Download as PDF, PPTX






























![Application features use DBI::Const::GetInfoType; sub escape_for_like{ my ($self, $string) = @_; $string //= ''; my $escape_char = ''; $self ->storage->dbh_do(sub{ my ( $storage, $dbh ) = @_; if( my $new_escape = $dbh->get_info( $GetInfoType{SQL_SEARCH_PATTERN_ESCAPE} ) ) { $escape_char = $new_escape; } }); $string =~ s/([_%])/$escape_char$1/g; return $string; }](https://image.slidesharecdn.com/2192223c-41bf-481d-9a5c-ec048df8cc30-150424042005-conversion-gate01/75/PerlApp2Postgresql-2-31-2048.jpg)

















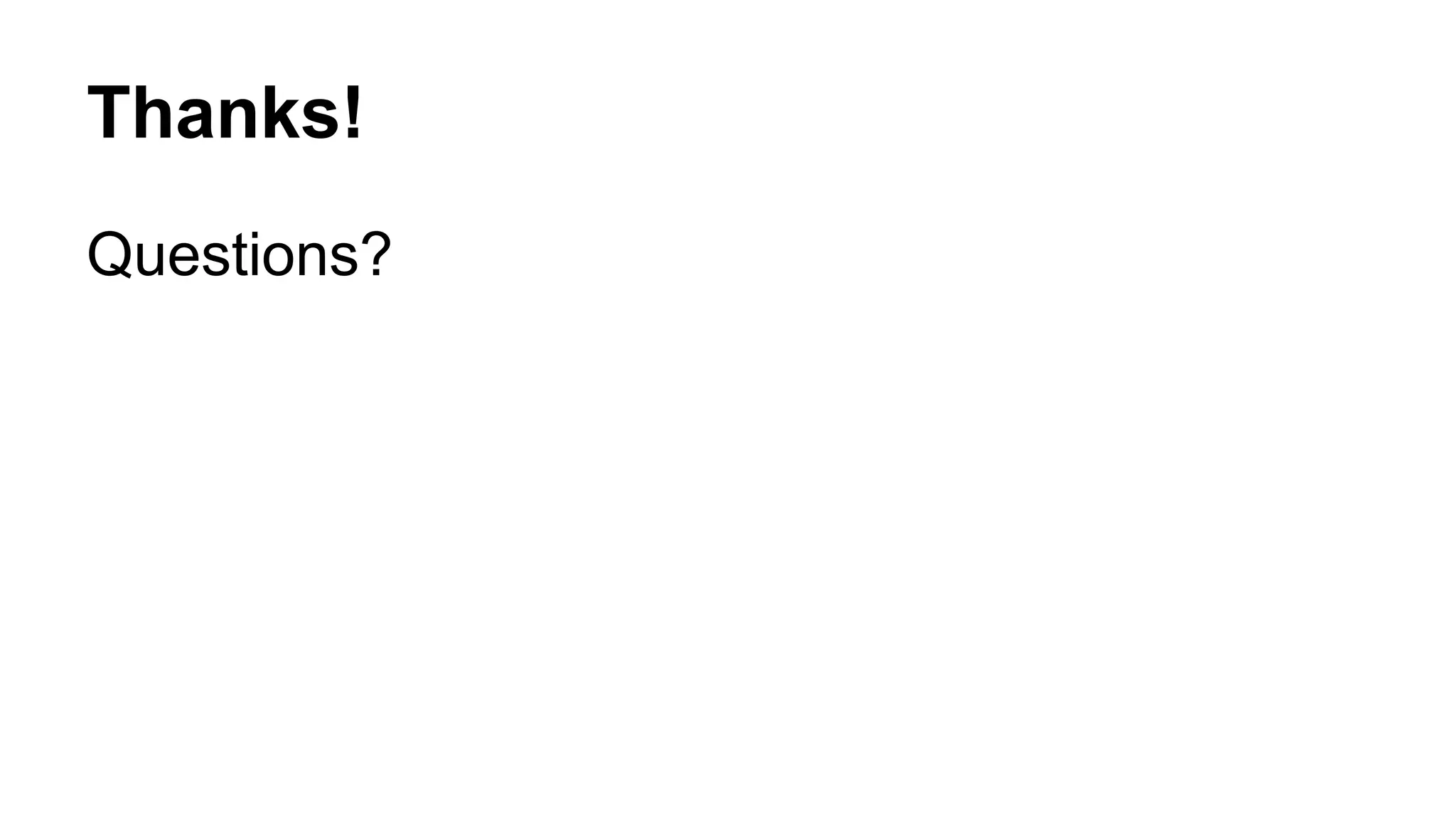

The document provides guidance on migrating a Perl application from MySQL to PostgreSQL. It discusses prerequisites like having a good test suite. Key steps include: automated schema migration where possible by adapting MySQL schemas to PostgreSQL; making code compatible by adding a "with_db" function to abstract differences; and migrating data through tools or custom scripts. Challenges addressed include data types, indexes, dates/times, application features like locking, and ensuring the application works as intended on PostgreSQL. Proper testing at each stage is emphasized for a successful migration.