Download as PDF, PPTX





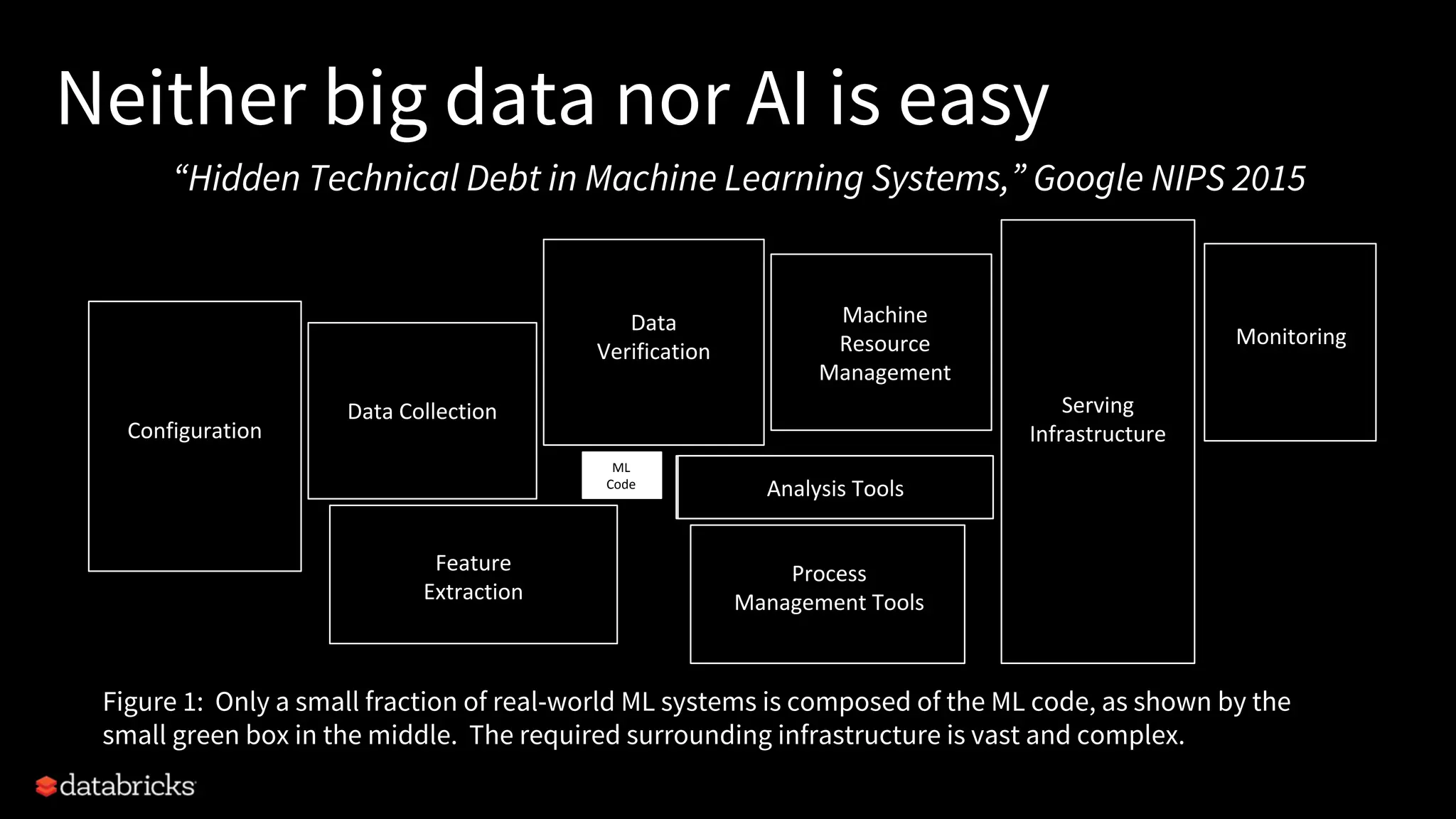


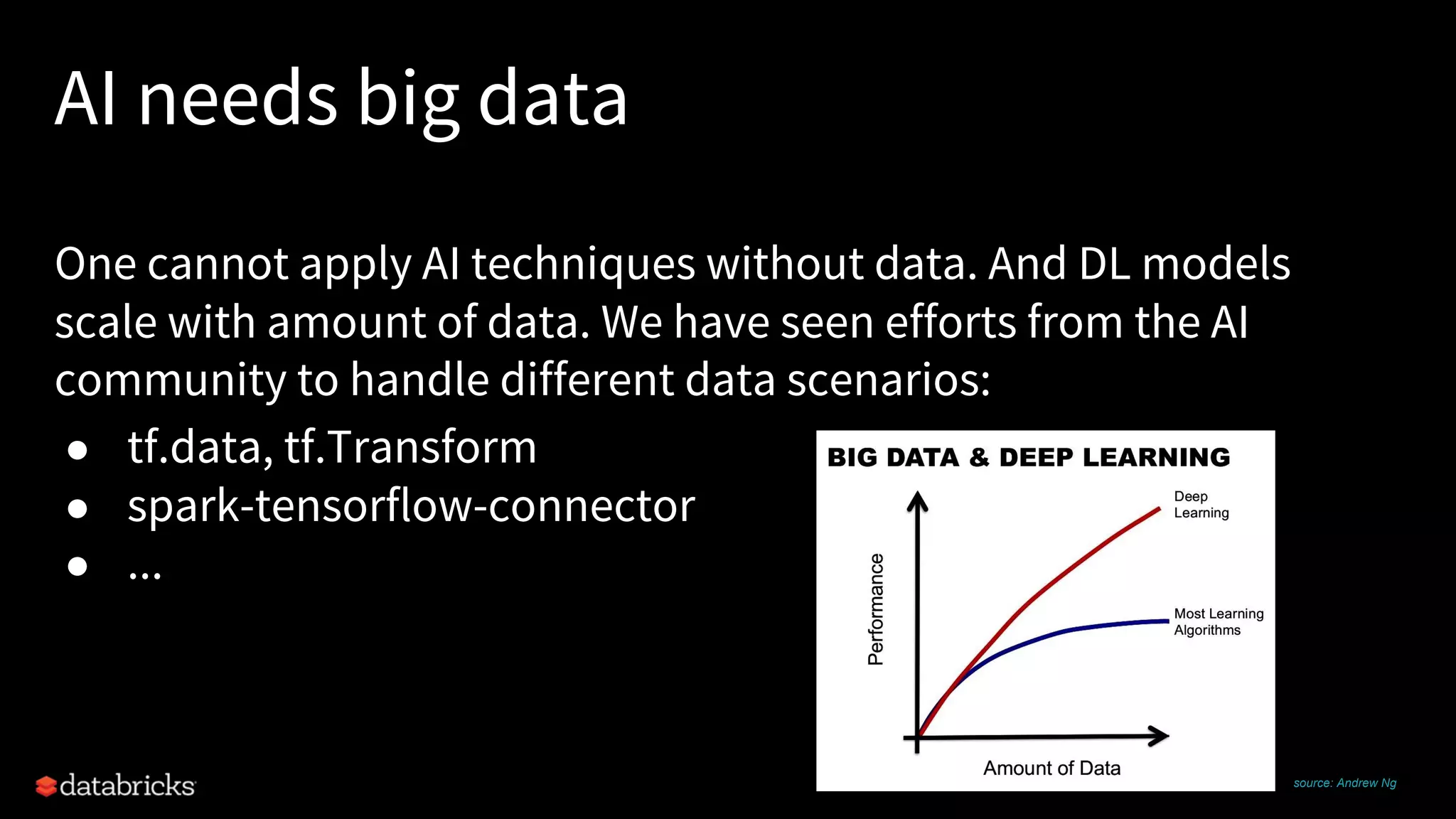


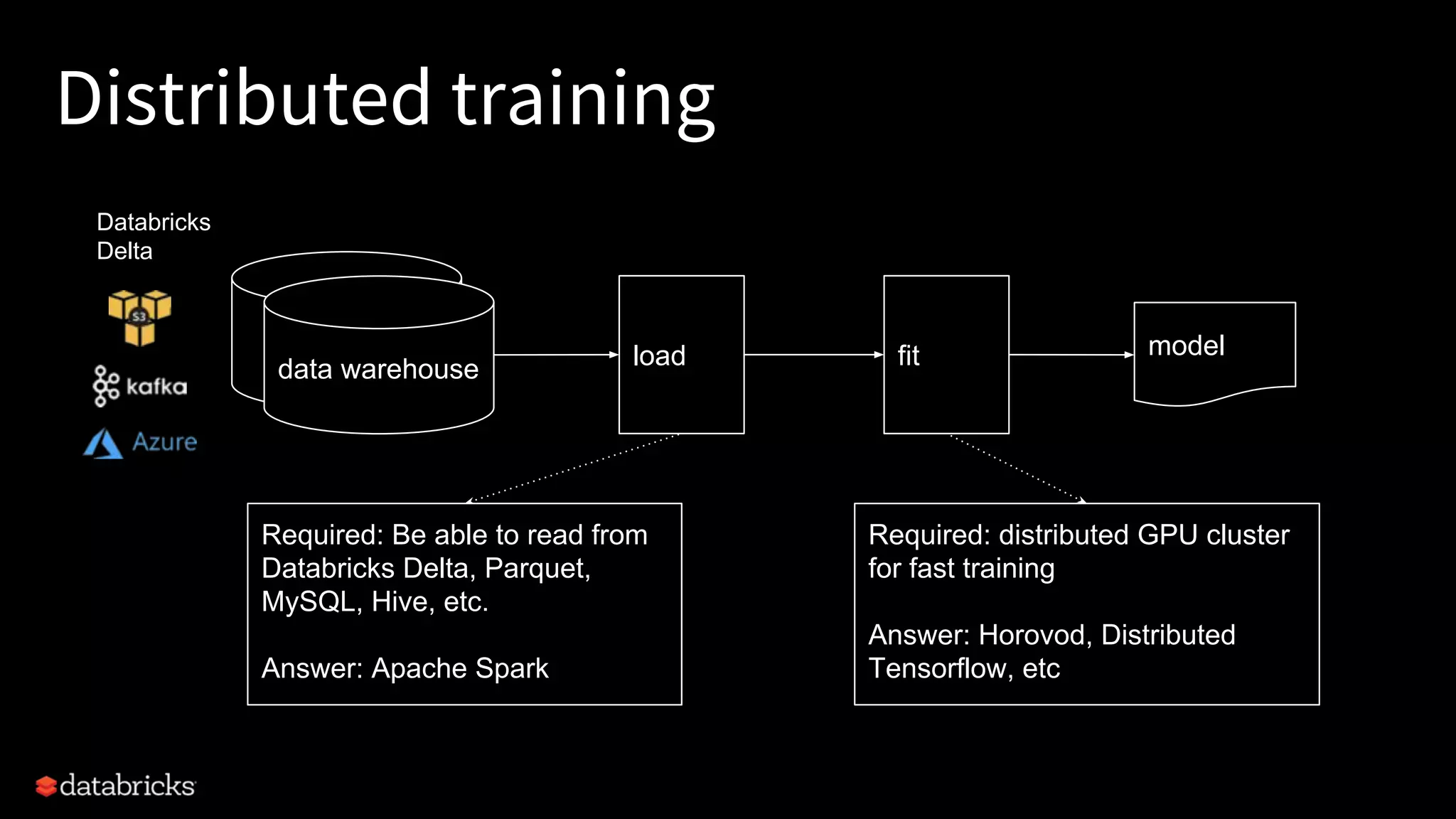
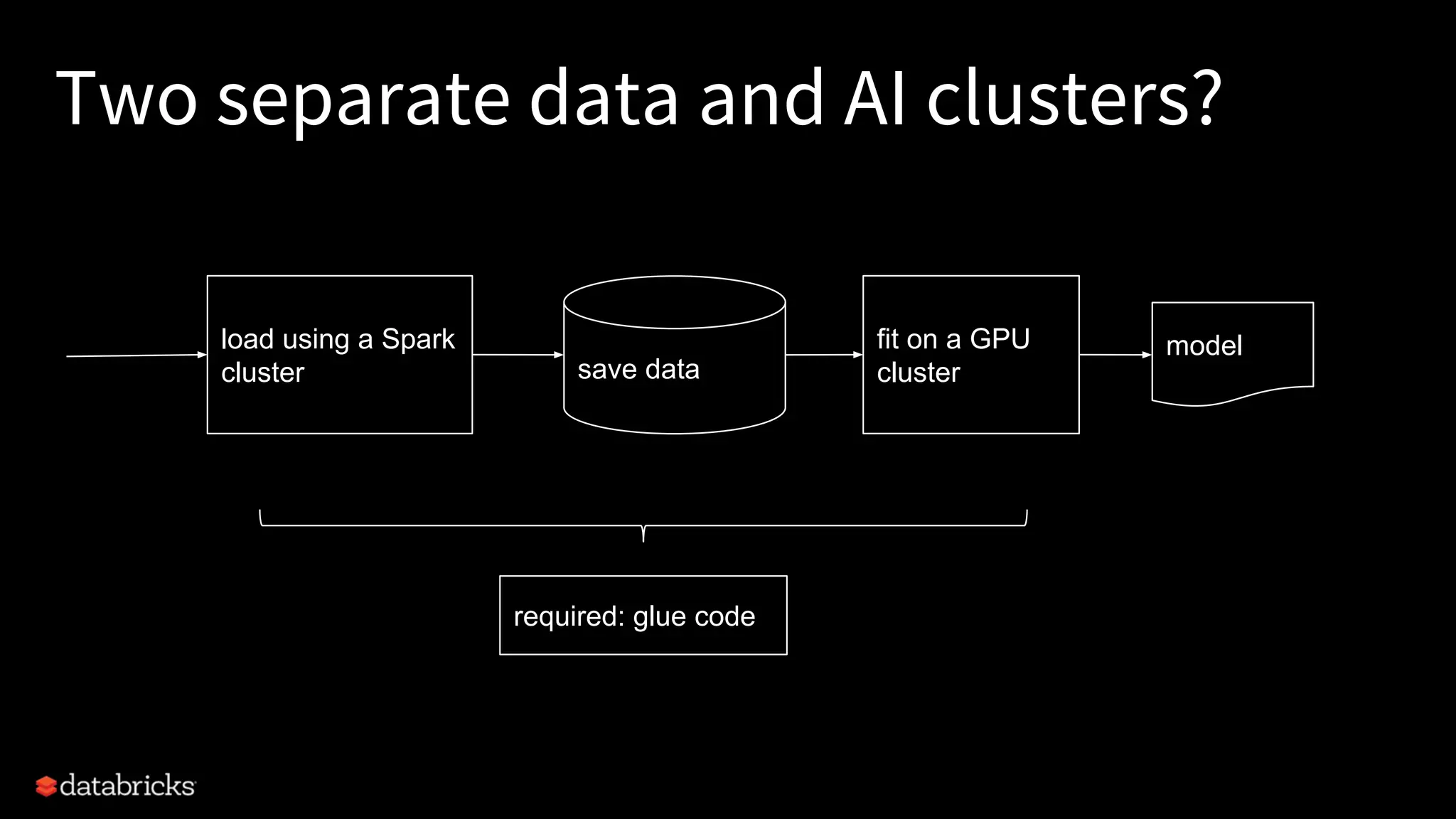
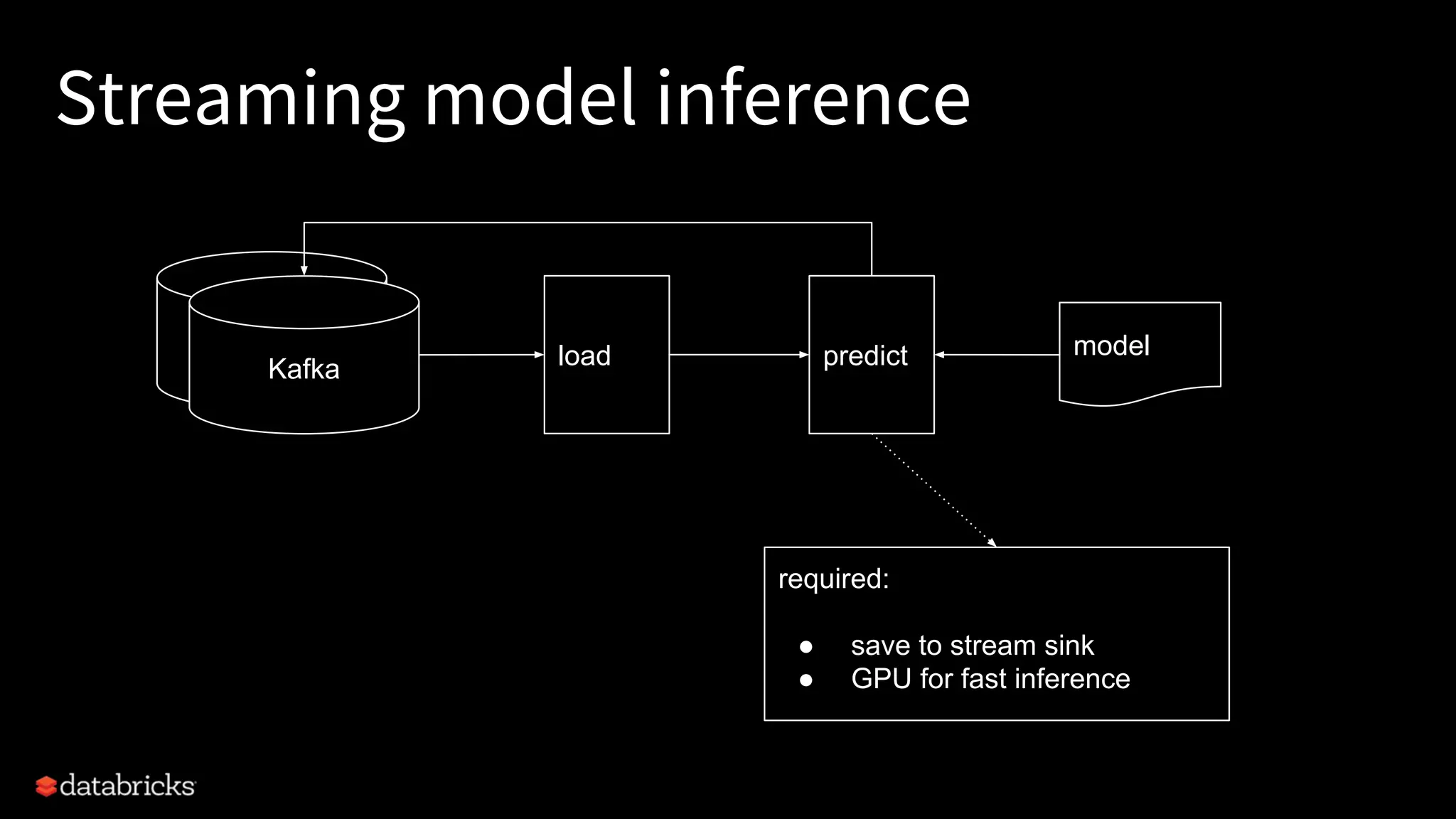
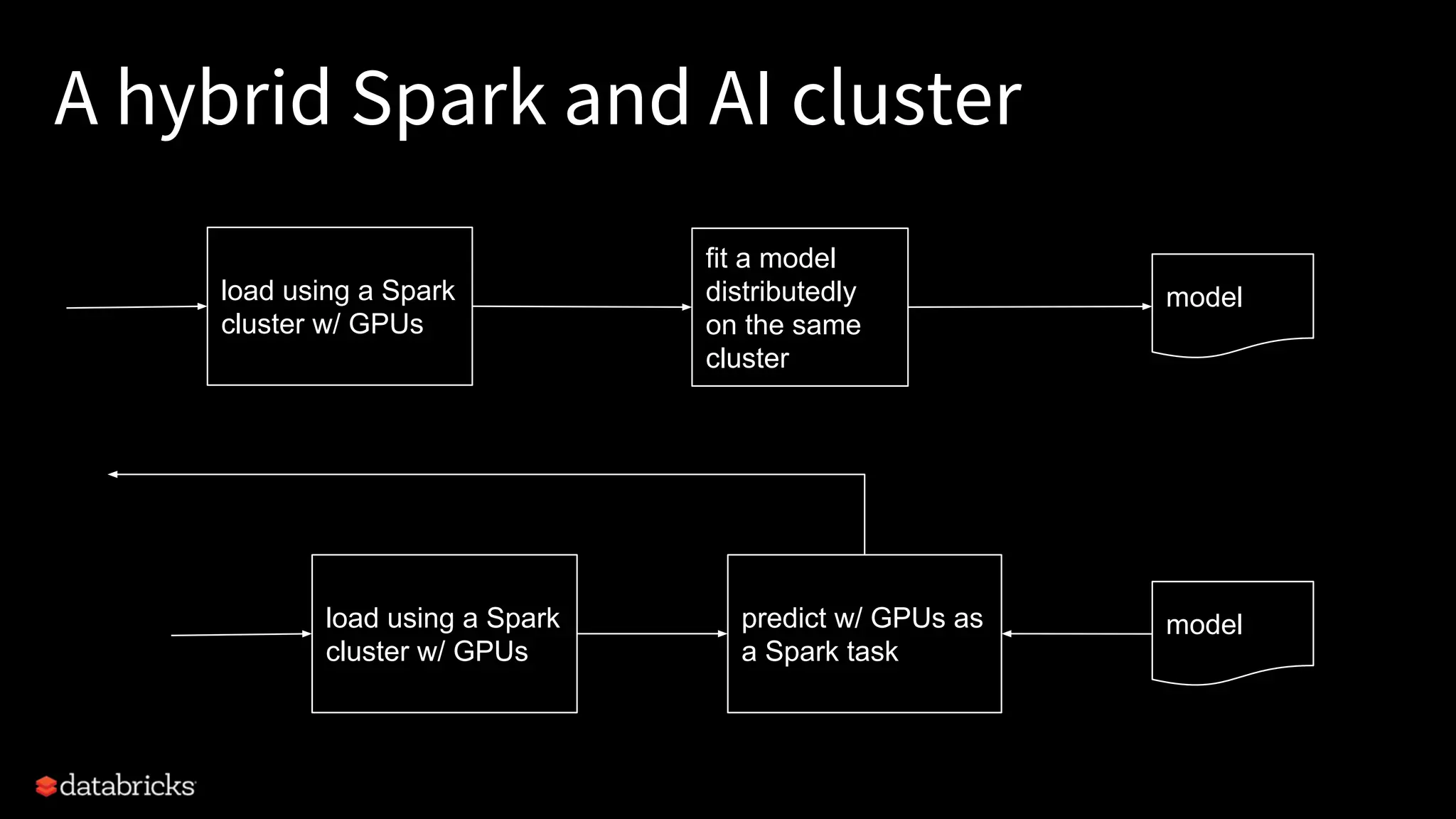




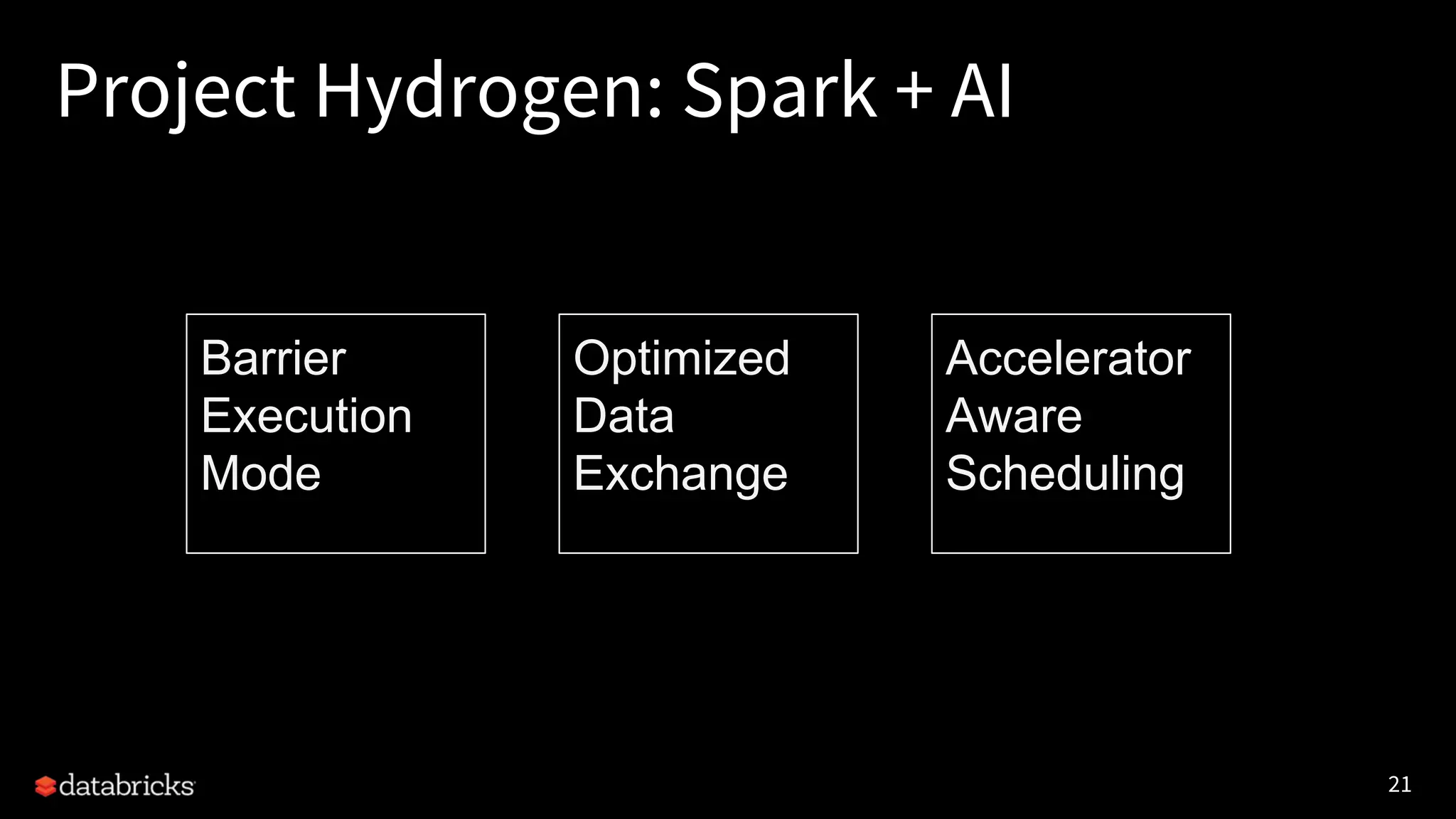




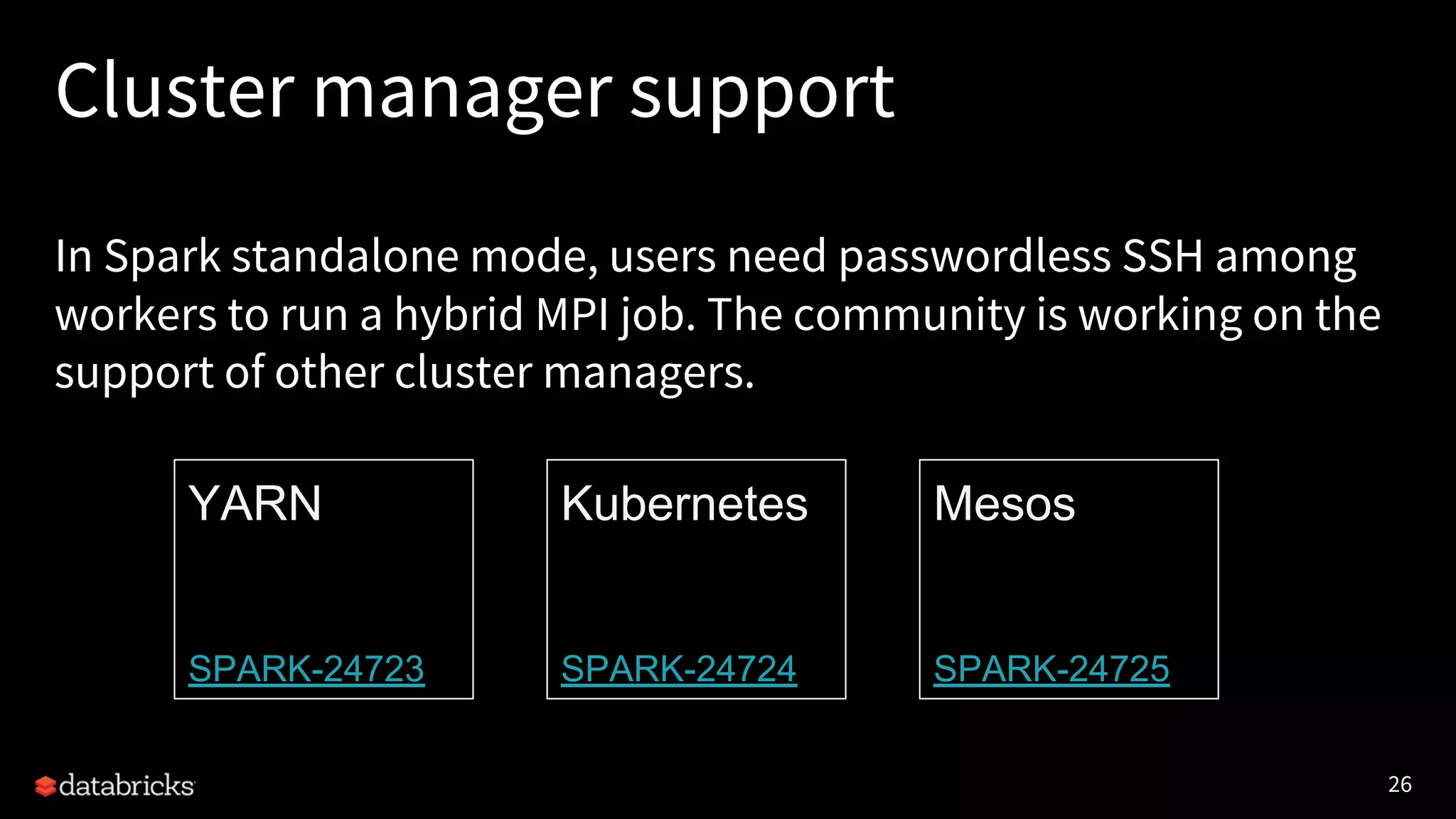



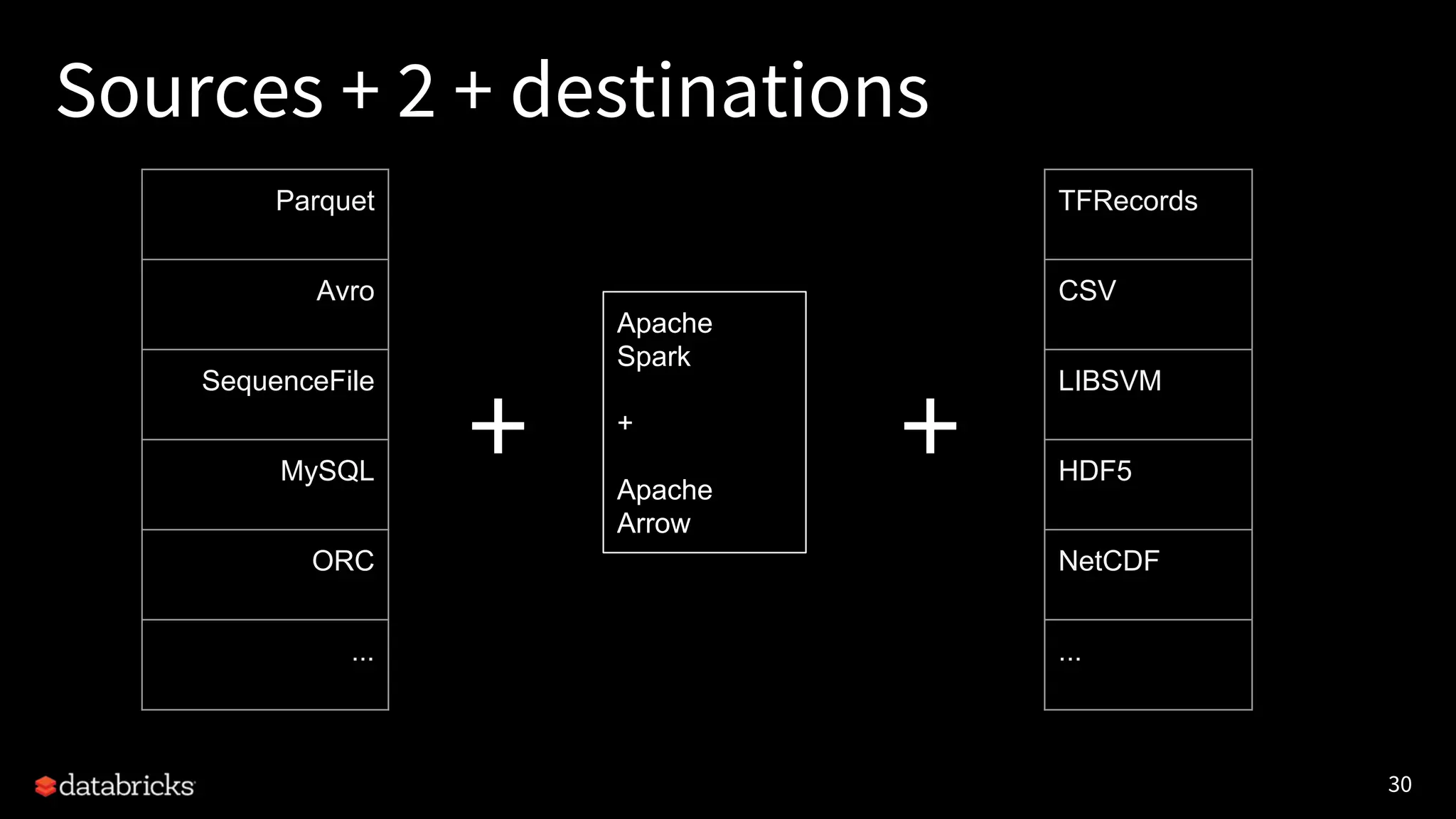
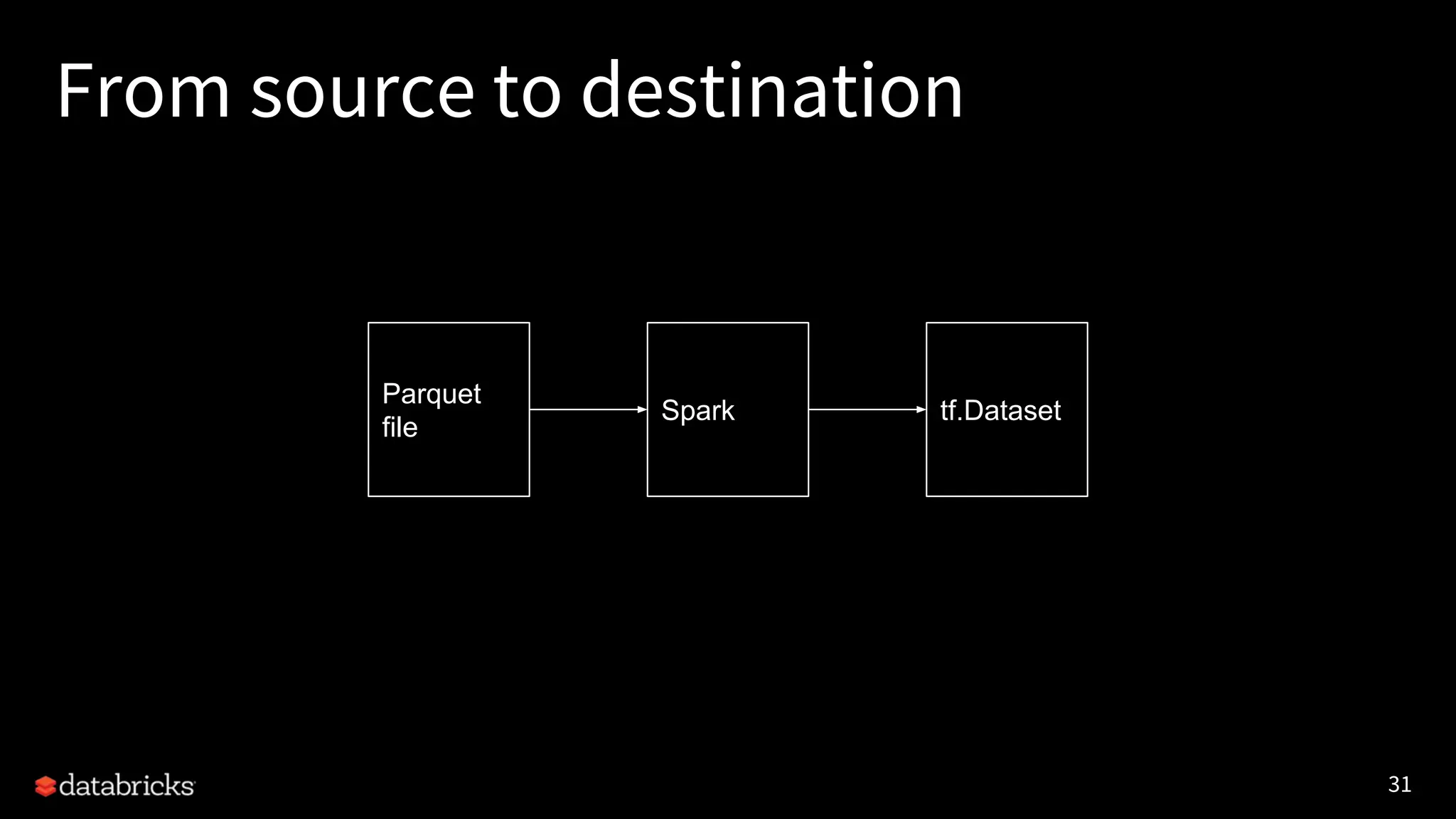

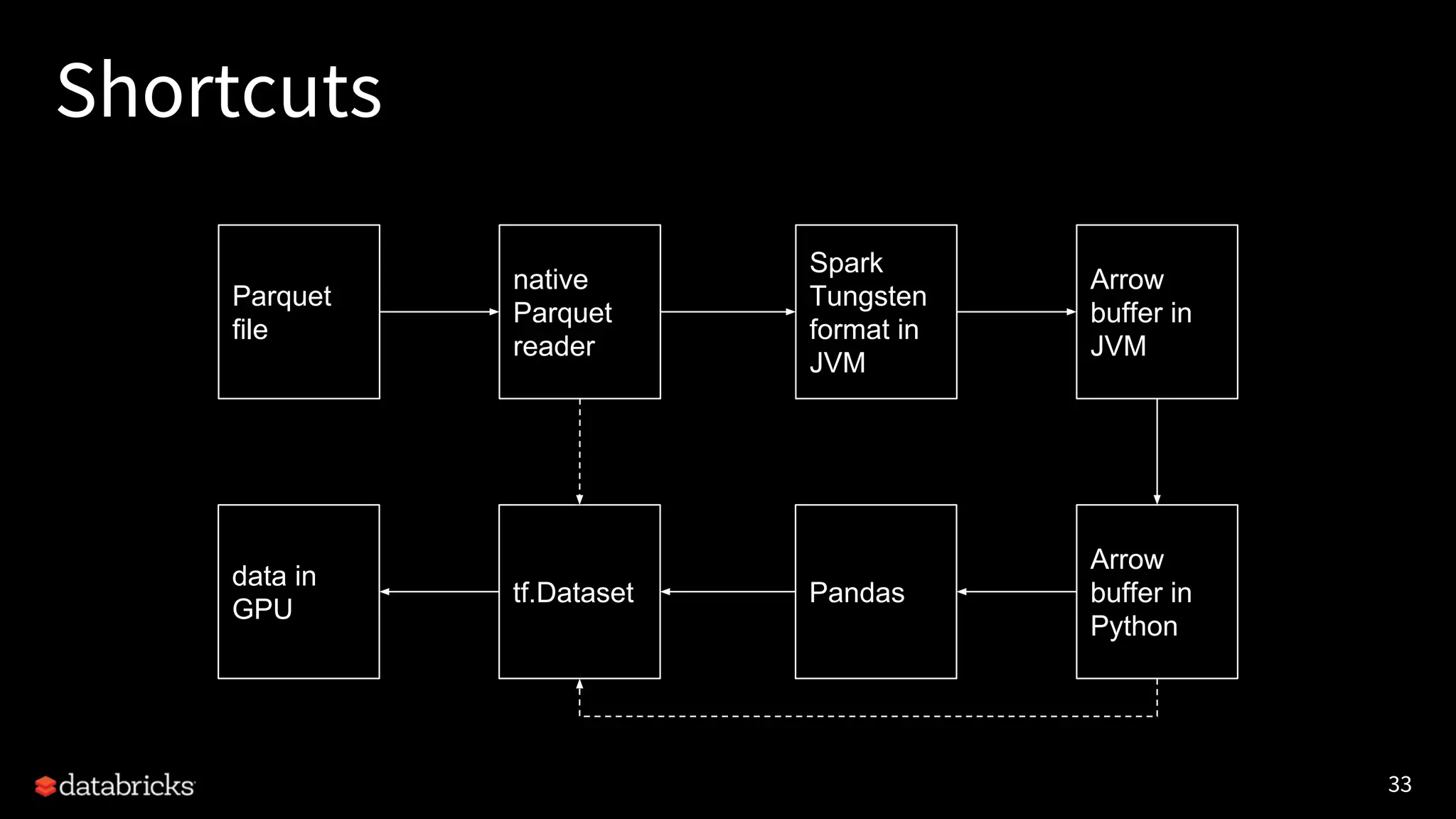











Project Hydrogen integrates big data and AI within Apache Spark, emphasizing the need for a unified framework to enhance machine learning systems and their performance. It outlines the challenges and solutions for distributed training, optimized data exchange, and the importance of leveraging both GPU and CPU resources in hybrid clusters. The initiative aims to provide a streamlined approach to handling complex data scenarios and improve integration with AI frameworks.