Download as PDF, PPTX
















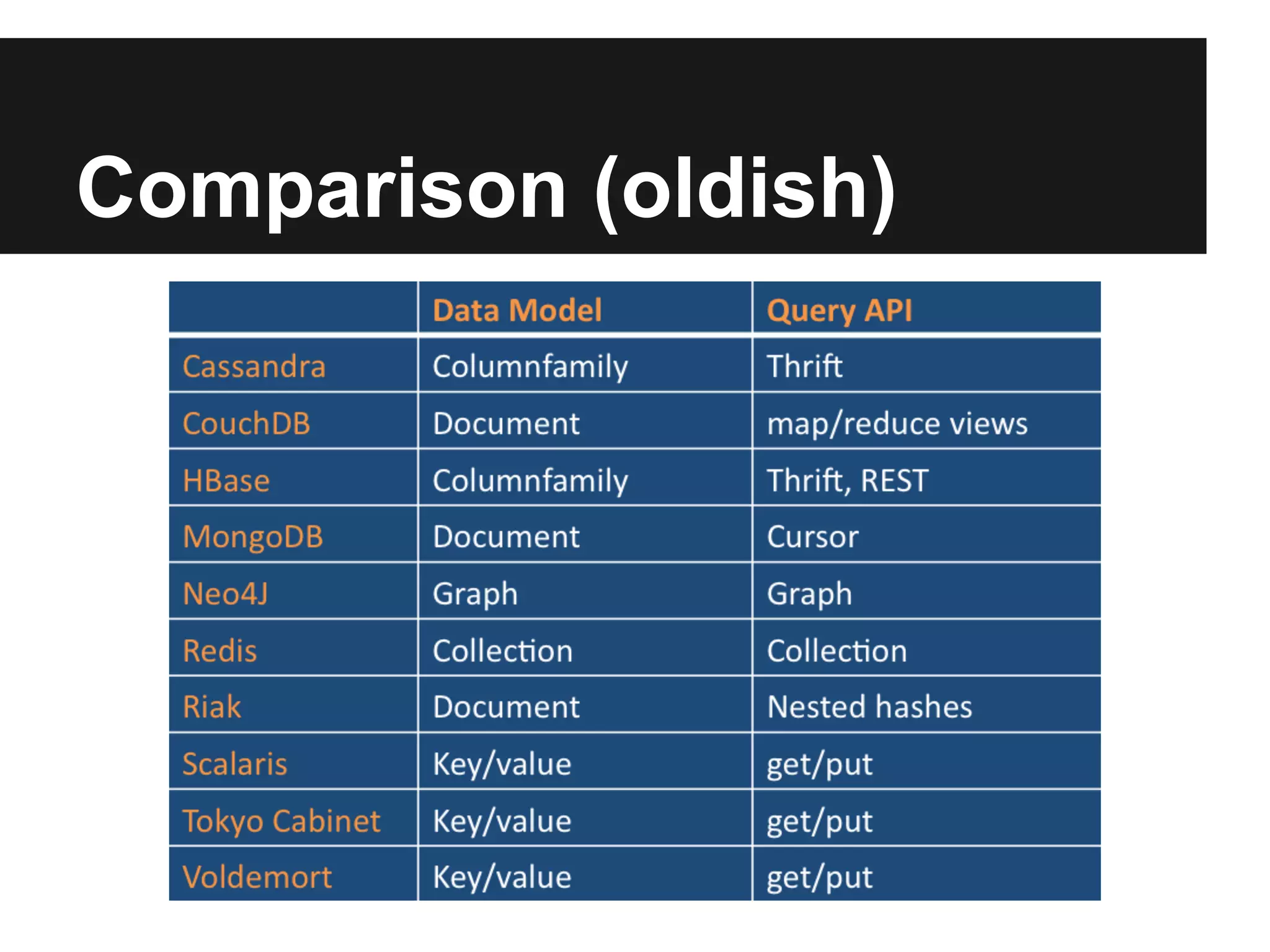
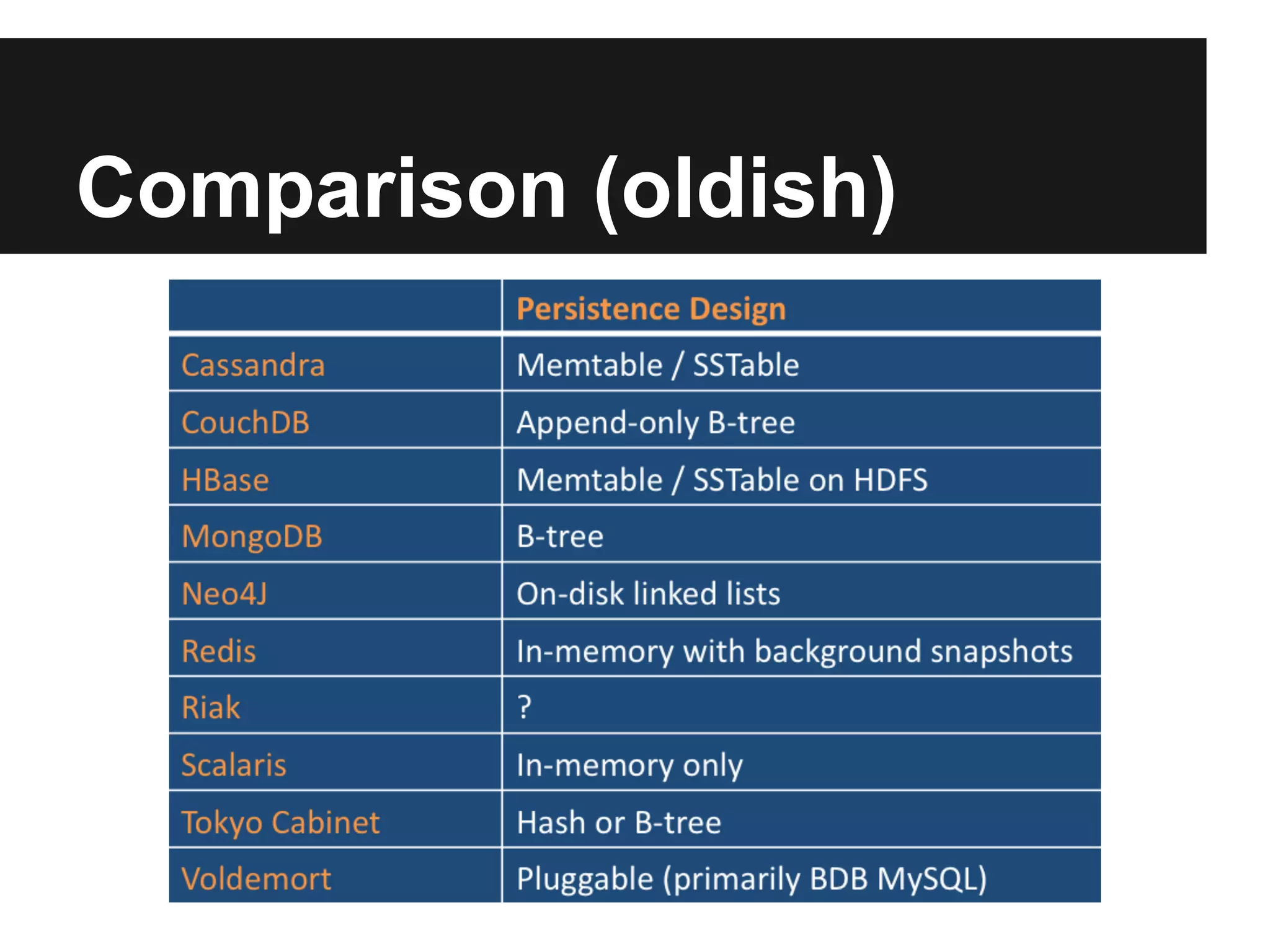



The document provides an overview of NoSQL databases, including their origins and motivations, characteristics, classifications, and current status. NoSQL databases are non-relational databases that were developed for large datasets requiring high performance and flexibility over rigid schemas. They include column-based, document-based, key-value, and graph databases. While diverse, they typically don't use SQL, are open source, and sacrifice consistency for performance and flexibility.