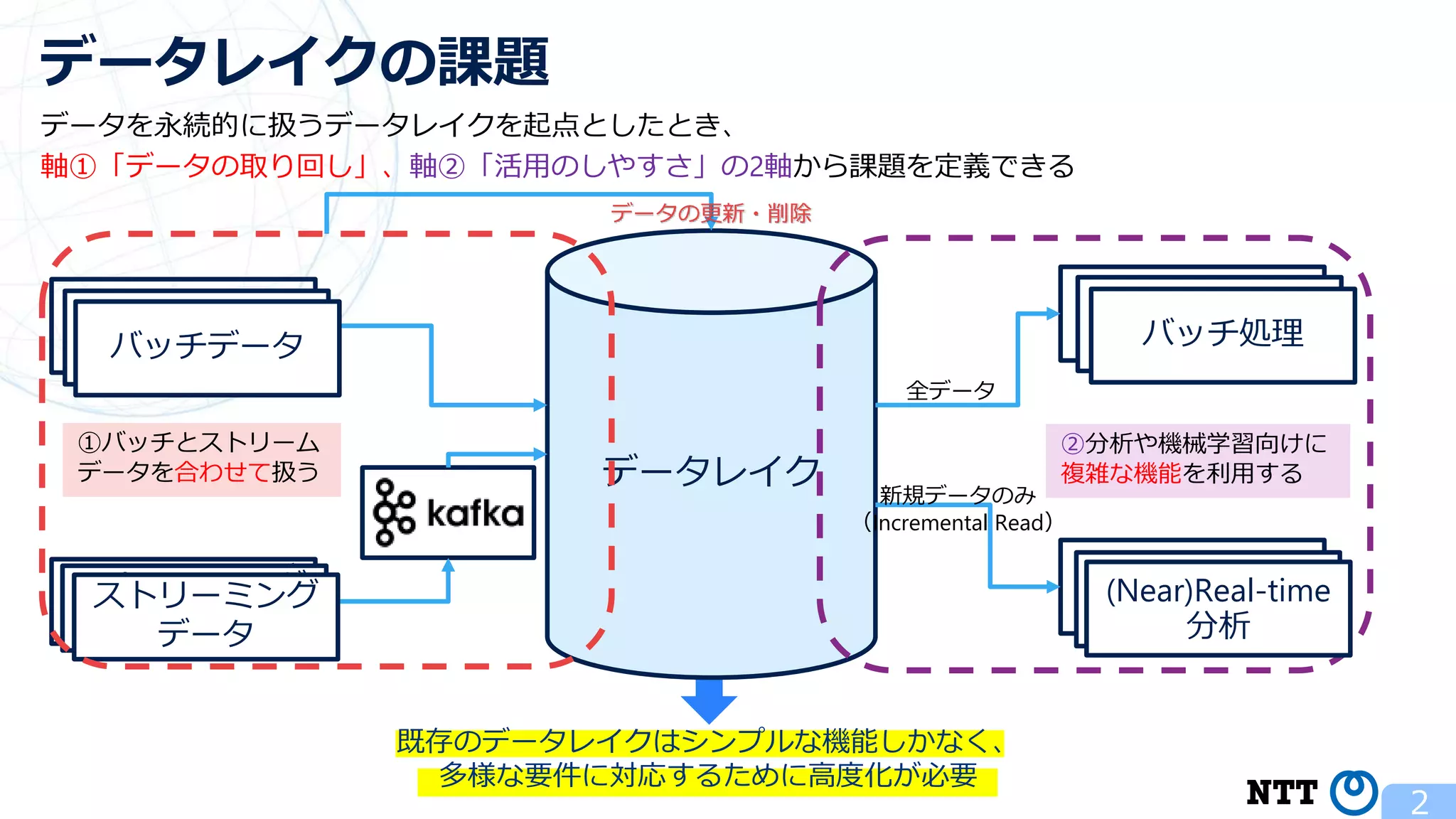
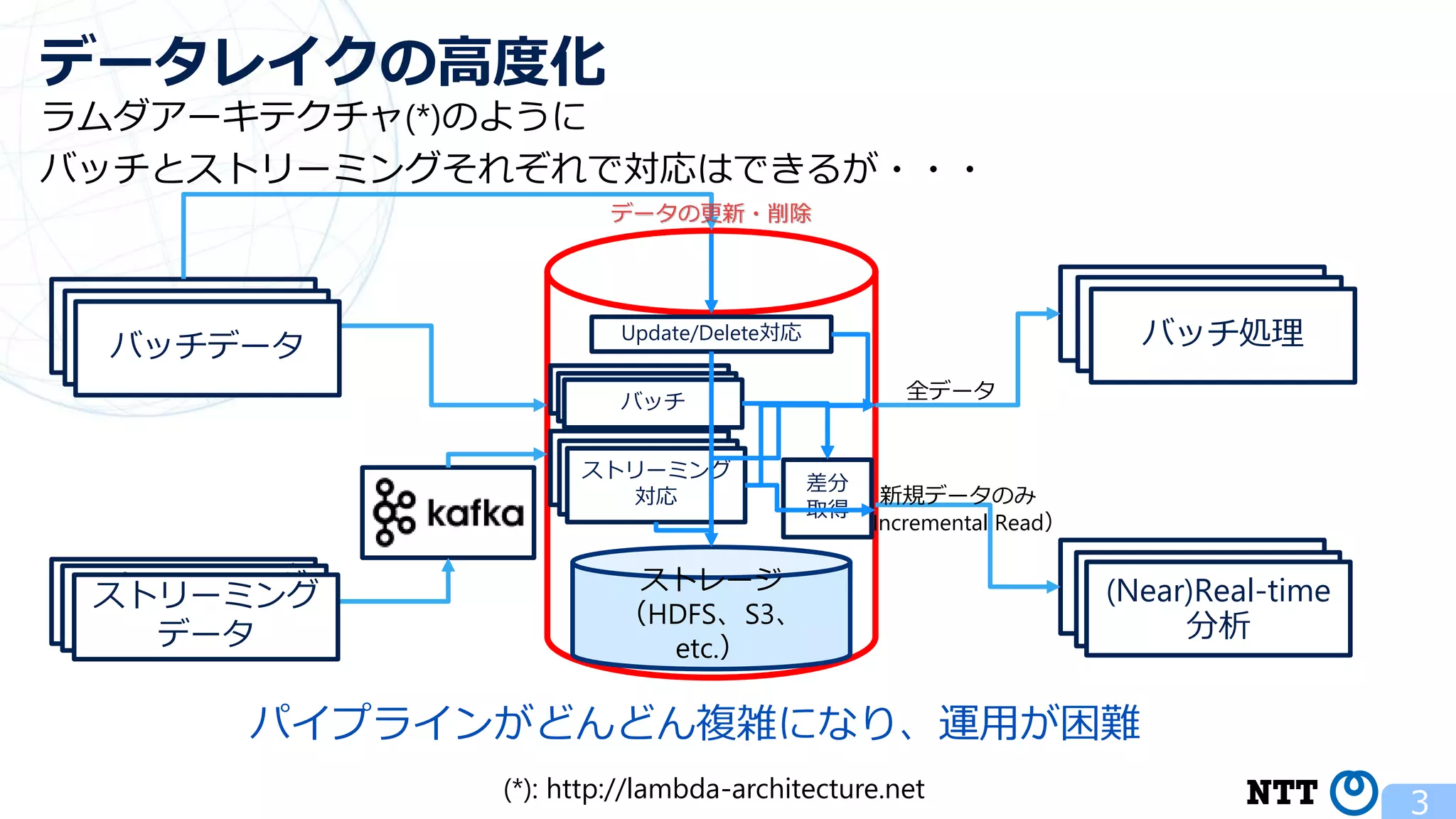
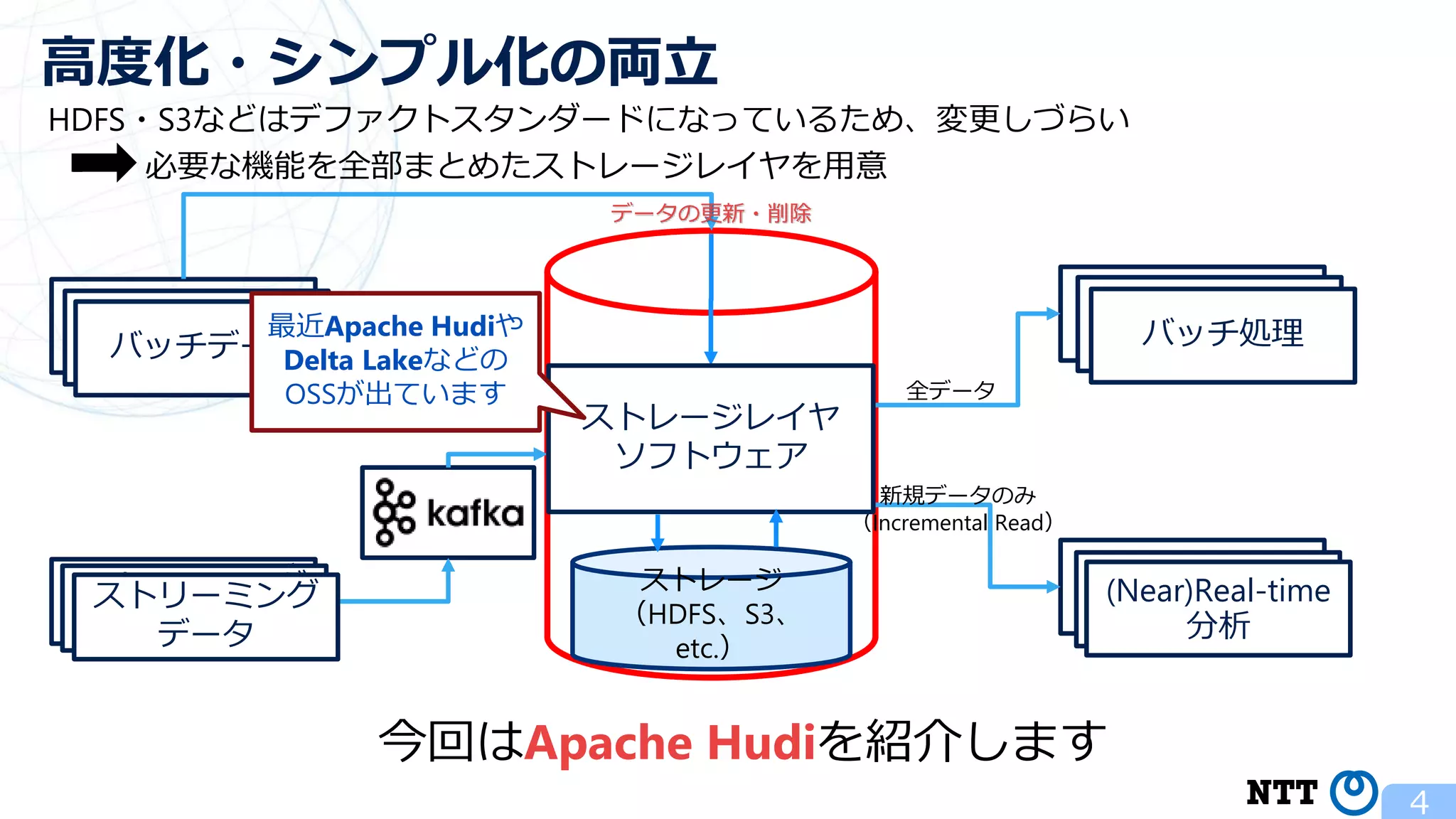
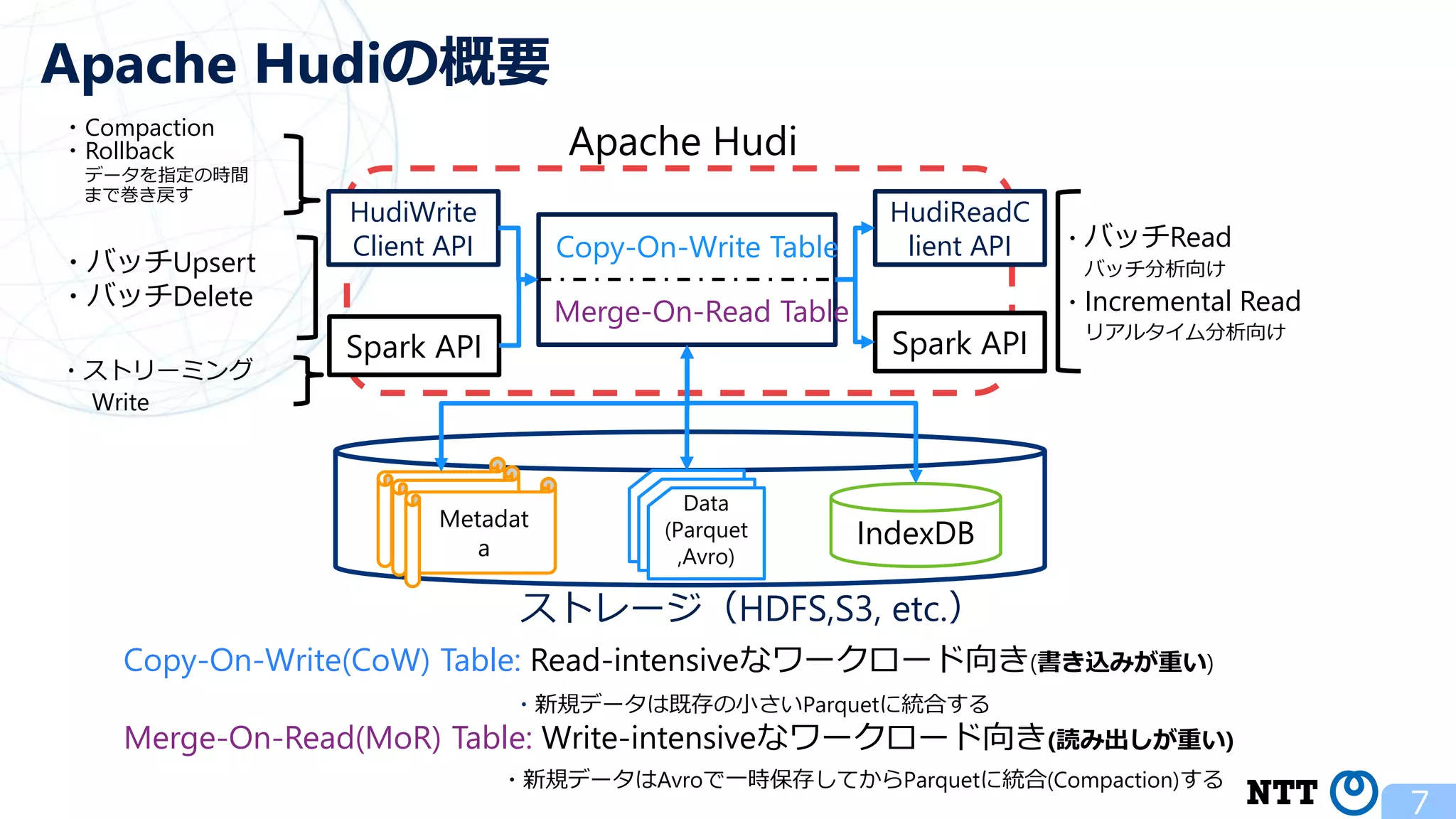
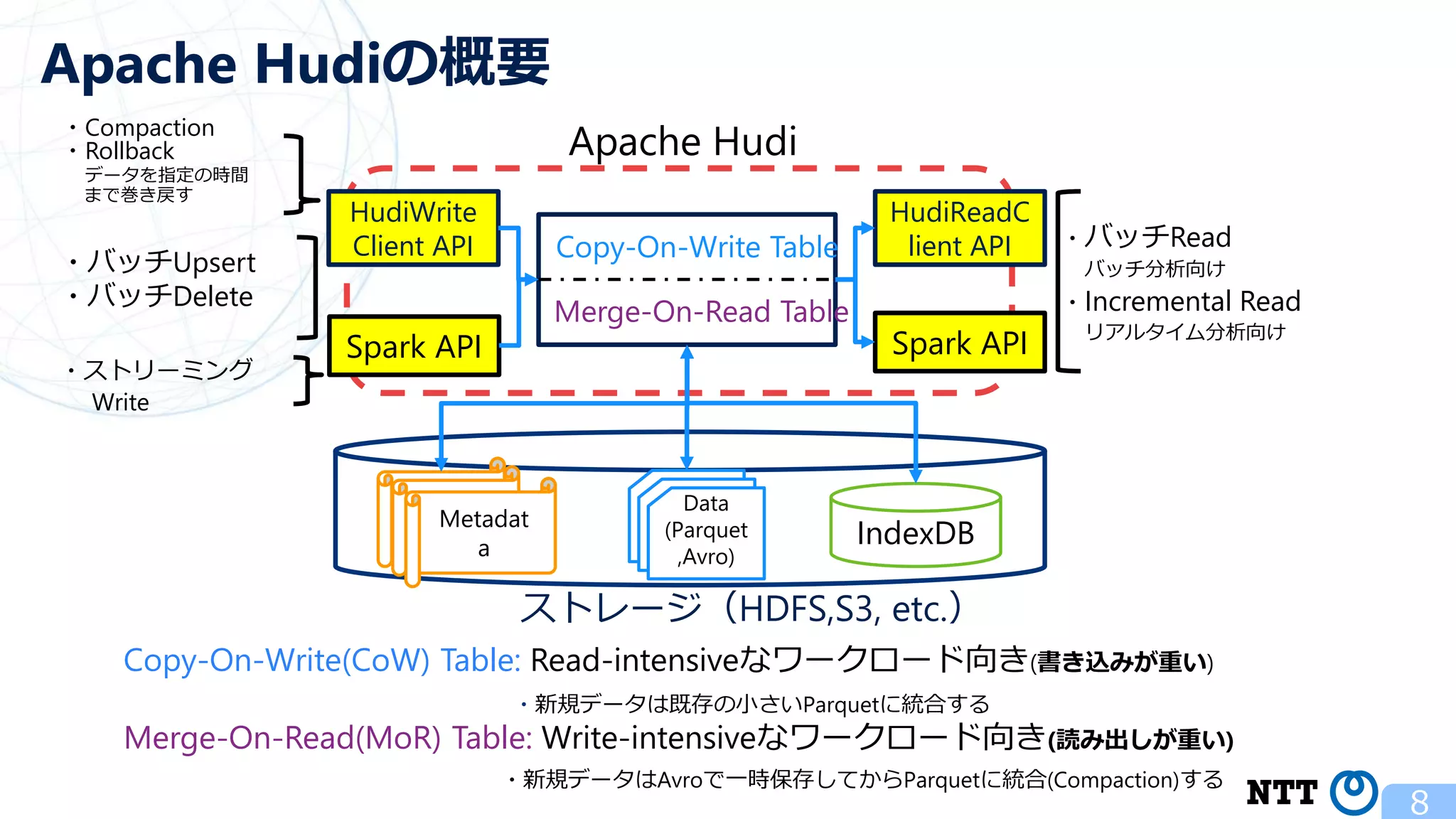
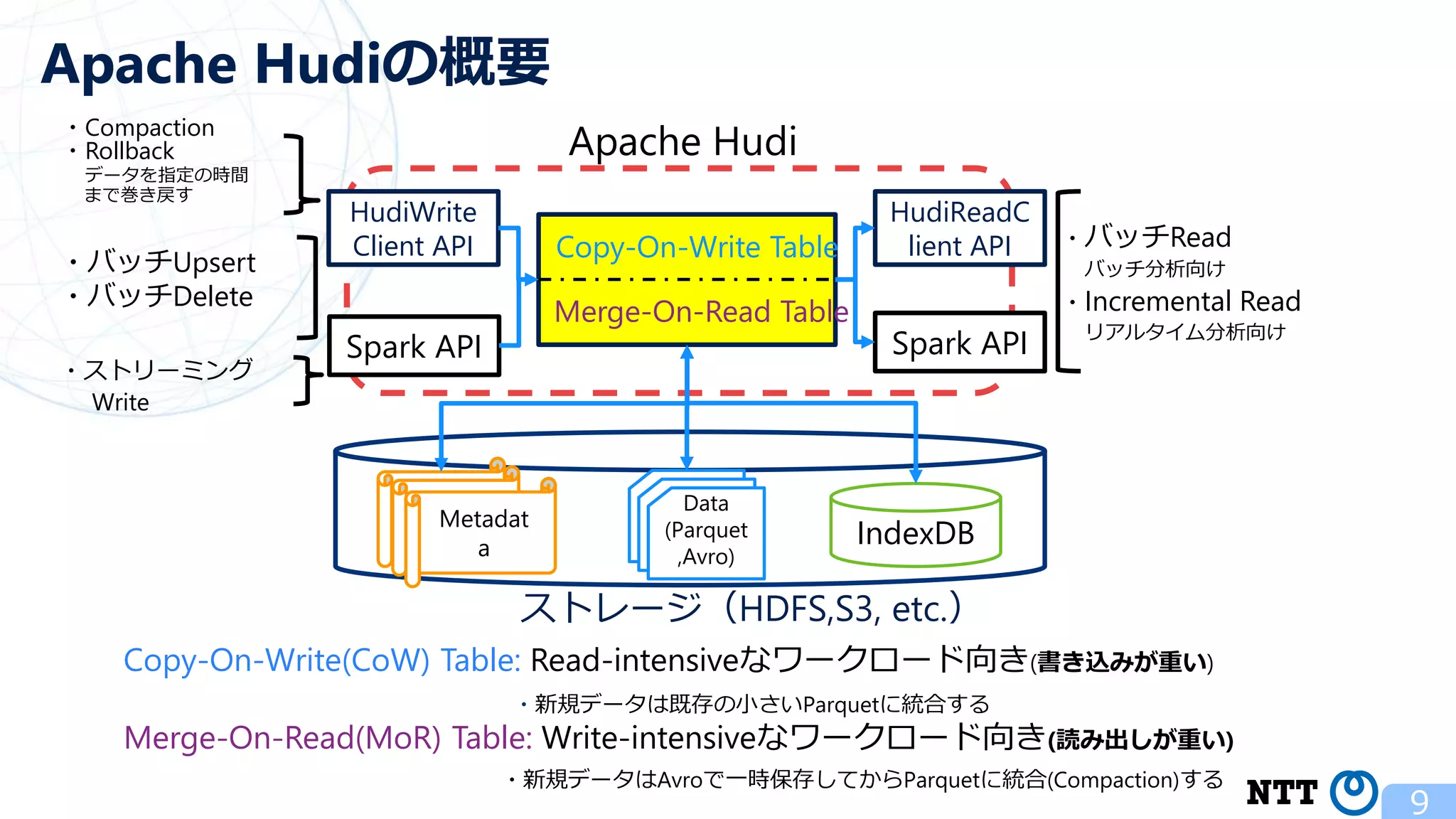
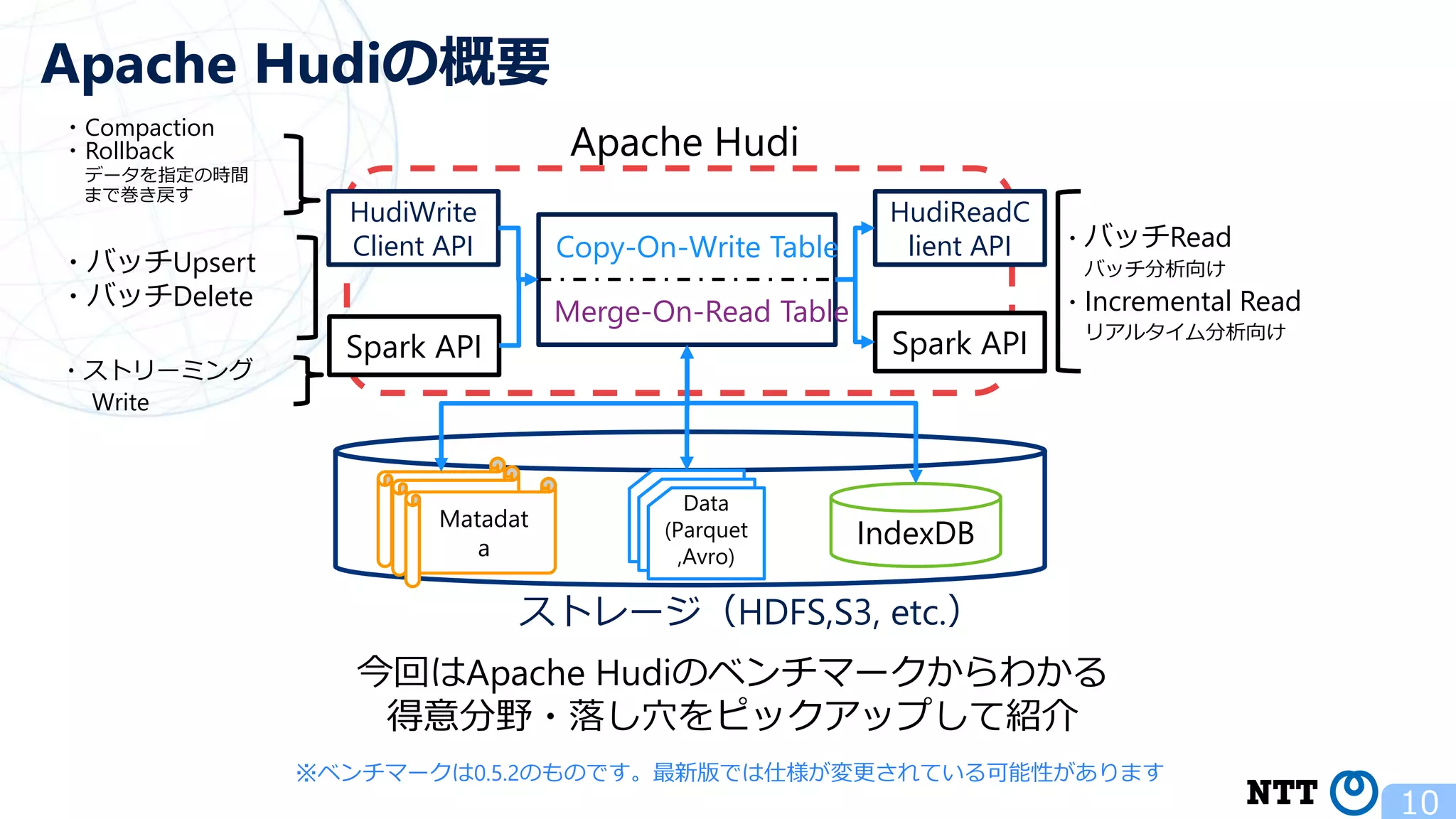
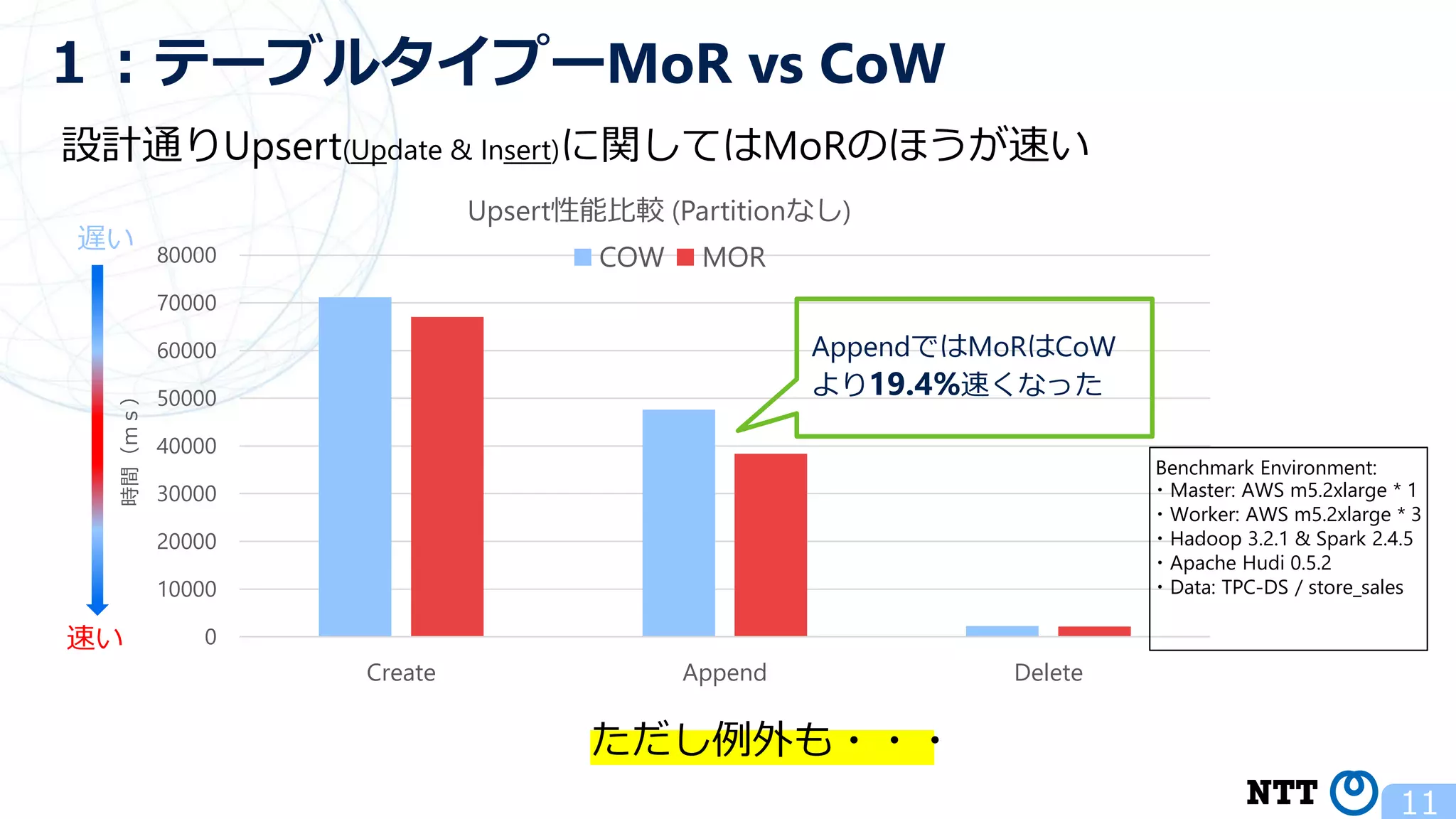
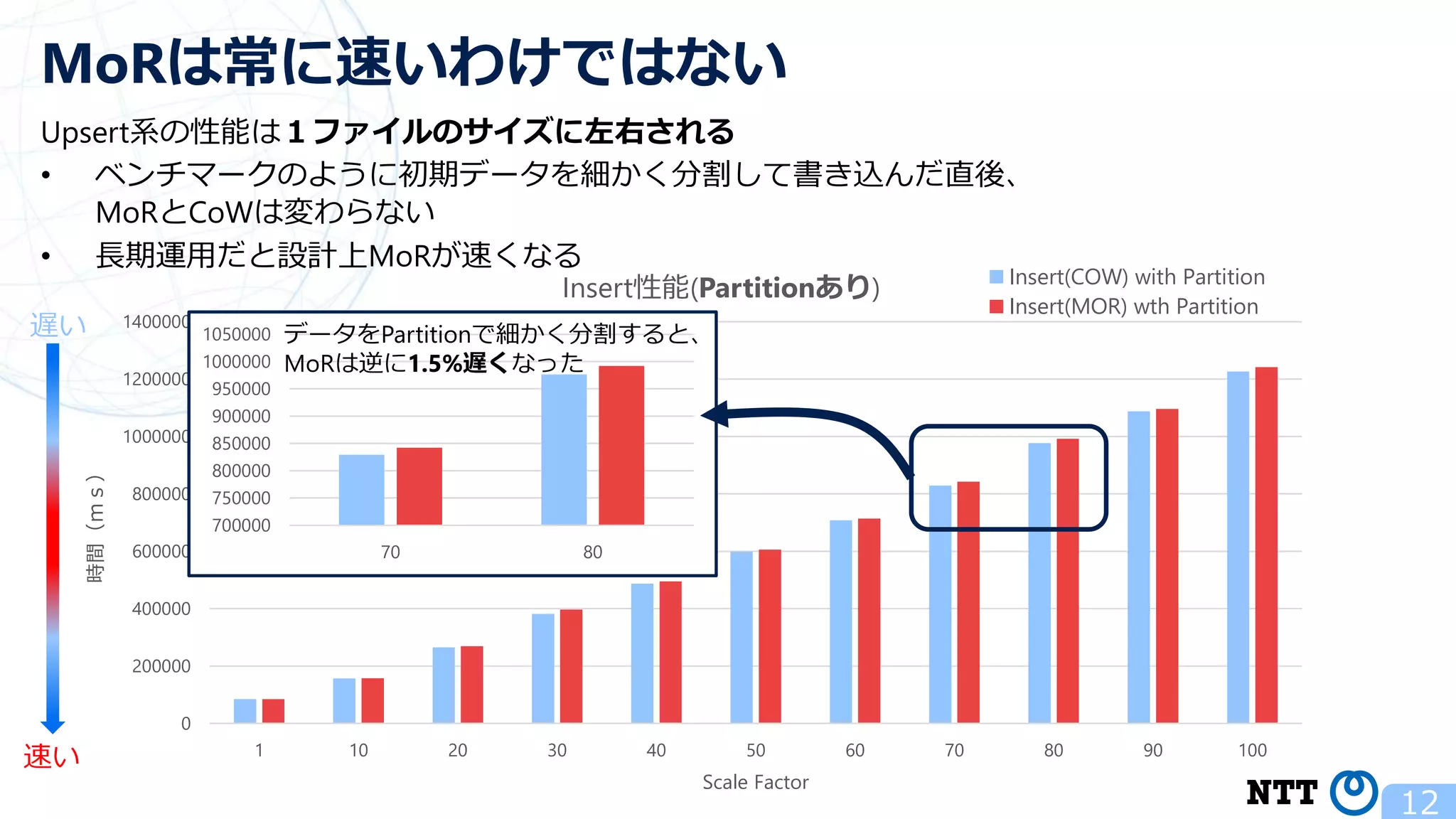
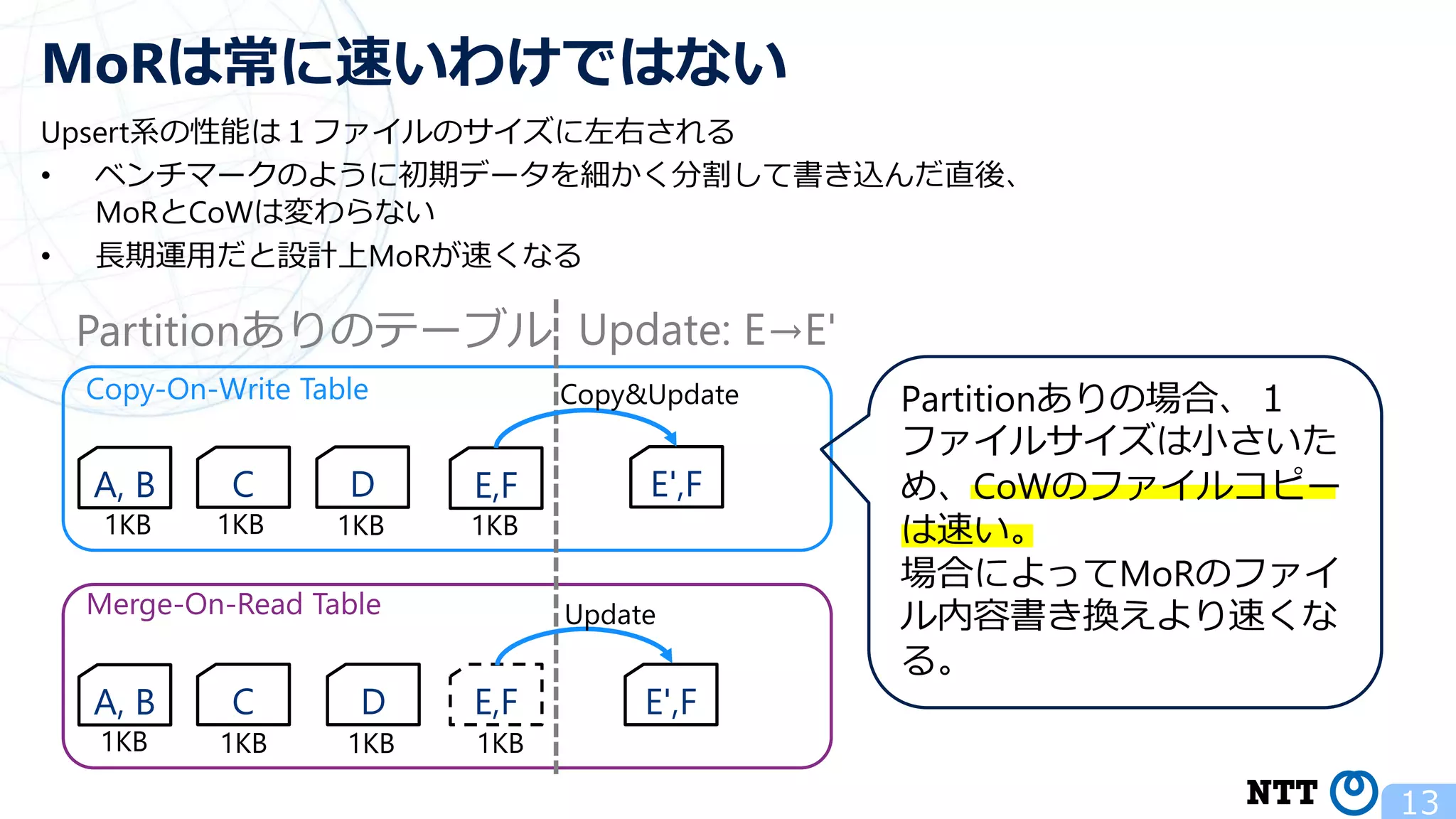
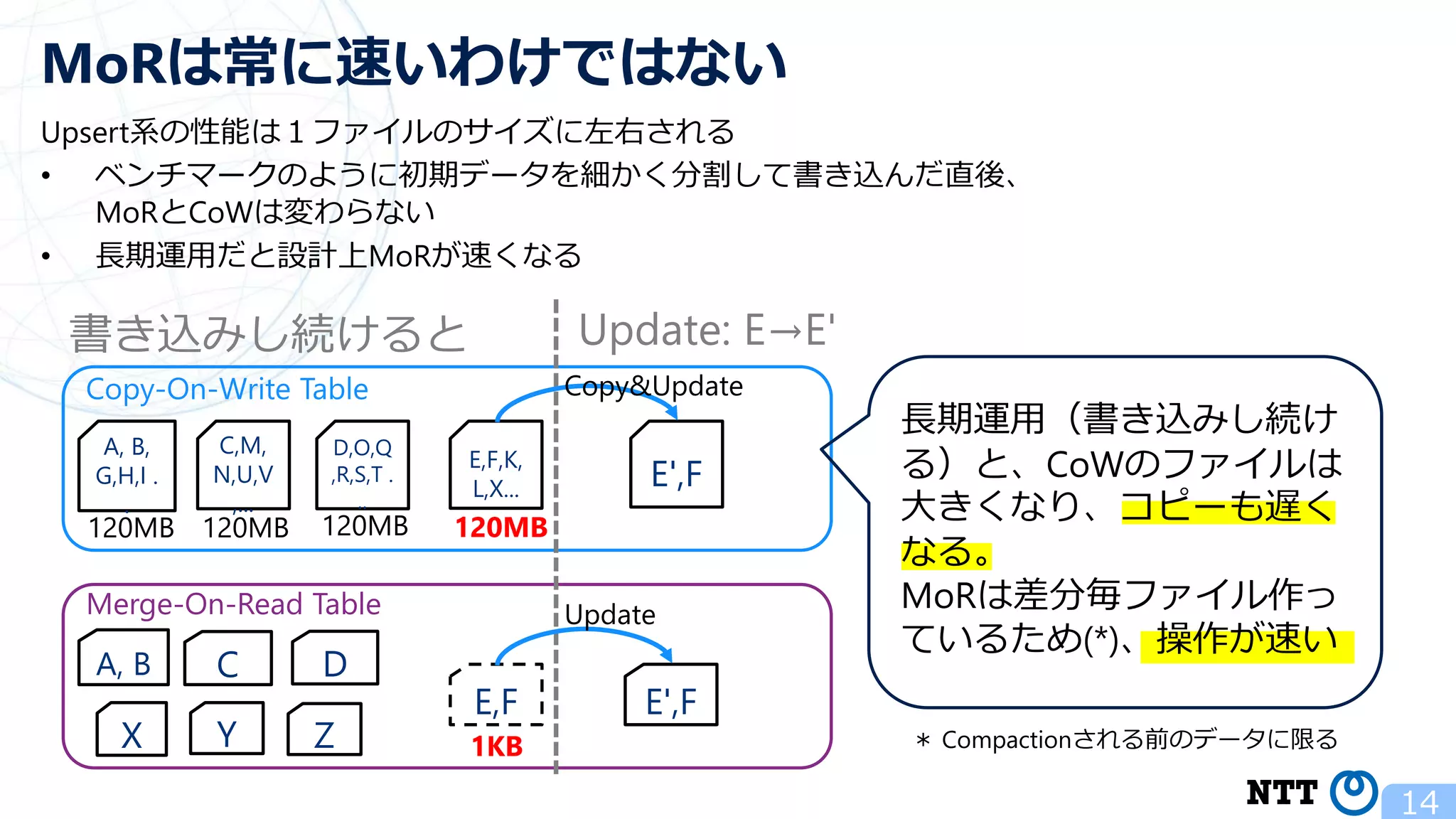
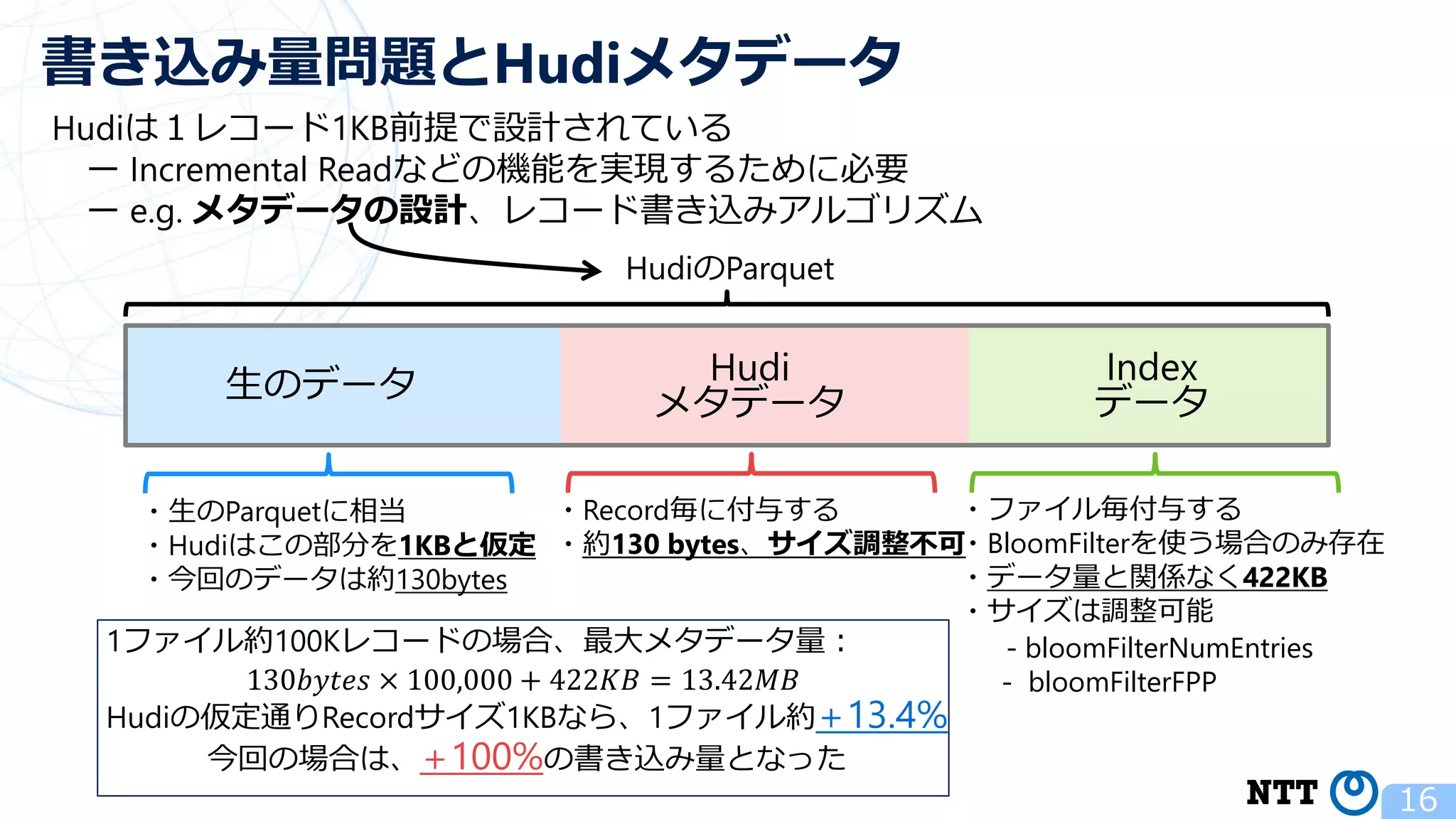
ポスト・ラムダアーキテクチャの切り札? Apache Hudi (NTTデータ テクノロジーカンファレンス 2020 発表資料) 2020年10月16日(金) NTT ソフトウェアイノベーションセンタ Zhai Hongjie 講演動画は、YouTubeチャンネル「NTT DATA Tech」にて公開中! https://www.youtube.com/watch?v=qMmJUjpff-8