Downloaded 737 times





![API • Producer messages = new List<KeyedMessage<K,V>>(); messages.add(newKeyedMessage(“topic1”, null, “msg1”); send(messages); • Consumer streams[] = Consumer.createMessageStream(“topic1”, 1); for(message: streams[0]) { // do something with message }](https://image.slidesharecdn.com/kafkareplicationapachecon2013-130227131545-phpapp02/75/Kafka-replication-apachecon_2013-11-2048.jpg)
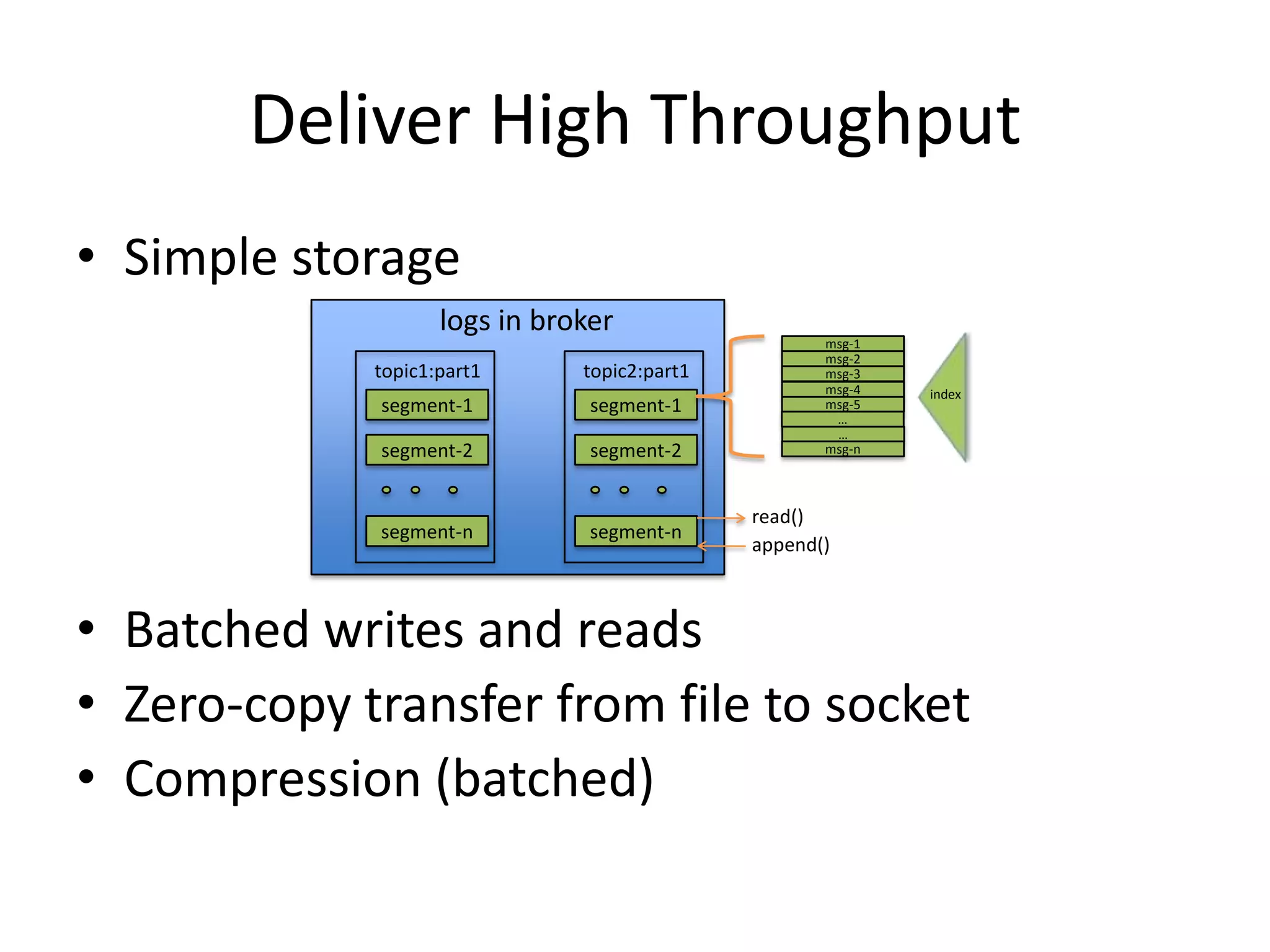
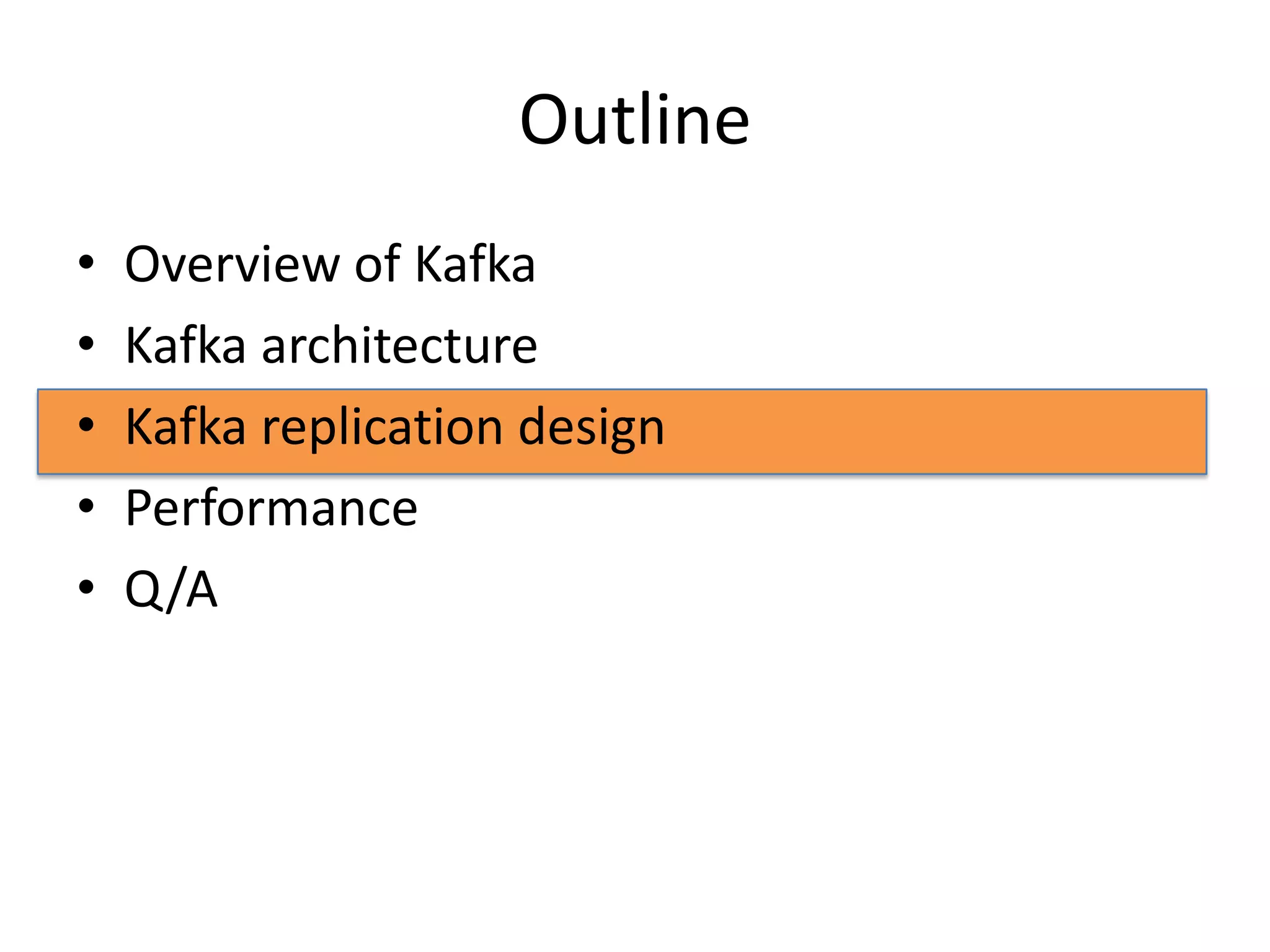






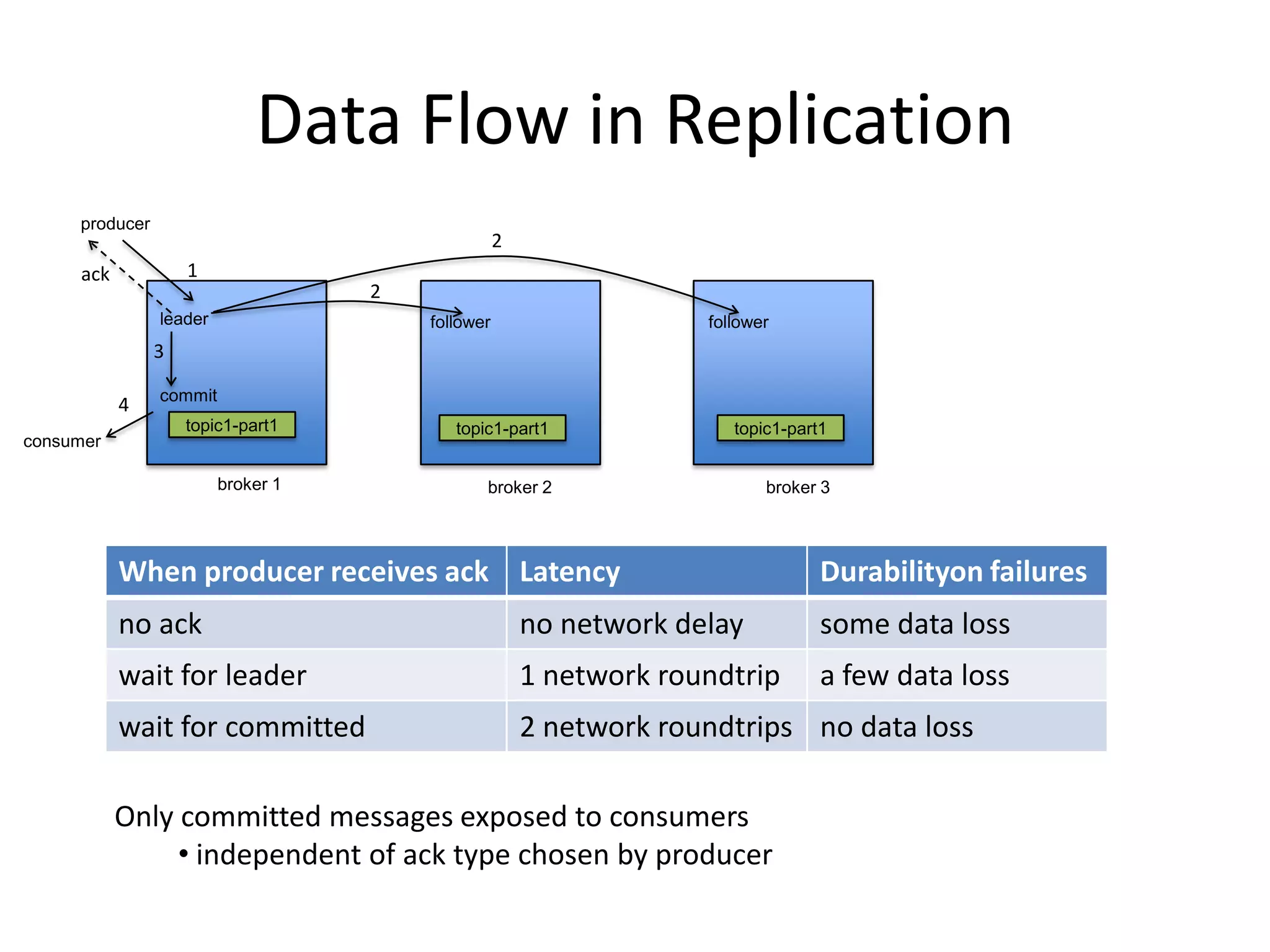
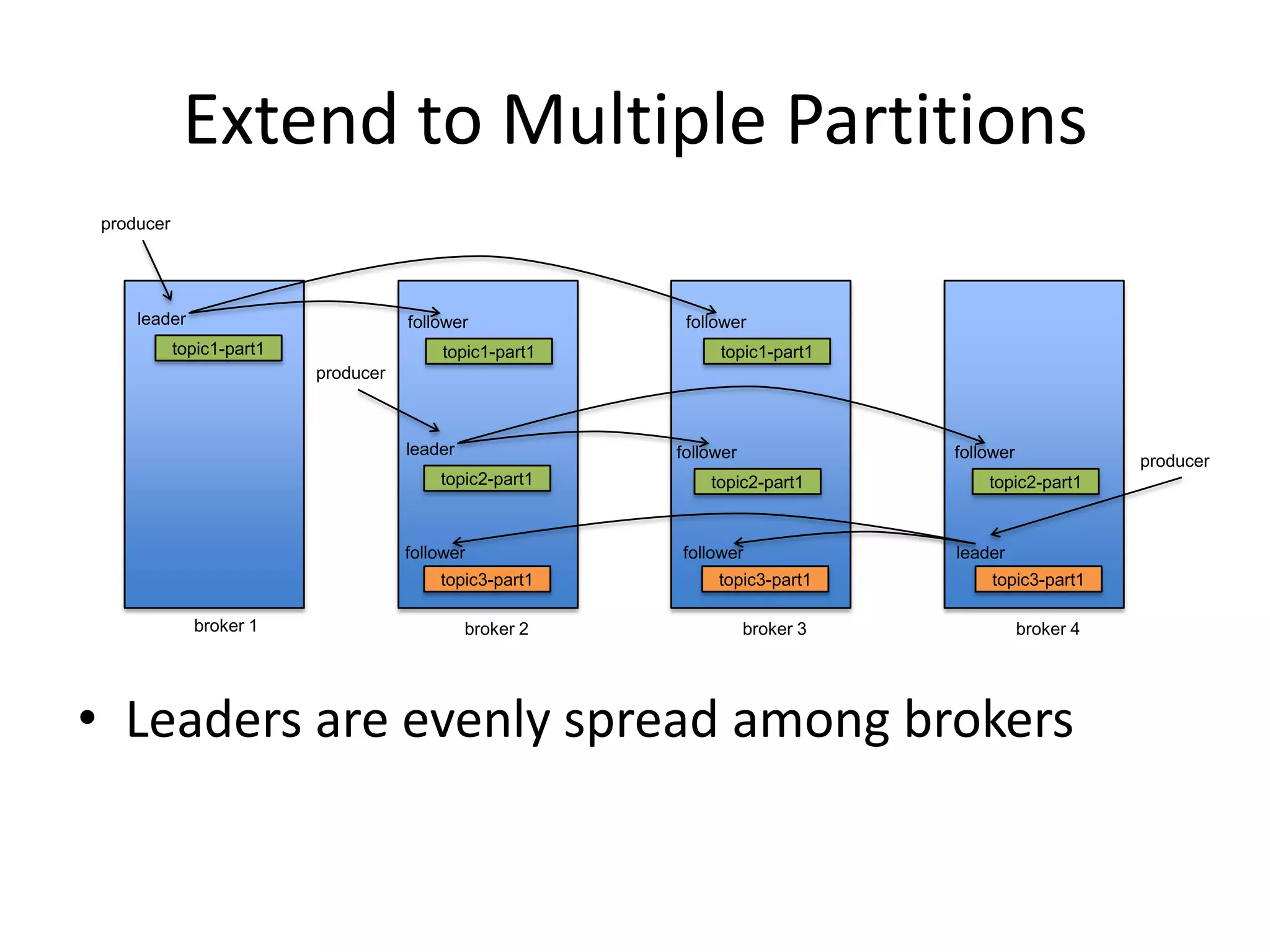


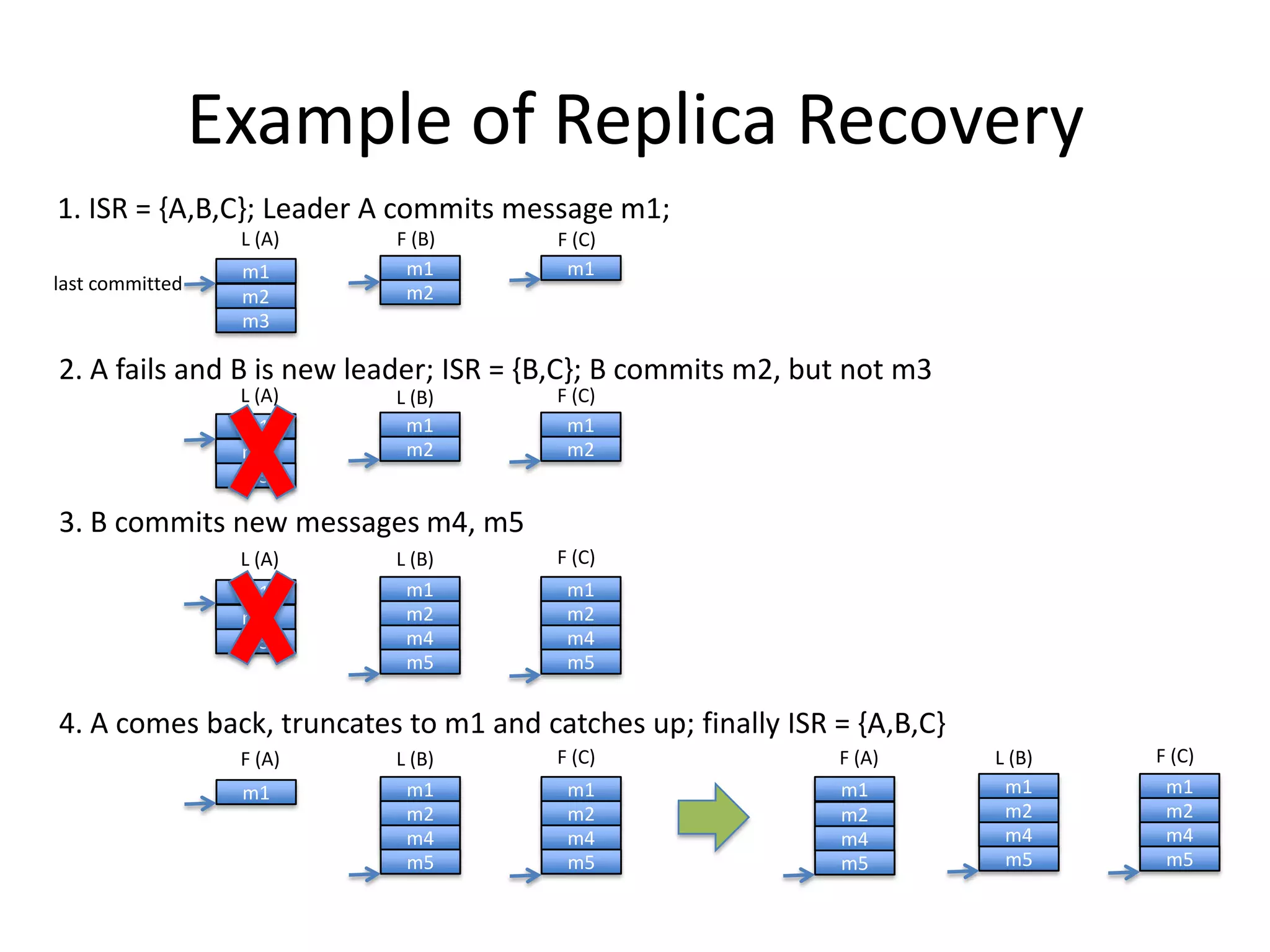


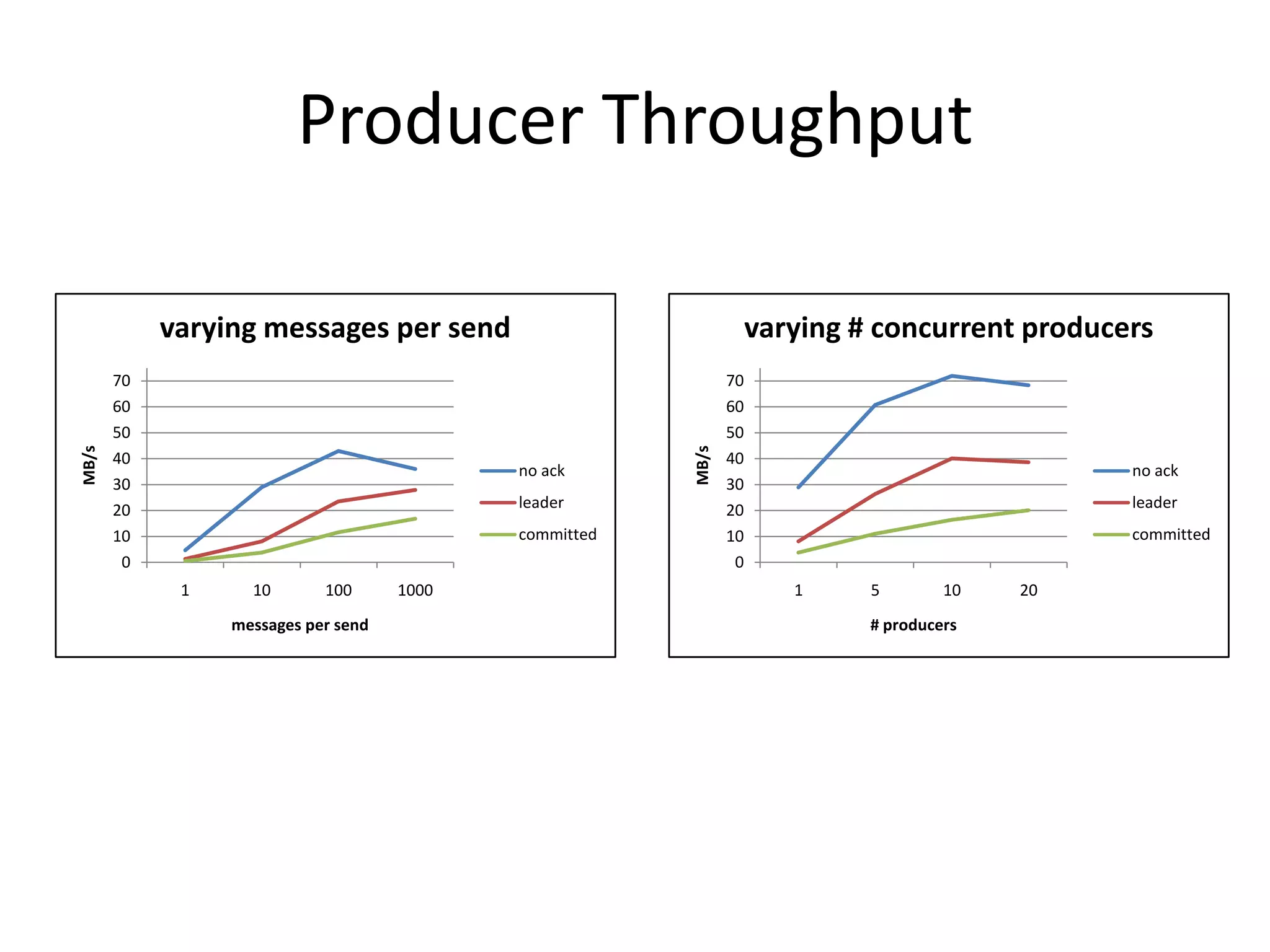
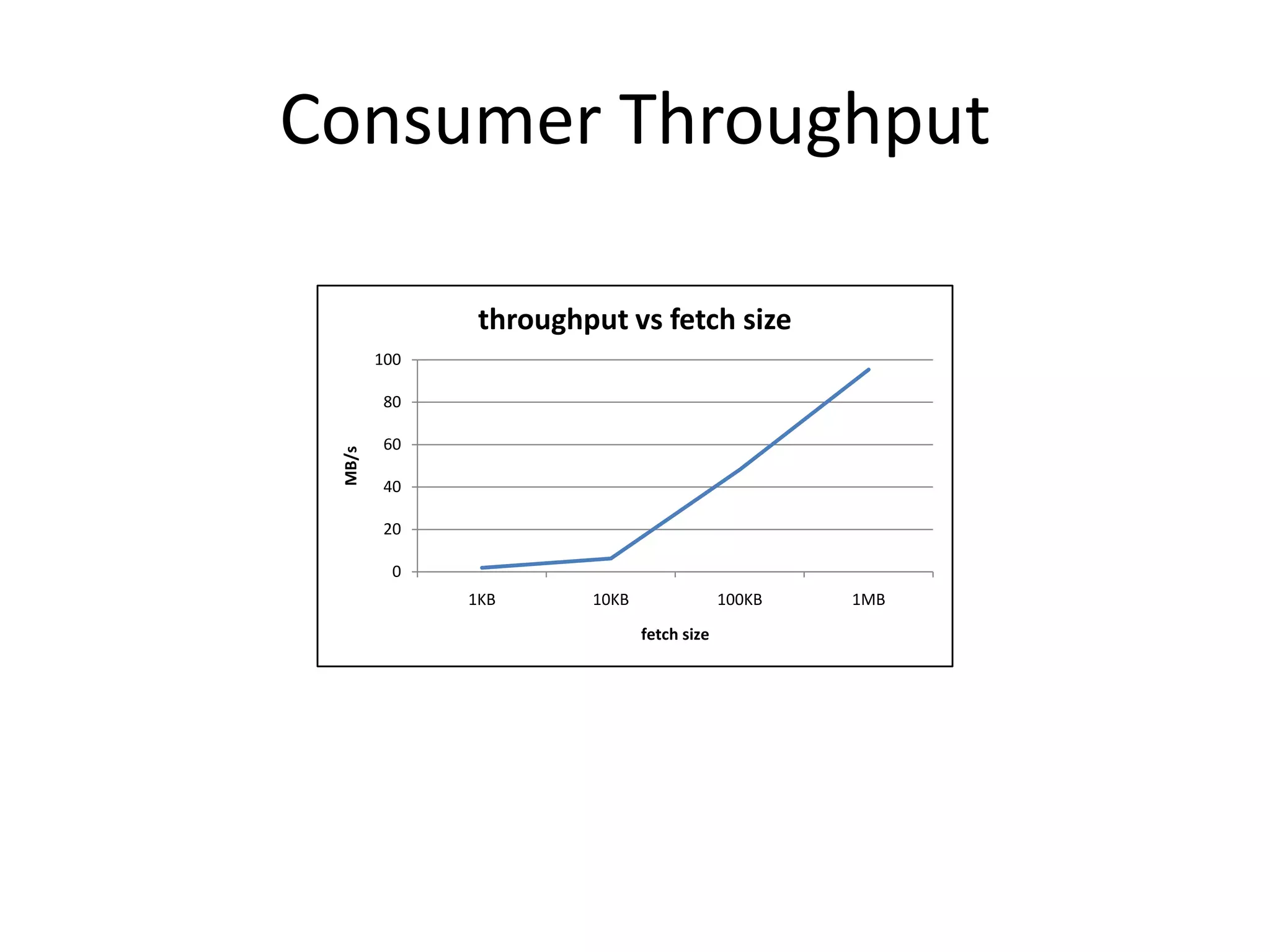


The document discusses intra-cluster replication in Apache Kafka, including its architecture where partitions are replicated across brokers for high availability. Kafka uses a leader and in-sync replicas approach to strongly consistent replication while tolerating failures. Performance considerations in Kafka replication include latency and durability tradeoffs for producers and optimizing throughput for consumers.