Downloaded 33 times




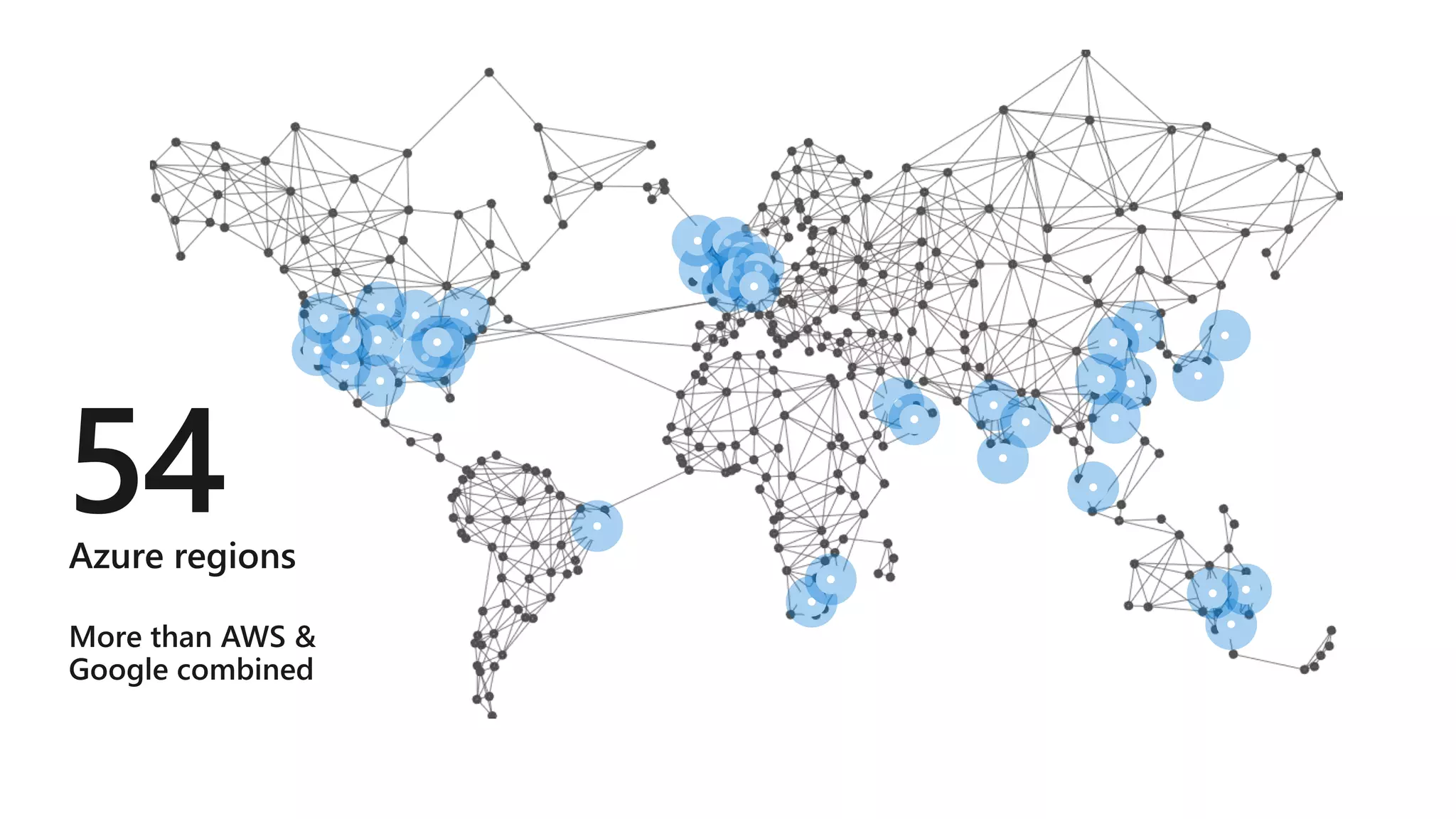


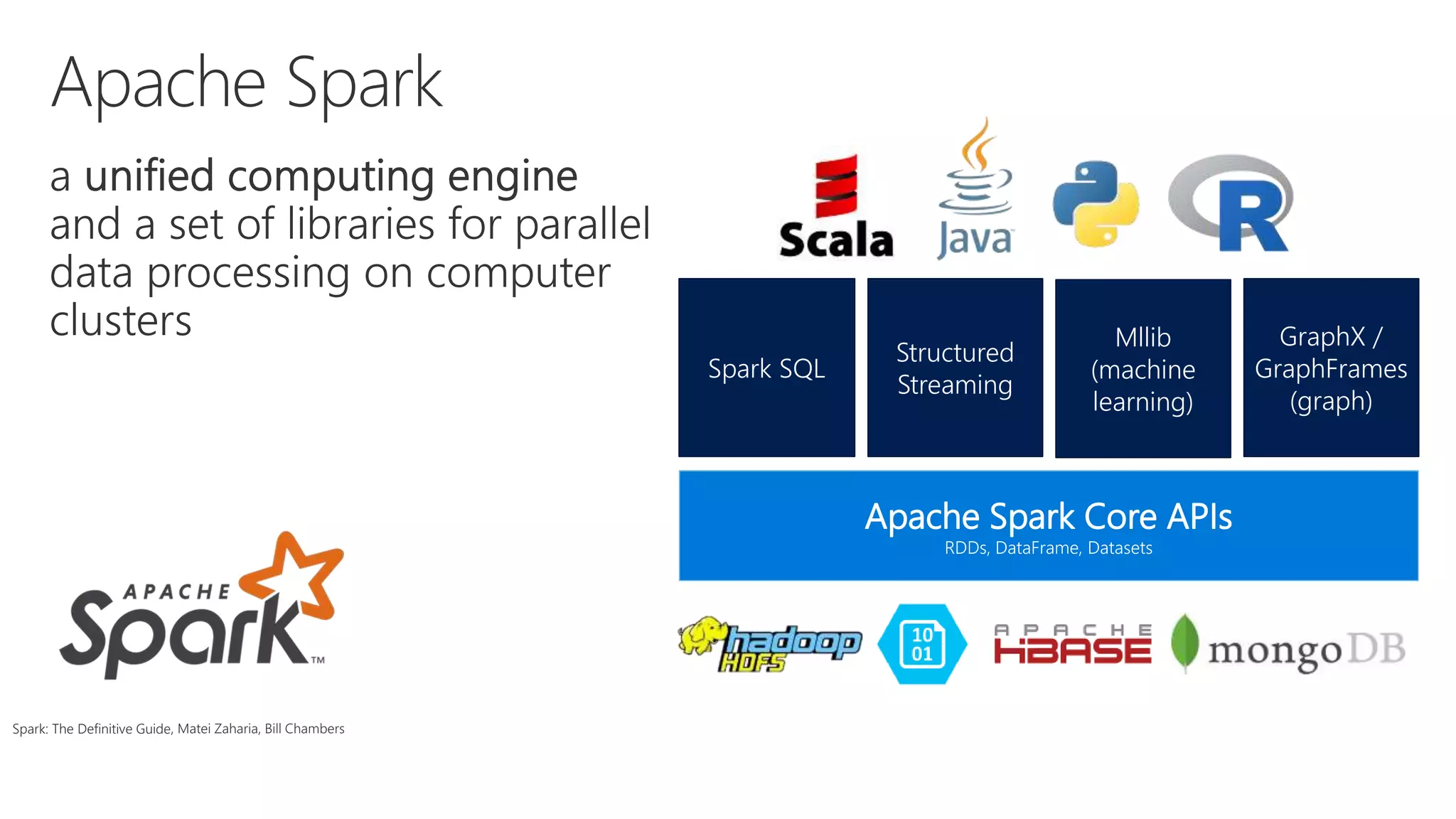
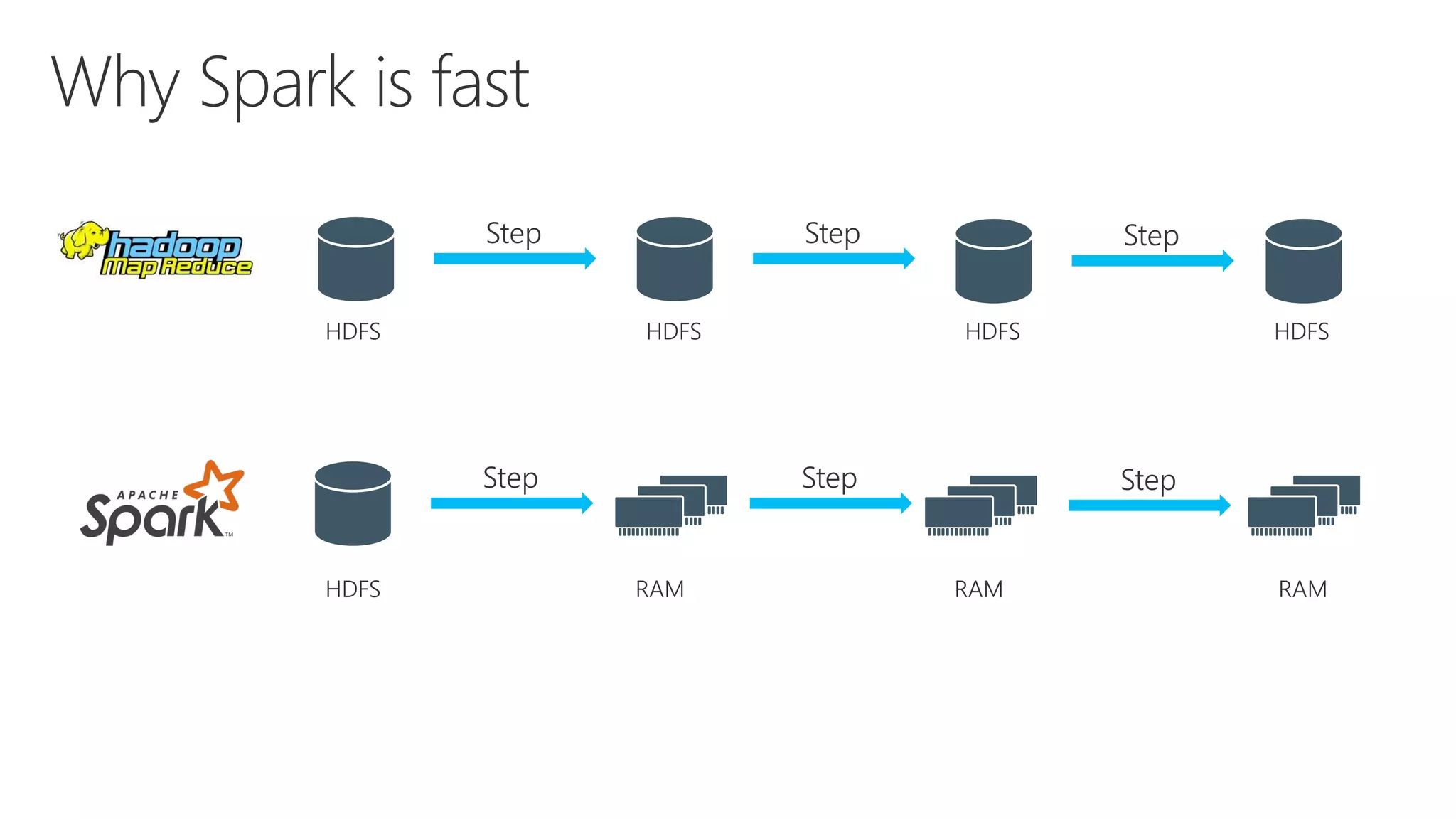
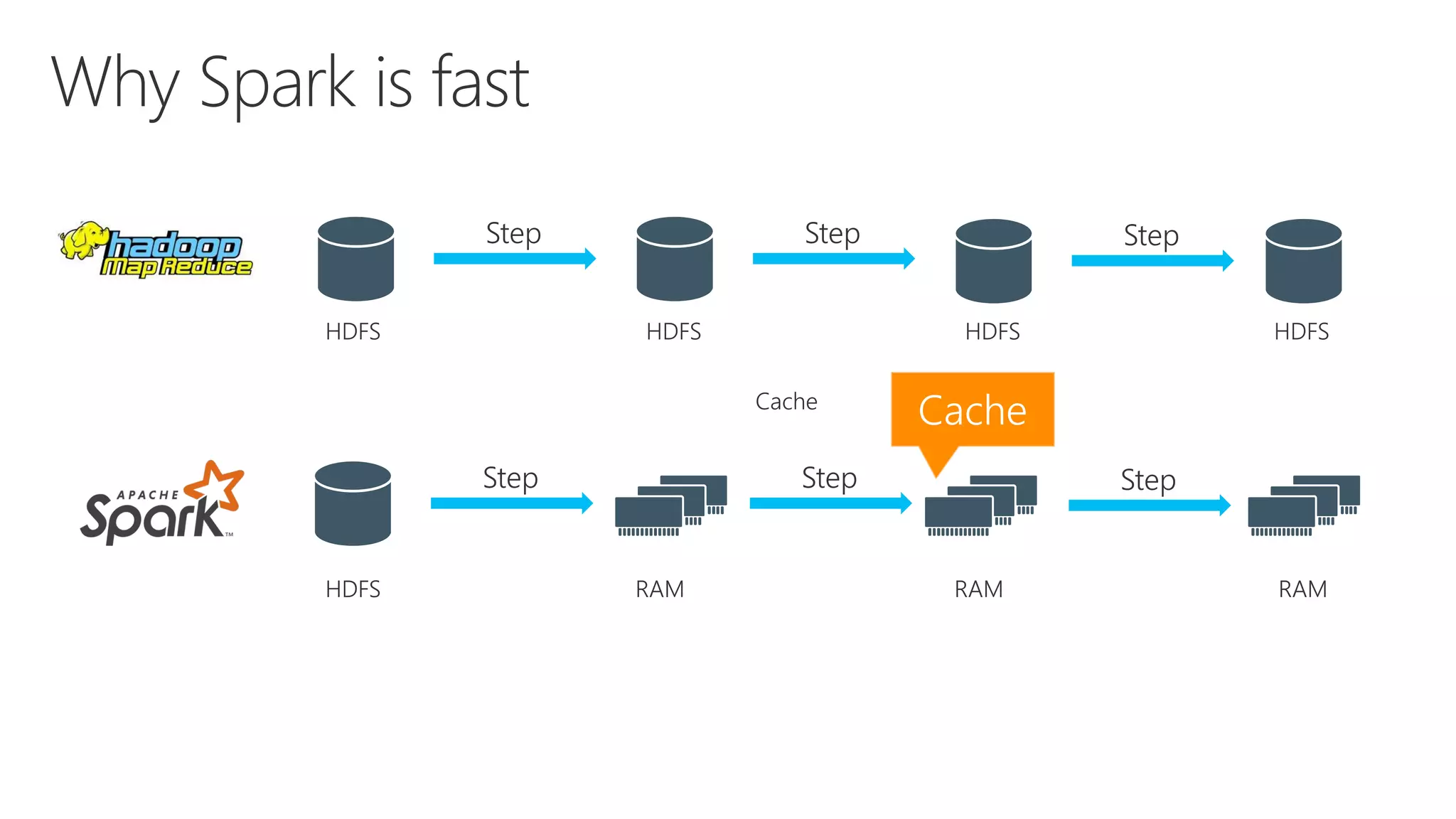


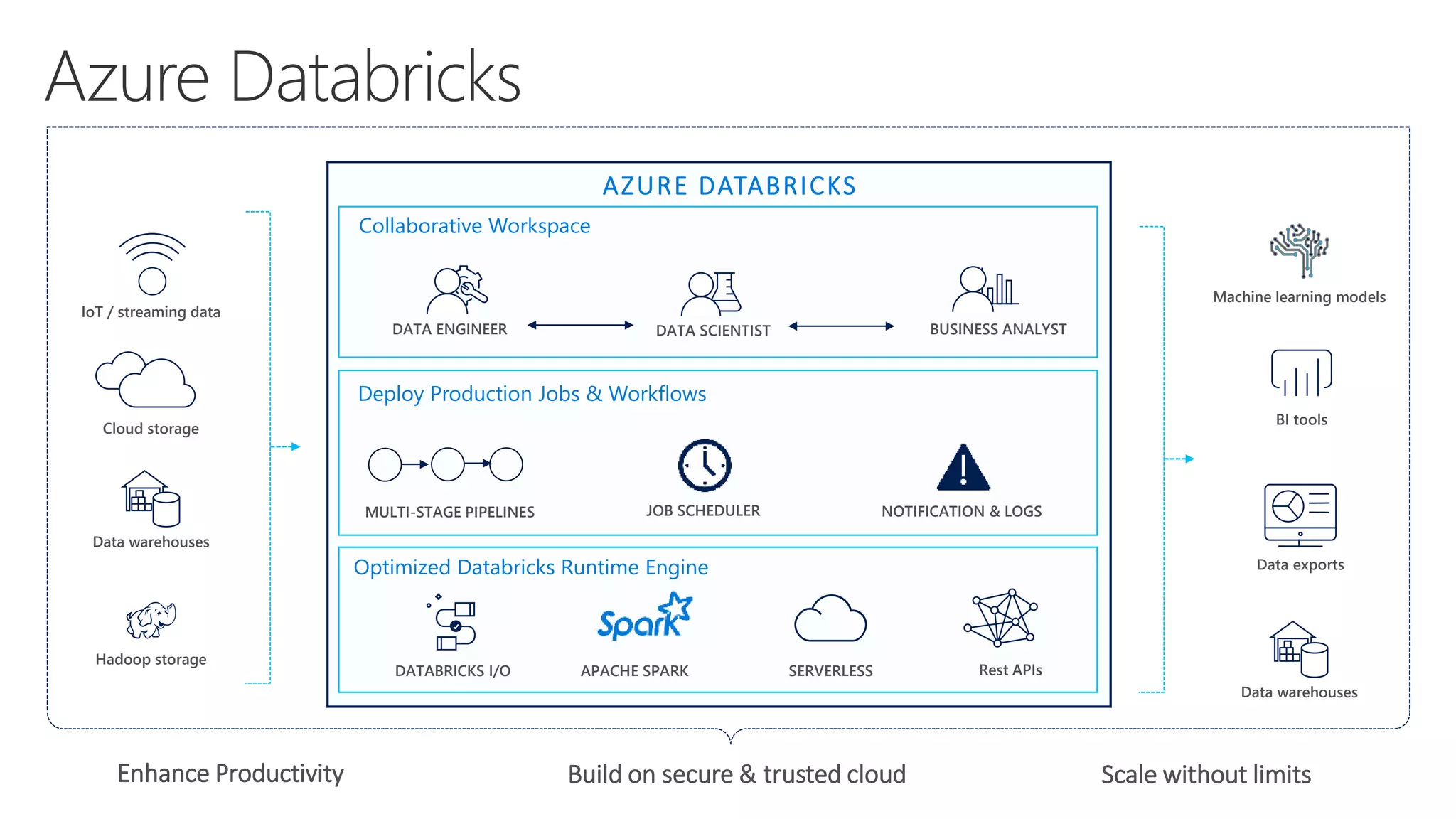




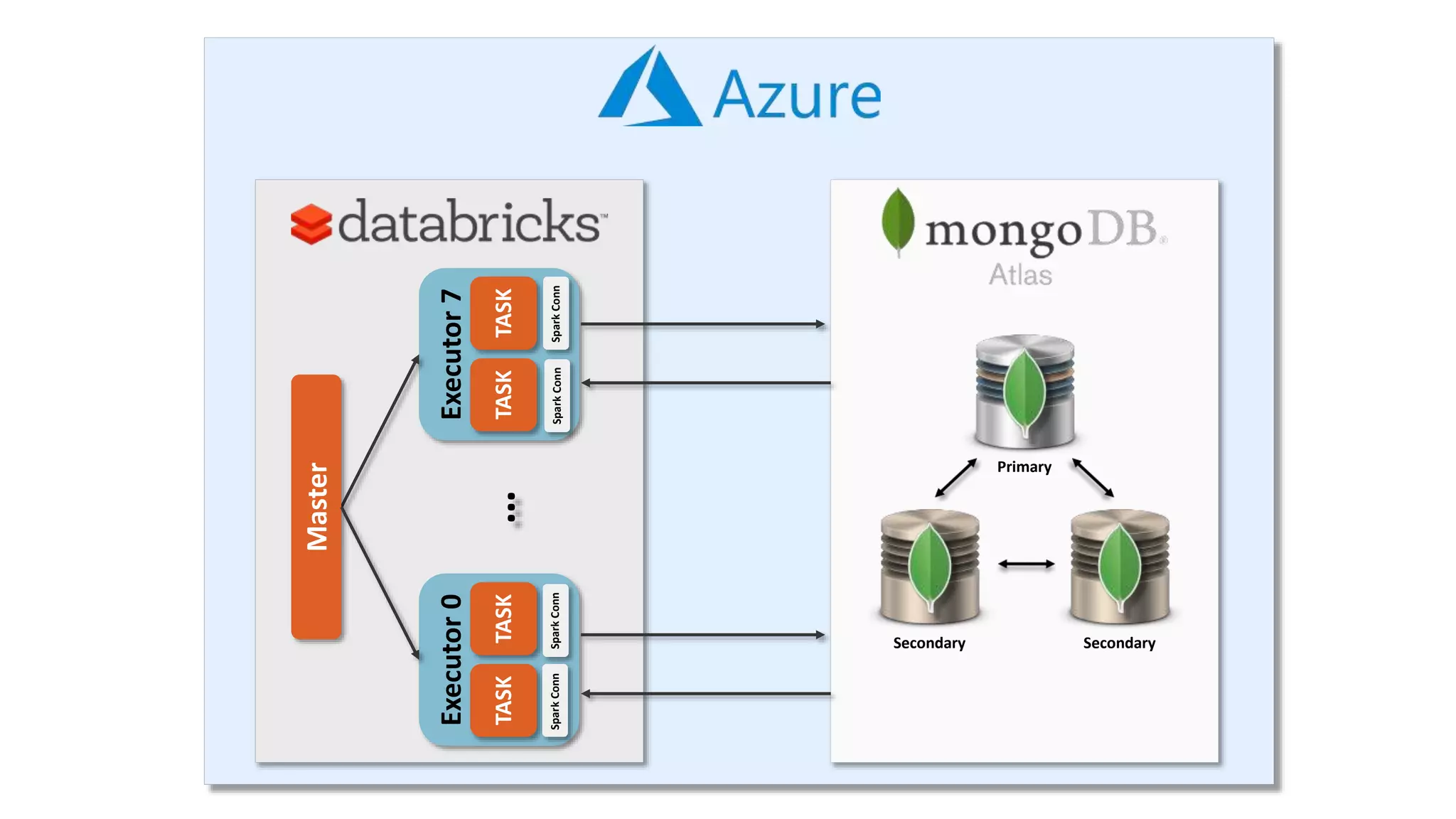

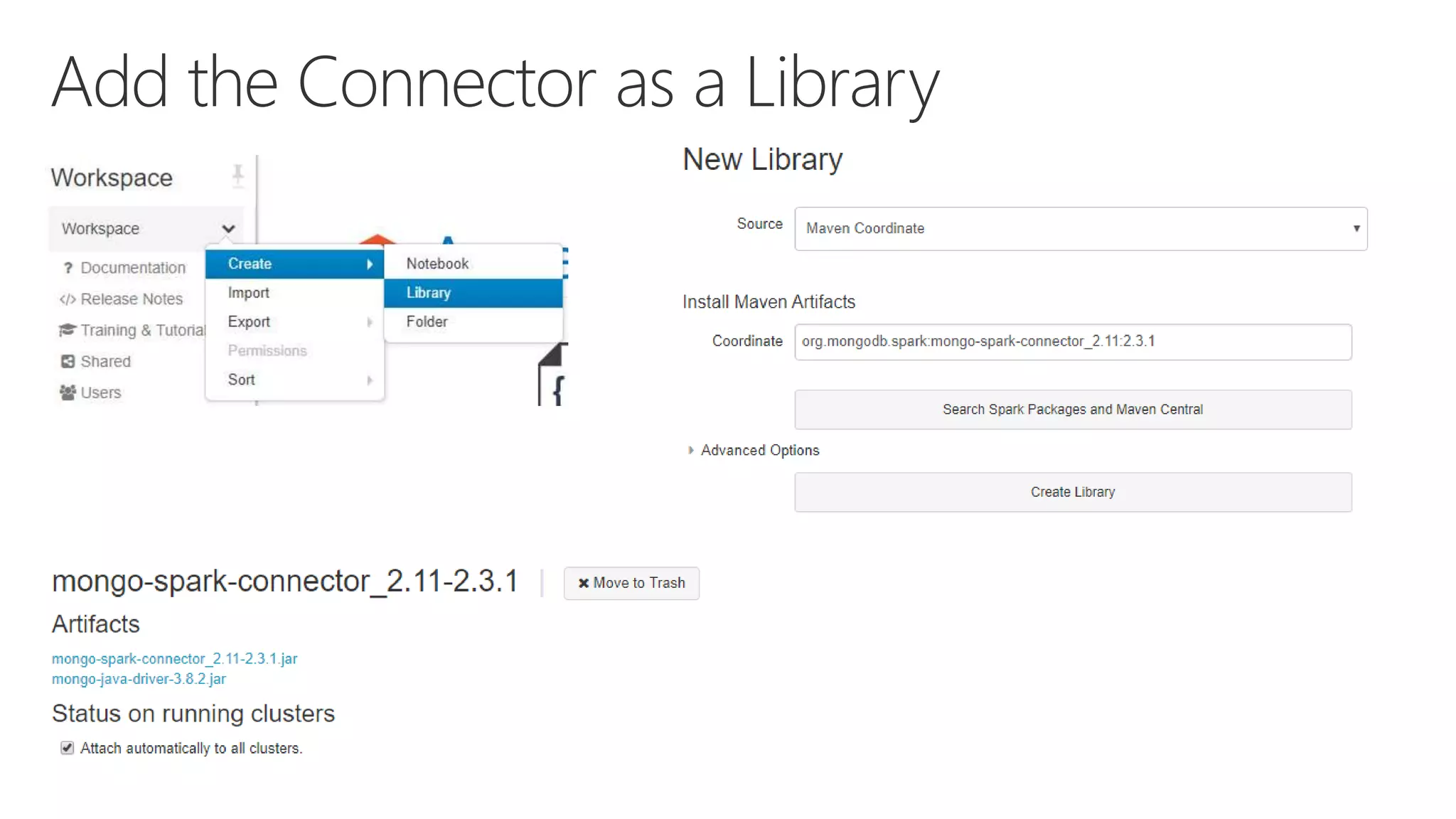
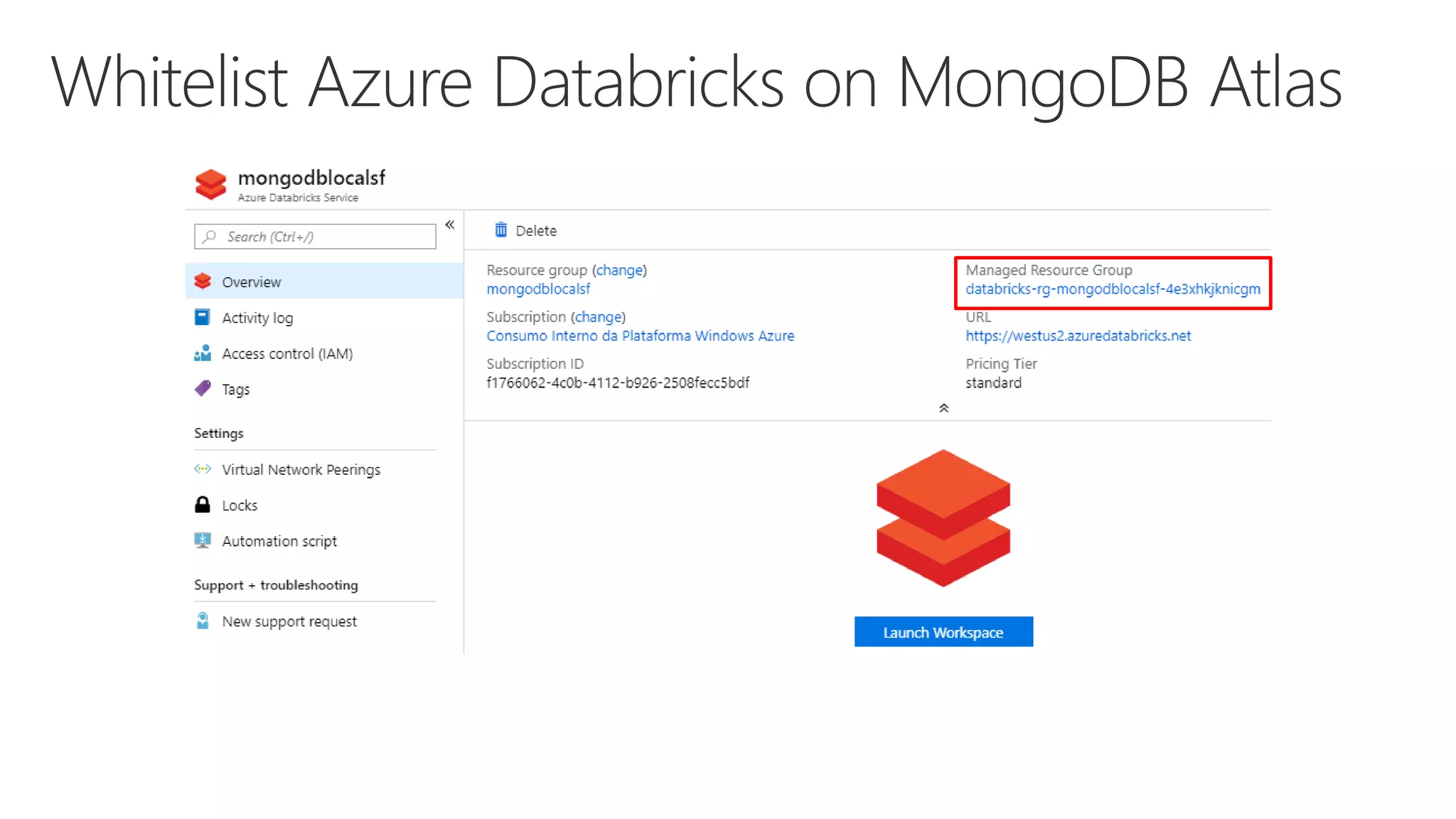
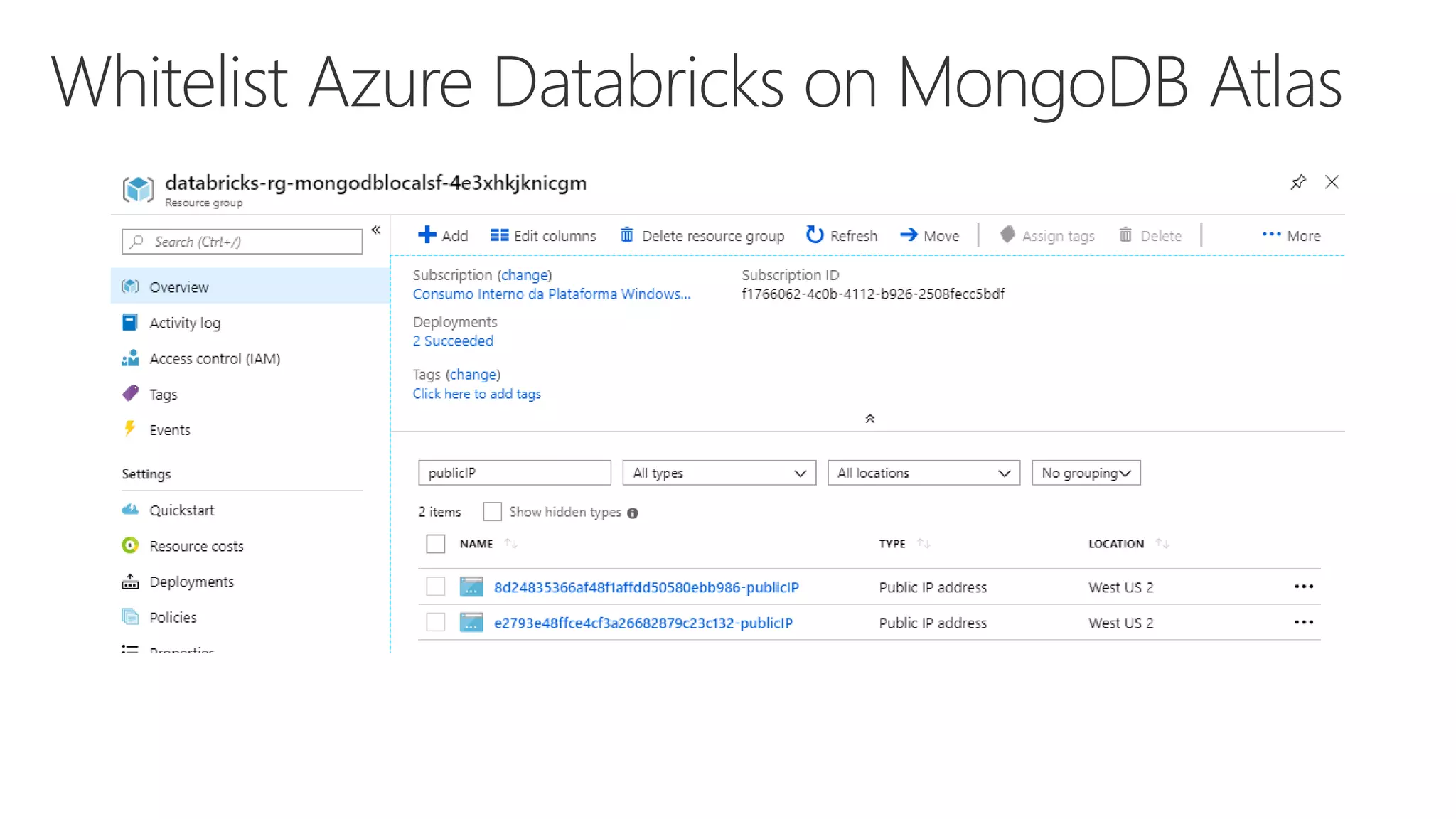
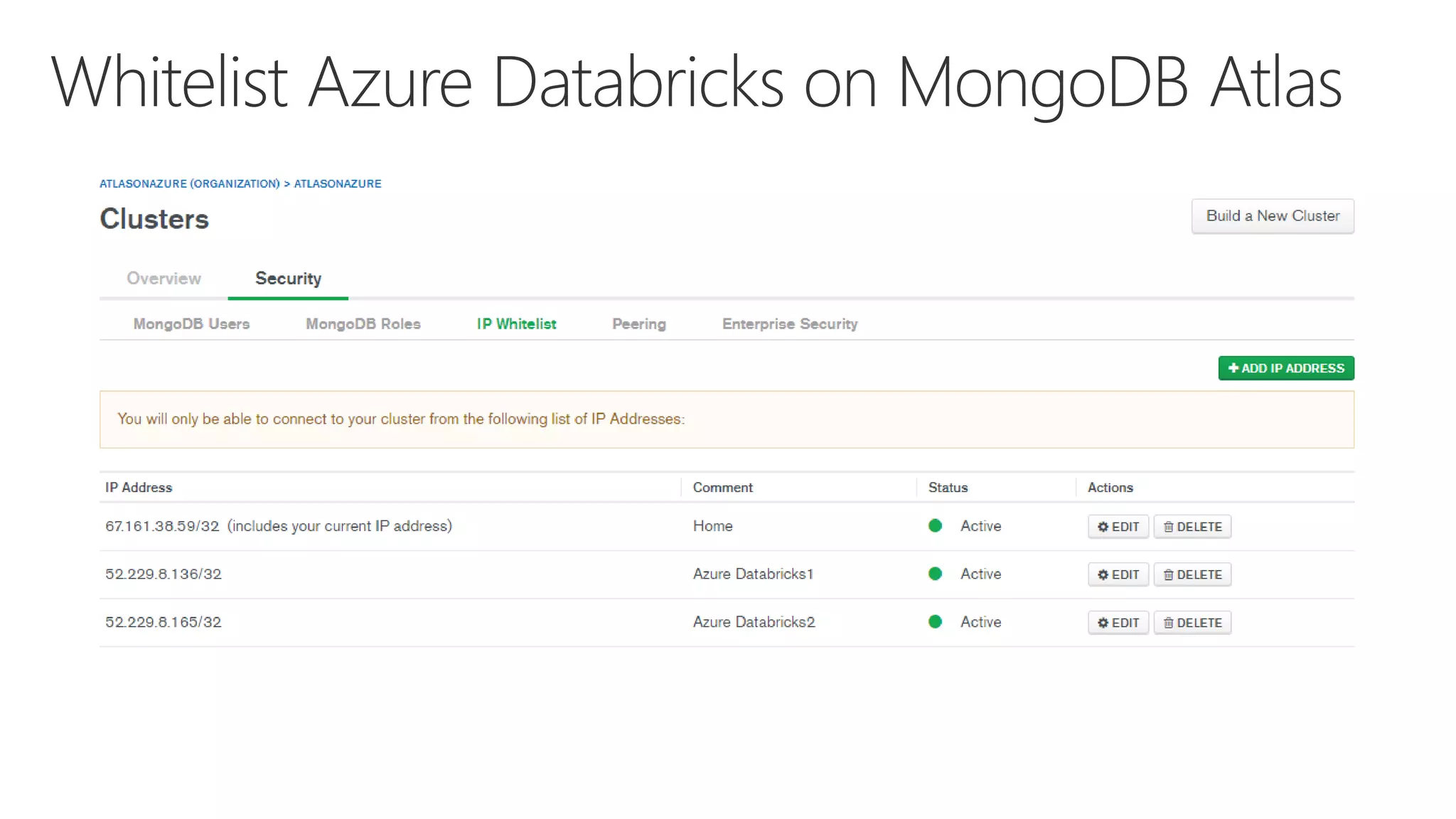
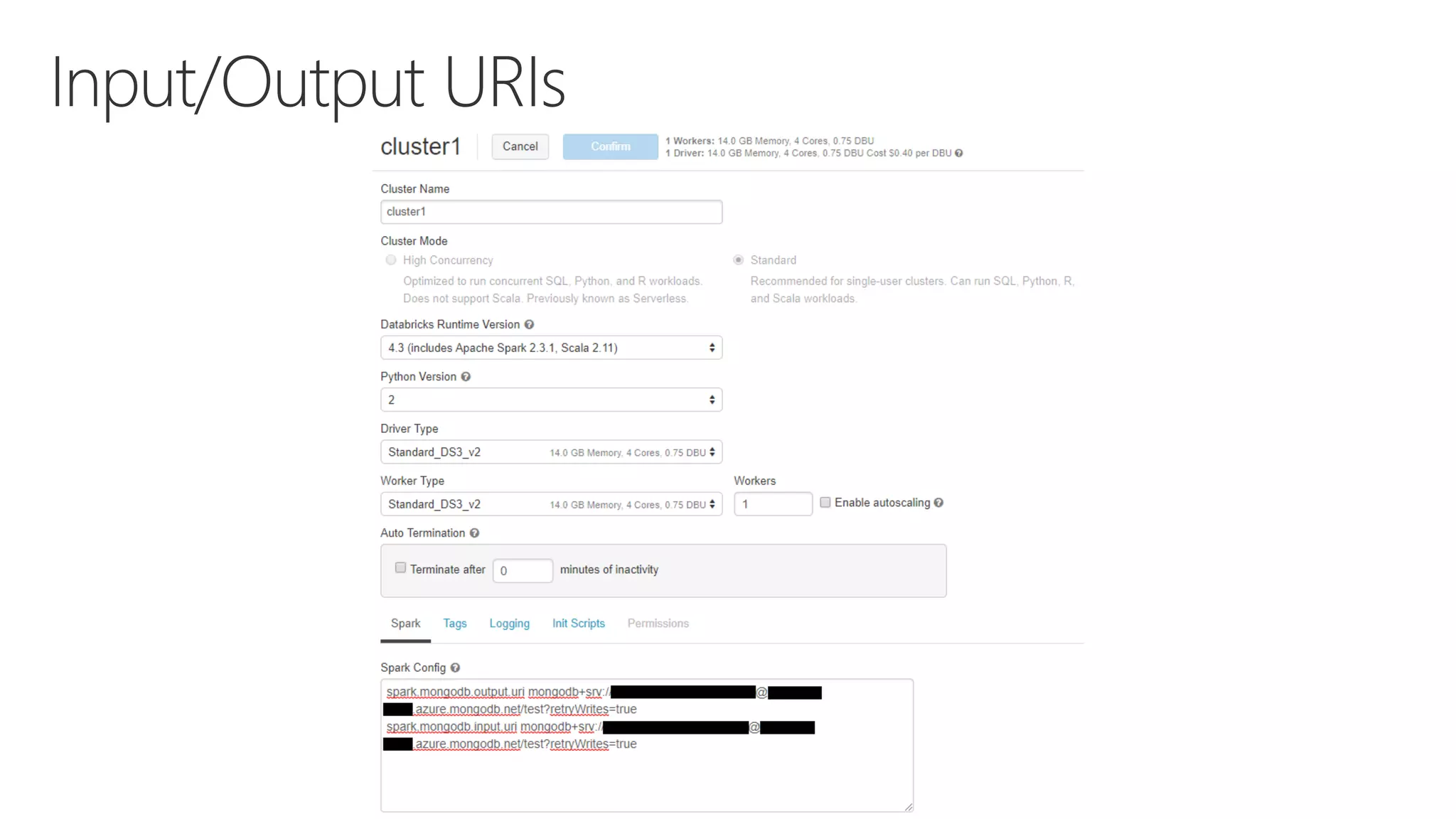




The document outlines various components and features of Apache Spark, including core APIs like RDDs, DataFrames, and Datasets, as well as tools for machine learning and structured streaming. It highlights the integration of Spark with Azure Databricks for optimized performance and productivity enhancements in data processing and warehousing. Additionally, it covers the environment's support for collaborative workspaces, job scheduling, and bi tool integrations.