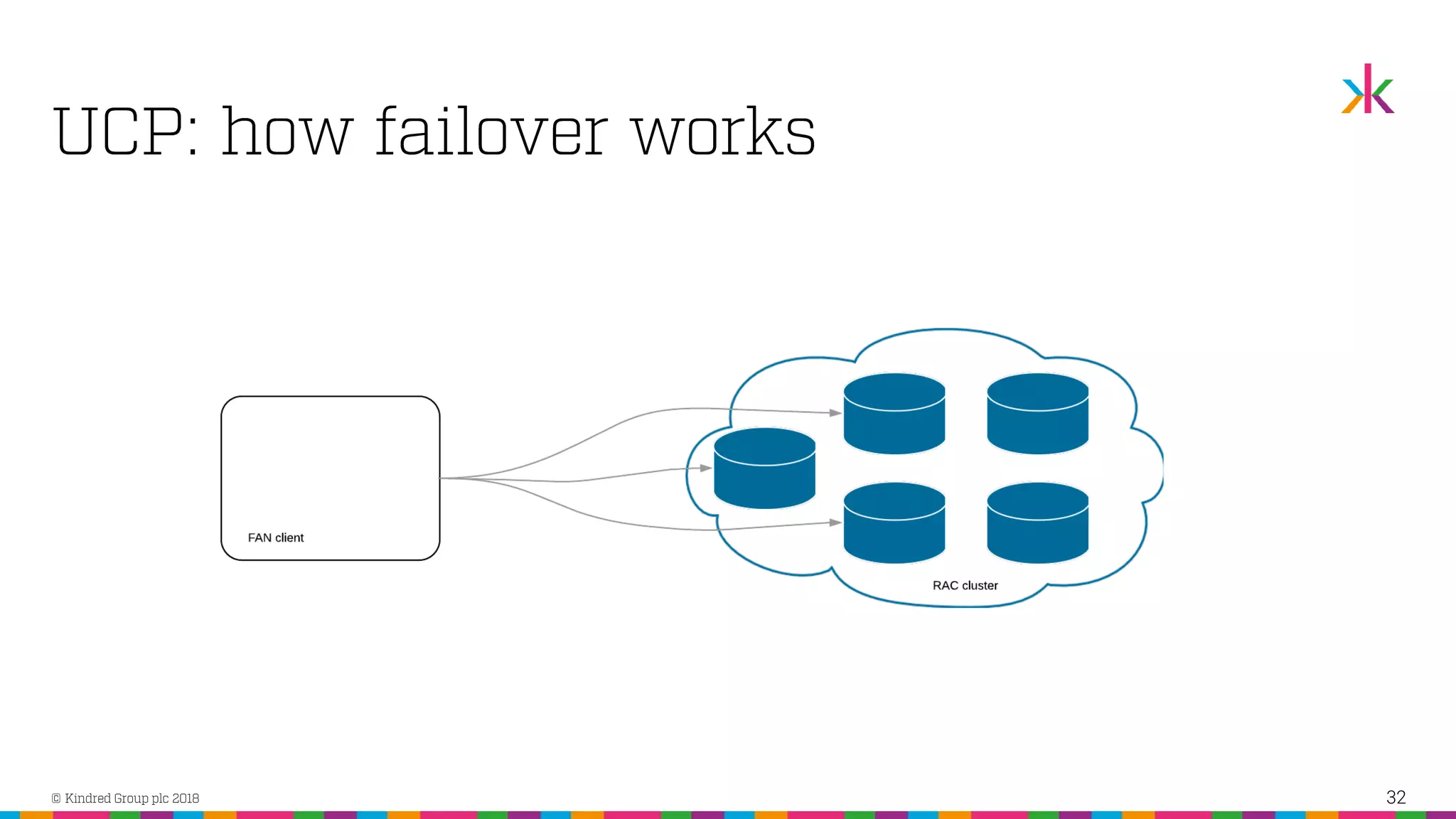
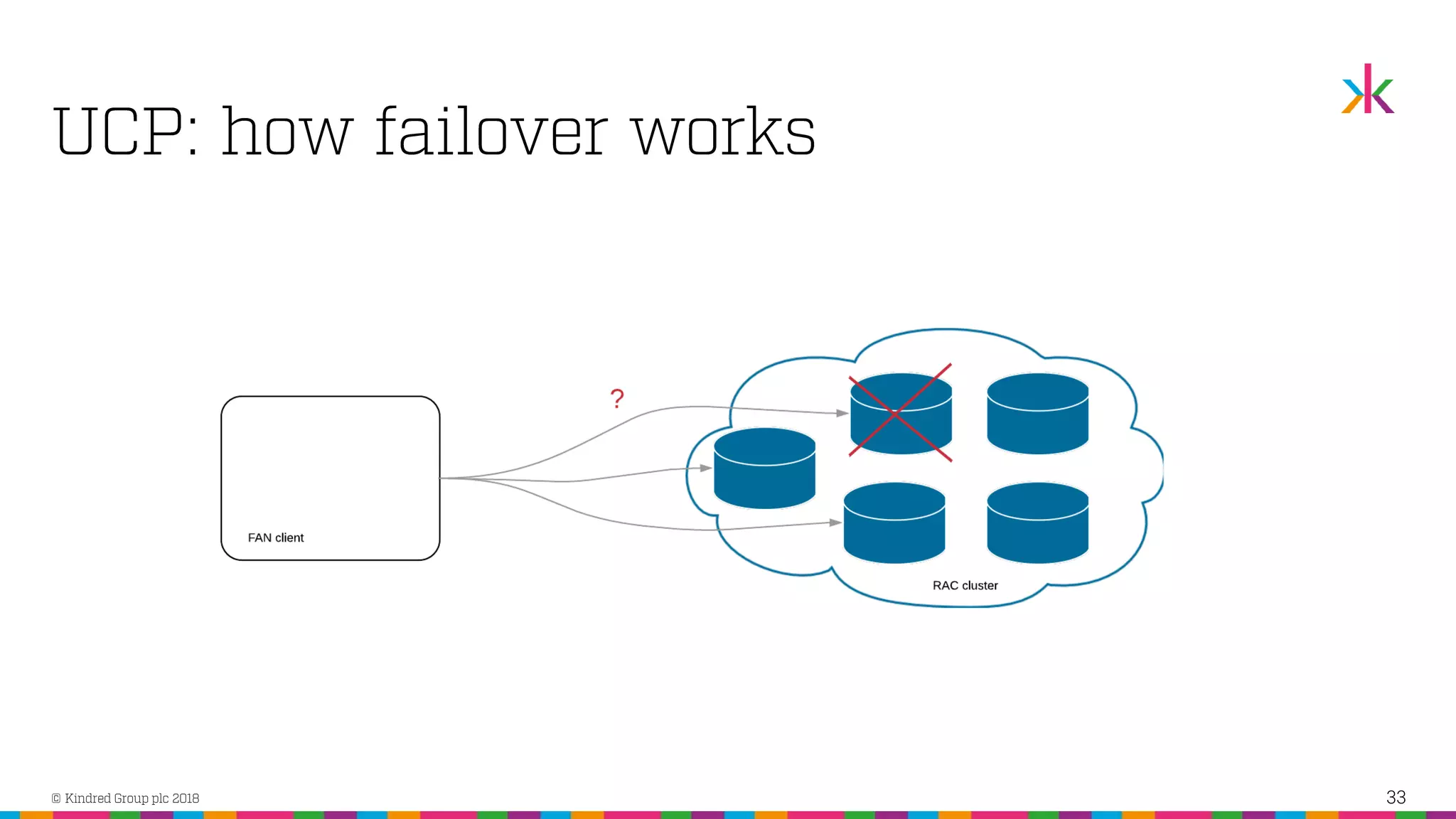
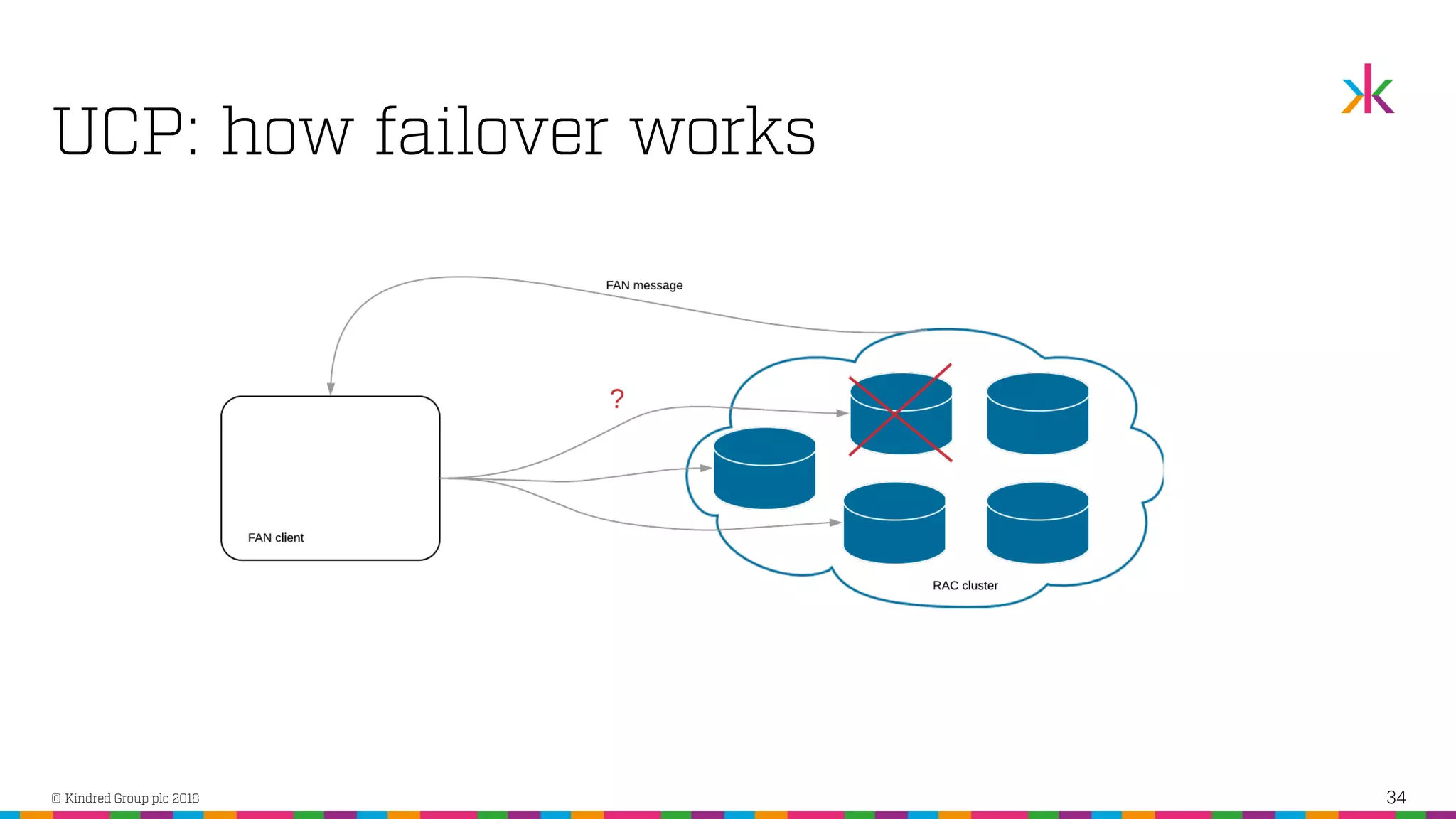
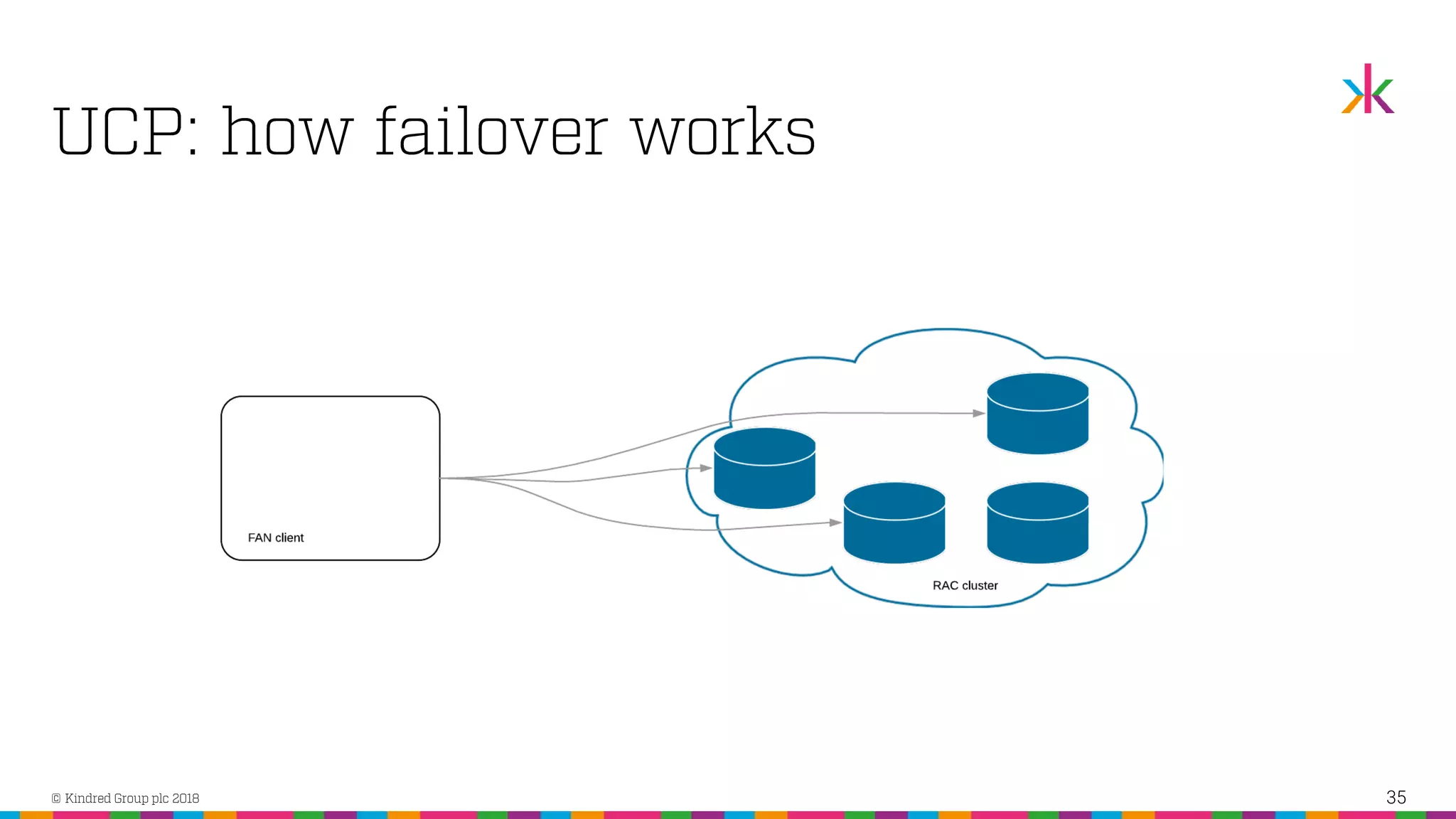
The document discusses the importance of application high availability in Oracle databases, outlining various technologies and methods to achieve it, including RAC, Data Guard, and Fast Application Notification. It emphasizes that simply purchasing Oracle RAC does not ensure high availability; proper implementation of Oracle's tools and client-side support are essential. The presentation also covers common causes of downtime and strategies for handling both planned and unplanned outages effectively.