Downloaded 319 times









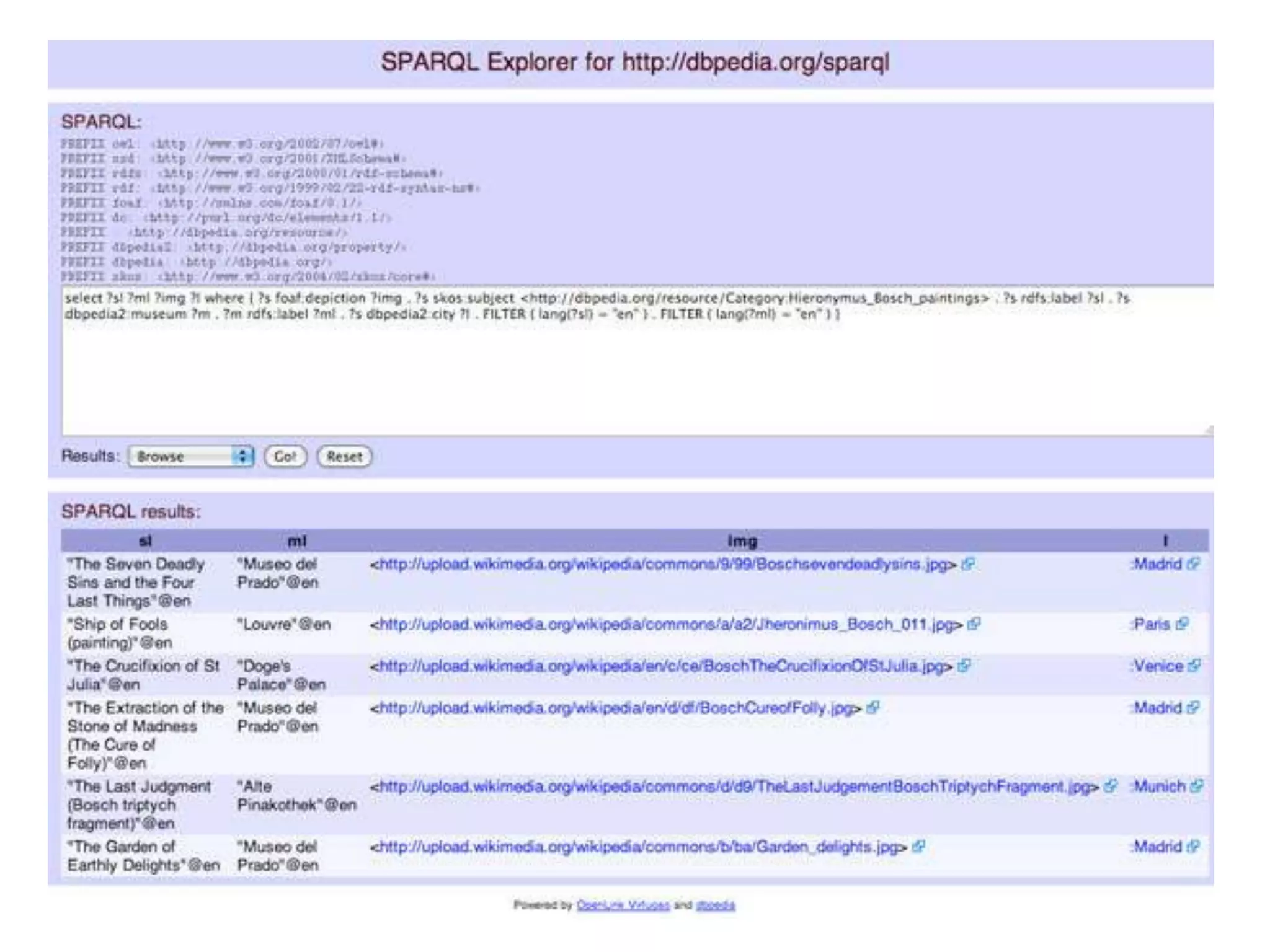

![SPARQL QueryPREFIX fb: http://rdf.freebase.com/ns/PREFIX dbpedia: http://dbpedia.org/resource/PREFIX dbp-prop: http://dbpedia.org/property/PREFIX dbp-ont: http://dbpedia.org/ontology/PREFIX umbel-sc: http://umbel.org/umbel/sc/PREFIX rdf: http://www.w3.org/1999/02/22-rdf-syntax-ns#PREFIX ot: http://www.ontotext.com/SELECT DISTINCT ?painting_l ?owner_l ?city_fb_con ?city_db_loc ?city_db_citWHERE { ?pfb:visual_art.artwork.artistdbpedia:Amedeo_Modigliani ; fb:visual_art.artwork.owners [ fb:visual_art.artwork_owner_relationship.owner ?ow ] ; ot:preferredLabel ?painting_l. ?owot:preferredLabel ?owner_l . OPTIONAL { ?owfb:location.location.containedby [ ot:preferredLabel ?city_fb_con ] } . OPTIONAL { ?owdbp-prop:location ?loc. ?loc rdf:type umbel-sc:City ; ot:preferredLabel ?city_db_loc } OPTIONAL { ?owdbp-ont:city [ ot:preferredLabel ?city_db_cit ] }}](https://image.slidesharecdn.com/consuminglinkeddata-semtech2010-100624124026-phpapp01/75/Consuming-Linked-Data-SemTech2010-20-2048.jpg)
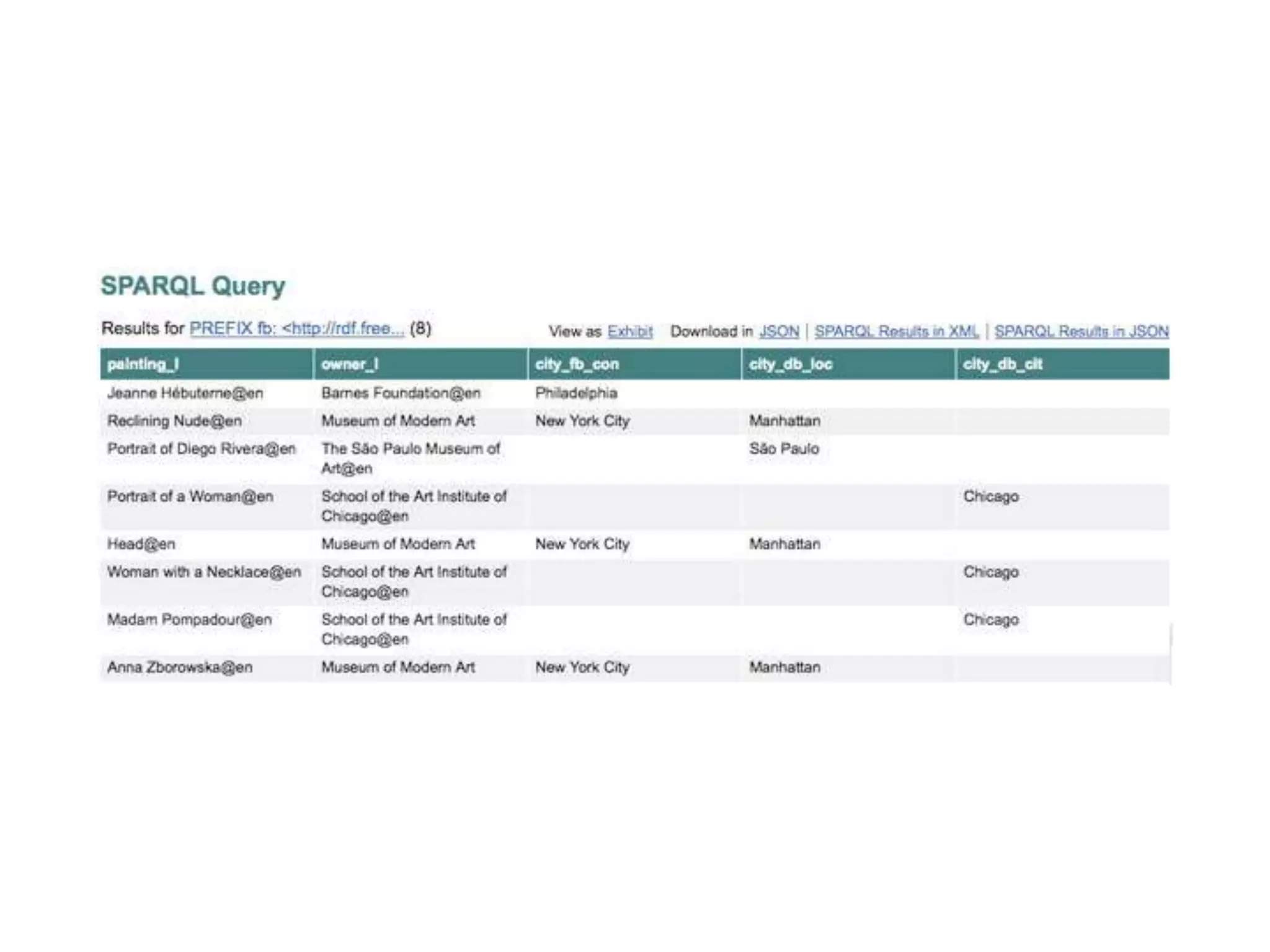





























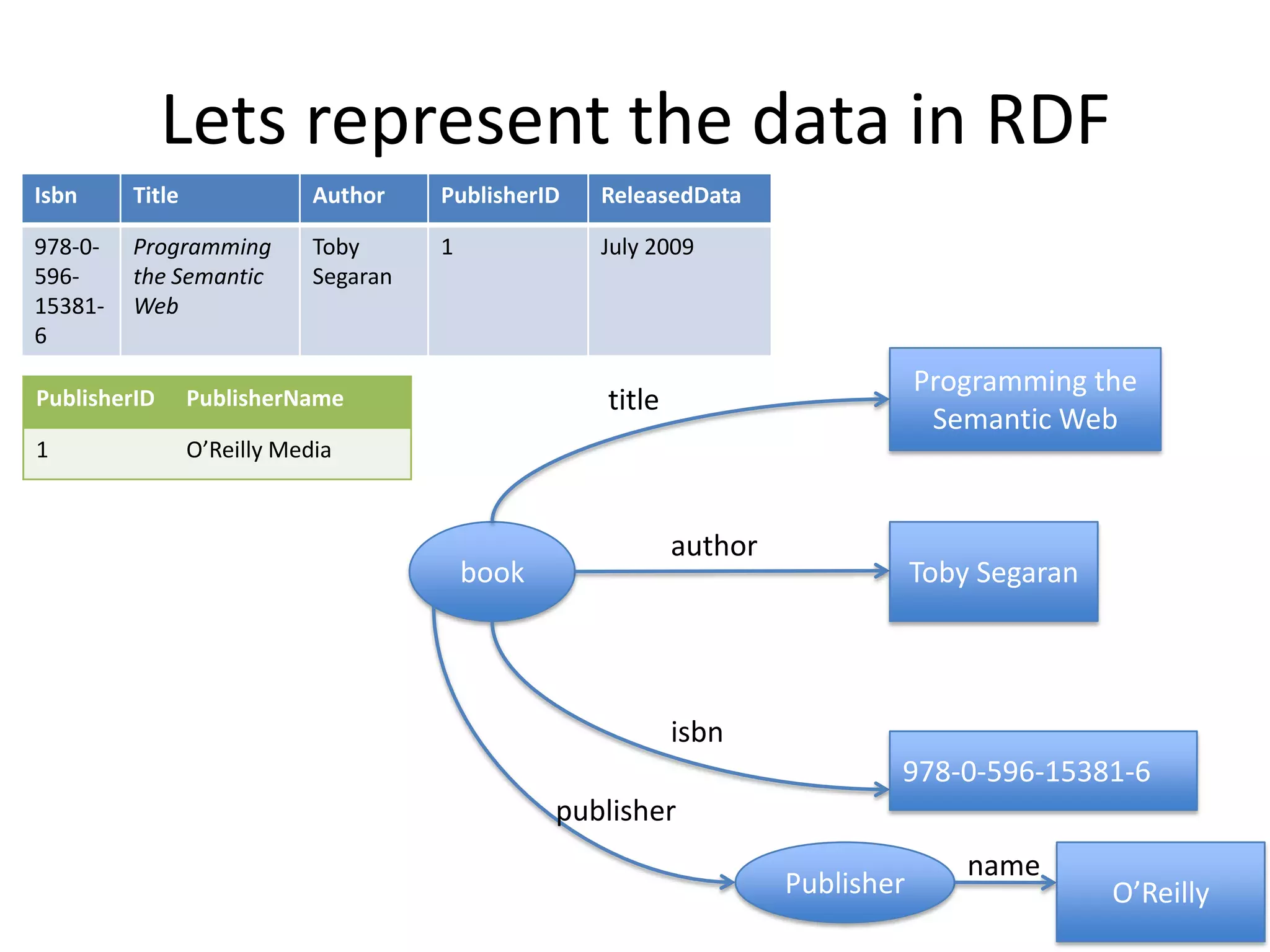

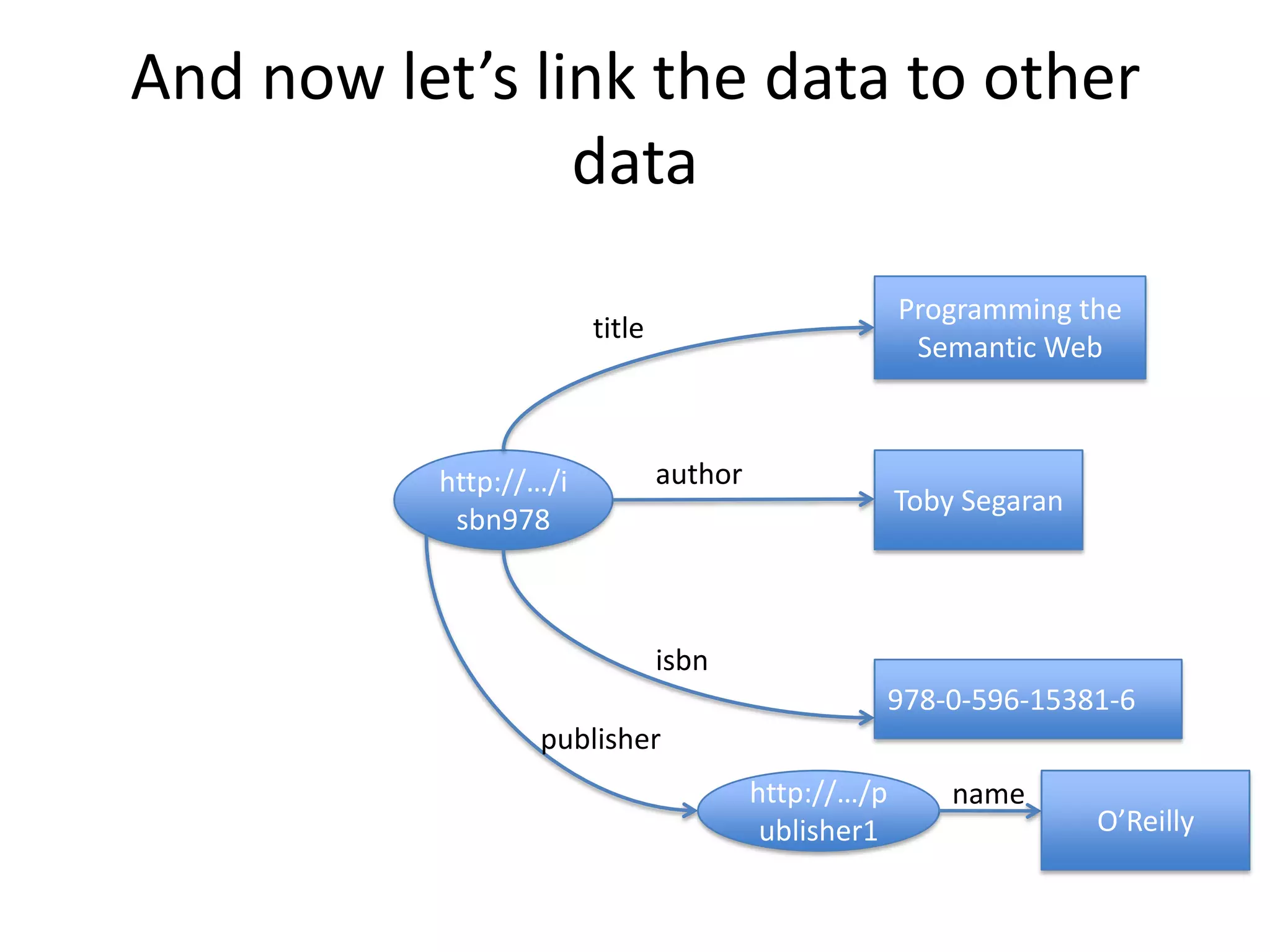



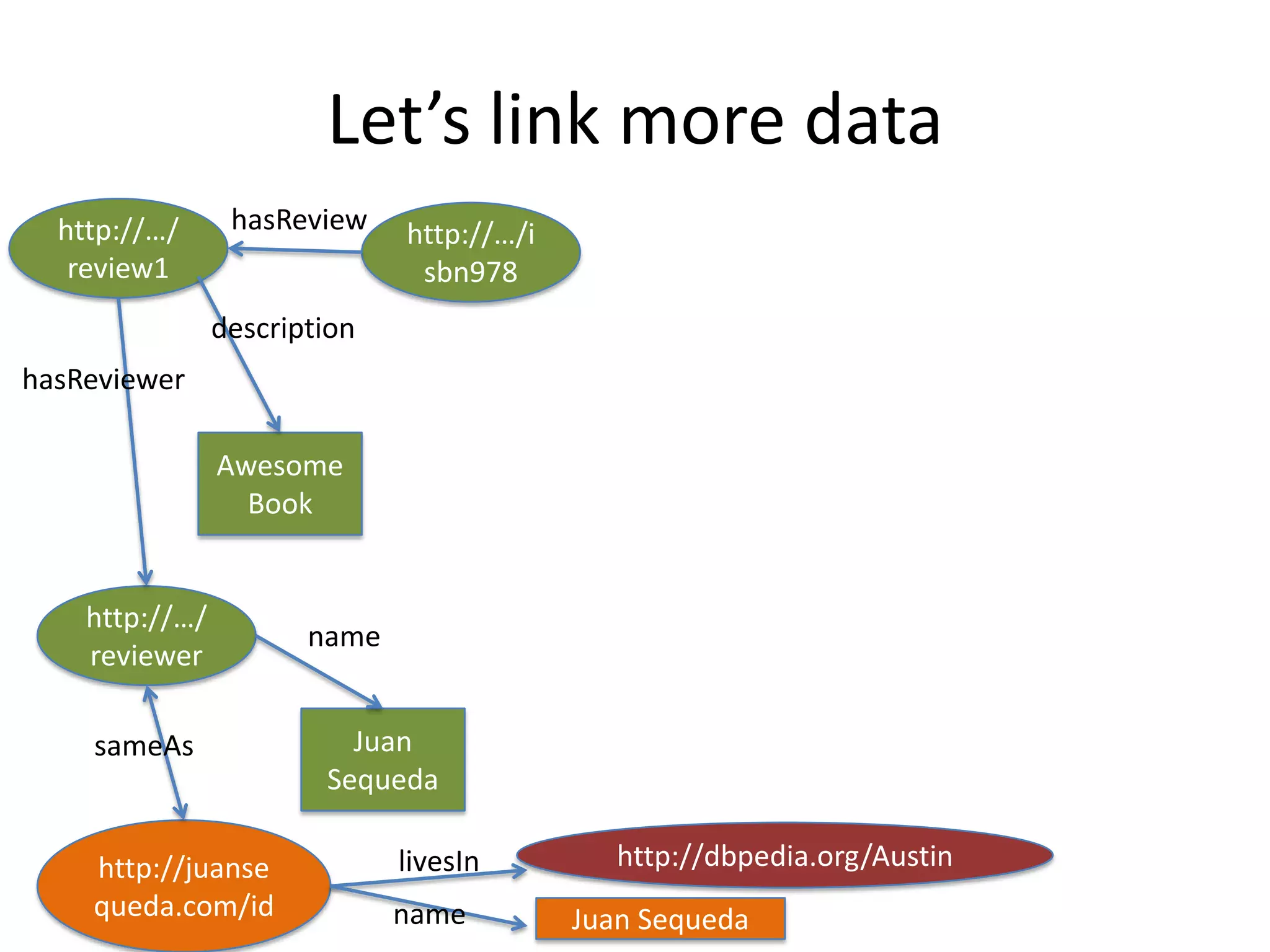
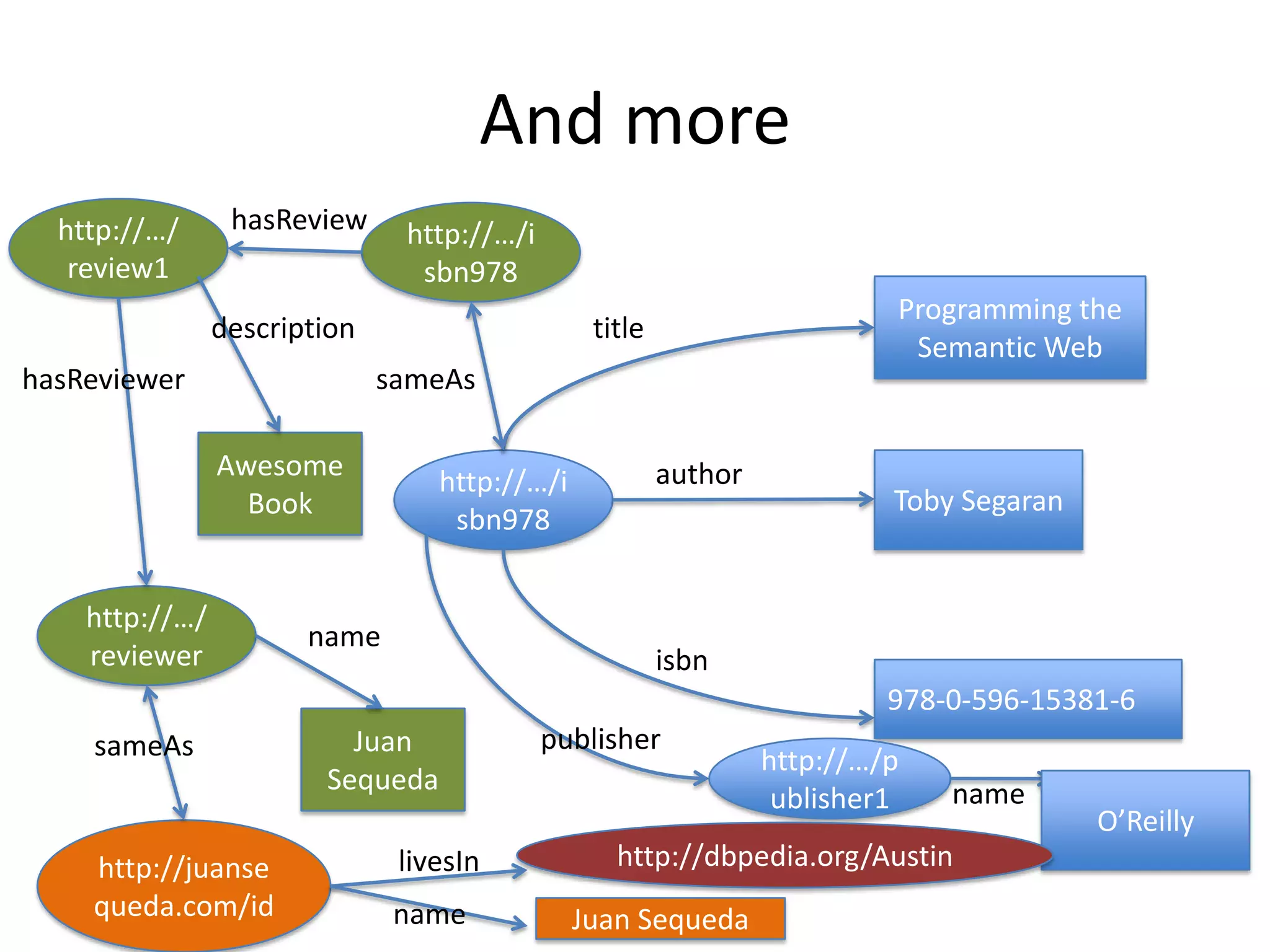






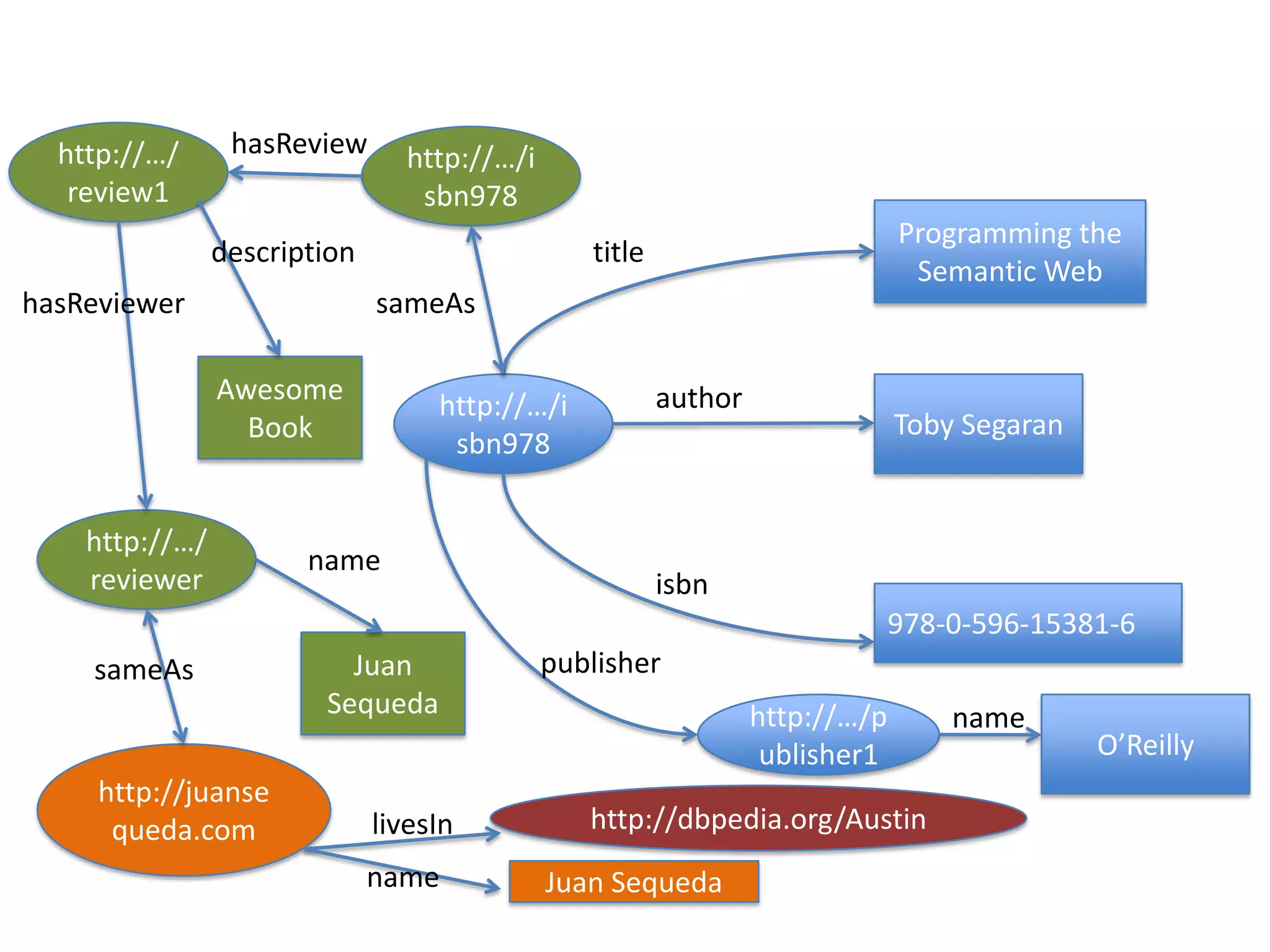

















































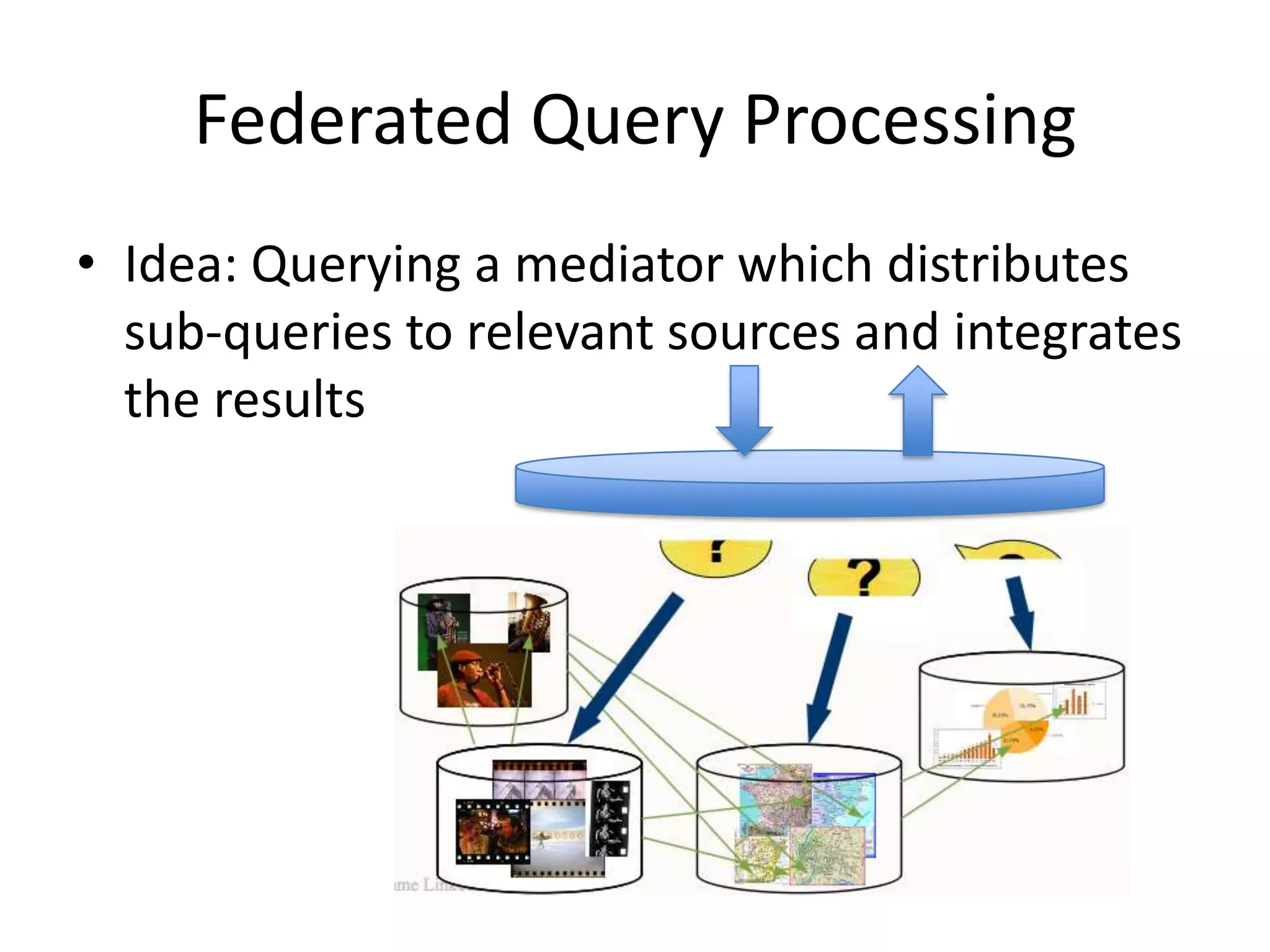








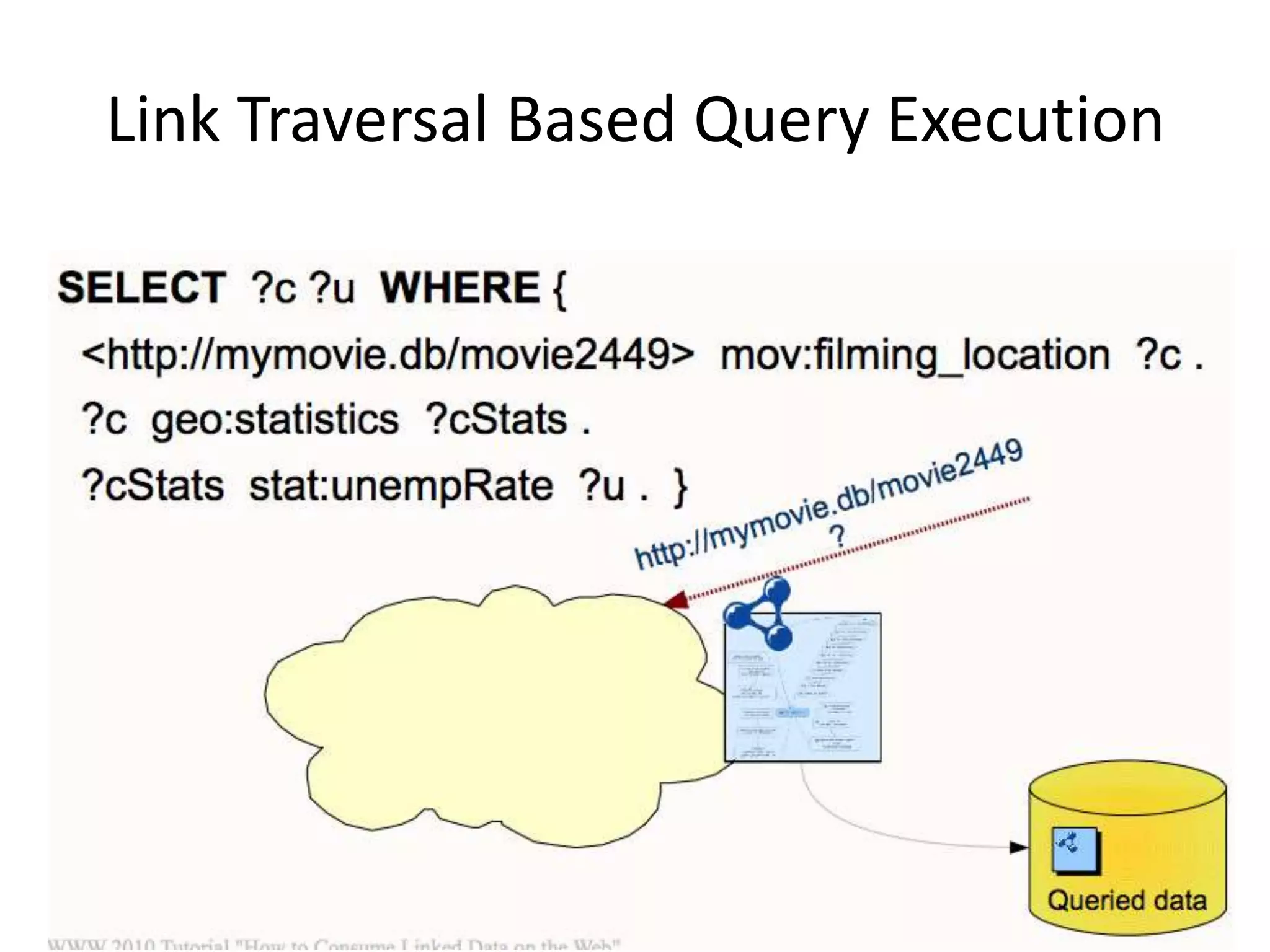
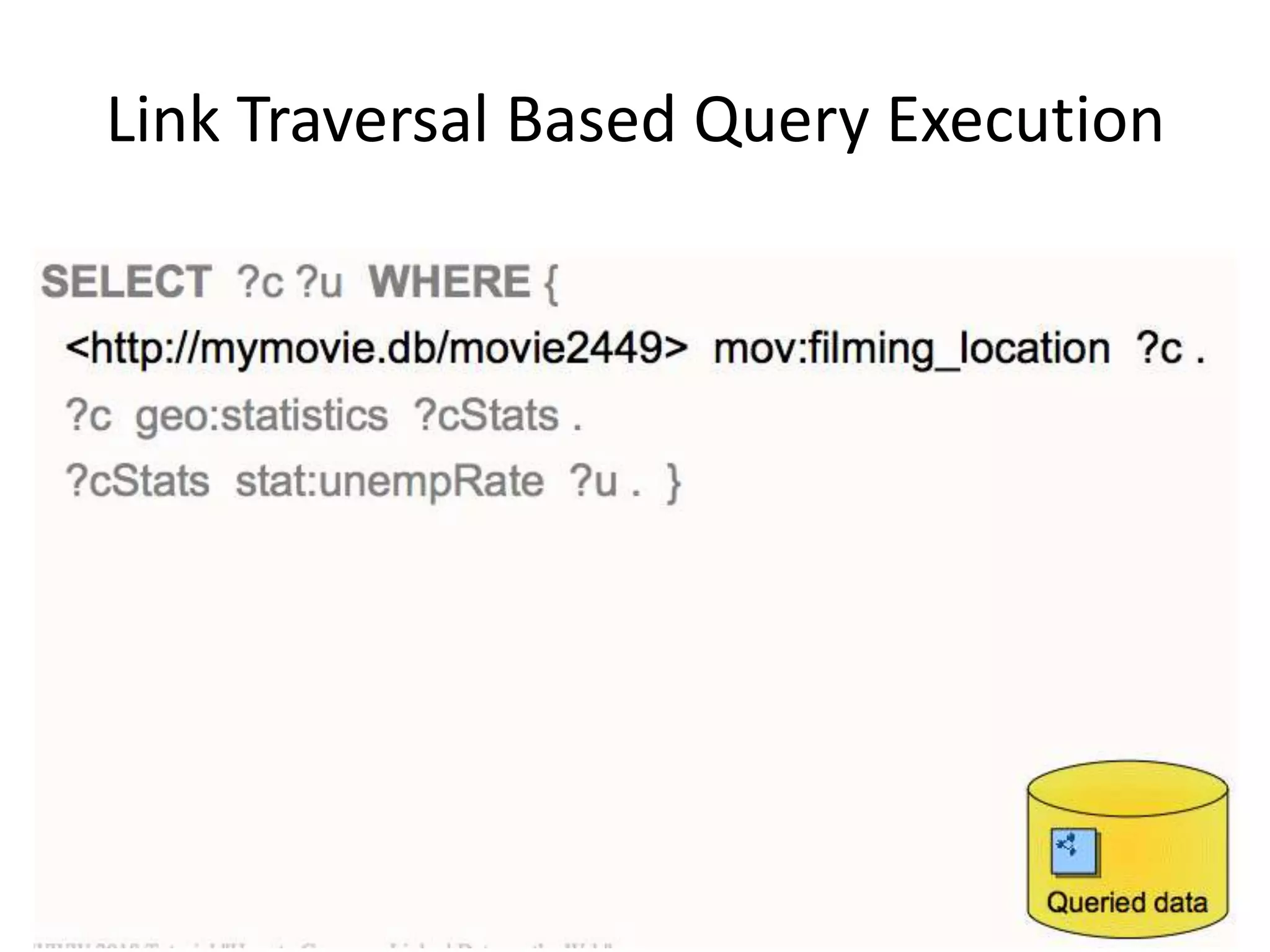



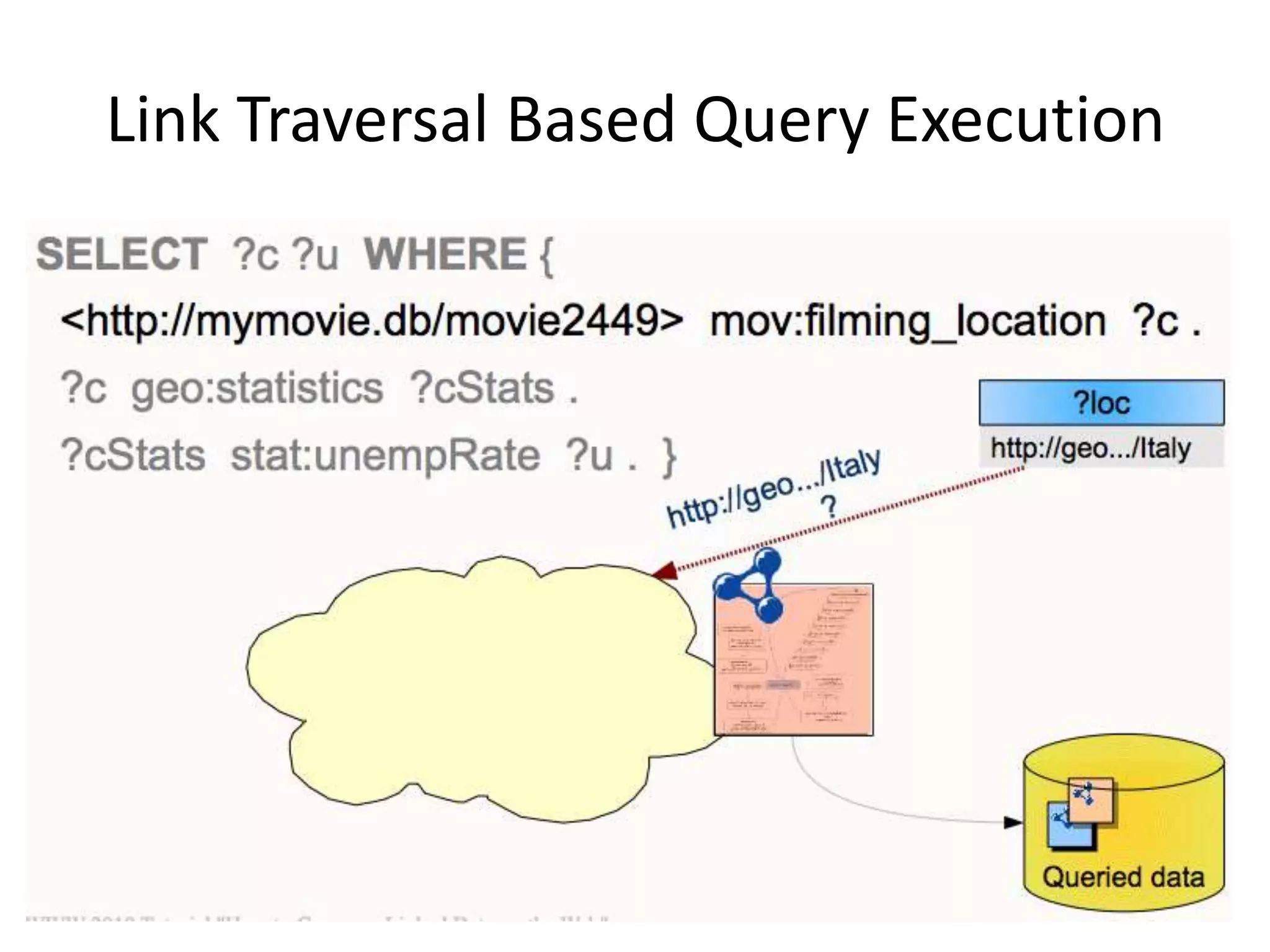

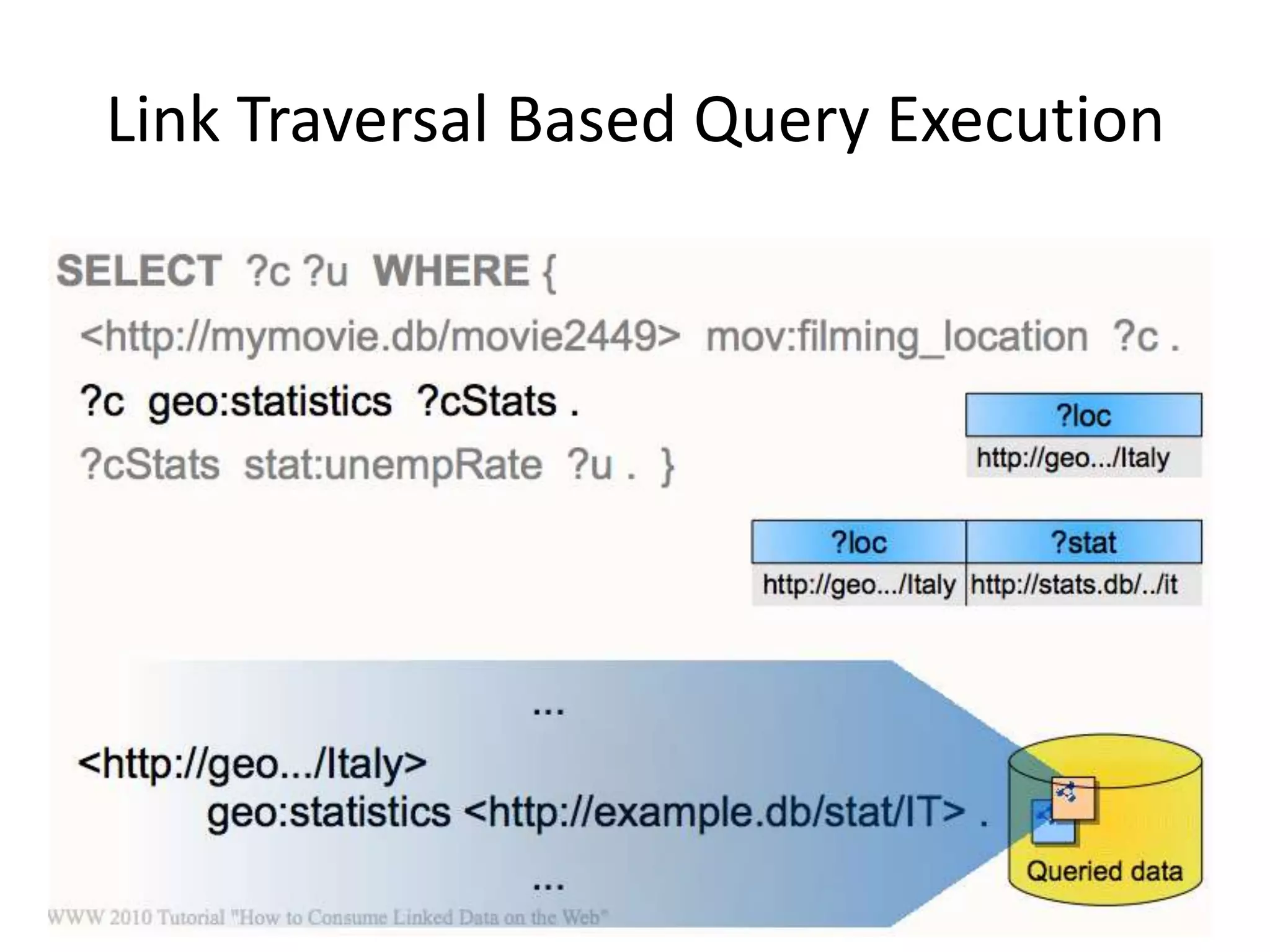
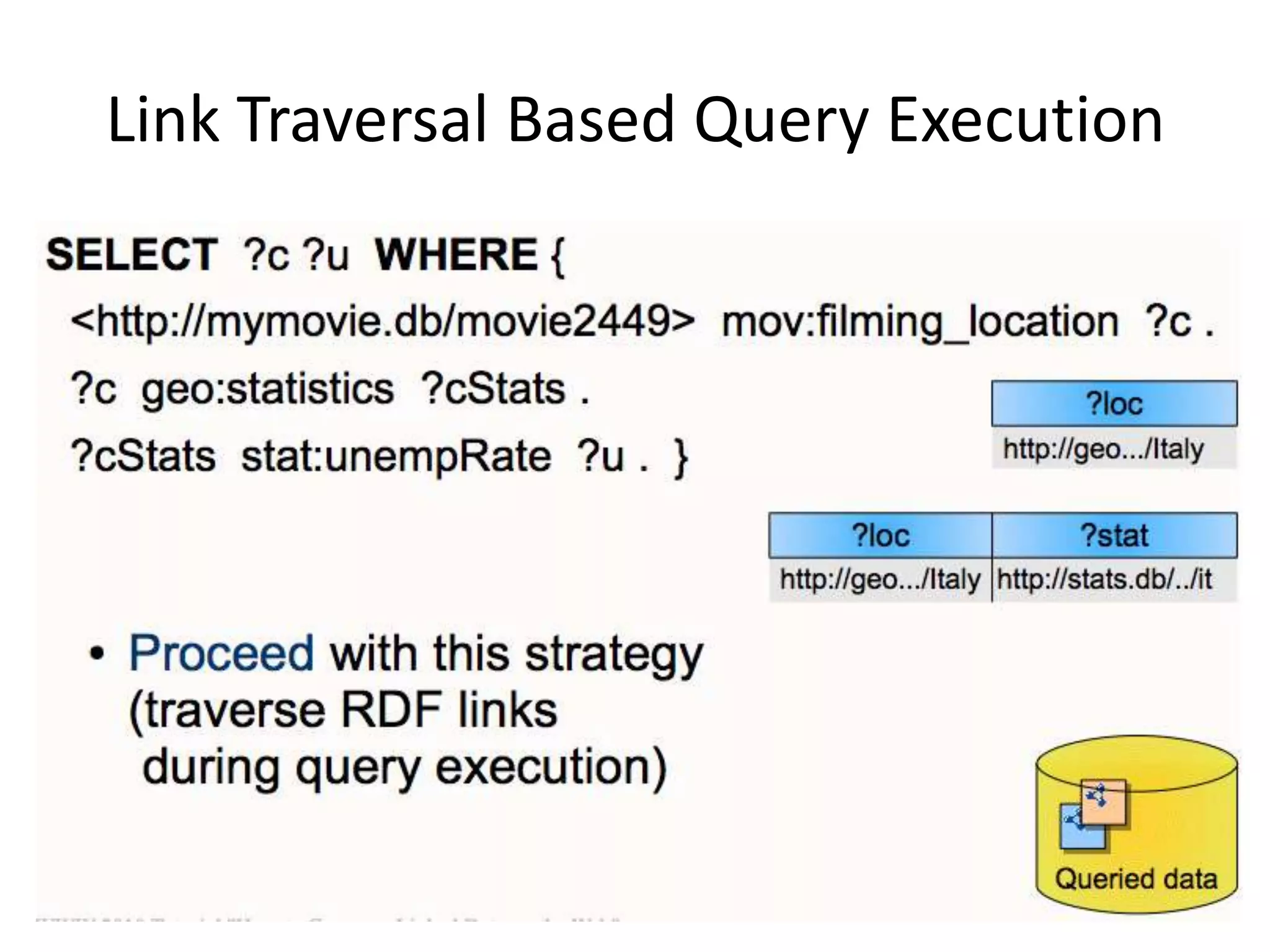



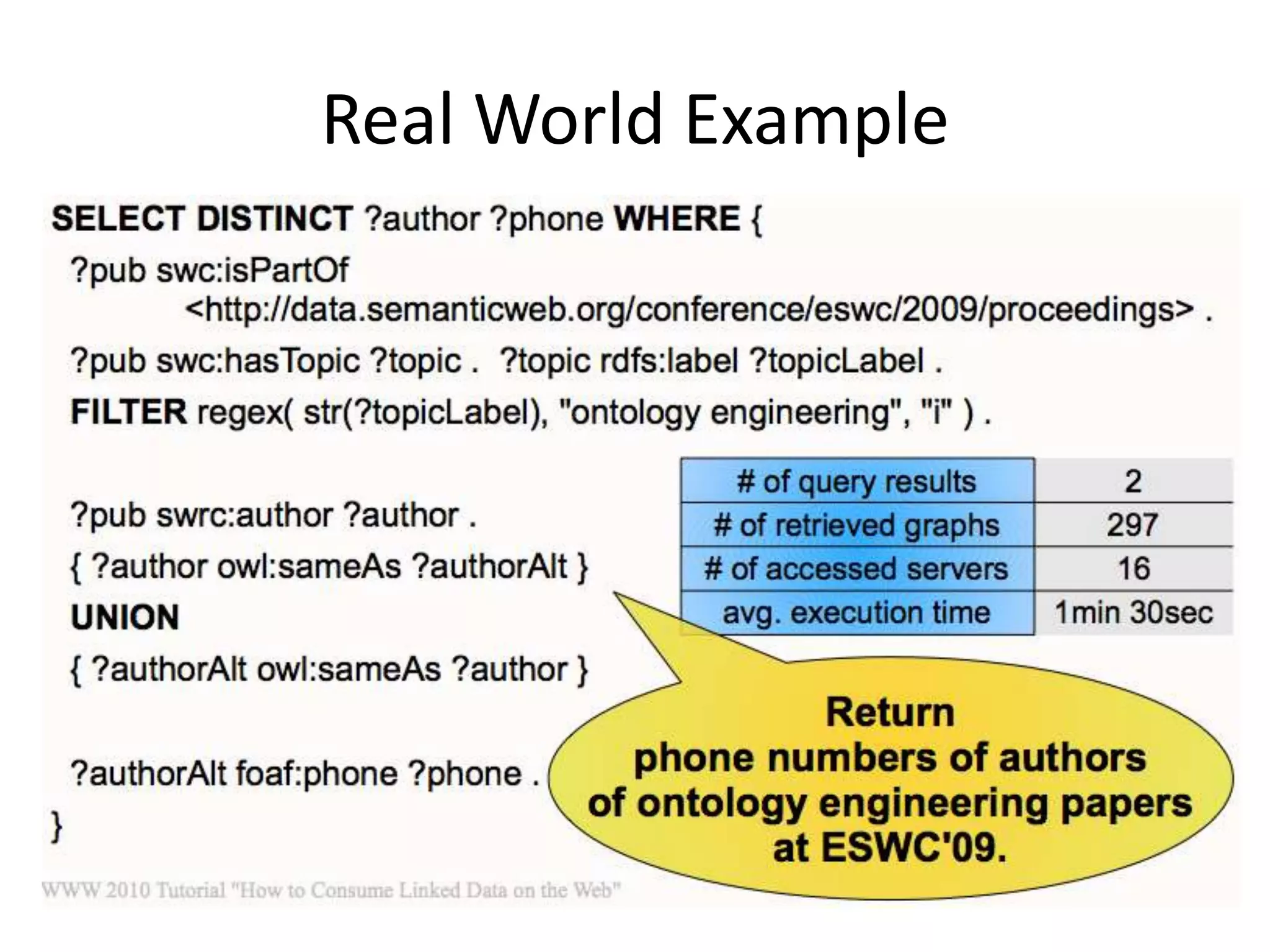







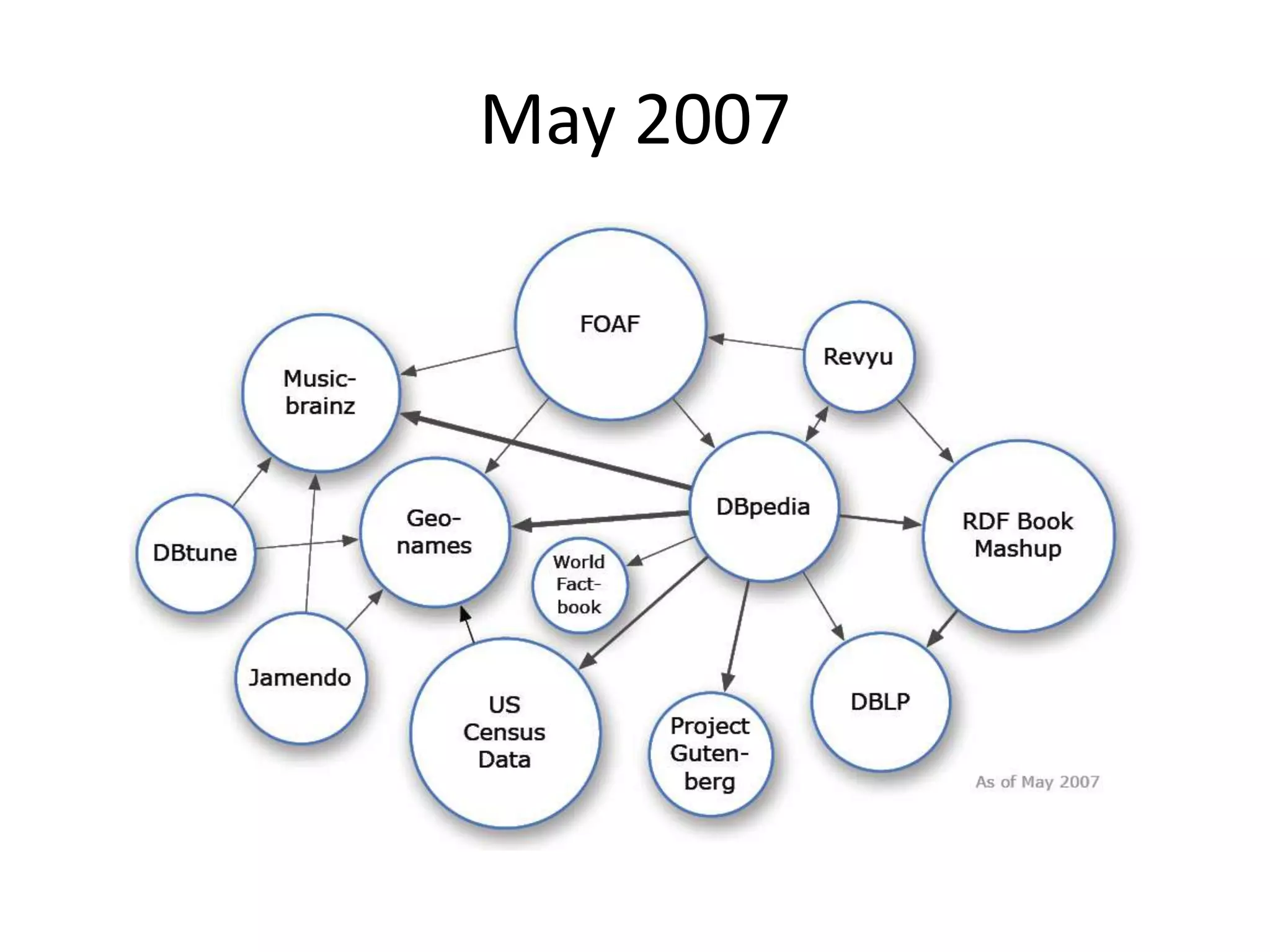
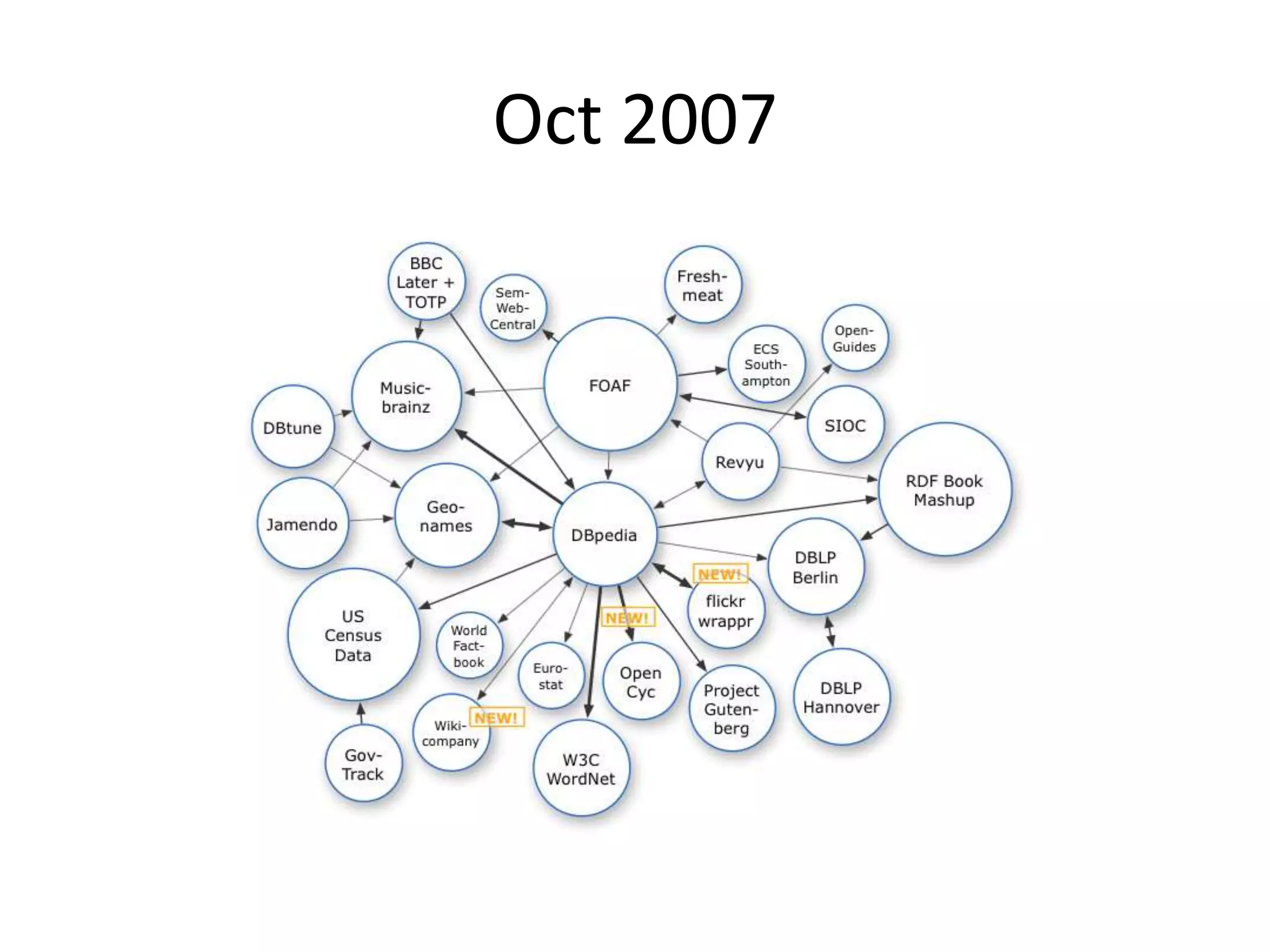
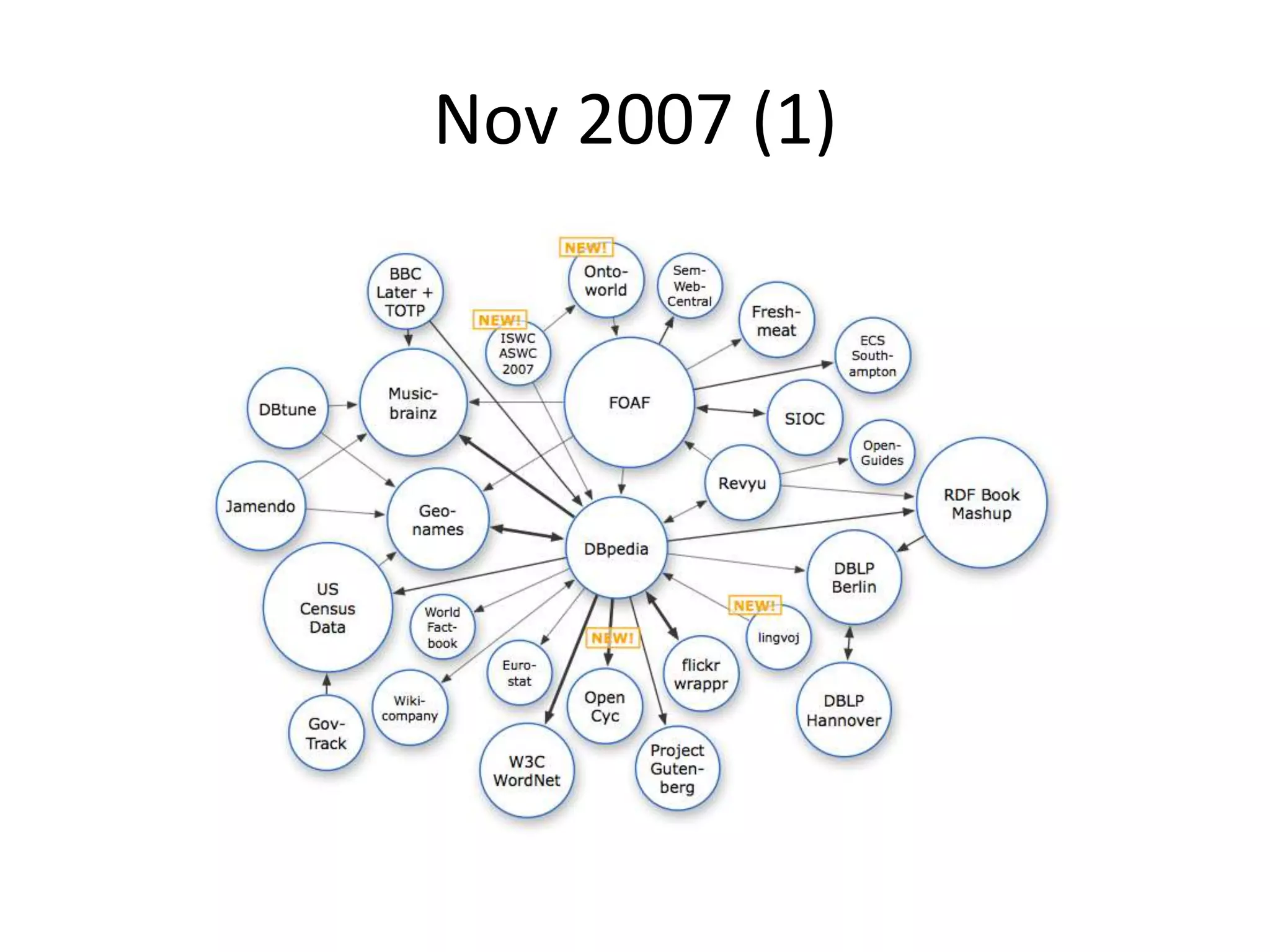
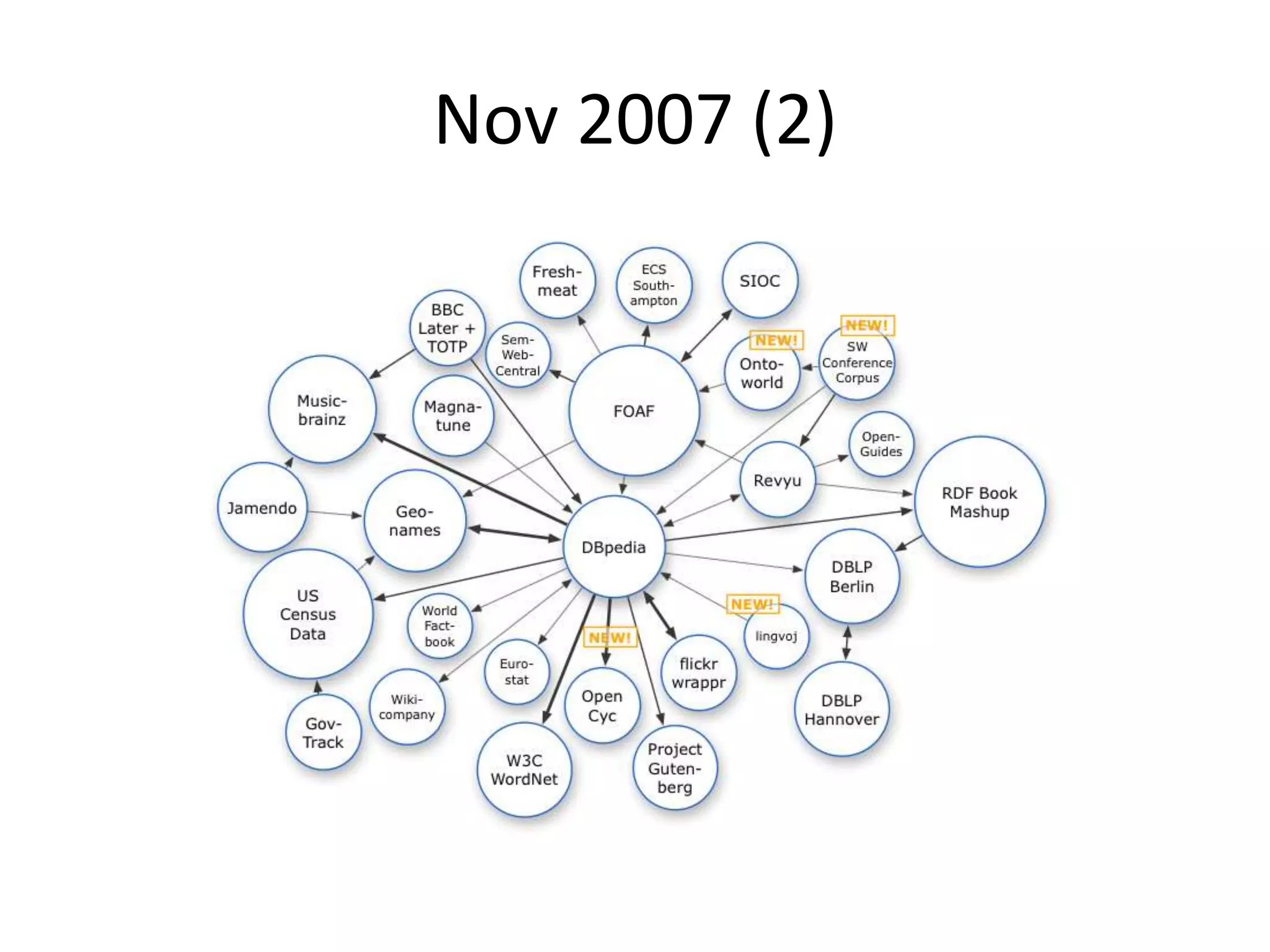
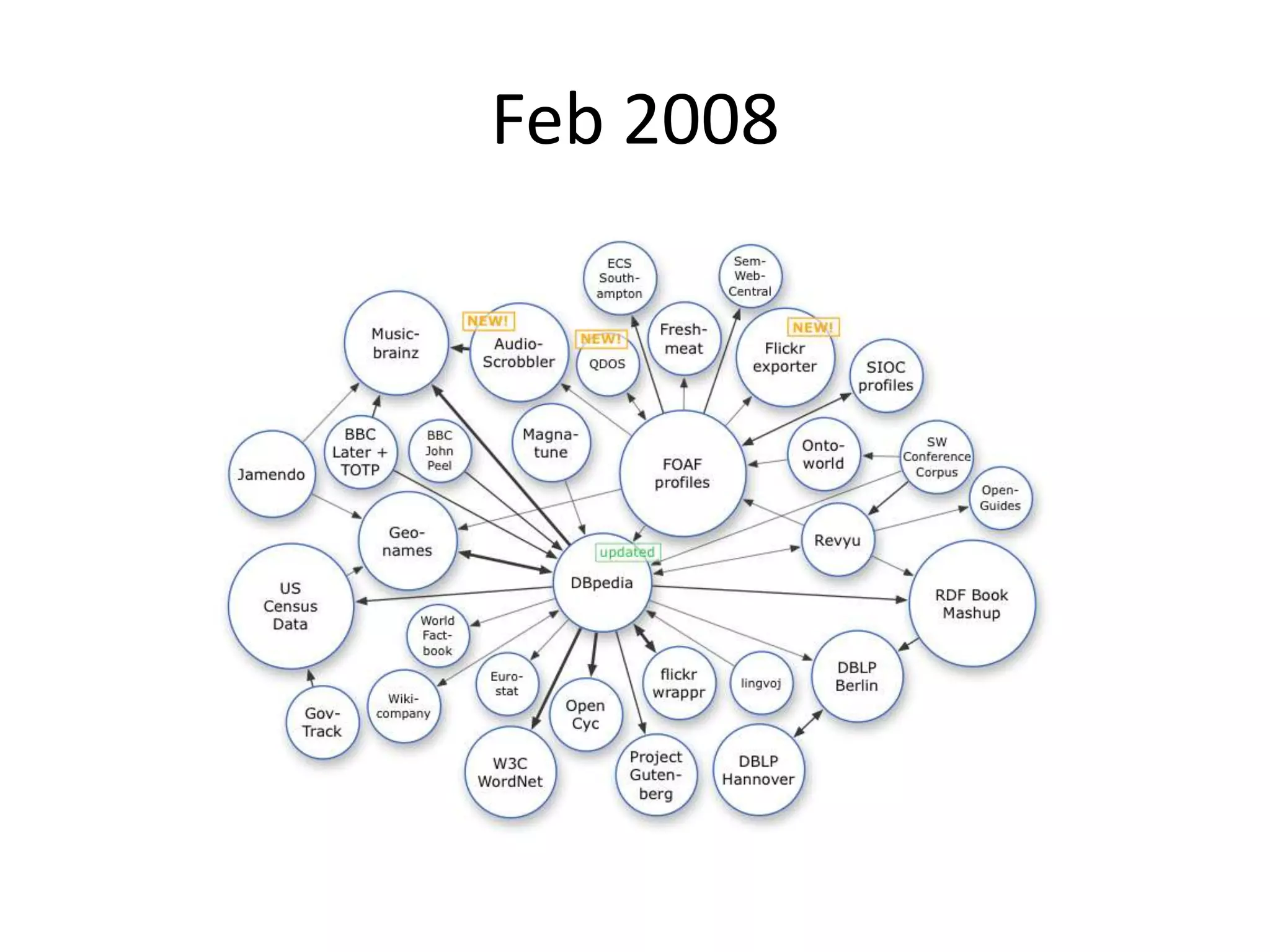
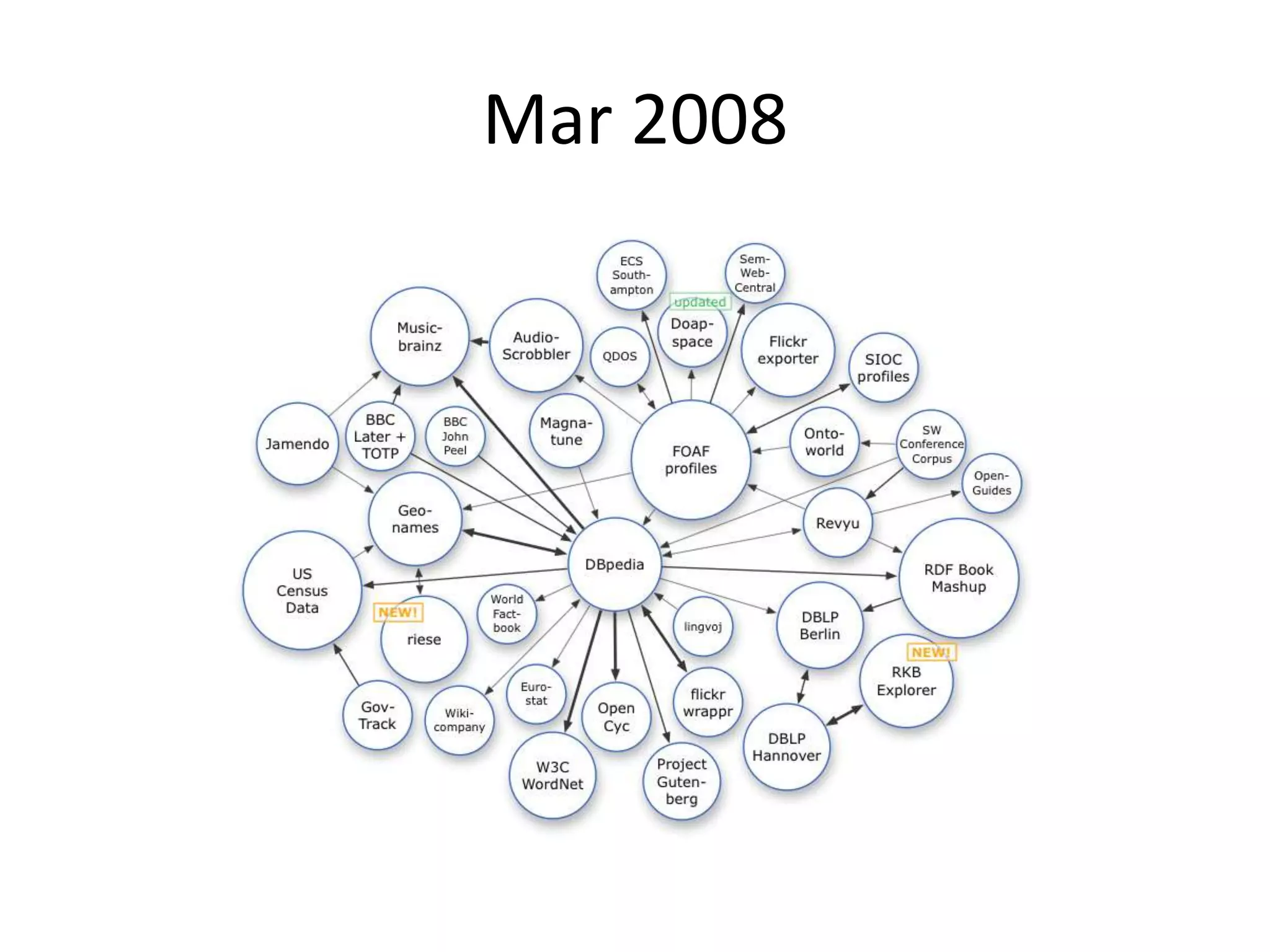
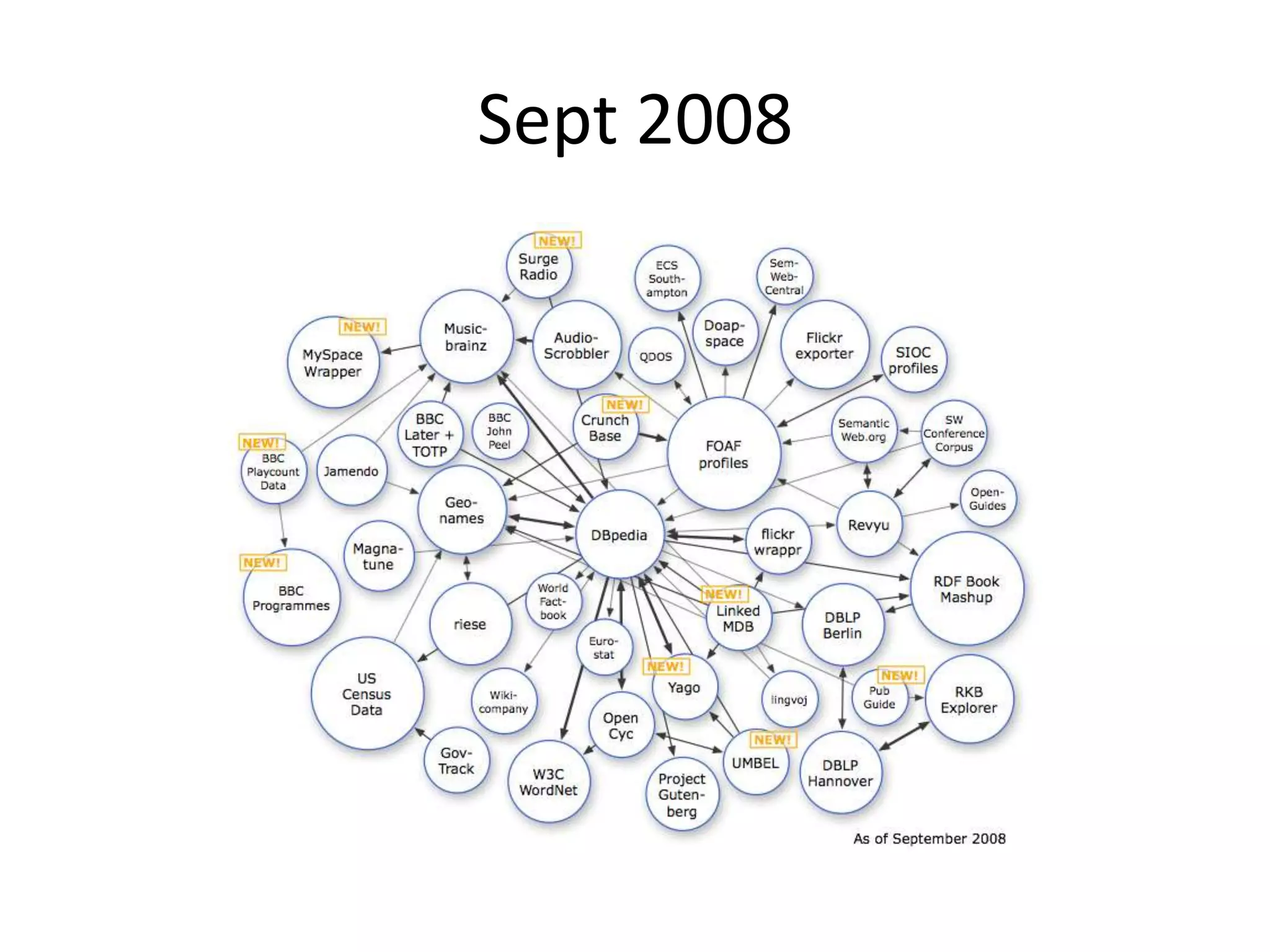
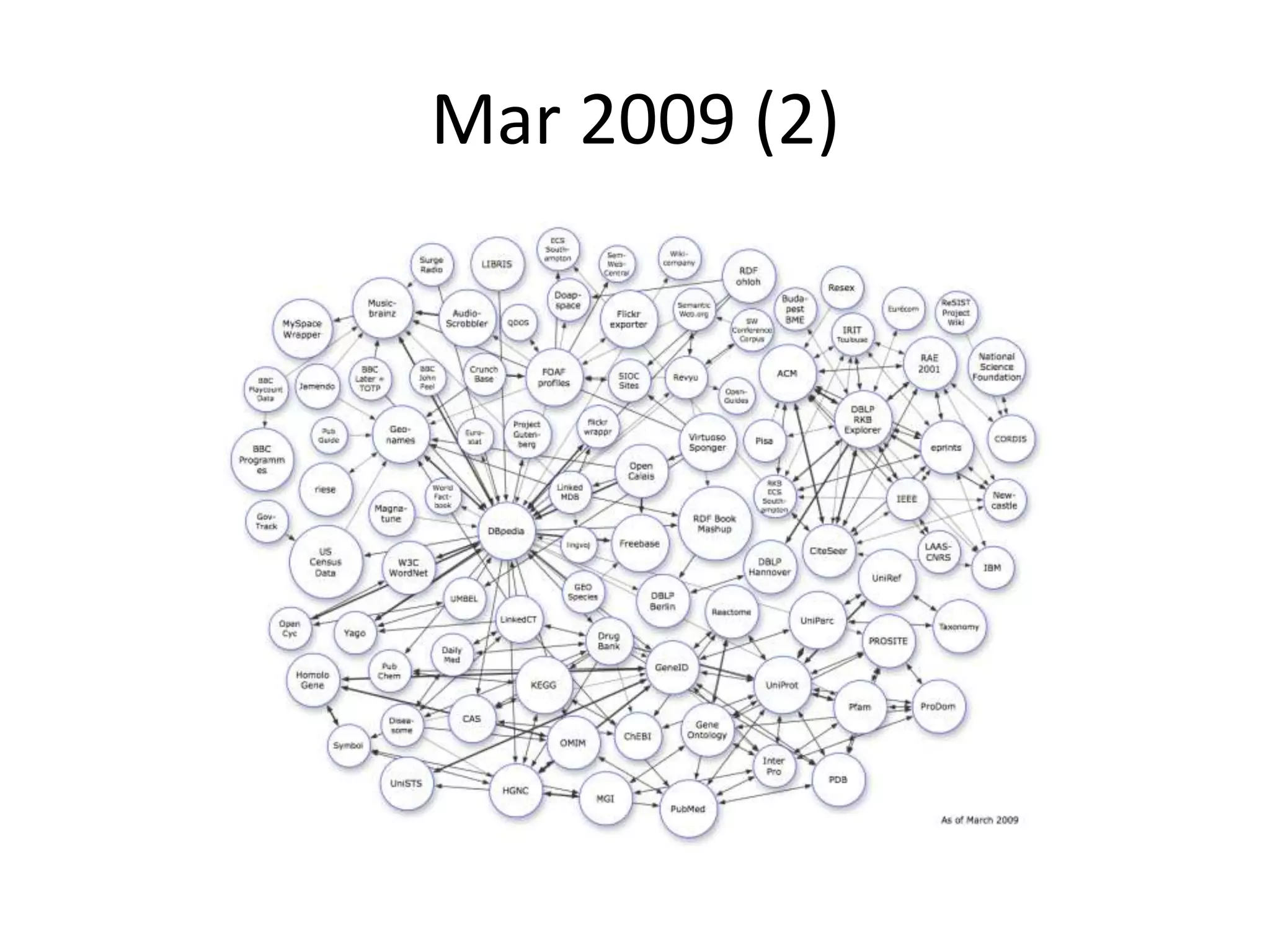
The document discusses the concept of linked data, particularly focusing on how to consume it and the benefits of using technologies like RDF and SPARQL for data integration. It highlights historical milestones in linked data development, offers examples of queries, and addresses the challenges and incentives for publishing and using linked data. Additionally, it presents various tools and methods for accessing and querying linked data efficiently.