Download as PDF, PPTX





![package net.jgp.labs.spark.datasources.l100_ photo_datasource; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; import org.apache.spark.sql.SparkSession; public class PhotoMetadataIngestionApp { public static void main(String[] args) { PhotoMetadataIngestionApp app = new PhotoMetadataIngestionApp(); app.start(); } private boolean start() { SparkSession spark = SparkSession.builder() .appName("EXIF to Dataset") .master("local[*]"). getOrCreate(); String importDirectory = "/Users/jgp/Pictures/All Photos/2010-2019/2016"; Solution #2 7@jgperrin - #EUdev6 • Write it yourself • In Java](https://image.slidesharecdn.com/a6jeangeorgesperrin-171031193503/75/Extending-Spark-s-Ingestion-Build-Your-Own-Java-Data-Source-with-Jean-Georges-Perrin-7-2048.jpg)








![/jgperrin /net.jgp.labs.spark.datasources Application 19@jgperrin - #EUdev6 import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; import org.apache.spark.sql.SparkSession; public class PhotoMetadataIngestionApp { public static void main(String[] args) { PhotoMetadataIngestionApp app = new PhotoMetadataIngestionApp(); app.start(); } private boolean start() { SparkSession spark = SparkSession.builder() .appName("EXIF to Dataset").master("local[*]").getOrCreate(); Dataset<Row> df = spark.read() .format("exif") .option("recursive", "true") .option("limit", "80000") .option("extensions", "jpg,jpeg") .load("/Users/jgp/Pictures"); df = df .filter(df.col("GeoX").isNotNull()) .filter(df.col("GeoZ").notEqual("NaN")) .orderBy(df.col("GeoZ").desc()); System.out.println("I have imported " + df.count() + " photos."); df.printSchema(); df.show(5); return true; } } Normal imports, no reference to our data source Local mode Classic read Standard dataframe API: getting my ”highest” photos! Standard output mechanism](https://image.slidesharecdn.com/a6jeangeorgesperrin-171031193503/75/Extending-Spark-s-Ingestion-Build-Your-Own-Java-Data-Source-with-Jean-Georges-Perrin-19-2048.jpg)














The document outlines a presentation by Jean Georges Perrin on extending Apache Spark's ingestion capabilities using Java to create custom data sources. It discusses different data ingestion solutions, including leveraging existing libraries and building new ones, along with practical examples of coding. The presentation targets software and data engineers looking to enhance Spark's versatility with non-standard data formats.
The speaker discusses extending Apache Spark's ingestion capabilities using Java, introducing themselves and engaging with the audience on their programming experiences.
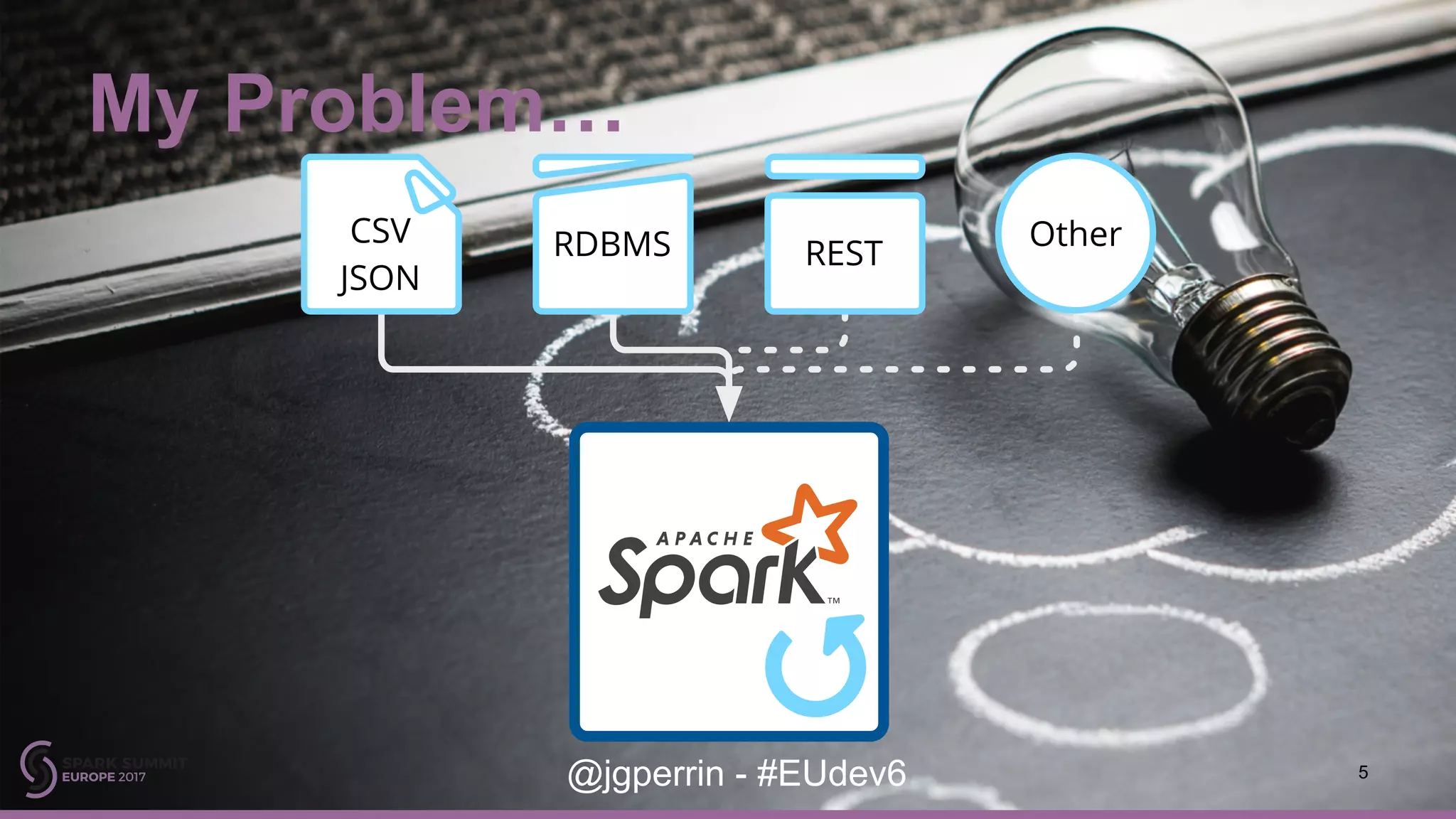
Identifies challenges with existing data formats like CSV and JSON, encouraging users to explore Spark packages and custom solutions.
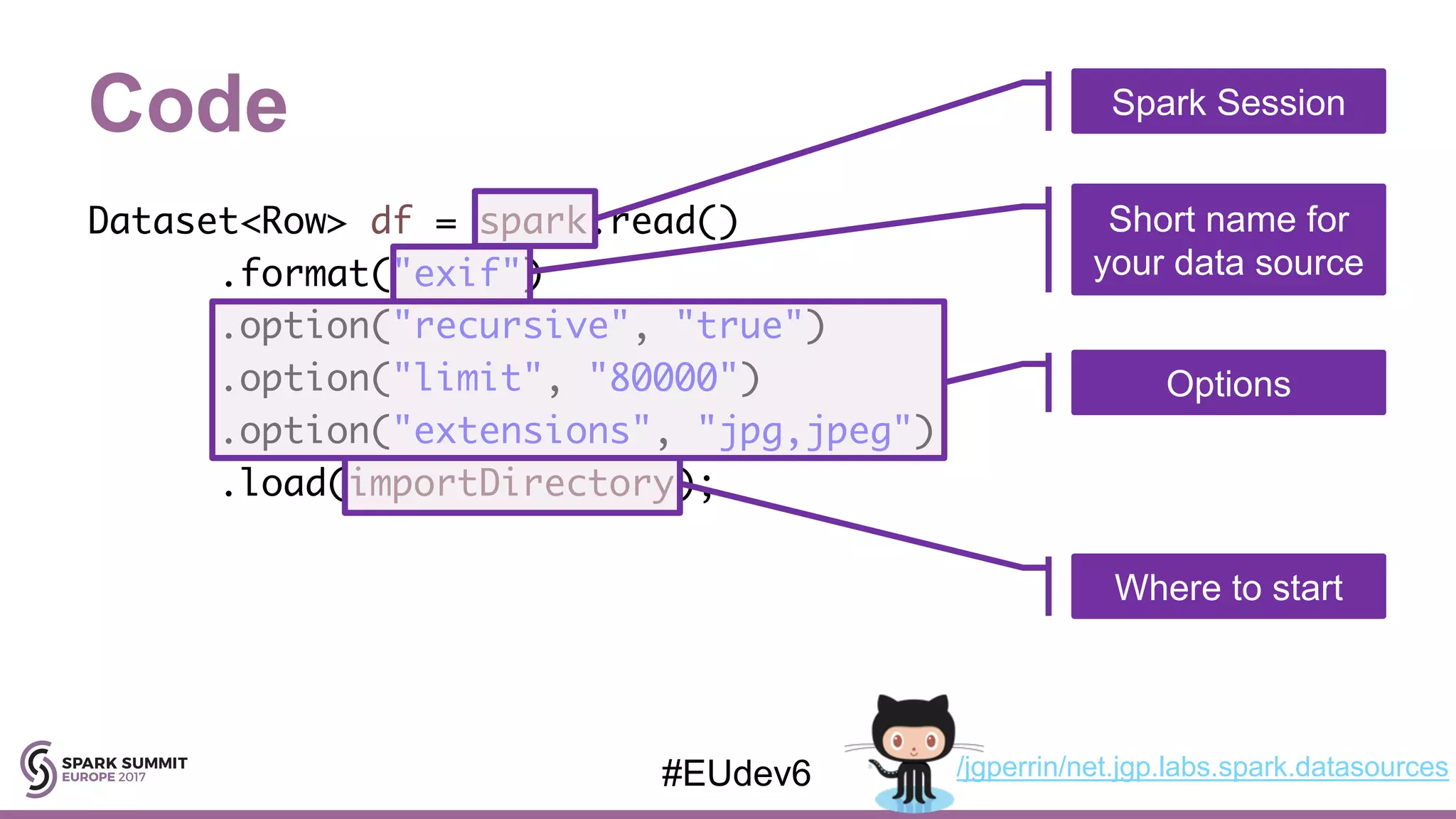
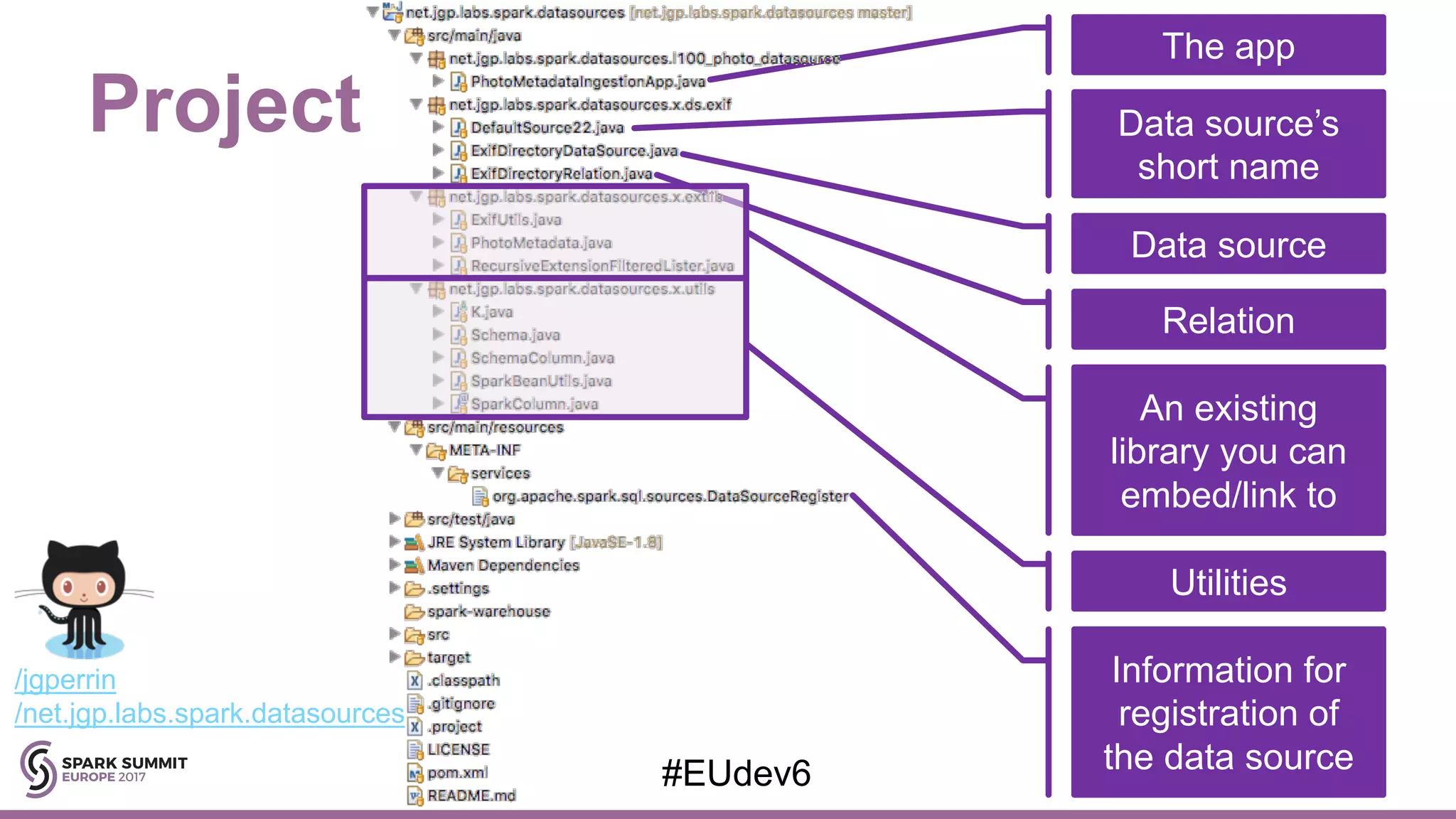
Step-by-step guidance on writing a custom data source in Java, including reading metadata and building Spark applications.
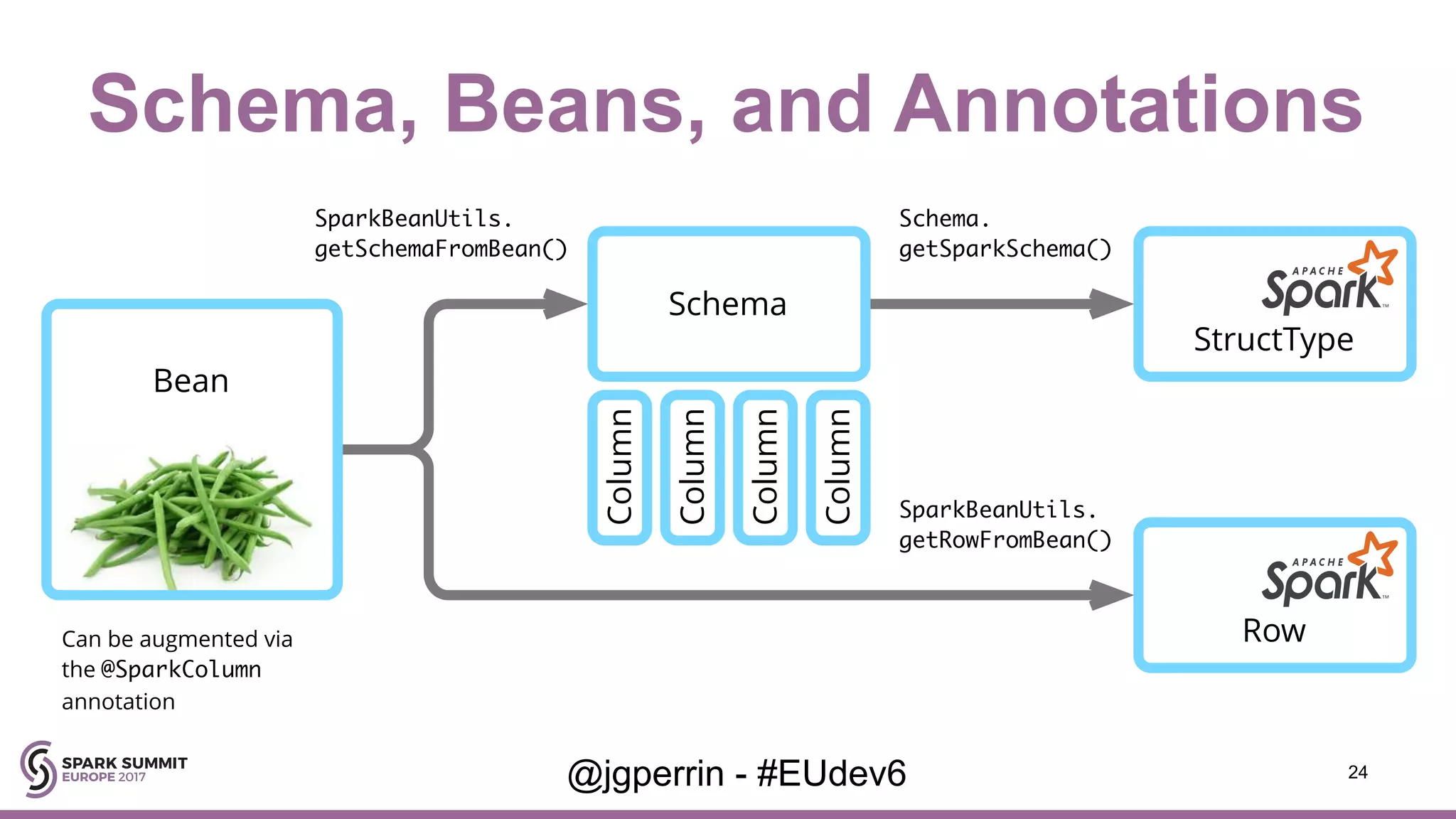
Covers the mechanics of importing photo metadata into Spark, including schema definition and data extraction processes.
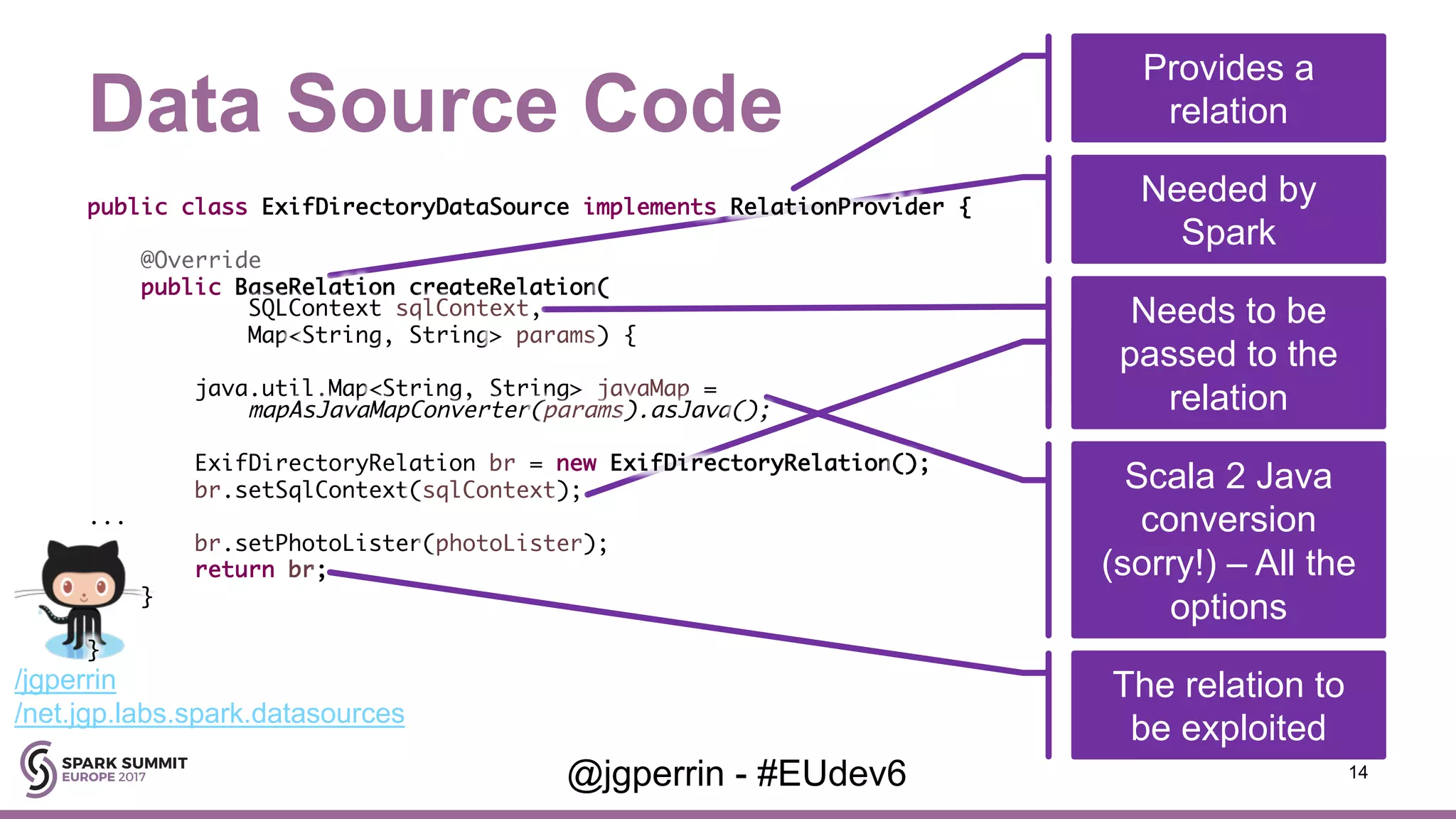
Focuses on the relation structure between Spark and Java libraries, emphasizing data conversion and efficient schema management.
Provides resources for further learning, concluding insights on building custom data sources, and encouraging audience engagement.