Download as PDF, PPTX

















![Intro Ian Dewancker. SigOpt for ML: TensorFlow ConvNets on a Budget with Bayesian Optimization. Ian Dewancker. SigOpt for ML: Unsupervised Learning with Even Less Supervision Using Bayesian Optimization. Ian Dewancker. SigOpt for ML : Bayesian Optimization for Collaborative Filtering with MLlib. #1 Trusting the Defaults Keras recurrent layers documentation #2 Using the Wrong Metric Ron Kohavi et al. Trustworthy Online Controlled Experiments: Five Puzzling Outcomes Explained. Xavier Amatriain. 10 Lessons Learning from building ML systems [Video at 19:03]. Image from PhD Comics. See also: SigOpt in Depth: Intro to Multicriteria Optimization. #4 Too Few Hyperparameters Image from TensorFlow Playground. Ian Dewancker. SigOpt for ML: Unsupervised Learning with Even Less Supervision Using Bayesian Optimization. #5 Hand Tuning On algorithms beating experts: Scott Clark, Ian Dewancker, and Sathish Nagappan. Deep Neural Network Optimization with SigOpt and Nervana Cloud. #6 Grid Search NoGridSearch.com References - by Section](https://image.slidesharecdn.com/commonproblemsinhyperparameteroptimization21-170324153628/75/Common-Problems-in-Hyperparameter-Optimization-30-2048.jpg)


This document discusses common problems that can occur in hyperparameter optimization including trusting default values too much, using the wrong evaluation metric, overfitting hyperparameters to validation data, optimizing too few hyperparameters, relying too heavily on manual tuning, using grid search which scales poorly, using random search which has high variance, and provides recommendations such as using Bayesian optimization which can efficiently search large hyperparameter spaces and intelligently determine the most promising configurations to evaluate next.
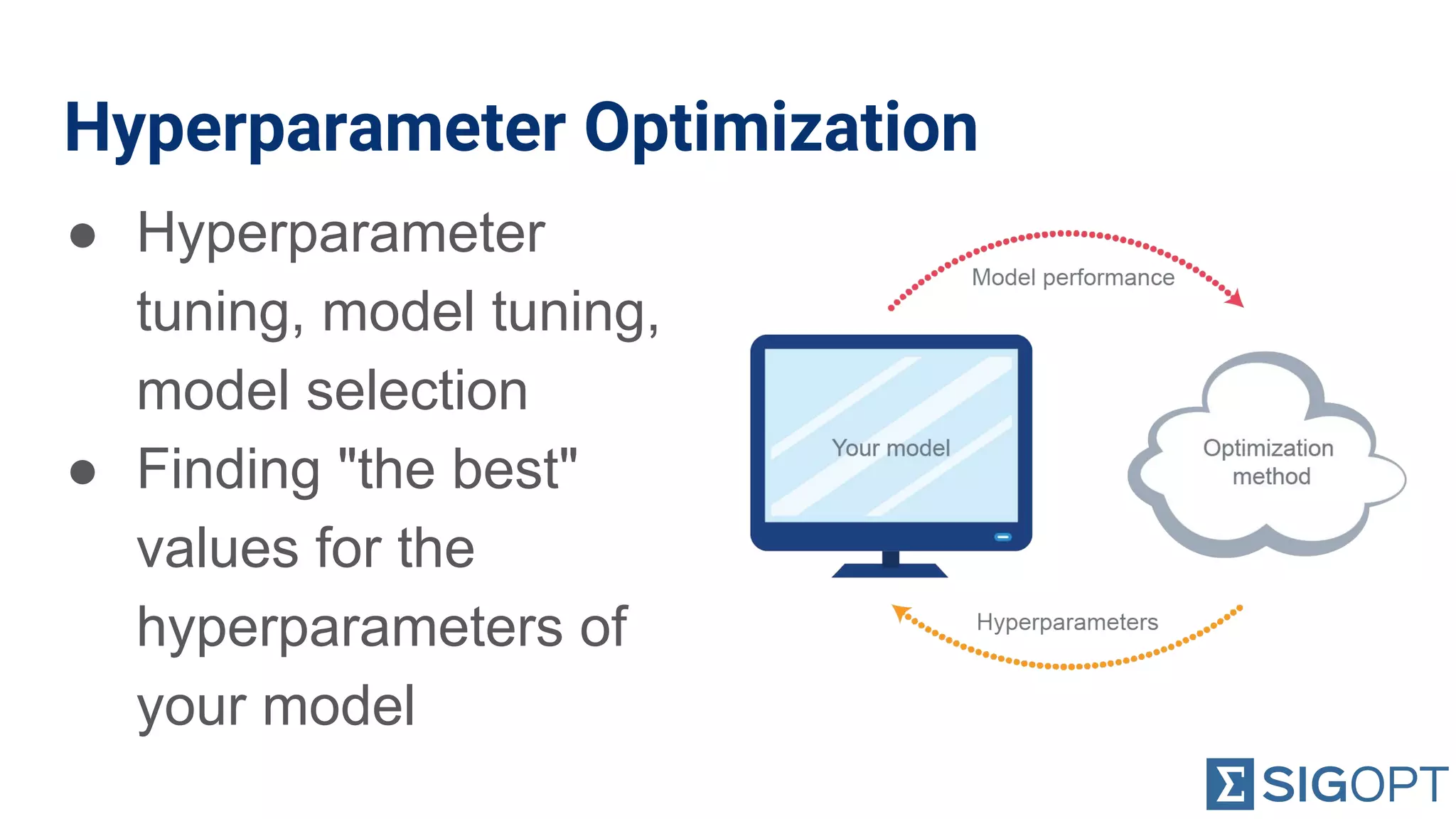
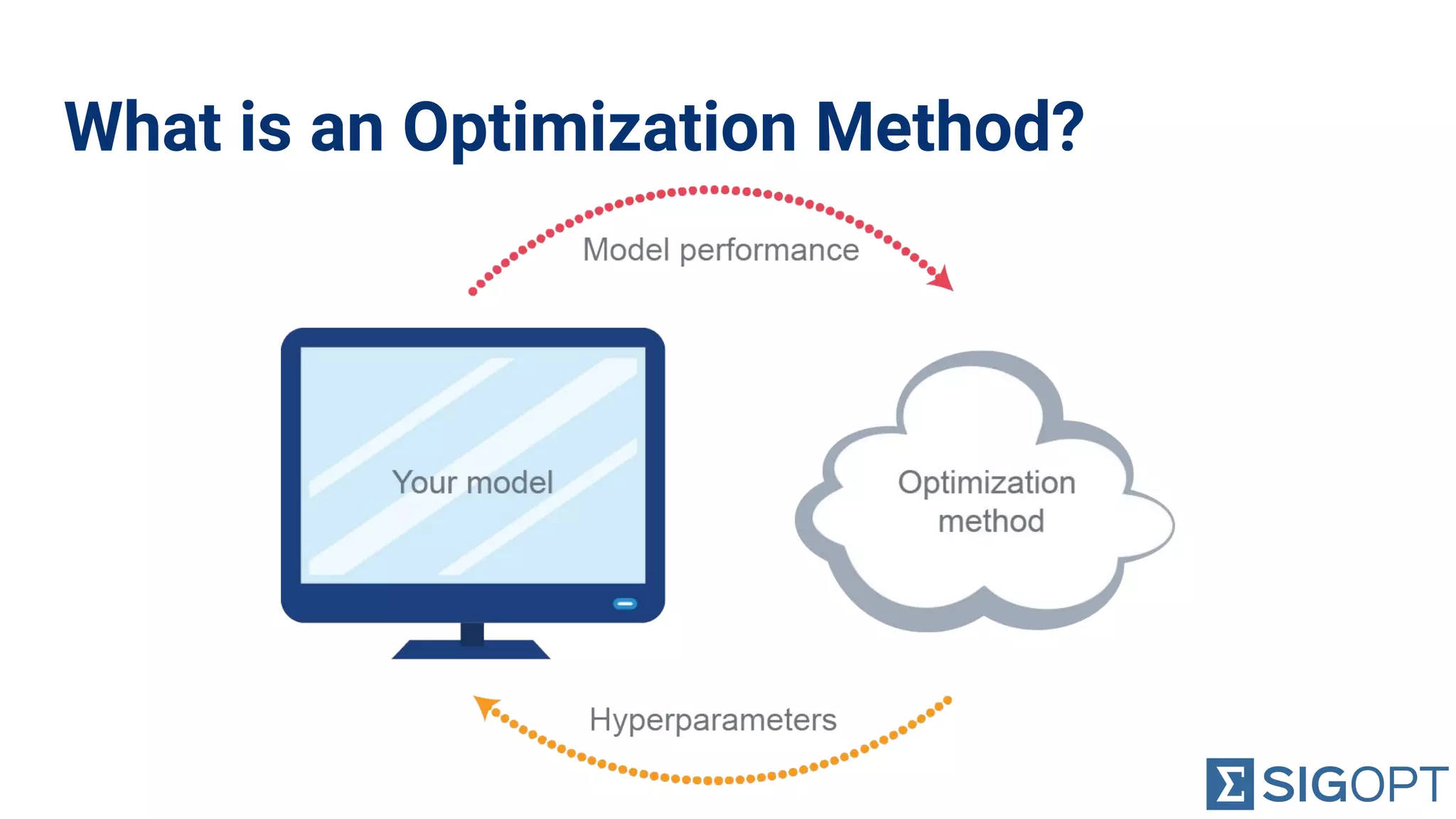
Introduction to hyperparameters and their tuning for model selection, aiming for optimal values.
Showcases significant accuracy improvements across different machine learning models with specified percentages.
Highlights the problem of depending on default hyperparameter values which may not suit all models.
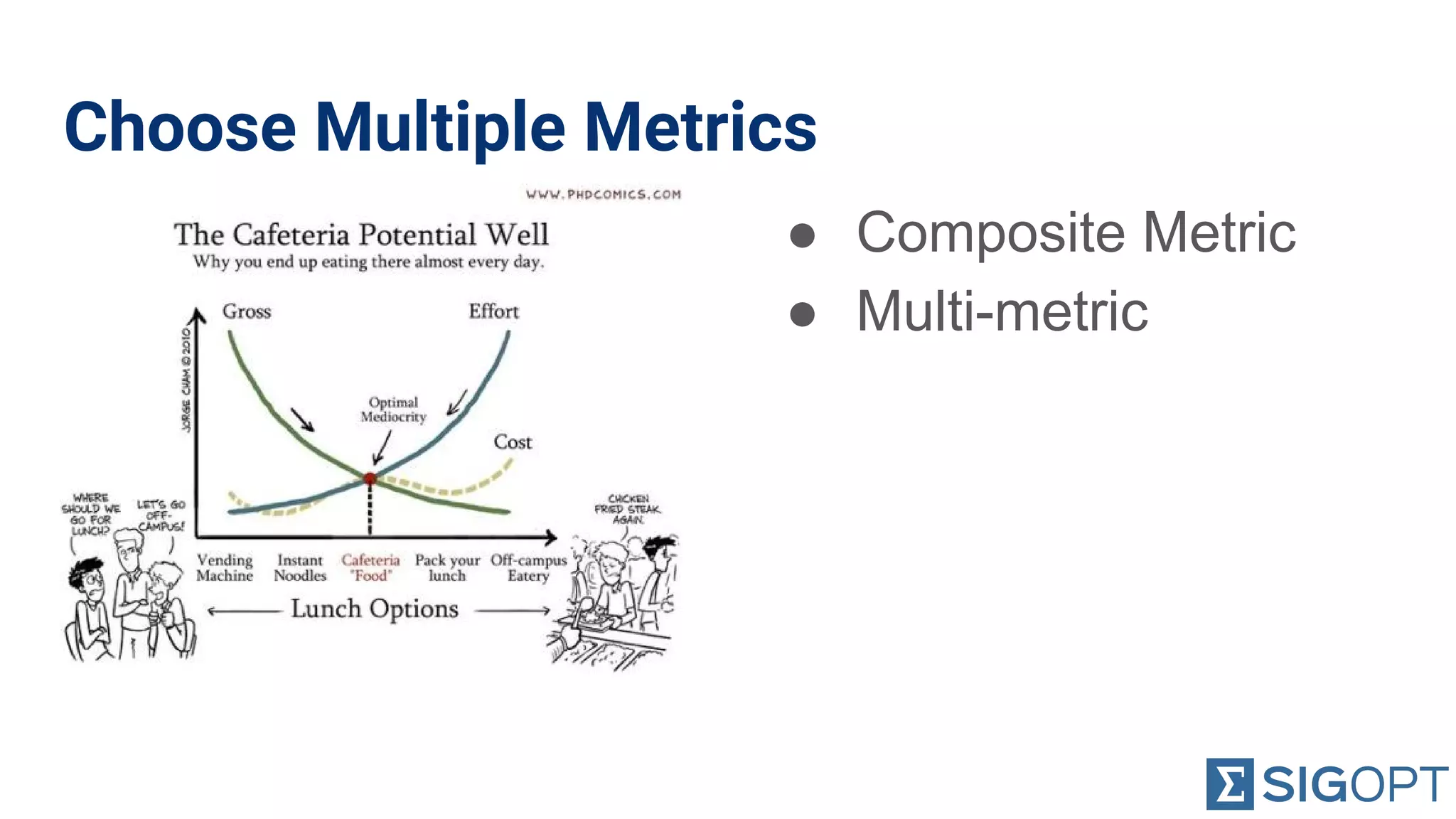
Emphasizes the importance of selecting appropriate metrics to balance goals and avoid biases.
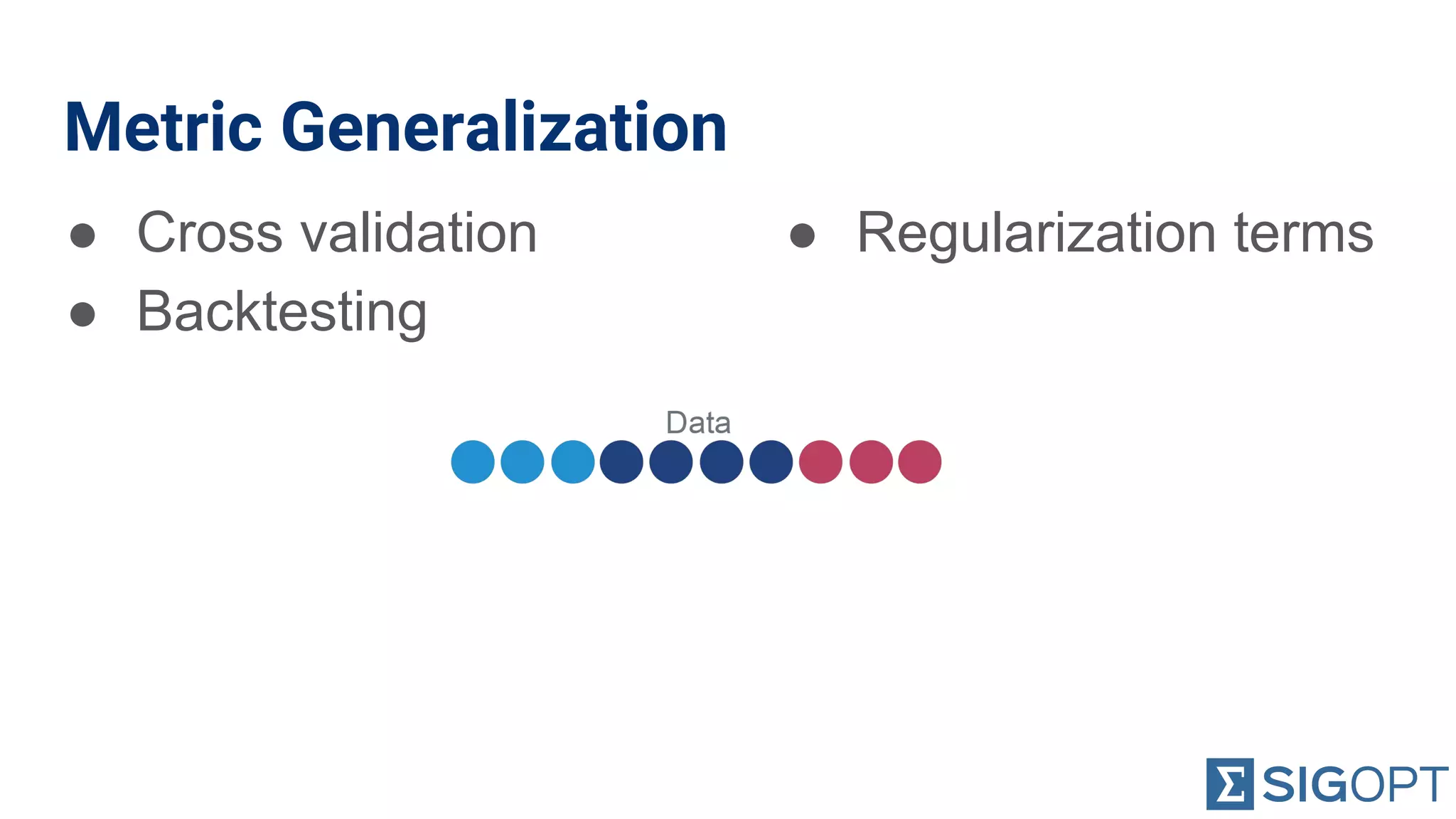
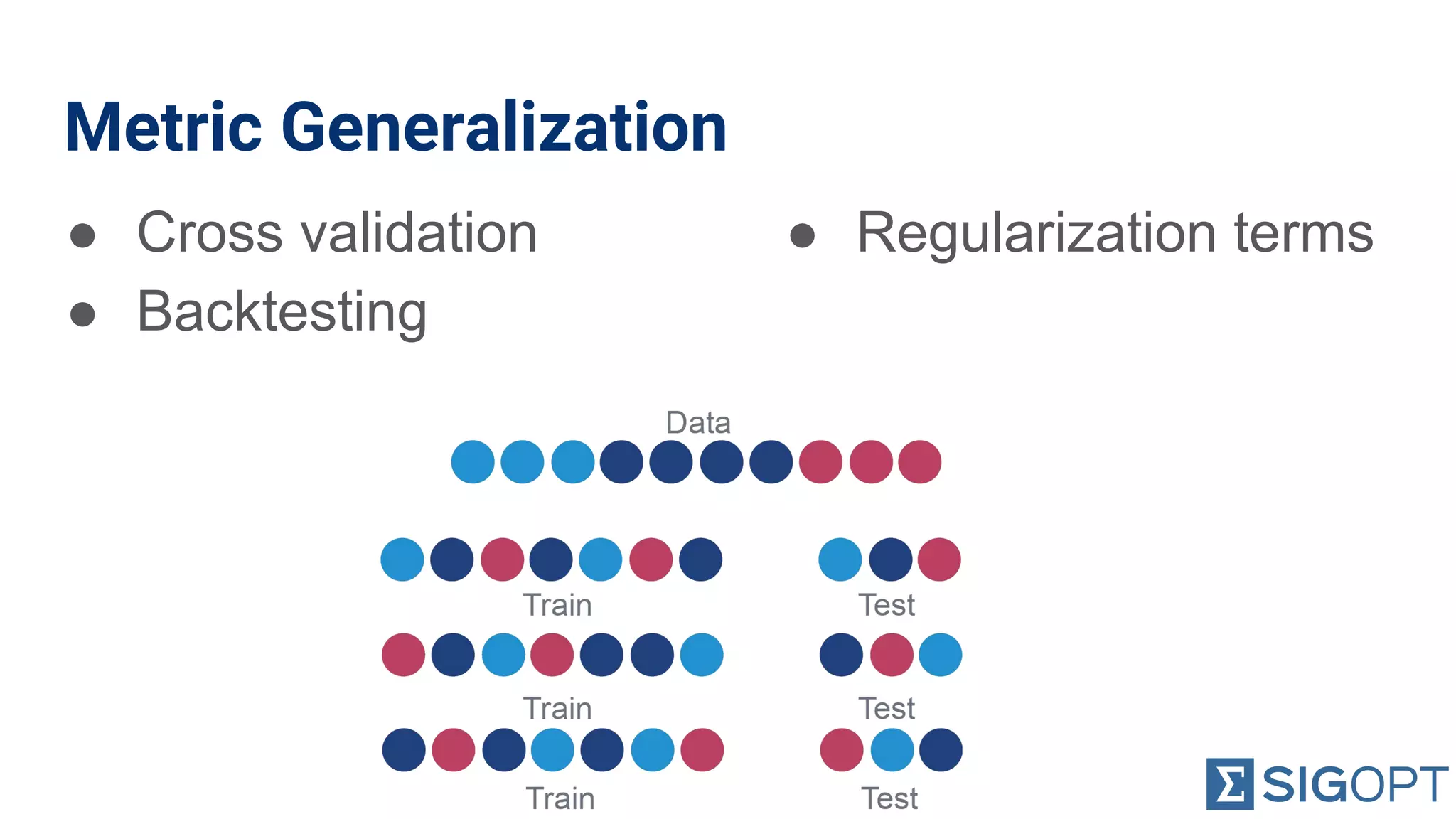
Discusses the risks of overfitting and methods for metric generalization like cross-validation.
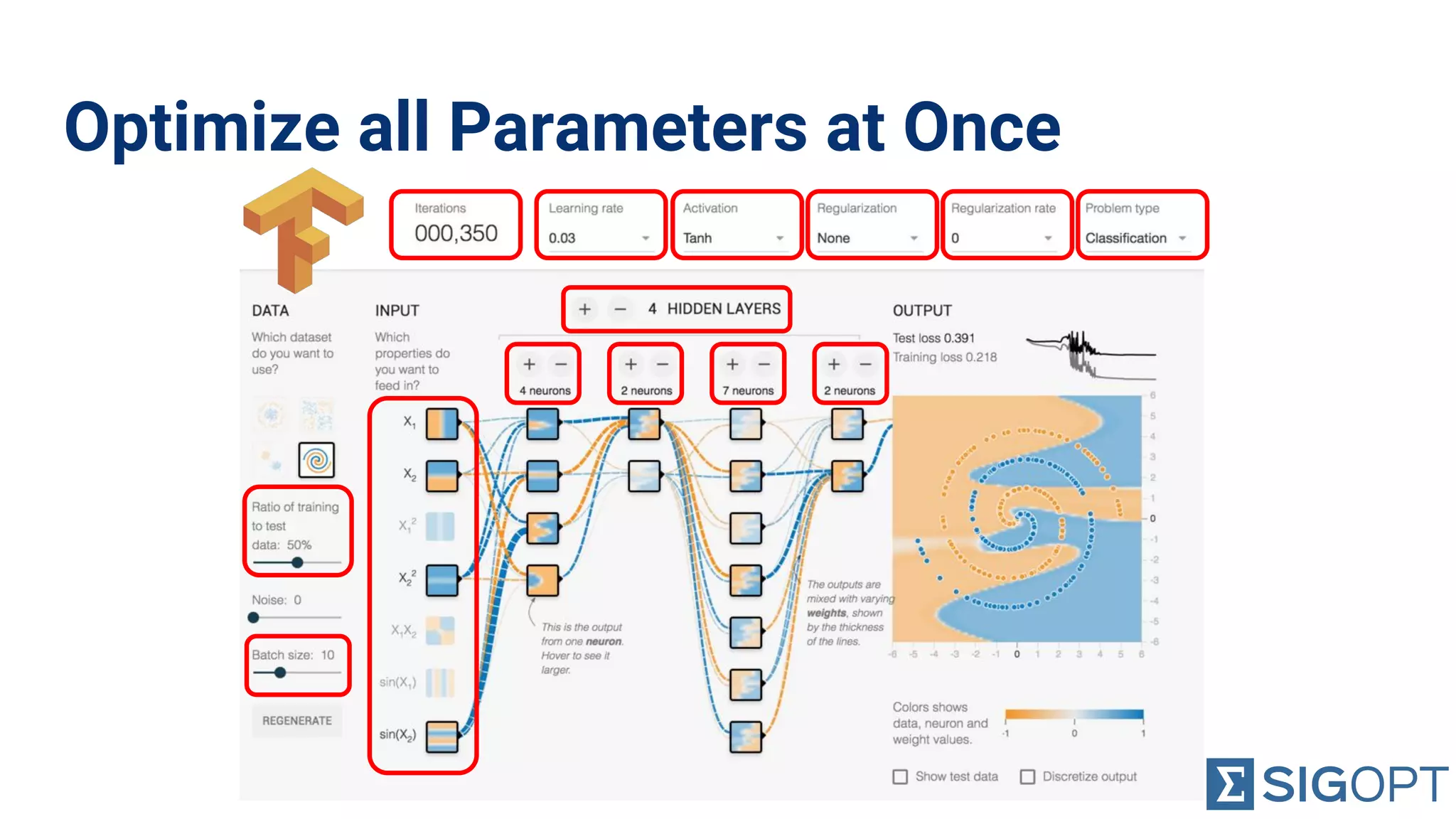
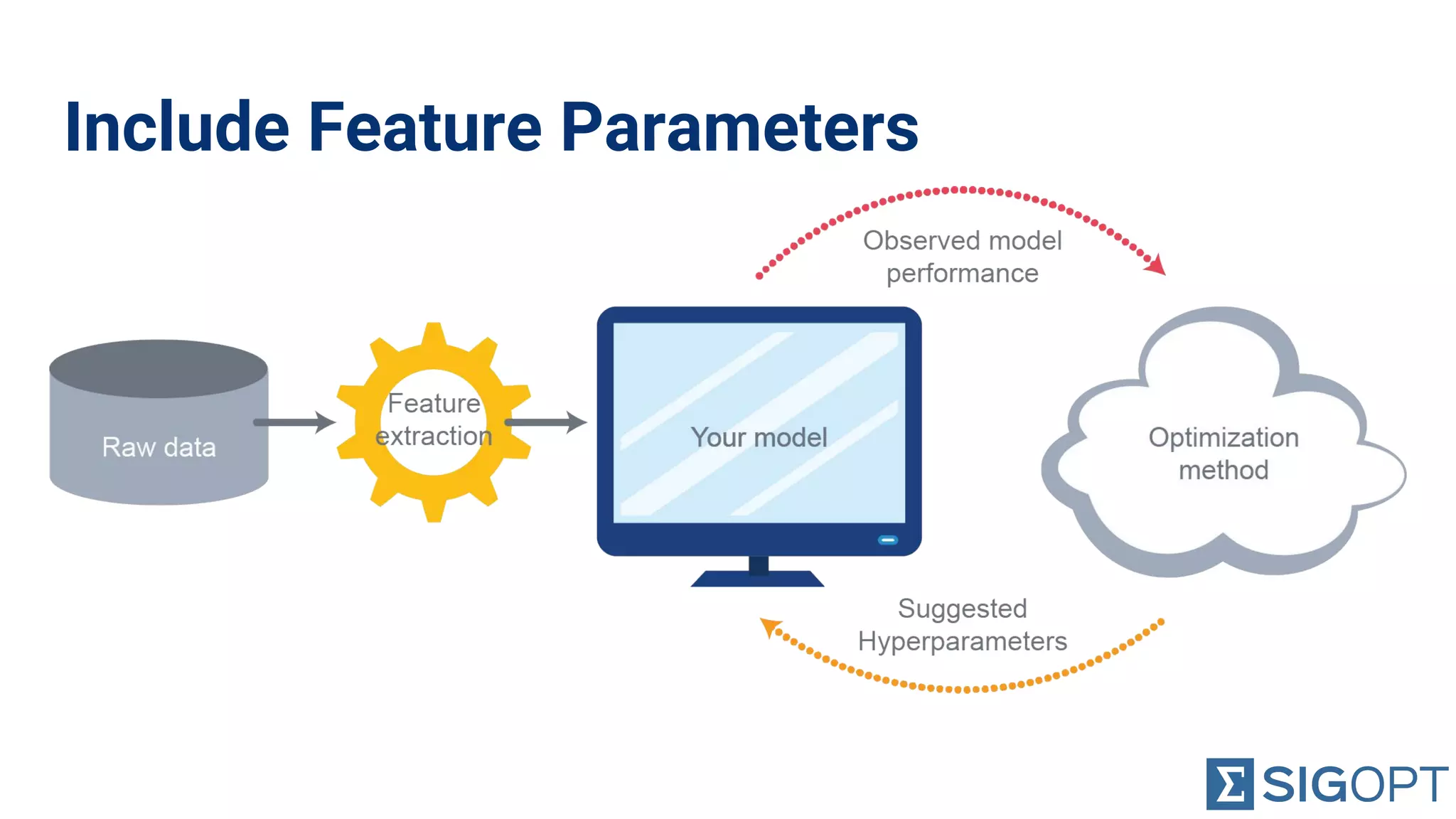
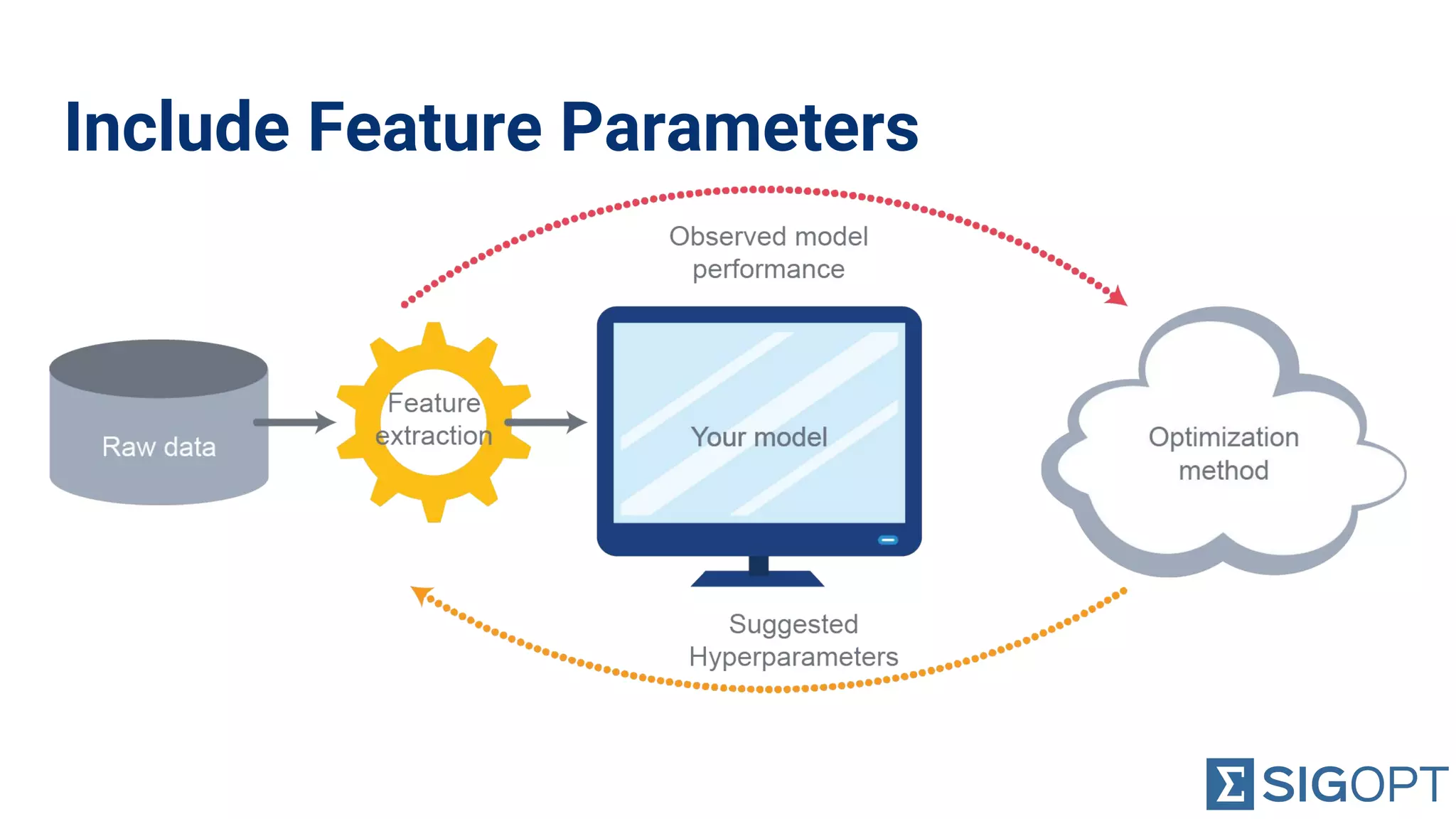
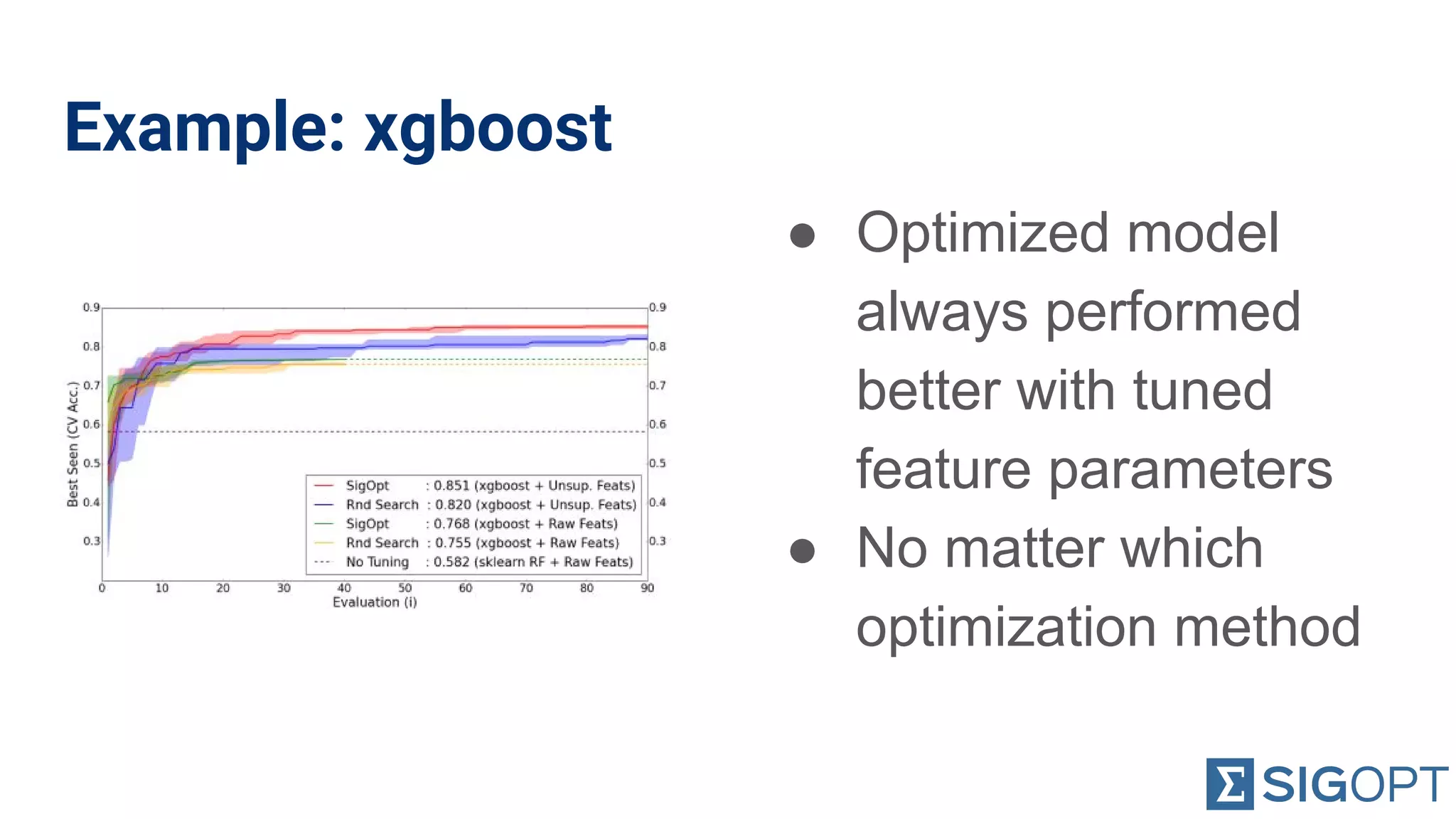
Importance of not neglecting hyperparameters and feature parameters during optimization for better results.
Critiques manual tuning and advocates for using algorithms for optimization to save time and cost.
Descriptions of grid search limitations through examples of model evaluations across hyperparameters.
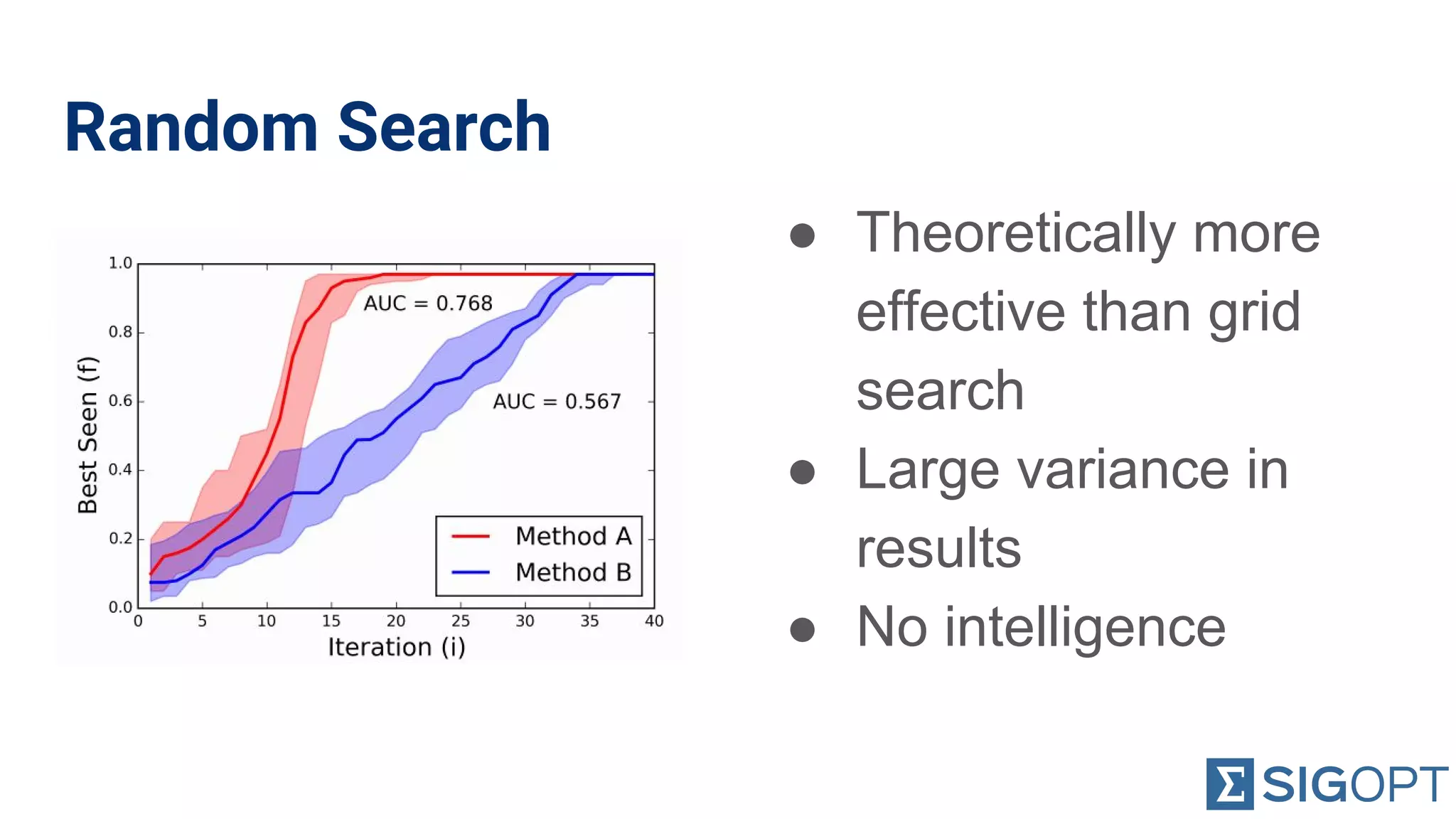
Examines random search effectiveness, its variances, and the lack of intelligence in the method.
Introduces advanced methods for optimization, mentioning genetic algorithms and Bayesian optimization.
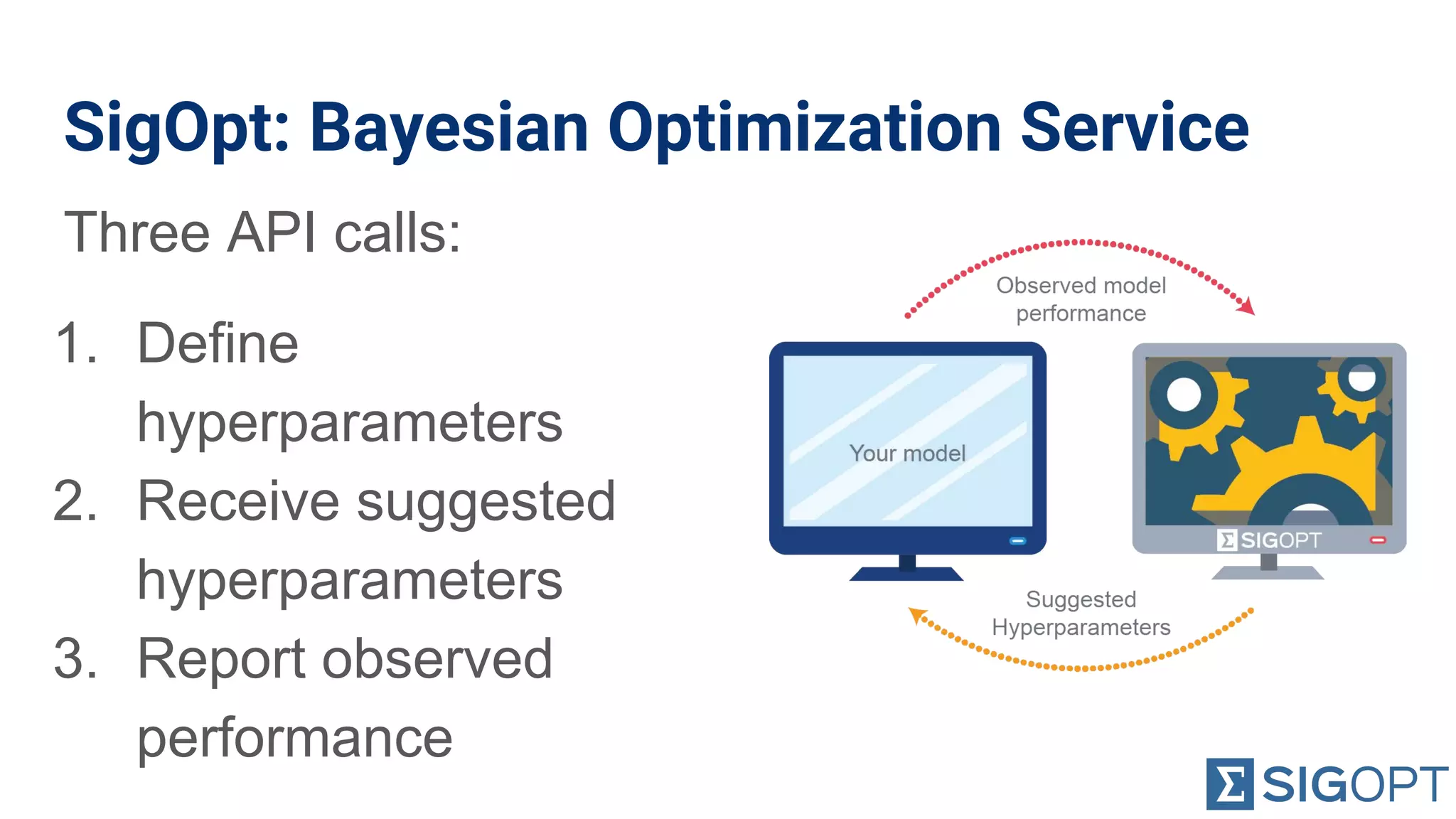
Overview of using SigOpt's Bayesian optimization service for defining and reporting hyperparameters.
Wraps up the presentation with acknowledgments and references to further reading related to the discussed topics.