Download as PDF, PPTX











![public static void main(String args[]) throws Exception { SimpleWalker sw = new SimpleWalker(); sw.parse(args[0]); sw.printAllElements(); } } // class SimpleWalker Prepared By: Prabu.U](https://image.slidesharecdn.com/buildingxmlbasedapplications-180322042009/75/Building-XML-Based-Applications-15-2048.jpg)











































![Working with SAX import java.io.*; import org.xml.sax.*; import org.xml.sax.helpers.*; import javax.xml.parsers.*; public class SAXDemo extends DefaultHandler { public void startDocument() { System.out.println(“***Start of Document***”); } public void endDocument() { System.out.println(“***End of Document***”); } public void startElement(String uri, String localName, String qName, Attributes attributes) { public void startElement(String uri, String localName, String qName, Attributes attributes) { System.out.print(“<” + qName); int n = attributes.getLength(); for (int i=0; i<n; i+=1) { System.out.print(“ “ + attributes.getQName(i) + “=’” + attributes.getValue(i) + “‘“); } System.out.println(“>”); } public void characters(char[] ch, int start, int length) { System.out.println(new String(ch, start, length).trim()); } public void endElement(String namespaceURI, String localName, String qName) throws SAXException { System.out.println(“</” + qName + “>”); } Prepared By: Prabu.U](https://image.slidesharecdn.com/buildingxmlbasedapplications-180322042009/75/Building-XML-Based-Applications-62-2048.jpg)
![Working with SAX public static void main(String args[]) throws Exception { if (args.length != 1) { System.err.println(“Usage: java SAXDemo <xml- file>”); System.exit(1); } SAXDemo handler = new SAXDemo(); SAXParserFactory factory = SAXParserFactory.newInstance(); SAXParser parser = factory.newSAXParser(); parser.parse(new File(args[0]), handler); } } Prepared By: Prabu.U](https://image.slidesharecdn.com/buildingxmlbasedapplications-180322042009/75/Building-XML-Based-Applications-63-2048.jpg)














































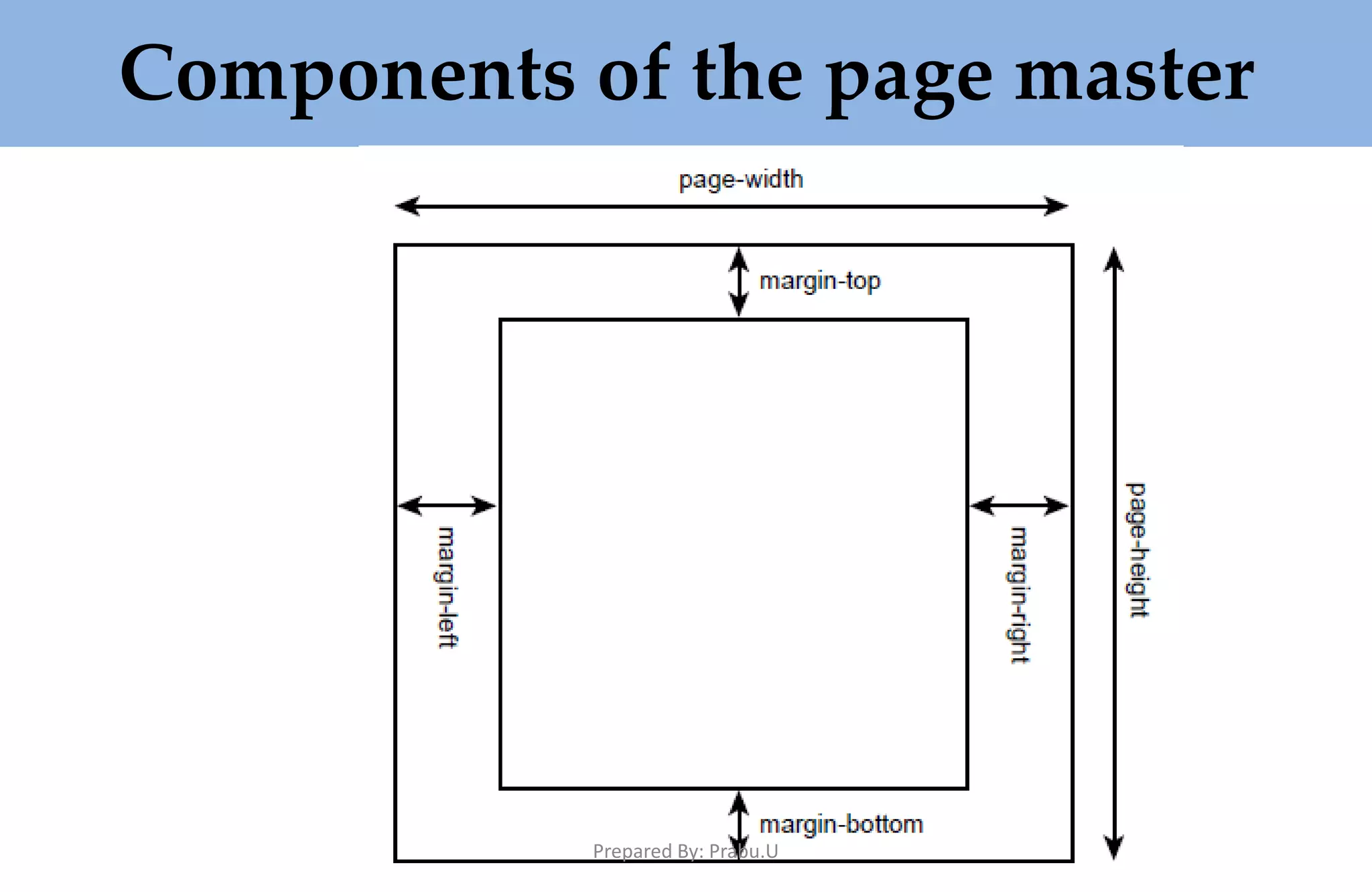
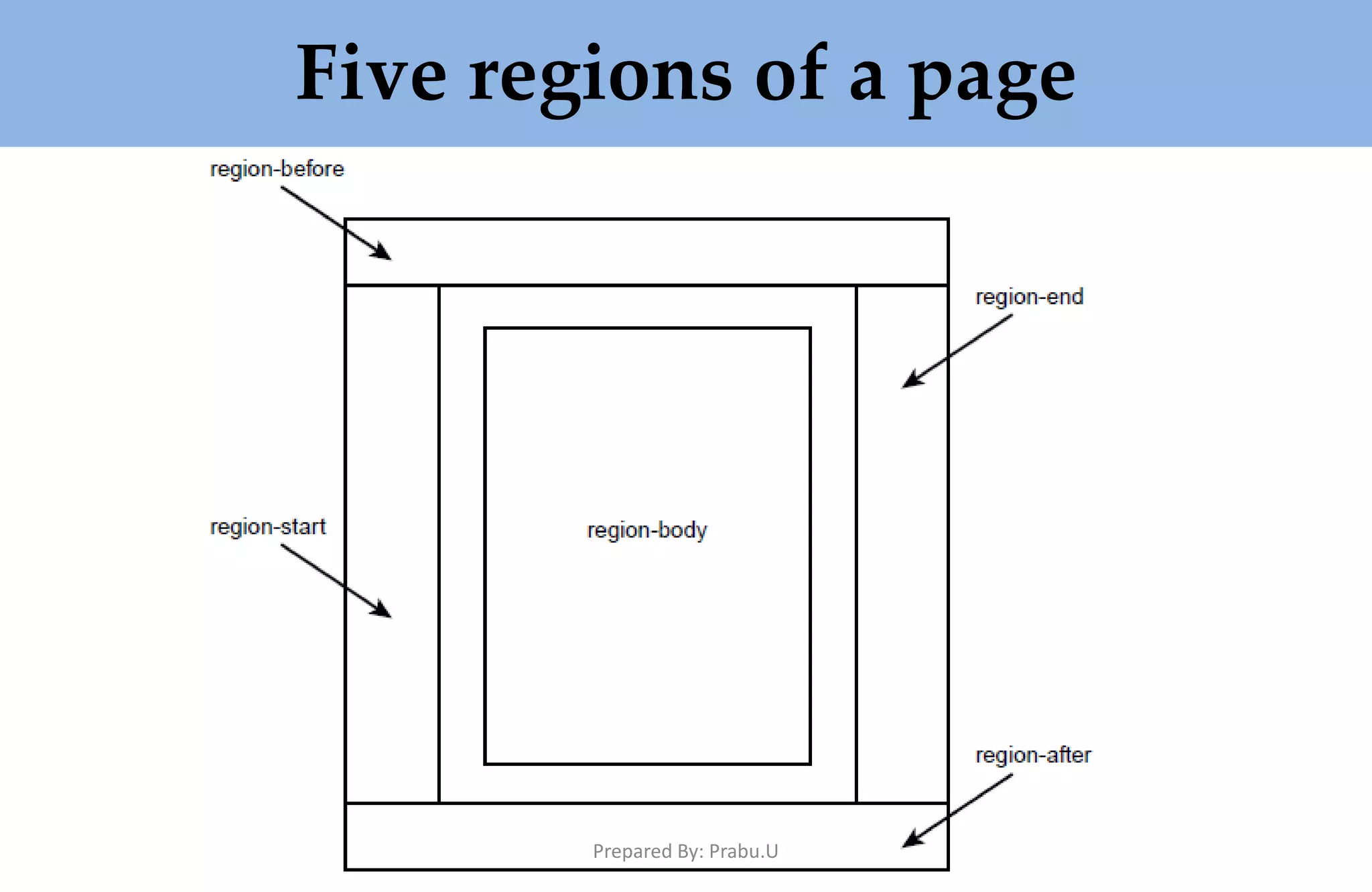

















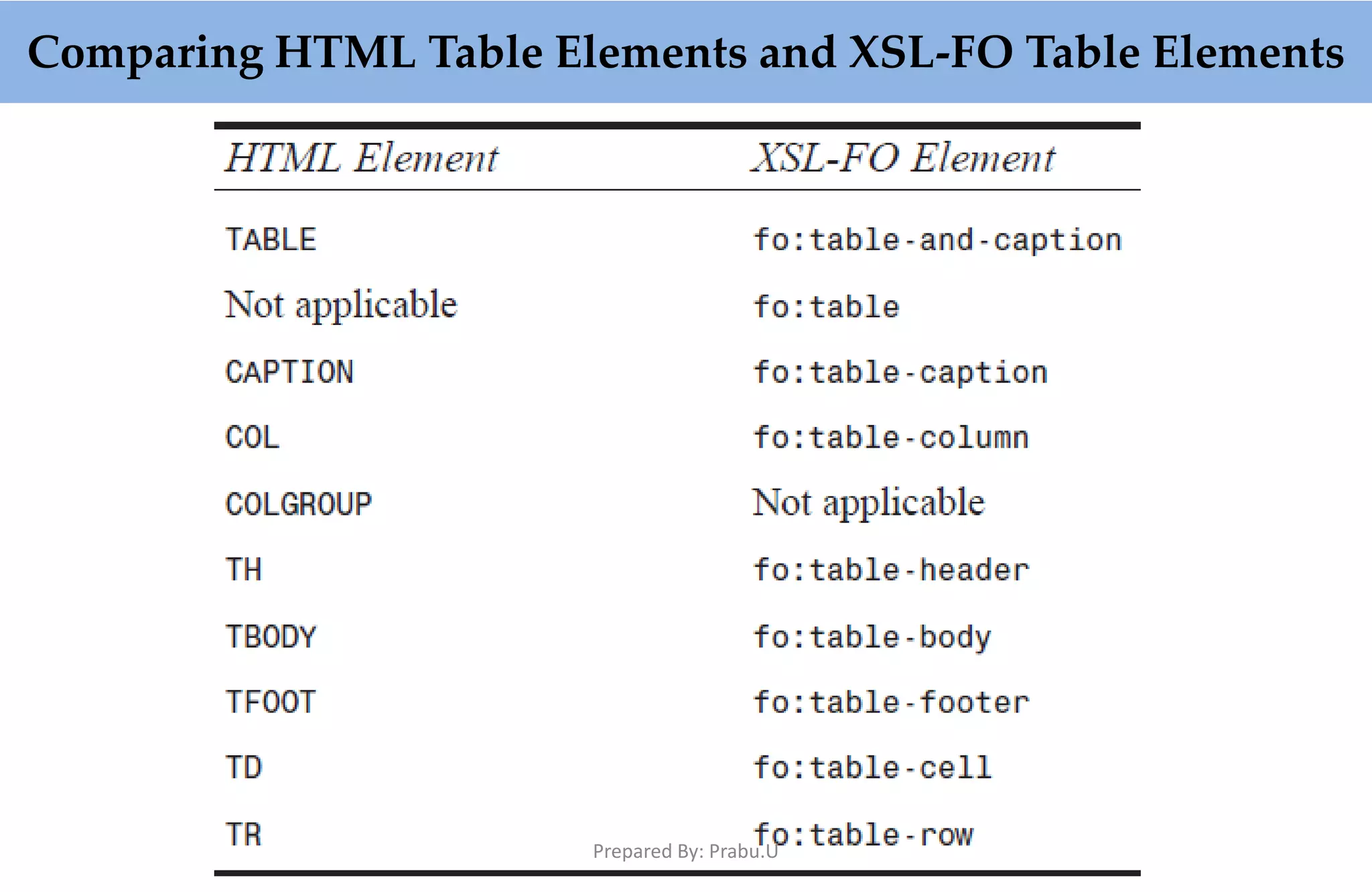





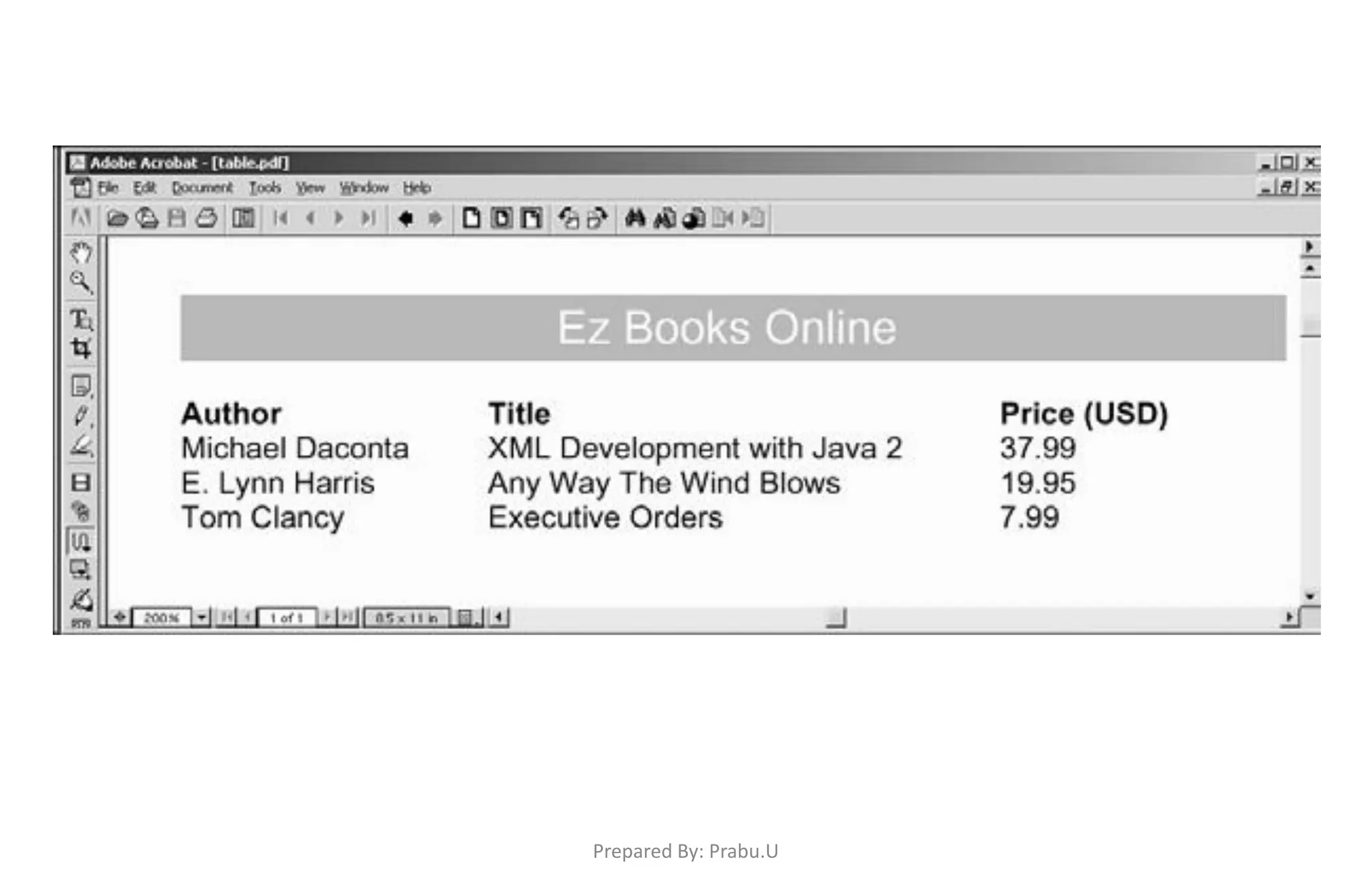










![public static void main(String[] args) { try { TestApp myApp = new TestApp(); myApp.process(); } catch (Exception exc) { exc.printStackTrace(); } } Prepared By: Prabu.U](https://image.slidesharecdn.com/buildingxmlbasedapplications-180322042009/75/Building-XML-Based-Applications-153-2048.jpg)



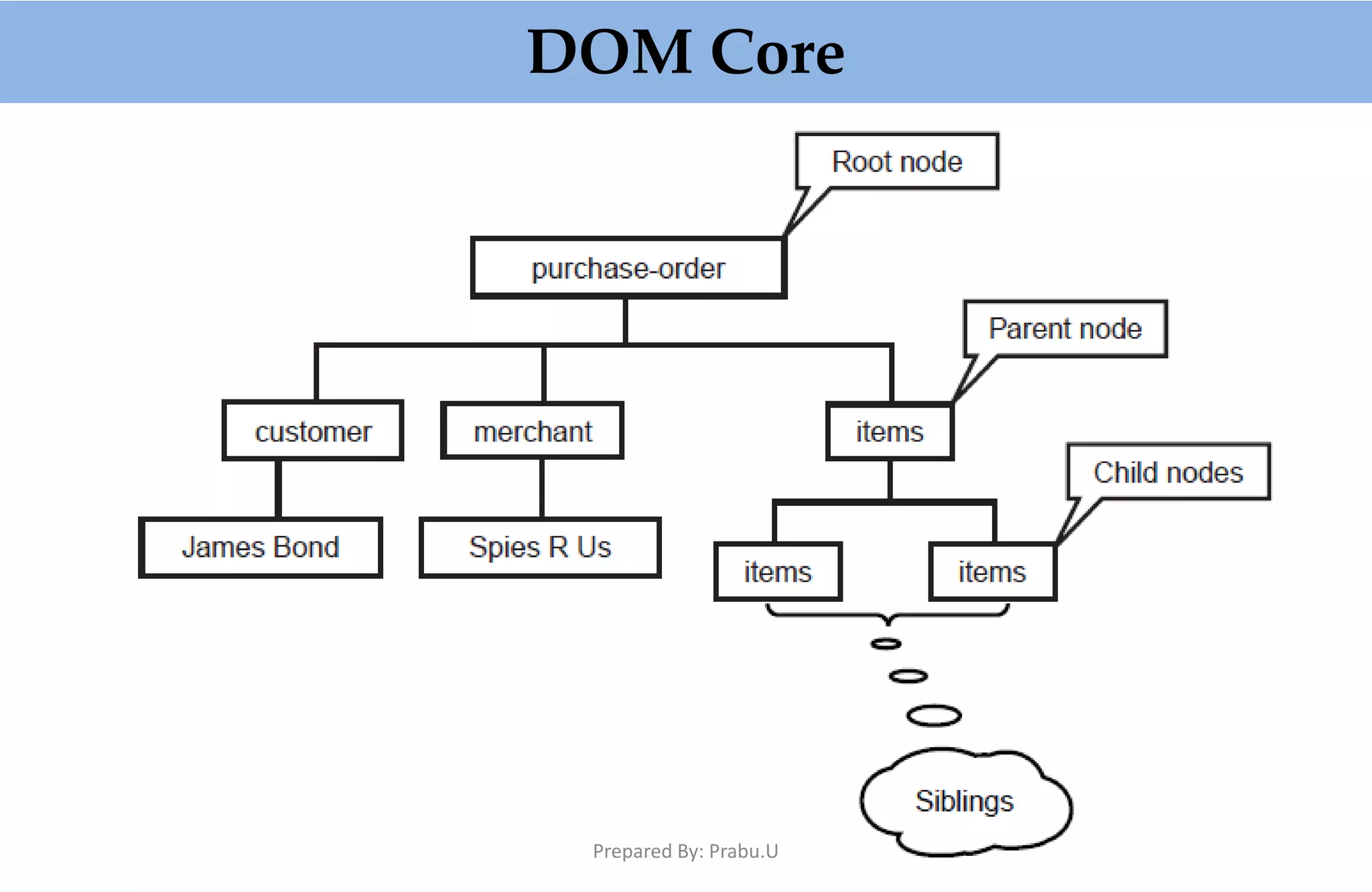
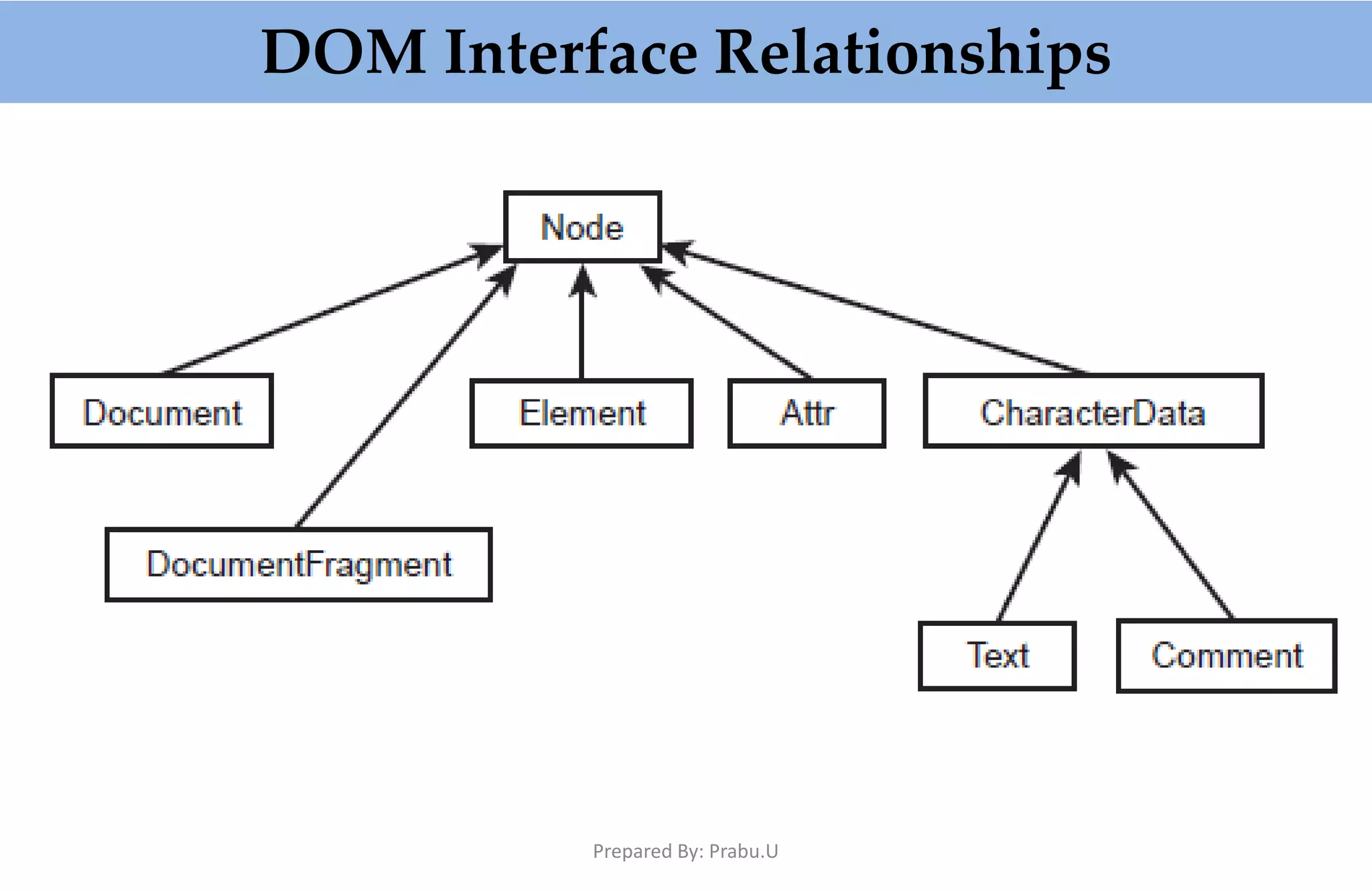
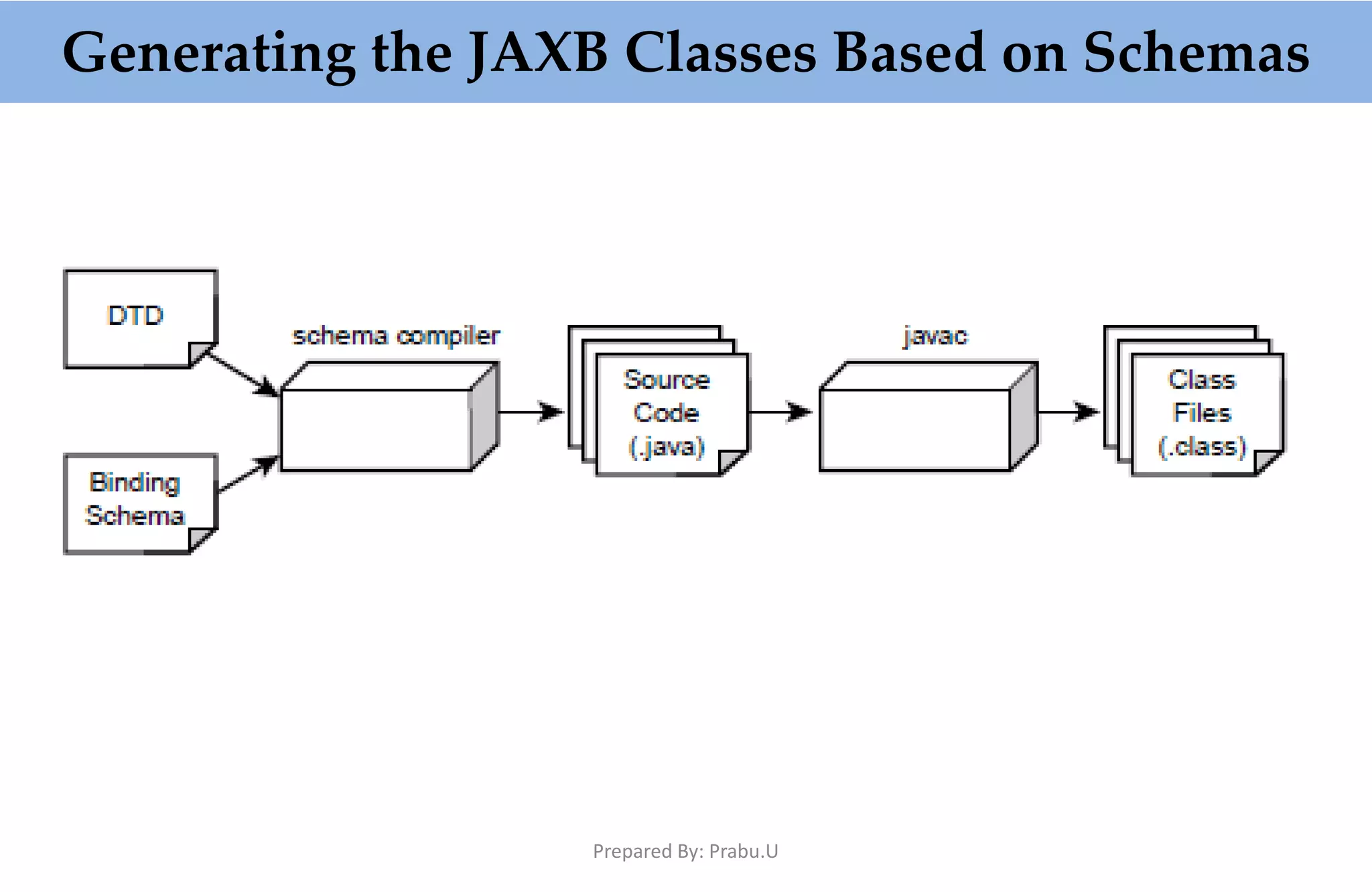
The document provides an in-depth overview of XML-based applications, focusing on the Document Object Model (DOM) and Simple API for XML (SAX) for parsing XML. It discusses the functionality, advantages, and disadvantages of using DOM, including its memory-intensive nature and its capacity for manipulating XML documents. Additionally, it highlights the event-driven nature of SAX, its efficiency with large documents, and contrasts it with DOM's capabilities, while mentioning alternative implementations like JDOM and Java Architecture for XML Binding (JAXB).