Relational and Non Relational Databases • Whatis a database • A database is an organised collection of information, nowadays commonly stored electronically in a computer system. It is usually controlled by a Database Management system(DBMS), which along with the application associated with it, forms a database system.
3.
What is a Database? •Database: A very large collection (of files) of related data • Examples: Accounts in a bank, UG students database, Airline reservations… also, facebook pictures and comments, web logs, etc… • Models a real world enterprise: • Entities (e.g., teams, games / students, courses) • Relationships (e.g., student takes CS460) • Even active components (e.g. “business logic”) • .
4.
What is a DataBase Manageme nt System? • Data Base Management System (DBMS): A software package/system that can be used to store, manage and retrieve data from databases that persist for long periods of time! • Examples: Oracle, IBM DB2, MS SQLServer, MySQL, PostgreSQL, SQLite,… • Database System: DBMS+data (+ applications
5.
Why Databases • Databases aredesigned for easy access, management and updating of data, and they can contain various types of data : including words, numbers, images, videos and files. • Companies use databases including Cloud databases, for a multitude of purposes, such as: • Storing and Managing data • Improving Business processes • Tracking Customers • Supporting Internal Operations • Data Analysis • Data Security
6.
Why Study Databases?? •Shift from computation to data (information) • Always true for corporate computing • More and more true in the scientific world • and of course, Web • New trend: social media generate ever increasing amount of data, sensor devices generate also huge datasets • DBMS encompasses much of CS in a practical discipline • OS, languages, theory, AI, logic
7.
Why Databases?? • Whynot store everything on flat files: use the file system of the OS, cheap/simple… Name, Course, Grade John Smith, CS112, B Mike Stonebraker, CS234, A Jim Gray, CS560, A John Smith, CS560, B+ ………………… • Yes, but has many problems…
8.
Problem 1 • DataOrganization • redundancy and inconsistency • Multiple file formats, duplication of information in different files Name, Course, Email, Grade John Smith, js@cs.bu.edu, CS112, B Mike Stonebraker, ms@cs.bu.edu, CS234, A Jim Gray, CS560, jg@cs.bu.edu, A John Smith, CS560, js@cs.bu.edu, B+ Why this is a problem? • Wasted space • Potential inconsistencies (multiple formats, John Smith vs Smith J.)
9.
Problem 2 • Dataretrieval: • Find the students registered for CS460 • Find the students with GPA > 3.5 For every query we need to write a program! • We need the retrieval to be: • Easy to write • Execute efficiently
10.
Problem 3 • DataIntegrity • No support for sharing: • Prevent simultaneous modifications • No coping mechanisms for system crashes • No means of Preventing Data Entry Errors (checks must be hard-coded in the programs) • Security problems • Database systems offer solutions to all the above problems
11.
What is a Relational Database (SQL Database) •A relational database organises data into tables, which are made up of rows and colums • Each row in the table represents a unique record and each column represents a specific attribute of the data. • The key feature of a relational database is the ability to create relationships between these tables, allowing data to be linked and organised in a structured manner. • The relationships in a relational database are established using Keys. A primary key is a unique identifier for a record in a table, while a foreign key is a field in a table that matches the primary key of another table. • These keys enable the creation of relationships between tables. • These keys can be one-to-one, one-to-many, many-to-one or many-to-many.
12.
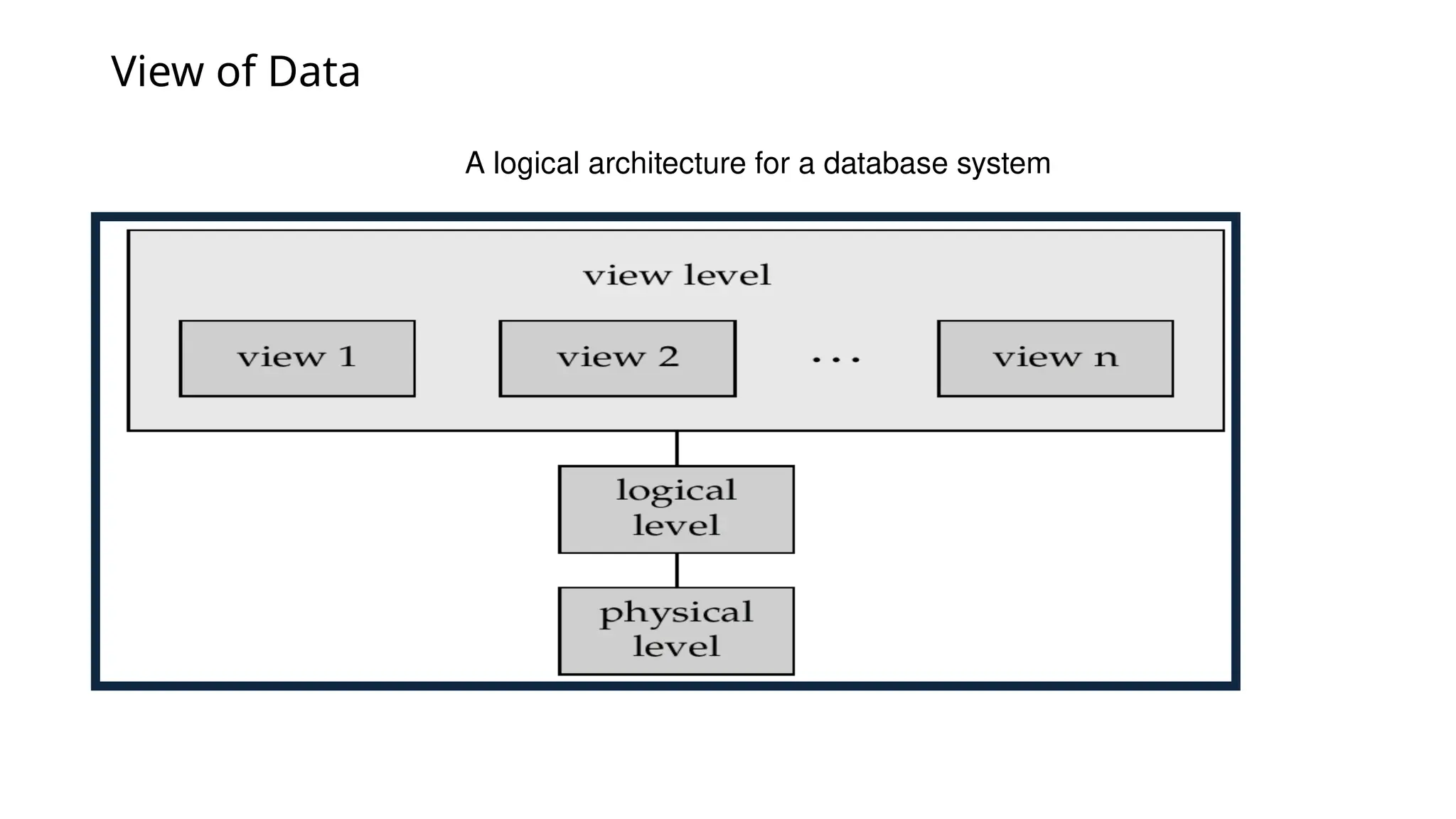
Data Organization • Twolevels of data modeling • Conceptual or Logical level: describes data stored in database, and the relationships among the data. type customer = record name : string; street : string; city : integer; end; • Physical level: describes how a record (e.g., customer) is stored. • Also, External (View) level: application programs hide details of data types. Views can also hide information (e.g., salary) for security purposes.
13.
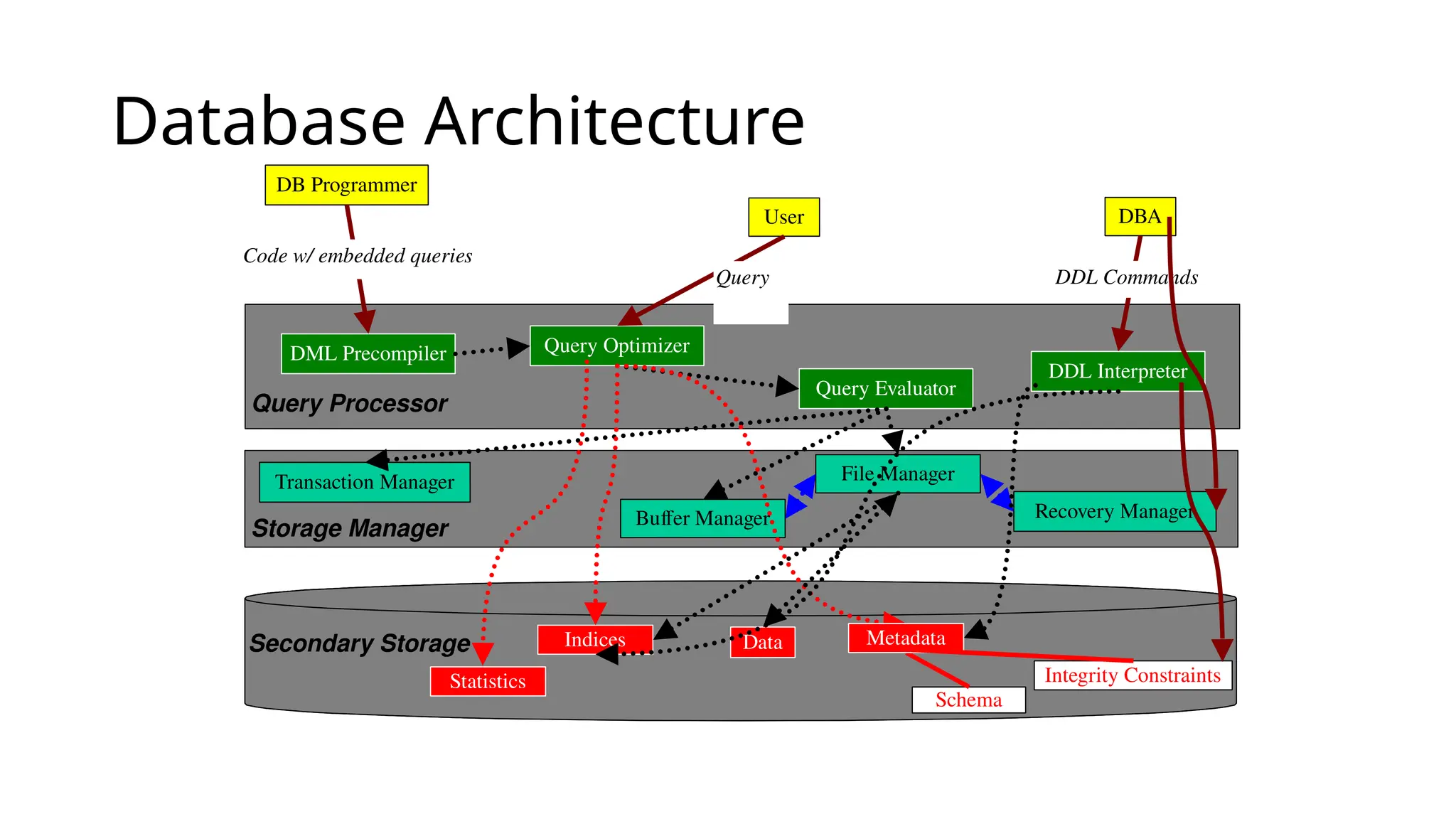
View of Data Alogical architecture for a database system
14.
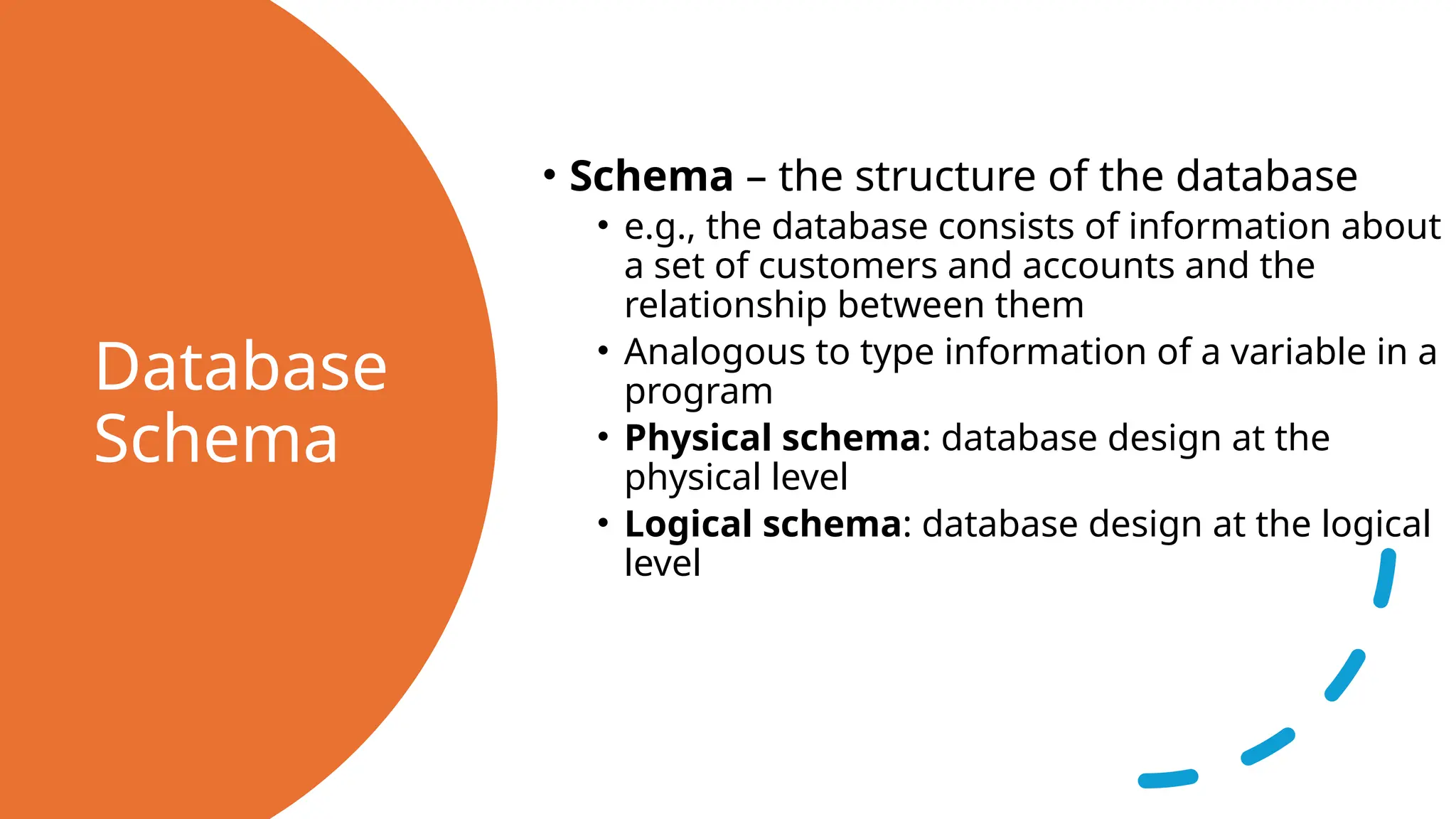
Database Schema • Schema –the structure of the database • e.g., the database consists of information about a set of customers and accounts and the relationship between them • Analogous to type information of a variable in a program • Physical schema: database design at the physical level • Logical schema: database design at the logical level
15.
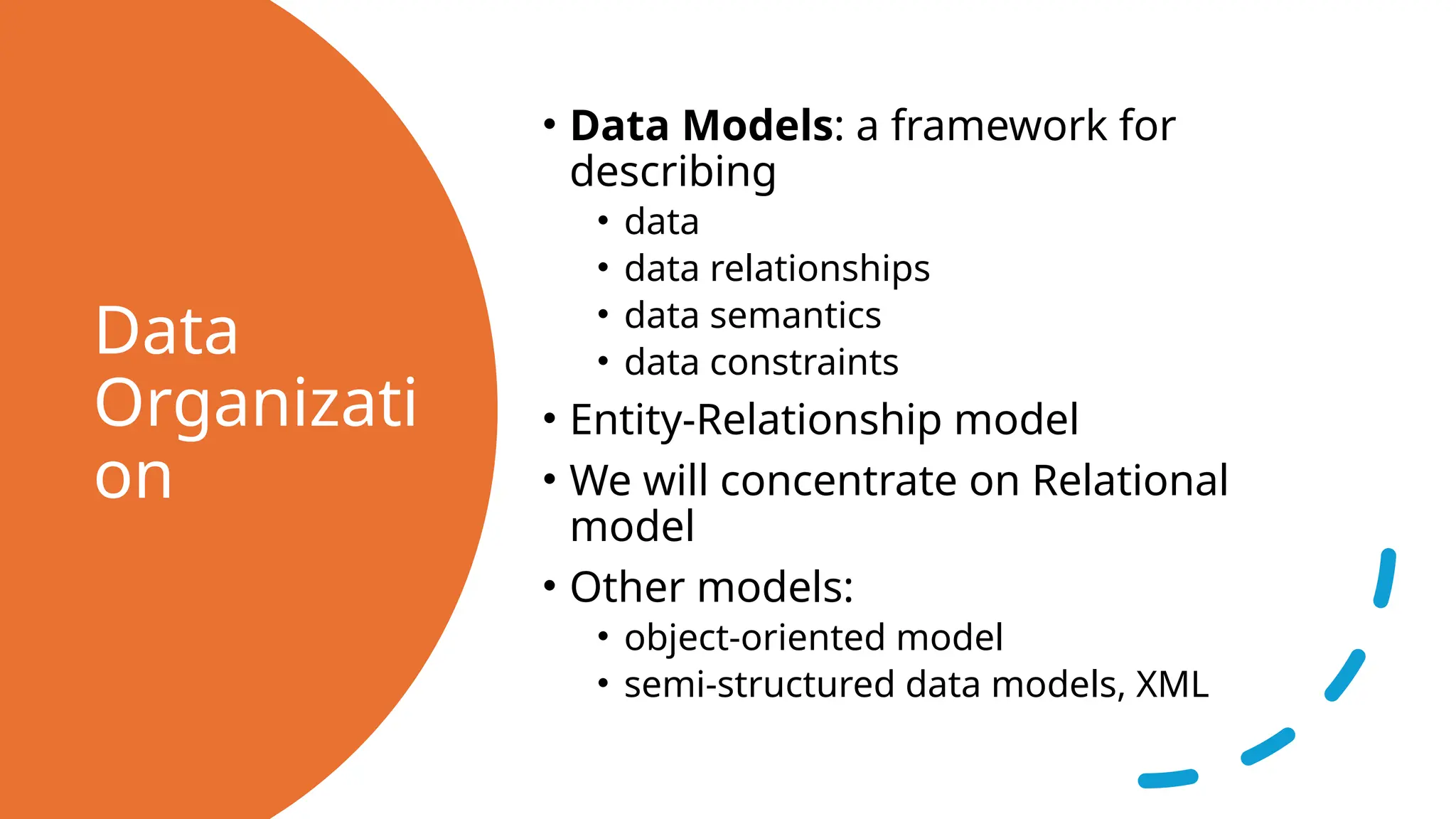
Data Organizati on • Data Models:a framework for describing • data • data relationships • data semantics • data constraints • Entity-Relationship model • We will concentrate on Relational model • Other models: • object-oriented model • semi-structured data models, XML
16.
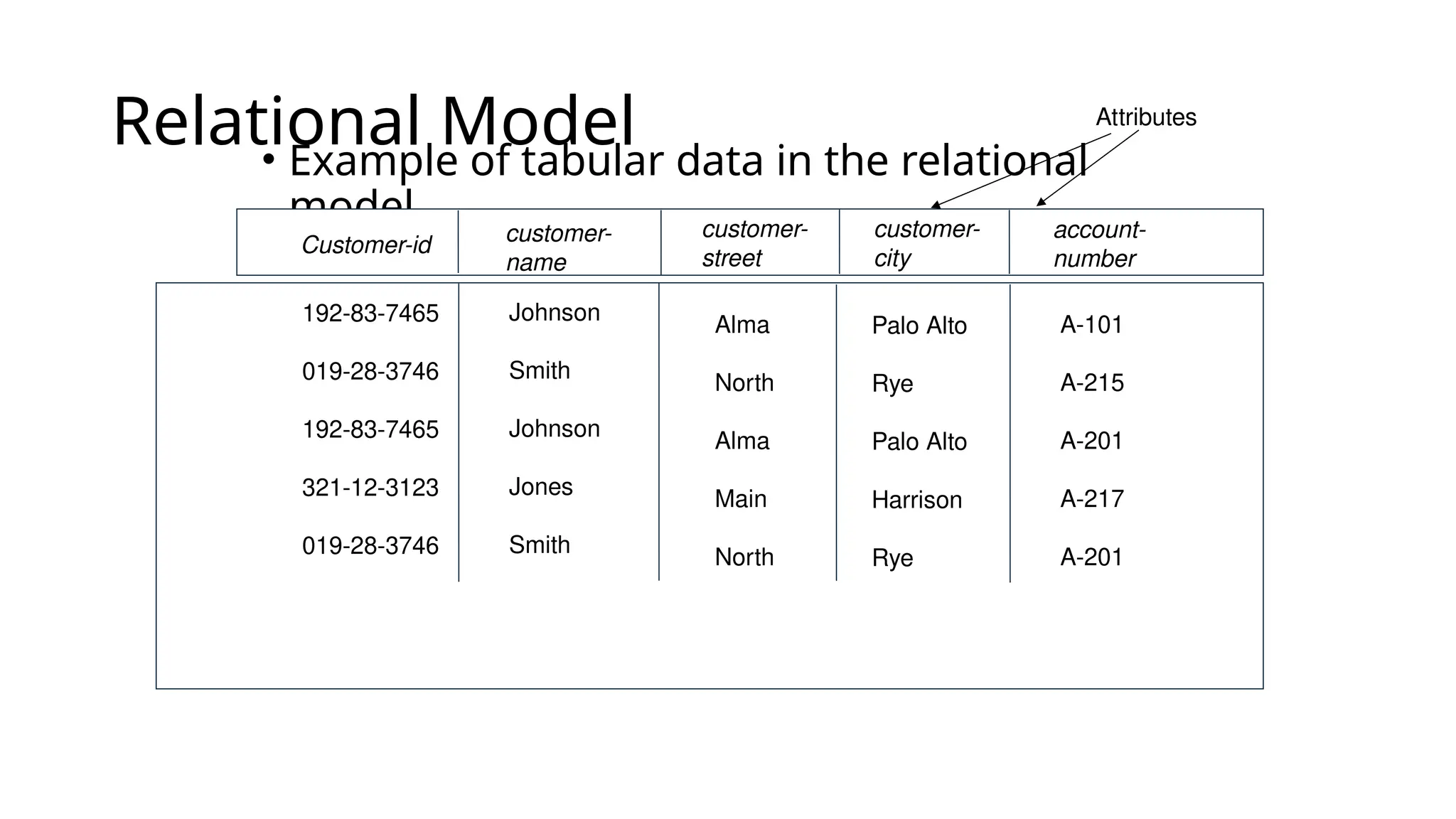
Relational Model • Exampleof tabular data in the relational model customer- name Customer-id customer- street customer- city account- number Johnson Smith Johnson Jones Smith 192-83-7465 019-28-3746 192-83-7465 321-12-3123 019-28-3746 Alma North Alma Main North Palo Alto Rye Palo Alto Harrison Rye A-101 A-215 A-201 A-217 A-201 Attributes
17.
Data Organizati on • Data Storage Wherecan data be stored? • Main memory • Secondary memory (hard disks) • Optical storage (DVDs) • Tertiary store (tapes) • Move data? Determined by buffer manager • Mapping data to files? Determined by file manager
18.
Data Retrieval • Queries Query =Declarative data retrieval describes what data, not how to retrieve it Ex. Give me the students with GPA > 3.5 vs Scan the student file and retrieve the records with gpa>3.5 • Why? 1. Easier to write 2. Efficient to execute (why?)
19.
SQL • all accountsheld by the customer with customer-id 192-83-7465 select account.balance from depositor, account where deSQL: widely used (declarative) non-procedural language • E.g. find the name of the customer with customer- id 192-83-7465 select customer.customer-name from customer where customer.customer-id = ‘192-83-7465’ • E.g. find the balances of positor.customer-id = ‘192- 83-7465’ and depositor.account-number = account.account-number • Procedural languages: C++, Java, relational algebra
20.
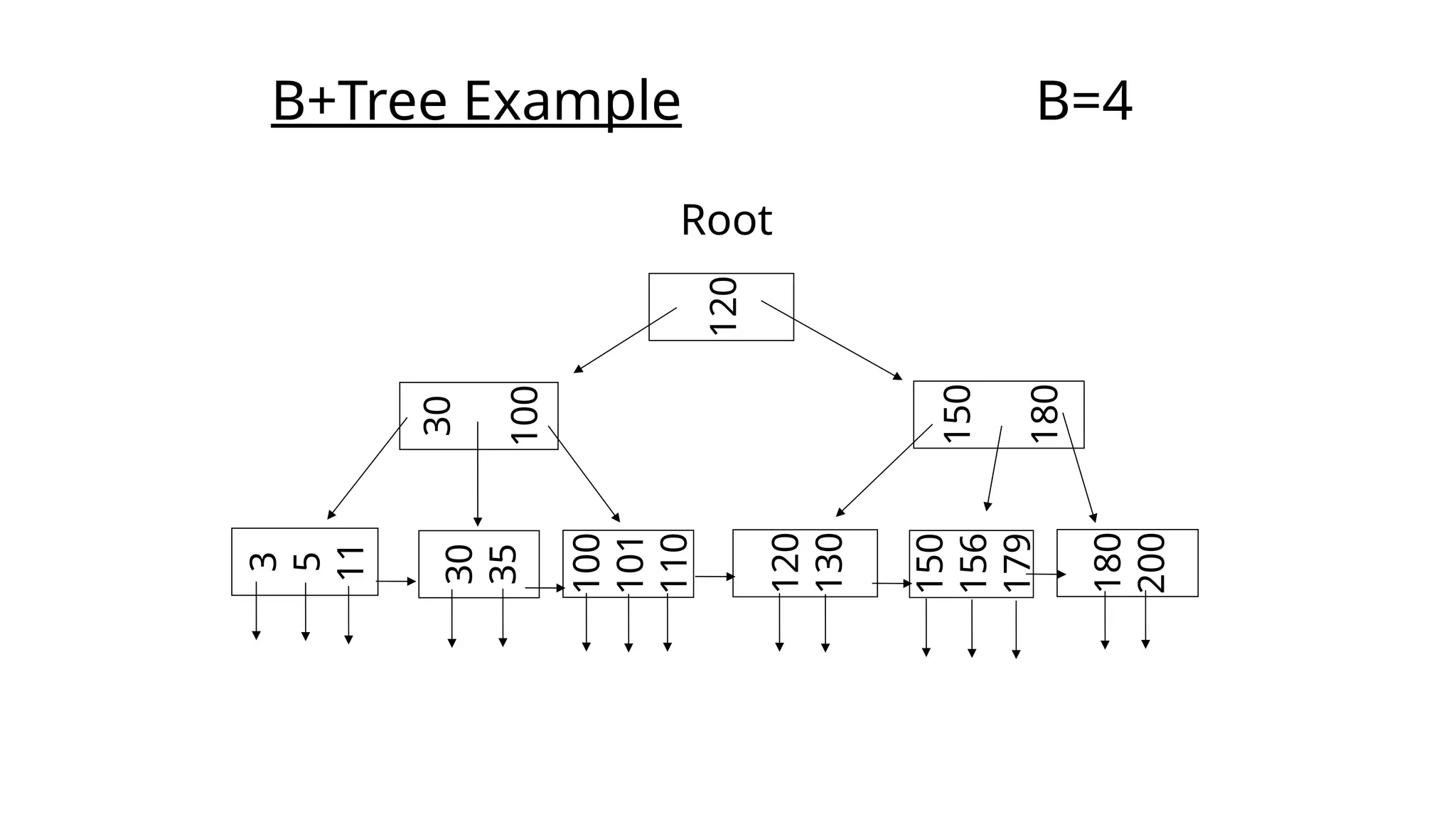
Data retrieval: Indexing • Howto answer fast the query: “Find the student with SID = 101”? • One approach is to scan the student table, check every student, return the one with id=101… very slow for large databases • Any better idea? 1st keep student record over the SID. Do a binary search…. Updates… 2nd Use a dynamic search tree!! Allow insertions, deletions, updates and at the same time keep the records sorted! In databases we use the B+-tree (multiway search tree) 3rd Use a hash table. Much faster for exact match queries… but cannot support Range queries. (Also, special hashing schemes are needed for dynamic data)
Data Integrity Transaction processing •Why Concurrent Access to Data must be Managed? John and Jane withdraw $50 and $100 from a common account… Initial balance $300. Final balance=? It depends… John: 1. get balance 2. if balance > $50 3. balance = balance - $50 4. update balance Jane: 1. get balance 2. if balance > $100 3. balance = balance - $100 4. update balance
23.
Data Integrity Recovery Transfer $50from account A ($100) to account B ($200) 1. get balance for A 2. If balanceA > $50 3. balanceA = balanceA – 50 4.Update balanceA in database 5. Get balance for B 6. balanceB = balanceB + 50 7. Update balanceB in database System crashes…. Recovery management
Big Data and NoSQL •Large amount of data are collected and stored everyday • Can come from different sources, huge amounts, large update rates • Examples: facebook needs to handle: 2.7 billion “likes”, 400 million images, 500+ TB per day!!, Google receives more than 1 billion queries per day! • Question: How to utilize these datasets in order to help us on our goals: • Data Analytics: Try to analyze the data in order to find useful, unknown and actionable information in the data • Cluster based data analytics: • Map-Reduce, shared nothing DBs • NoSQL: trade something for improved performance • (usually: ACID properties, flexibility, functionality)
So far Wehave concentrated on relational databases • Proposed by Ted Codd in 1969 • Developed by IBM for System R in the early 1970s • blahblah SQL blahblah Ingres blahblah Oracle blahblah etc What came before relational databases? What can we learn from those systems? What are the modern equivalents to those systems?
IBM Information ManagementSystem Development started in 1966 to support the Apollo programme • Originally IBM Information Control System and Data Language/Interface (ICS/DL/I) • Used to track the bill of materials for the Saturn V and the CSM Best known example of a hierarchical database • Still in use! • Fast on common tasks that change infrequently – complements DB2 (IBM’s relational database)
30.
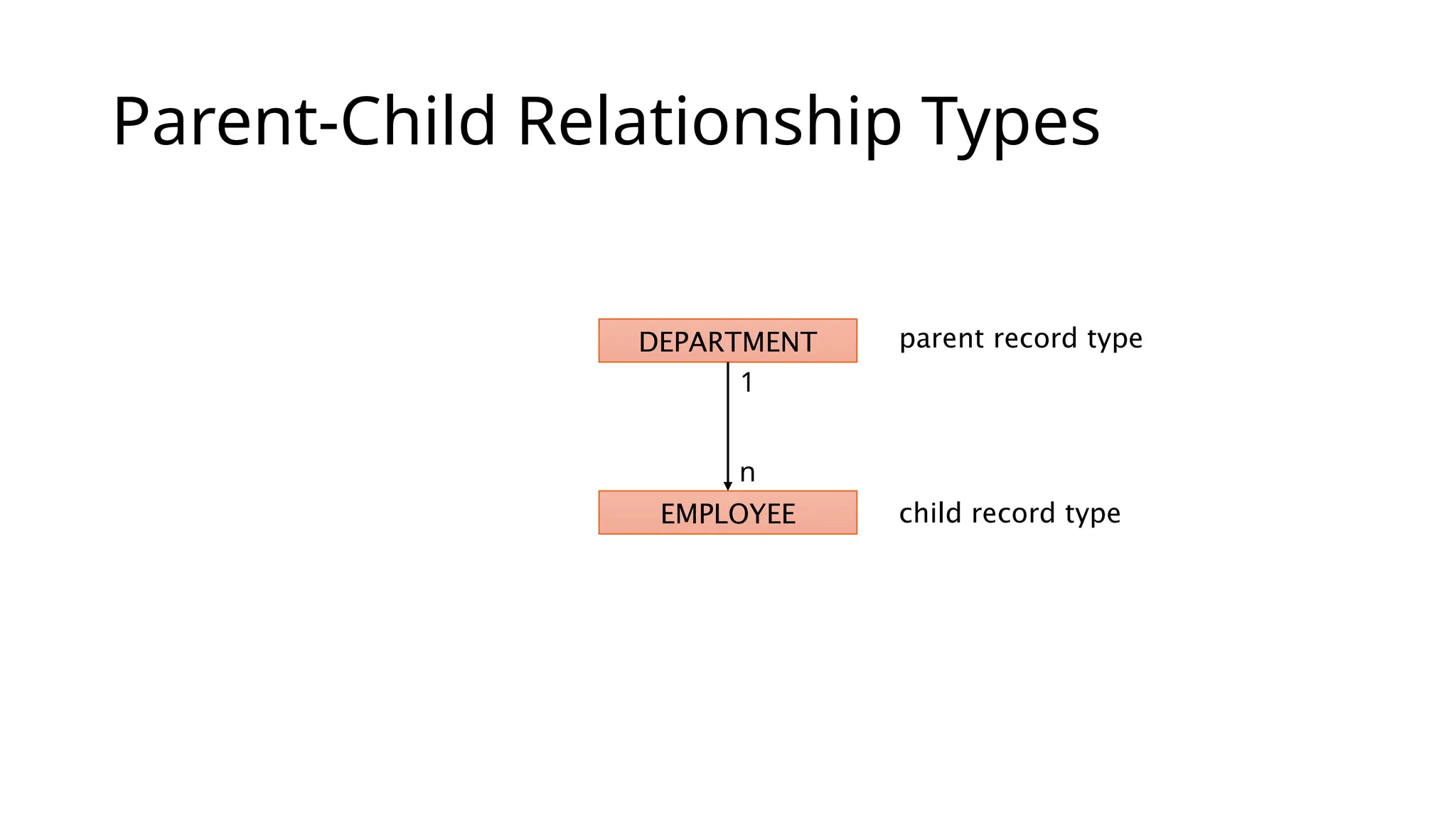
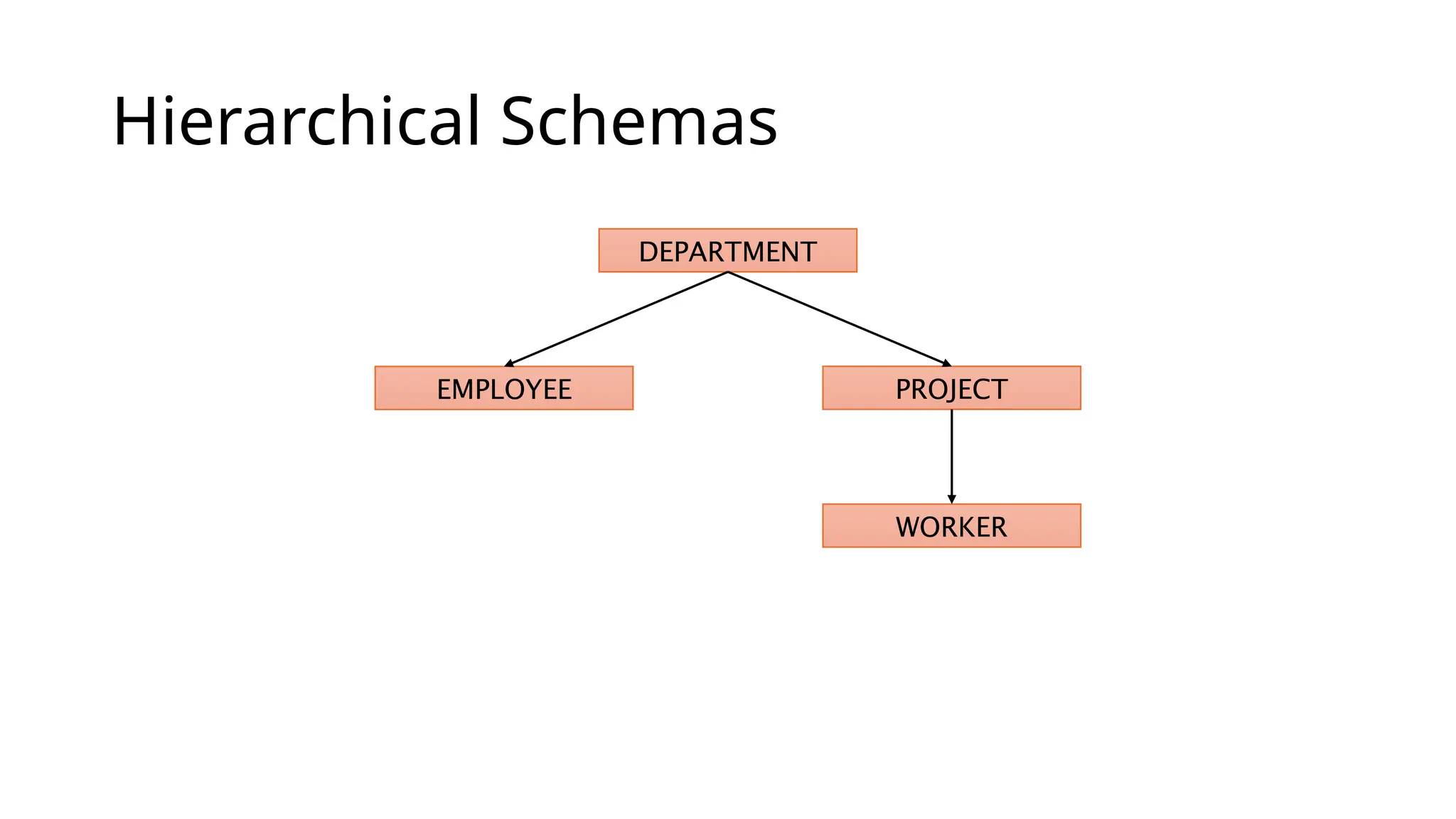
Hierarchical Databases A hierarchyis a natural way to model many real world systems • Taxonomy (“is a kind of”) • Meronymy (“is a part of”) Many real-world examples • Organisation charts • Library classification systems • Biological taxonomies • Components of manufactures Hierarchical DBs are built as trees of related record types connected by parent-child relationships
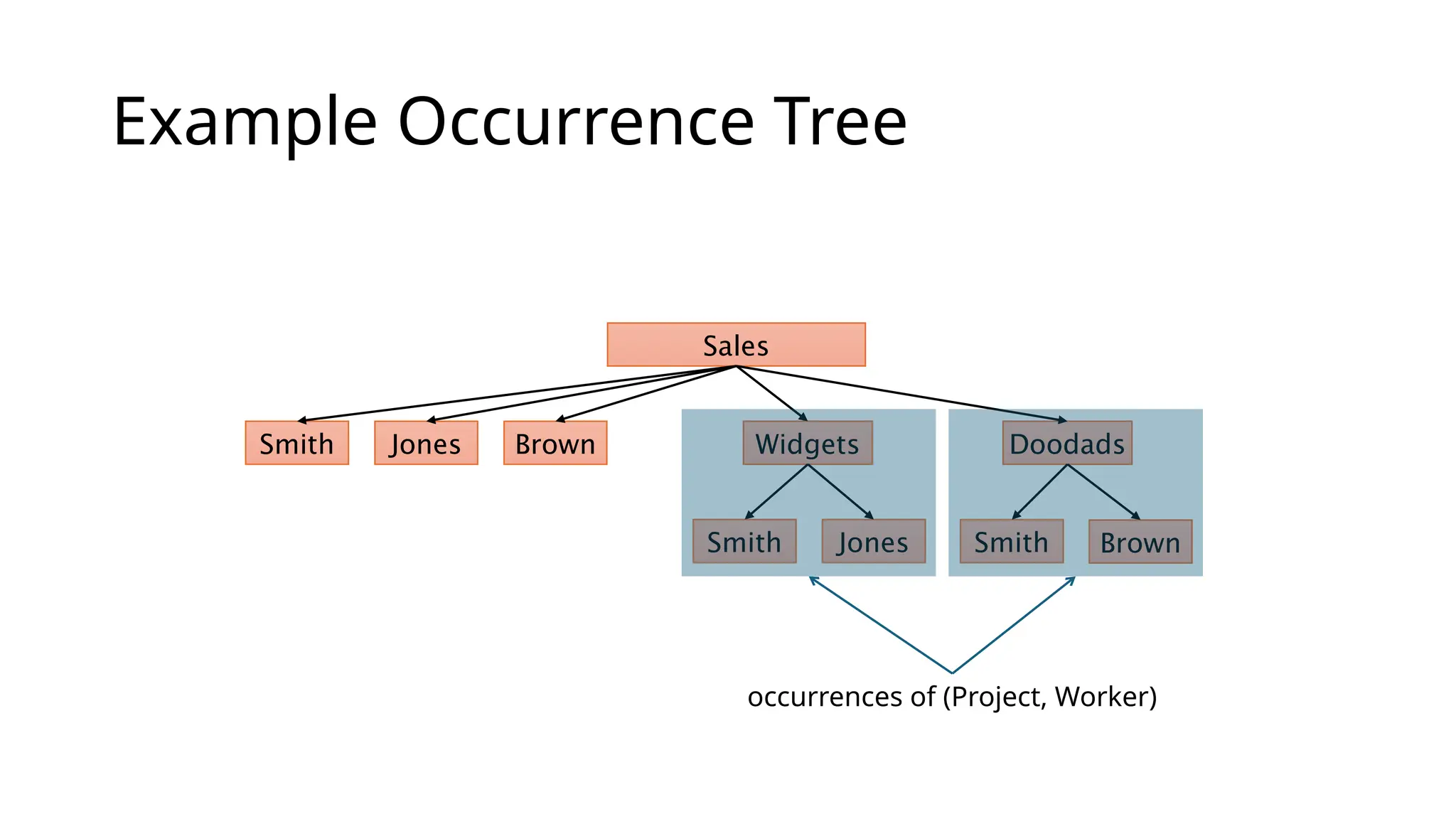
Occurrences An occurrence orinstance of the PCR type consists of: • One record of the parent record type • Zero or more records of the child record type • (i.e. an instance is a record and all its children) PCR types are referred to by naming the parent record type and child record type • e.g. (Department, Employee) A database may contain many hierarchical occurrences (occurrence trees) • Each occurrence tree is a tree structure whose root is a single record from the root record type of the schema • The occurrence tree contains all the children (and further descendants) of the root record, all the way to records of the leaf record types
Issues • Multiple parents(M:N relationships) are not supported – strict hierarchy • Can’t represent an employee that works in more than one department • Record type can't be involved in more than one PCR as child • Can't have both (DEPARTMENT, EMPLOYEE) and (PROJECT, EMPLOYEE) • N-ary relationships (between more than two record types) are not supported • Querying/update requires the programmer to explicitly navigate the hierarchy • Poor data independence
Network Databases • Standardisedin 1969 by the Conference on Data Systems Languages (CODASYL) • Addresses limitations of the hierarchical model • Entities may be related to any number of other entities – no longer limited to a tree • CA IDMS possibly the best-known example • Again, many instances still running worldwide
38.
Using Network Databases •Record types linked in 1:N relationships • There are no constraints on the number and direction of links between record types • No need for a root record type
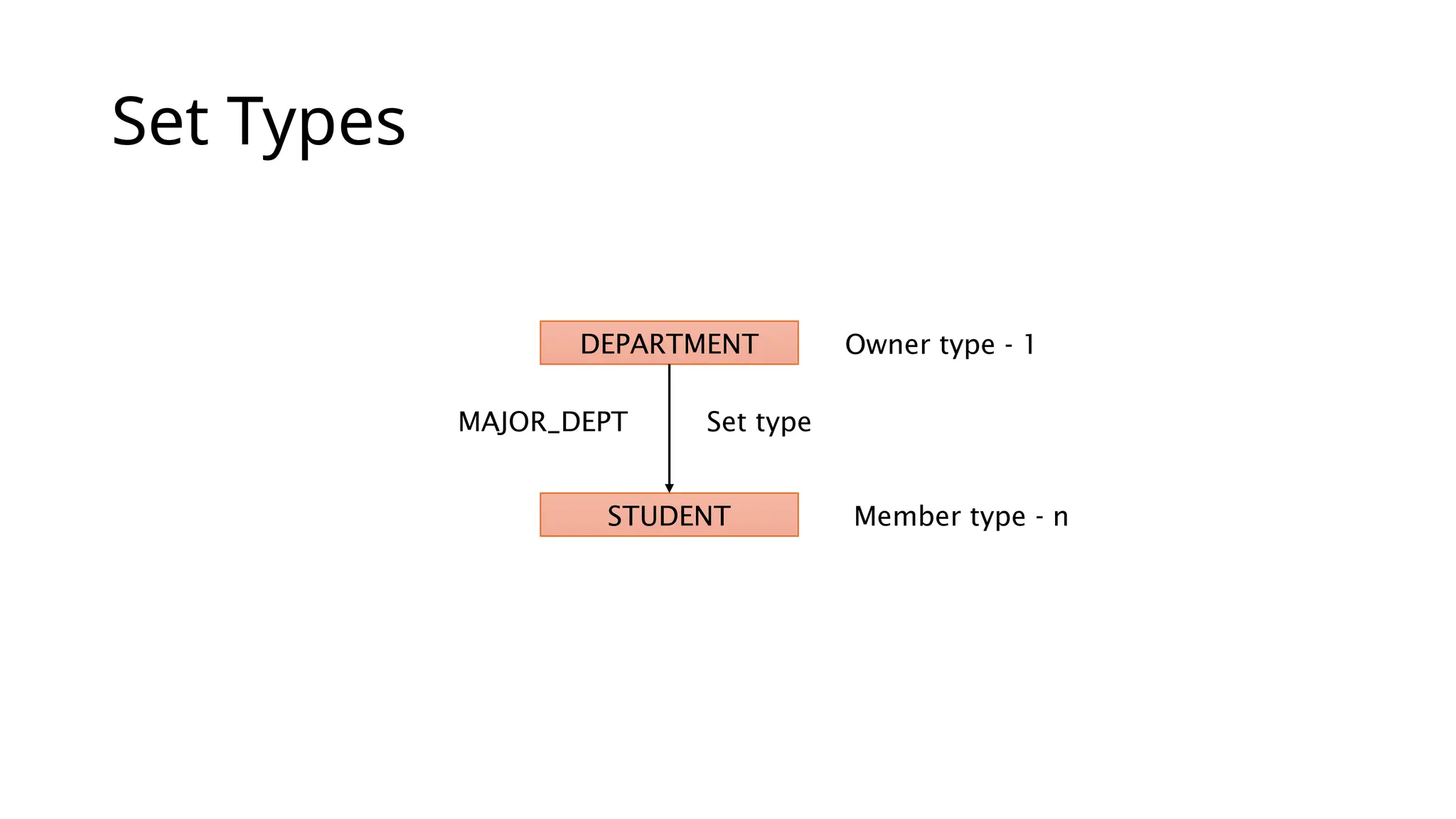
Set Occurrences Set occurrences(set instances) are composed of: • One owner record from the owner record type • Zero or more related member records from the member record type A record from the member record type cannot exist in more than one occurrence of a particular set type • Maintains 1:N constraint on set types
41.
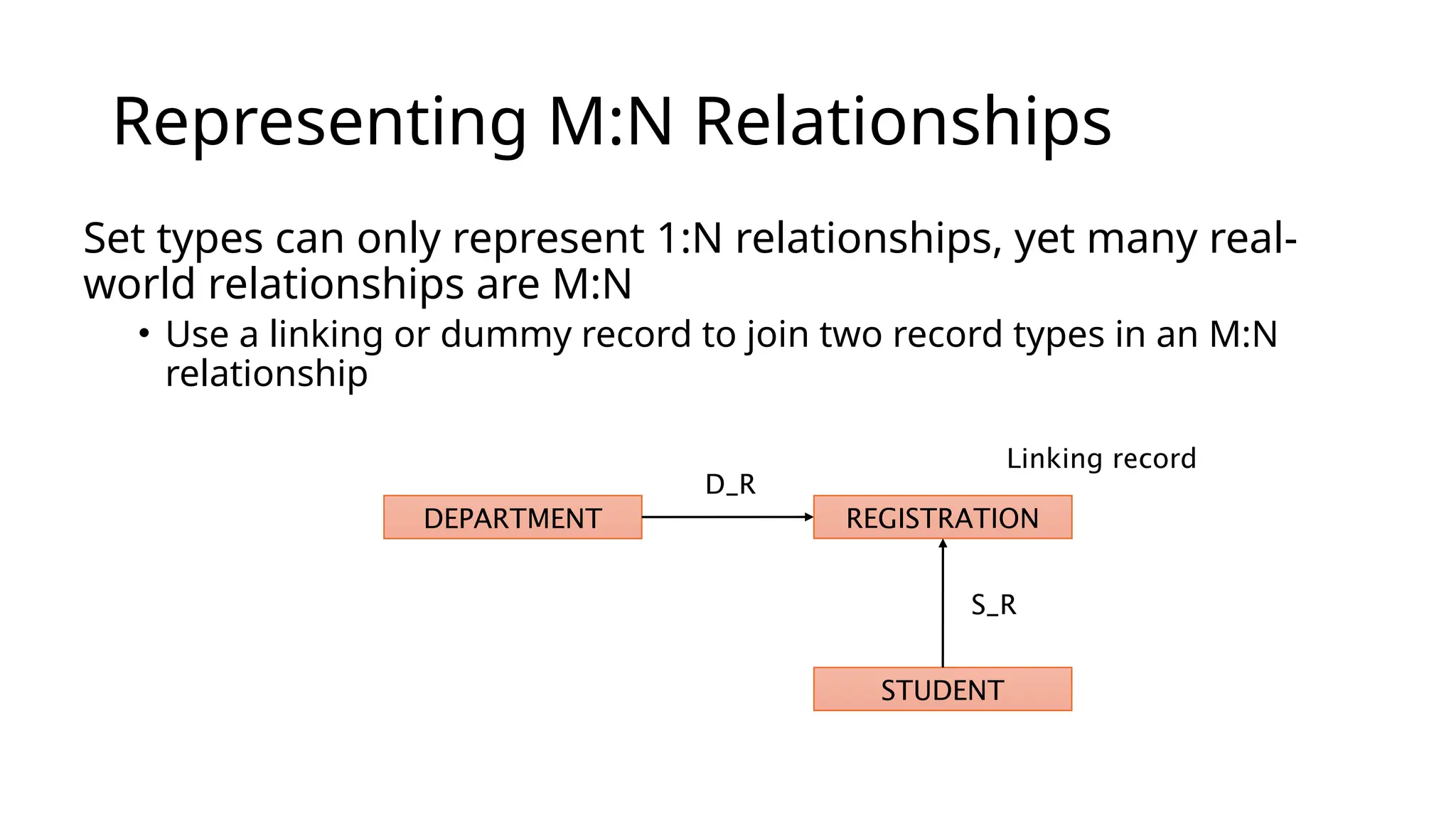
Representing M:N Relationships Settypes can only represent 1:N relationships, yet many real- world relationships are M:N • Use a linking or dummy record to join two record types in an M:N relationship DEPARTMENT STUDENT Linking record D_R REGISTRATION S_R
42.
Issues • Easier tomodel systems with networks than with hierarchies • Can deal with M:N or N-ary relationships But • Querying/update still requires the programmer to explicitly navigate the hierarchy – poor data independence
So you havesome data... Relational Databases solve most data problems: • Persistence • We can store data, and it will remain stored! • Integration • We can integrate lots of different apps through a central DB • SQL • Standard(ish), well understood, very expressive • Transactions • ACID transactions, strong consistency A few key trends and issues are motivating change in how we store data: • The impedance mismatch problem • Increasing volume of data and traffic
45.
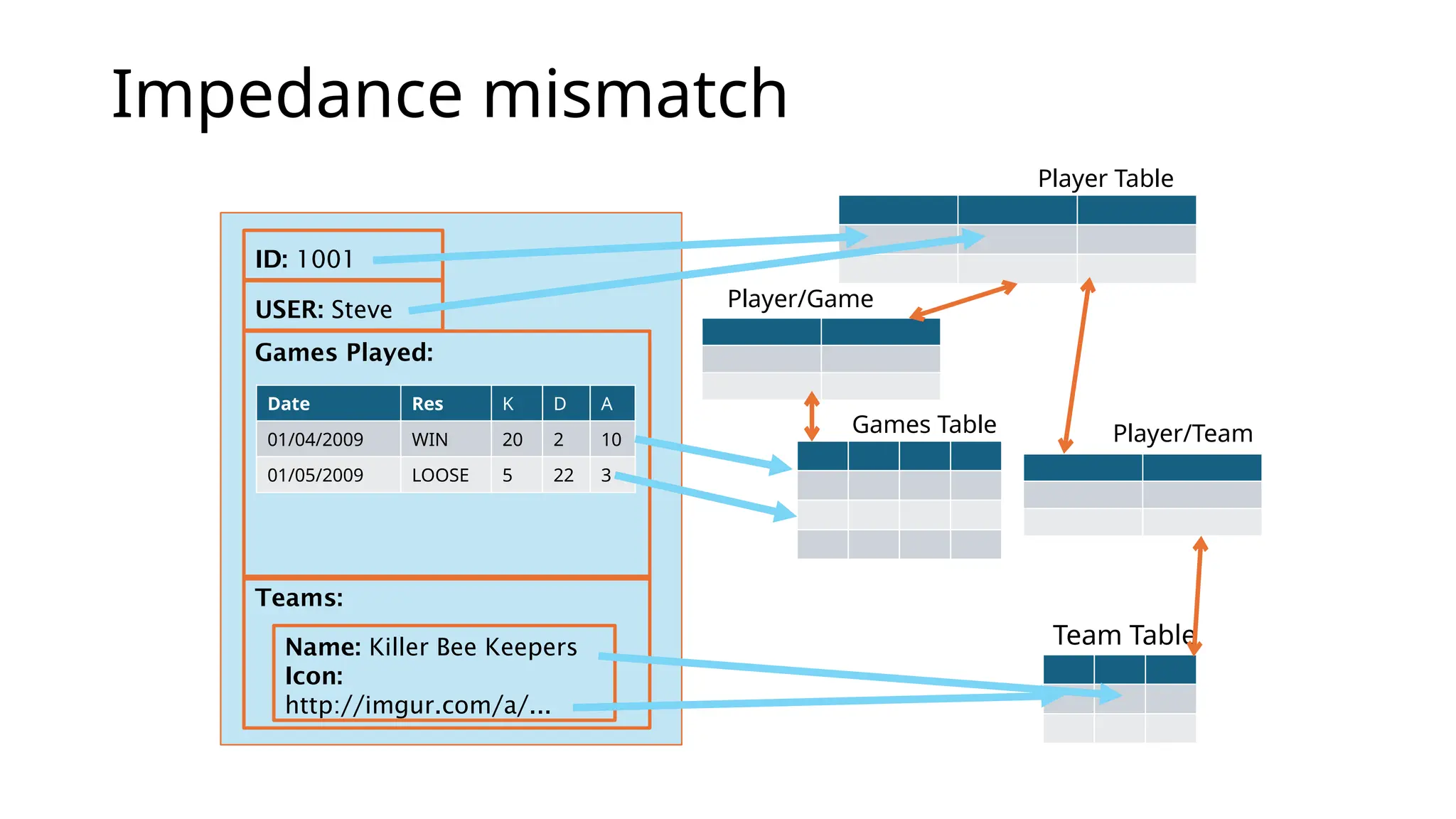
The impedance mismatchproblem We typically structure data in memory in an object-oriented fashion • based on software engineering principles of abstraction, encapsulation and inheritance We typically use RDBMSes for persistent storage on disc • relational model based on set theory These are fundamentally different approaches to structuring data Mapping from one world to the other has problems
46.
Impedance mismatch ID: 1001 USER:Steve Games Played: Teams: Name: Killer Bee Keepers Icon: http://imgur.com/a/... Date Res K D A 01/04/2009 WIN 20 2 10 01/05/2009 LOOSE 5 22 3 Games Table Player Table Team Table Player/Game Player/Team
47.
Increased data volume Weare creating/storing/processing more data than ever before “From 2005 to 2020, the digital universe will grow by a factor of 300, from 130 exabytes to 40,000 exabytes, or 40 trillion gigabytes (more than 5,200 gigabytes for every man, woman, and child in 2020). From now until 2020, the digital universe will about double every two years.” http://www.emc.com/leadership/digital-universe/index.htm
48.
Dealing with increaseddata volume Two options when dealing with these trends: 1. Build bigger database machines • This can be expensive • Fundamental limits to machine size 2. Build clusters of smaller machines • Lots of small machines (commodity machines) • Each machine is cheap, potentially unreliable • Needs a DBMS which understands clusters
49.
Relational Databases suck… Thereis a common perception that RDBMSes have fundamental issues: In dealing with (horizontal) scale • Designed to work on single, large machines • Difficult to distribute effectively In dealing with the impedance mismatch • We create data structures in memory and then rip them apart to stick them in an RDBMS • Relational data models often seem "unnatural" (normalisation seems unintuitive) • Uncomfortable to program with (joins and ORM etc.)
Editor's Notes
#5 Storing and managing data A da from customer information to financial records.tabase allows companies to store and manage large amounts of structured and unstructured data, Improving business processes
#11 Storing and managing data A da from customer information to financial records.tabase allows companies to store and manage large amounts of structured and unstructured data, Improving business processes
#31 A parent-child relationship type (PCR type) is a 1:N relationship between two record types The single end is the parent record type The multiple end has the child record type (each record may have many children) Each child may itself have child record types (i.e. it may be the parent in another relationship
#39 A set type is a description of a 1:N relationship between two record types Each set type has: A name An owner record type (the domain of the relationship) A member record type (the range of the relationship)