Downloaded 21 times











![8 . 1 DEALING LOCAL VARIABLES Compiler don't care how many variables are used in code, register allocation is done after IR rotations. for( ; j <= roi.width - 4; j += 4 ) { uchar t0 = tab[src[j]]; uchar t1 = tab[src[j+ 1]]; dst[j] = t0; dst[j+1] = t1; t0 = tab[src[j+2]]; t1 = tab[src[j+3]]; dst[j+2] = t0; dst[j+3] = t1; }](https://image.slidesharecdn.com/2-pragmatic-optimization-in-modern-programming-demystifying-the-compiler-151027072653-lva1-app6892/75/Pragmatic-Optimization-in-Modern-Programming-Demystifying-the-Compiler-15-2048.jpg)
![8 . 2 DEALING LOCAL VARIABLES .lr.ph4: ; preds = %0, %.lr.ph4 %indvars.iv5 = phi i64 [ %indvars.iv.next6, %.lr.ph4 ], [0, %0 ] %6 = getelementptr inbounds i8* %src, i64 %indvars.iv5 %7 = load i8* %6, align 1, !tbaa !1 %8 = zext i8 %7 to i64 %9 = getelementptr inbounds i8* %tab, i64 %8 %10 = load i8* %9, align 1, !tbaa !1 %11 = or i64 %indvars.iv5, 1 %12 = getelementptr inbounds i8* %src, i64 %11 %13 = load i8* %12, align 1, !tbaa !1 %14 = zext i8 %13 to i64 %15 = getelementptr inbounds i8* %tab, i64 %14 %16 = load i8* %15, align 1, !tbaa !1 %17 = getelementptr inbounds i8* %dst, i64 %indvars.iv5 store i8 %10, i8* %17, align 1, !tbaa !1 %18 = getelementptr inbounds i8* %dst, i64 %11 store i8 %16, i8* %18, align 1, !tbaa !1 %19 = or i64 %indvars.iv5, 2 // ... %28 = zext i8 %27 to i64 %29 = getelementptr inbounds i8* %tab, i64 %28 %30 = load i8* %29, align 1, !tbaa !1 %31 = getelementptr inbounds i8* %dst, i64 %19 store i8 %24, i8* %31, align 1, !tbaa !1 %32 = getelementptr inbounds i8* %dst, i64 %25 store i8 %30, i8* %32, align 1, !tbaa !1 %indvars.iv.next6 = add nuw nsw i64 %indvars.iv5,4 %33 = trunc i64 %indvars.iv.next6 to i32 %34 = icmp sgt i32 %33, %1 br i1 %34, label %..preheader_crit_edge, label %.lr.ph4](https://image.slidesharecdn.com/2-pragmatic-optimization-in-modern-programming-demystifying-the-compiler-151027072653-lva1-app6892/75/Pragmatic-Optimization-in-Modern-Programming-Demystifying-the-Compiler-16-2048.jpg)








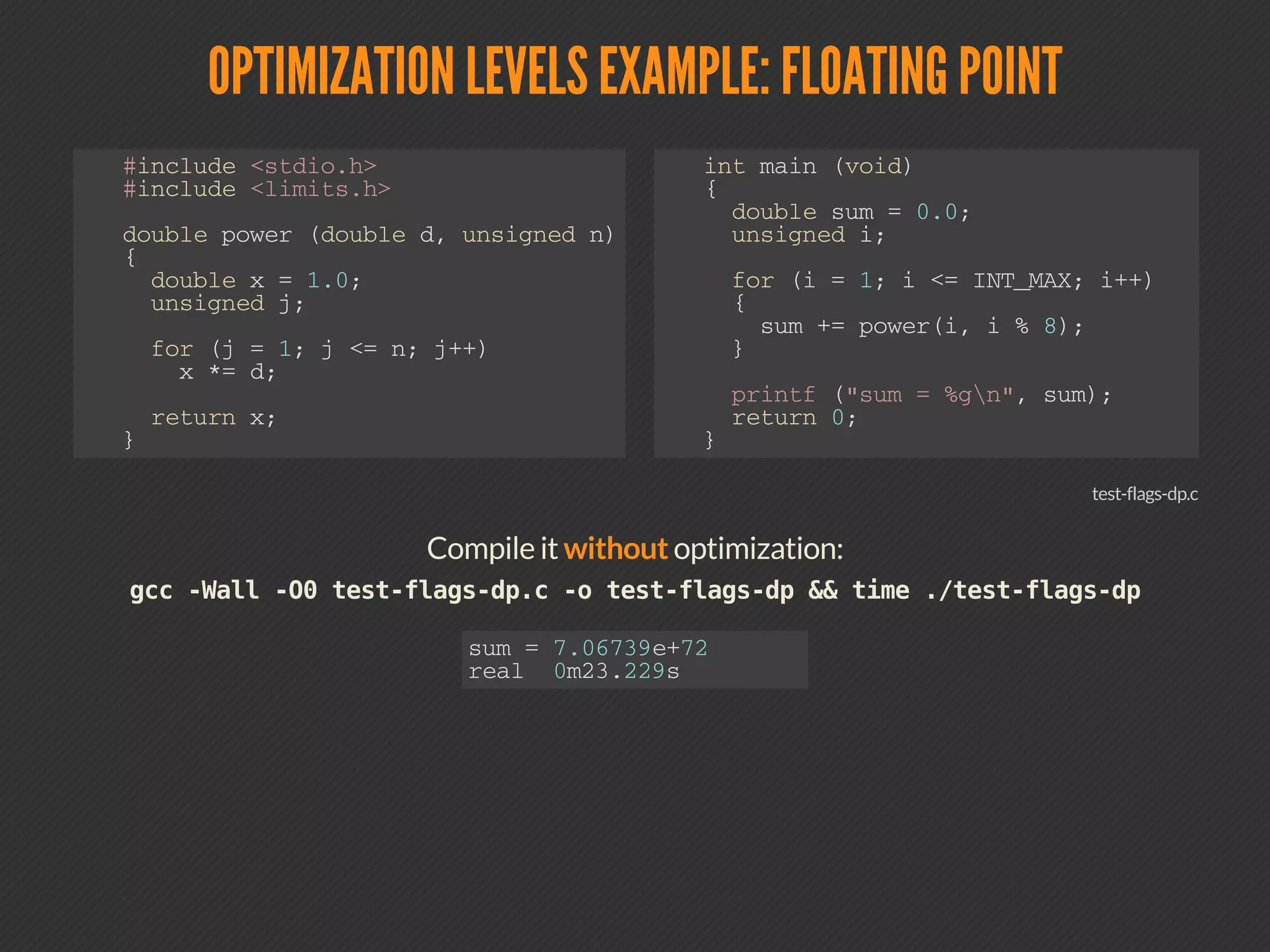




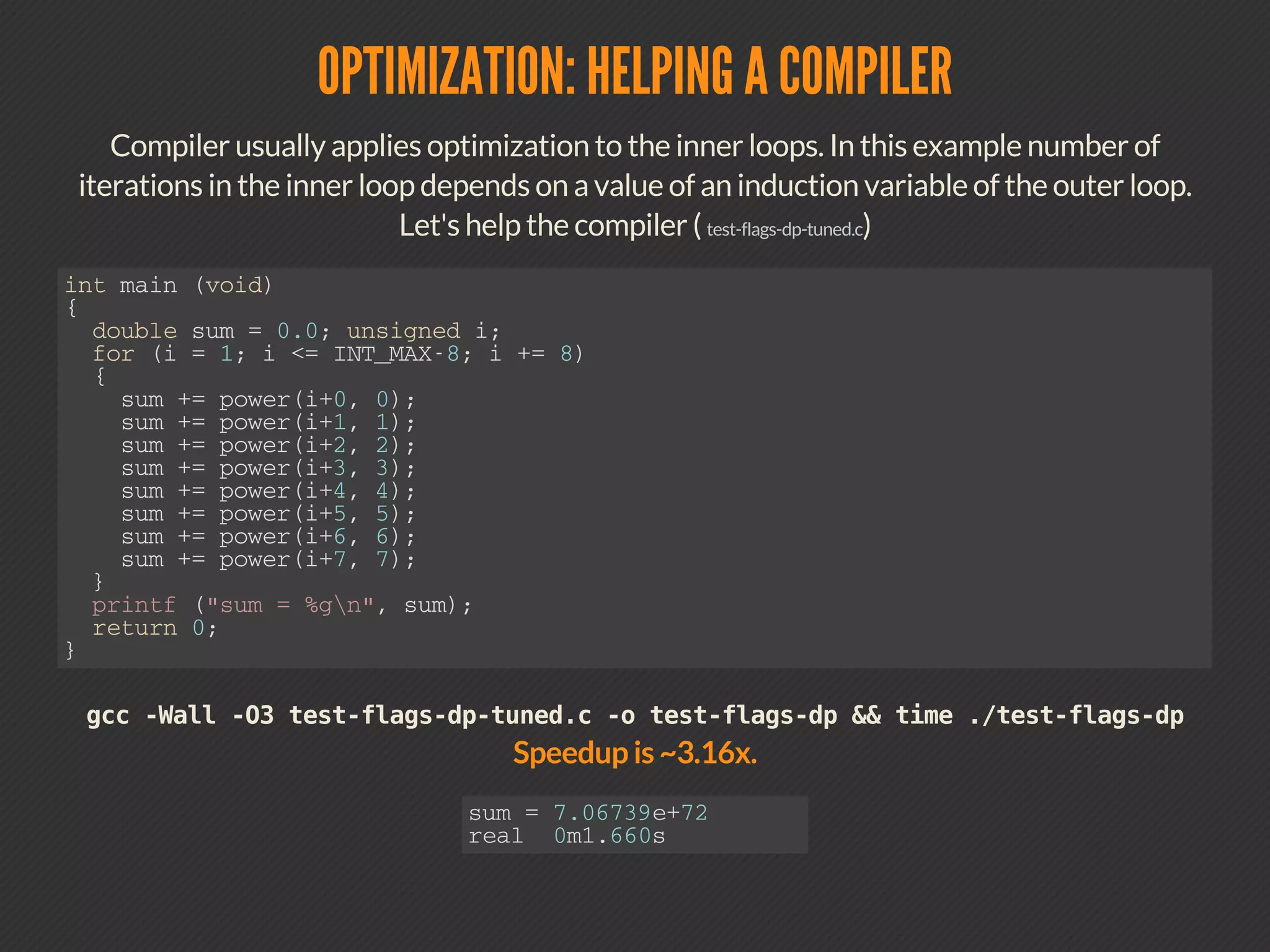
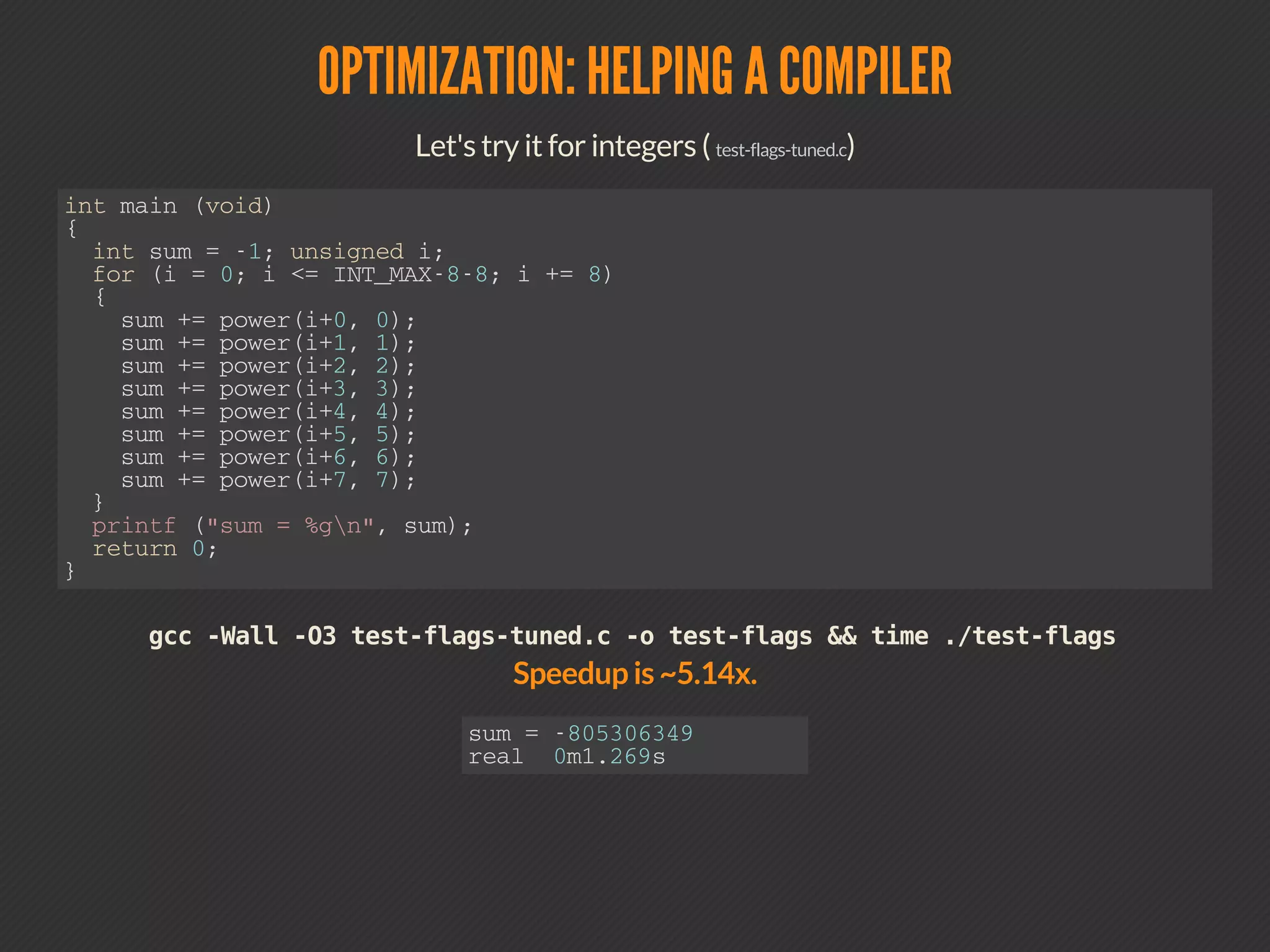




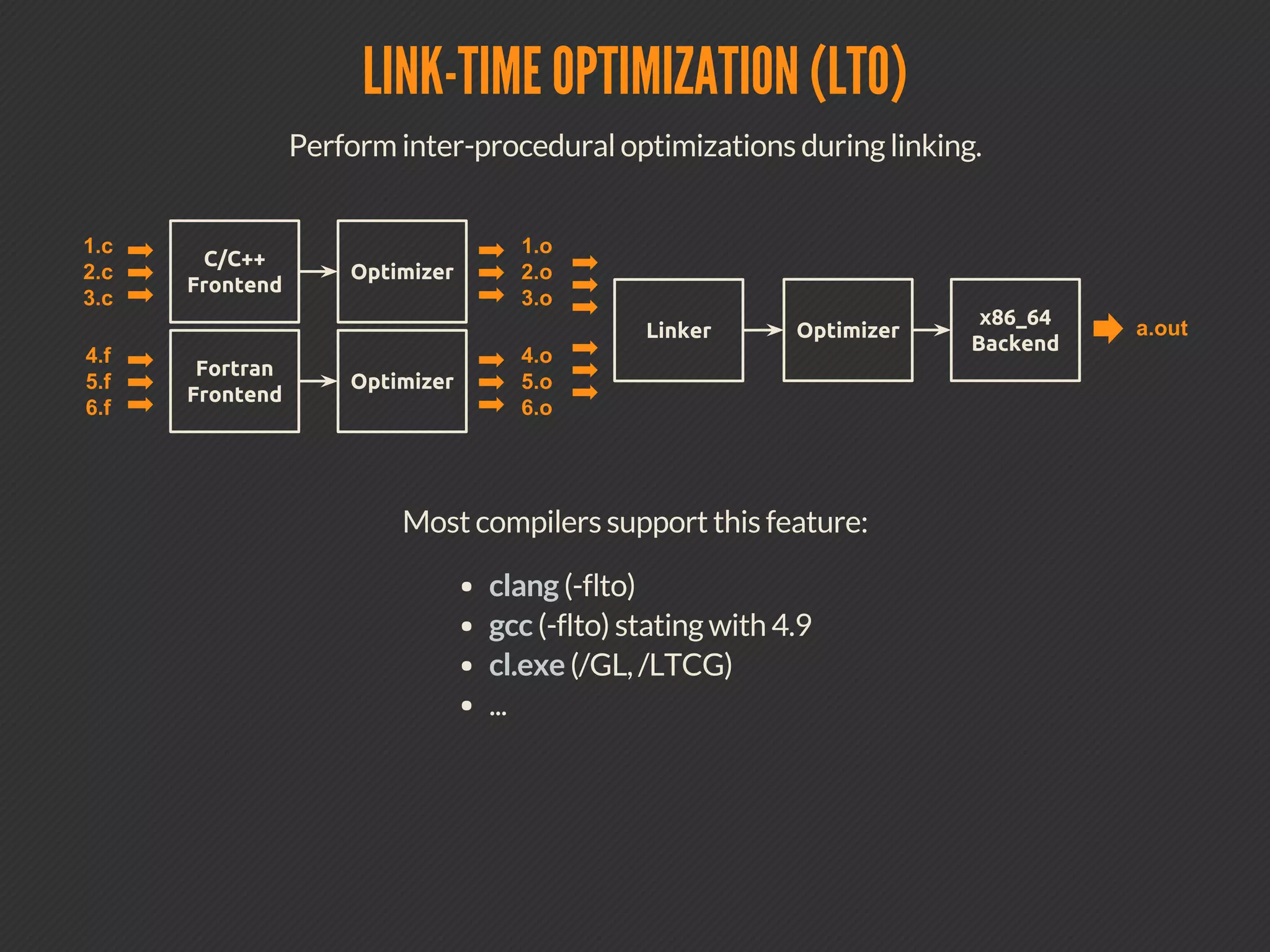
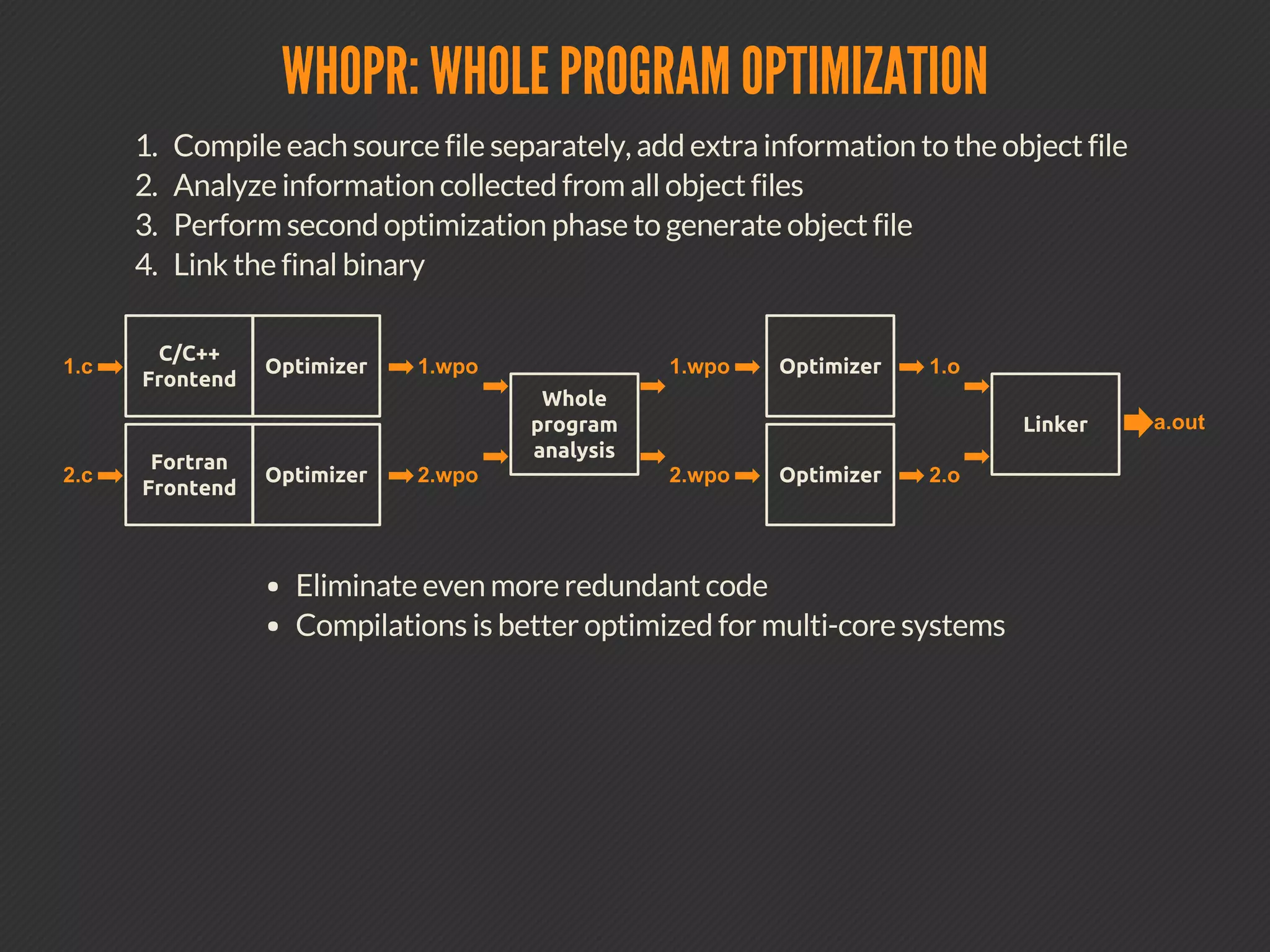
















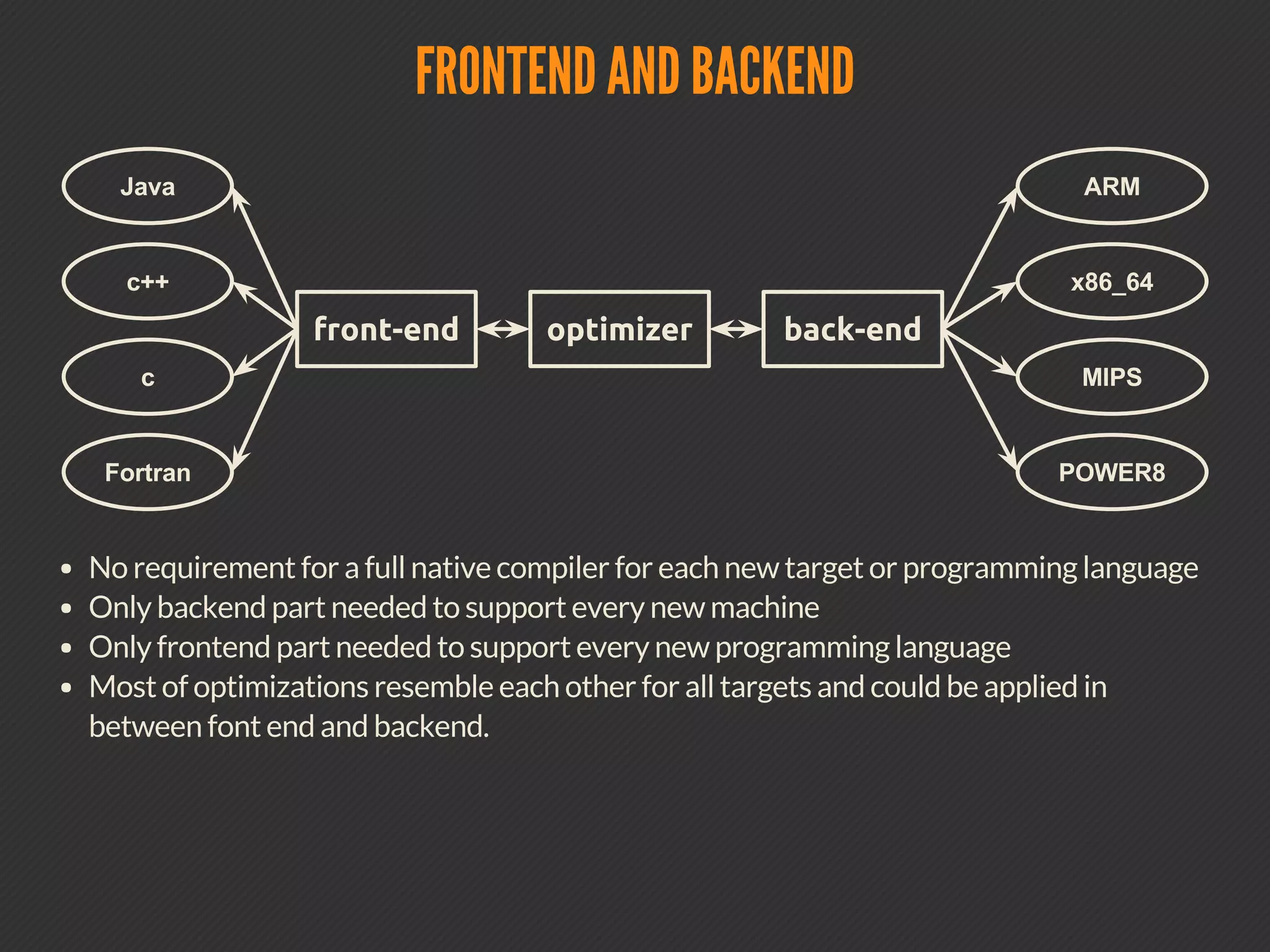
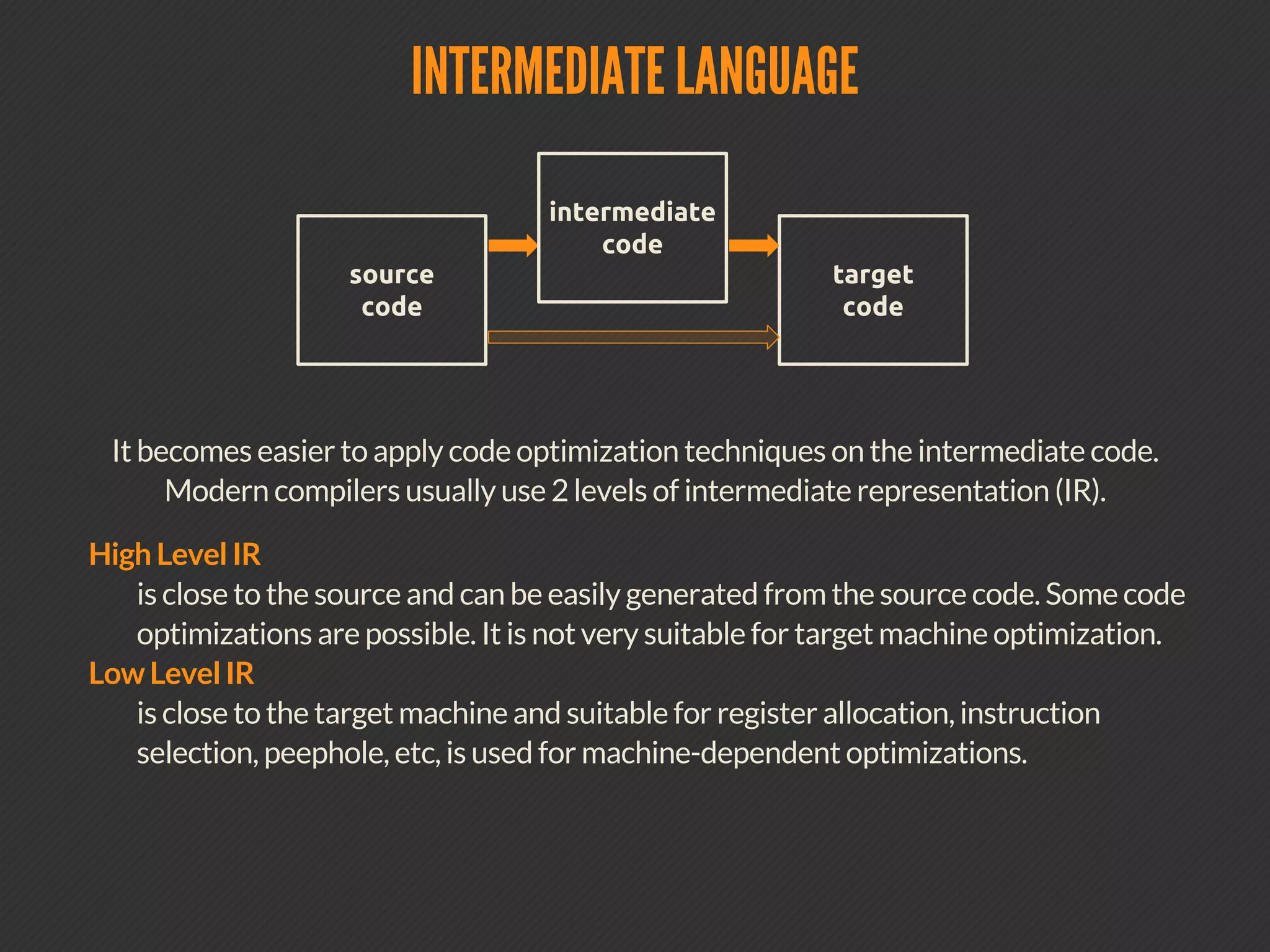
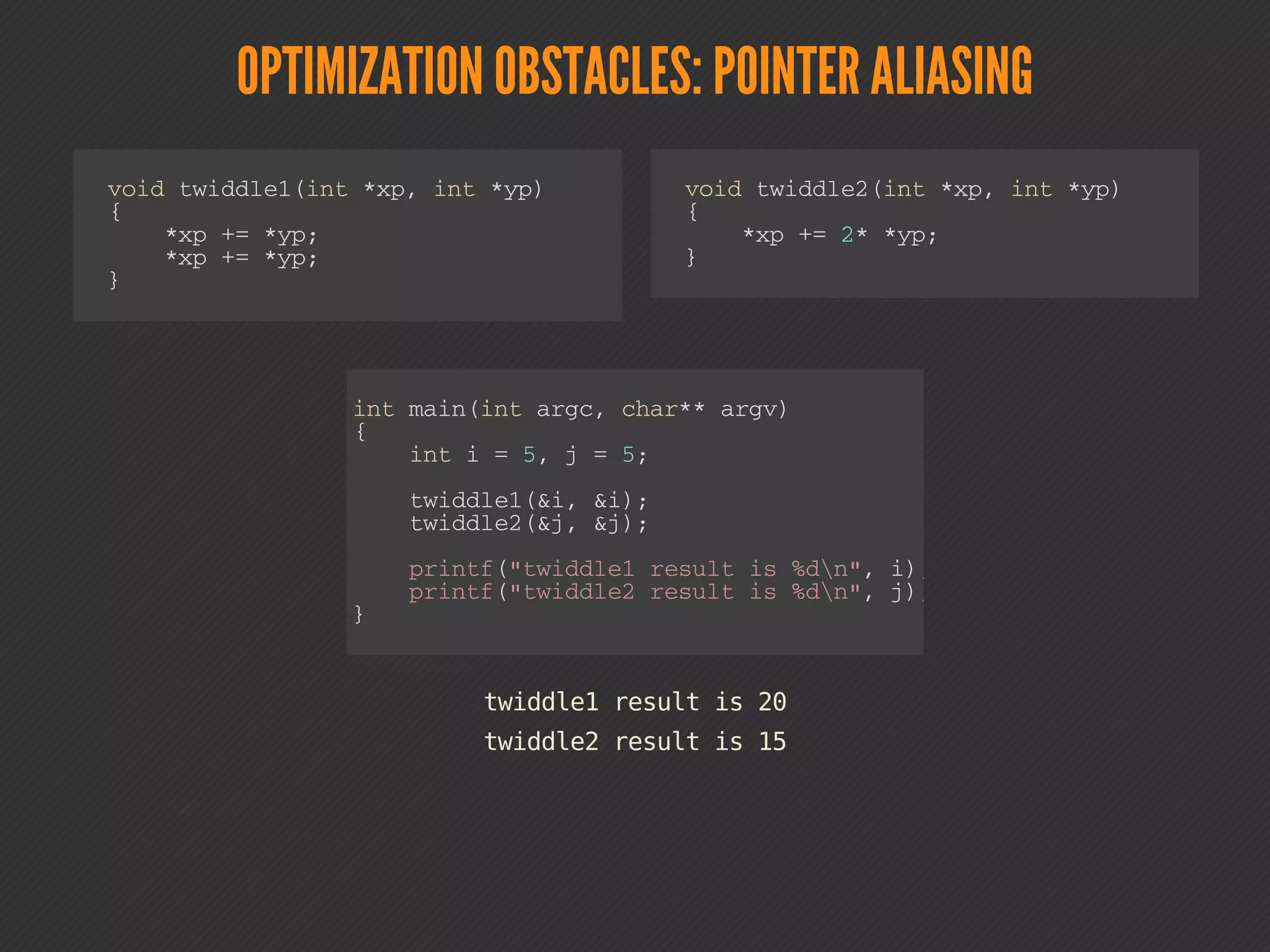
This document discusses compiler optimizations. It begins with an outline of topics including compilation trajectory, intermediate languages, optimization levels, and optimization techniques. It then provides more details on each phase of compilation, how compilers use intermediate representations to perform optimizations, and specific optimizations like common subexpression elimination, constant propagation, and instruction scheduling.