Downloaded 28 times





















![Index Types ● BTREE - ordered data structure ● HASH - hash table ● PostgreSQL has much more ● Each storage engine can implement any of both ● InnoDB uses BTREE and internally uses HASH when it thinks it’s better ● The syntax CREATE INDEX USING [BTREE | HASH] is generally useless We will focus on BTREE indexes in InnoDB](https://image.slidesharecdn.com/mysqlqueryoptimisation101-190516153520/75/MySQL-Query-Optimisation-101-26-2048.jpg)


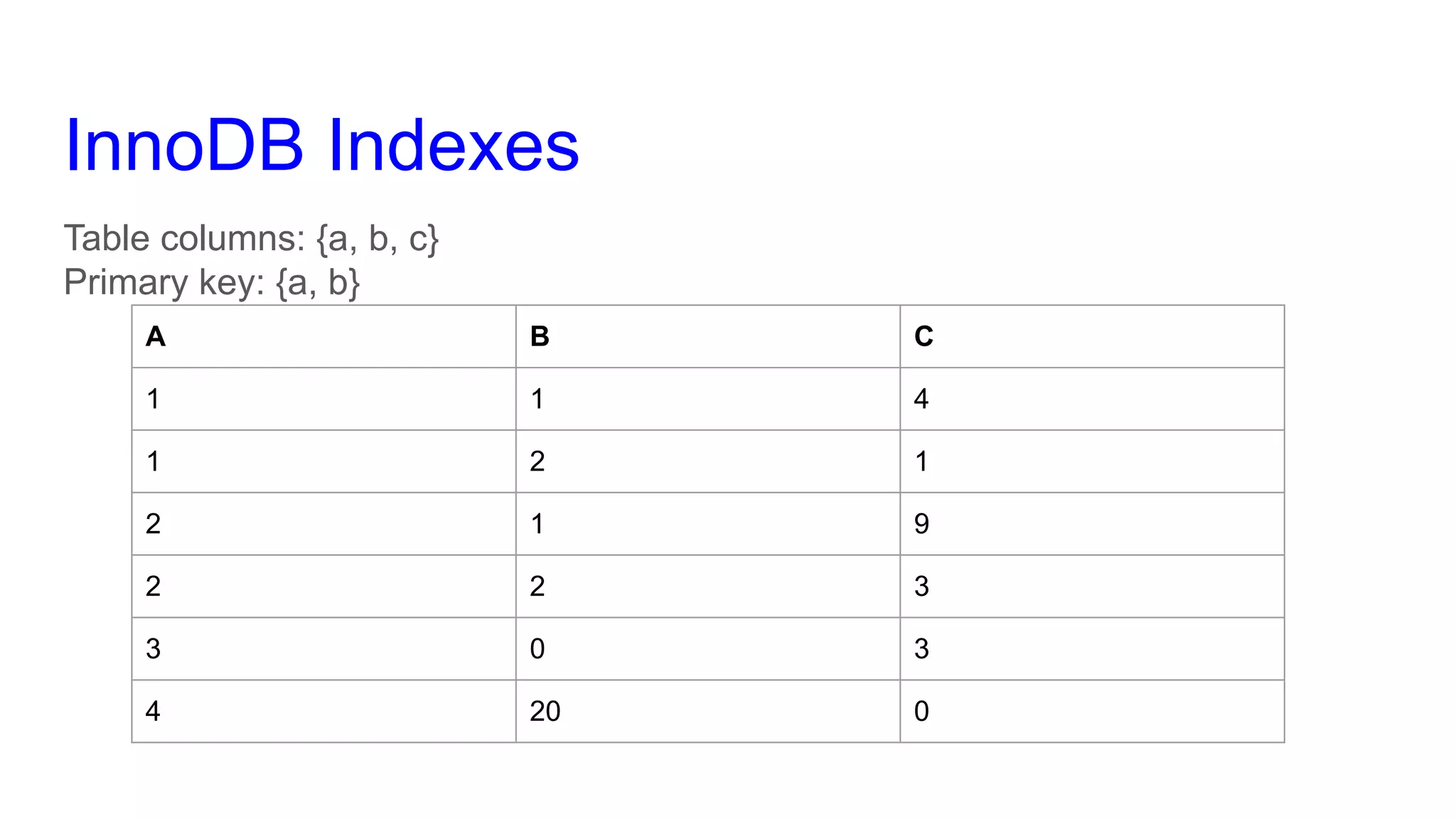

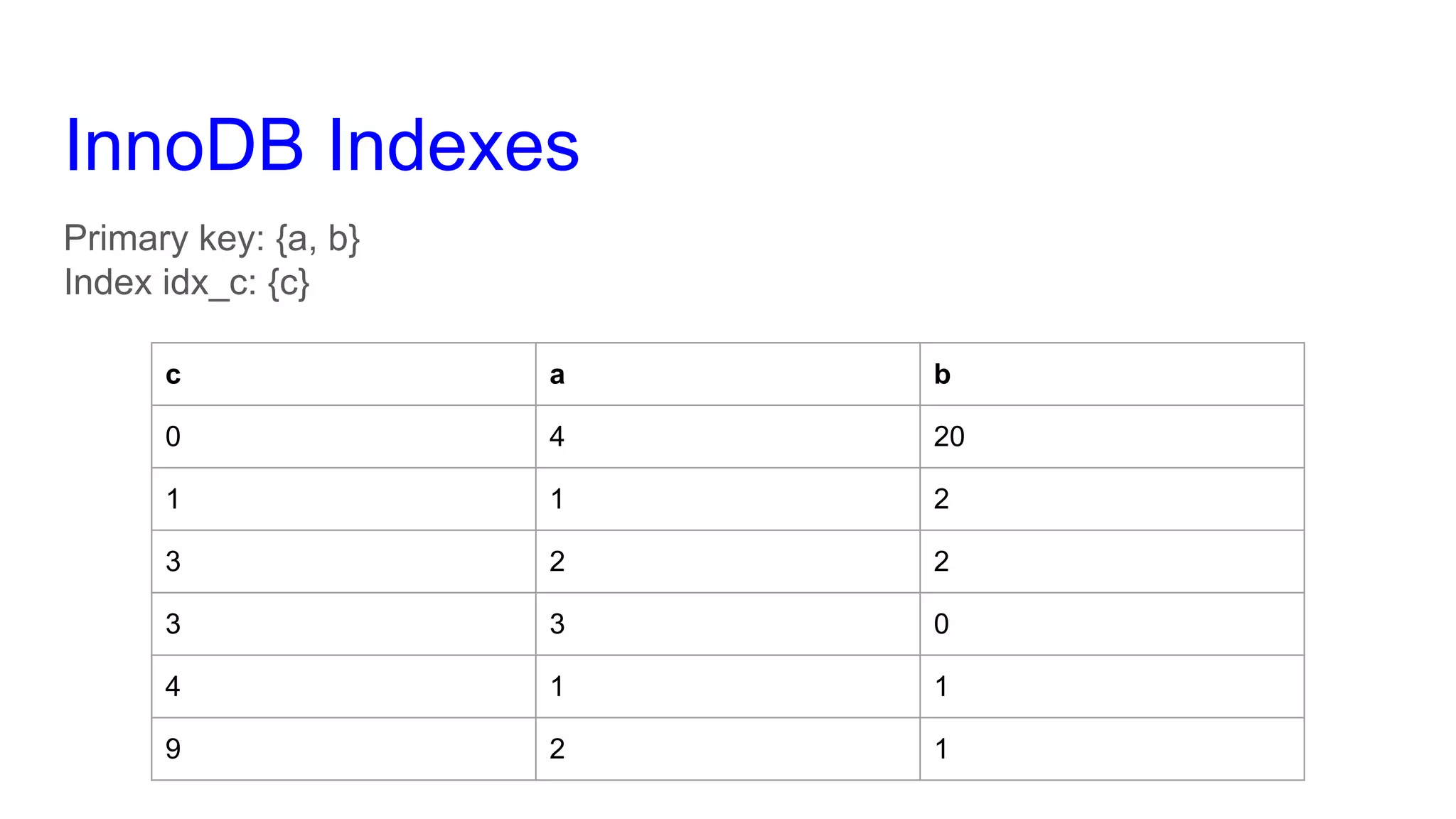

















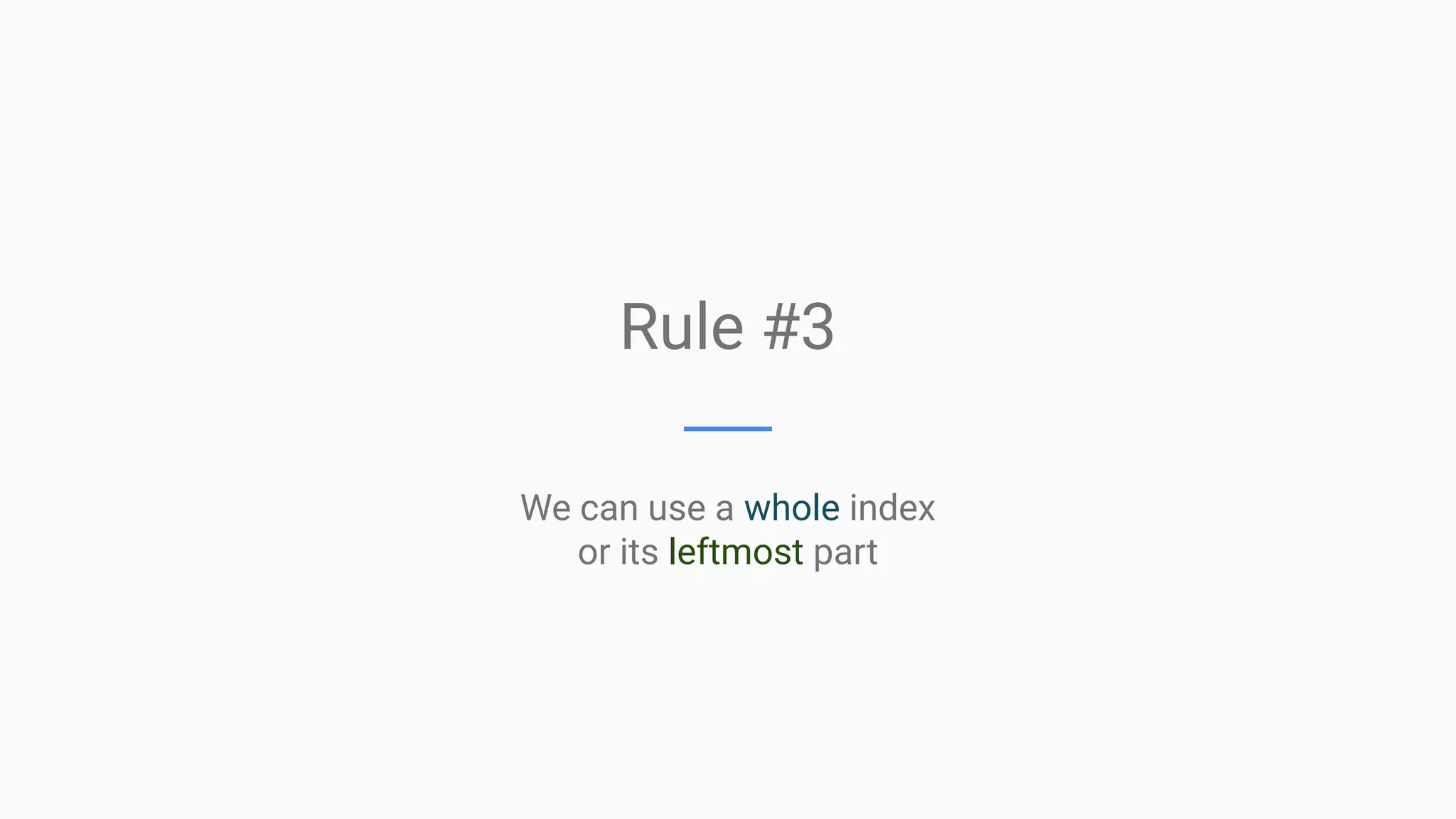





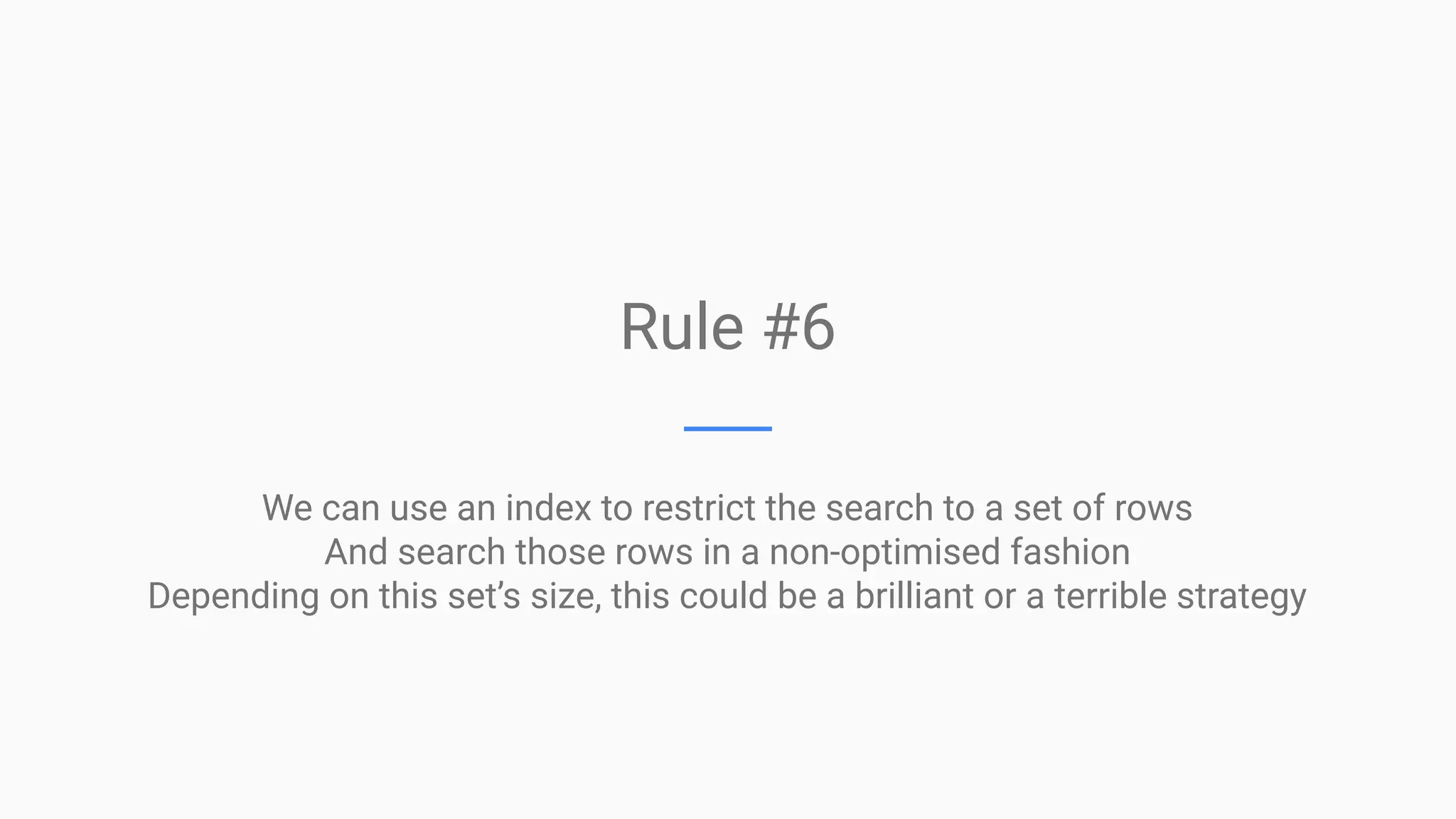















This document provides an overview of MySQL query optimization, highlighting the importance of databases, execution plans, and monitoring strategies for identifying impactful queries. It covers techniques for optimizing queries, such as using indexes effectively, understanding the costs of slowness, and the relationship between query performance and locking. Additionally, it elaborates on different query types, index usage rules, and performance considerations to improve database efficiency.