





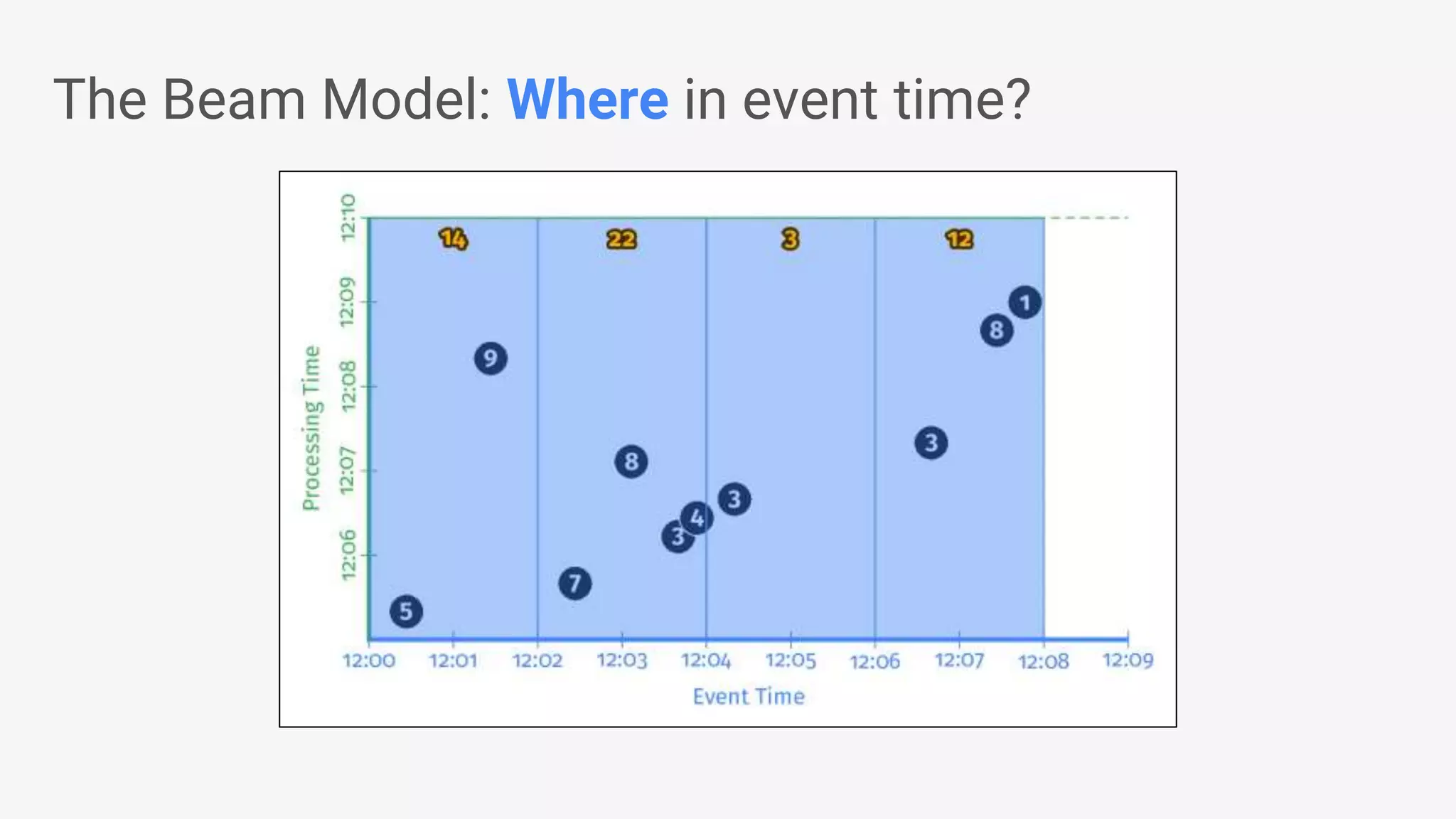

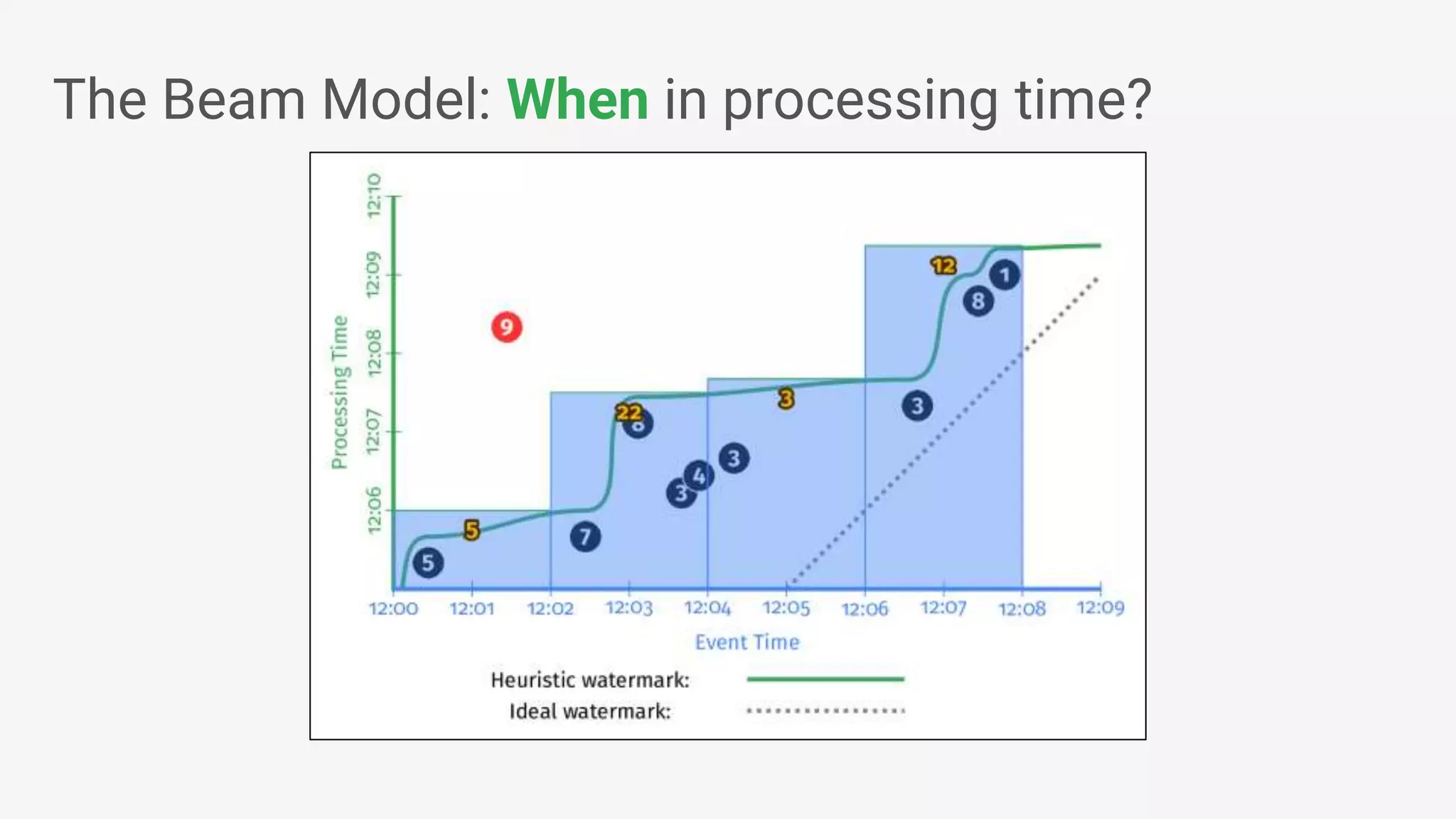

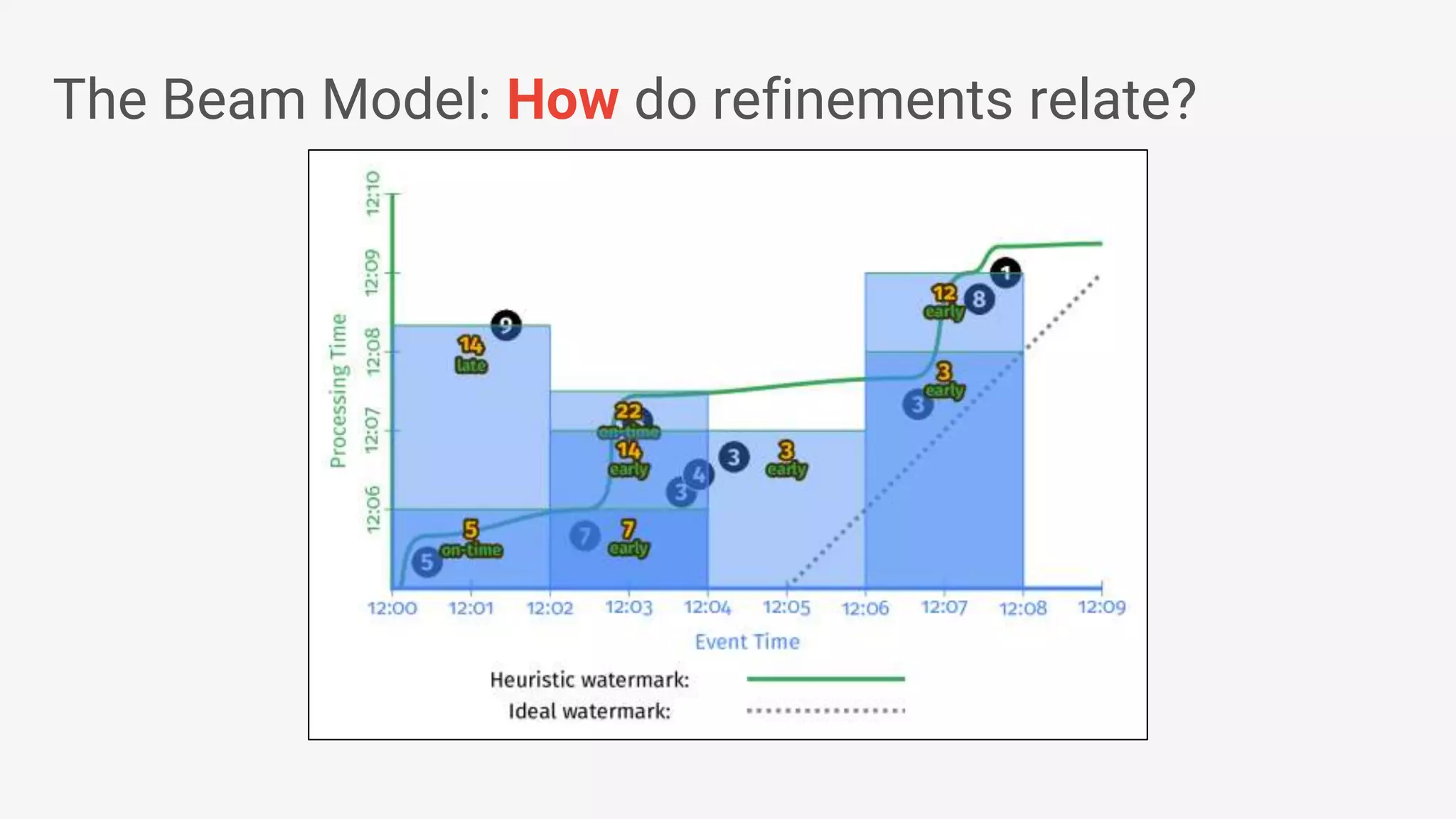
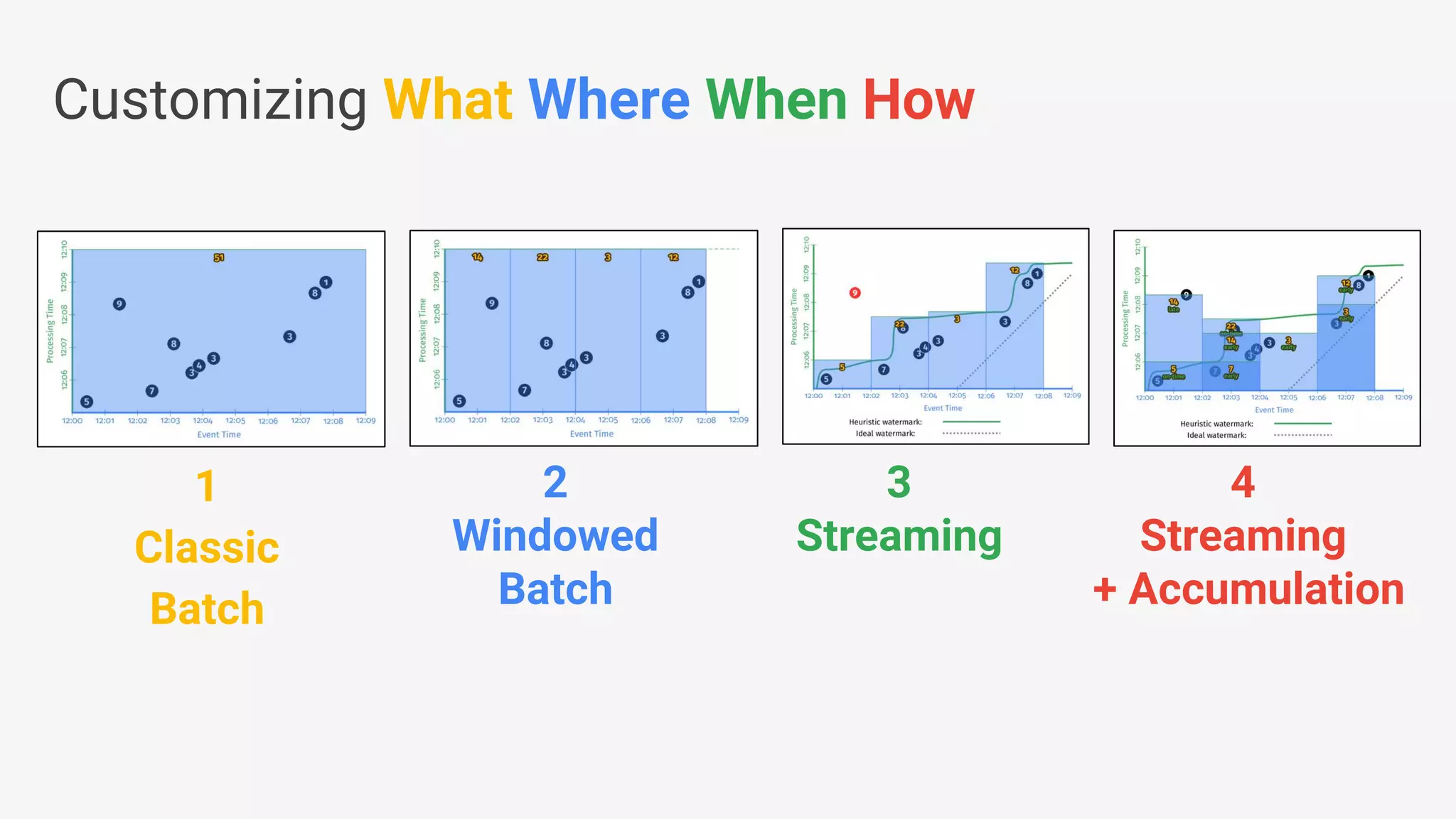


![● Beam’s Java SDK runs on multiple runtime environments, including: • Apache Apex • Apache Spark • Apache Flink • Google Cloud Dataflow • [in development] Apache Gearpump ● Cross-language infrastructure is in progress. • Beam’s Python SDK currently runs on Google Cloud Dataflow Beam Vision: as of March 2017 Beam Model: Fn Runners Apache Spark Cloud Dataflow Beam Model: Pipeline Construction Apache Flink Java Java Python Python Apache Apex Apache Gearpump](https://image.slidesharecdn.com/francesperryportablestreamingpipelineswithapachebeamkafkasummitnyc2017-170523193040/75/Portable-Streaming-Pipelines-with-Apache-Beam-20-2048.jpg)

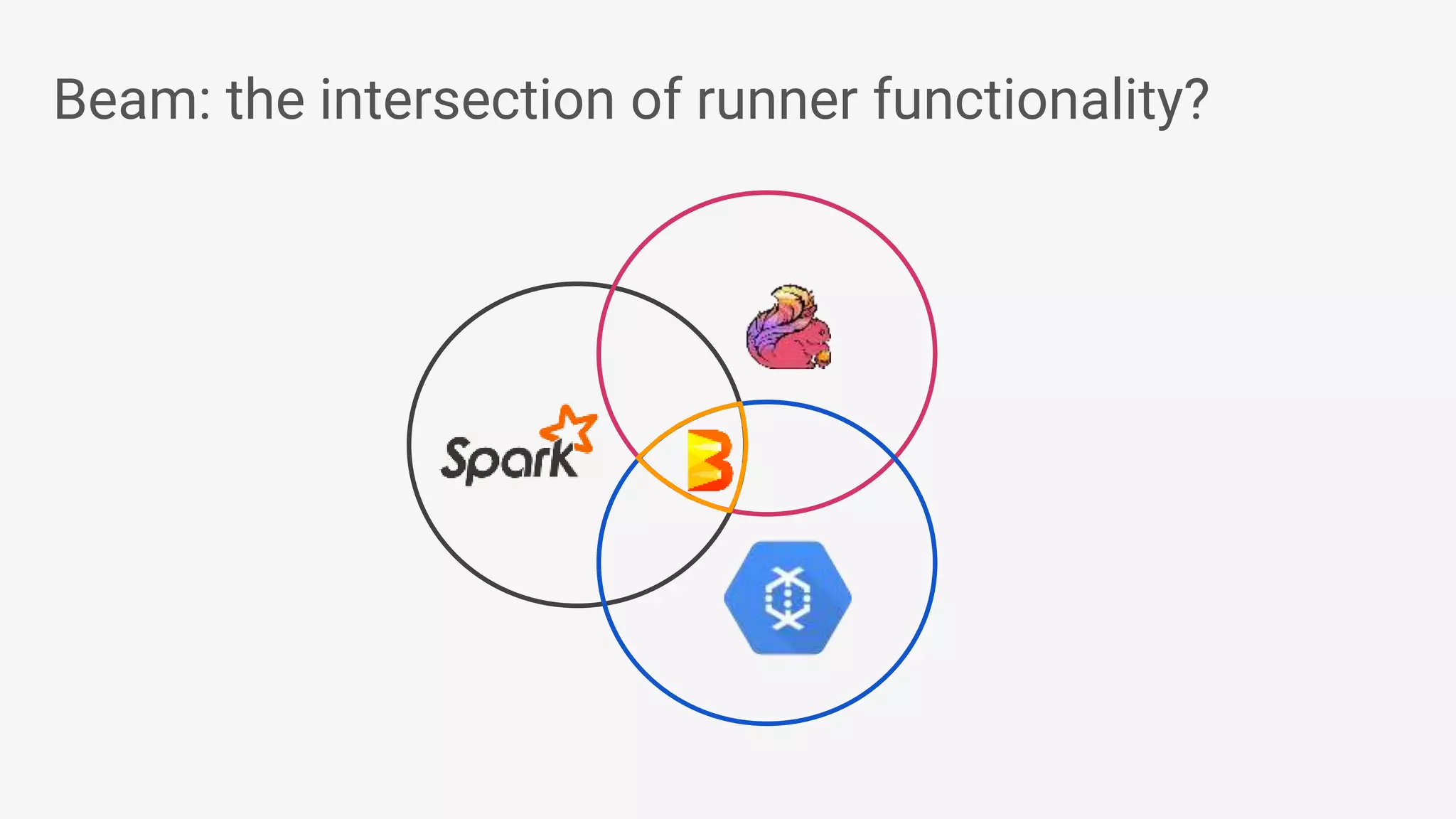
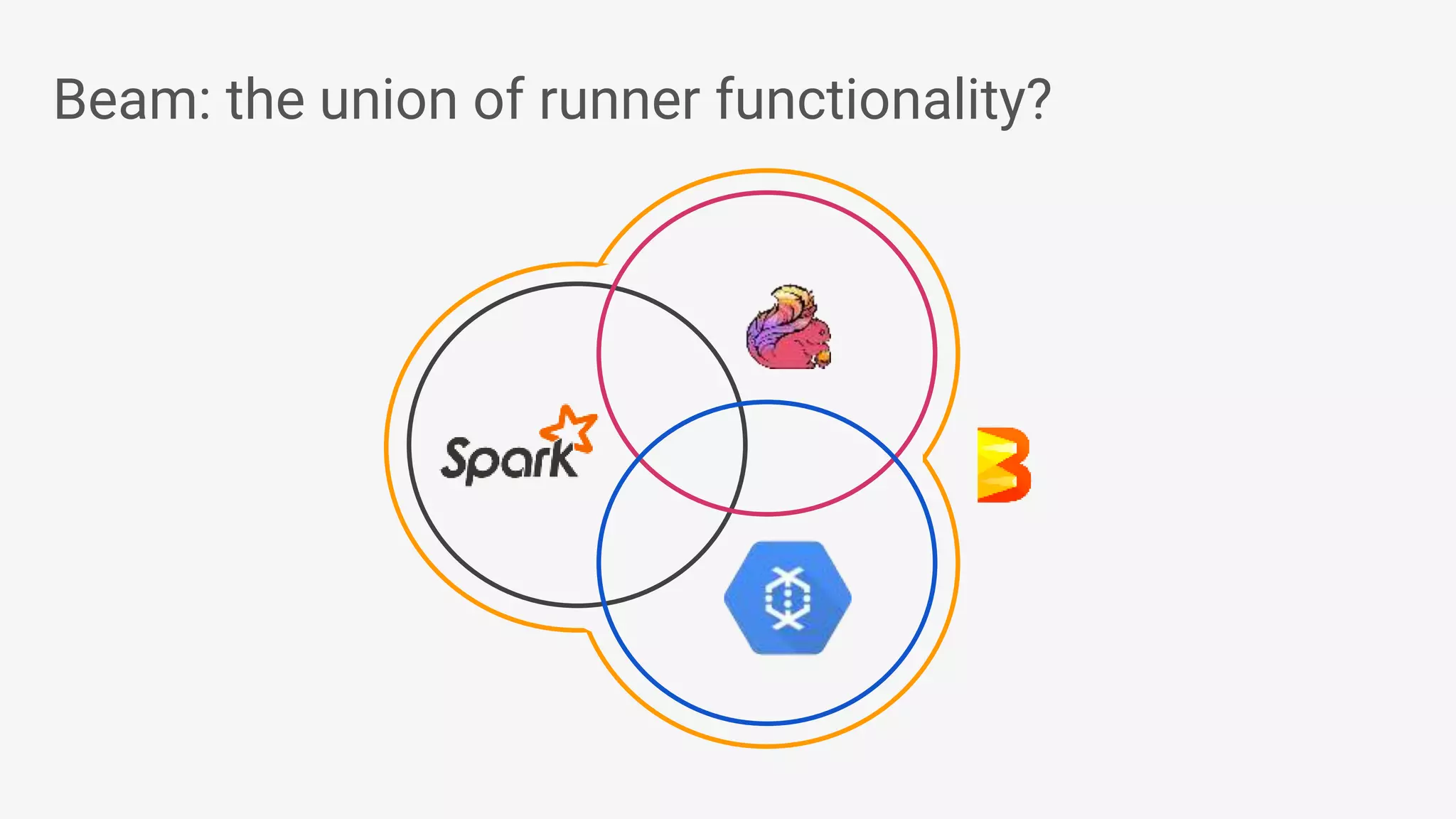






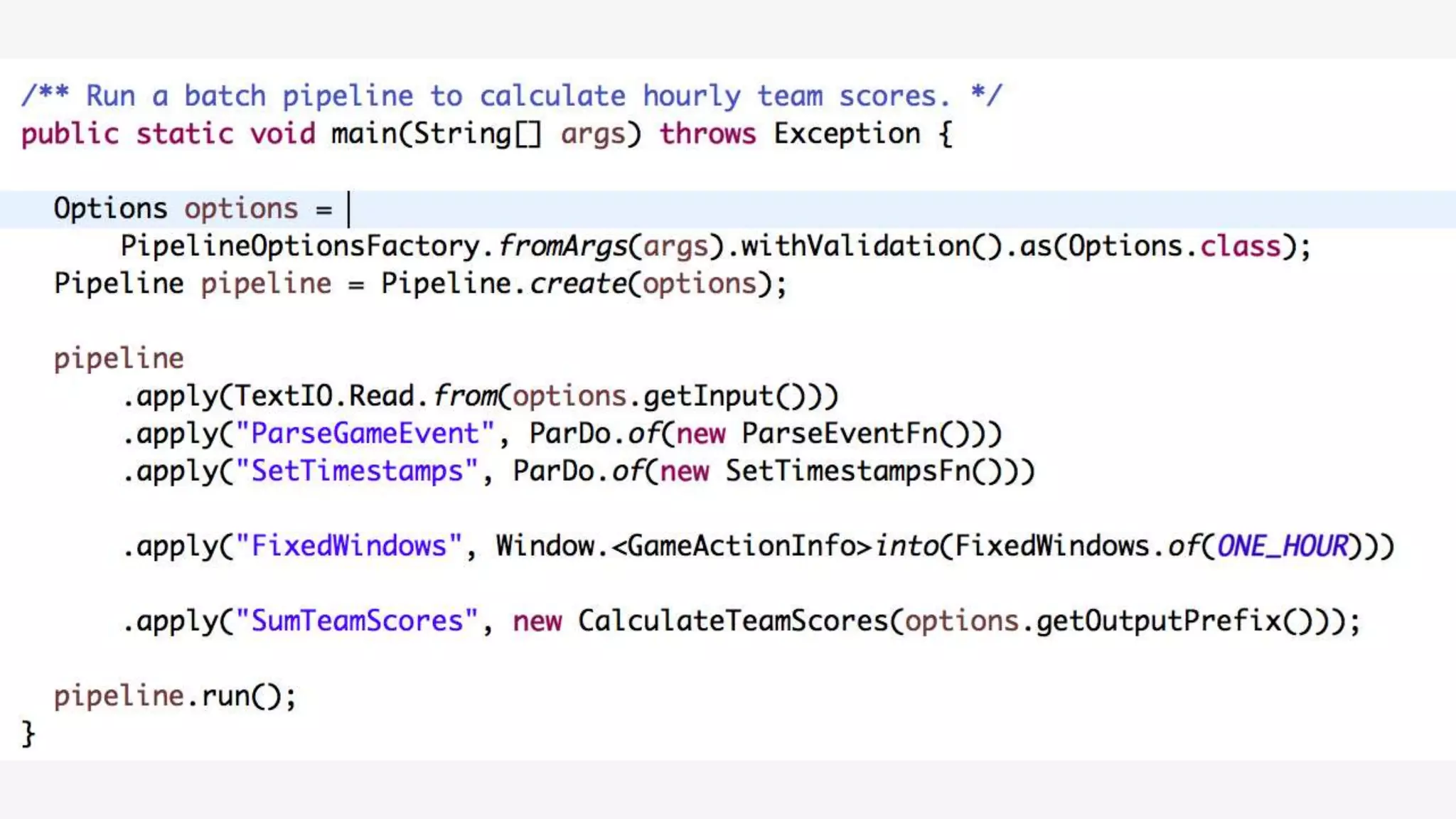
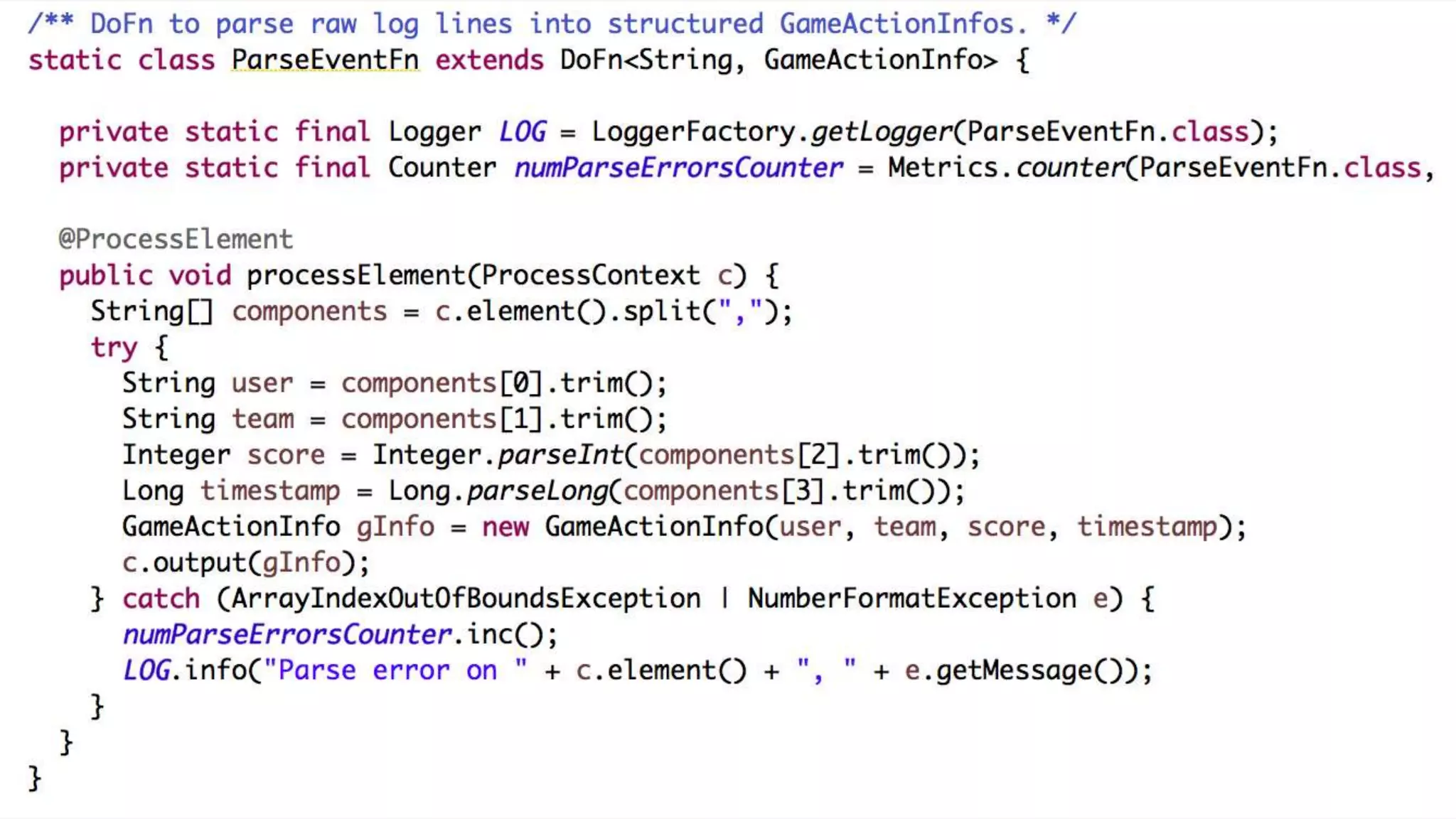
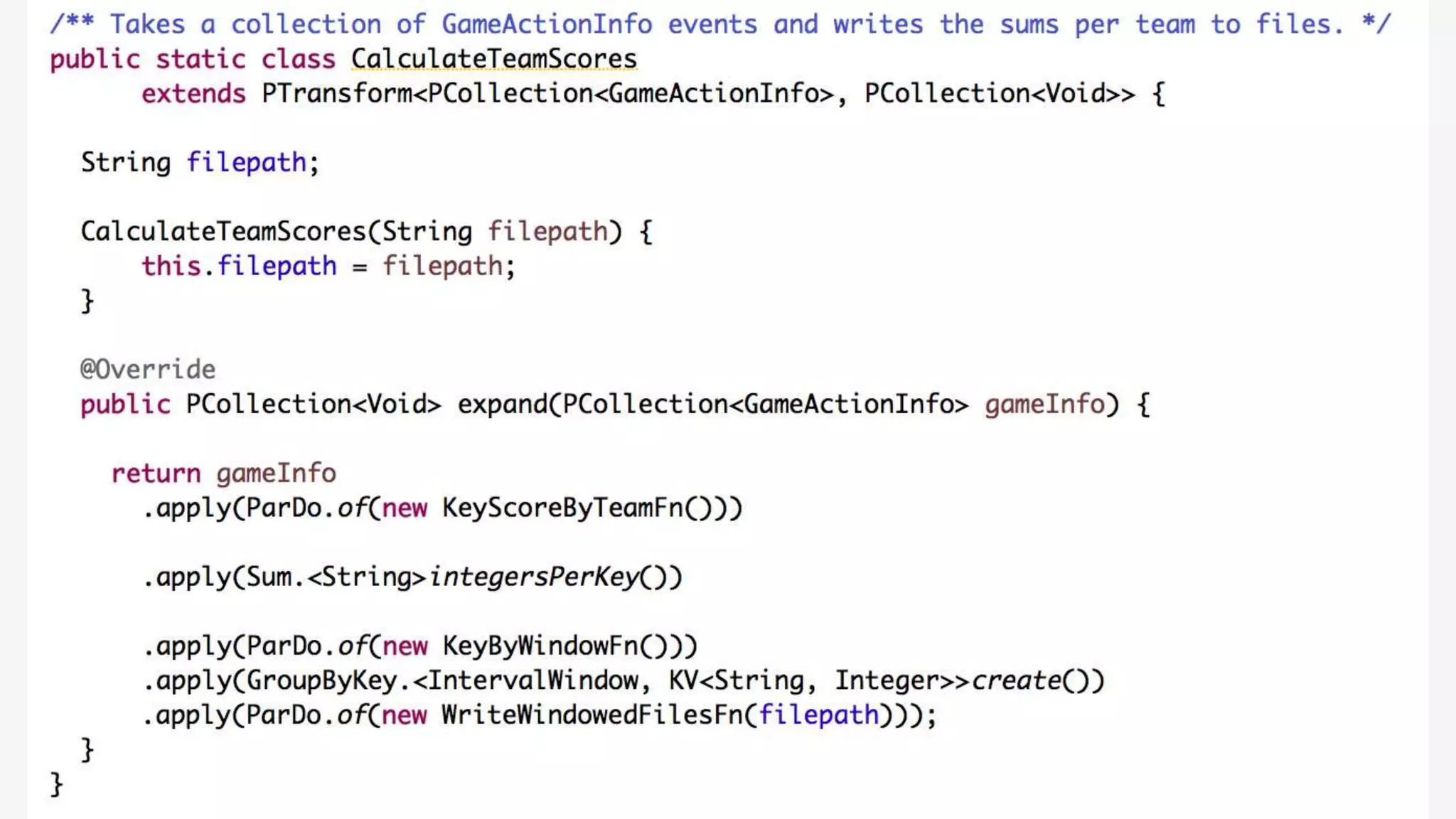


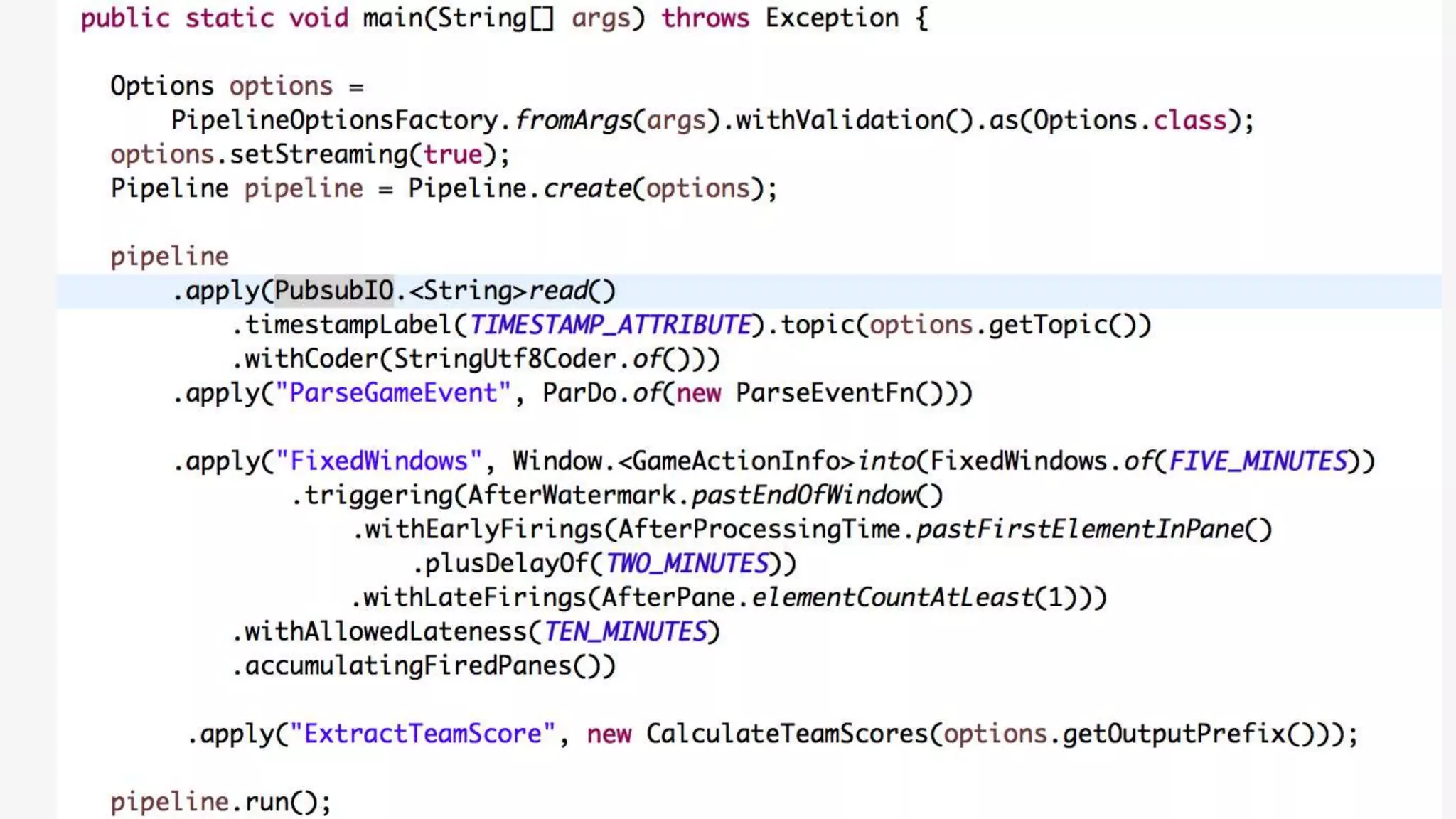
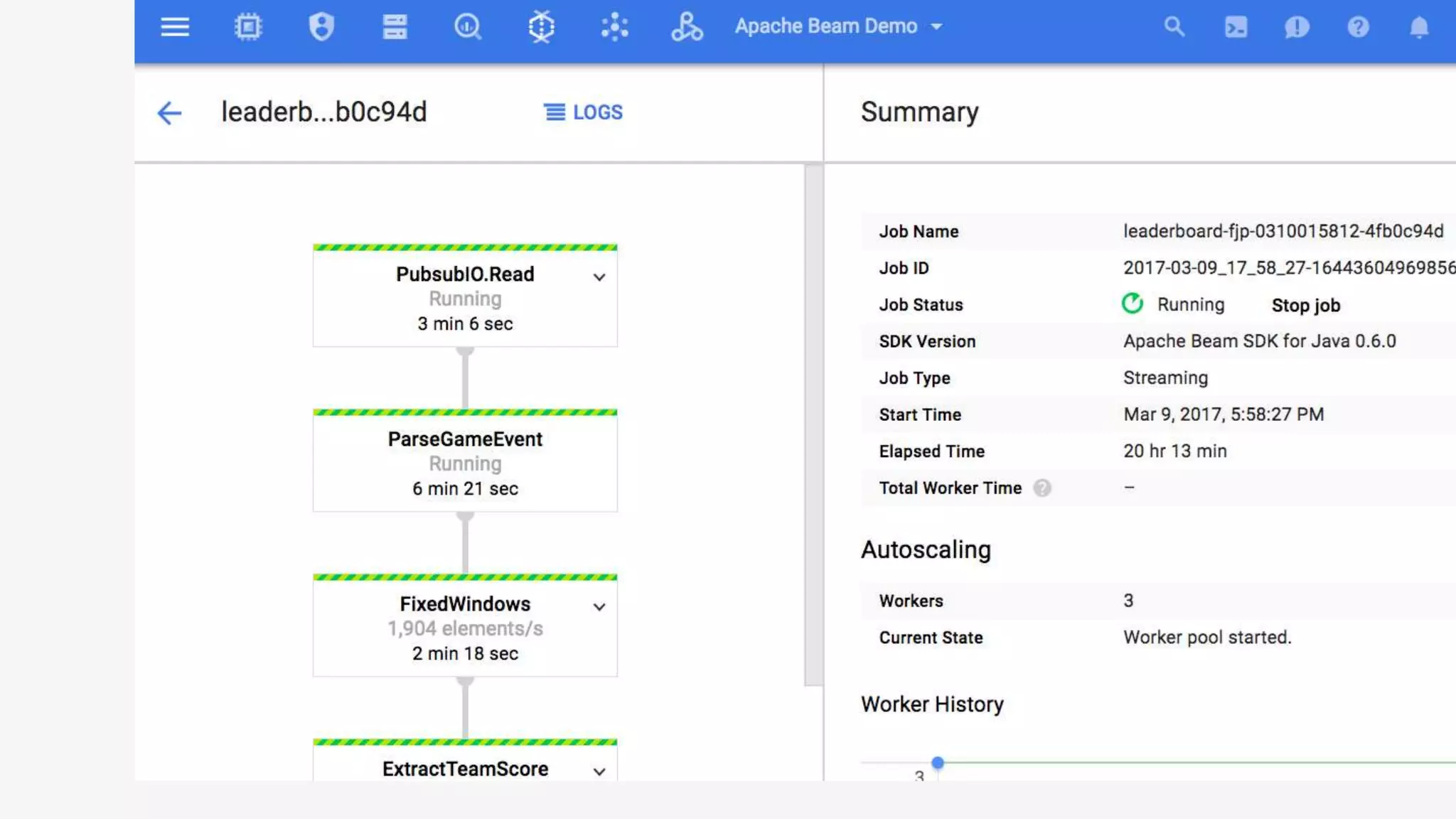

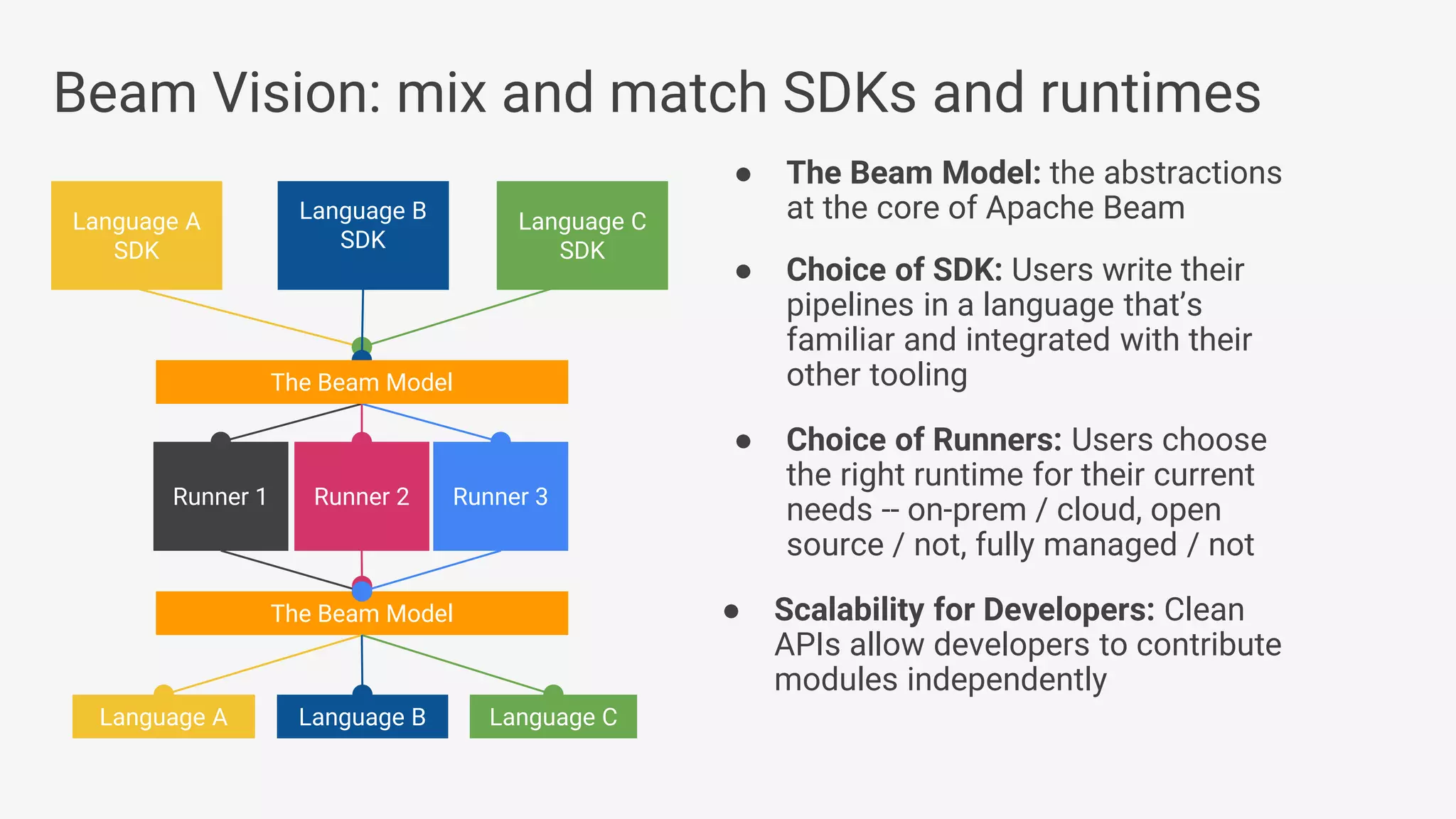
1) Apache Beam is an open source unified model for defining both batch and streaming data processing pipelines. It allows writing pipelines once that can run on multiple distributed processing backends. 2) The Beam model separates the data processing logic from runtime requirements. It defines concepts like processing time vs event time to allow portability across batch and streaming runners. 3) Beam supports extensible IO connectors and aims to allow pipelines written in one language to run on different runtimes through language-specific SDKs. Currently, Java and Python SDKs can run on backends like Apache Spark, Flink, and Google Cloud Dataflow.