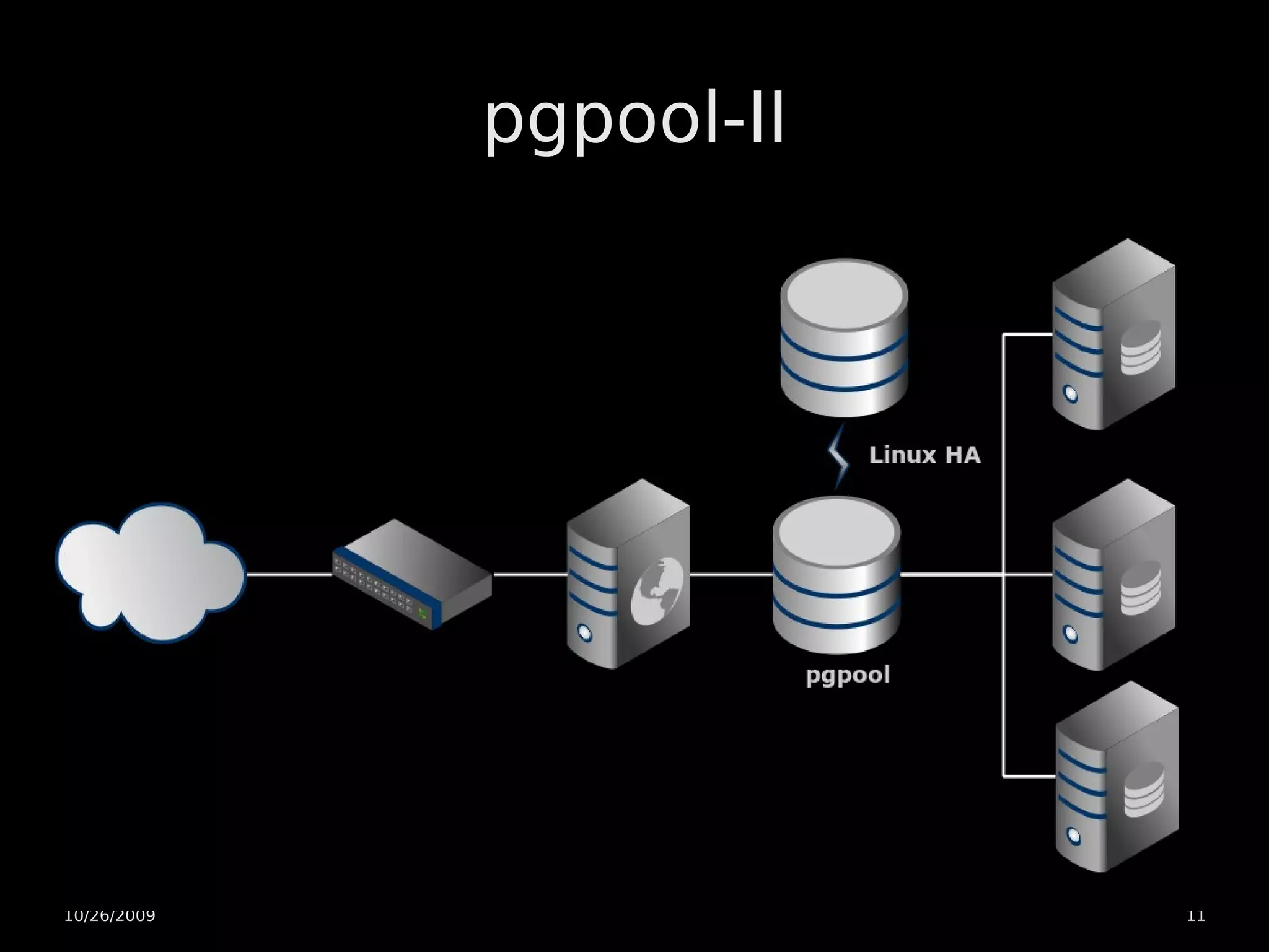
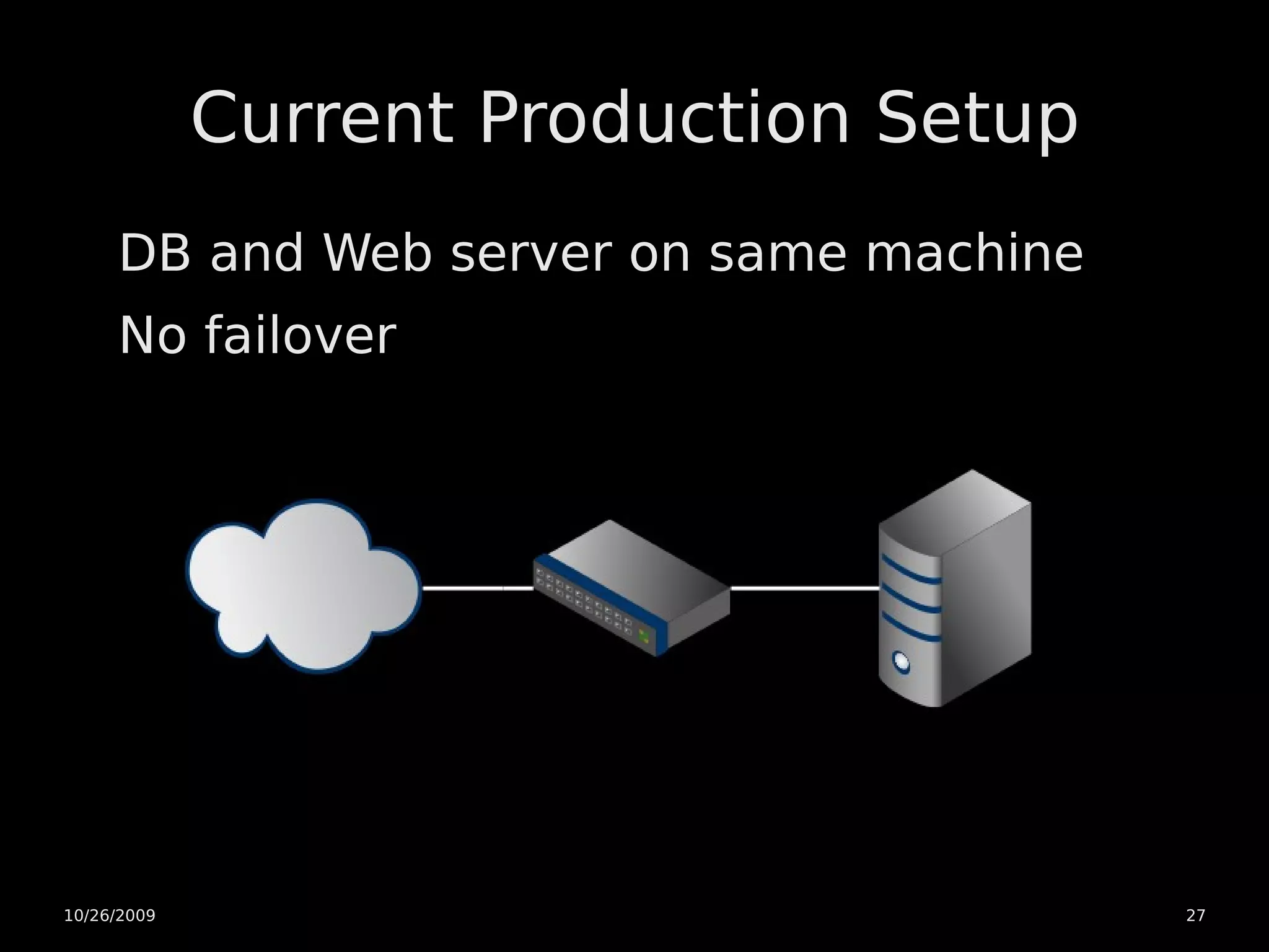
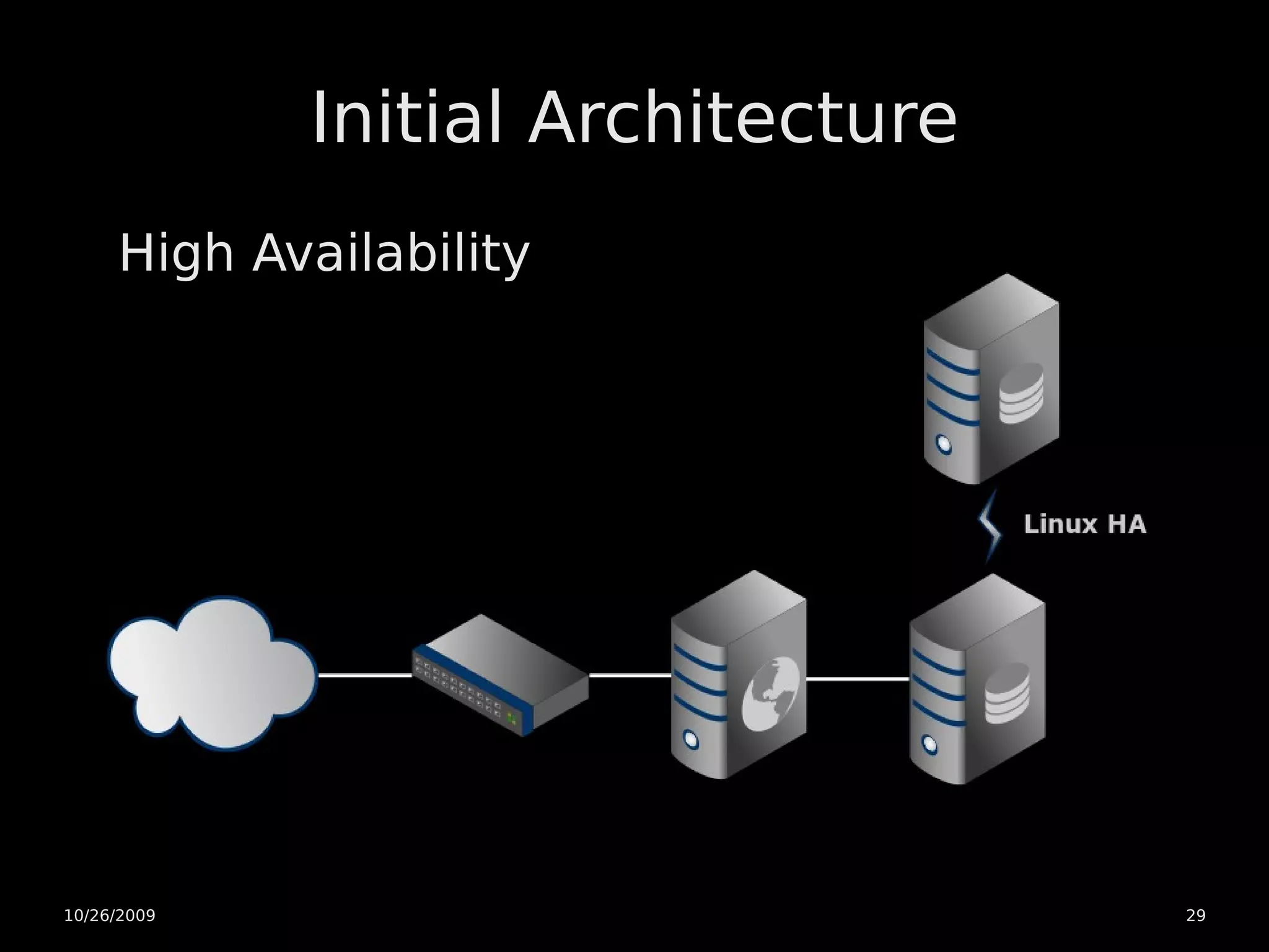
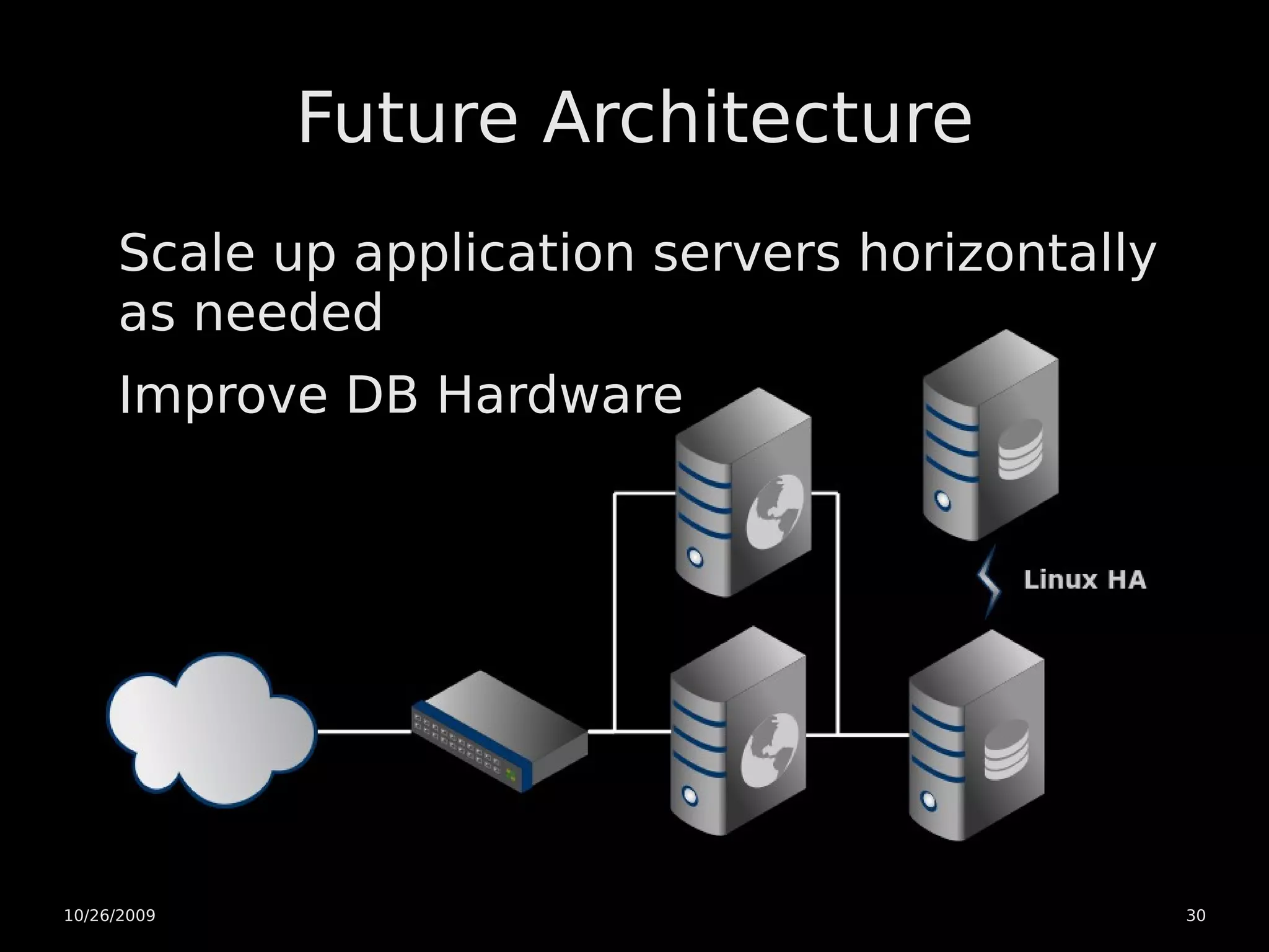
The document discusses PostgreSQL high availability and scaling options. It covers horizontal scaling using load balancing and data partitioning across multiple servers. It also covers high availability techniques like master-slave replication, warm standby servers with point-in-time recovery, and using a heartbeat to prevent multiple servers from becoming a master. The document recommends an initial architecture with two servers using warm standby and point-in-time recovery with a heartbeat for high availability. It suggests scaling the application servers horizontally later on if more capacity is needed.