NoSQL BIg Data Analytics Mongo DB and Cassandra .pdf
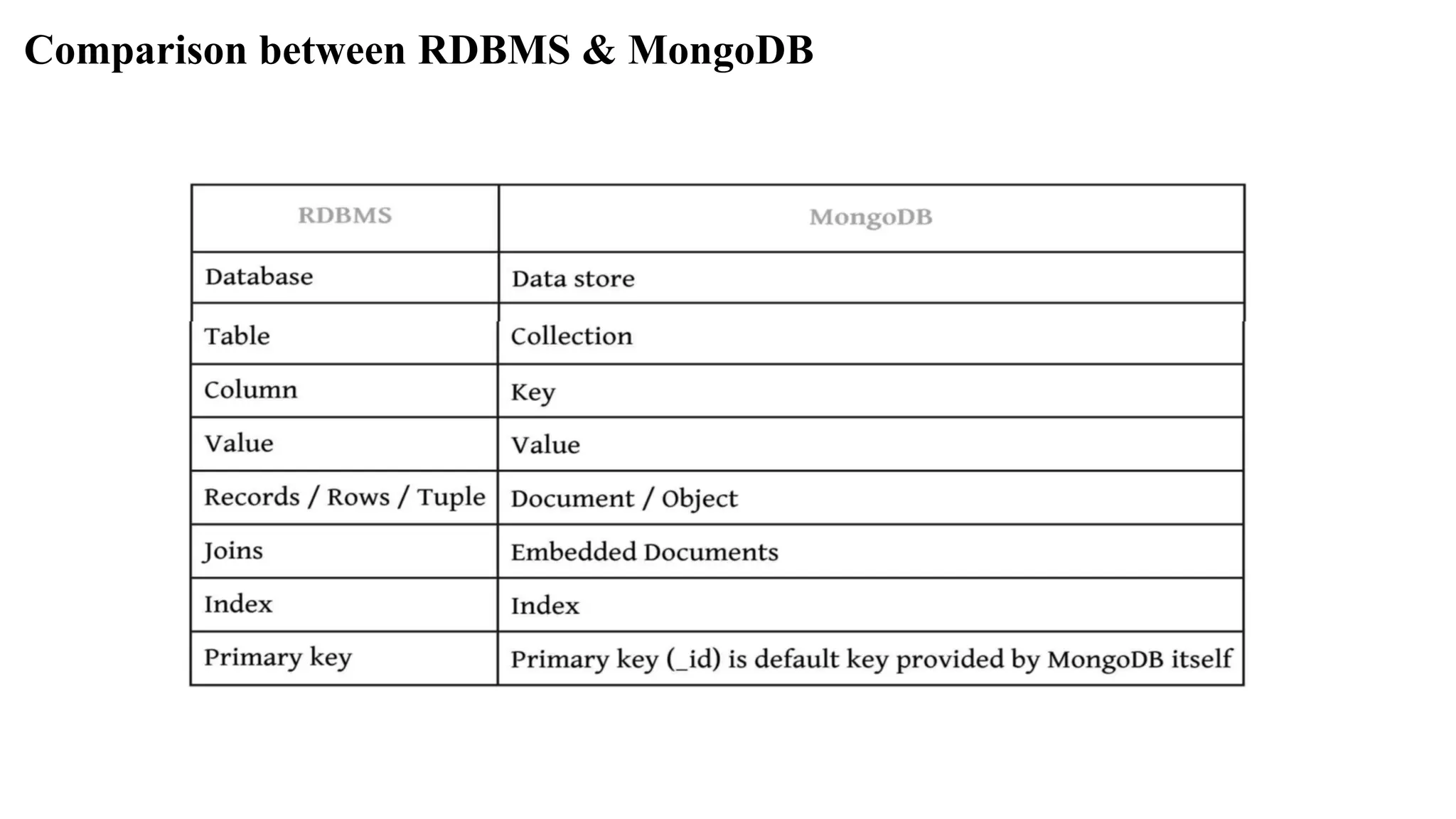
El documento detalla la gestión de datos en sistemas NoSQL y su relación con el Big Data, destacando las características de arquitecturas distribuidas que ofrecen alta disponibilidad, escalabilidad y un modelo sin esquemas fijos. Se discuten los diferentes tipos de bases de datos NoSQL, incluyendo almacenes de clave-valor, documentos, columnas y grafos, cada uno con sus propias ventajas y limitaciones. Además, se abordan problemas comunes en la gestión de Big Data y la falta de estandarización en los sistemas NoSQL, así como su comparación con bases de datos relacionales.
Presenting NoSQL Big Data Management focusing on MongoDB and Cassandra.
Big Data utilizes distributed systems for parallel processing, fault tolerance, and scalability.
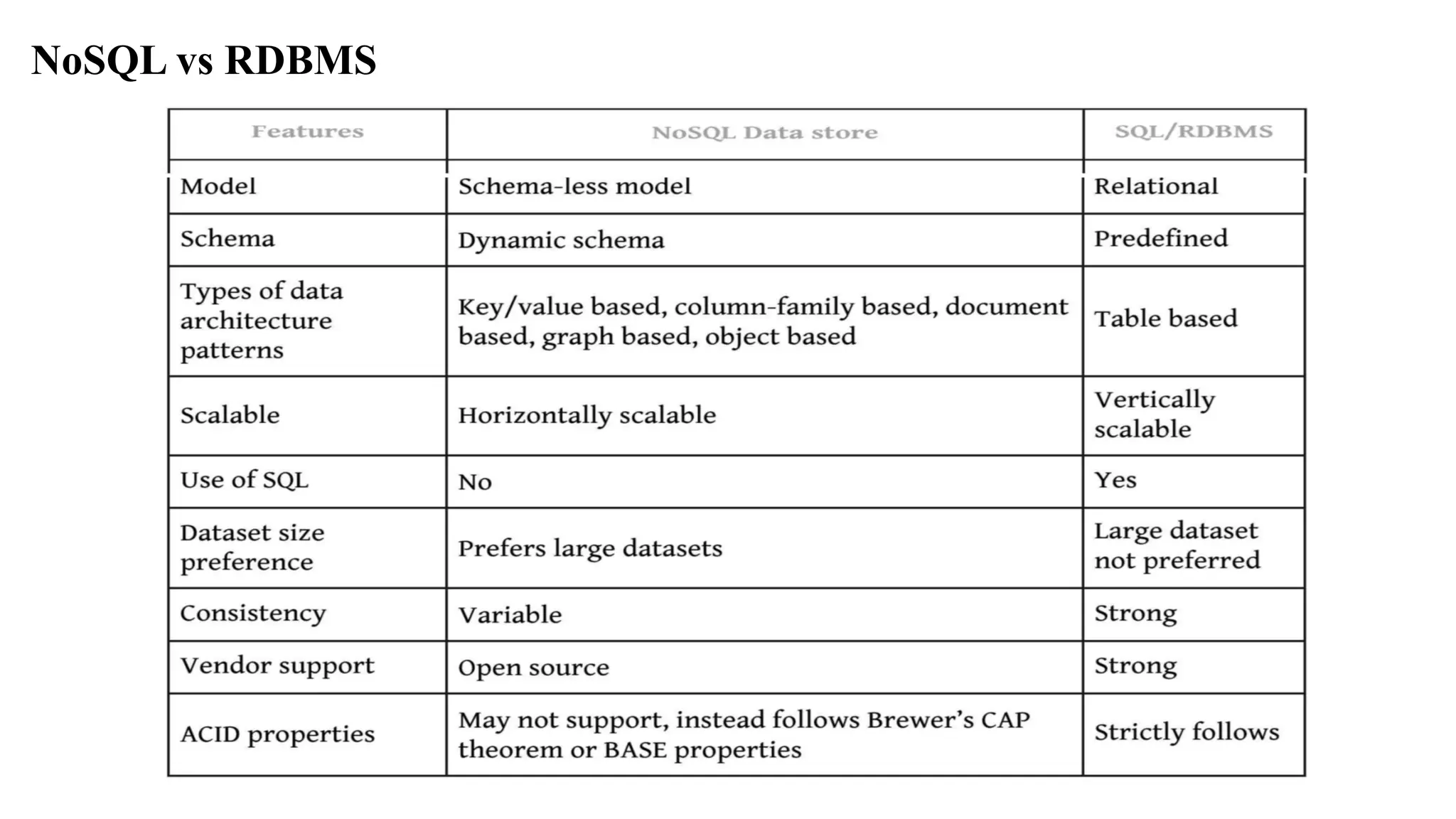
NoSQL databases are non-relational, schema-free systems suitable for handling massive data.
NoSQL databases offer scalability, easy integration, and high availability without rigid schemas.
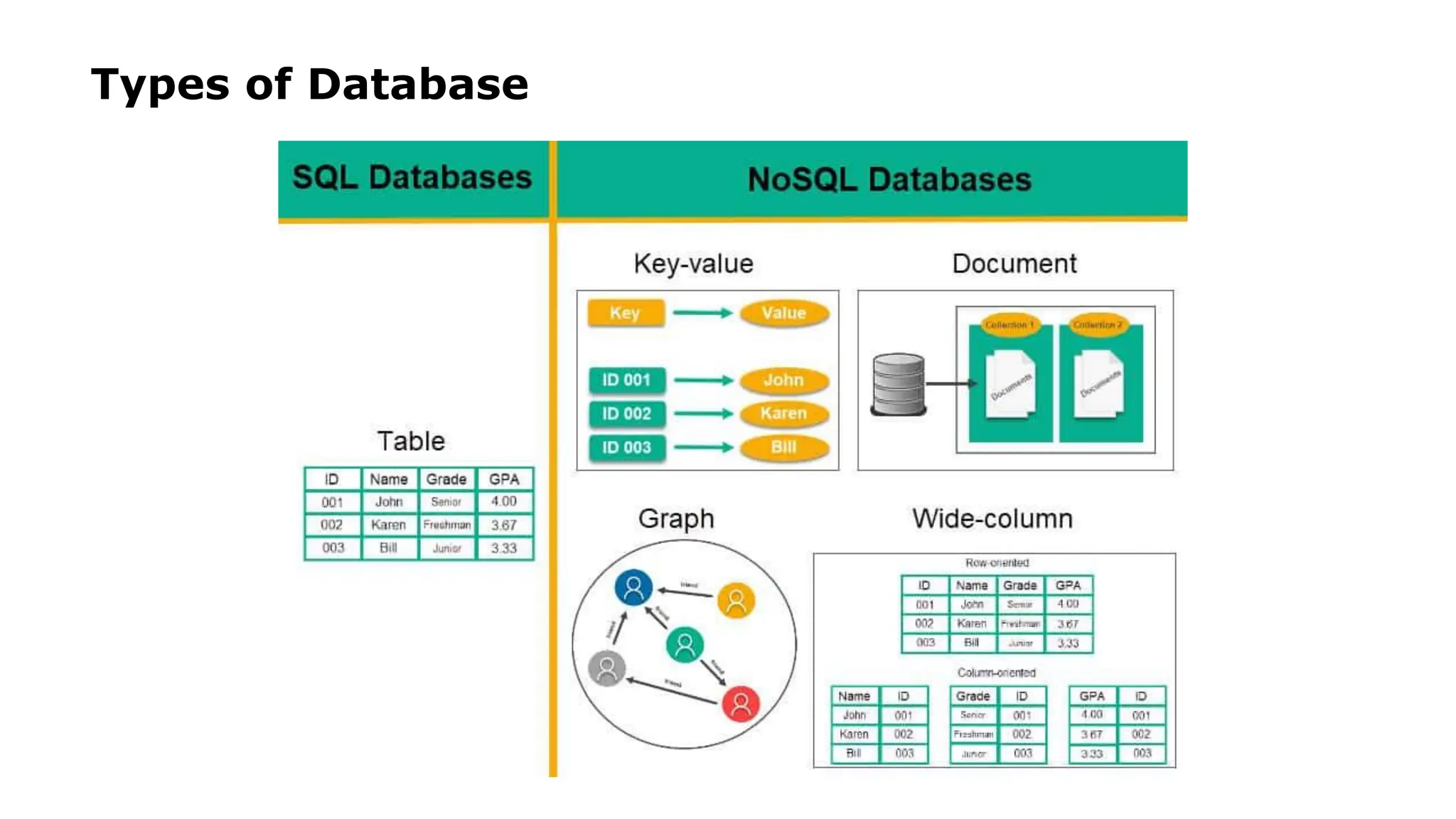
NoSQL databases are classified into key-value, document, column-family, and graph types.
Eventual consistency allows high availability and partition tolerance in distributed NoSQL systems.CAP Theorem states that in distributed databases, consistency, availability, or partition tolerance can be prioritized, but not all three together.
NoSQL databases feature schema-less models allowing late binding and flexibility in data structure.
NoSQL effectively manages big data with high scalability, replication support, and cost efficiency.
Key-value and document stores enable flexibility and high performance for big data workloads.
JSON and XML formats support structured and semi-structured data within NoSQL databases.
CouchDB and MongoDB are notable document stores utilizing JSON for flexible data representation.
Advantages of JSON over XML include easier parsing and support for structured data with arrays.Tabular data storage utilizes rows and columns, improving OLTP and OLAP operations.
Column-family storage enhances performance, partitionability, and availability while simplifying data access.
Object stores manage diverse content and metadata for efficient data handling and retrieval.
Graph databases enable interconnected data management, suitable for social networking and complex relationships.
Shared-nothing architecture supports parallel processing and high availability through independent nodes.
Various distribution models, including sharding and peer-to-peer, enhance data processing efficacy.
Effective data handling strategies involve even distribution, replication, and efficient querying.MongoDB is an open-source, flexible, and scalable document-oriented NoSQL database.
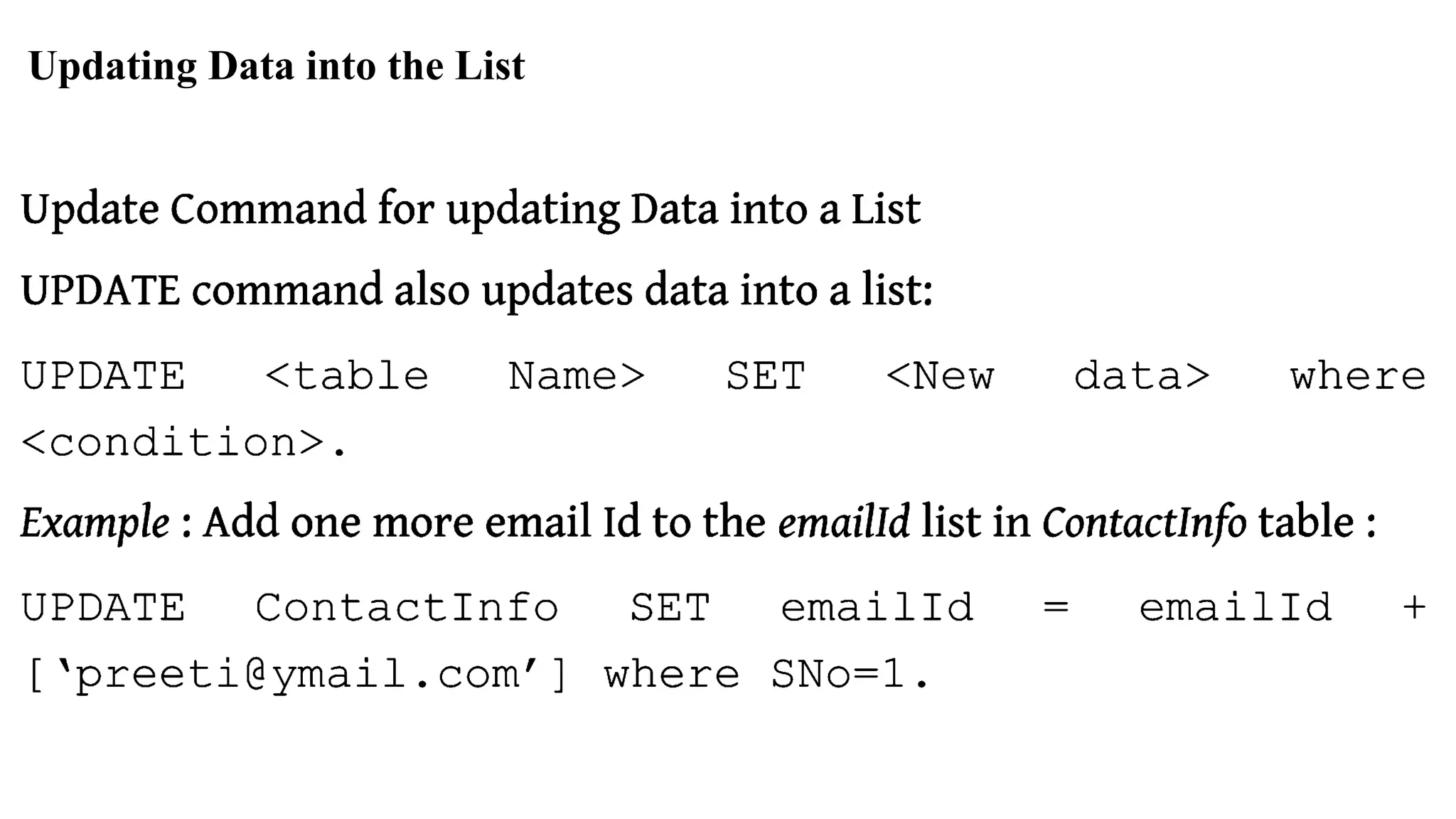
Commands for database management, collection creation, and data manipulation in MongoDB.Cassandra excels in handling large datasets with scalability, distributed architecture, and no single point of failure.
Cassandra Query Language (CQL) facilitates data manipulation and retrieval in a NoSQL setting.
NoSQL BIg Data Analytics Mongo DB and Cassandra .pdf
1.
NoSQLBig Data Management, MongoDBand Cassandra By: Sharmila Chidaravalli Assistant Professor Department of ISE Global Academy of Technology
2.
BIG Data andDistributed Systems Big Data uses distributed systems. A distributed system consists of multiple data nodes at clusters of machines and distributed software components. The tasks execute in parallel with data at nodes in clusters. The computing nodes communicate with the applications through a network.
3.
Features Of Distributed-ComputingArchitecture 1. Increased reliability and fault tolerance: The important advantage of distributed computing system is reliability. If a segment of machines in a cluster fails then the rest of the machines continue work. When the datasets replicate at number of data nodes, the fault tolerance increases further. The dataset in remaining segments continue the same computations as being done at failed segment machines.
4.
Features Of Distributed-ComputingArchitecture 2. Flexibility makes it very easy to install, implement and debug new services in a distributed environment. 3. Sharding is storing the different parts of data onto different sets of data nodes, clusters or servers. 4. Speed: Computing power increases in a distributed computing system as shards run parallelly on individual data nodes in clusters independently (no data sharing between shards). 5. Scalability: Consider sharding of a large database into a number of shards, distributed for computing in different systems. When the database expands further, then adding more machines and increasing the number of shards provides horizontal scalability.
5.
Features Of Distributed-ComputingArchitecture 6. Resources sharing: Shared resources of memory, machines and network architecture reduce the cost. 7. Open system makes the service accessible to all nodes. 8. Performance: The collection of processors in the system provides higher performance than a centralized computer, due to lesser cost of communication among machines (Cost means time taken up in communication).
6.
What is NoSQL? NoSQLDatabase is a non-relational Data Management System, that does not require a fixed schema. It avoids joins, and is easy to scale. The major purpose of using a NoSQL database is for distributed data stores with humongous data storage needs. NoSQL is used for Big data and real-time web apps. example, companies like Twitter, Facebook and Google collect terabytes of user data every single day.
7.
What is NoSQL? NoSQLdatabase stands for "Not Only SQL" or "Not SQL." Though a better term would be "NoREL", NoSQL caught on. Carl Strozz introduced the NoSQL concept in 1998. Traditional RDBMS uses SQL syntax to store and retrieve data for further insights. Instead, a NoSQL database system encompasses a wide range of database technologies that can store structured, semi-structured, unstructured and polymorphic data
8.
What is NoSQL? NoSQLis a new approach of thinking about databases, such as schema flexibility, simple relationships, dynamic schemas, auto sharding, replication, integrated caching, horizontal scalability of shards, distributable tuples, semi-structures data flexibility in approach. NoSQL DB does not require specialized RDBMS like storage and hardware for processing. Storage can be on a cloud.
9.
What is NoSQL? Issueswith NoSQL lack of standardization in approaches, processing difficulties for complex queries.
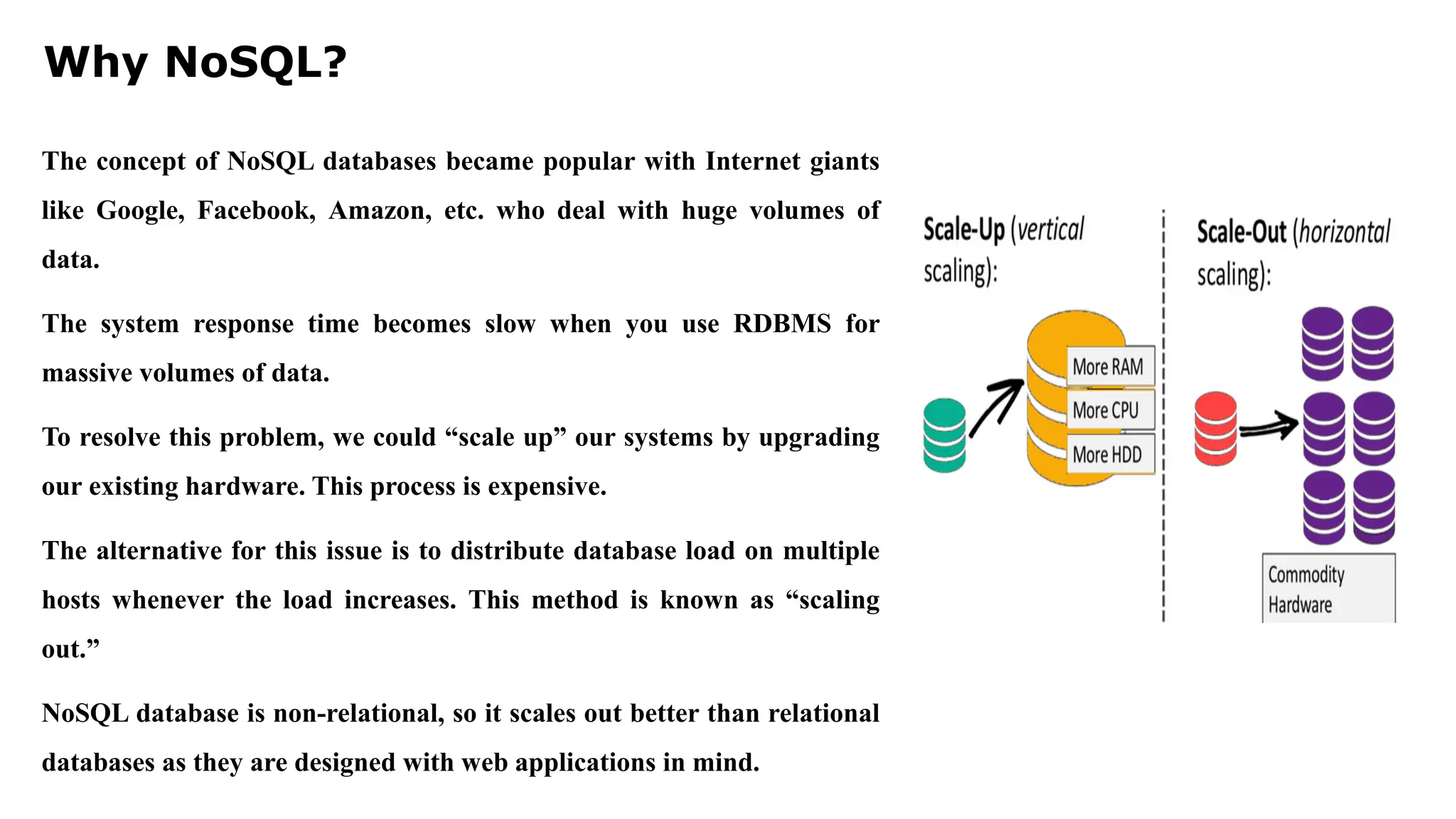
Why NoSQL? The conceptof NoSQL databases became popular with Internet giants like Google, Facebook, Amazon, etc. who deal with huge volumes of data. The system response time becomes slow when you use RDBMS for massive volumes of data. To resolve this problem, we could “scale up” our systems by upgrading our existing hardware. This process is expensive. The alternative for this issue is to distribute database load on multiple hosts whenever the load increases. This method is known as “scaling out.” NoSQL database is non-relational, so it scales out better than relational databases as they are designed with web applications in mind.
Features of NoSQL Non-relational NoSQLdatabases never follow the relational model Never provide tables with flat fixed-column records Work with self-contained aggregates or BLOBs Doesn’t require object-relational mapping and data normalization No complex features like query languages, query planners, referential integrity joins, ACID
14.
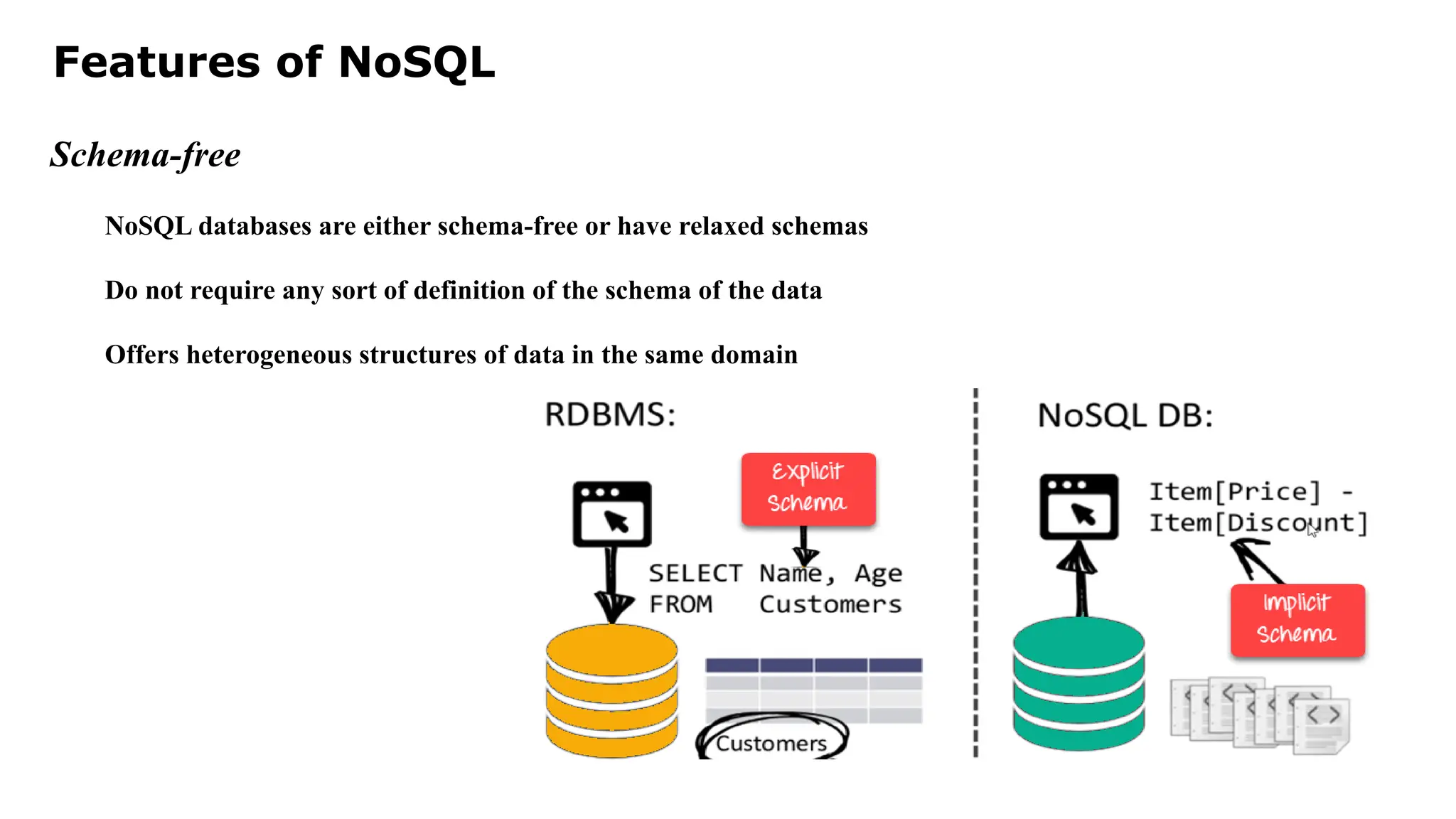
Features of NoSQL Schema-free NoSQLdatabases are either schema-free or have relaxed schemas Do not require any sort of definition of the schema of the data Offers heterogeneous structures of data in the same domain
15.
Features of NoSQL SimpleAPI Offers easy to use interfaces for storage and querying data provided APIs allow low-level data manipulation & selection methods Text-based protocols mostly used with HTTP REST with JSON Mostly used no standard based NoSQL query language Web-enabled databases running as internet-facing services
16.
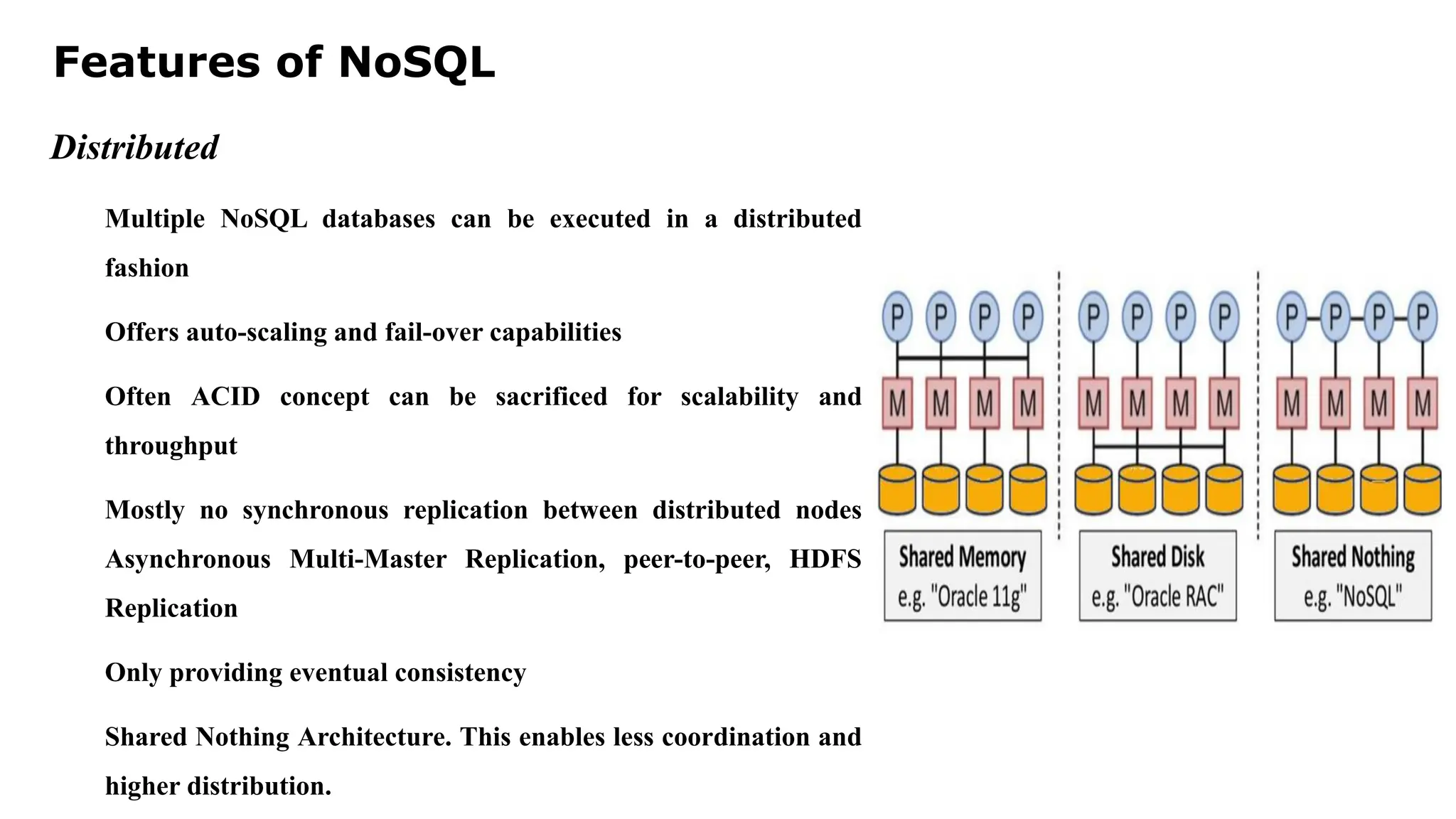
Features of NoSQL Distributed MultipleNoSQL databases can be executed in a distributed fashion Offers auto-scaling and fail-over capabilities Often ACID concept can be sacrificed for scalability and throughput Mostly no synchronous replication between distributed nodes Asynchronous Multi-Master Replication, peer-to-peer, HDFS Replication Only providing eventual consistency Shared Nothing Architecture. This enables less coordination and higher distribution.
17.
Types of NoSQLDatabases NoSQL databases can be classified into four types 1.Key-Value Stores 2.Document Stores 3.Column based data stores 4.Graph Databases Every category has its unique attributes and limitations. None of the above-specified database is better to solve all the problems. Users should select the database based on their product needs.
18.
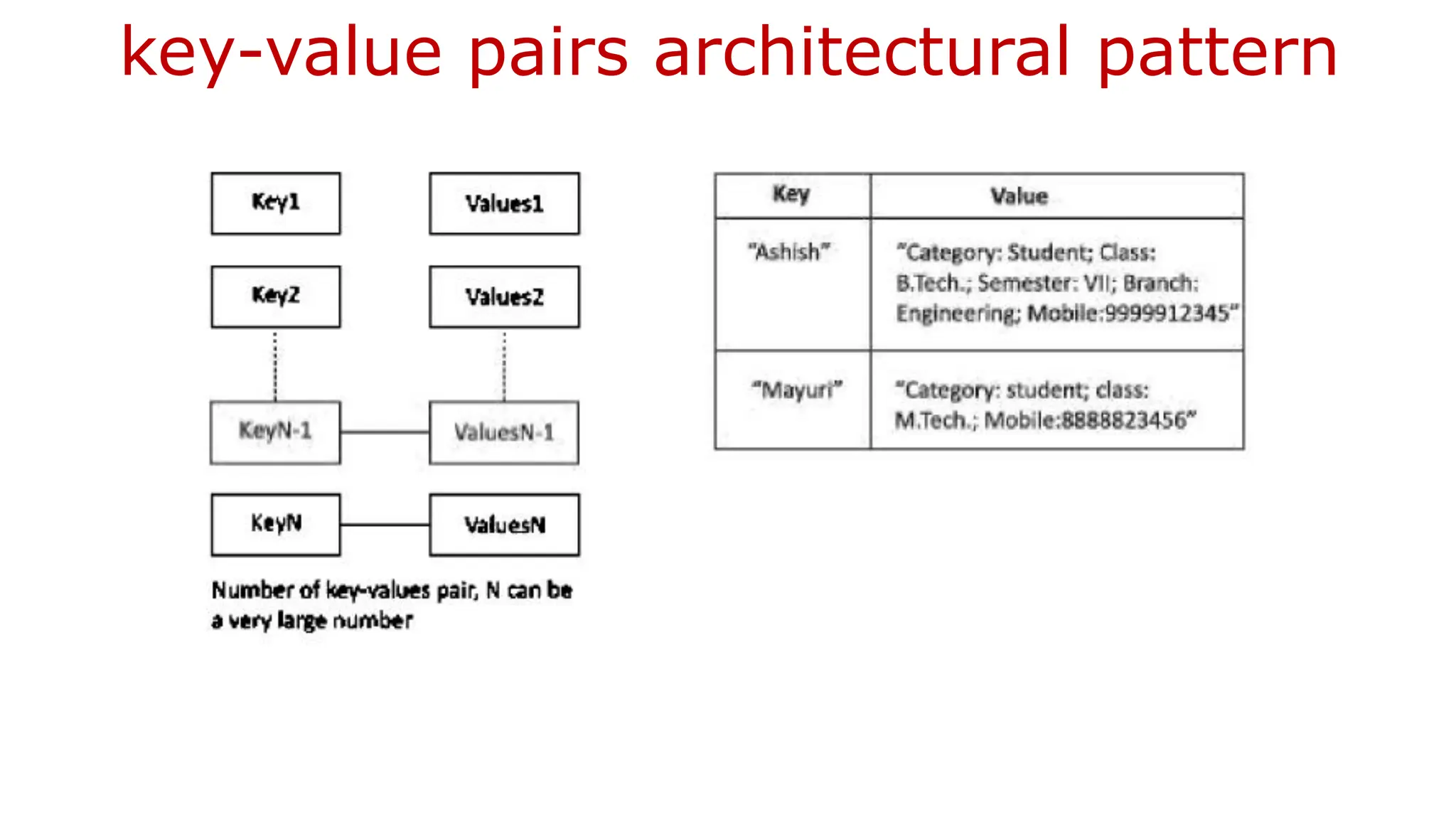
Key Value PairBased Key-value databases are the simplest type of NoSQL database. These NoSQL databases have a dictionary data structure that consists of a set of objects that represent fields of data. Each object is assigned a unique key. To retrieve data stored in a particular object, you need to use a specific key. In turn, you get the value assigned to the key. This value can be a number, a string, or even another set of key-value pairs. Unlike traditional relational databases, key-value databases do not require a predefined structure. They offer more flexibility when storing data and have faster performance. Without having to rely on placeholders, key-value databases are a lighter solution as they require fewer resources.
19.
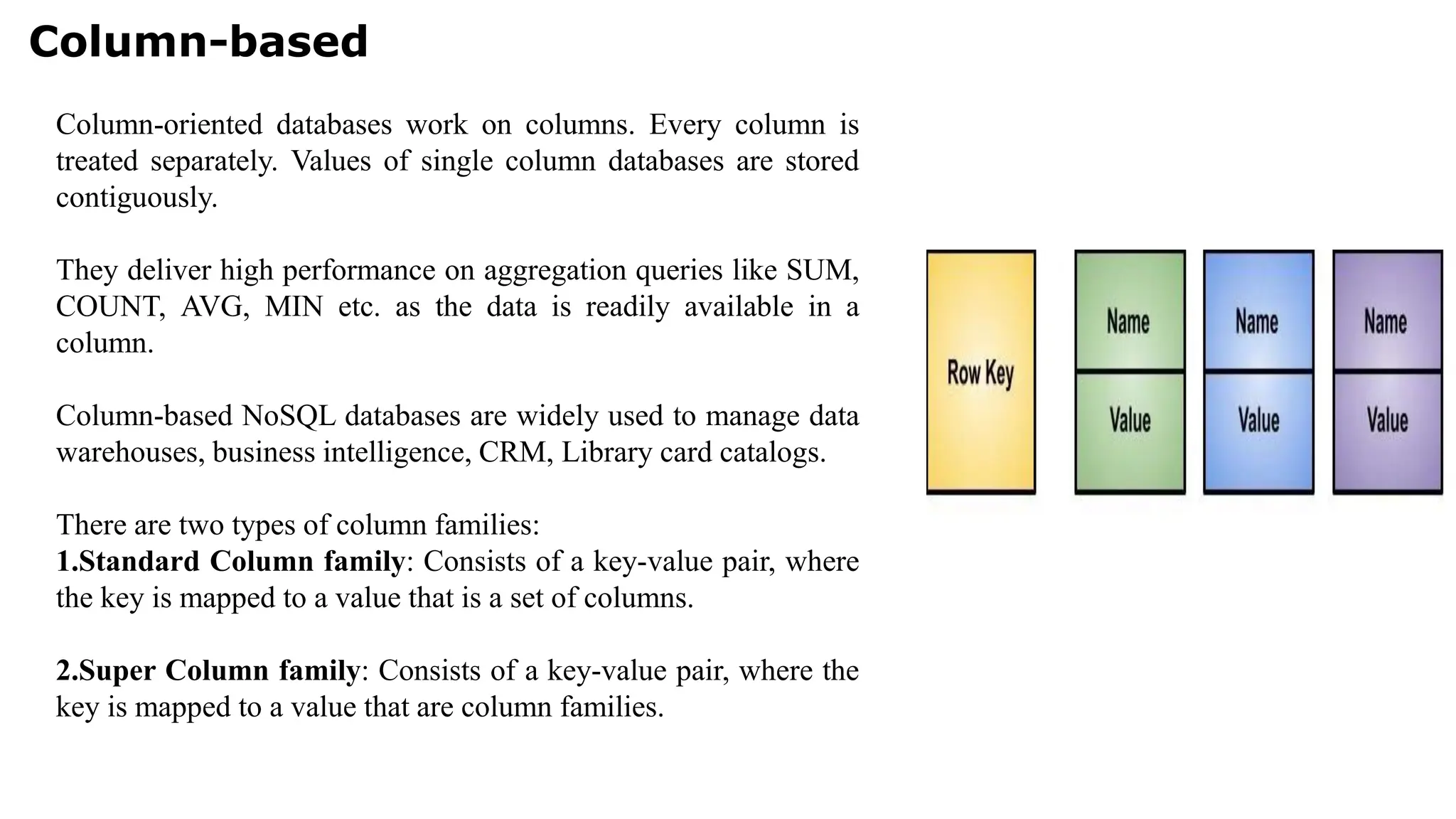
Column-based Column-oriented databases workon columns. Every column is treated separately. Values of single column databases are stored contiguously. They deliver high performance on aggregation queries like SUM, COUNT, AVG, MIN etc. as the data is readily available in a column. Column-based NoSQL databases are widely used to manage data warehouses, business intelligence, CRM, Library card catalogs. There are two types of column families: 1.Standard Column family: Consists of a key-value pair, where the key is mapped to a value that is a set of columns. 2.Super Column family: Consists of a key-value pair, where the key is mapped to a value that are column families.
20.
Document-Oriented Document-Oriented NoSQL DBstores and retrieves data as a key value pair but the value part is stored as a document. The document is stored in JSON or XML formats. The value is understood by the DB and can be queried. For a document database, you have data store like JSON object. You do not require to define which make it flexible. The document type is mostly used for CMS systems, blogging platforms, real-time analytics & e-commerce applications. It should not use for complex transactions which require multiple operations or queries against varying aggregate structures.
21.
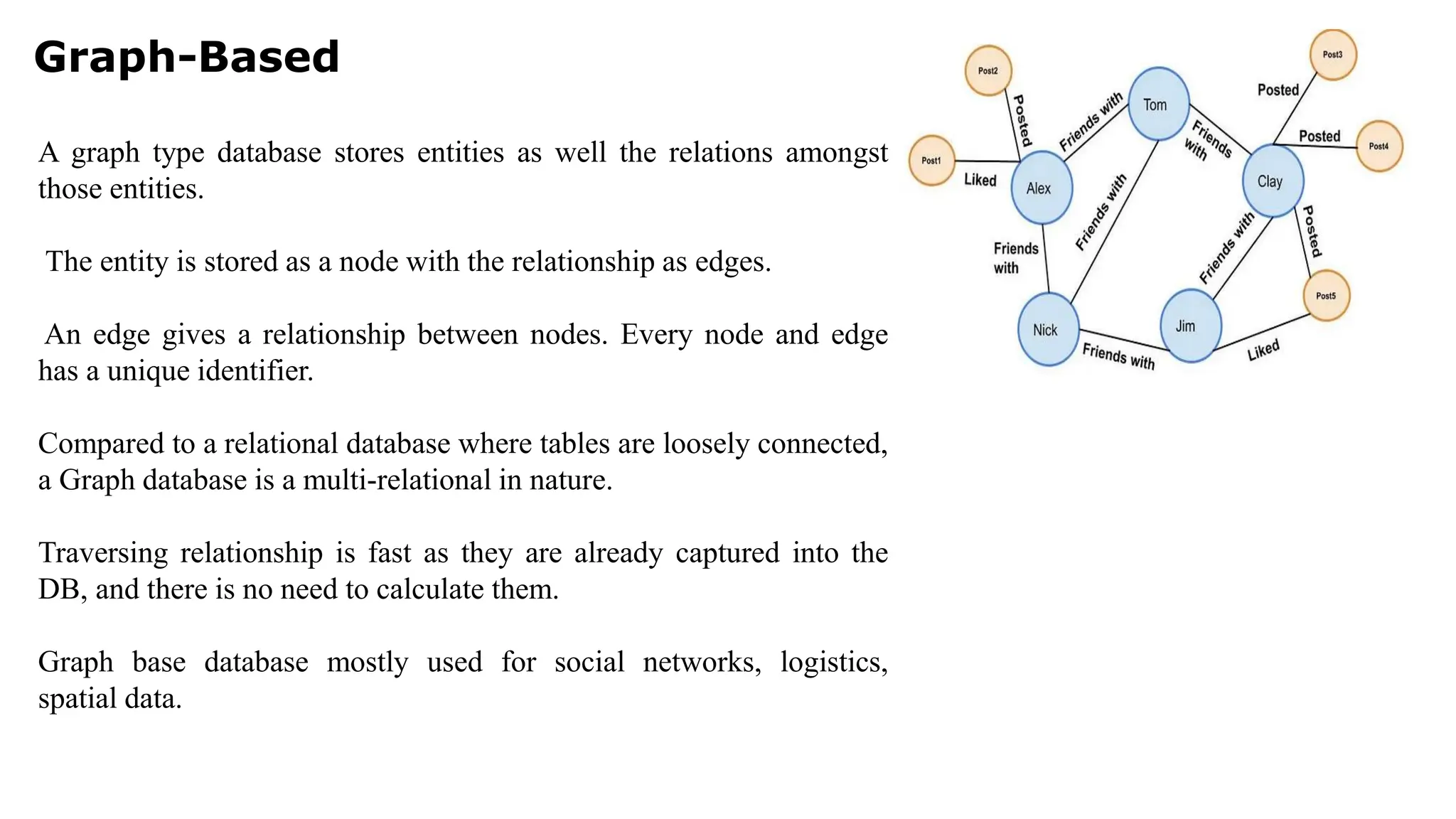
Graph-Based A graph typedatabase stores entities as well the relations amongst those entities. The entity is stored as a node with the relationship as edges. An edge gives a relationship between nodes. Every node and edge has a unique identifier. Compared to a relational database where tables are loosely connected, a Graph database is a multi-relational in nature. Traversing relationship is fast as they are already captured into the DB, and there is no need to calculate them. Graph base database mostly used for social networks, logistics, spatial data.
22.
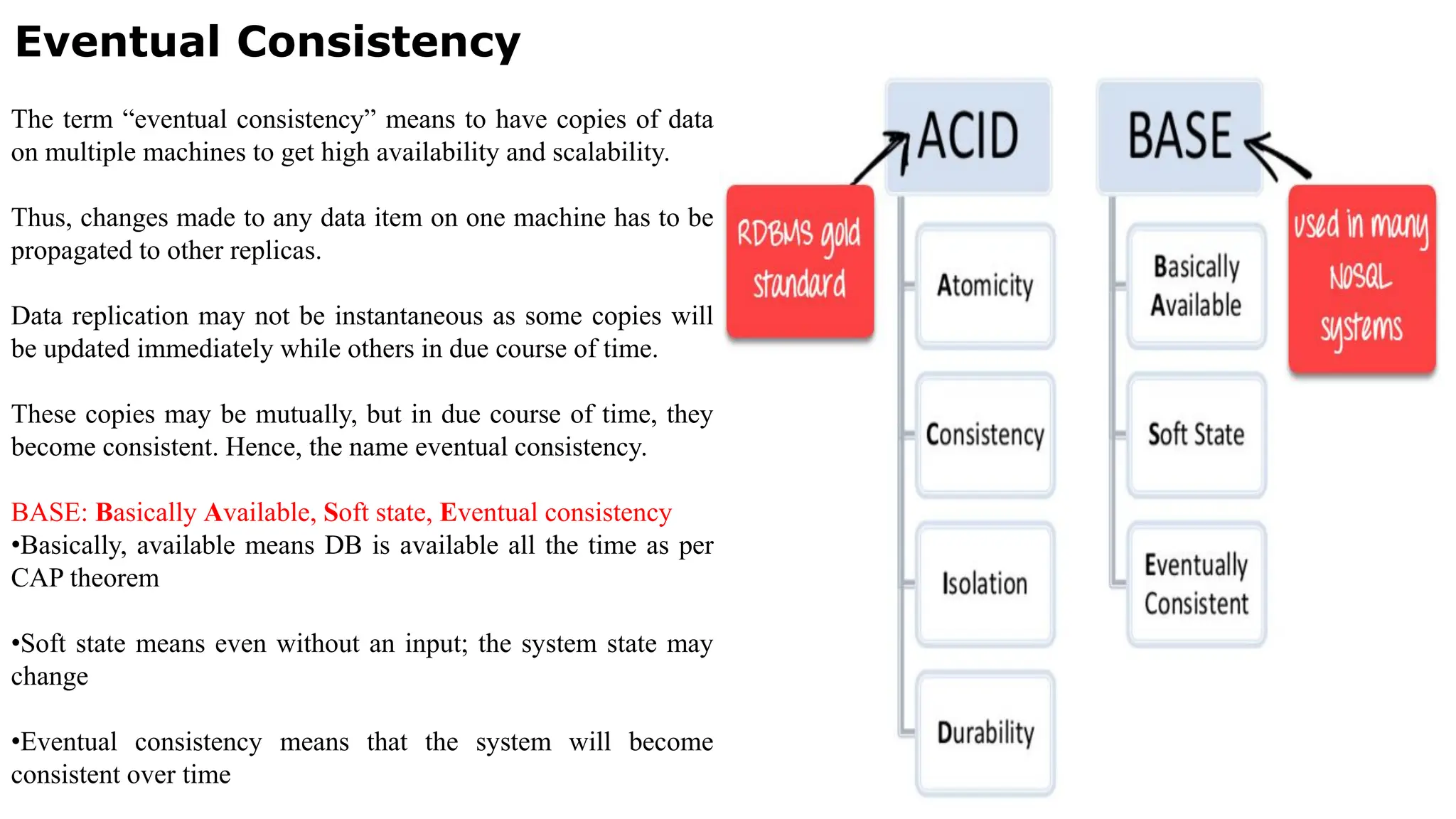
Eventual Consistency The term“eventual consistency” means to have copies of data on multiple machines to get high availability and scalability. Thus, changes made to any data item on one machine has to be propagated to other replicas. Data replication may not be instantaneous as some copies will be updated immediately while others in due course of time. These copies may be mutually, but in due course of time, they become consistent. Hence, the name eventual consistency. BASE: Basically Available, Soft state, Eventual consistency •Basically, available means DB is available all the time as per CAP theorem •Soft state means even without an input; the system state may change •Eventual consistency means that the system will become consistent over time
23.
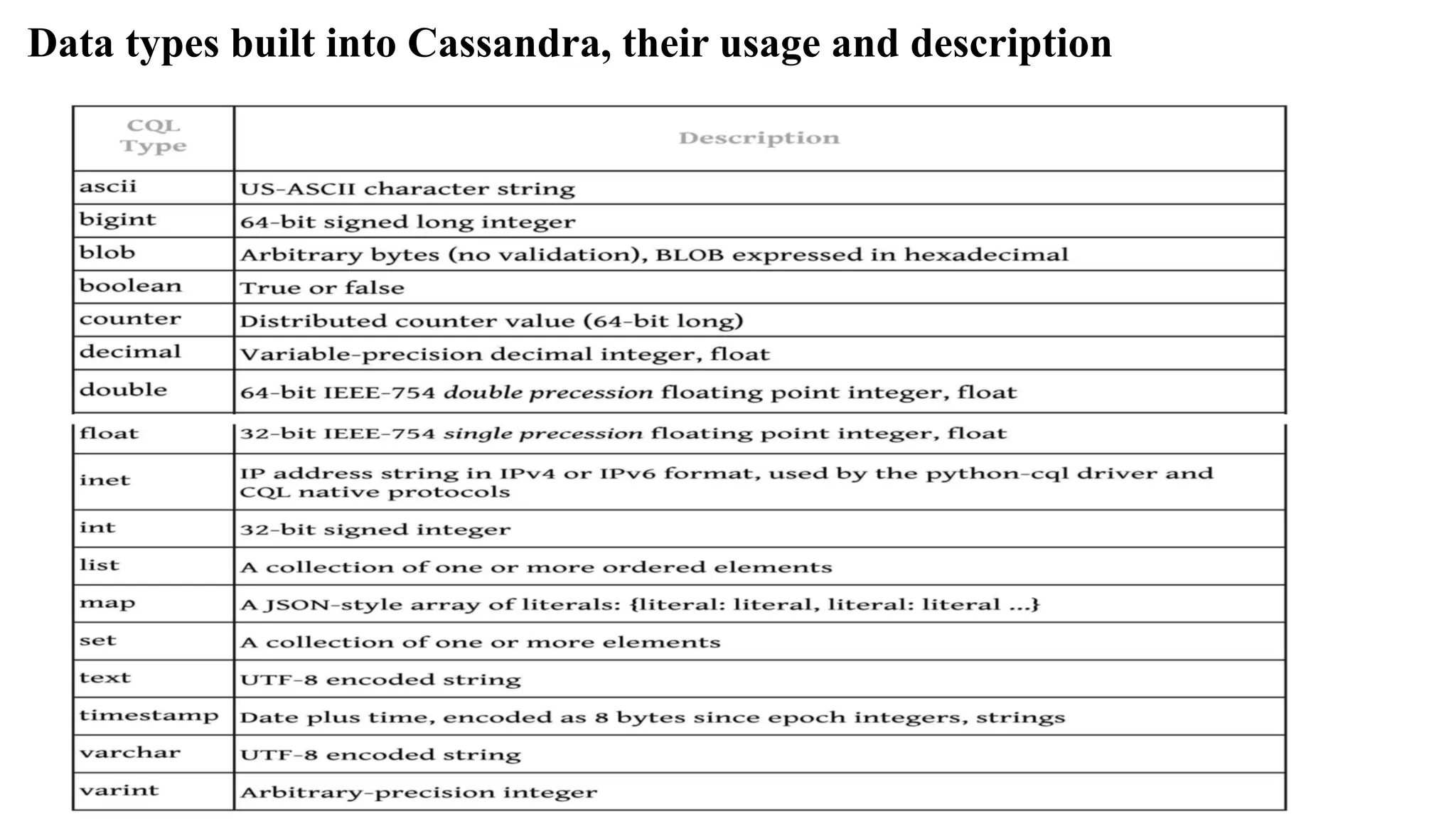
NoSQL data storecharacteristics are as follows: 1. NoSQL is a class of non-relational data storage system with flexible data model. Examples of NoSQL data- architecture patterns of datasets are - key-value pairs, - name/value pairs, - Column family Big-data store, - Tabular data store, - Cassandra (used in Facebook/Apache), - HBase, hash table [Dynamo (Amazon S3)], - JSON (CouchDB), JSON (PNUTS), - JSON (MongoDB), Graph Store, Object Store, ordered keys and semi-structured data storage systems.
24.
2. NoSQL notnecessarily has a fixed schema, such as table; do not use the concept of Joins (in distributed data storage systems); Data written at one node can be replicated to multiple nodes. Data store is thus fault-tolerant. The store can be partitioned into unshared shards. NoSQL data store characteristics are as follows:
25.
Features in NoSQLTransactions NoSQL transactions have following features: (i) Relax one or more of the ACID properties. (ii) Characterize by two out of three properties (consistency, availability and partitions) of CAP theorem, two are at least present for the application/service/process. (iii) Can be characterized by BASE properties (Basically Available, Soft State, Eventual consistency) principles
26.
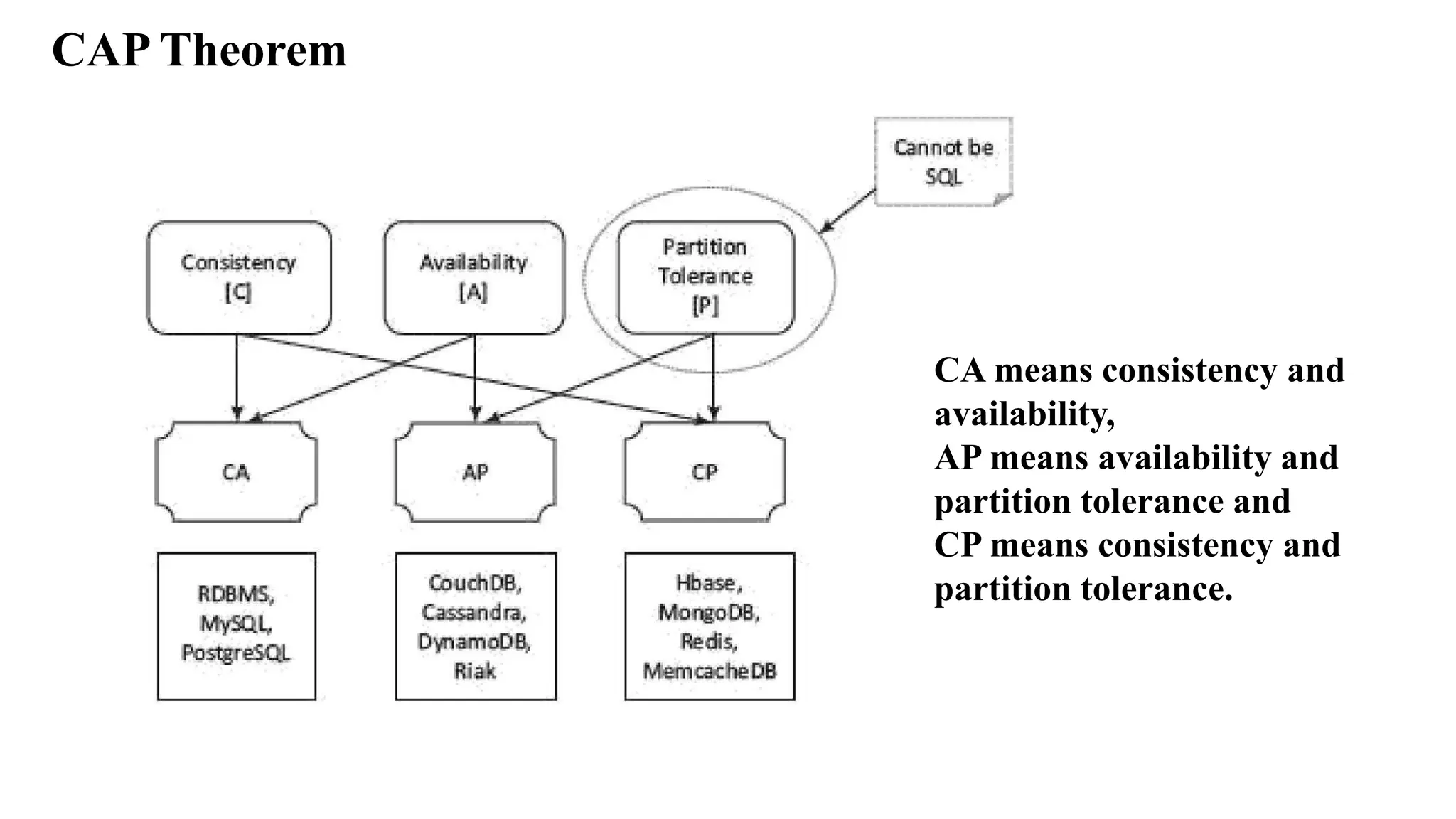
CAP Theorem Among C,A and P, two are at least present for the application/service/process. Consistency means all copies have the same value like in traditional DBs. Availability means at least one copy is available in case a partition becomes inactive or fails. Partition means parts which are active but may not cooperate (share) as in distributed DBs.
27.
1. Consistency indistributed databases means that all nodes observe the same data at the same time. Therefore, the operations in one partition of the database should reflect in other related partitions in case of distributed database. 2. Availability means that during the transactions, the field values must be available in other partitions of the database so that each request receives a response on success as well as failure. (Failure causes the response to request from the replicate of data). Distributed databases require transparency between one another. Network failure may lead to data unavailability in a certain partition in case of no replication. Replication ensures availability. 3. Partition means division of a large database into different databases CAP Theorem
28.
CAP Theorem Partition tolerance:Refers to continuation of operations as a whole even in case of message loss, node failure or node not reachable. Brewer's CAP (Consistency, Availability and Partition Tolerance) theorem demonstrates that any distributed system cannot guarantee C, A and P together. 1. Consistency- All nodes observe the same data at the same time. 2. Availability- Each request receives a response on success/failure. 3. Partition Tolerance-The system continues to operate as a whole even in case of message loss, node failure or node not reachable.
29.
CAP Theorem Partition tolerancecannot be ignored for achieving reliability in a distributed database system. Thus, in case of any network failure, a choice can be: Database must answer, and that answer would be old or wrong data (AP). Database should not answer, unless it receives the latest copy of the data (CP). The CAP theorem implies that for a network partition system, the choice of consistency and availability are mutually exclusive.
30.
CA means consistencyand availability, AP means availability and partition tolerance and CP means consistency and partition tolerance. CAP Theorem
31.
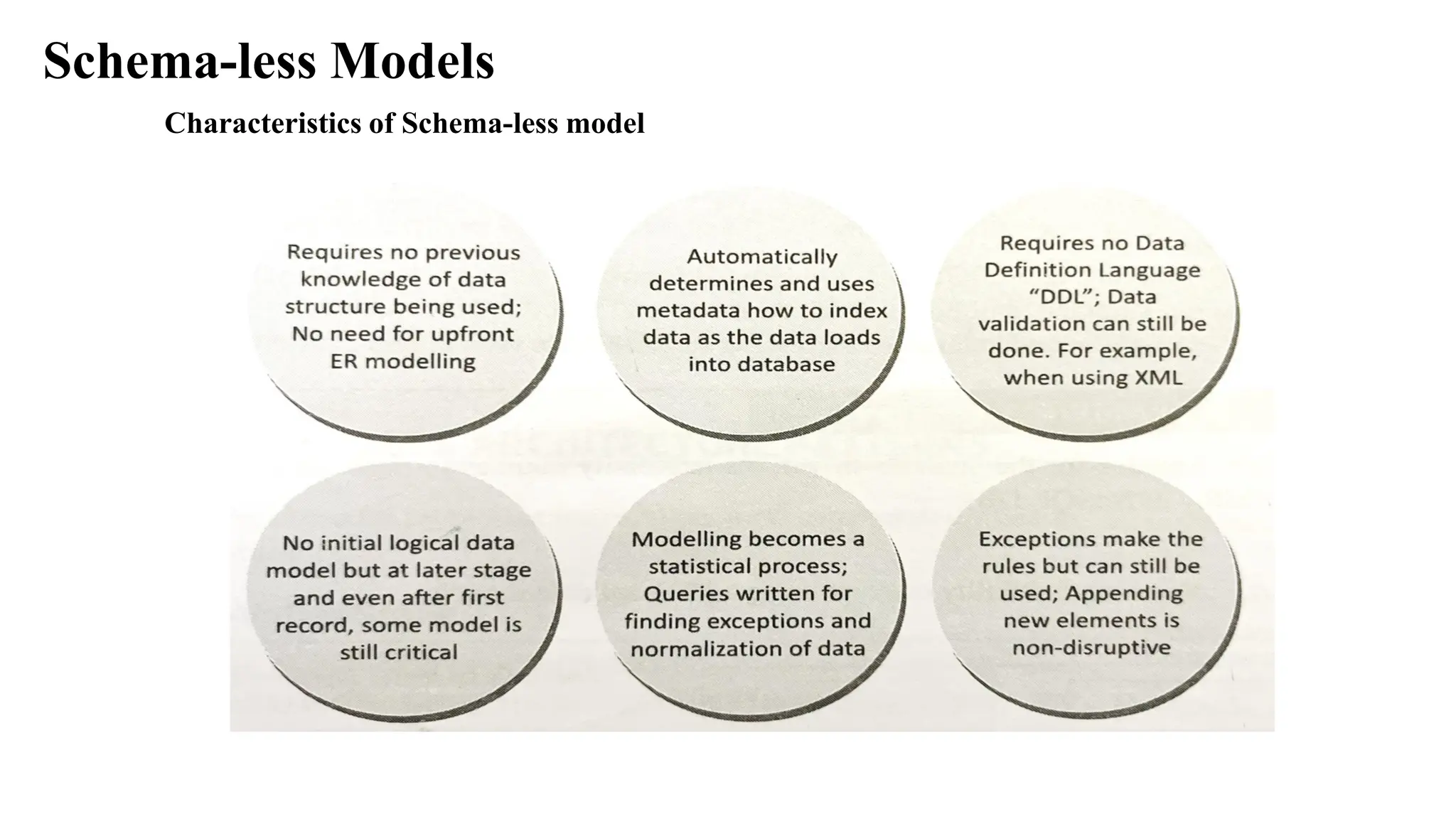
Schema-less Models • NoSQLdata not necessarily have a fixed table schema. The systems do not use the concept of Join (between distributed datasets). • Data written at one node replicates to multiple nodes. Therefore, these are identical, fault-tolerant and partitioned into shards. • NoSQL data model offers relaxation in one or more of the ACID properties (Atomicity, consistence, isolation and durability) of the database. • Follows CAP theorem “states that out of the three properties, two must at least be present for the application/service/process”
Increasing Flexibility forData Manipulation NoSQL data store possess characteristic of increasing flexibility for data manipulation. The new attributes to database can be increasingly added. Late binding of them is also permitted. BASE is a flexible model for NoSQL data stores. Provisions of BASE increase flexibility. BASE Properties BA stands for basic availability, S stands for soft state and E stands for eventual consistency.
34.
Increasing Flexibility forData Manipulation BASE Properties 1. Basic availability ensures by distribution of shards (many partitions of huge data store) across many data nodes with a high degree of replication. Then, a segment failure does not necessarily mean a complete data store unavailability. 2. Soft state ensures processing even in the presence of inconsistencies but achieving consistency eventually. A program suitably takes into account the inconsistency found during processing. NoSQL database design does not consider the need of consistency all along the processing time. 3. Eventual consistency means consistency requirement in NoSQL databases meeting at some point of time in future. Data converges eventually to a consistent state with no time-frame specification for achieving that. ACID rules require consistency all along the processing on completion of each transaction. BASE does not have that requirement and has the flexibility.
35.
NOSQL TO MANAGEBIG DATA Using NoSQL to Manage Big Data NoSQL (i) limits the support for Join queries, supports sparse matrix like columnar-family, (ii) Has characteristics of easy creation and high processing speed, scalability and storability of much higher magnitude of data (terabytes and petabytes). (iii) NoSQL sacrifices the support of ACID properties, and instead supports CAP and BASE properties. (iv) NoSQL data processing scales horizontally as well vertically.
36.
NOSQL TO MANAGEBIG DATA Characteristics of Big Data NoSQL solution are: 1. High and easy scalability: NoSQL data stores are designed to expand horizontally. Horizontal scaling means that scaling out by adding more machines as data nodes (servers) into the pool of resources (processing, memory, network connections). The design scales out using multi-utility cloud services. 2. Support to replication: Multiple copies of data store across multiple nodes of a cluster. This ensures high availability, partition, reliability and fault tolerance. 3. Distributable: Big Data solutions permit sharding and distributing of shards on multiple clusters which enhances performance and throughput.
37.
NOSQL TO MANAGEBIG DATA Characteristics of Big Data NoSQL solution are: 4. Usages of NoSQL servers which are less expensive. NoSQL data stores require less management efforts. It supports many features like automatic repair, easier data distribution and simpler data models that makes database administrator (DBA) and tuning requirements less stringent. 5. Usages of open-source tools: NoSQL data stores are cheap and open source. Database implementation is easy and typically uses cheap servers to manage the exploding data and transaction while RDBMS databases are expensive and use big servers and storage systems. So, cost per gigabyte data store and processing of that data can be many times less than the cost of RDBMS. 6. Support to schema-less data model: NoSQL data store is schema less, so data can be inserted in a NoSQL data store without any predefined schema. So, the format or data model can be changed any time, without disruption of application. Managing the changes is a difficult problem in SQL.
38.
7. Support tointegrated caching: NoSQL data store support the caching in system memory. That increases output performance. SQL database needs a separate infrastructure for that. 8. No inflexibility unlike the SQL/RDBMS, NoSQL DBs are flexible (not rigid) and have no structured way of storing and manipulating data. SQL stores in the form of tables consisting of rows and columns. NoSQL data stores have flexibility in following ACID rules. NOSQL TO MANAGE BIG DATA Characteristics of Big Data NoSQL solution are:
39.
Types of BigData Problems The following types of problems are faced using Big Data solutions. 1. Big Data need the scalable storage and use of distributed servers together as a cluster. Therefore, the solutions must drop support for the database Joins 2. NoSQL database is open source and that is its greatest strength but at the same time its greatest weakness also because there are not many defined standards for NoSQL data stores. Hence, no two NoSQL data stores are equal. For example: (i) No stored procedures in MongoDB (NoSQL data store) (ii) GUI mode tools to access the data store are not available in the market (iii) Lack of standardization (iv) NoSQL data stores sacrifice ACID compliancy for flexibility and processing speed.
NoSQL data storesarchitectural patterns NoSQL data stores broadly categorize into architectural patterns 1. Key Value Pairs 2. Document Stores 3. Tabular Data 4. Object Data Store 5. Graph Database
42.
Key-Value Store • Thesimplest way to implement a schema-less data store is to use key-value pairs. • The data store characteristics are high performance, scalability and flexibility. • Data retrieval is fast in key-value pairs data store. • The concept is similar to a hash table where a unique key points to a particular item(s) of data.
Advantages of akey-value store are as follows: 1. Data Store can store any data type in a value field. 2. A query just requests the values and returns the values as a single item. Values can be of any data type. 3. Key-value store is eventually consistent. 4. Key-value data store may be hierarchical or may be ordered key-value store. 5. Returned values on queries can be used to convert into lists, table-columns, data-frame fields and columns. 6. Have (i) scalability, (ii) reliability, (iii) portability and (iv) low operational cost. 7. The key can be synthetic or auto-generated. The key is flexible and can be represented in many formats: (i) Artificially generated strings created from a hash of a value, (ii) Logical path names to images or files
45.
The key-value storeprovides client to read and write values using a key as follows: (i) Get (key) , returns the value associated with the key. (ii) Put (key, value), associates the value with the key and updates a value if this key is already present. (iii) Multi-get (key1, key2, .., keyN), returns the list of values associated with the list of keys. (iv) Delete (key) , removes a key and its value from the data store.
46.
Limitations of key-valuestore architectural pattern are: (i) No indexes are maintained on values, thus a subset of values is not searchable. (ii) Key-value store does not provide traditional database capabilities, such as atomicity of transactions, or consistency when multiple transactions are executed simultaneously. The application needs to implement such capabilities. (iii) Maintaining unique values as keys may become more difficult when the volume of data increases. One cannot retrieve a single result when a key-value pair is not uniquely identified. (iv) Queries cannot be performed on individual values. No clause like 'where' in a relational database usable that filters a result set.
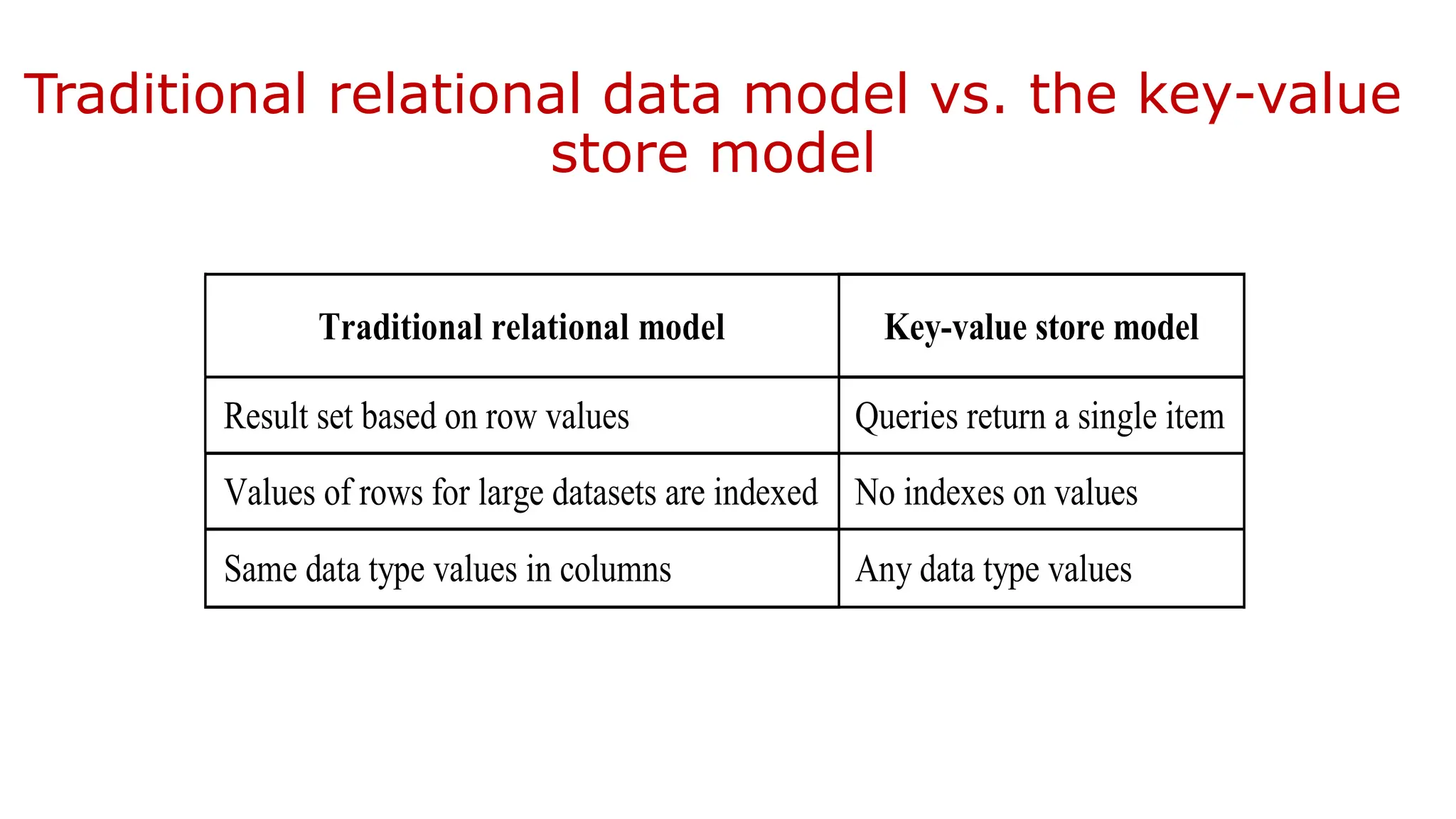
47.
Traditional relational datamodel vs. the key-value store model Traditional relational model Key-value store model Result set based on row values Queries return a single item Values of rows for large datasets are indexed No indexes on values Same data type values in columns Any data type values
48.
Riak Key-Value DataStore • Riak is open-source Erlang language data store. • It is a key-value data store system. • Data auto-distributes and replicates in Riak. • It is thus, fault tolerant and reliable. • Some other widely used key-value pairs in NoSQL DBs are Amazon's DynamoDB, Redis (often referred as Data Structure server), Memcached and its flavours, Berkeley DB, upscaledb (used for embedded databases), project Voldemort and Couchbase.
49.
Document Store Characteristics ofDocument Data Store are: • high performance and flexibility. • Scalability varies, depends on stored contents. • Complexity is low compared to tabular, object and graph data stores.
50.
Following are thefeatures in Document Store: 1. Document stores unstructured data. 2. Storage has similarity with object store. 3. Data stores in nested hierarchies. For example, in JSON formats data model XML document object model (DOM), or machine-readable data as one BLOB [Binary Large Object]. Hierarchical information stores in a single unit called document tree. Logical data stores together in a unit. 4. Querying is easy. For example, using section number, sub-section number and figure caption and table headings to retrieve document partitions. 5. Transactions on the document store exhibit ACID properties.
51.
Typical uses ofa document store are: (i) office documents, (ii) inventory store, (iii) forms data, (iv) document exchange and (v) document search. Examples of Document Data Stores are CouchDB and MongoDB.
CSV and JSONFile Formats CSV does not represent object-oriented databases or hierarchical data records. JSON and XML represent semistructured data, object-oriented records and hierarchical data records. JSON (Java Script Object Notation) refers to a language format for semistructured data. JSON represents object-oriented and hierarchical data records, object, and resource arrays in JavaScript.
54.
Example Assume Preeti gaveexamination in Semester 1 in 1995 in four subjects. She gave examination in five subjects in Semester 2 and so on in each subsequent semester. Another student, Kirti gave examination in Semester 1 in 2016 in three subjects, out of which one was theory and two were practical subjects. Presume the subject names and grades awarded to them.
55.
(i) Write twoCSV files for cumulative grade-sheets for both the students. Point the difficulty during processing of data in these two files. SOLUTION (i) Two CSV file for cumulative grade-sheets are as follows: CSV file for Preeti consists of the following nine lines each with four Semester, Subject Code, Subject Name, Grade 1, CS101, ""Theory of Computations", 7.8. 1, CS102,1, "Computer Architecture", 7.8. 2, CS204, "Object Oriented Programming", 7.2. 2, CS205, "Data Analytics", 8.1.
56.
The CSV filefor Kirti consist of following five lines each with five columns: Semester, Subject Type, Subject Code, Subject Name, Grade 1, Theory, EL101, “Analog Electronics", 7.6. 1, Theory, EL102,"Principles of Analog Communication", 7.5. 1, Theory, EL103, “Digital Electronic", 7.8. 1, Practical, CS104, "Analog ICs", 7.2 1, Practical, CS105, "Digital ICs", 8.4
57.
• A columnhead is a key. • Number of key-value pairs are (4 x 9) = 36 for preetiGradeSheet.csv and • (5 x 5) = 25 for kirtiGradeSheet.csv. • Therefore, when processing student records, merger of both files into a single file will need a program to extract the key-value pairs separately, and then prepare a single file.
58.
(ii) Write afile in JSON format with each student grade-sheet as an object instance. How does the object-oriented and hierarchical data record in JSON make processing easier? SOLUTION JSON gives an advantage of creating a single file with multiple instances and inheritances of an object. Consider a single JSON file, studentGradeSheets json for cumulative grade-sheets of many students. Student Grades object is top in the hierarchy. Each student name object is next in the hierarchy with object consisting of student name, each with number of instances of subject codes, subject types, subject titles and grades awarded. Each student name object-instance extends in student grades object- instances.
60.
XML (extensible MarkupLanguage) XML is an extensible, simple and scalable language. Its self-describing format describes structure and contents in an easy to understand format. XML is widely used in data store and data exchanges over the network. The document model consists of root element and their sub-elements. XML document model has a hierarchical structure. XML document model has features of object-oriented records. XML is semi-structured.
61.
Document JSON FormatCouchDB Database Its features are: 1. CouchDB provides querying, combining and filtering of information. 2. CouchDB uses JSON Data Store model for documents. Each document maintains separate data and metadata (schema). 3. CouchDB is a multi-master application. Write does not require field locking when controlling the concurrency during multi-master application. 4. CouchDB querying language is JavaScript. 5. CouchDB accesses the documents using HTTP API. HTTP methods are Get, Put and Delete 6. CouchDB data replication is the distribution model that results in fault tolerance and reliability.
62.
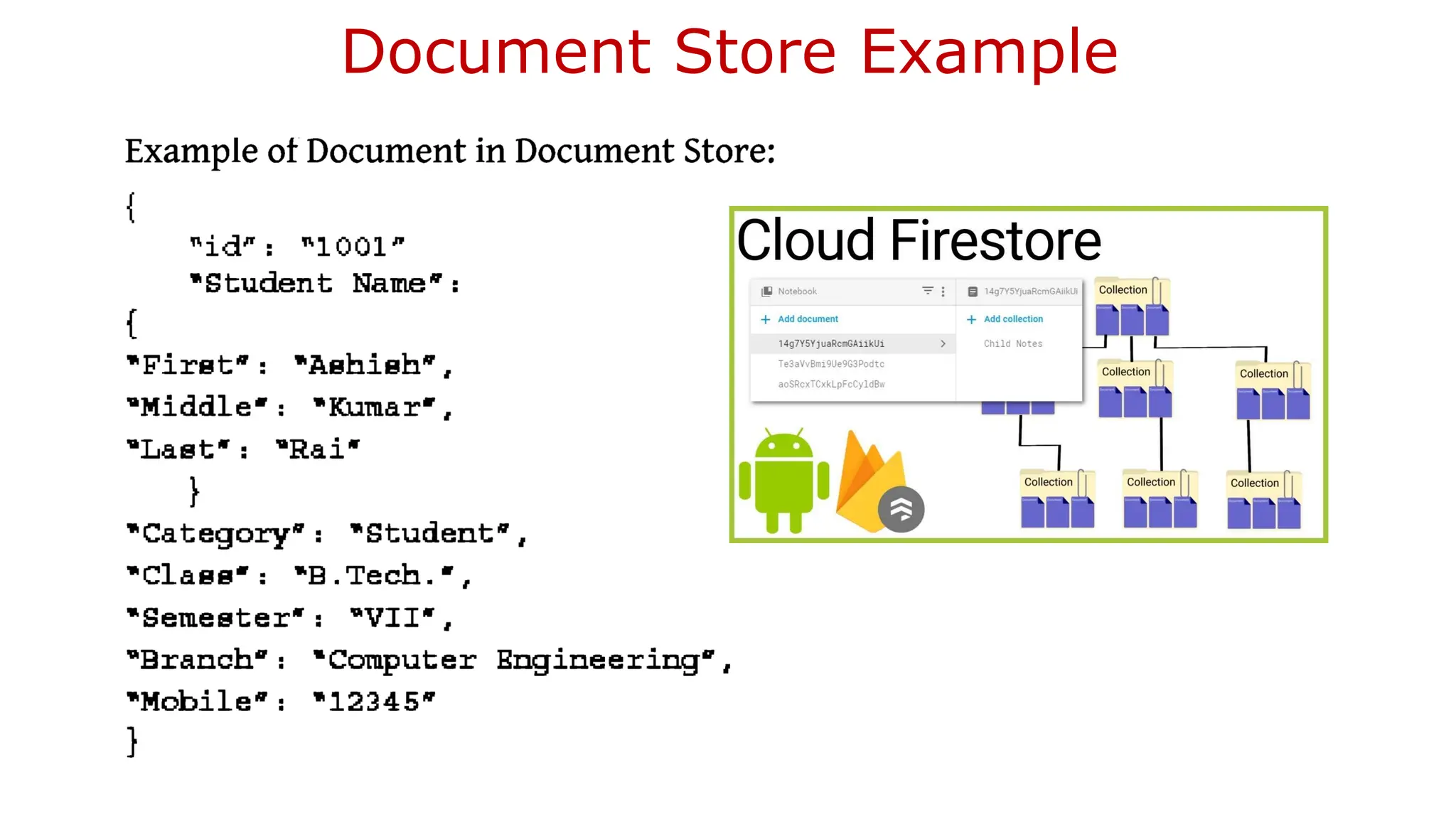
Document JSON Format—MongoDBDatabase MongoDB Document database provides a rich query language and constructs, such as database indexes allowing easier handling of Big Data. Example of Document in Document Store:
63.
• The documentstore allows querying the data based on the contents as well. • For example, it is possible to search the document where student's first name is "Ashish". • Document store can also provide the search value's exact location. • The search is by using the document path. • A type of key accesses the leaf values in the tree structure. • Since the document stores are schema-less, adding fields to documents (XML or JSON) becomes a simple task.
64.
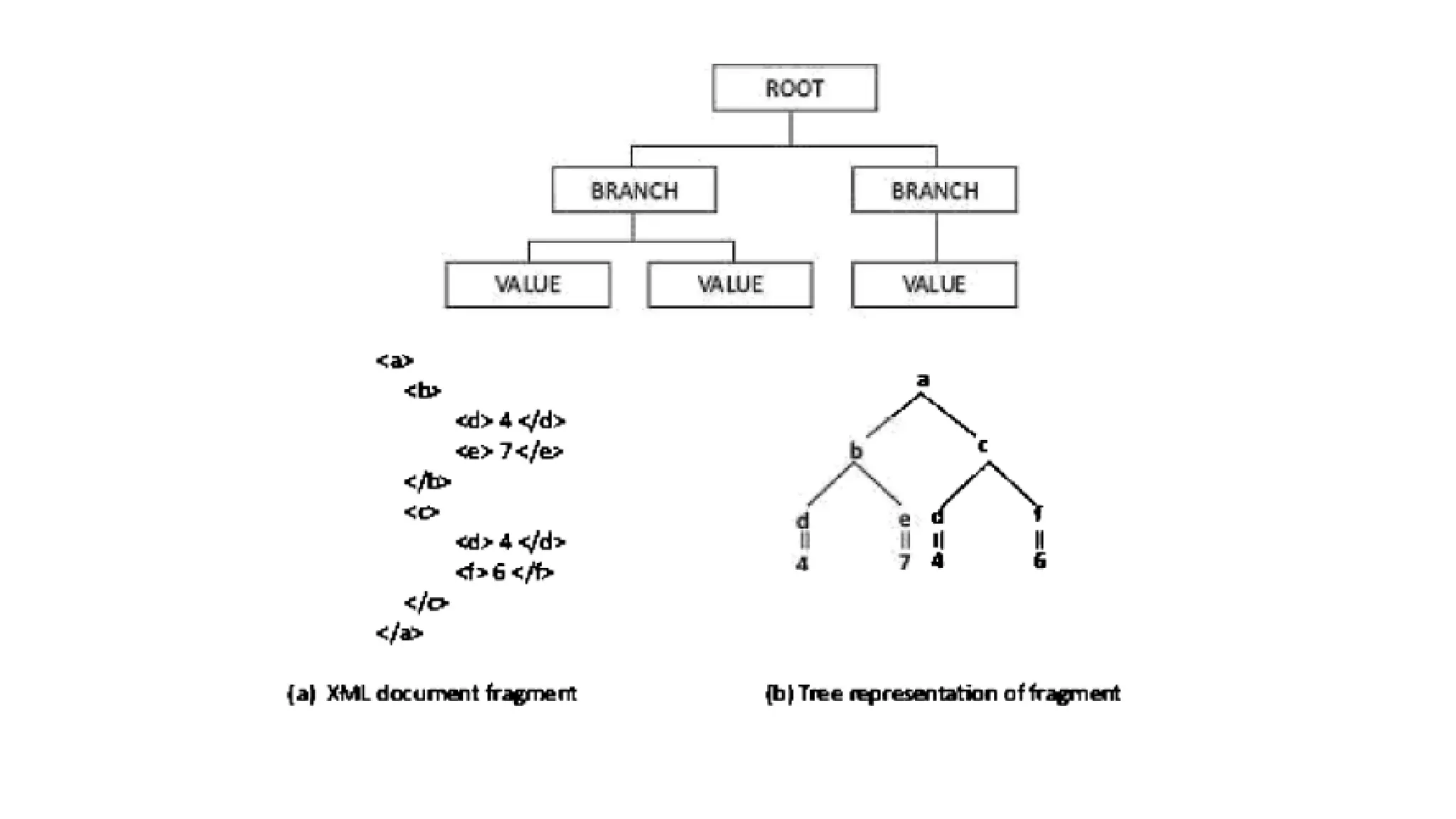
XML document architecturepattern • An XML document architecture pattern is a document fragment and document tree structure. • The document store follows a tree-like structure (similar to directory structure in file system). • The root element there are multiple branches. • Each branch has a related path expression that provides a way to navigate from the root to any given branch, sub-branch or value.
66.
XQuery and XPathare query languages for finding and extracting elements and attributes from XML documents. The query commands use sub-trees and attributes of documents. The querying is similar as in SQL for databases. XPath treats XML document as a tree of nodes. XPath queries are expressed in the form of XPath expressions.
67.
Example Give examples ofXPath expressions. Let outermost element of the XML document is a. SOLUTION • An XPath expression /a/b/c selects c elements that are children of b elements that are children of element a that forms the outermost element of the XML document. • An XPath expression /a/b[c=5] selects elements b and c that are children of a and value of c element is 5. • An XPath expression /a[b/c]/d selects elements c and d where c is child of b and, b and d are children of a.
69.
Benefits of JSONover XML When compared with XML, JSON has the following advantages: • XML is easier to understand but XML is more verbose than JSON. • XML is used to describe structured data and does not include arrays, whereas JSON includes arrays. • JSON has basically key-value pairs and is easier to parse from JavaScript. • The concise syntax of JSON for defining lists of elements makes it preferable for serialization of text format objects.
70.
Benefits of DocumentCollection 1. Group the documents together, similar to a directory structure in a file- system. (A directory consists of grouping of file folders.) 2. Enables navigating through document hierarchies, logically grouping similar documents and storing business rules such as permissions, indexes and triggers (special procedure on some actions in a database). 3. A collection can contain other collections as well.
71.
Tabular Data Tabular datastores use rows and columns. Row Oriented or Row Format Data Row-head field may be used as a key which access and retrieves multiple values from the successive columns in that row. The OLTP is fast on in-memory row-format data. In-memory row-based data is the example for row oriented data, in which a key in the first column of the row is at a memory address, and values in successive columns at successive memory addresses. That makes OLTP easier. All fields of a row are accessed at a time together during OLTP.
72.
Column-based data TabularData: In-memory column-based data has the keys (row-head keys) in the first row is the key of the each column. The next column of each row after the key has the values at successive memory addresses. The column-based data makes the OLAP easier. All fields of a column can be accessed together. All fields of a set of columns may also be accessed together during OLAP.
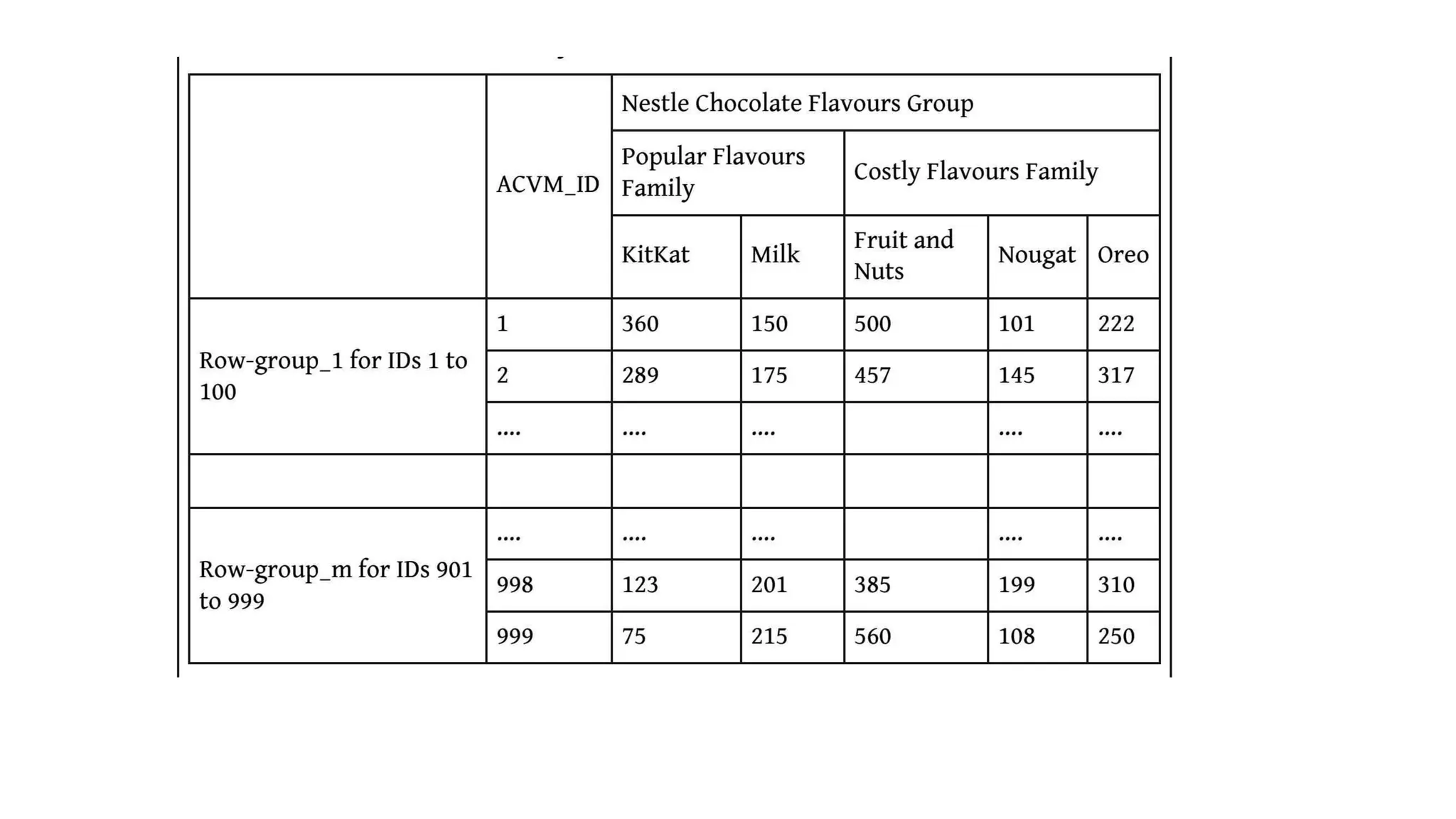
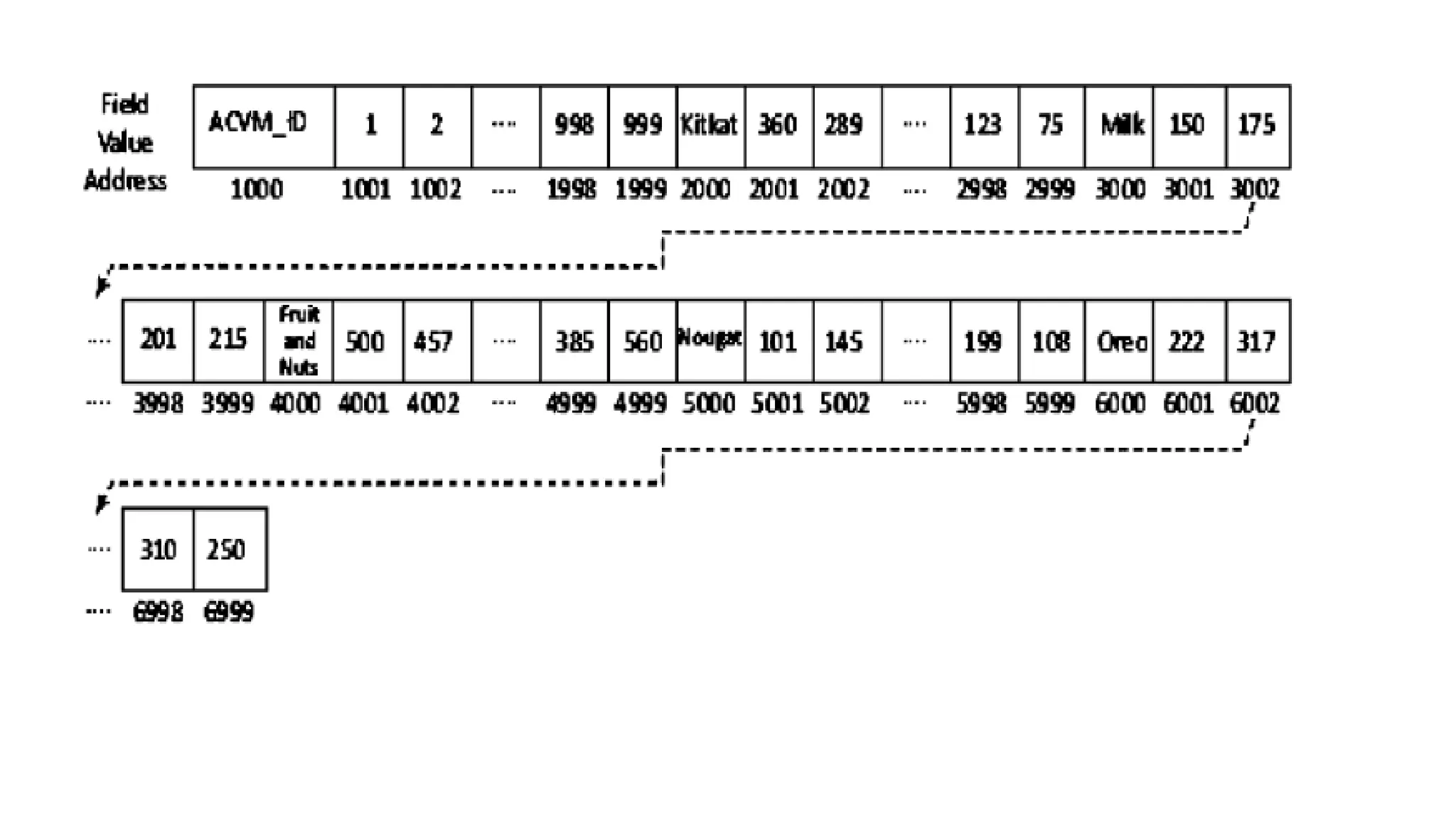
Advantages of columnstores are: 1. Scalability: The database uses row IDs and column names to locate a column and values at the column fields. The back-end system can distribute queries over a large number of processing nodes without performing any Join operations. 2. Partitionability: For example, large data of ACVMs can be partitioned into datasets of size, say 1 MB in the number of row-groups. Values in columns of each row- group independently parallelly process in-memory at the partitioned nodes. 3. Availability: The cost of replication is lower since the system scales on distributed nodes efficiently. Thus, the data is always available in case of failure of any node.
78.
4. Tree-like columnarstructure A key for the column fields consists of three secondary keys: column-families group ID, column-family ID and column-head name. 5. Adding new data at ease: Permits new column Insert operations. 6. Querying all the field values in a column in a family, all columns in the family or a group of column-families, is fast in in-memory column-family data store. 7. Replication of columns: HDFS-compatible column-family data stores replicate each data store with default replication factor = 3. 8. No optimization for Join: Column-family data stores are similar to sparse matrix data. The data do not optimize for Join operations.
79.
Examples of widelyused column-family data store: Google's BigTable, HBase and Cassandra. Following are features of a BigTable: 1. Massively scalable NoSQL. BigTable scales up to 100s of petabytes. 2. Integrates easily with Hadoop and Hadoop compatible systems. 3. Compatibility with MapReduce, HBase APIs which are open-source Big Data platforms. 5. Handles million of operations per second. 6. Handle large workloads with low latency and high throughput 7. Consistent low latency and high throughput 8. APIs include security and permissions 9. BigTable, being Google's cloud service, has global availability and its service is seamless.
80.
ORC File Format •ORC (Optimized Row Columnar). • ORC is an intelligent Big Data file format for HDFS and Hive. • An ORC file stores a collections of rows as a row-group. • Each row-group data store in columnar format. • This enables parallel processing of multiple row-groups in an HDFS cluster. • A mapped column has contents required by the query. • The columnar layout in each ORC file thus, optimizes for compression and enables skipping of data in columns. • This reduces read and decompression load.
81.
• An ORCthus, optimizes for reading serially the column fields in HDFS environment. • The throughput increases due to skipping and reading of the required fields at contents-column key. • Reading less number of ORC file content-columns reduces the workload on the NameNode.
82.
Parquet File Formats ApacheParquet is a columnar storage file format available to any project in the Hadoop ecosystem (Hive, Hbase, MapReduce, Pig, Spark). What is a columnar storage format? In order to understand Parquet file format in Hadoop better, first let’s see what is columnar format. In a column oriented format values of each column of in the records are stored together.
83.
For example ifthere is a record which comprises of ID, emp Name and Department then all the values for ID column will be stored together, values for Name column together and so on. If we take the same record schema as mentioned above having three fields ID (int), NAME (varchar) and Department (varchar)
84.
row wise storageformat : For this table in a row wise storage format the data will be stored as follows- Column oriented storage format- data will be stored as follows in a Column oriented storage format-
85.
How columnar storageformat helps? • If you need to query few columns from a table then columnar storage format is more efficient as it will read only required columns since they are adjacent in memory thus minimizing IO. • If you want only the NAME column. In a row storage format each record in the dataset has to be loaded, parsed into fields and then data for Name is extracted. • With column oriented format it can directly go to Name column as all the values for that columns are stored together and get those values. No need to go through the whole record.
86.
• Column orientedformat increases the query performance as less seek time is required to go the required columns and less IO is required as it needs to read only the columns whose data is required. • Another benefit that you get is in the form of less storage. Compression works better if data is of same type. With column oriented format columns of the same type are stored together resulting in better compression.
87.
Parquet format Parquet fileformat is also a column oriented format so it brings the same benefit of improved performance and better compression. One of the unique feature of Parquet is that it can store data with nested structures also in columnar fashion.
88.
Object Data Store Anobject store refers to a repository which stores the: 1. Objects (such as files, images, documents, folders, and business reports) 2. System metadata which provides information such as filename, creation_date, last_modified, language_used (such as Java, C, C#, C++, Smalltalk, Python), access_permissions, supported query languages) 3. Custom metadata which provides information, such as subject, category, sharing permissions.
89.
Eleven Functions SupportingAPIs An Object data store consists of functions supporting APIs for: (i) scalability, (ii) indexing, (iii)large collections, (iv)querying language, processing and optimization (s), (v) Transactions, (vi)data replication for high availability, data distribution model, data integration (such as with relational database, XML, custom code),
90.
(vii) schema evolution, (viii)persistency, (ix) persistent object life cycle, (x) adding modules and (xi) locking and caching strategy.
91.
Examples of ObjectStore Amazon S3 and Microsoft Azure BLOB support the Object Store. Amazon S3 (Simple Storage Service) S3 refers to Amazon web service on the cloud named S3. The S3 provides the Object Store. The Object Store differs from the block and file-based cloud storage. S3 assigns an ID number for each stored object. The service has two storage classes: Standard and infrequent access. Interfaces for S3 service are REST representational state transfer, SOAP Simple Object Access Protocol and Bit Torrent. S3 uses include web hosting, image hosting and storage for backup systems. S3 is scalable storage infrastructure, same as used in Amazon e-commerce service. S3 may store trillions of objects.
92.
Graph Database Another wayto implement a data store is to use graph database. Data store as series of interconnected nodes. • Data Store focuses on modeling interconnected structure of data. Data stores based on graph theory relation G = (E, V), where E is set of edges el, e2, ... and V is set of vertices, v1, v2, ..., vn. • Nodes represent entities or objects. Edges encode relationships between nodes. Some operations become simpler to perform using graph models. • Examples of graph model usages are social networks of connected people. The connections to related persons become easier to model when using the graph model.
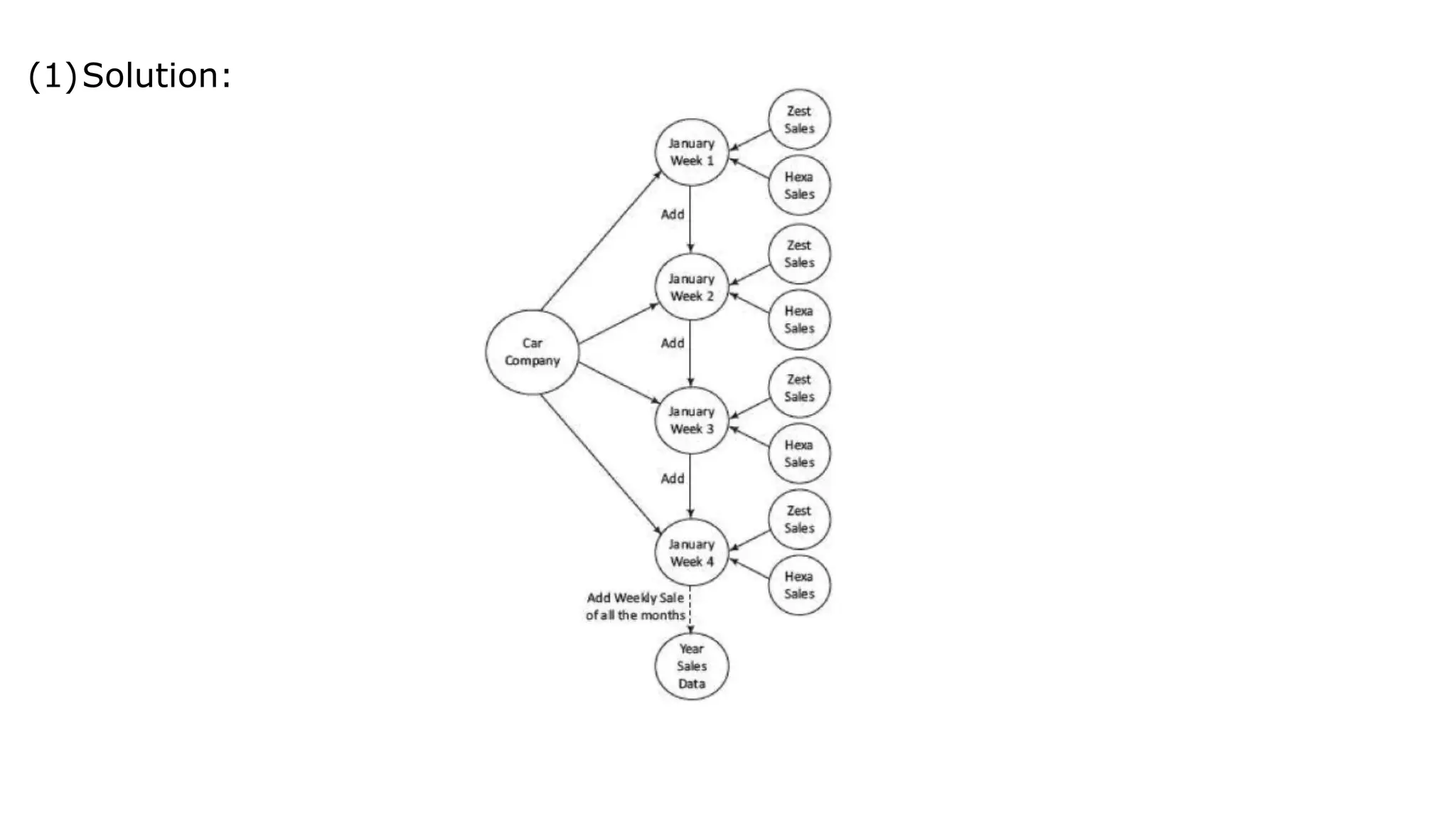
(ii) Solution: The yearlysales compute by path traversals from nodes for weekly sales to yearly sales data. (iii) Solution: The path traversals exhibit BASE properties because during the intermediate paths, consistency is not maintained. Eventually when all the path traversals complete, the data becomes consistent.
96.
Typical uses ofgraph databases are: (i) link analysis, (ii) friend of friend queries, (iii) rule checking and [Finite Automata Theory] (iv) Pattern matching. Limitations of Graph Data Base: • Graph databases have poor scalability. • They are difficult to scale out on multiple servers. This is due to the close connectivity feature of each node in the graph. • Write operations to multiple servers and graph queries that span multiple nodes, can be complex to implement.
97.
Examples of graphDBs are Neo4J, AllegroGraph, HyperGraph, Infinite Graph, Titan and FlockDB.
98.
SHARED-NOTHING ARCHITECTURE FORBIG DATA TASKS • The columns of two RDBMS tables relate by a relationship. • A relational algebraic equation specifies the relation. • Keys share between two or more SQL tables in RDBMS. • Shared nothing (SN) is a cluster architecture. A node does not share data with any other node. • Big Data store consists of SN architecture. • Big Data store, therefore, easily partitions into shards. • A partition processes the different queries on data of the different users at each node independently. Thus, data processes run in parallel at the nodes.
99.
SHARED-NOTHING ARCHITECTURE FORBIG DATA TASKS The features of SN architecture are as follows: 1. Independence: Each node with no memory sharing; thus possesses computational self- sufficiency 2. Self-Healing: A link failure causes creation of another link 3. Each node functioning as a shard: Each node stores a shard (a partition of large DBs) 4. No network contention
100.
Choosing the DistributionModels SHARED-NOTHING ARCHITECTURE FOR BIG DATA TASKS Big Data requires distribution of data on multiple data nodes at clusters. Distributed software components give advantage of parallel processing, providing horizontal scalability. Distribution gives (i) ability to handle large-sized data, and (ii) processing of many read and write operations simultaneously in an application. (iii) A resource manager manages, allocates, and schedules the resources of each processor, memory and network connection. (iv) Distribution increases the availability when a network slows or link fails.
101.
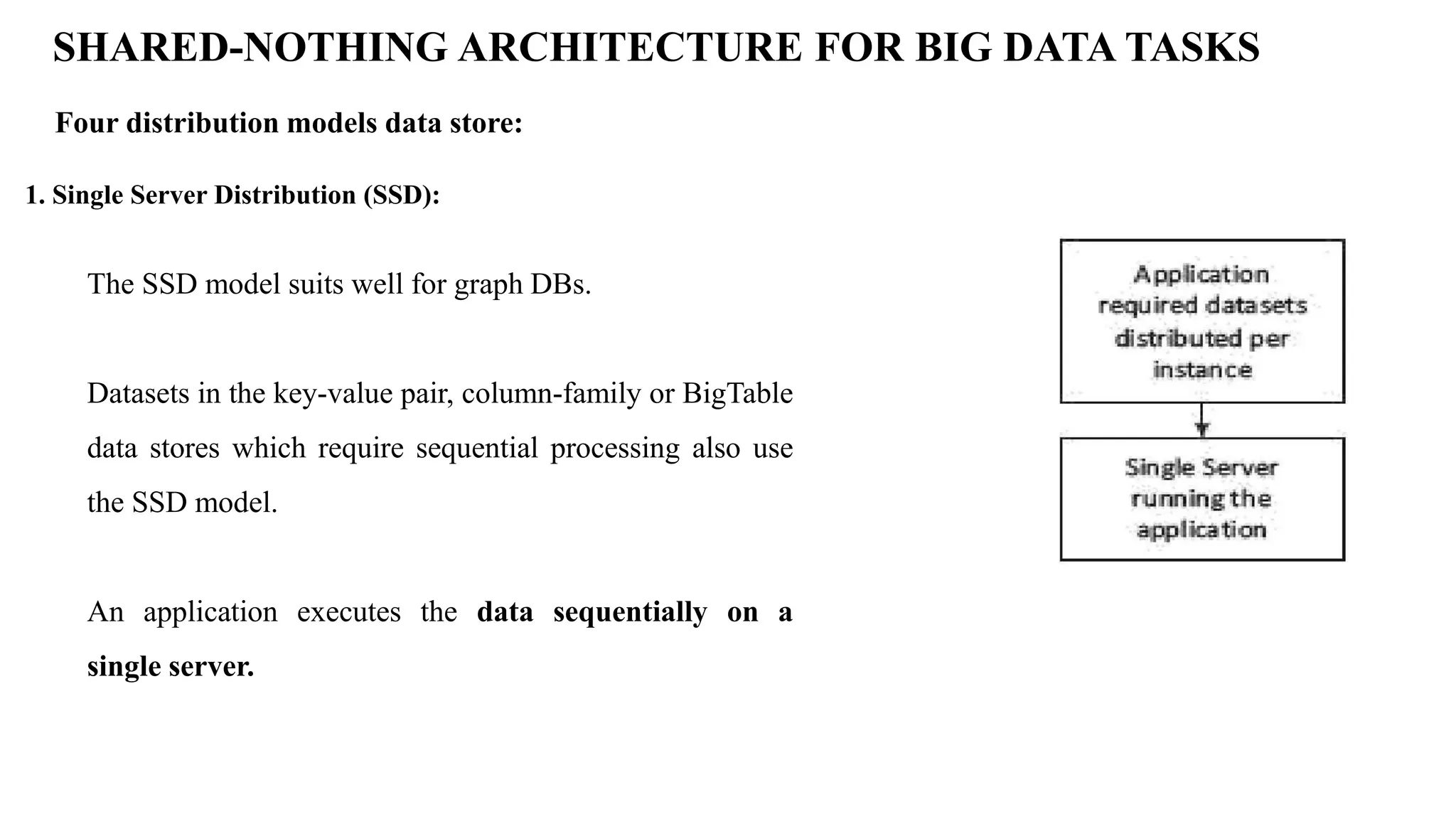
SHARED-NOTHING ARCHITECTURE FORBIG DATA TASKS Four distribution models data store: 1. Single Server Distribution (SSD): The SSD model suits well for graph DBs. Datasets in the key-value pair, column-family or BigTable data stores which require sequential processing also use the SSD model. An application executes the data sequentially on a single server.
102.
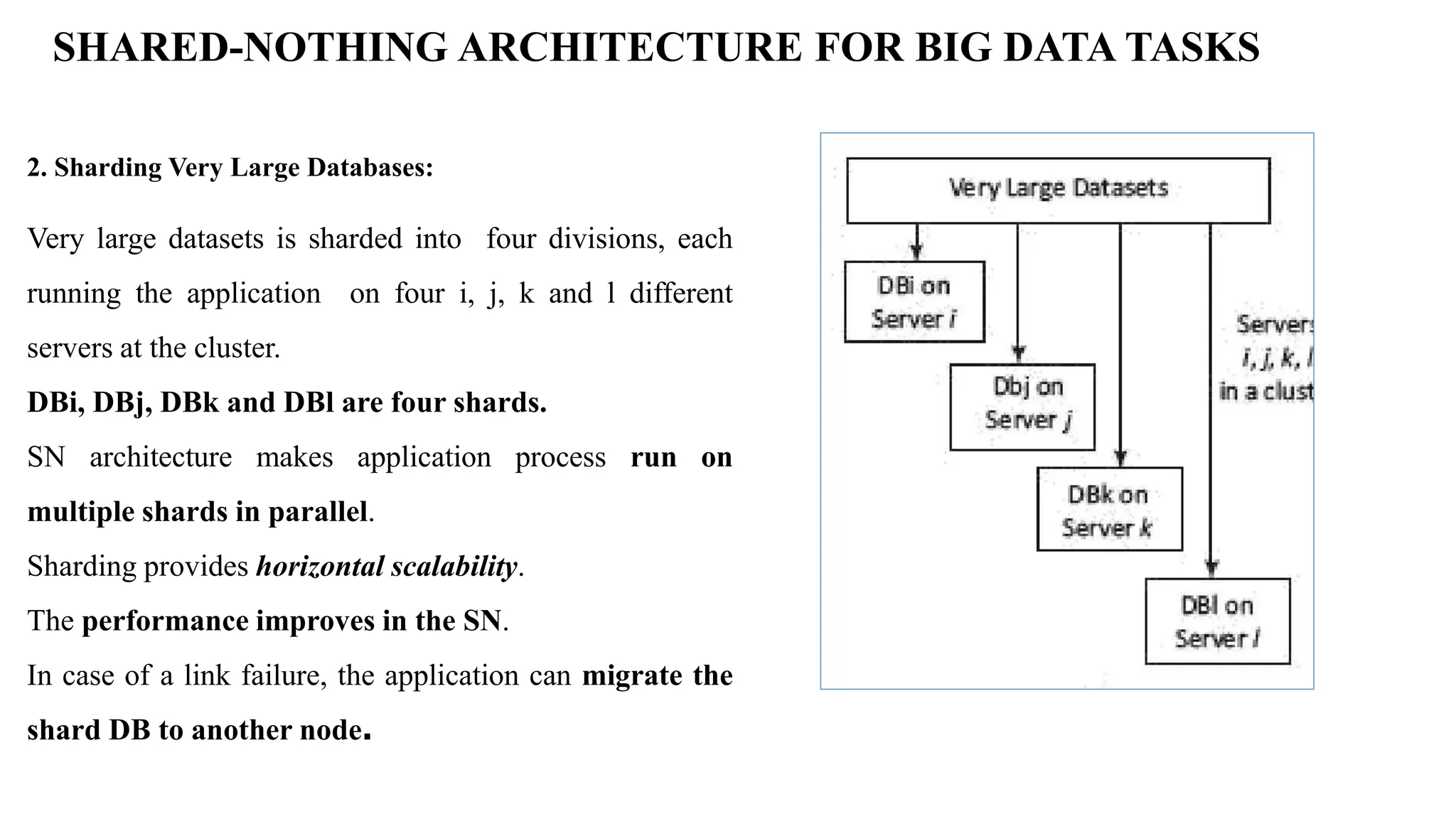
SHARED-NOTHING ARCHITECTURE FORBIG DATA TASKS 2. Sharding Very Large Databases: Very large datasets is sharded into four divisions, each running the application on four i, j, k and l different servers at the cluster. DBi, DBj, DBk and DBl are four shards. SN architecture makes application process run on multiple shards in parallel. Sharding provides horizontal scalability. The performance improves in the SN. In case of a link failure, the application can migrate the shard DB to another node.
103.
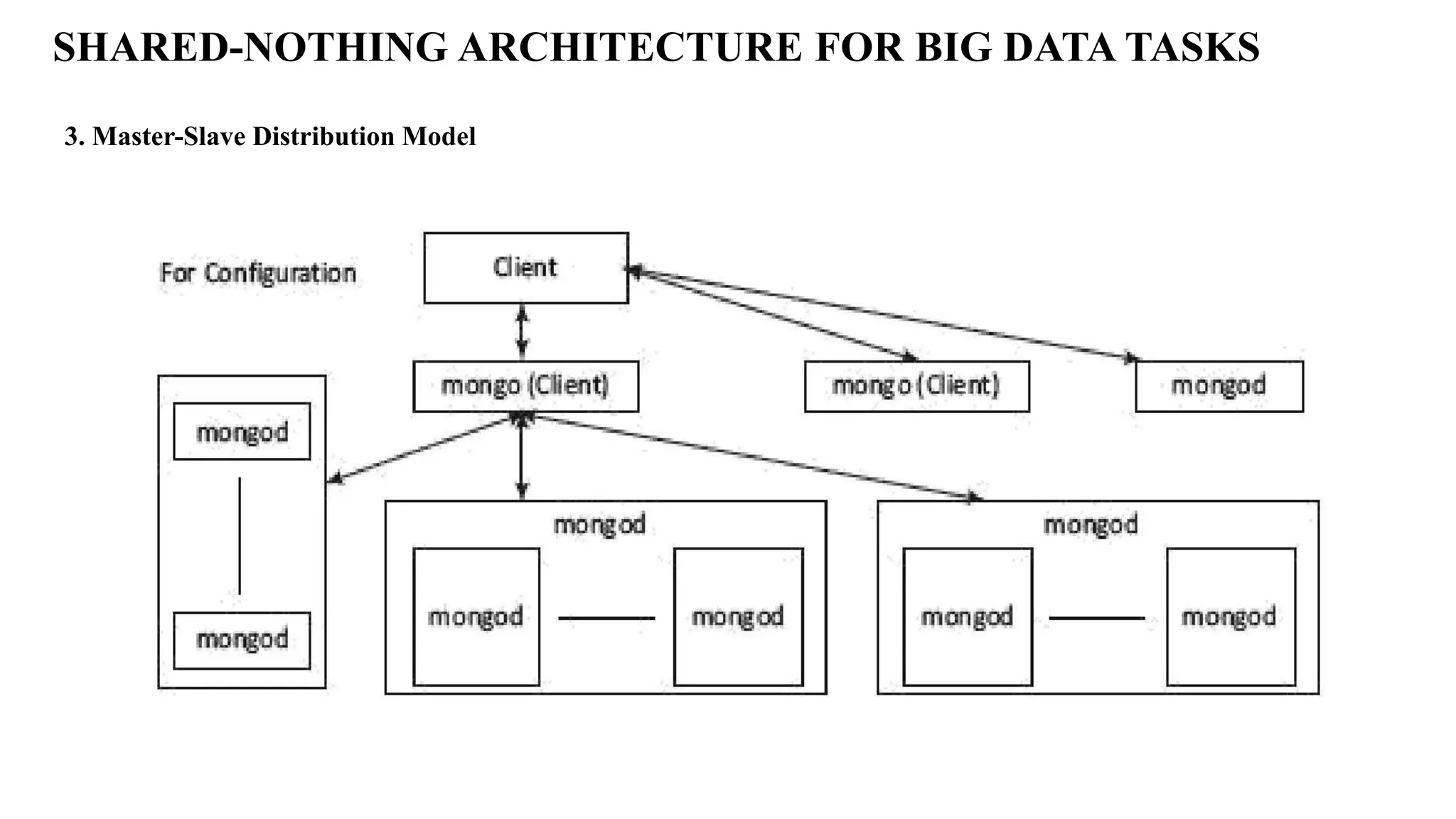
SHARED-NOTHING ARCHITECTURE FORBIG DATA TASKS 3. Master-Slave Distribution Model A node serves as a master or primary node and the other nodes are slave nodes. Master directs the slaves. Data gets replicated on the slave nodes. When a process updates the master, it updates the slaves also. A process uses the slaves for read operations and write is done in master. Processing performance improves when process runs large datasets distributed onto the slave nodes. Limitations of Master Slave Distribution Model: 1. Processing performance decreases due to replication in MSD distribution model, if in case the data is not found on the salve node. [Then it has to be obtained from the other node on which the data is replicated] 2. Complexity increases: Cluster-based processing has greater complexity than the other architectures. Consistency can also be affected in case of problem of significant time taken for updating.
4. Peer-to-Peer DistributionModel [PPD Model]: SHARED-NOTHING ARCHITECTURE FOR BIG DATA TASKS Peer-to-Peer distribution (PPD) model and replication has the following characteristics: (1) All replication nodes accept read request and send the responses. (2) All replicas function equally [read support and write support also]. (3) Node failures do not cause loss of write capability, as other replicated node responds. Cassandra adopts the PPD model. Benefits: Performance can further be enhanced by adding the nodes. Since nodes read and write both, a replicated node also has updated data. Therefore, the biggest advantage in the model is consistency.
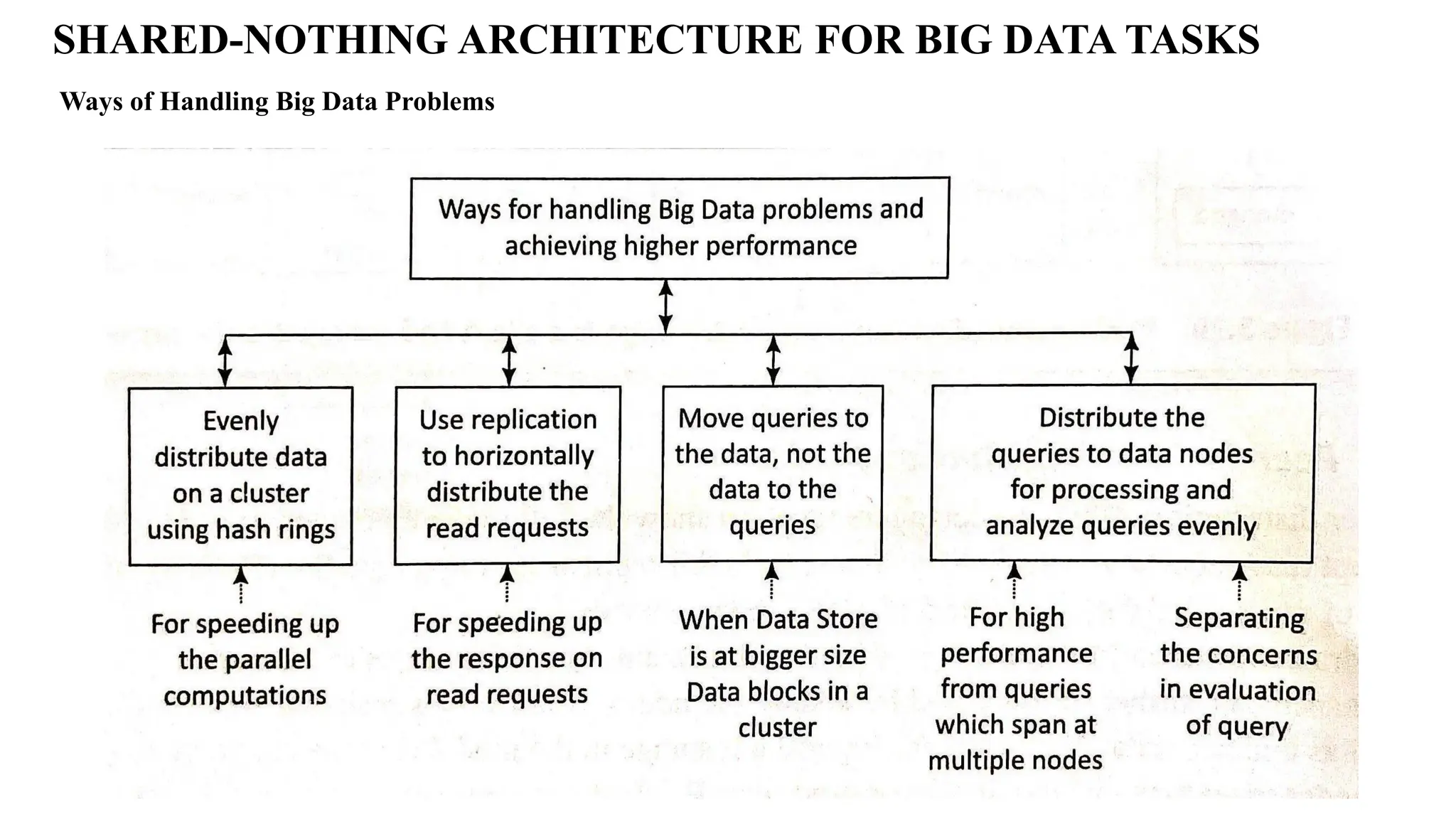
Ways of HandlingBig Data Problems SHARED-NOTHING ARCHITECTURE FOR BIG DATA TASKS
108.
1. Evenly distributethe data on a cluster using the hash rings: • Uses the hashing algorithm which generates the pointer to the data collection. • Generated hash ID determines the data location in the cluster. • Hash Ring refers to a map of hashes with locations. • The client, use the hash ring for data searches. 2. Use replication to horizontally distribute the client read-requests: Replication means creating backup copies of data in real time. Using replication enables horizontal scaling out of the client requests. 3. Moving queries to the data, not the data to the queries: Moving client node queries to the data is efficient as well as a requirement in Big Data solutions. 4. Queries distribution to multiple nodes: Evenly distribute the queries to data nodes/ replica nodes. High performance query processing requires usages of multiple nodes. Ways of Handling Big Data Problems SHARED-NOTHING ARCHITECTURE FOR BIG DATA TASKS
MONGODB DATABASE MongoDB isan open source DBMS. MongoDB programs create and manage databases. MongoDB manages the collection and document data store. MongoDB functions do querying and accessing the required information. The functions include viewing, querying, changing, visualizing and running the transactions. Changing includes updating, inserting, appending or deleting.
111.
MONGODB DATABASE MongoDB is (i)non-relational, (ii) NoSQL, (iii) distributed, (iv) open source, (v) document based (vi) cross-platform, (vii) Scalable, (viii) flexible data model, (ix) Indexed, (x) multi-master (xi) fault tolerant. Document data store in JSON-like documents. The data store uses the dynamic schemas. The typical MongoDB applications are content management and delivery systems, mobile applications, user data management, gaming, e-commerce, analytics, archiving and logging.
112.
Features of MongoDB 1.MongoDB data store is a physical container for collections. A number of DBs can run on a single MongoDB server. The database server of MongoDB is mongod and the client is mongo. 2. Collection stores a number of MongoDB documents. It is analogous to a table of RDBMS. Collections may store documents that do not have the same fields. Thus, documents of the collection are schema-less. Thus, it is possible to store documents of varying structures in a collection. Practically, in an RDBMS, it is required to define a column and its data type, but does not need them while working with the MongoDB. 3. Document model is well defined. Structure of document is clear, Document is the unit of storing data in a MongoDB database. Documents are analogous to the records of RDBMS table. Insert, update and delete operations can be performed on a collection. Document use JSON (JavaScript Object Notation) approach for storing data. JSON is a lightweight, self-describing format used to exchange data between various applications. JSON data basically has key-value pairs. Documents have dynamic schema.
113.
4. MongoDB isa document data store in which one collection holds different documents. Data store in the form of JSON-style documents. Number of fields, content and size of the document can differ from one document to another. 5. Storing of data is flexible, and data store consists of JSON-like documents. This implies that the fields can vary from document to document and data structure can be changed over time; JSON has a standard structure, and scalable way of describing hierarchical data 6. Storing of documents on disk is in BSON serialization format. BSON is a binary representation of JSON documents. The mongo JavaScript shell and MongoDB language drivers perform translation between BSON and language-specific document representation. Features of MongoDB
114.
Features of MongoDB 7.Querying, indexing, and real time aggregation allows accessing and analyzing the data efficiently. 8. Deep query-ability—Supports dynamic queries on documents using a document-based query language that's nearly as powerful as SQL. 9. No complex Joins. 10. Distributed DB makes availability high, and provides horizontal scalability. 11. Indexes on any field in a collection of documents: Users can create indexes on any field in a document. Indices support queries and operations. By default, MongoDB creates an index on the _id field of every collection.
115.
12 Atomic operationson a single document can be performed even though support of multi-document transactions is not present. The operations are alternate to ACID transaction requirement of a relational DB. 13. Fast-in-place updates: The DB does not have to allocate new memory location and write a full new copy of the object in case of data updates. This results into high performance for frequent update use cases. For example, incrementing a counter operation does not fetch the document from the server. Here, the increment operation can simply be set. 14. No configurable cache: MongoDB uses all free memory on the system automatically by way of memory- mapped files (The operating systems use the similar approach with their file system caches). The most recently used data is kept in RAM. If indexes are created for queries and the working dataset fits in RAM, MongoDB serves all queries from memory. 15. Conversion/mapping of application objects to data store objects not needed Features of MongoDB
To Create database: Commandis use — use command creates a database; For example, Command use lego creates a database named lego. (A sample database is created to demonstrate subsequent queries. The Lego is an international toy brand). Default database in MongoDB is test. To see the existence of database: Command is db — db command shows that lego database is created. To get list of all the databases: Command is show dbs — This command shows the names of all the databases.
122.
To drop database: Commandis db.dropDatabase () - This command drops a database. Run use lego command before the db.dropDatabase () command to drop lego Database. If no database is selected, the default database test will be dropped. To create a collection Command is insert () - To create a collection, the easiest way is to insert a record (a document consisting of keys (Field names) and Values) into a collection. A new collection will be created, if the collection does not exist. The following statements demonstrate the creation of a collection with three fields (ProductCategory, Productld and ProductName) in the lego
123.
• To createa collection Command is insert () - To create a collection, the easiest way is to insert a record (a document consisting of keys (Field names) and Values) into a collection. A new collection will be created, if the collection does not exist. The following statements demonstrate the creation of a collection with three fields (ProductCategory, Productld and ProductName) in the lego
124.
To add arrayin a collection: Command is insert () - Insert command can also be used to insert multiple documents into a collection at one time.
126.
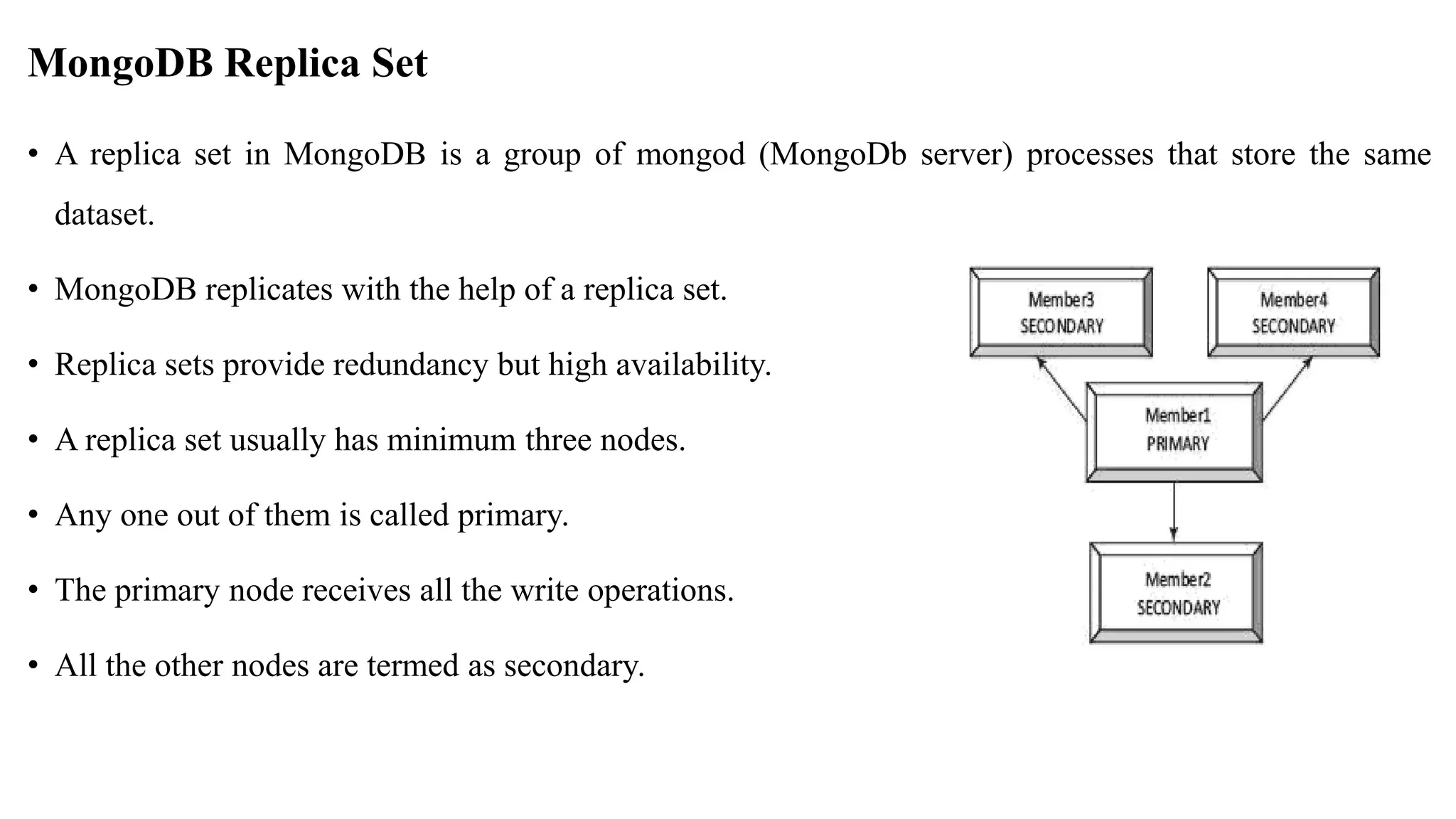
MongoDB Replica Set •A replica set in MongoDB is a group of mongod (MongoDb server) processes that store the same dataset. • MongoDB replicates with the help of a replica set. • Replica sets provide redundancy but high availability. • A replica set usually has minimum three nodes. • Any one out of them is called primary. • The primary node receives all the write operations. • All the other nodes are termed as secondary.
127.
The data replicatesfrom primary to secondary nodes. A new primary node can be chosen among the secondary nodes at the time of automatic failover or maintenance. The failed node when recovered can join the replica set as secondary node again.
128.
Following are thecommands used for replication (Recoverability means even on occurrences of failures; the transactions ensure consistency).
129.
Auto-sharding • Sharding isa method for distributing data across multiple machines in a distributed application environment. • Vertical scaling by increasing the resources of a single machine is quite expensive. Thus, horizontal scaling of the data can be achieved using sharding mechanism where more database servers can be added to support data growth and the demands of more read and write operations. • Sharding automatically balances the data and load across various servers. Sharding provides additional write capability by distributing the write load over a number of mongod (MongoDB Server) instances. • DB has a 1 terabyte dataset distributed amongst 20 shards, then each shard contains only 50 Giga Byte of data.
Cassandra Database • Cassandrawas developed by Facebook and released by Apache. • Cassandra is basically a column family database that stores and handles massive data of any format including structured, semi-structured and unstructured data. • Apache Cassandra DBMS contains a set of programs. They create and manage databases. Cassandra provides functions (commands) for querying the data and accessing the required information. • Functions do the viewing, querying and changing (update, insert or append or delete), visualizing and perform transactions on the DB. • Apache Cassandra has the distributed design • Cassandra is written in Java. • Big organizations, such as Facebook, IBM, Twitter, Cisco, Rackspace, eBay, Twitter and Netflix have adopted Cassandra.
132.
Characteristics of Cassandra (i)open source, (ii) scalable (iii) non-relational (iv) NoSQL (v) Distributed (vi) column based, (vii) decentralized, (viii) fault tolerant and (ix) tuneable consistency.
133.
Features of Cassandraare as follows: 1. Maximizes the number of writes - writes are not very costly (time consuming) 2. Maximizes data duplication 3. Does not support Joins, group by, OR clause and aggregations 4. Is fast and easily scalable as write operations spread across the cluster. The cluster does not have a master-node, so any read and write can be handled by any node in the cluster. 5. Is a distributed DBMS designed for handling a high volume of structured data across multiple cloud servers 6. Uses PPD (Peer to Peer Data distribution model) Data distribution model
134.
Data Replication • Cassandrastores data on multiple nodes (data replication) and thus has no single point of failure, and ensures availability, a requirement in CAP theorem. • Cassandra returns the most recent value of the data to the client. • If it has detected that some of the nodes responded with a stale value, Cassandra performs a read repair in the background to update the stale values.
Scalability: Cassandra provides linearscalability which increases the throughput and decreases the response time on increase in the number of nodes at cluster. Transaction Support Supports ACID properties (Atomicity, Consistency, Isolation, and Durability). Replication Option: Specifies any of the two replica placement strategy. The strategy names are Simple Strategy or Network Topology Strategy. 1. Simple Strategy: Specifies simply a replication factor for the cluster. 2. Network Topology Strategy: Allows setting the replication factor for each data center independently.
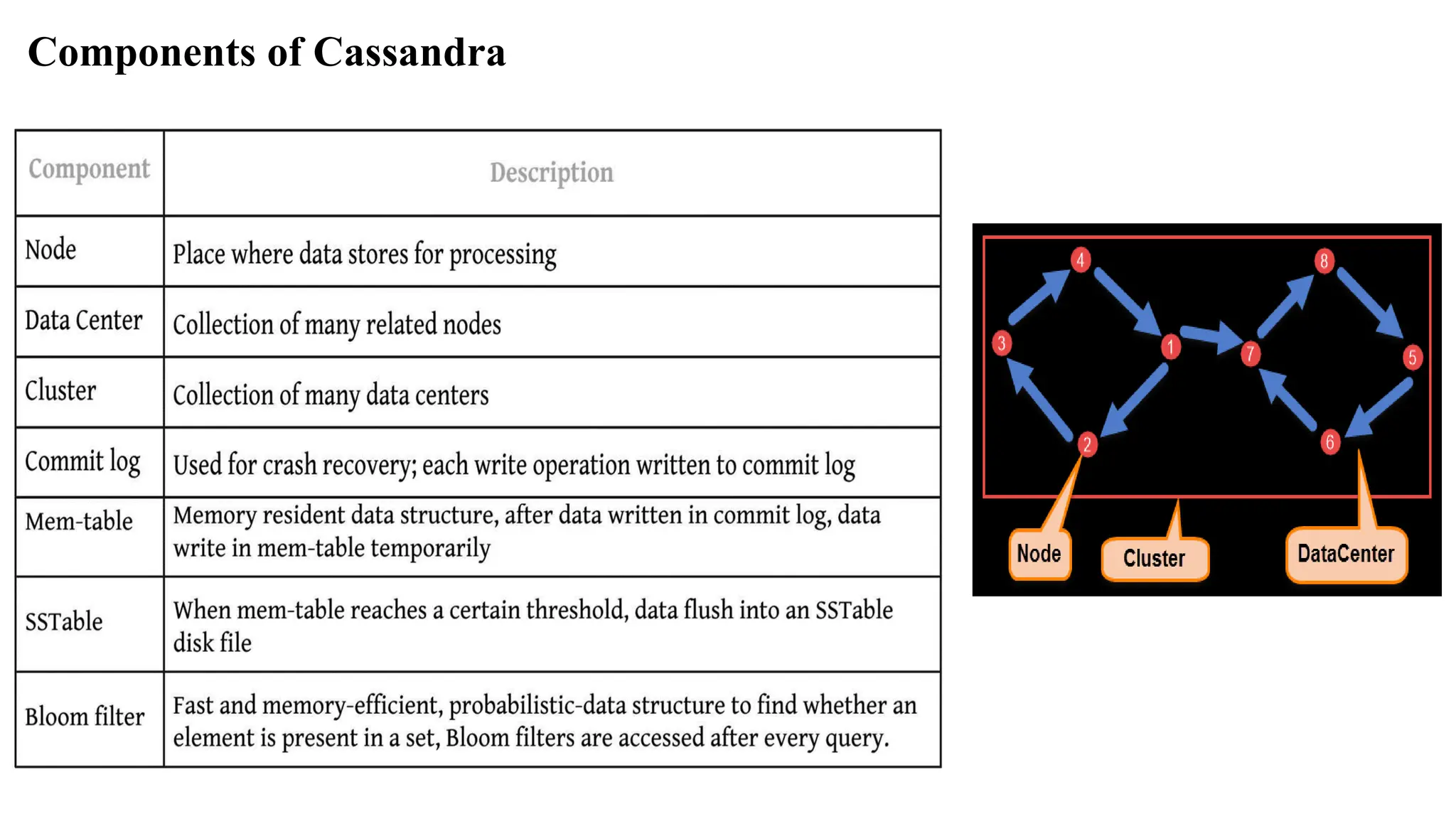
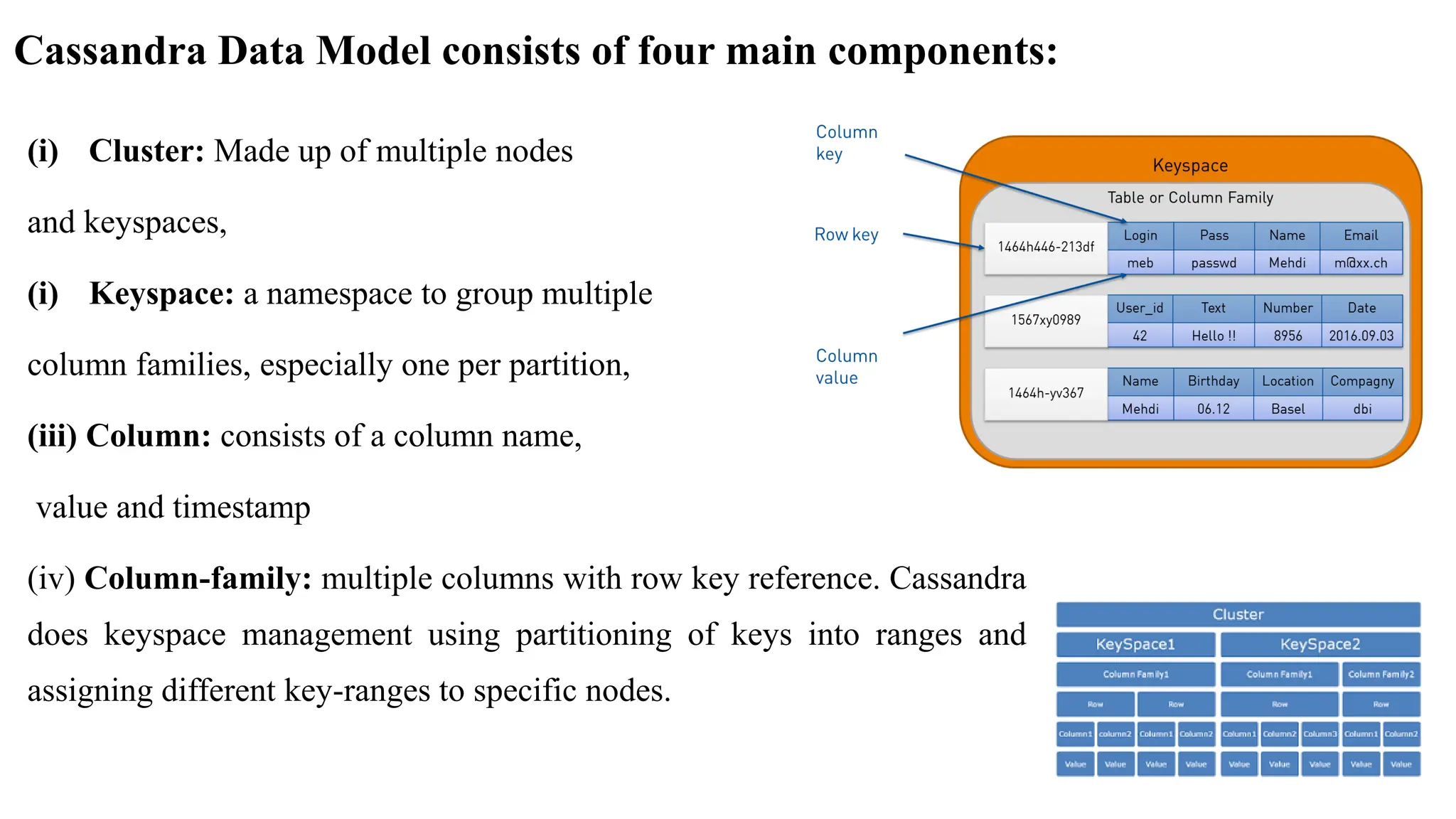
Cassandra Data Modelconsists of four main components: (i) Cluster: Made up of multiple nodes and keyspaces, (i) Keyspace: a namespace to group multiple column families, especially one per partition, (iii) Column: consists of a column name, value and timestamp (iv) Column-family: multiple columns with row key reference. Cassandra does keyspace management using partitioning of keys into ranges and assigning different key-ranges to specific nodes.
139.
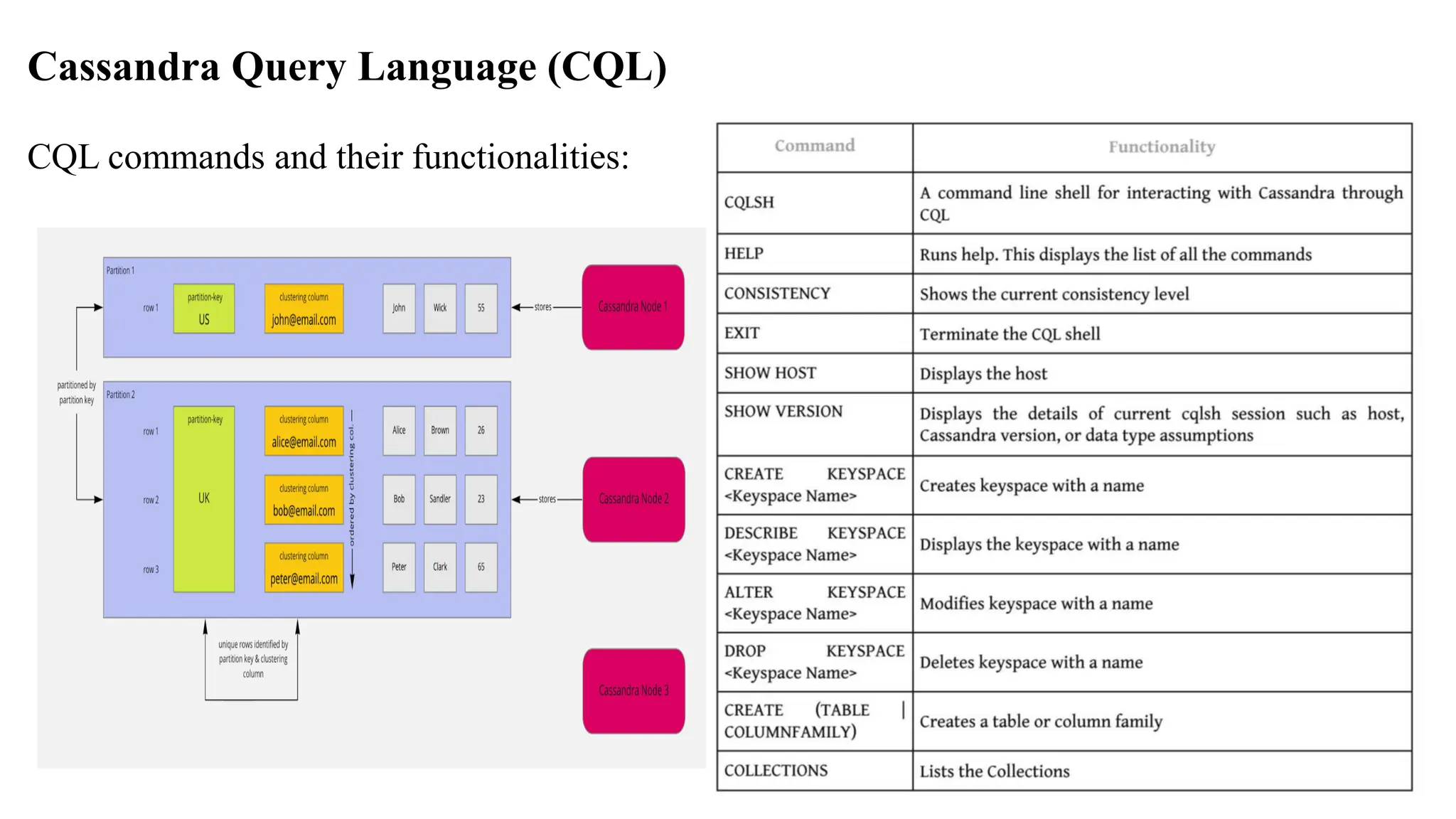
Following Commands printsa description DESCRIBE CLUSTER DESCRIBE SCHEMA DESCRIBE KEYSPACES DESCRIBE KEYSPACE <keyspace name> DESCRIBE TABLES DESCRIBE TABLE <table name> DESCRIBE INDEX <index name> DESCRIBE MATERIALIZED VIEW <view name> DESCRIBE TYPES DESCRIBE TYPE <type name> DESCRIBE FUNCTIONS DESCRIBE FUNCTION <function name> DESCRIBE AGGREGATES DESCRIBE AGGREGATE <aggregate function name>
140.
Consistency Command CONSISTENCYshows the current consistency level. CONSISTENCY <LEVEL> sets a new consistency level. Valid consistency levels are ALL, ANY, ONE, TWO, THREE, QUORUM, LOCAL_ONE, LOCAL_QUORUM, EACH_QUORUM, SERIAL AND LOCAL_SERIAL. 1. ALL: Highly consistent. A write must be written to commitlog and memtable on all replica nodes in the cluster. 2. EACH_QUORUM: A write must be written to commitlog and memtable on quorum of replica nodes in all data centers. 3. LOCAL_QUORUM: A write must be written to commitlog and memtable on quorum of replica nodes in the same center. 4. ONE: A write must be written to commitlog and memtable of at least one replica node. 5. TWO, THREE: Same as One but at least two and three replica nodes, respectively.
141.
6. LOCAL_ONE: Awrite must be written for at least one replica node in the local data center. 7. ANY: A write must be written to at least one node. 8. SERIAL: Linearizable consistency to prevent unconditional update. 9. LOCAL SERIAL: Same as Serial but restricted to the local data center.
142.
Keyspaces Keyspaces: A keyspace(or key space) in a NoSQL data store is an object that contains all column families data as a bundle. Keyspace is the outermost grouping of the data in the data store. Generally, there is one keyspace per application. Keyspace in Cassandra is a namespace that defines data replication on nodes. A cluster contains one keyspace per node. Create Keyspace Command CREATE KEYSPACE <Keyspace Name> WITH replication = {'class : '<Strategy name>', 'replication_factor': '<No. of replicas>'} AND durablewrites= '<TRUE/FALSE>'; CREATE KEYSPACE statement has attributes replication with option class and replication factor, and durable_write.
143.
Default value ofdurable_writes properties of a table is set to true. This commands the Cassandra to use Commit Log for updates on the current Keyspace. The option is not compulsory. 1. ALTER KEYSPACE command changes (alter) properties, such as the number of replicas and the durable_writes of a keyspace: ALTER KEYSPACE <Keyspace Name> WITH replication = {`class': '<Strategy name>', `replication_factor': '<No. of replicas>'}; 2. DESCRIBE KEYSPACE command displays the existing keyspaces. 3. DROP KEYSPACE command drops a keyspace: 4. Re-executing the drop command to drop the same keyspace will result in configuration exception. 5. Use KEYSPACE command connects the client session with a keyspace.















![NoSQL data store characteristics are as follows: 1. NoSQL is a class of non-relational data storage system with flexible data model. Examples of NoSQL data- architecture patterns of datasets are - key-value pairs, - name/value pairs, - Column family Big-data store, - Tabular data store, - Cassandra (used in Facebook/Apache), - HBase, hash table [Dynamo (Amazon S3)], - JSON (CouchDB), JSON (PNUTS), - JSON (MongoDB), Graph Store, Object Store, ordered keys and semi-structured data storage systems.](https://image.slidesharecdn.com/module2nosql-241106043720-a01e1f70/75/NoSQL-BIg-Data-Analytics-Mongo-DB-and-Cassandra-pdf-23-2048.jpg)





















![Following are the features in Document Store: 1. Document stores unstructured data. 2. Storage has similarity with object store. 3. Data stores in nested hierarchies. For example, in JSON formats data model XML document object model (DOM), or machine-readable data as one BLOB [Binary Large Object]. Hierarchical information stores in a single unit called document tree. Logical data stores together in a unit. 4. Querying is easy. For example, using section number, sub-section number and figure caption and table headings to retrieve document partitions. 5. Transactions on the document store exhibit ACID properties.](https://image.slidesharecdn.com/module2nosql-241106043720-a01e1f70/75/NoSQL-BIg-Data-Analytics-Mongo-DB-and-Cassandra-pdf-50-2048.jpg)














![Example Give examples of XPath expressions. Let outermost element of the XML document is a. SOLUTION • An XPath expression /a/b/c selects c elements that are children of b elements that are children of element a that forms the outermost element of the XML document. • An XPath expression /a/b[c=5] selects elements b and c that are children of a and value of c element is 5. • An XPath expression /a[b/c]/d selects elements c and d where c is child of b and, b and d are children of a.](https://image.slidesharecdn.com/module2nosql-241106043720-a01e1f70/75/NoSQL-BIg-Data-Analytics-Mongo-DB-and-Cassandra-pdf-67-2048.jpg)

























![Typical uses of graph databases are: (i) link analysis, (ii) friend of friend queries, (iii) rule checking and [Finite Automata Theory] (iv) Pattern matching. Limitations of Graph Data Base: • Graph databases have poor scalability. • They are difficult to scale out on multiple servers. This is due to the close connectivity feature of each node in the graph. • Write operations to multiple servers and graph queries that span multiple nodes, can be complex to implement.](https://image.slidesharecdn.com/module2nosql-241106043720-a01e1f70/75/NoSQL-BIg-Data-Analytics-Mongo-DB-and-Cassandra-pdf-96-2048.jpg)




![SHARED-NOTHING ARCHITECTURE FOR BIG DATA TASKS 3. Master-Slave Distribution Model A node serves as a master or primary node and the other nodes are slave nodes. Master directs the slaves. Data gets replicated on the slave nodes. When a process updates the master, it updates the slaves also. A process uses the slaves for read operations and write is done in master. Processing performance improves when process runs large datasets distributed onto the slave nodes. Limitations of Master Slave Distribution Model: 1. Processing performance decreases due to replication in MSD distribution model, if in case the data is not found on the salve node. [Then it has to be obtained from the other node on which the data is replicated] 2. Complexity increases: Cluster-based processing has greater complexity than the other architectures. Consistency can also be affected in case of problem of significant time taken for updating.](https://image.slidesharecdn.com/module2nosql-241106043720-a01e1f70/75/NoSQL-BIg-Data-Analytics-Mongo-DB-and-Cassandra-pdf-103-2048.jpg)
![4. Peer-to-Peer Distribution Model [PPD Model]: SHARED-NOTHING ARCHITECTURE FOR BIG DATA TASKS Peer-to-Peer distribution (PPD) model and replication has the following characteristics: (1) All replication nodes accept read request and send the responses. (2) All replicas function equally [read support and write support also]. (3) Node failures do not cause loss of write capability, as other replicated node responds. Cassandra adopts the PPD model. Benefits: Performance can further be enhanced by adding the nodes. Since nodes read and write both, a replicated node also has updated data. Therefore, the biggest advantage in the model is consistency.](https://image.slidesharecdn.com/module2nosql-241106043720-a01e1f70/75/NoSQL-BIg-Data-Analytics-Mongo-DB-and-Cassandra-pdf-105-2048.jpg)
![4. Peer-to-Peer Distribution Model [PPD Model]: SHARED-NOTHING ARCHITECTURE FOR BIG DATA TASKS](https://image.slidesharecdn.com/module2nosql-241106043720-a01e1f70/75/NoSQL-BIg-Data-Analytics-Mongo-DB-and-Cassandra-pdf-106-2048.jpg)