Downloaded 59 times


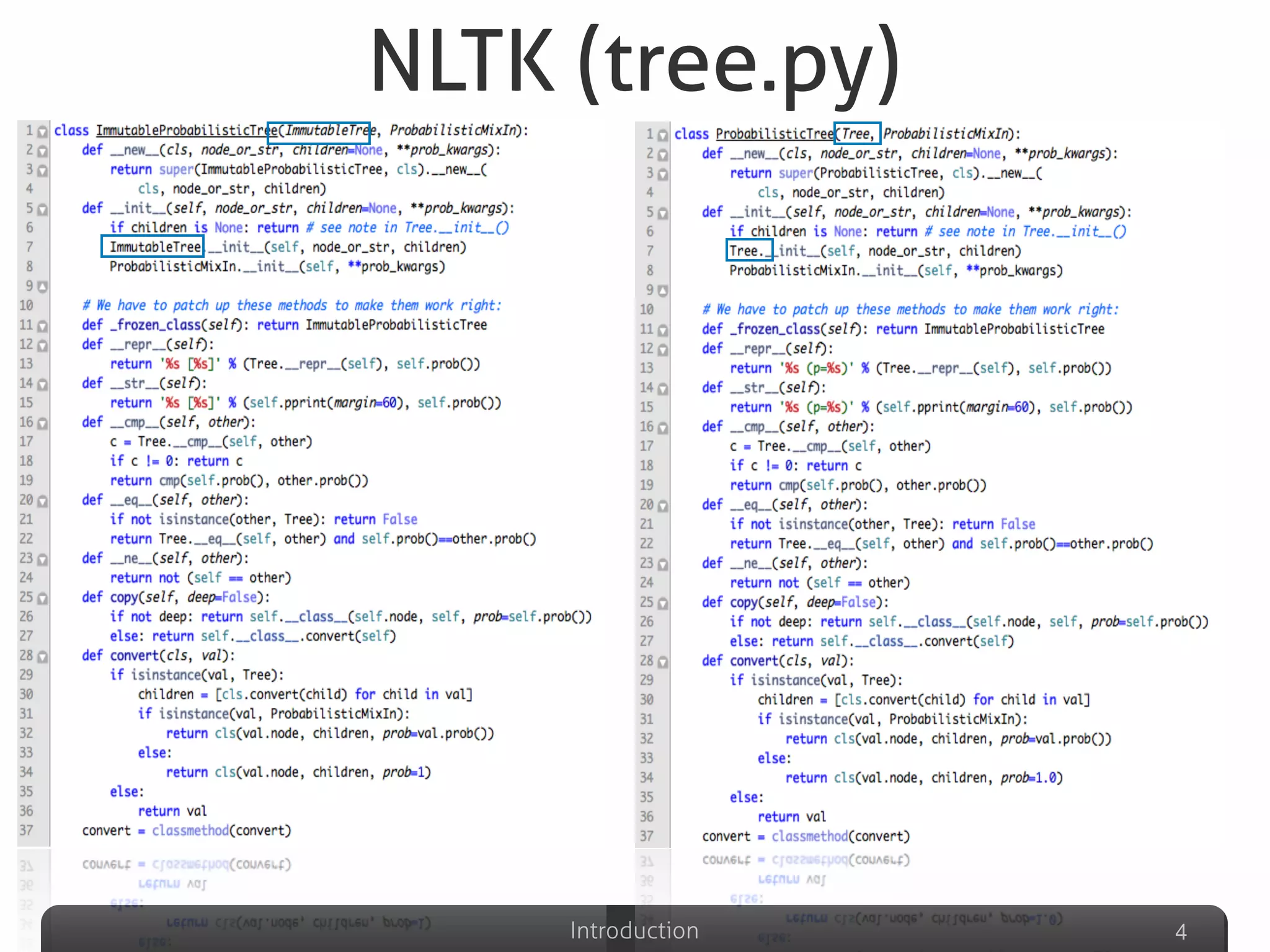
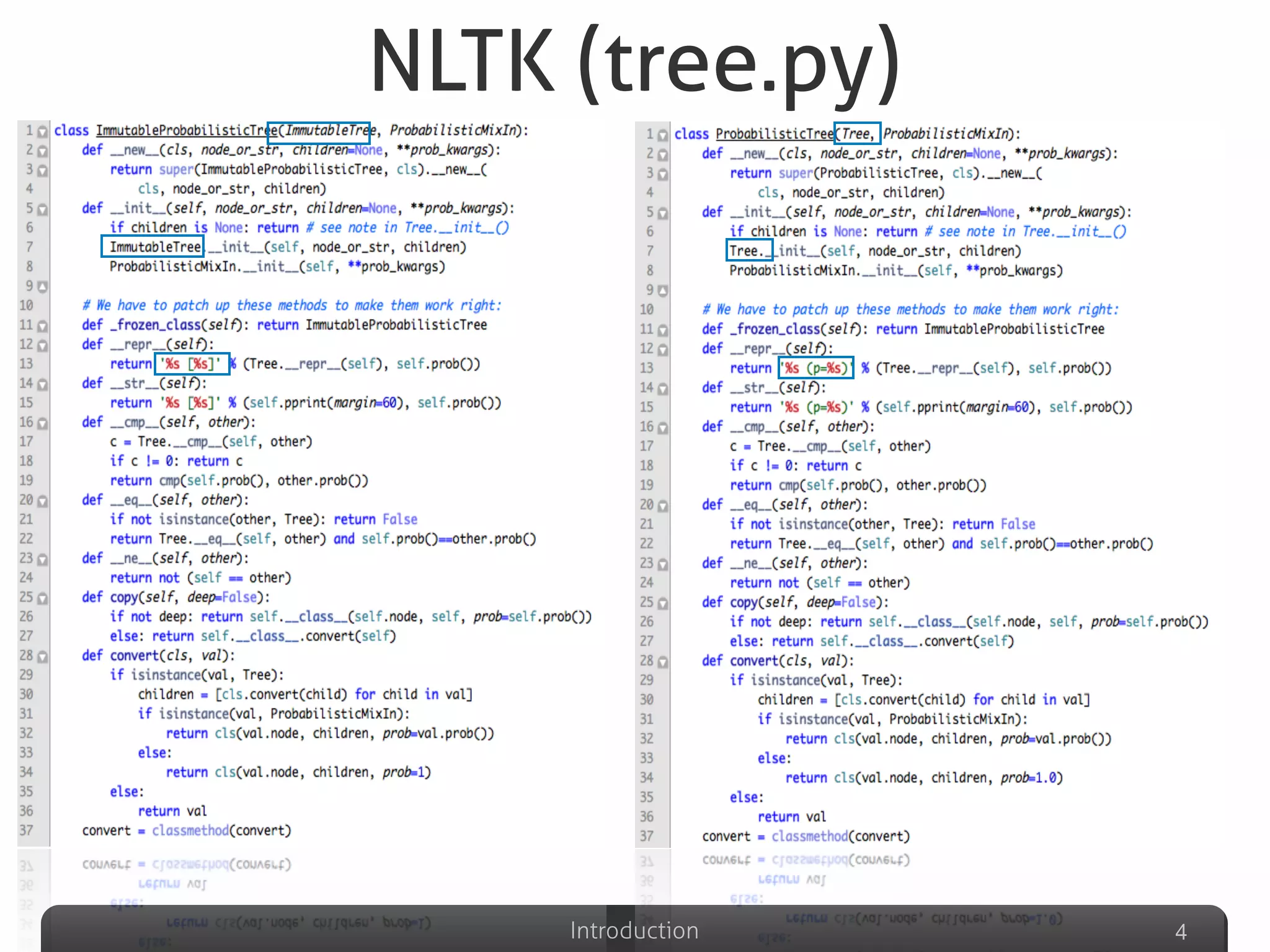
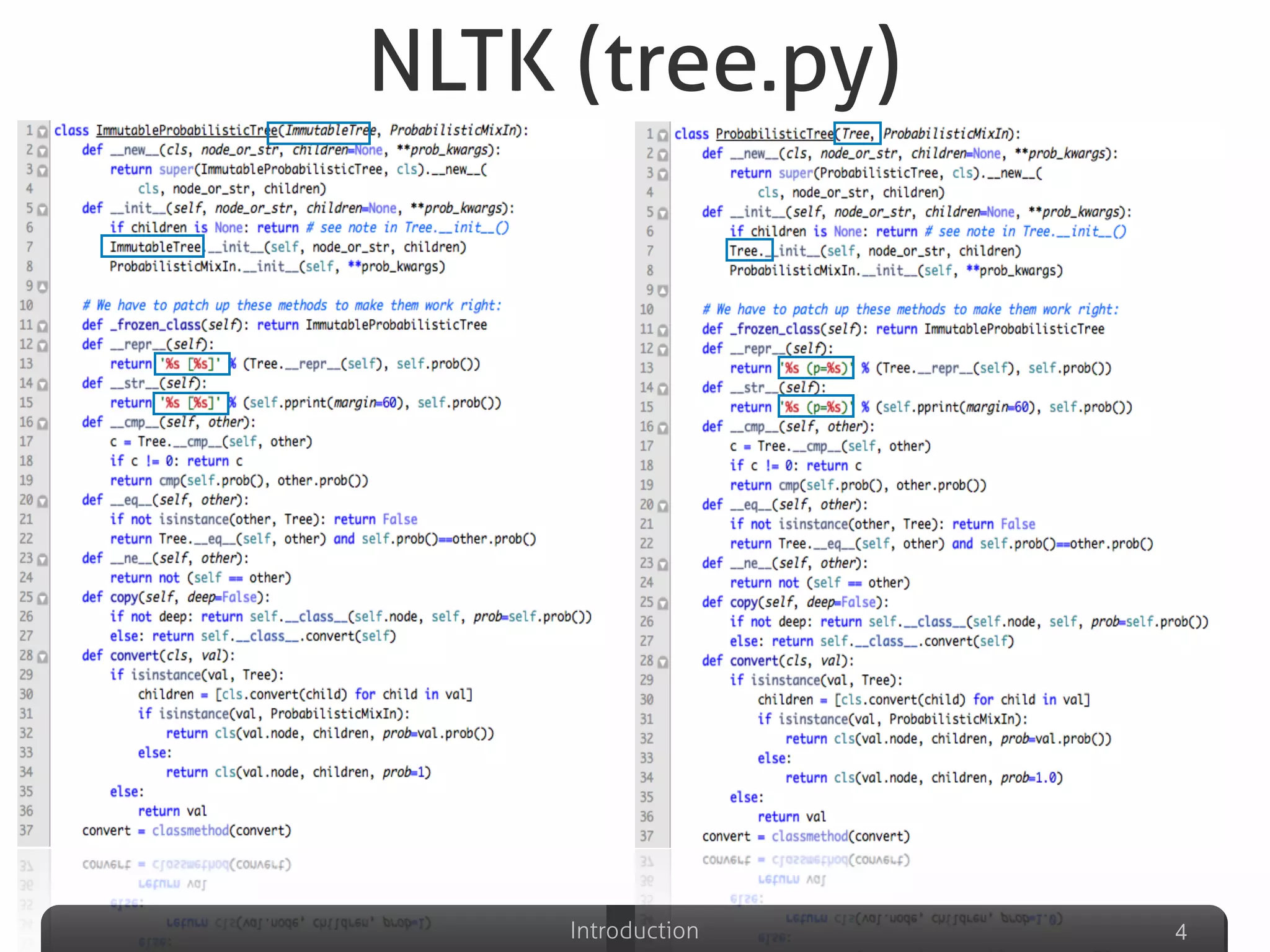
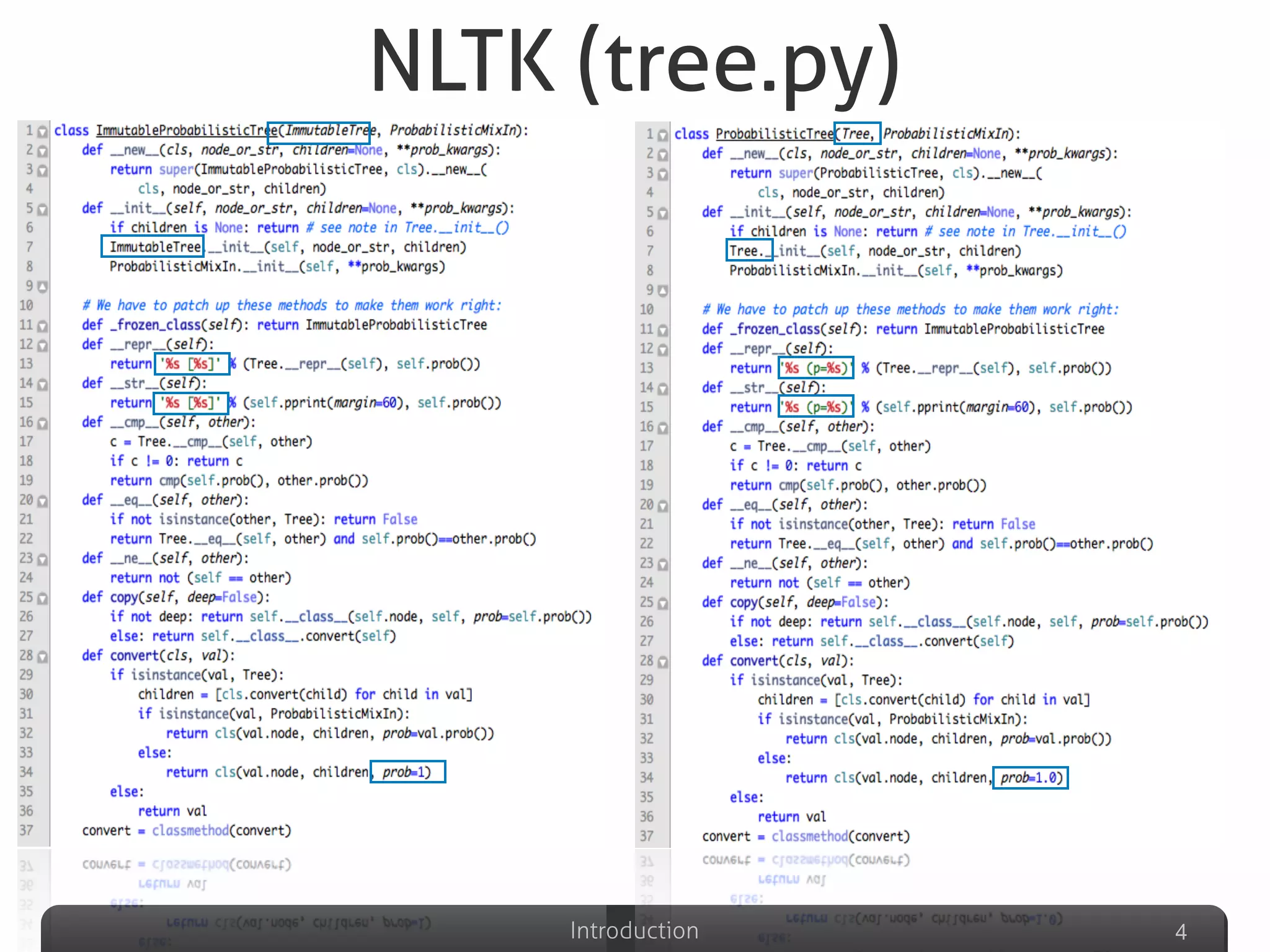









































The document discusses clone detection in Python, identifying duplicated code as a significant issue in software development. It categorizes code clones into four types based on similarity, and outlines various clone detection techniques, including text-based, token-based, syntax-based, and graph-based methods. Additionally, it suggests the use of machine learning to improve clone detection accuracy by analyzing structural and lexical features of code.
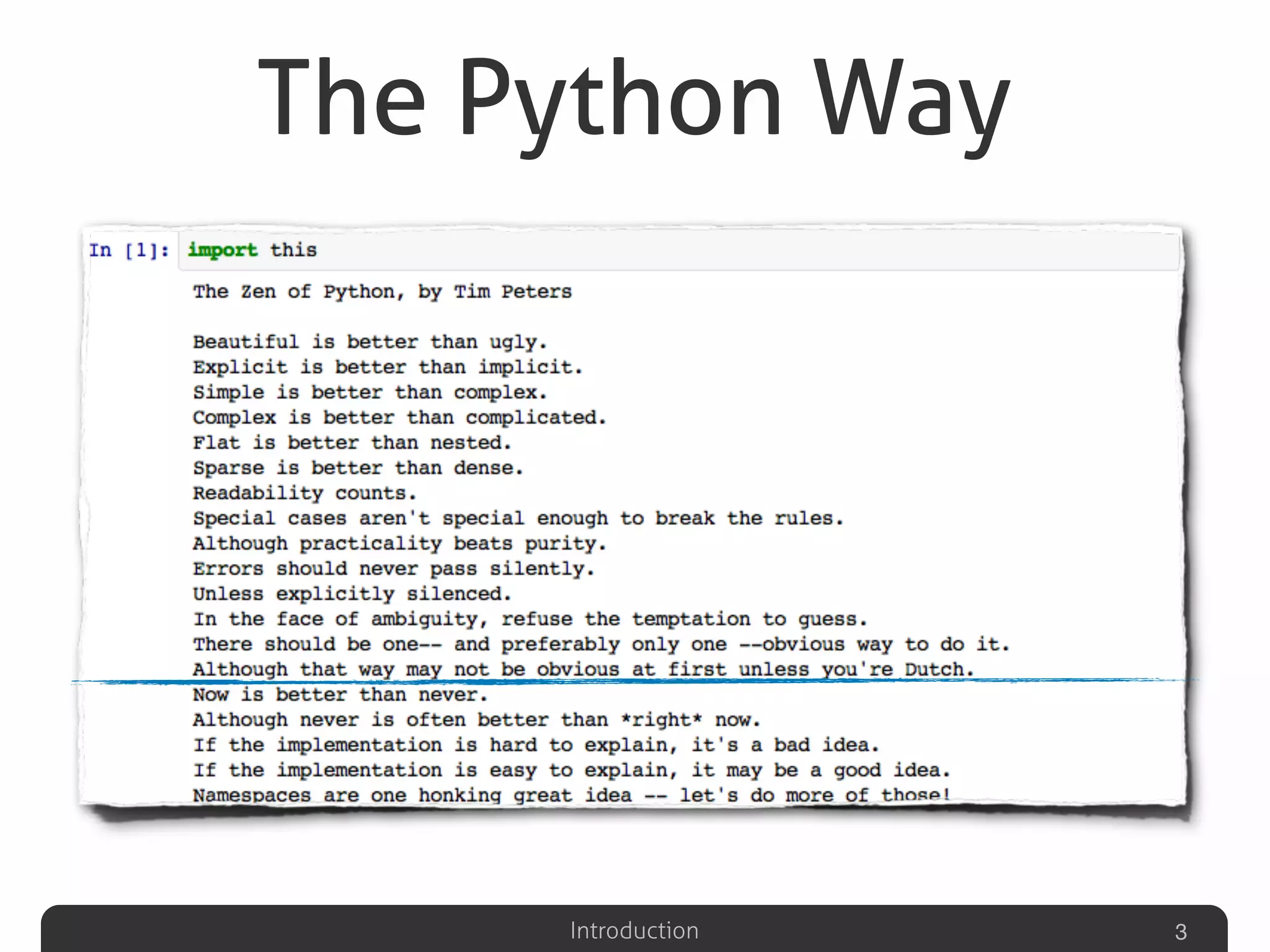
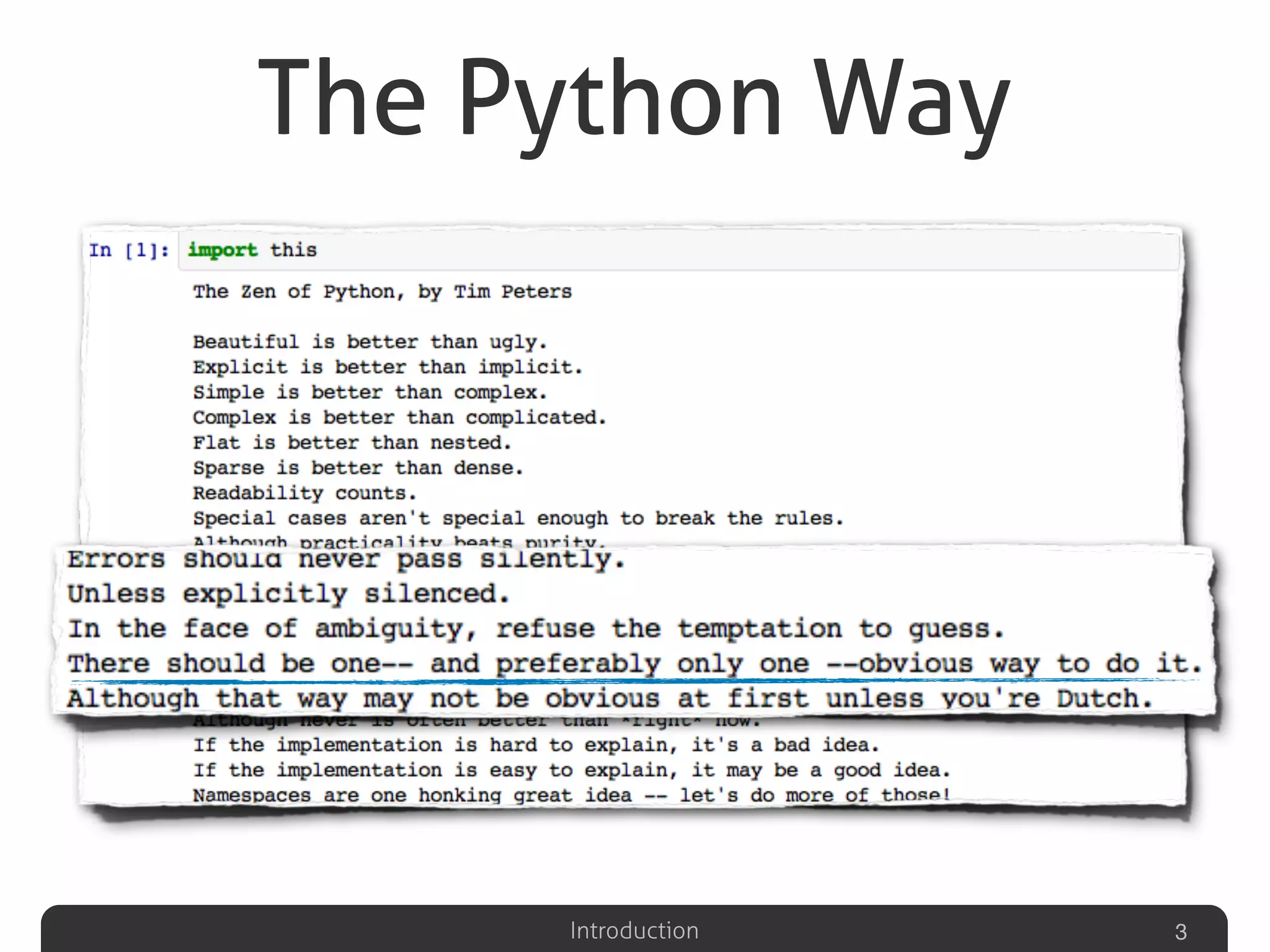
Introduction to clone detection in Python presented by Valerio Maggio during a 2013 seminar.
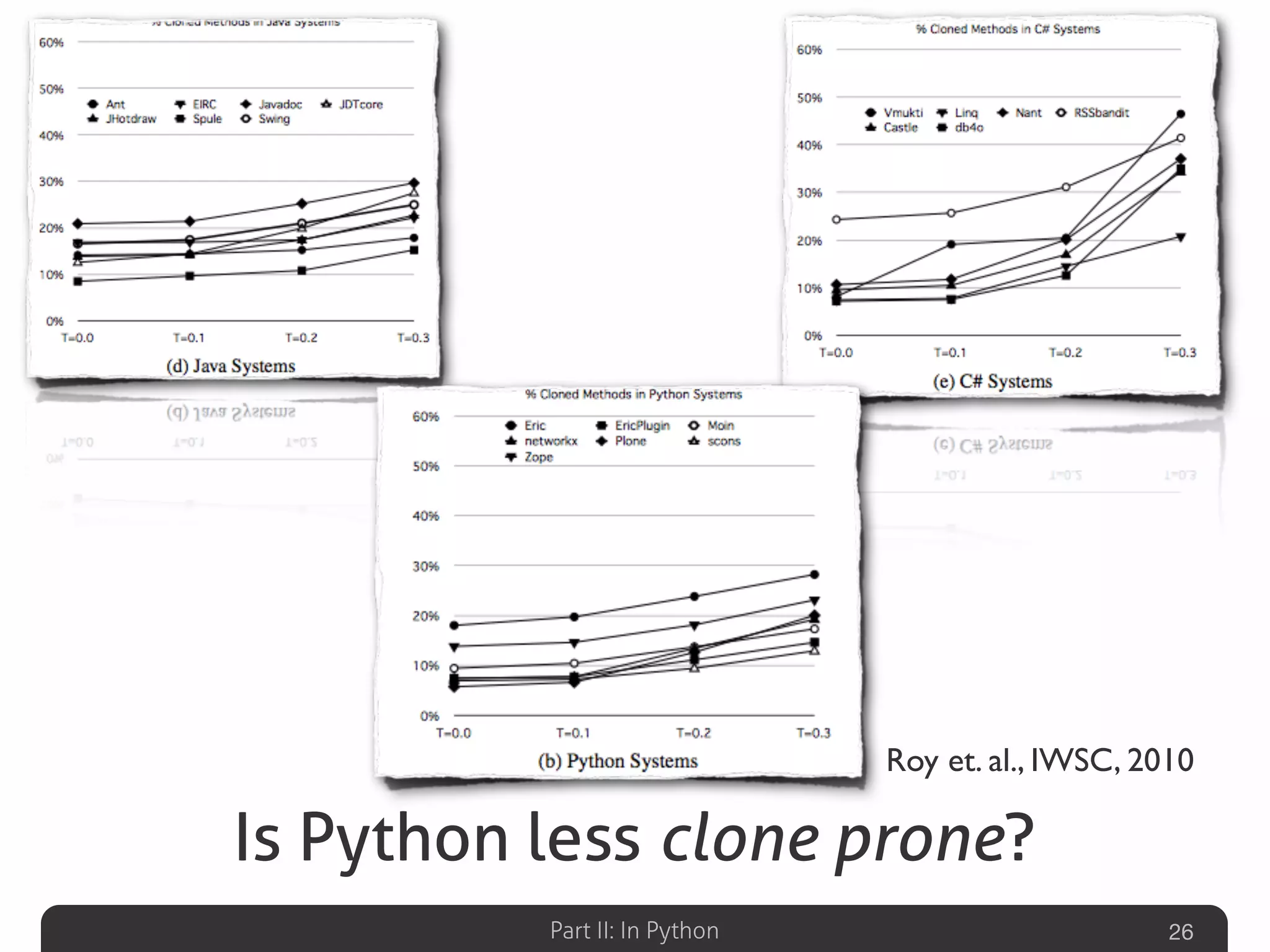
Focuses on the prevalence (5-50%) of duplicated code, its causes, and the need for unification.
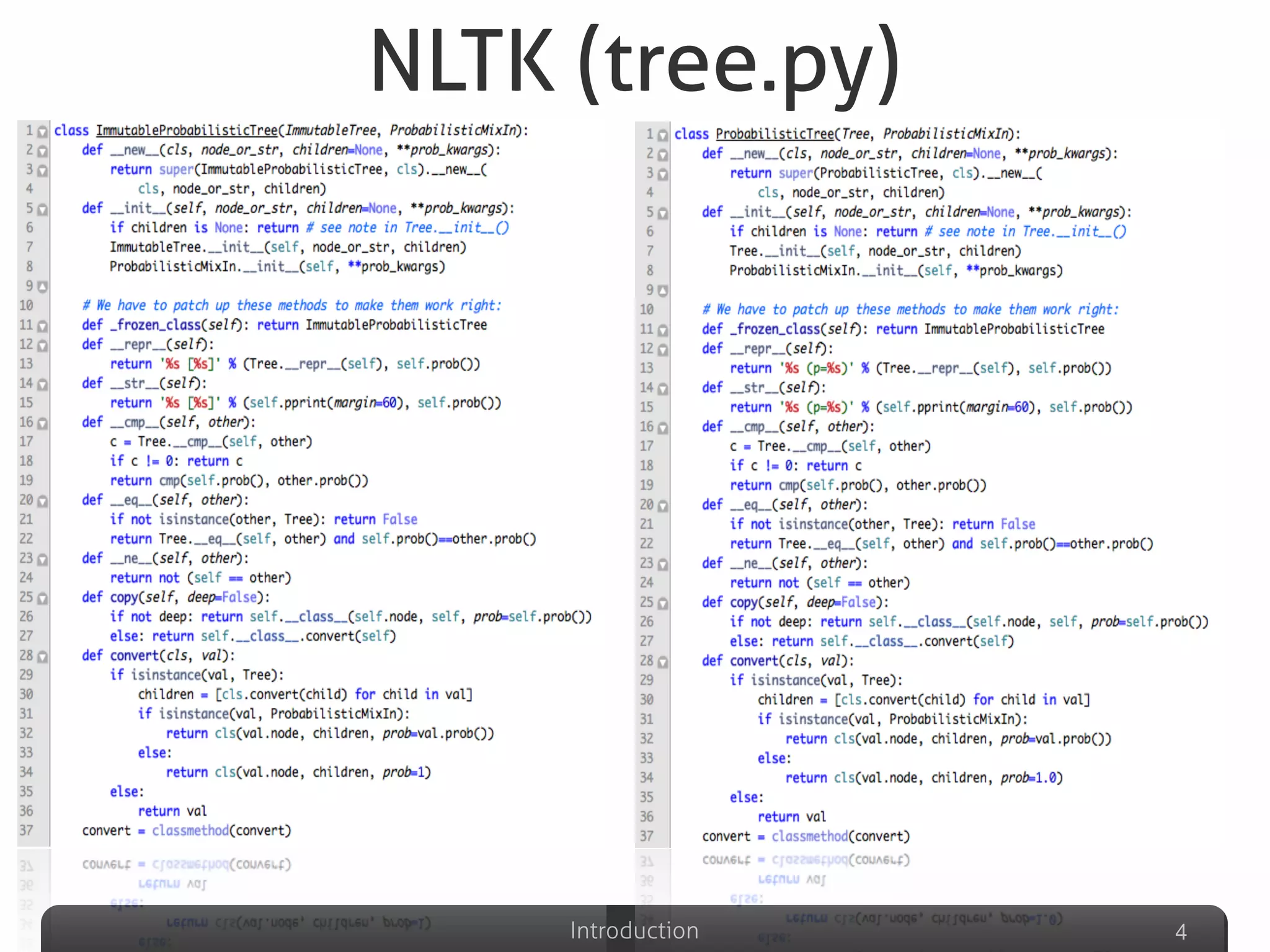
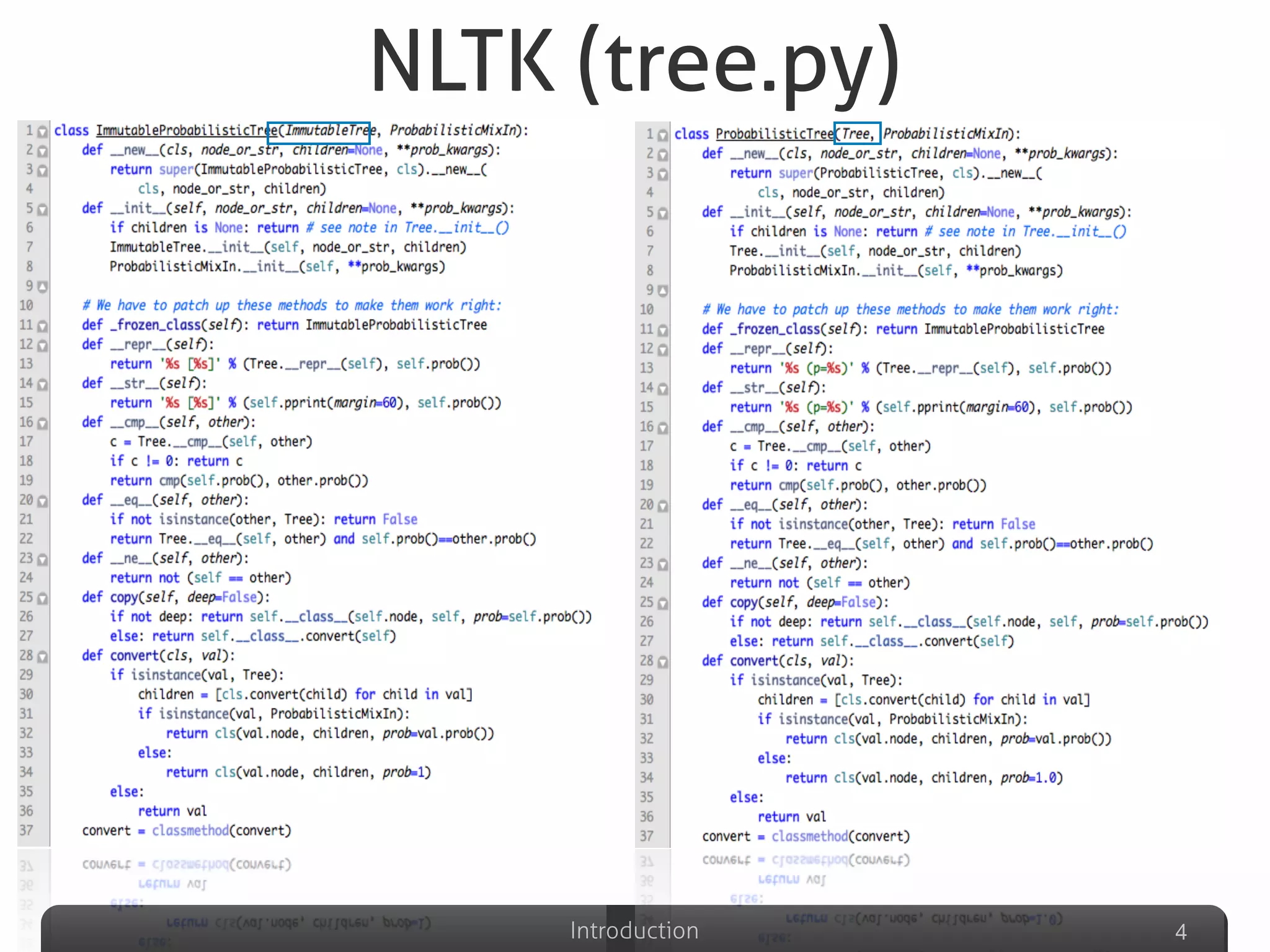
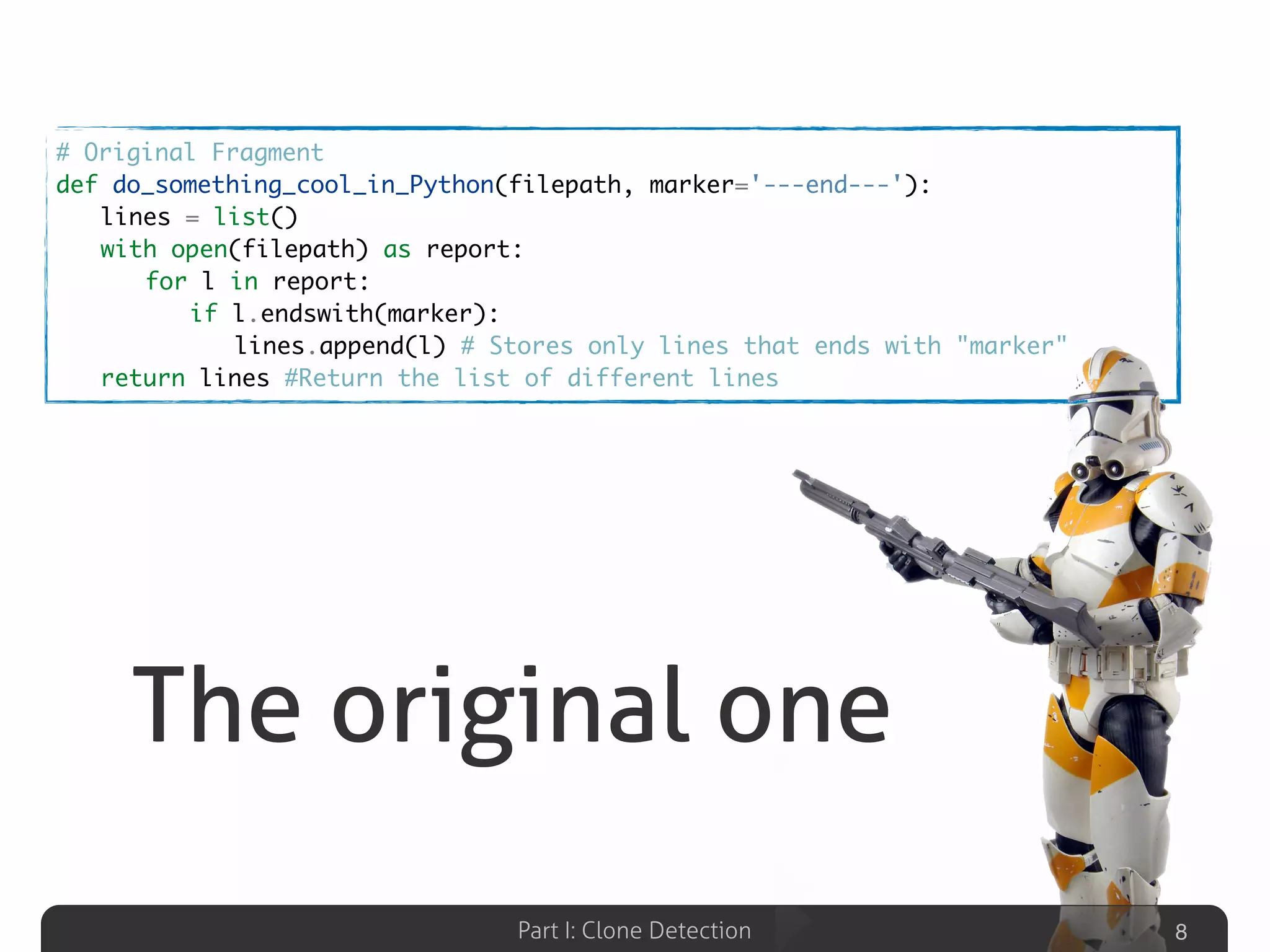
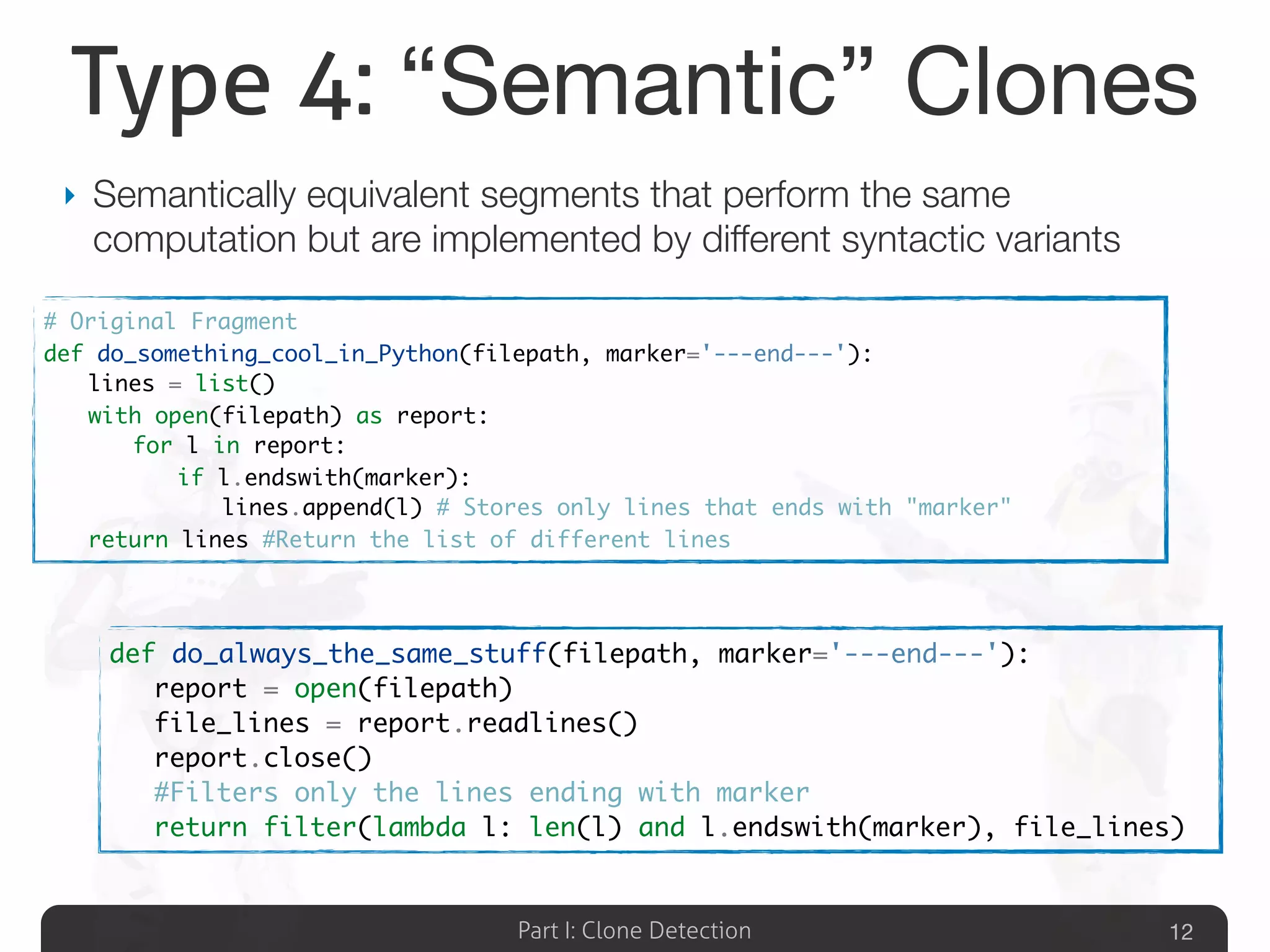
Describes various definitions of software clones, identifying different types including exact copy, parameter substituted, structure substituted, and semantic clones.
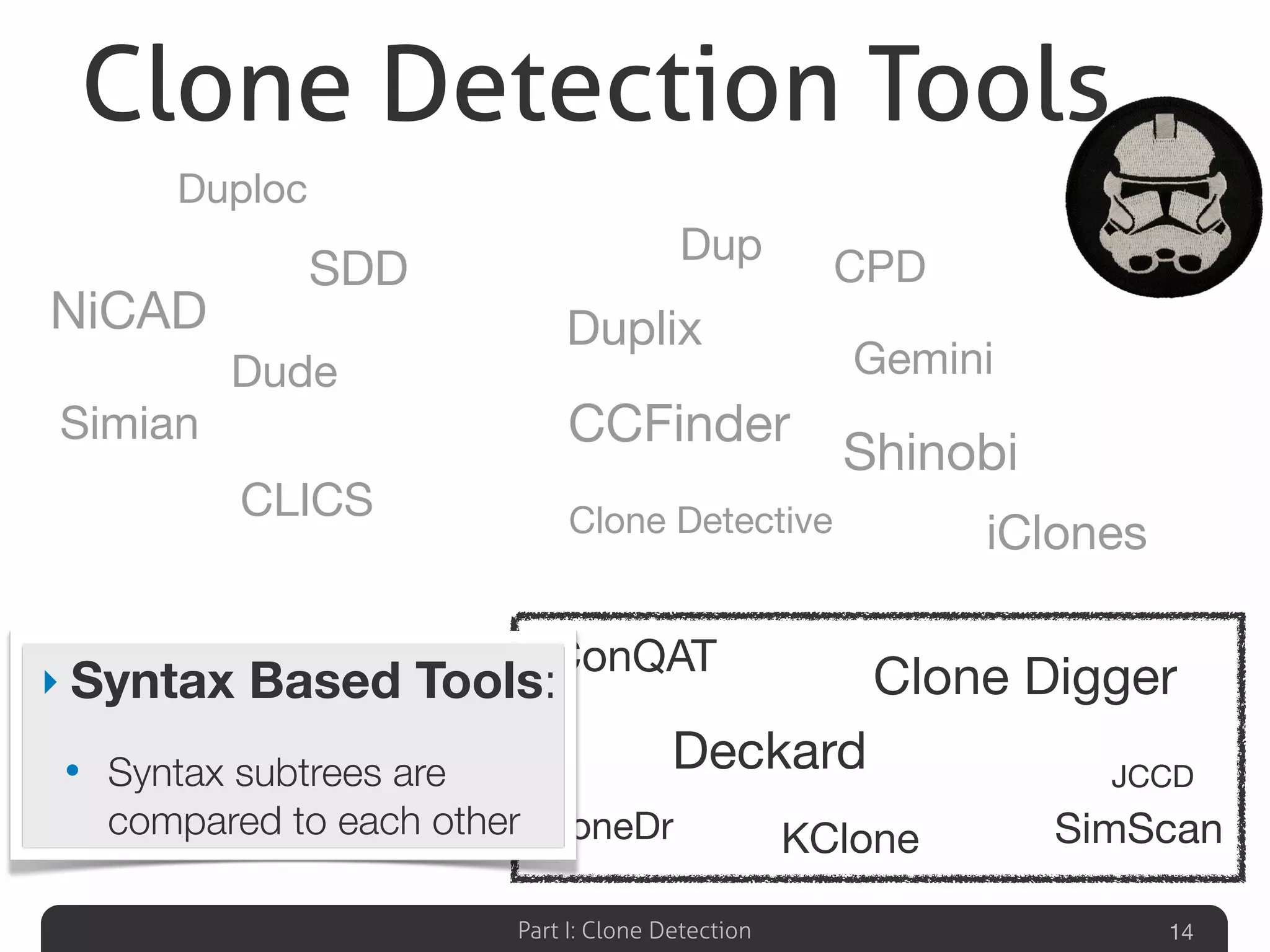
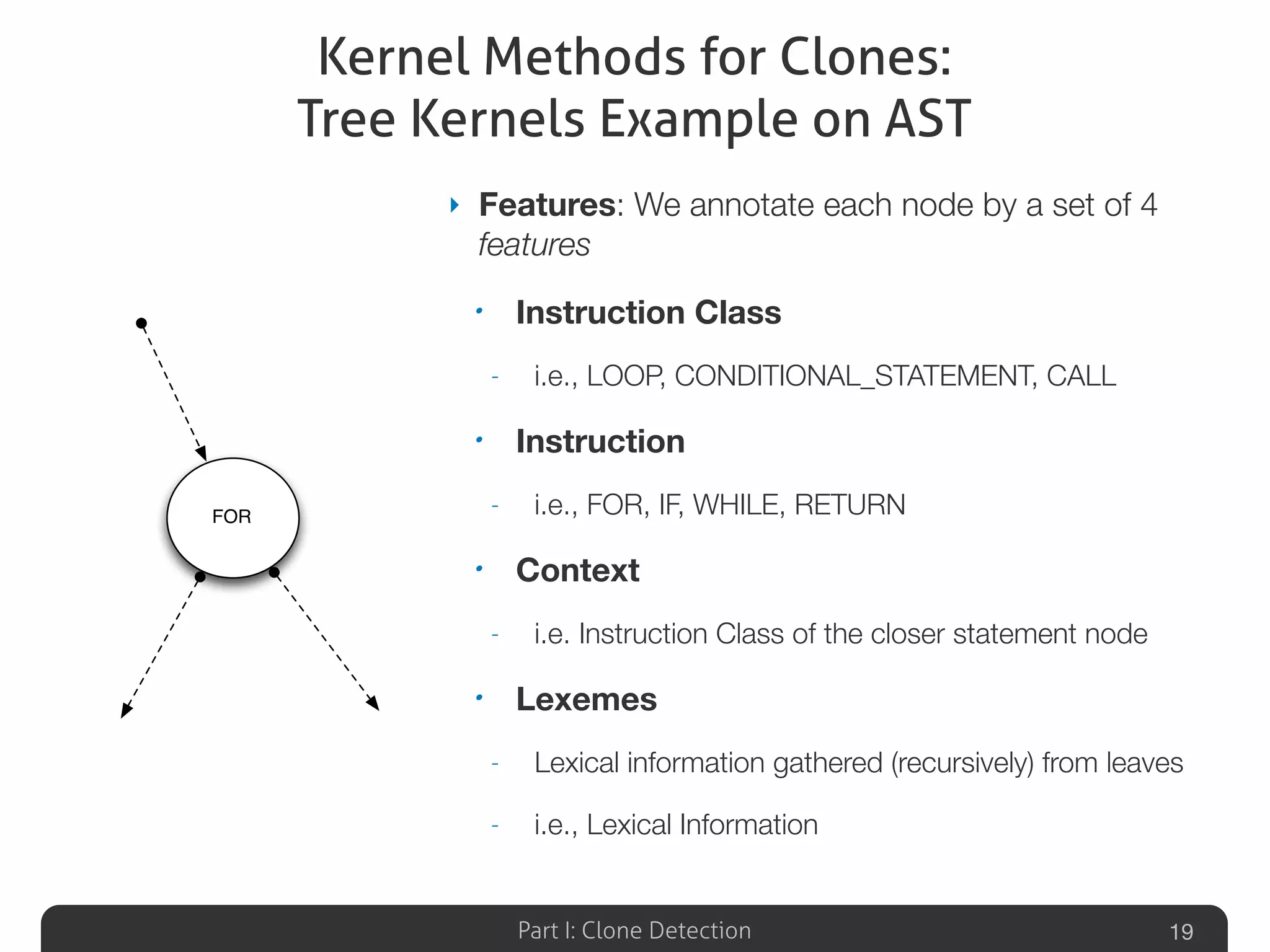
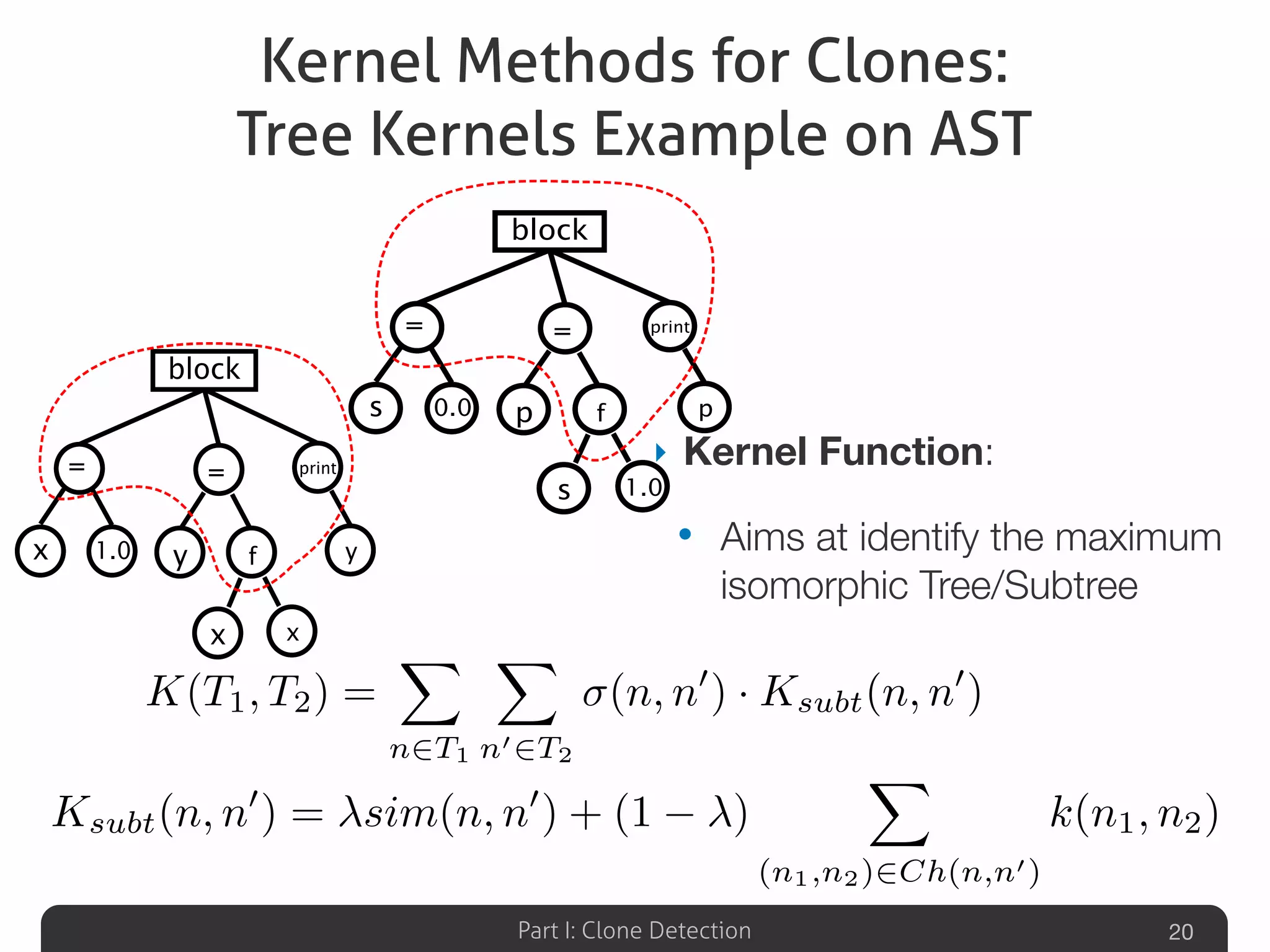
Lists various clone detection tools and discusses evaluating techniques, including token-based, syntax-based, and graph-based methods.Explores the potential of machine learning to identify code clones through structural and contextual analysis.
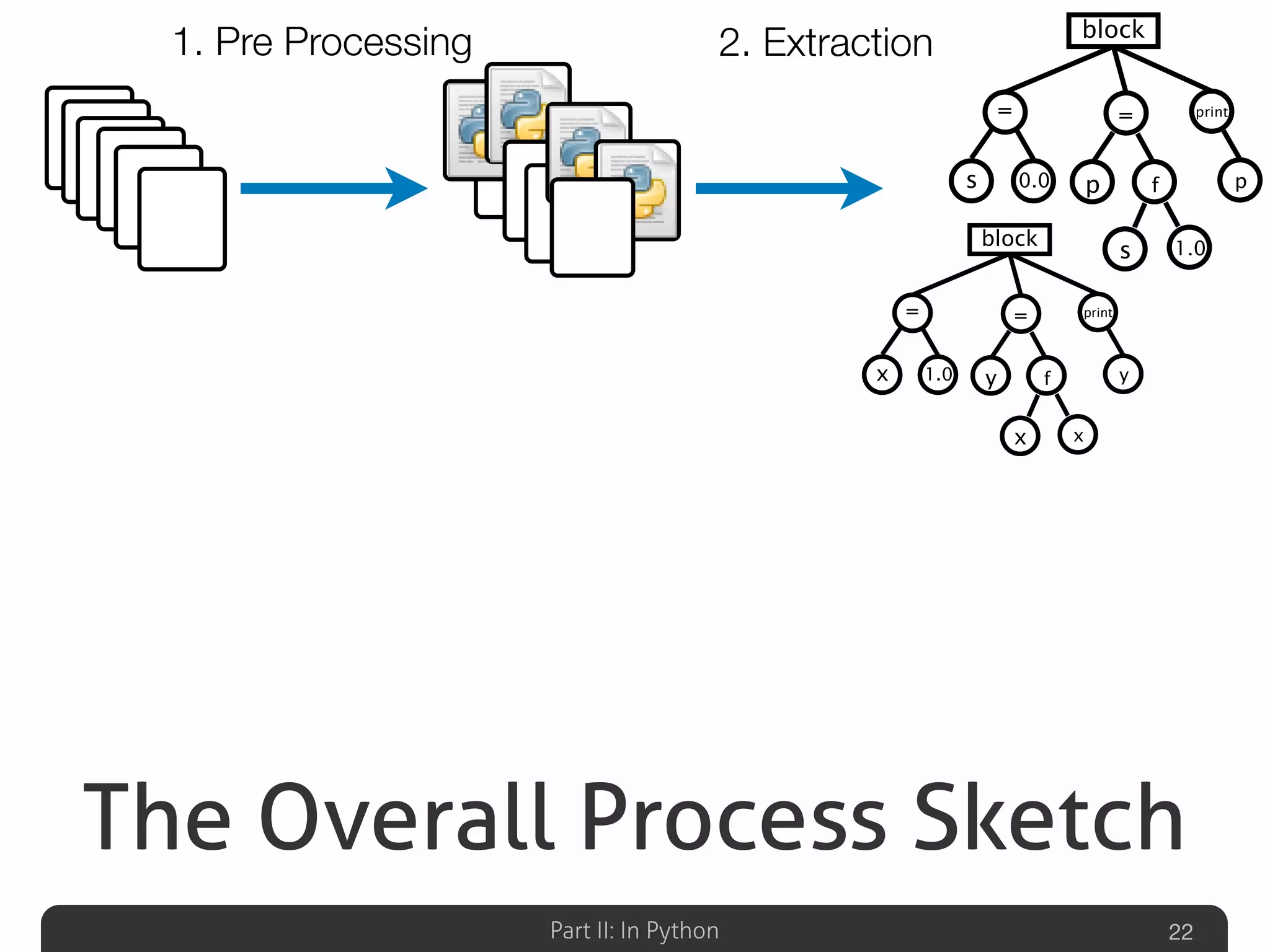
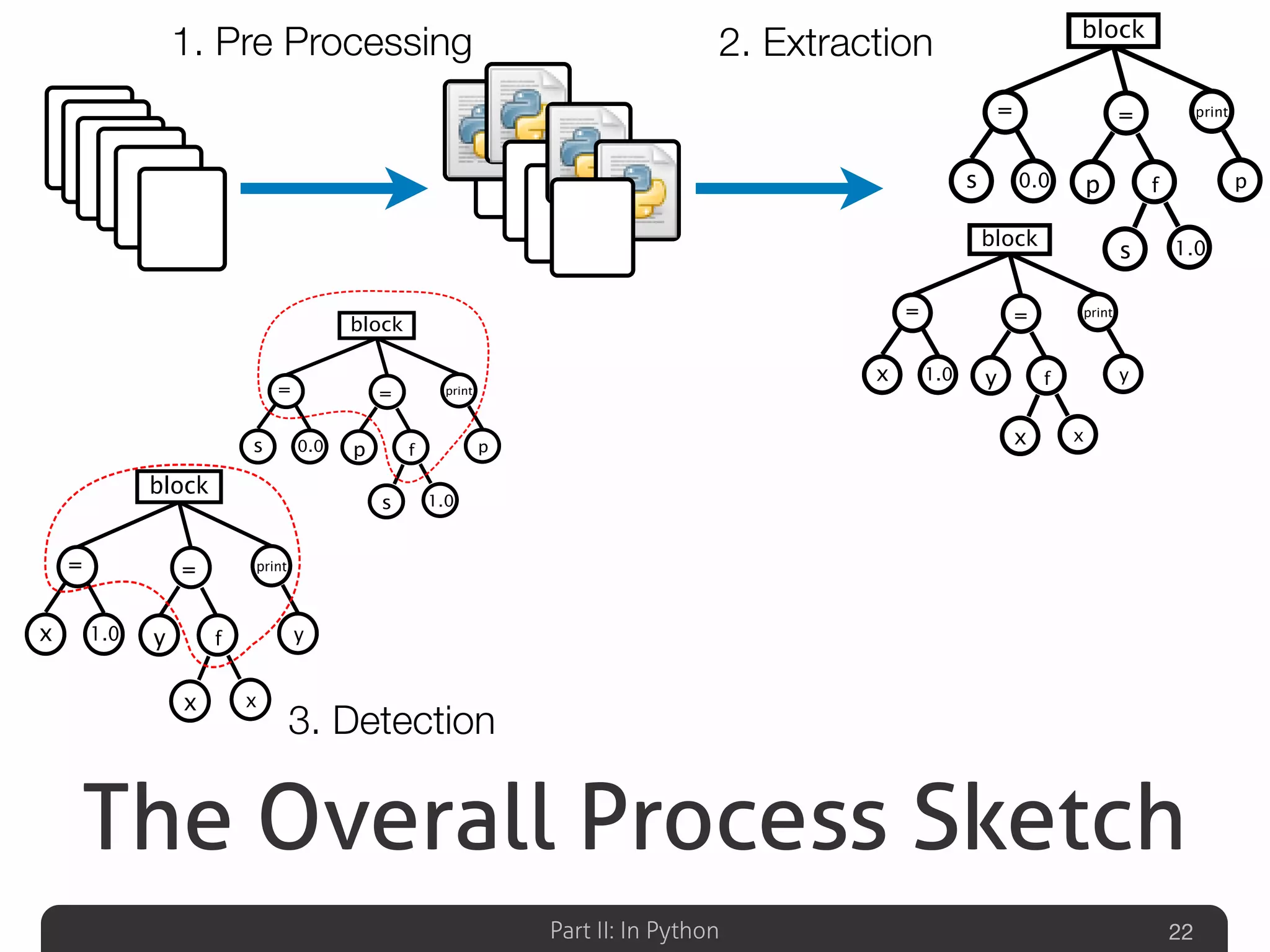
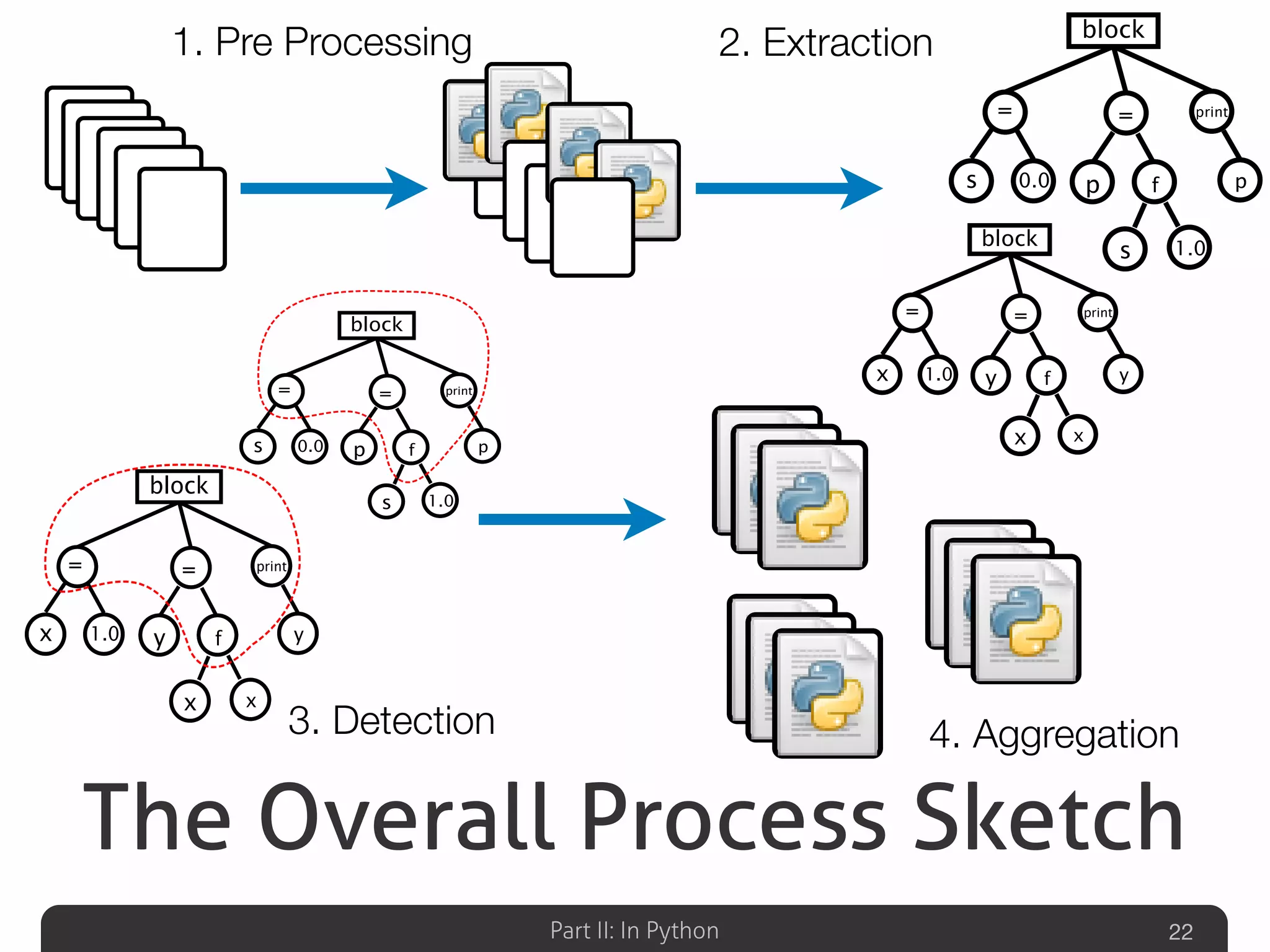
Outlines the overall detection process for clones in Python, including preprocessing, extraction, detection, and aggregation.
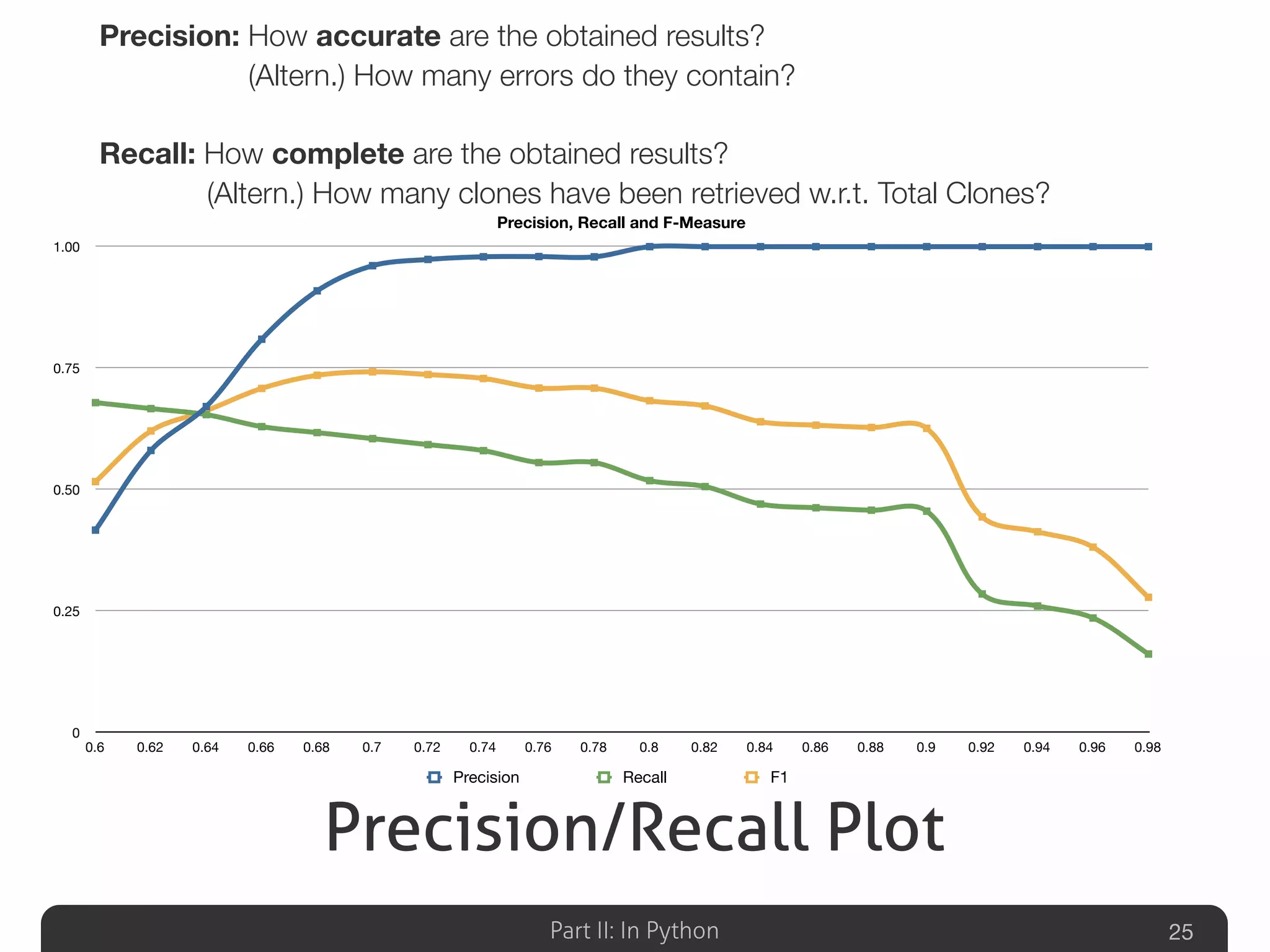
Discusses empirical evaluation of clone detection precision/recall in Python, highlighting comparisons to previous tools in the field.
Thanks audience for participation, concluding the presentation on clone detection in Python.