Downloaded 31 times






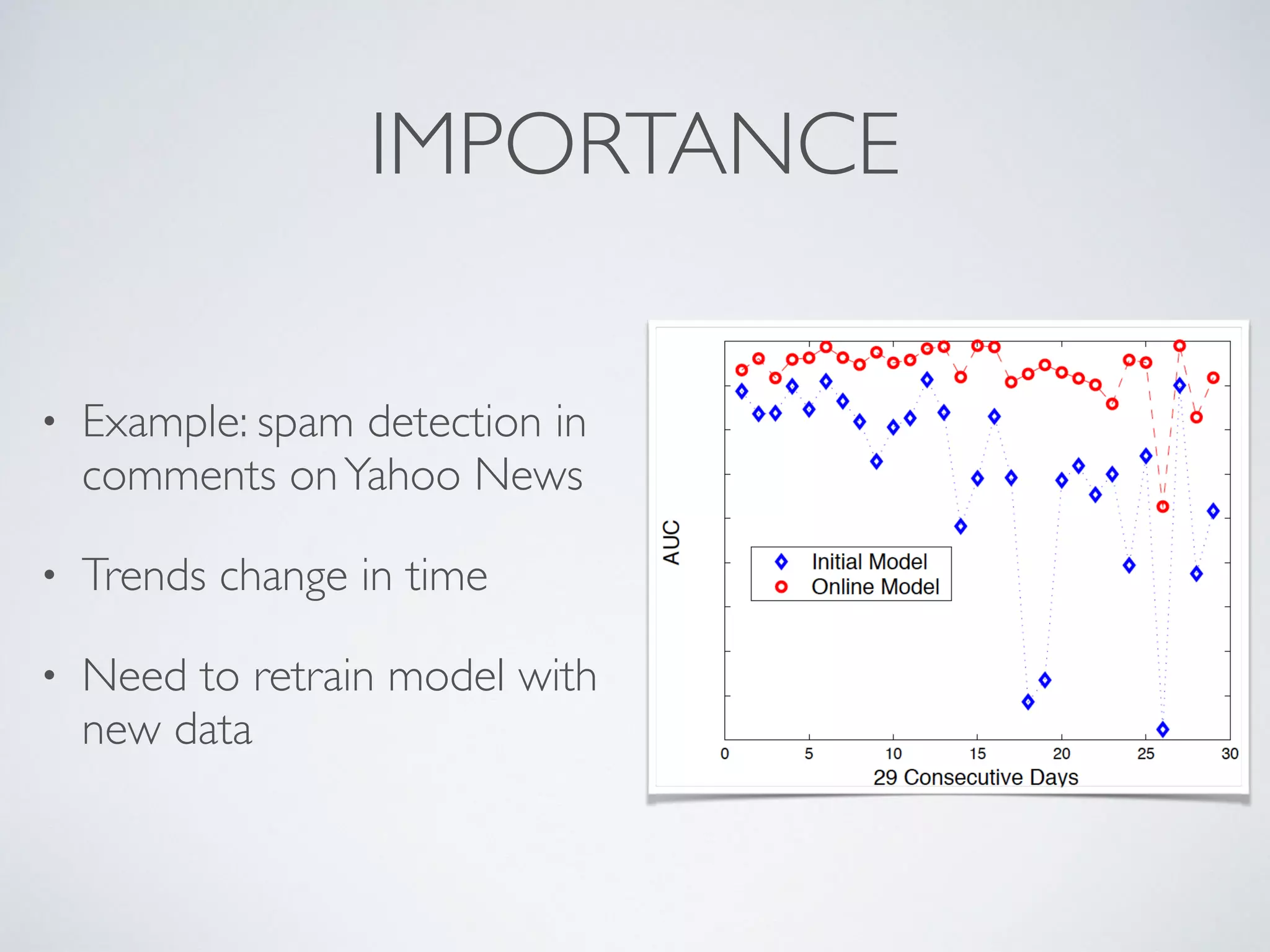
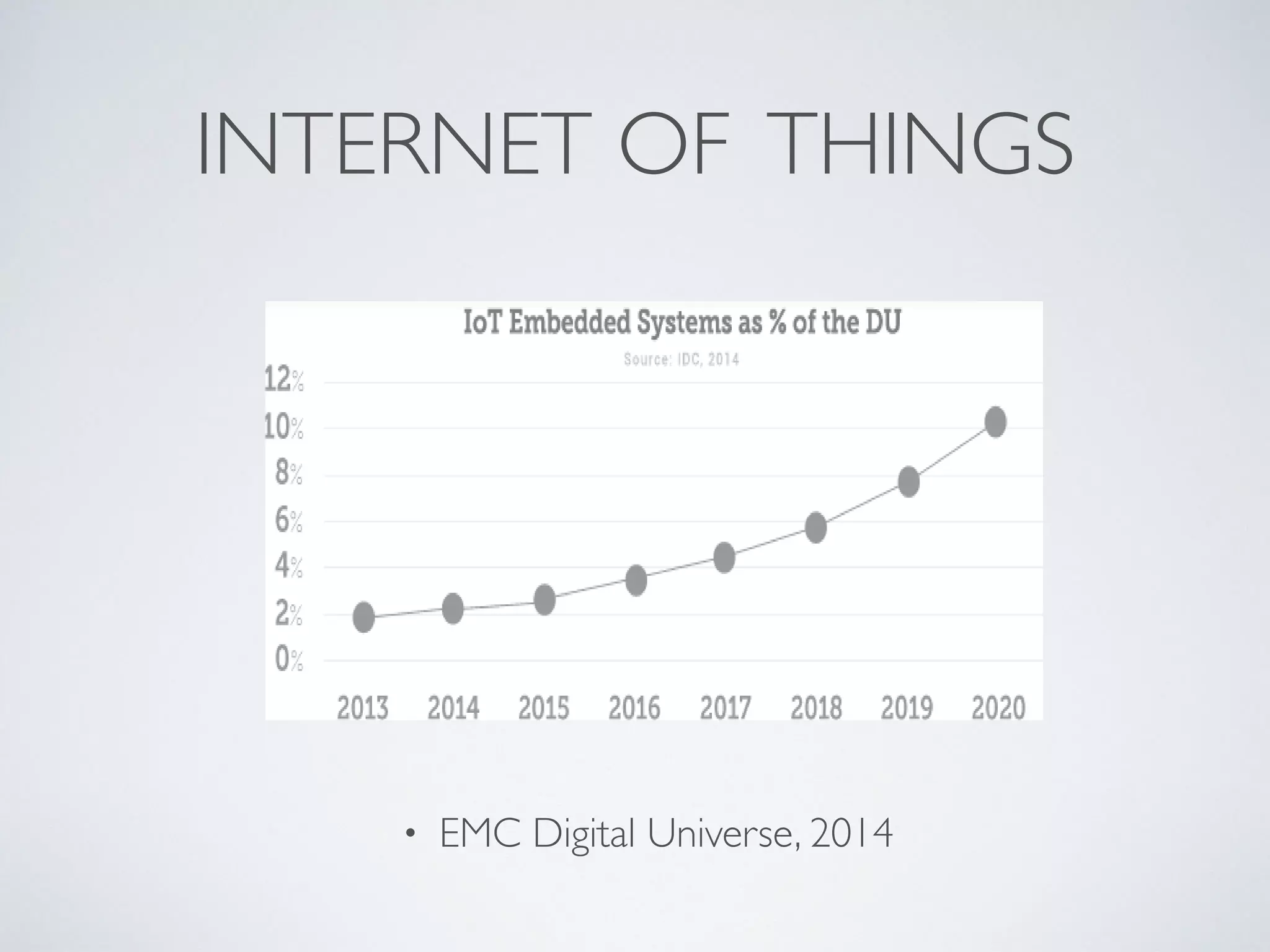




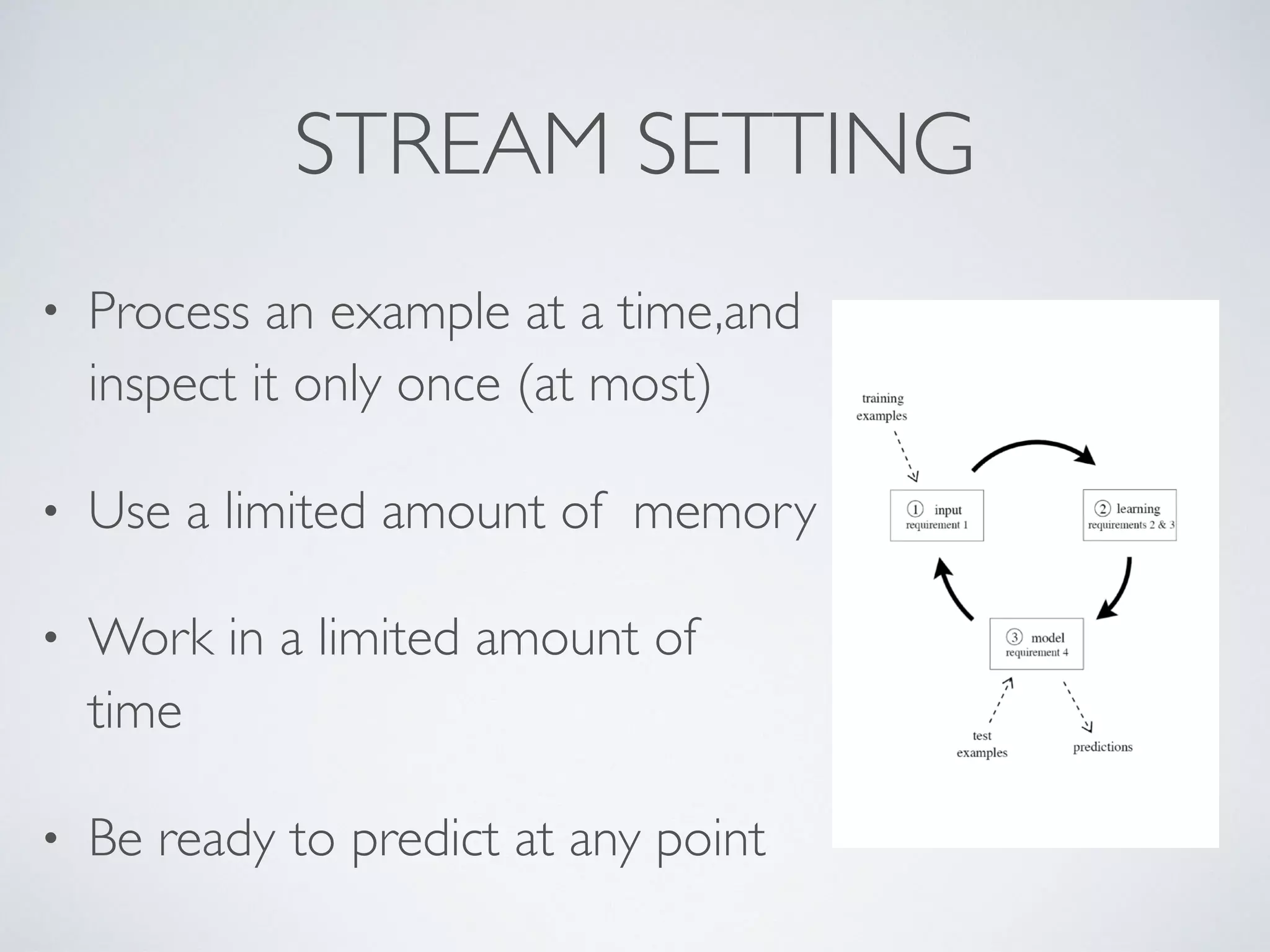



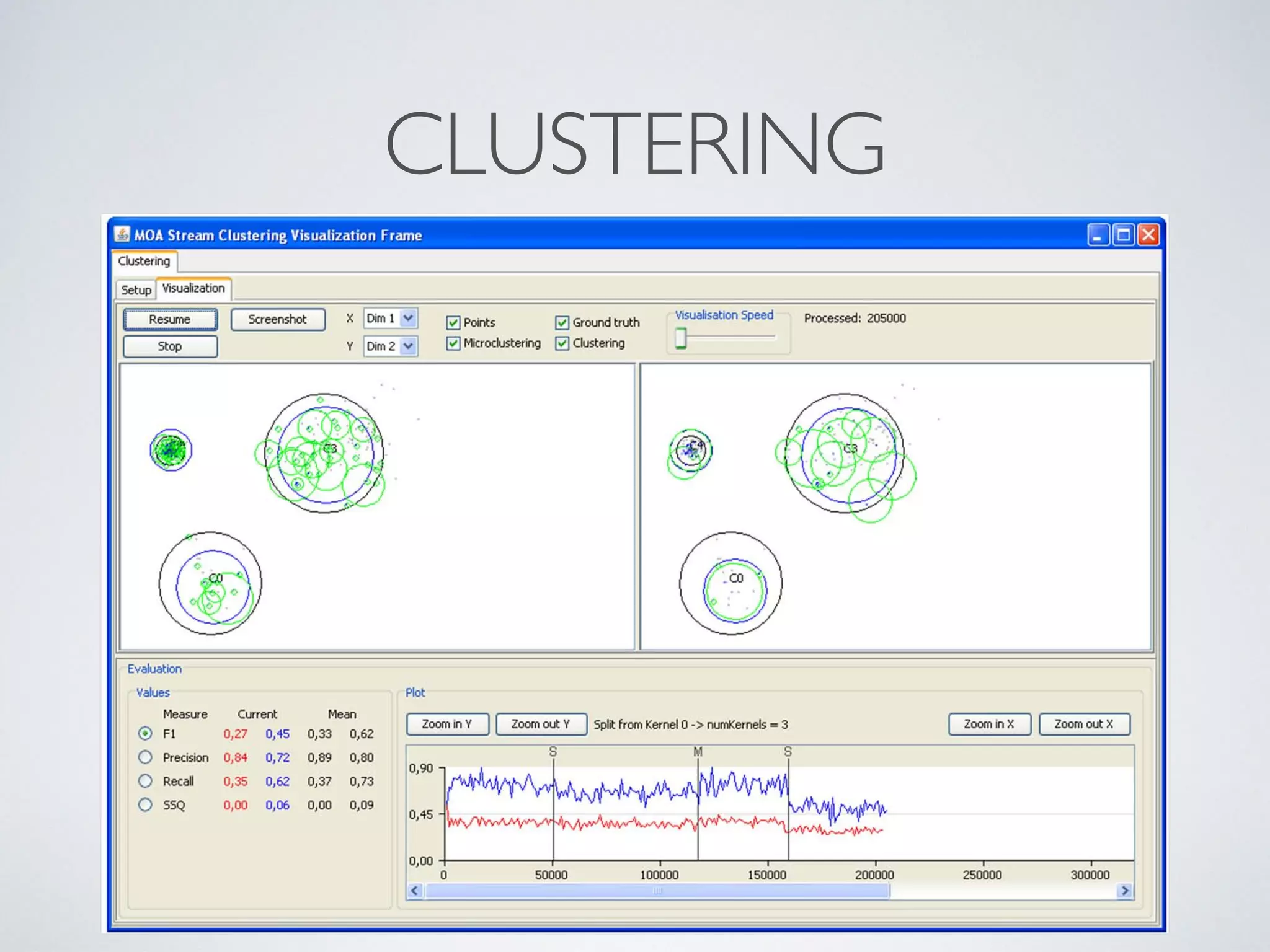



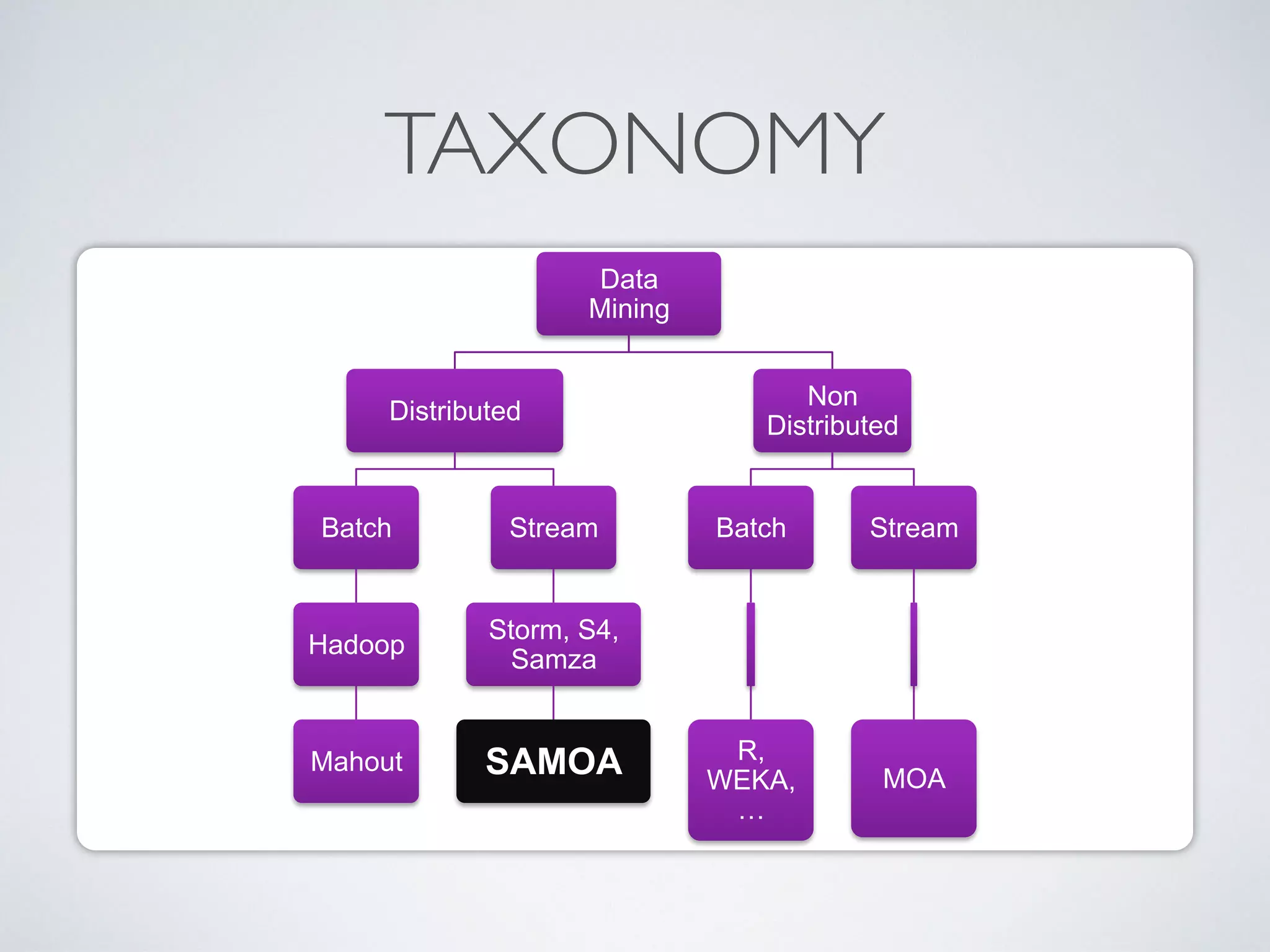
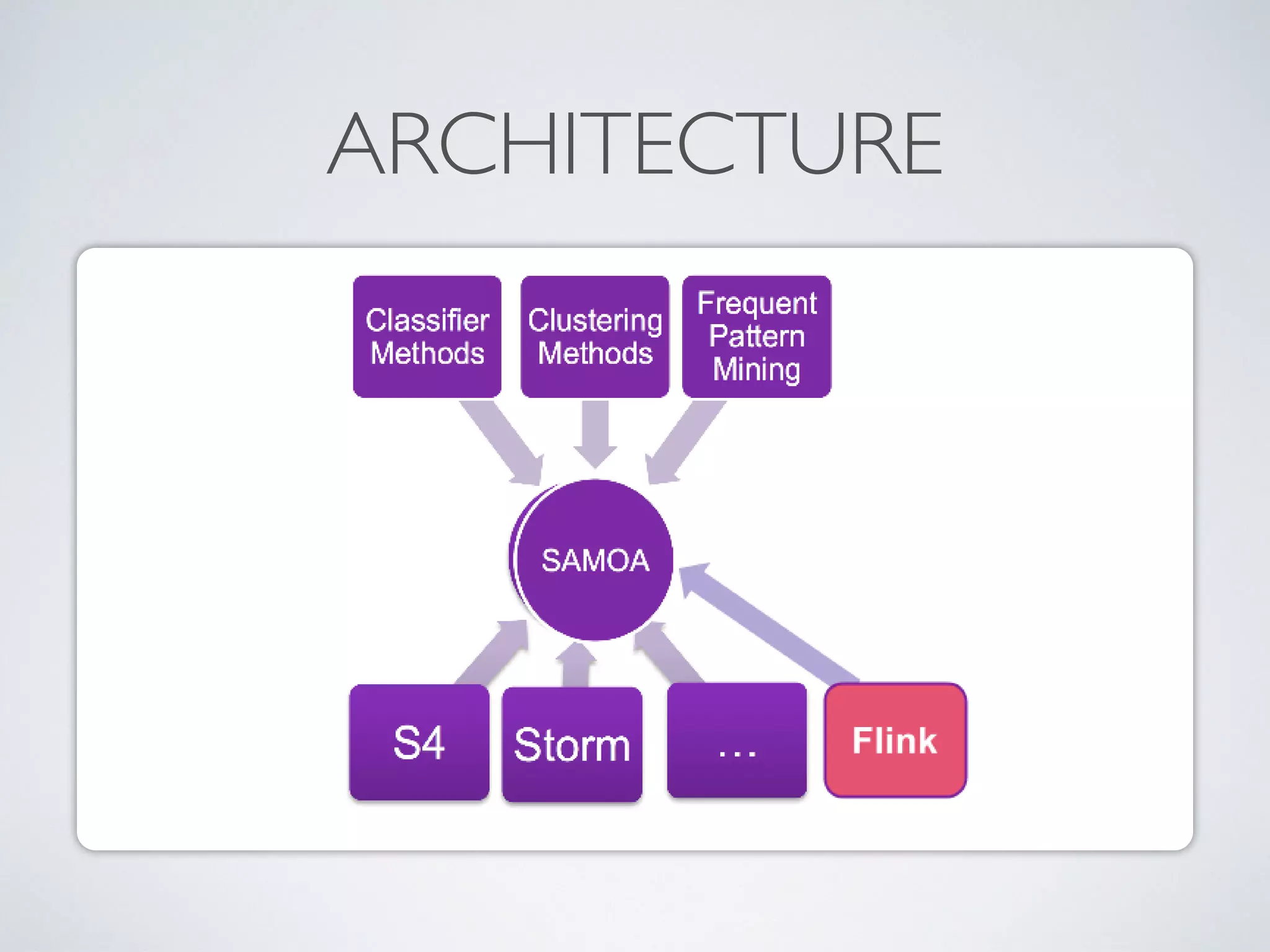


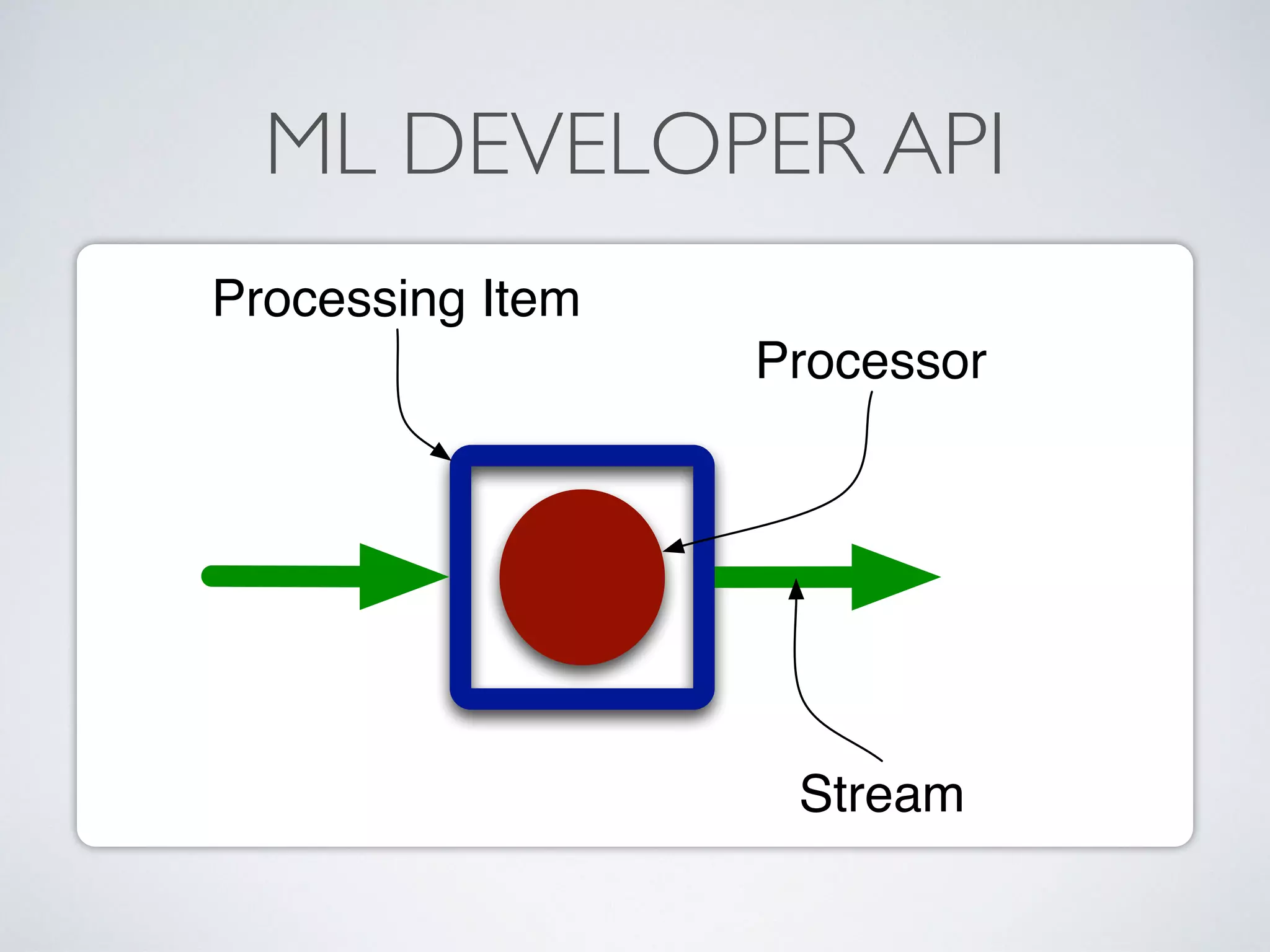


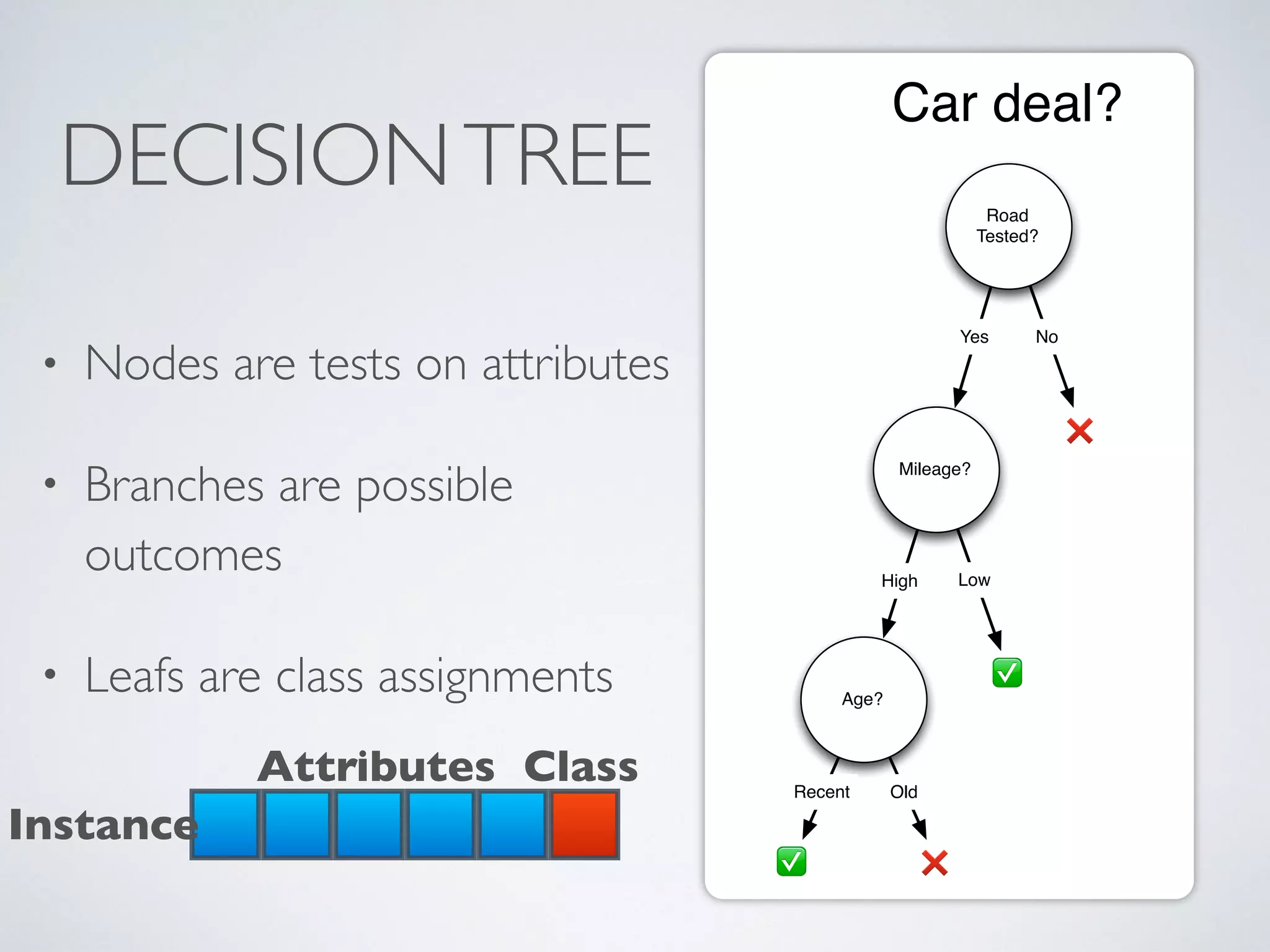

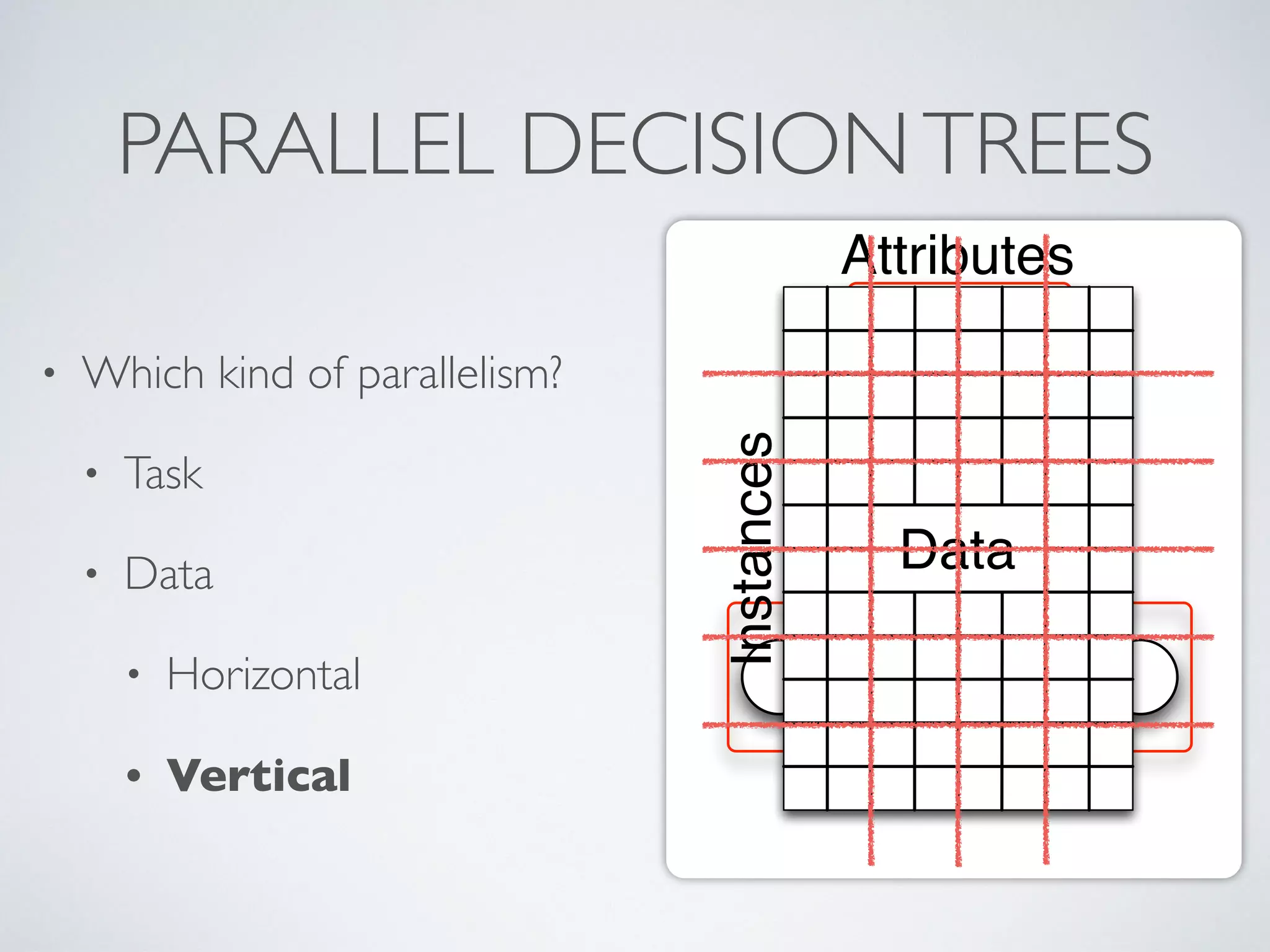
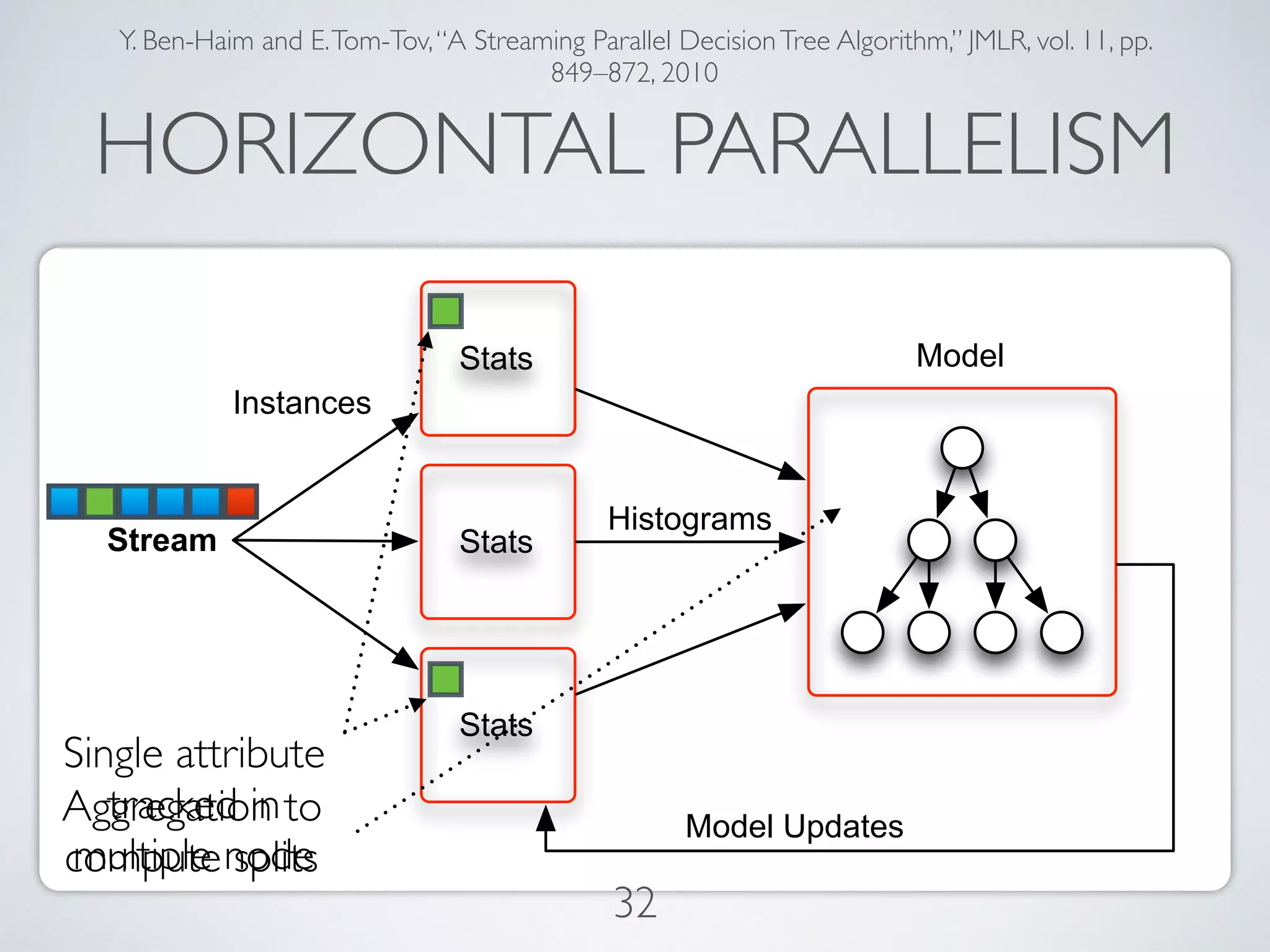

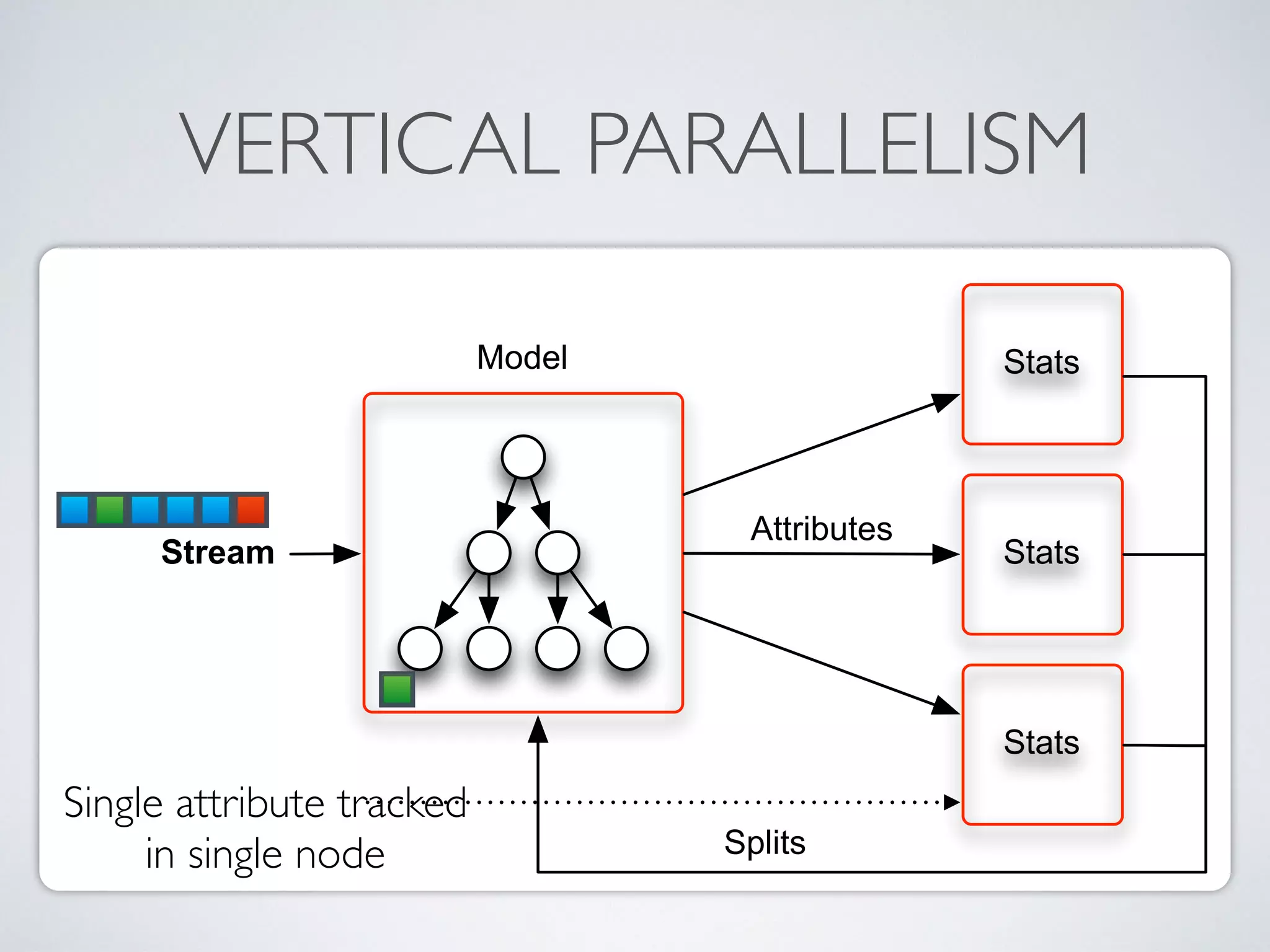

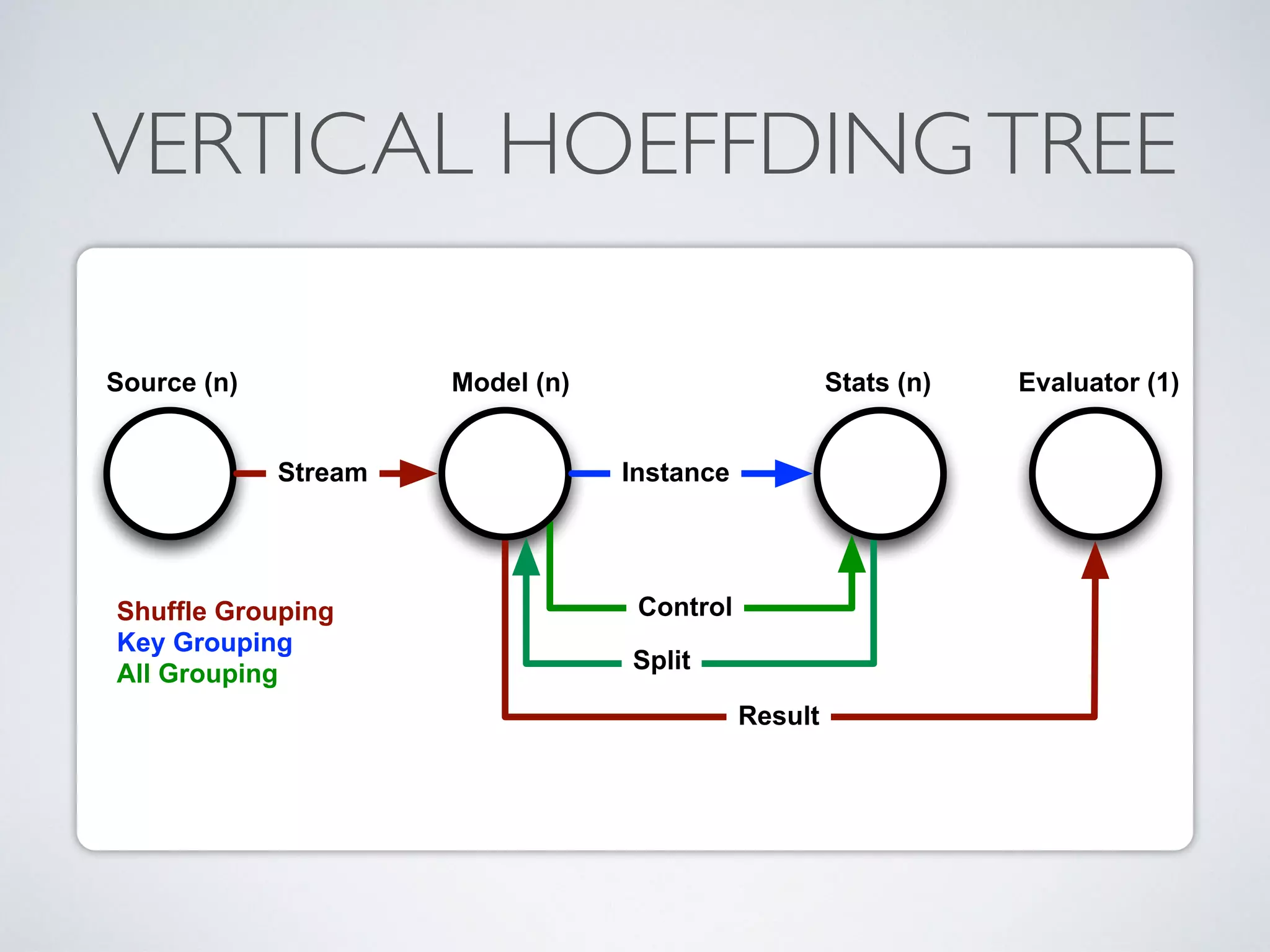
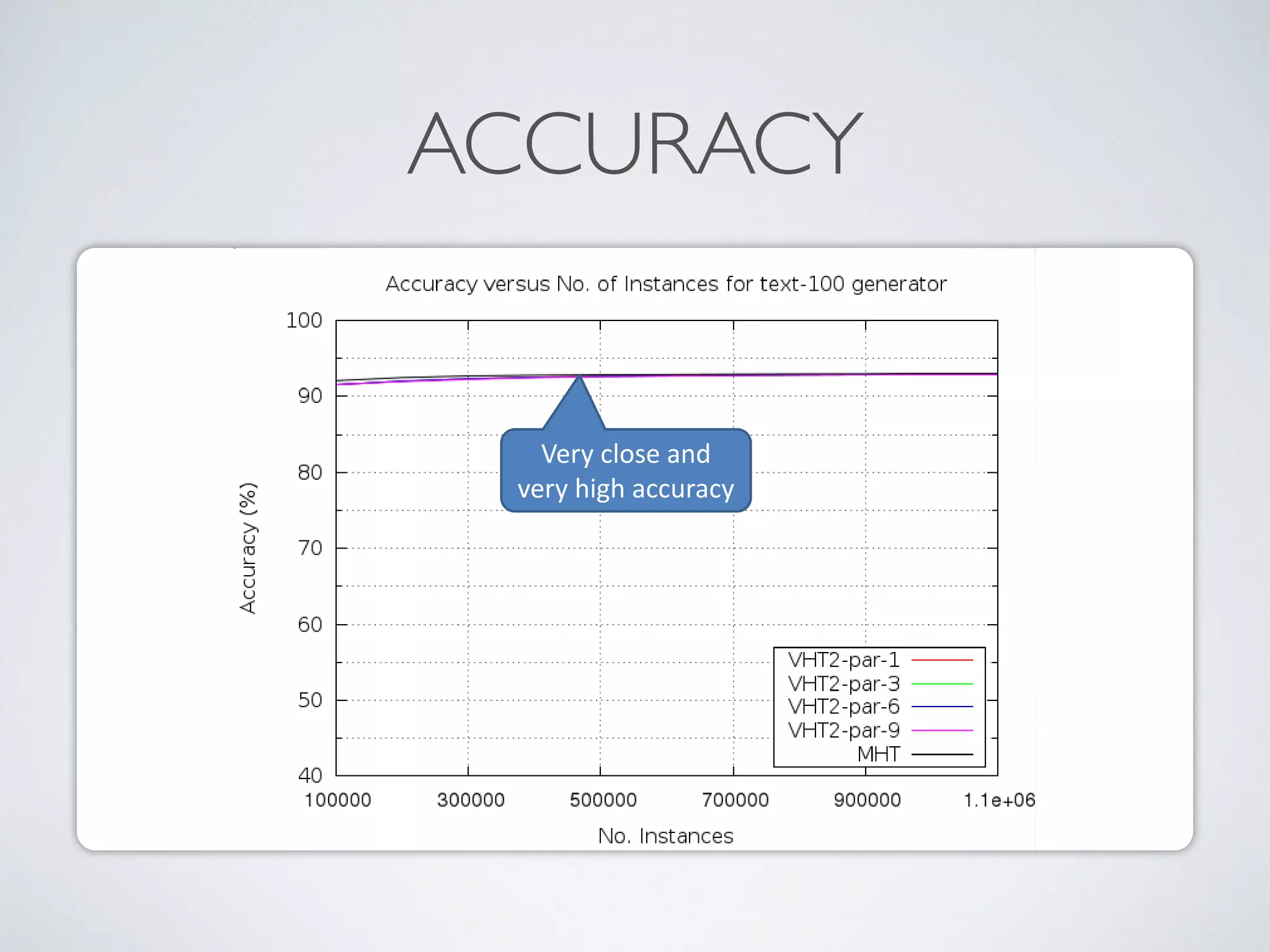
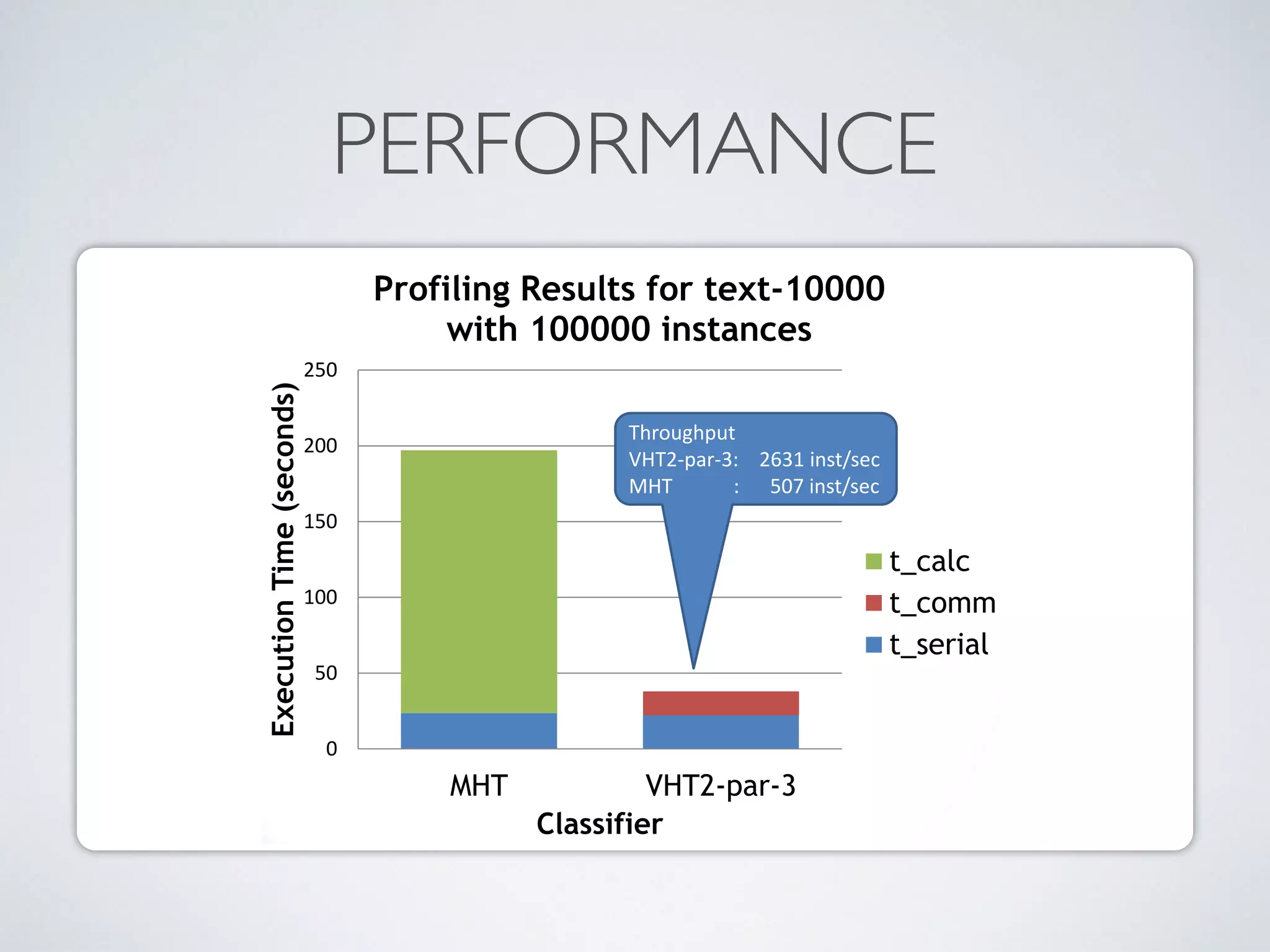






The document discusses mining big data streams using Apache SAMOA and highlights the importance of real-time analytics, model retraining, and handling high-velocity data. It covers various systems such as Apache Storm, Samza, and the Massive Online Analysis (MOA) framework for streaming data processing and evaluation. The authors emphasize the need for effective algorithms for evolving data and the challenges faced in distributed stream mining.