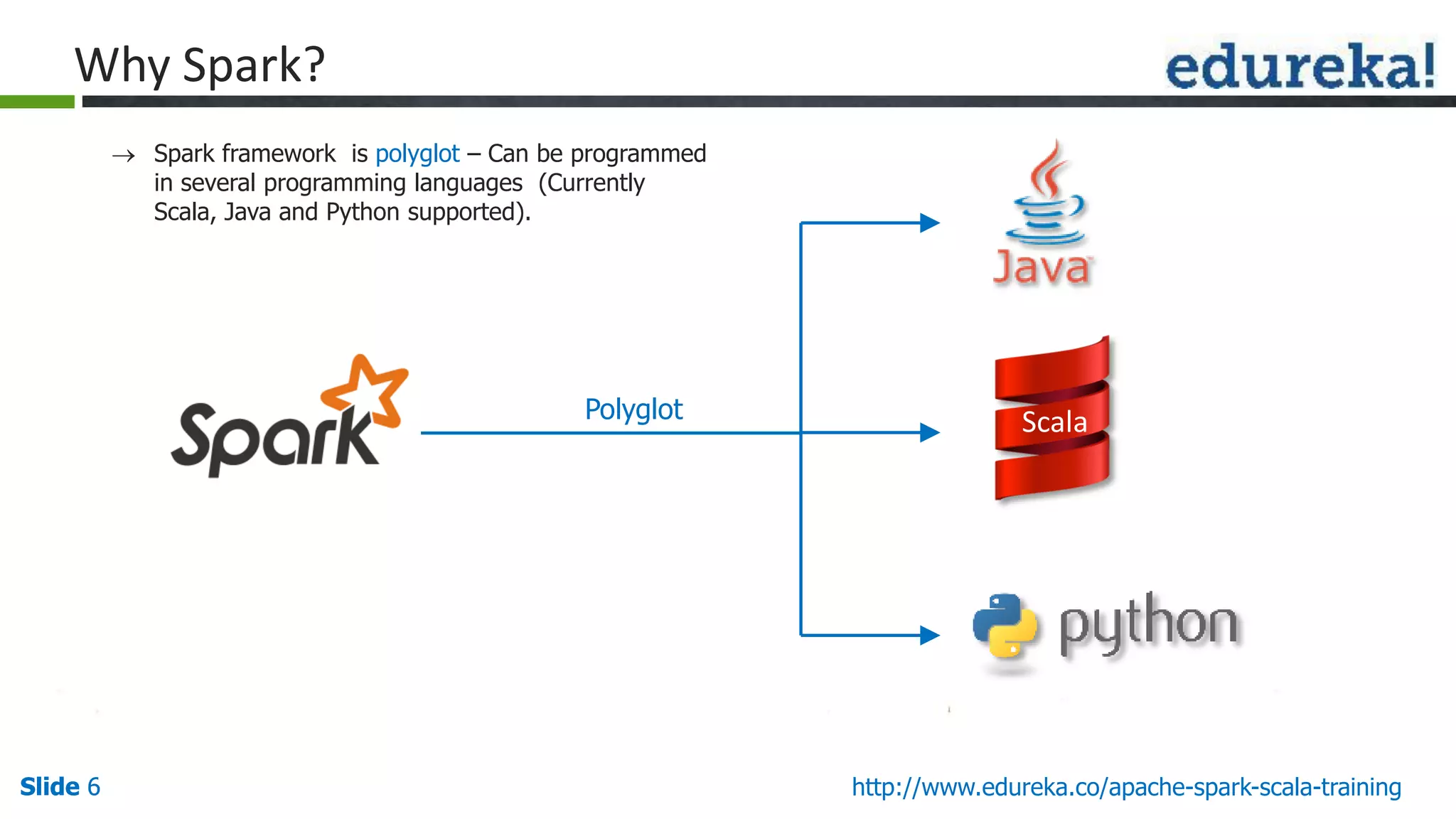




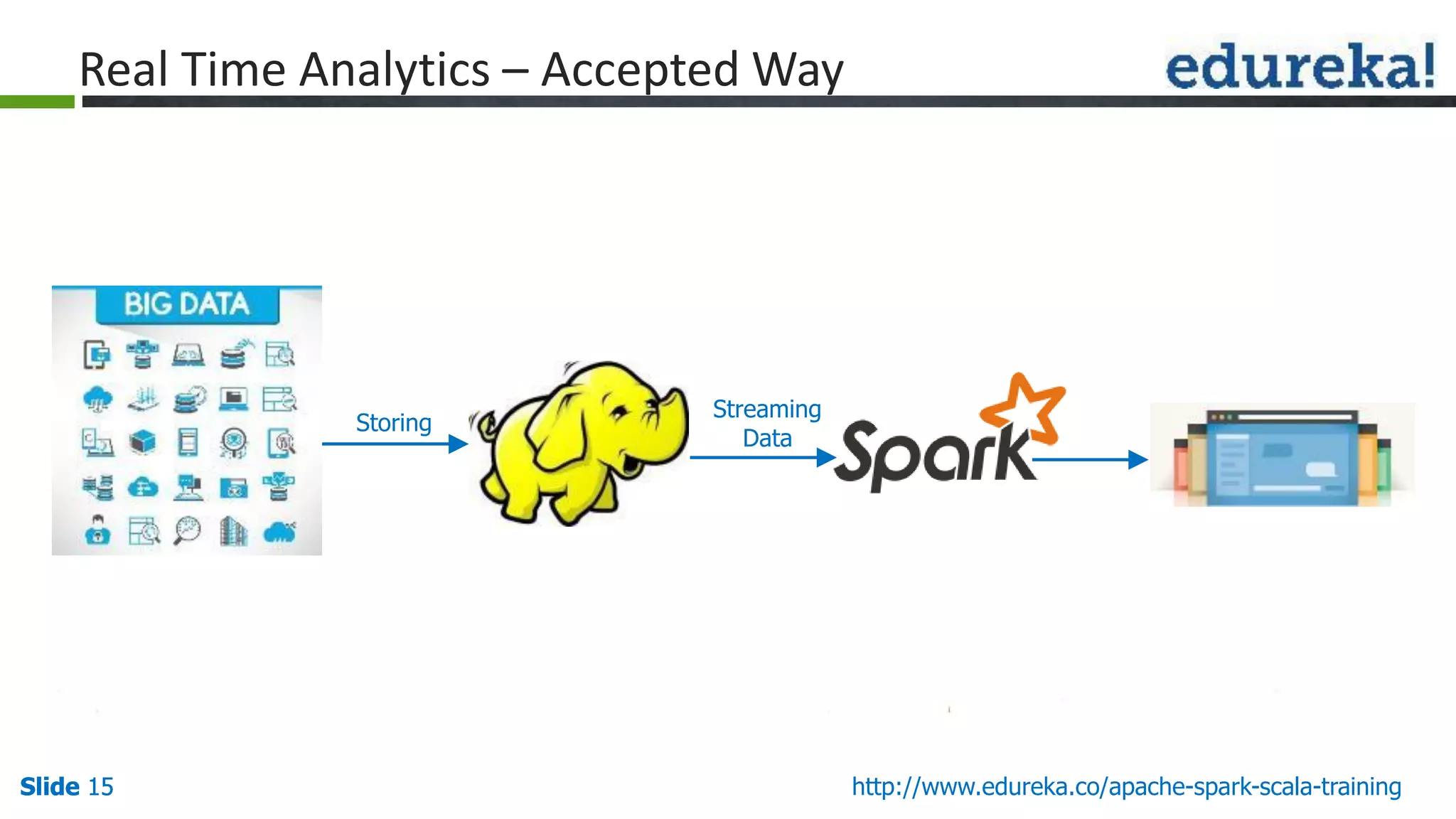
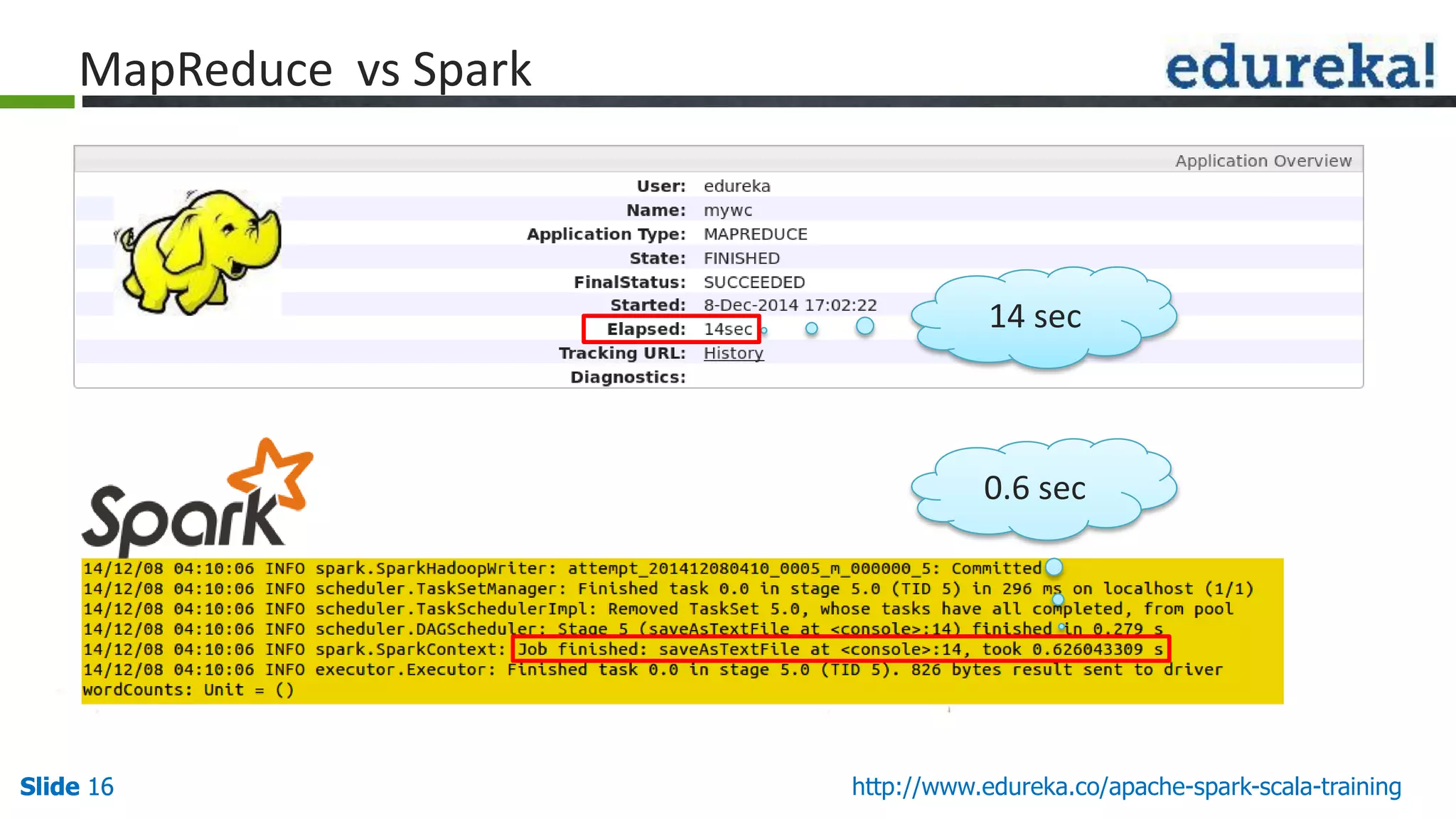




The document provides an overview of big data processing using Apache Spark and Scala, highlighting the definition of big data, the capabilities of Spark, and the advantages of using Scala with Spark. It explains Spark's ecosystem, which includes tools for SQL, machine learning, and streaming data, and compares Spark's performance to traditional MapReduce. The document emphasizes Spark's efficiency, versatility, and the necessity of Scala for effective big data manipulation.