RRZE “Woody” cluster all 246 nodes with 4 cores and high clock frequency (3.5/3.7 GHz) Intel Xeon E3-1240 v? processors 70x Intel Haswell, 8 GB RAM 64x Intel Skylake, 32 GB RAM 112x Intel Kaby Lake, 32 GB RAM at least 960 GB local HDD/SSD and Gbit network only main workhorse for throughput and single-node jobs 2021-10-20 | HPC in a Nutshell | HPC@RRZE 4
5.
RRZE “Emmy” cluster 543 compute nodes (10.880 cores) 2 Intel Xeon E5-2660v2 (Ivy Bridge) 2.2 GHz (10 cores) 20 cores/node + SMT cores 64 GB main memory per node No local disks Full QDR Infiniband fat tree network: up to 40 GBit/s main workhorse for parallel jobs 2021-10-20 | HPC in a Nutshell | HPC@RRZE 5
6.
RRZE “Meggie” cluster 728 Compute nodes (14.560 cores) 2 Intel Xeon E5-2630 v4 (Broadwell) 2.2 GHz (10 cores) 20 cores/node 64 GB main memory No local disks Intel OmniPath network: Up to 100 Gbit/s for scalable parallel jobs 2021-10-20 | HPC in a Nutshell | HPC@RRZE 6
7.
RRZE “TinyGPU” cluster 7 nodes with 2x “Broadwell” @2.2 GHz, 64 GB RAM, 980 GB SSD, 4x GTX1080 10 nodes with 2x “Broadwell” @2.2 GHz, 64 GB RAM, 980 GB SSD, 4x GTX1080Ti 12 nodes with 2x “Skylake” @ 3.2 GHz, 96 GB RAM, 1.8 TB SSD, 4x RTX 2080Ti 4 nodes with 2x “Skylake” @3.2 GHz, 96 GB RAM, 2.9 TB SSD, 4x Tesla V100 7 nodes with 2x “Cascade Lake” @2.9 GHz, 384 GB RAM, 3.8 TB SSD, 8x RTX3080 8 nodes with 2x AMD Rome 7662 @2.0 GHz, 512 GB RAM, 5.8 TB SSD, 4x Volta A100 for GPU workloads – not all nodes always generally available 2021-10-20 | HPC in a Nutshell | HPC@RRZE 7 Use different batch system (Torque)
8.
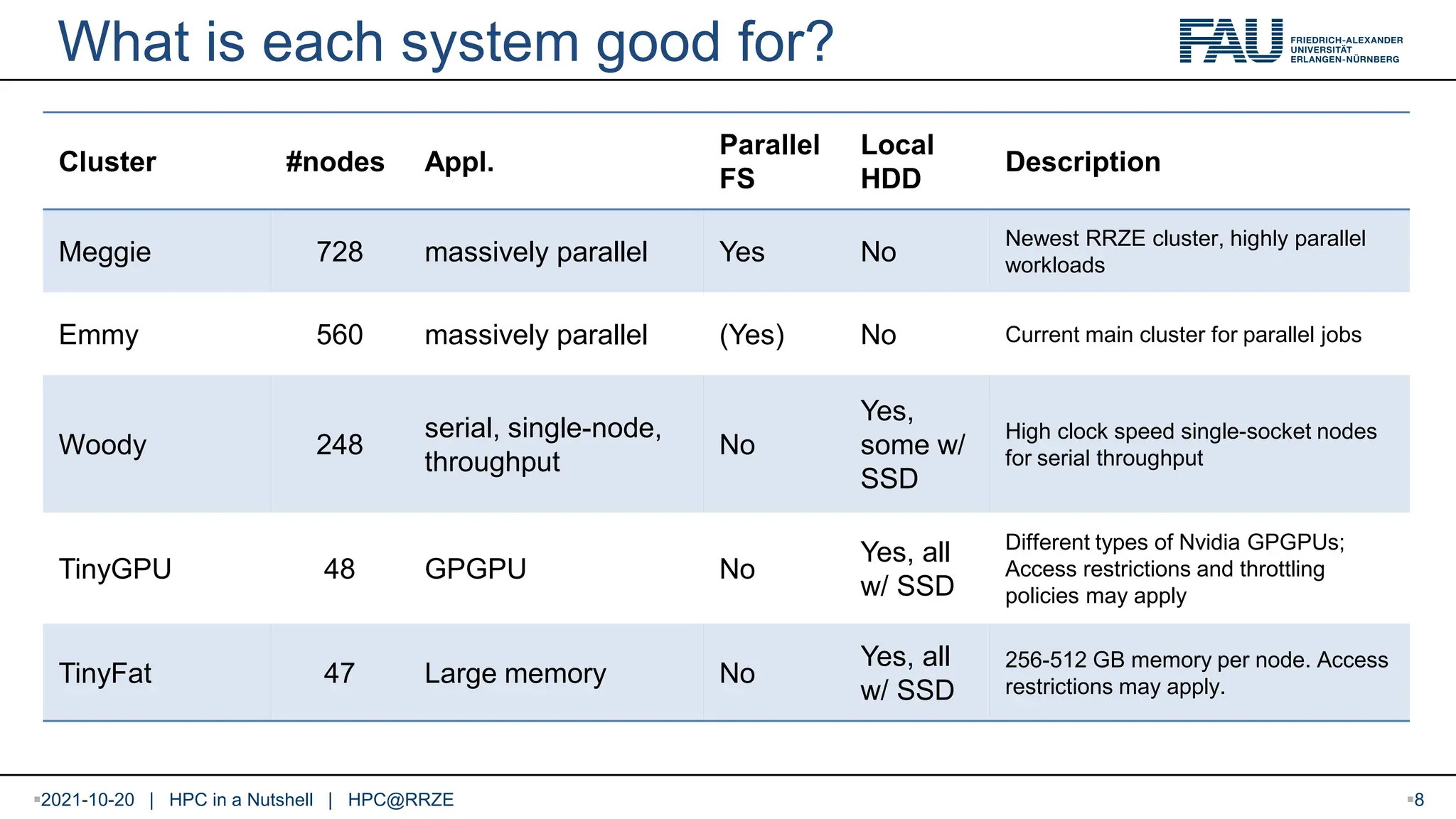
What is eachsystem good for? Cluster #nodes Appl. Parallel FS Local HDD Description Meggie 728 massively parallel Yes No Newest RRZE cluster, highly parallel workloads Emmy 560 massively parallel (Yes) No Current main cluster for parallel jobs Woody 248 serial, single-node, throughput No Yes, some w/ SSD High clock speed single-socket nodes for serial throughput TinyGPU 48 GPGPU No Yes, all w/ SSD Different types of Nvidia GPGPUs; Access restrictions and throttling policies may apply TinyFat 47 Large memory No Yes, all w/ SSD 256-512 GB memory per node. Access restrictions may apply. 2021-10-20 | HPC in a Nutshell | HPC@RRZE 8
HPC account Youneed a separate account (not your IdM account) HPC account application form Account can access all HPC systems at RRZE! Ask your local RRZE contact person for help If you change your affiliation, you need a new HPC account. Data migration may be required 2021-10-20 | HPC in a Nutshell | HPC@RRZE 10
11.
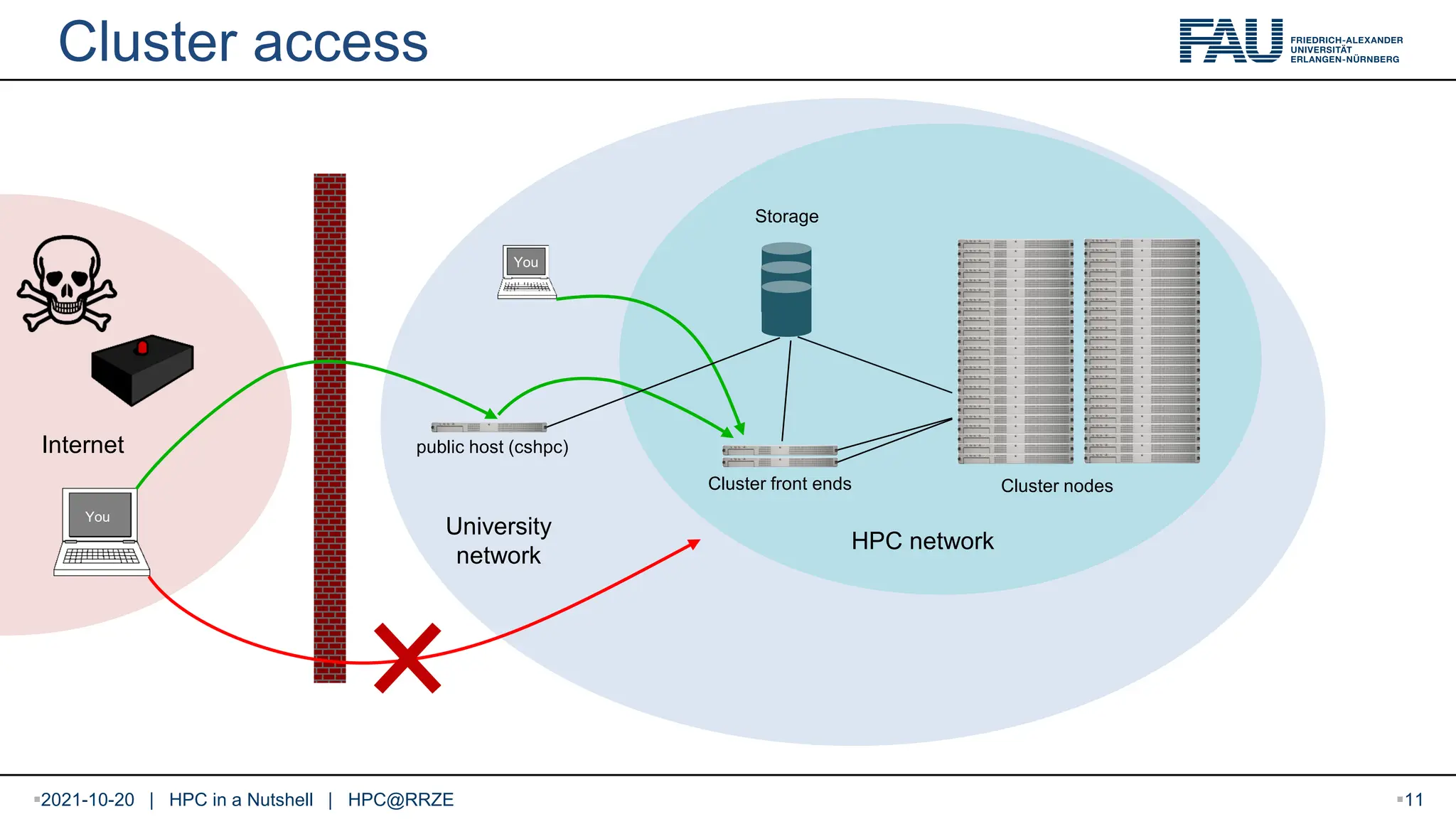
2021-10-20 | HPCin a Nutshell | HPC@RRZE Cluster access Internet University network Cluster nodes HPC network Cluster front ends Storage public host (cshpc) You You 11
12.
Cluster access Primarypoint of contact: cluster frontends woody.rrze.fau.de (also for TinyX) emmy.rrze.fau.de meggie.rrze.fau.de Only available from within FAU (private IP addresses) Access from outside FAU: dialog server cshpc.rrze.fau.de The only machine with a public IP address 2021-10-20 | HPC in a Nutshell | HPC@RRZE 12
13.
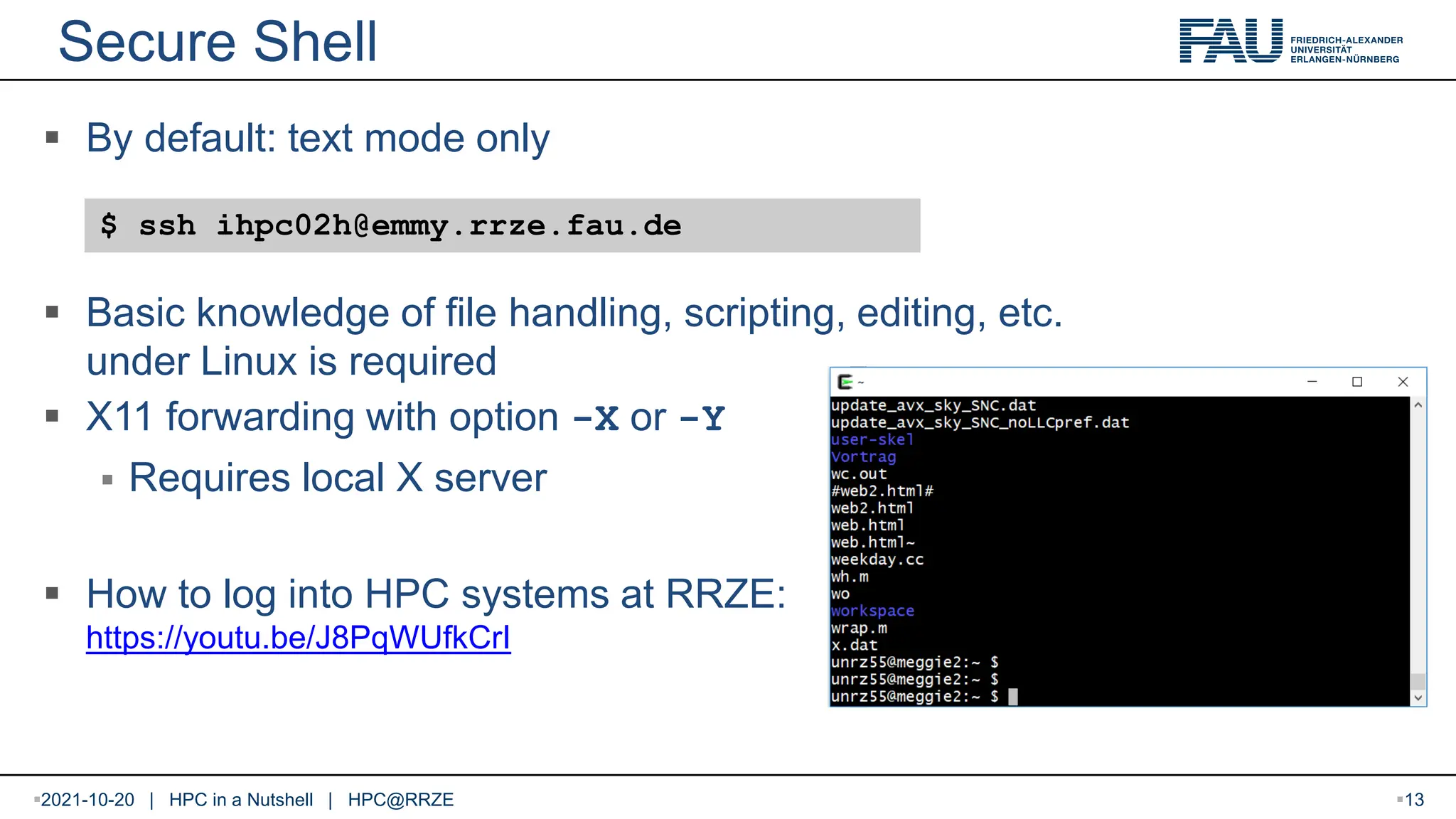
Secure Shell Bydefault: text mode only Basic knowledge of file handling, scripting, editing, etc. under Linux is required X11 forwarding with option -X or -Y Requires local X server How to log into HPC systems at RRZE: https://youtu.be/J8PqWUfkCrI $ ssh ihpc02h@emmy.rrze.fau.de 2021-10-20 | HPC in a Nutshell | HPC@RRZE 13
14.
Secure Shell clientprograms Linux: OpenSSH available in any distribution Mac: ditto Windows Putty (https://putty.org/) MobaXterm (https://mobaxterm.mobatek.net/) includes an embedded X server OpenSSH via Command/PowerShell Linux Subsystem for Windows WinSCP (data transfer only) (https://winscp.net) 2021-10-20 | HPC in a Nutshell | HPC@RRZE 14
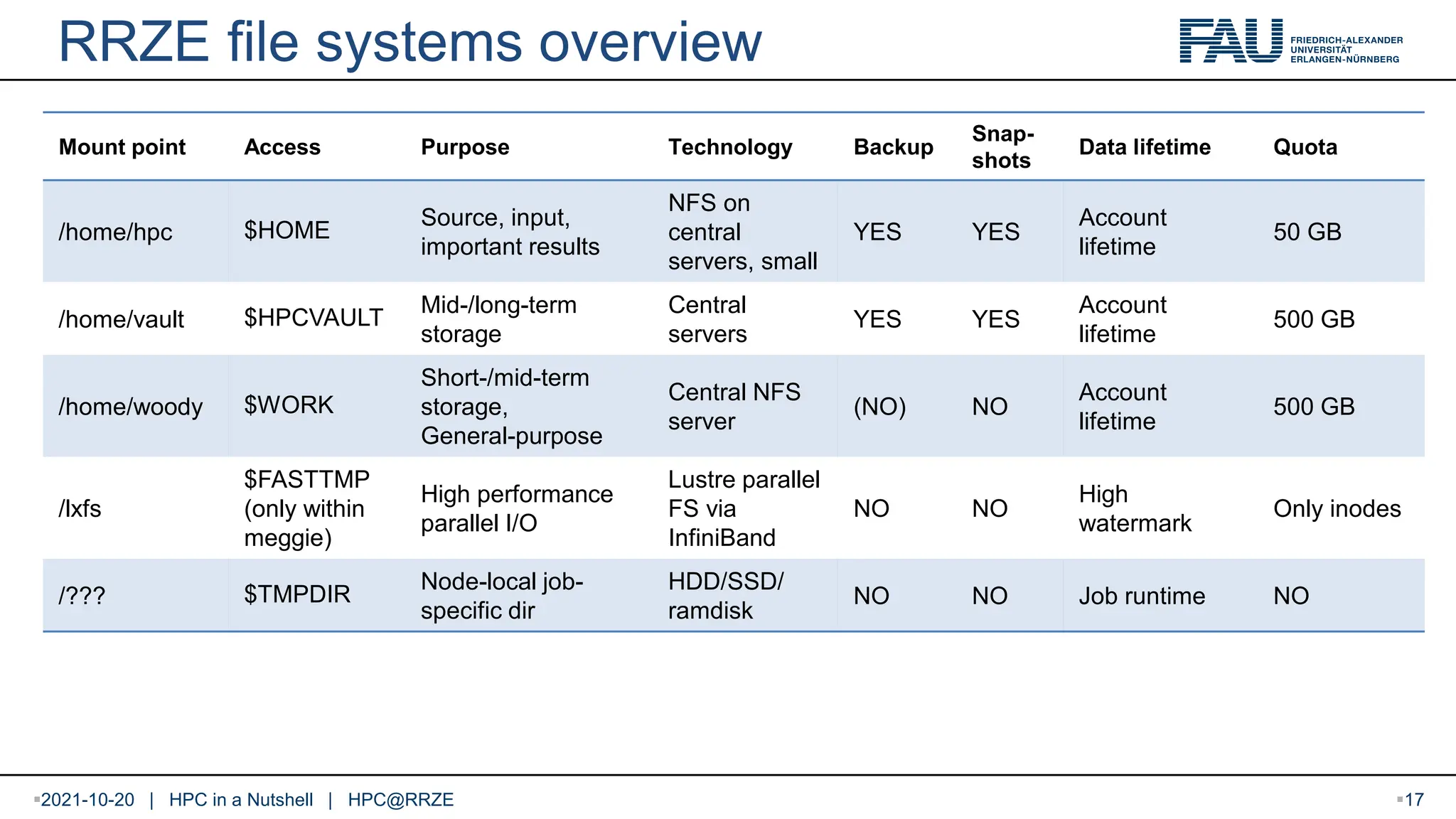
File systems Filesystem == directory structure that can store files Several file systems can be “mounted” at a compute node Similar to drive letters in Windows (C:, D:, …) Mount points can be anywhere in the root file system Available file systems differ in size, redundancy and how they should be used HPC Café on “Using file systems properly“ (especially for data-intensive applications): https://hpc.fau.de/files/2022/01/2022-01-11-hpc-cafe-file-systems.pdf https://www.fau.tv/clip/id/40199 2021-10-20 | HPC in a Nutshell | HPC@RRZE 16
17.
RRZE file systemsoverview Mount point Access Purpose Technology Backup Snap- shots Data lifetime Quota /home/hpc $HOME Source, input, important results NFS on central servers, small YES YES Account lifetime 50 GB /home/vault $HPCVAULT Mid-/long-term storage Central servers YES YES Account lifetime 500 GB /home/woody $WORK Short-/mid-term storage, General-purpose Central NFS server (NO) NO Account lifetime 500 GB /lxfs $FASTTMP (only within meggie) High performance parallel I/O Lustre parallel FS via InfiniBand NO NO High watermark Only inodes /??? $TMPDIR Node-local job- specific dir HDD/SSD/ ramdisk NO NO Job runtime NO 2021-10-20 | HPC in a Nutshell | HPC@RRZE 17
18.
File system quotas File system may impose quotas on Stored data volume Number of files and directories (inodes, actually) Quotas may be set per user or per group (or both) Hard quota Absolute upper limit, cannot be exceeded Soft quota May be exceeded temporarily (e.g., for 7 days – grace period) Turns into hard quota at end of grace period 2021-10-20 | HPC in a Nutshell | HPC@RRZE 18
19.
Displaying the quotalimits $ quota –s # generic command Disk quotas for user unrz55 (uid 12050): Filesystem blocks quota limit grace files quota limit grace 10.28.20.201:/hpcdatacloud/hpchome/shared 5544M 51200M 100G 72041 500k 1000k wnfs1.rrze.uni-erlangen.de:/srv/home 112G 318G 477G 199k 0 0 $ shownicerquota.pl # only on RRZE systems Path Used SoftQ HardQ Gracetime Filec FileQ FiHaQ FileGrace /home/hpc 5.7G 52.5G 104.9G N/A 72K 500K 1,000K N/A /home/woody 112G 333.0G 499.5G N/A 188K N/A 2021-10-20 | HPC in a Nutshell | HPC@RRZE 19
20.
Data transfer MostRRZE file systems are mounted at all HPC systems Exception: parallel FS and node-local storage No NFS mounting from or to systems outside of RRZE scp / rsync is the preferred file transfer tool from and to the outside Windows: https://winscp.net/ $ scp –r –p code unrz55@emmy.rrze.fau.de:/home/woody/unrz/unrz55 $ scp unrz55@emmy.rrze.fau.de:results/output.dat . Preserve time stamps and access modes Recurse into subdirectories 2021-10-20 | HPC in a Nutshell | HPC@RRZE 20
The modules system Linux standard distro packages available on frontends and to some extend on compute nodes, but might be outdated Software provided locally by RRZE via modules system Compilers, libraries, commercial and open software Installed on central server and available on all cluster nodes A package must be made available in the user’s environment to become usable Command: module All module commands affect the current shell only! 2021-10-20 | HPC in a Nutshell | HPC@RRZE 22
The module command Loada module: module load <modulename> Display loaded modules: module list $ module load intel64 $ icc –V Intel(R) C Intel(R) 64 Compiler for applications running on Intel(R) 64, Version 17.0.5.239 Build 20170817 Copyright (C) 1985-2017 Intel Corporation. All rights reserved. $ module list Currently Loaded Modulefiles: 1) torque/current 2) intelmpi/2017up04-intel 3) mkl/2017up05 4) intel64/17.0up05 2021-10-20 | HPC in a Nutshell | HPC@RRZE 24
25.
Module command summary CommandWhat it does module avail List available modules module whatis Shows over-verbose listing of all modules module list Shows which modules are currently loaded module load <pkg> Loads module pkg, i.e., adjusts environment module load <pkg>/<version> Loads specific version of pkg instead of default module unload <pkg> Undoes what the load command did module help <pkg> Shows a detailed description of pkg module show <pkg> Shows what environment variables pkg modifies and how https://hpc.fau.de/systems-services/systems-documentation-instructions/environment/#modules 2021-10-20 | HPC in a Nutshell | HPC@RRZE 25
26.
Using Python 2021-10-20 |HPC in a Nutshell | HPC@RRZE 26 Use anaconda modules instead of system installation Build packages in an interactive job on the target cluster (especially for GPUs) It might be necessary to configure a proxy to access external repositories Install packages via conda/pip with --user option Change default package installation path from $HOME to $WORK More details: https://hpc.fau.de/systems-services/systems-documentation-instructions/special- applications-and-tips-tricks/python-and-jupyter/ $ module avail python ------------ /apps/modules/modulefiles/tools ------------ python/2.7-anaconda python/3.6-anaconda python/3.7-anaconda(default) python/3.8-anaconda
Interactive work onthe front-ends The cluster frontends are for interactive work Editing, compiling, preparing input,… Amount of compute time per binary is limited by system limits E.g., after 1 hour of CPU time your process will be killed MPI jobs are not allowed on front ends at RRZE Front-ends are shared among all users, so be considerate! Submit computational intensive work to the batch system to be run on the compute nodes! Use interactive batch jobs for debugging and testing. 2021-10-20 | HPC in a Nutshell | HPC@RRZE 28
29.
Batch System Userscan interact with the resources of the cluster via the “Batch system” “Batch jobs” encapsulate: Resource requirements (number of nodes, number of GPUs, …) Job runtime (usually max. 24 hours) Setup of runtime environment Commands for application run Batch system will handle queuing of jobs, resource distribution and allocation Job will run when resources become available 2021-10-20 | HPC in a Nutshell | HPC@RRZE 29
2021-10-20 | HPCin a Nutshell | HPC@RRZE Example: Complex Slurm batch script #!/bin/bash -l #SBATCH --nodes=4 --ntasks-per-node=20 --time=06:00:00 #SBATCH --job-name=Sparsejob_33 #SBATCH --export=NONE unset SLURM_EXPORT_ENV # avoid login shell settings # create a temporary job dir on $WORK mkdir ${WORK}/$SLURM_JOB_ID cd ${WORK}/$SLURM_JOB_ID # copy input file from location where job was submitted, and run cp ${SLURM_SUBMIT_DIR}/inputfile . srun --mpi=pmi2 ${HOME}/bin/a.out -i inputfile -o outputfile Job submission options: Nodes, cores per node, time, name,… Job option sentinel $SLURM_* variables contain job-relevant data Actual run of your binary 31
32.
2021-10-20 | HPCin a Nutshell | HPC@RRZE Slurm batch job submission iww042@meggie1$ sbatch job3.sh Submitted batch job 357074 iww042@meggie1:~ $ squeue -l Mon Jan 28 17:38:52 2019 JOBID PARTITION NAME USER STATE TIME TIME_LIMI NODES NODELIST(REASON) 357074 work Sparsejo iww042 RUNNING 0:35 1:00:00 4 m[0101-0104] 32
33.
Jobs on TinyX Nearly all nodes use Slurm All jobs are submitted from the woody frontend via wrapper scripts (e.g. sbatch.tinygpu, sbatch.tinyfat) TinyGPU: nodes are shared, granularity is one GPU with a corresponding proportion of CPU and main memory Request a specific GPU type by e.g. sbatch.tinygpu --gres=gpu:1 […] (if you don‘t care which type you get) sbatch.tinygpu --gres=gpu:rtx3080:1 […] (to request a specific type) sbatch.tinygpu --gres=gpu:a100:1 --partition=a100 […] (necessary for V100 and A100 GPUs) More details and examples: https://hpc.fau.de/systems-services/systems-documentation-instructions/clusters/tinyfat-cluster https://hpc.fau.de/systems-services/systems-documentation-instructions/clusters/tinygpu-cluster 2021-10-20 | HPC in a Nutshell | HPC@RRZE 33
2021-10-20 | HPCin a Nutshell | HPC@RRZE Slurm user commands (non-exhaustive) Command Purpose Options sbatch [<options>] <job_script> Submit batch job --time=HH:MM:SS --nodes=# --ntasks=# --ntasks-per-node=# --mail-user=<address> --mail-type=ALL|BEGIN|END|... --partition=work|devel squeue [<options>] Check job status -j <JobID> show job -t RUNNING show only running jobs scancel <JobID> Delete batch job – srun <options> Run program Many options; see man page 35 https://hpc.fau.de/systems-services/systems-documentation-instructions/batch-processing/
36.
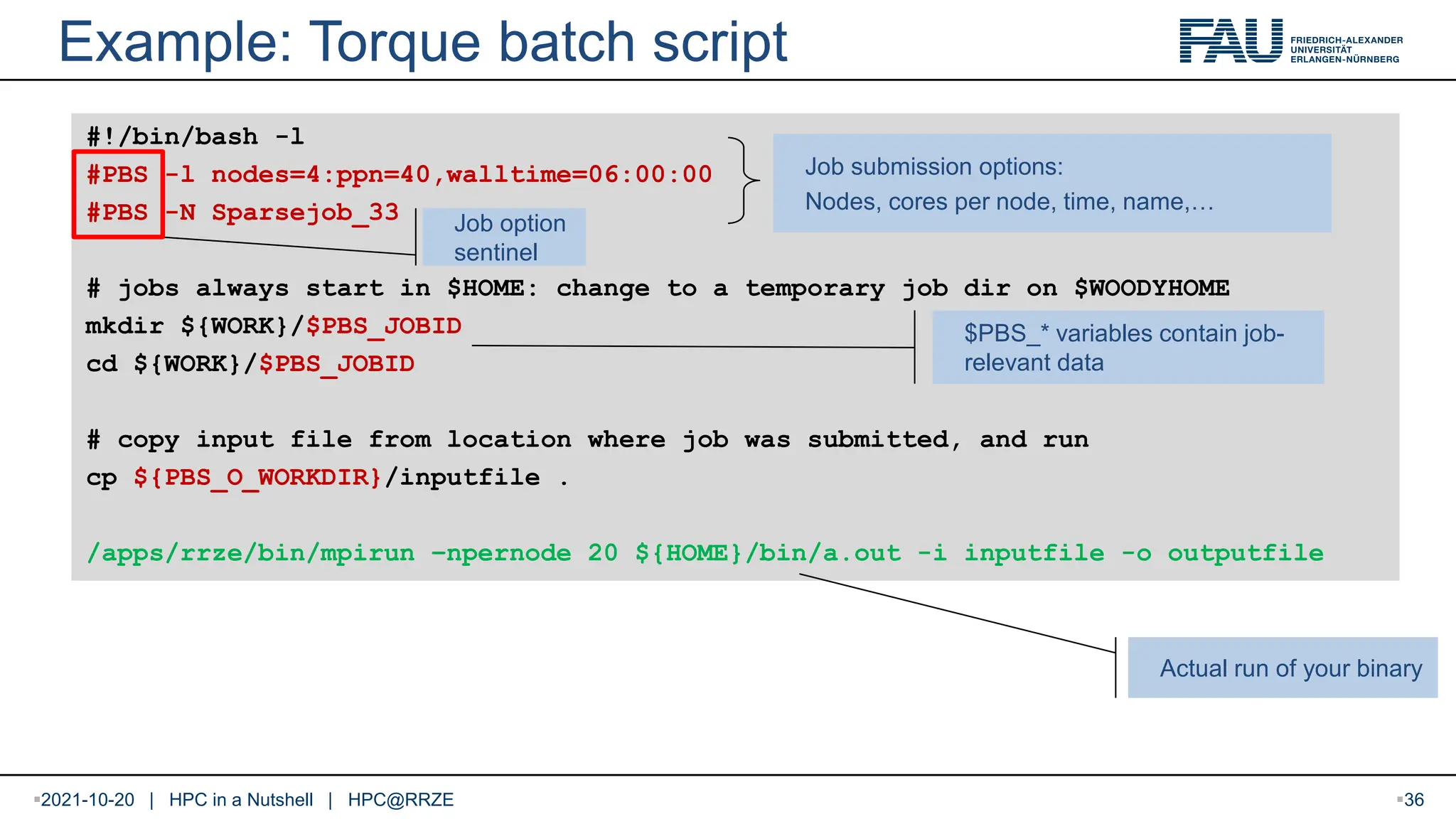
Example: Torque batchscript #!/bin/bash -l #PBS -l nodes=4:ppn=40,walltime=06:00:00 #PBS -N Sparsejob_33 # jobs always start in $HOME: change to a temporary job dir on $WOODYHOME mkdir ${WORK}/$PBS_JOBID cd ${WORK}/$PBS_JOBID # copy input file from location where job was submitted, and run cp ${PBS_O_WORKDIR}/inputfile . /apps/rrze/bin/mpirun –npernode 20 ${HOME}/bin/a.out -i inputfile -o outputfile Job submission options: Nodes, cores per node, time, name,… $PBS_* variables contain job- relevant data Actual run of your binary Job option sentinel 2021-10-20 | HPC in a Nutshell | HPC@RRZE 36
37.
Example: Managing aTorque job Job ID can be used to check and control the job later stdout/stderr will be in <JobName>.[o|e]<JobID> iww042@emmy1$ qsub job2.sh 1051342.eadm iww042@emmy1$ qstat –a eadm: Req'd Req'd Elap Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time ----------------------- ----------- -------- ---------------- ------ ----- ------ ------ --------- - --------- 1051342.eadm iww042 devel test.sh -- 1 40 -- 00:10:00 R 00:00:02 iww042@emmy1$ qalter –l walltime=02:00:00 1051342 iww042@emmy1$ qdel 1051342 2021-10-20 | HPC in a Nutshell | HPC@RRZE 37
38.
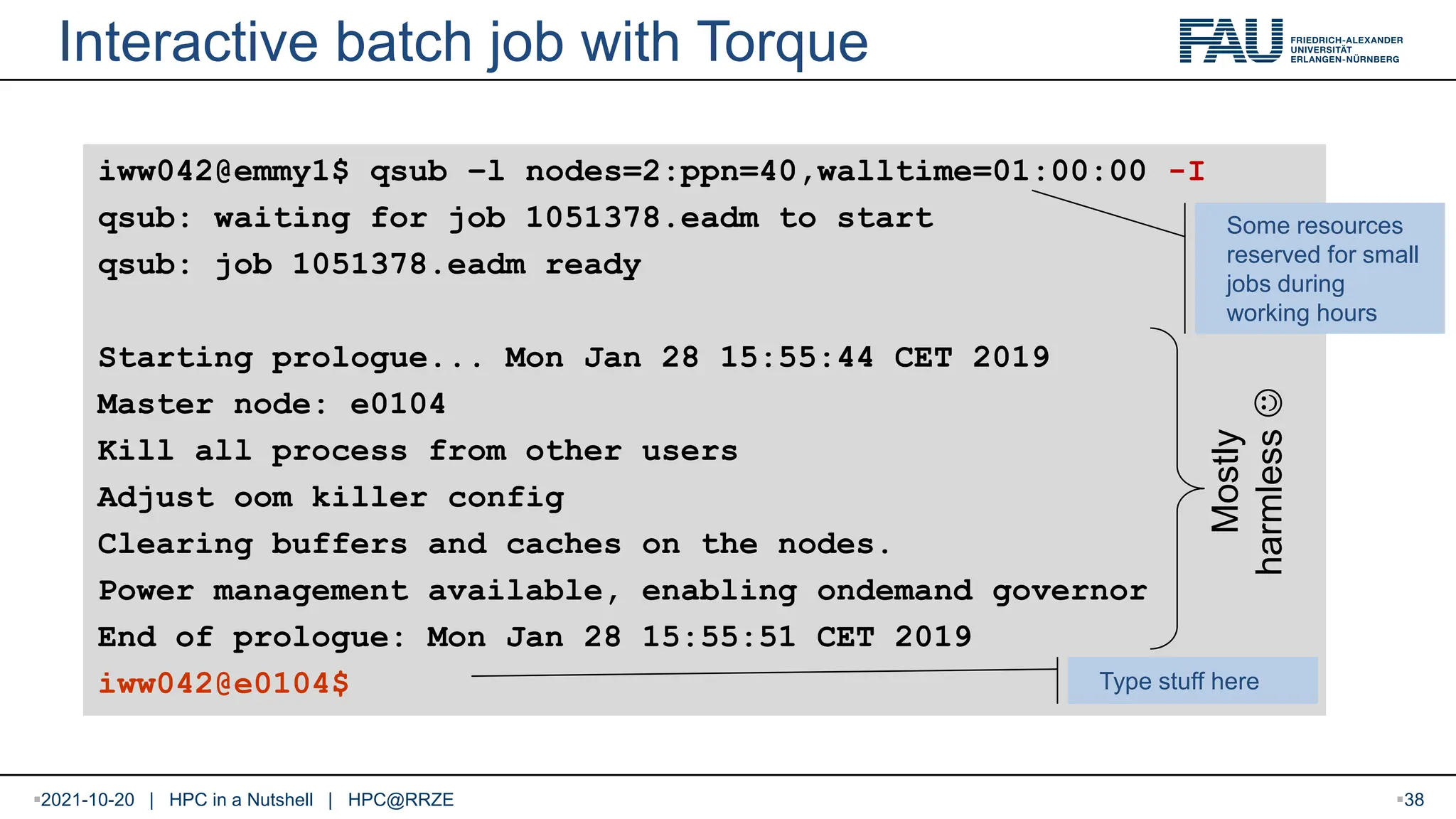
Interactive batch jobwith Torque iww042@emmy1$ qsub –l nodes=2:ppn=40,walltime=01:00:00 -I qsub: waiting for job 1051378.eadm to start qsub: job 1051378.eadm ready Starting prologue... Mon Jan 28 15:55:44 CET 2019 Master node: e0104 Kill all process from other users Adjust oom killer config Clearing buffers and caches on the nodes. Power management available, enabling ondemand governor End of prologue: Mon Jan 28 15:55:51 CET 2019 iww042@e0104$ Type stuff here Mostly harmless Some resources reserved for small jobs during working hours 2021-10-20 | HPC in a Nutshell | HPC@RRZE 38
39.
Torque user commands(non-exhaustive) Command Purpose Options qsub [<options>] [-I|<job_script>] Submit batch job (-I = interactive) -l <resource_spec> -N <JobName> -o <stdout_filename> -e <stderr_filename> -M your@email.de –m abe -X X11 fowarding qstat [<options>] [<JobID>|<queue>] Check job status -a friendly formatting -f verbose job info -r only running jobs -n show nodes of each job qdel <JobID> Delete batch job – 2021-10-20 | HPC in a Nutshell | HPC@RRZE 39
Good practices Beconsiderate. Clusters are valuable shared resources that have been paid by the taxpayer. Use the appropriate amount of parallelism Most workloads are not highly scalable Best to run scaling experiments to figure out “sweet spot” Use the appropriate file system(s) #1 mistake: Overload metadata servers by doing tiny-size, high-frequency I/O to parallel FS Delete obsolete data 2021-10-20 | HPC in a Nutshell | HPC@RRZE 41
42.
Good practices Checkyour jobs regularly Are the results OK? Does the job actually use the allocated nodes in the intended way? Does it run with the expected performance? Check if your job makes use of the GPUs Use ssh to log into a node where you have a job running Use e.g. nvidia-smi to check GPU utilization For pytorch/tensorflow, check if GPUs are detected https://hpc.fau.de/systems-services/systems-documentation-instructions/special-applications-and-tips-tricks/tensorflow- pytorch/ Job Monitoring: https://www.hpc.rrze.fau.de/HPC-Status/job-info.php How to use it and what to look out for: https://hpc.fau.de/files/2019/11/2019-11-2_HPC_Cafe_monitoring.pdf 2021-10-20 | HPC in a Nutshell | HPC@RRZE 42
43.
Good practices Talkto co-workers who are more experienced cluster users; let them educate you Do not re-use other people’s job scripts if you don’t understand them completely Look at tips and tricks for various applications (e.g. example batch scripts): https://hpc.fau.de/systems-services/systems-documentation-instructions/special-applications- and-tips-tricks/ 2021-10-20 | HPC in a Nutshell | HPC@RRZE 43
44.
Good practices When reportinga problem to RRZE: Use the official contact hpc-support@fau.de – this will immediately open a helpdesk ticket Provide as much detail as possible so we know where to look “My jobs always crash” will not do Cluster, JobID, file system, time of event, … Batch script, output files, … 2021-10-20 | HPC in a Nutshell | HPC@RRZE 44


























![2021-10-20 | HPC in a Nutshell | HPC@RRZE Slurm batch job submission iww042@meggie1$ sbatch job3.sh Submitted batch job 357074 iww042@meggie1:~ $ squeue -l Mon Jan 28 17:38:52 2019 JOBID PARTITION NAME USER STATE TIME TIME_LIMI NODES NODELIST(REASON) 357074 work Sparsejo iww042 RUNNING 0:35 1:00:00 4 m[0101-0104] 32](https://image.slidesharecdn.com/2022-03-23hpcinanutshellonline-250615133333-b205571b/75/High-Performance-Computing-in-a-Nutshell-32-2048.jpg)
![Jobs on TinyX Nearly all nodes use Slurm All jobs are submitted from the woody frontend via wrapper scripts (e.g. sbatch.tinygpu, sbatch.tinyfat) TinyGPU: nodes are shared, granularity is one GPU with a corresponding proportion of CPU and main memory Request a specific GPU type by e.g. sbatch.tinygpu --gres=gpu:1 […] (if you don‘t care which type you get) sbatch.tinygpu --gres=gpu:rtx3080:1 […] (to request a specific type) sbatch.tinygpu --gres=gpu:a100:1 --partition=a100 […] (necessary for V100 and A100 GPUs) More details and examples: https://hpc.fau.de/systems-services/systems-documentation-instructions/clusters/tinyfat-cluster https://hpc.fau.de/systems-services/systems-documentation-instructions/clusters/tinygpu-cluster 2021-10-20 | HPC in a Nutshell | HPC@RRZE 33](https://image.slidesharecdn.com/2022-03-23hpcinanutshellonline-250615133333-b205571b/75/High-Performance-Computing-in-a-Nutshell-33-2048.jpg)

![2021-10-20 | HPC in a Nutshell | HPC@RRZE Slurm user commands (non-exhaustive) Command Purpose Options sbatch [<options>] <job_script> Submit batch job --time=HH:MM:SS --nodes=# --ntasks=# --ntasks-per-node=# --mail-user=<address> --mail-type=ALL|BEGIN|END|... --partition=work|devel squeue [<options>] Check job status -j <JobID> show job -t RUNNING show only running jobs scancel <JobID> Delete batch job – srun <options> Run program Many options; see man page 35 https://hpc.fau.de/systems-services/systems-documentation-instructions/batch-processing/](https://image.slidesharecdn.com/2022-03-23hpcinanutshellonline-250615133333-b205571b/75/High-Performance-Computing-in-a-Nutshell-35-2048.jpg)
![Example: Managing a Torque job Job ID can be used to check and control the job later stdout/stderr will be in <JobName>.[o|e]<JobID> iww042@emmy1$ qsub job2.sh 1051342.eadm iww042@emmy1$ qstat –a eadm: Req'd Req'd Elap Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time ----------------------- ----------- -------- ---------------- ------ ----- ------ ------ --------- - --------- 1051342.eadm iww042 devel test.sh -- 1 40 -- 00:10:00 R 00:00:02 iww042@emmy1$ qalter –l walltime=02:00:00 1051342 iww042@emmy1$ qdel 1051342 2021-10-20 | HPC in a Nutshell | HPC@RRZE 37](https://image.slidesharecdn.com/2022-03-23hpcinanutshellonline-250615133333-b205571b/75/High-Performance-Computing-in-a-Nutshell-37-2048.jpg)
![Torque user commands (non-exhaustive) Command Purpose Options qsub [<options>] [-I|<job_script>] Submit batch job (-I = interactive) -l <resource_spec> -N <JobName> -o <stdout_filename> -e <stderr_filename> -M your@email.de –m abe -X X11 fowarding qstat [<options>] [<JobID>|<queue>] Check job status -a friendly formatting -f verbose job info -r only running jobs -n show nodes of each job qdel <JobID> Delete batch job – 2021-10-20 | HPC in a Nutshell | HPC@RRZE 39](https://image.slidesharecdn.com/2022-03-23hpcinanutshellonline-250615133333-b205571b/75/High-Performance-Computing-in-a-Nutshell-39-2048.jpg)





