Download as PDF, PPTX























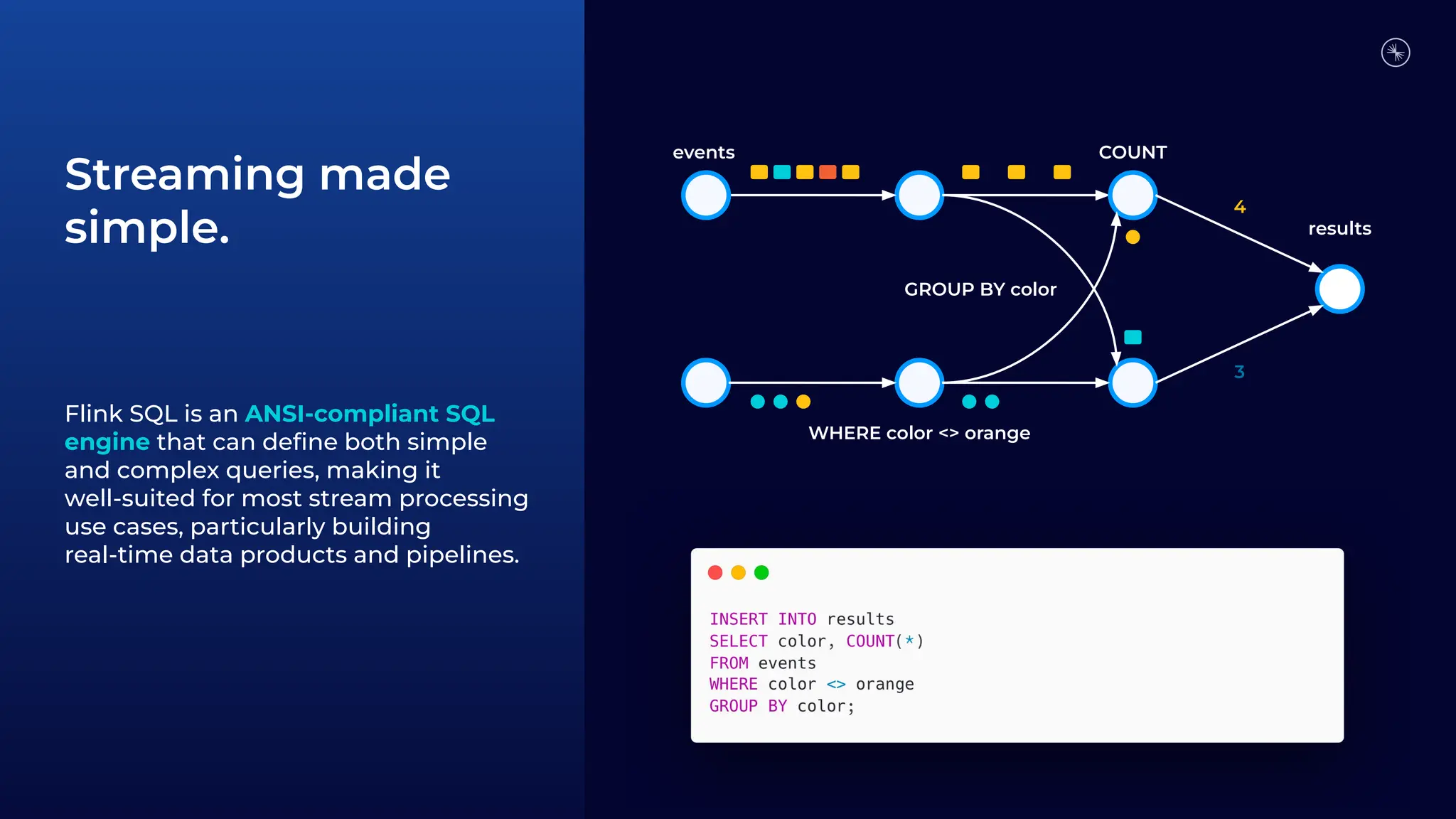

![Flink SQL operators work across both stream and batch processing modes STREAMING AND BATCH BATCH ONLY • SELECT FROM [WHERE] • GROUP BY [HAVING] (includes time-based windowing) • OVER aggregations (including Top-N and Deduplication queries) • INNER + OUTER JOINs • MATCH_RECOGNIZE (pattern matching) • Set Operations • User-Defined Functions • Statement Sets STREAMING ONLY • ORDER BY time ascending only • INNER JOIN with Temporal (versioned) table External lookup table • ORDER BY anything](https://image.slidesharecdn.com/santanderstreamprocessingwithapacheflink-techtalkdeck-240405123744-86a970b7/75/Santander-Stream-Processing-with-Apache-Flink-43-2048.jpg)


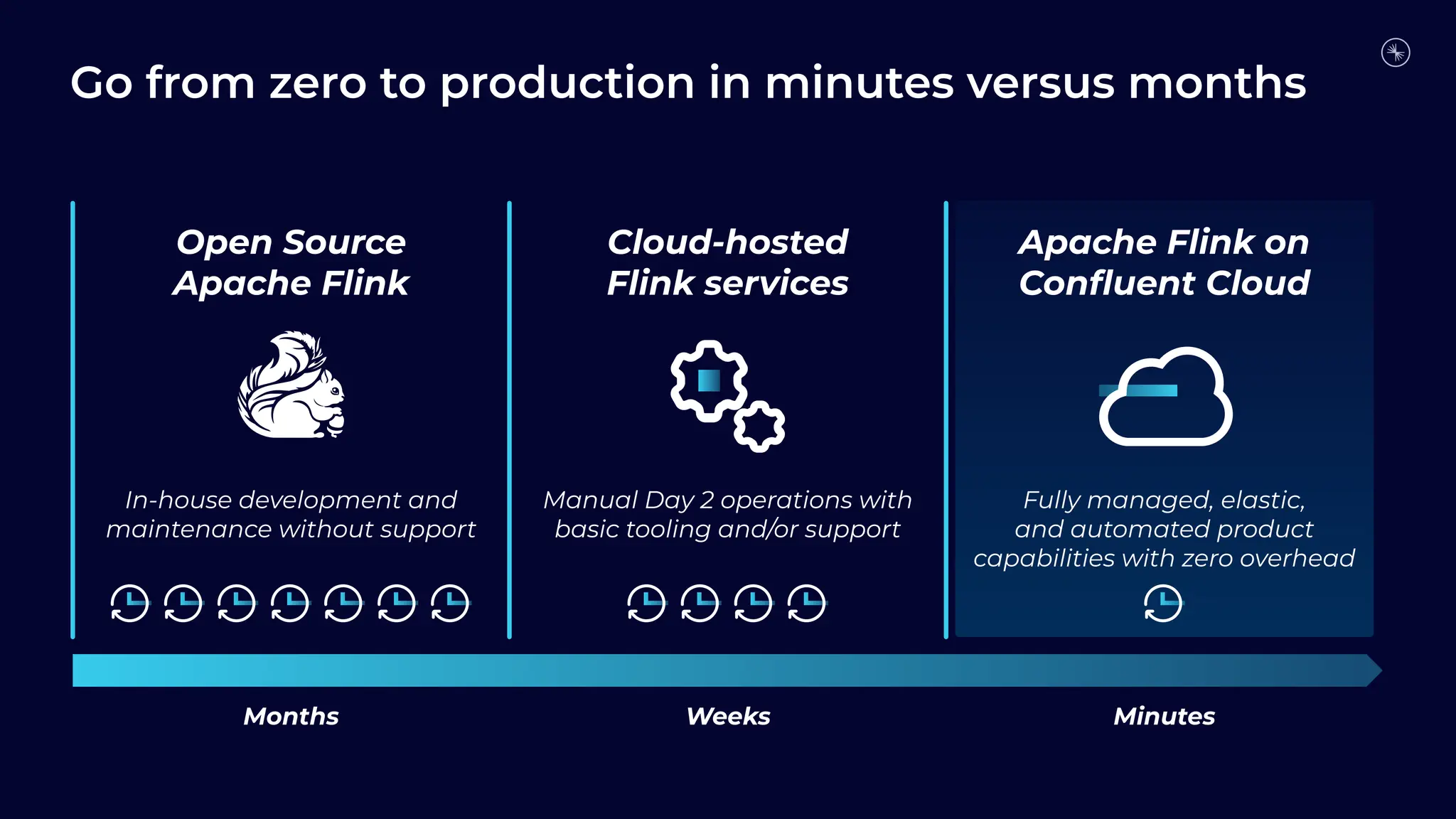

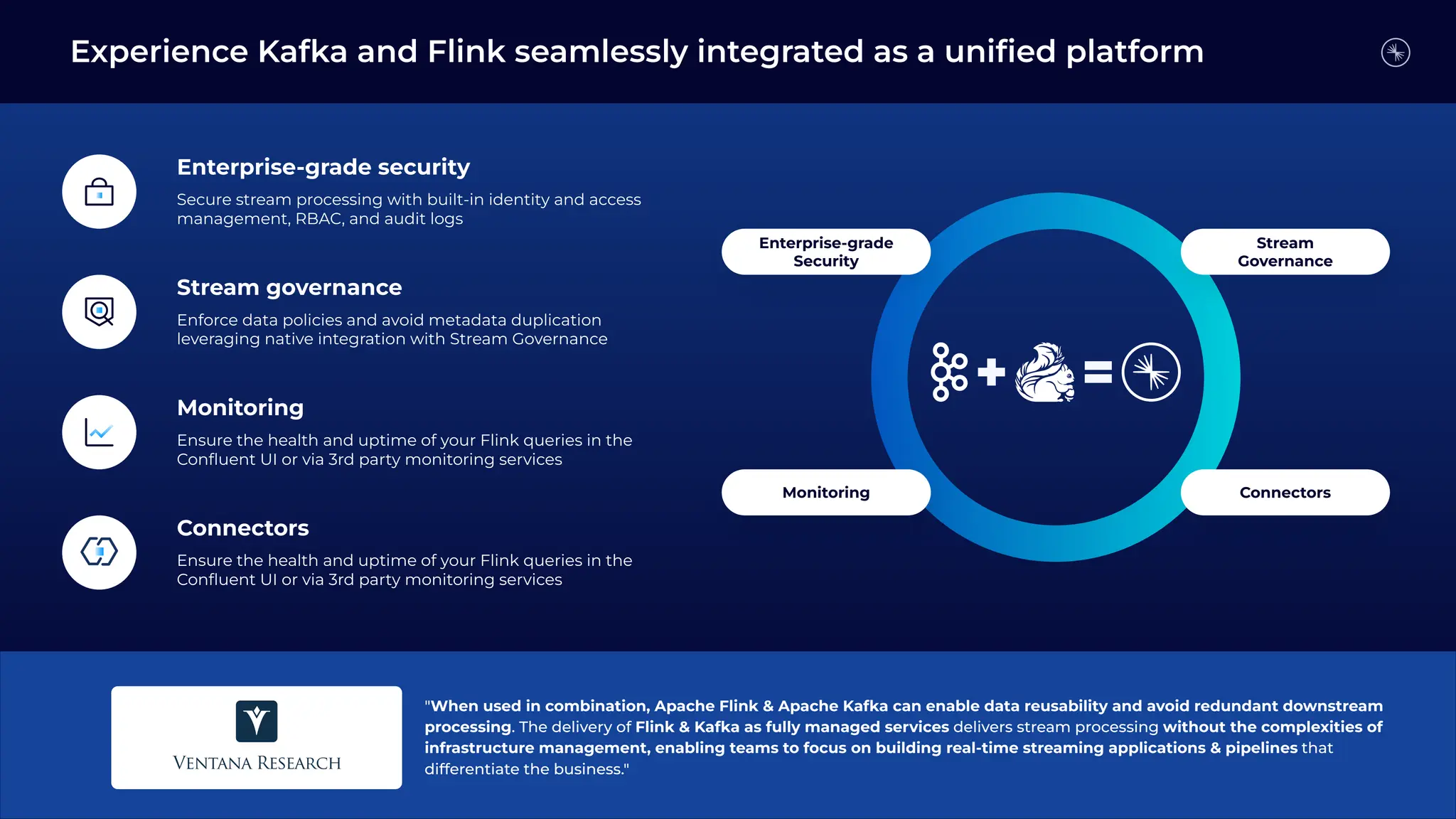
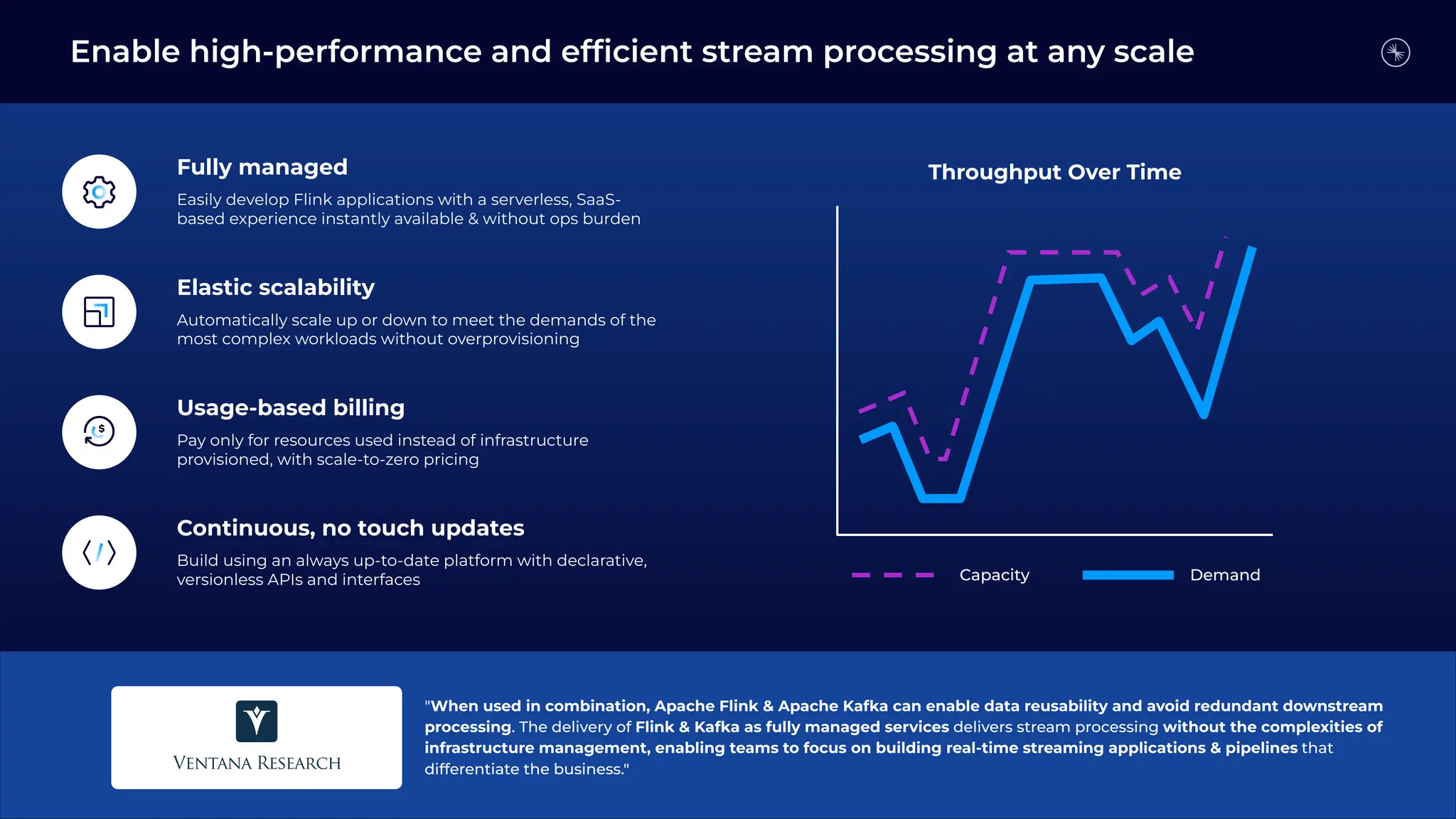





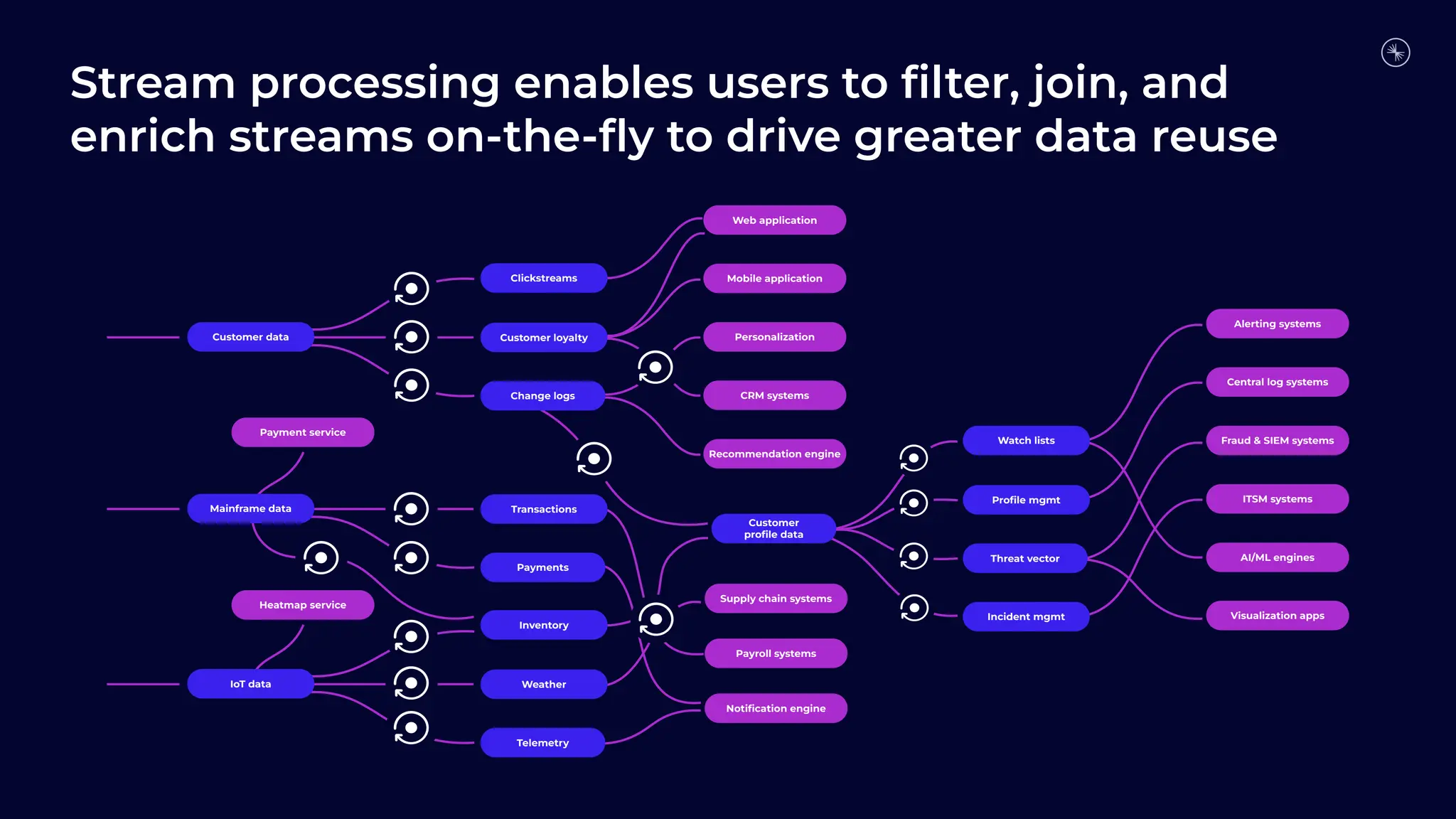
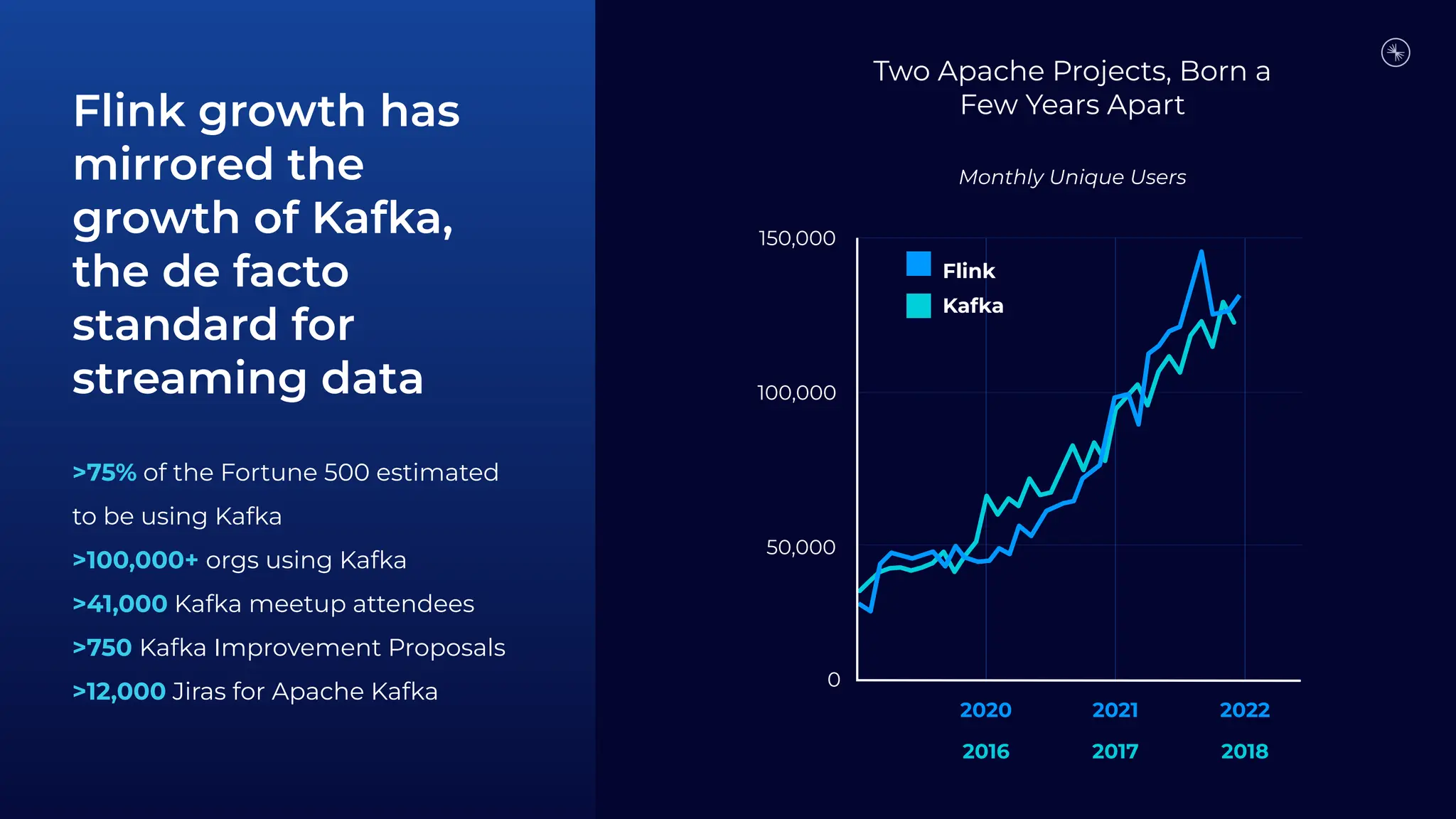
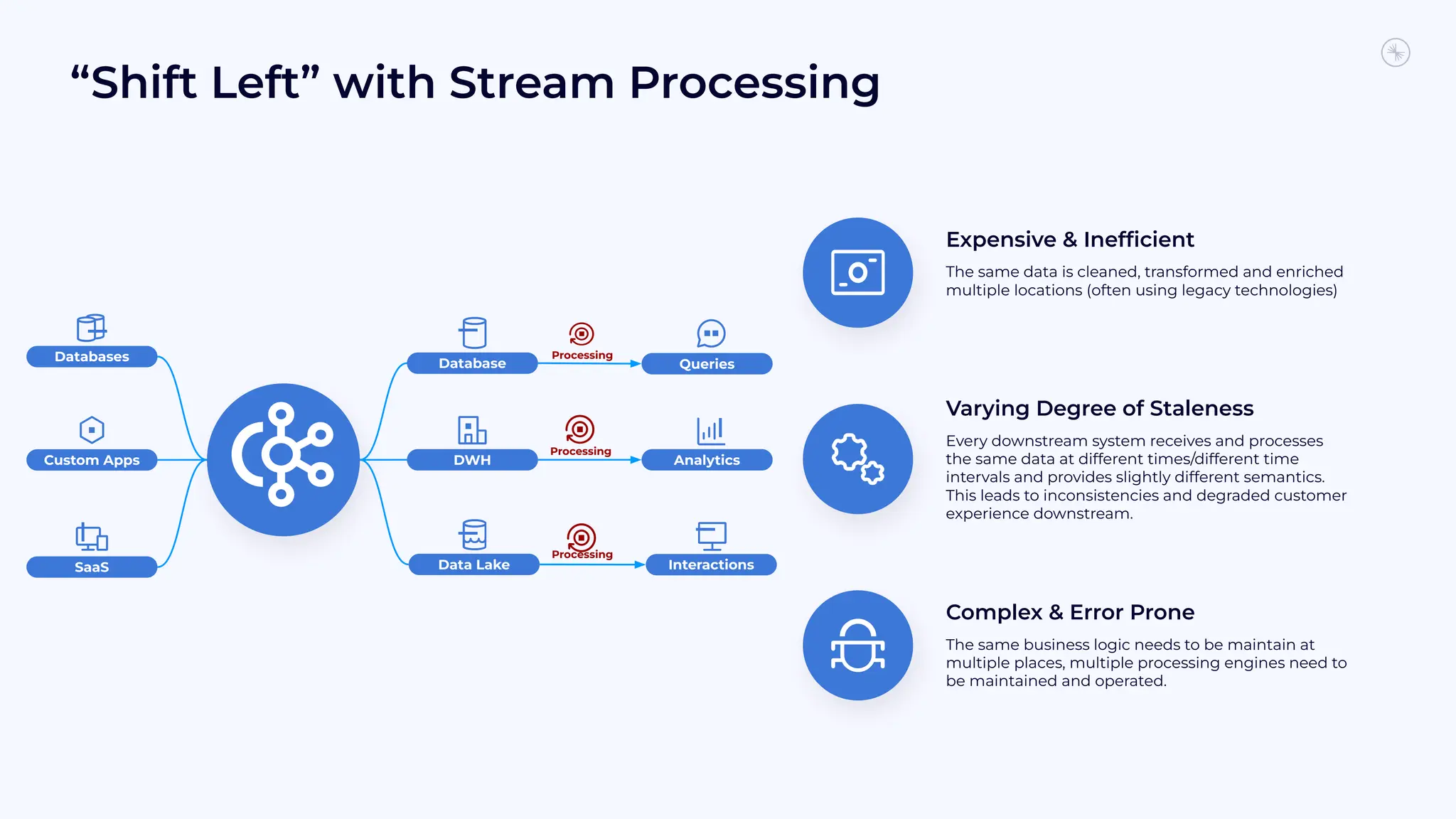
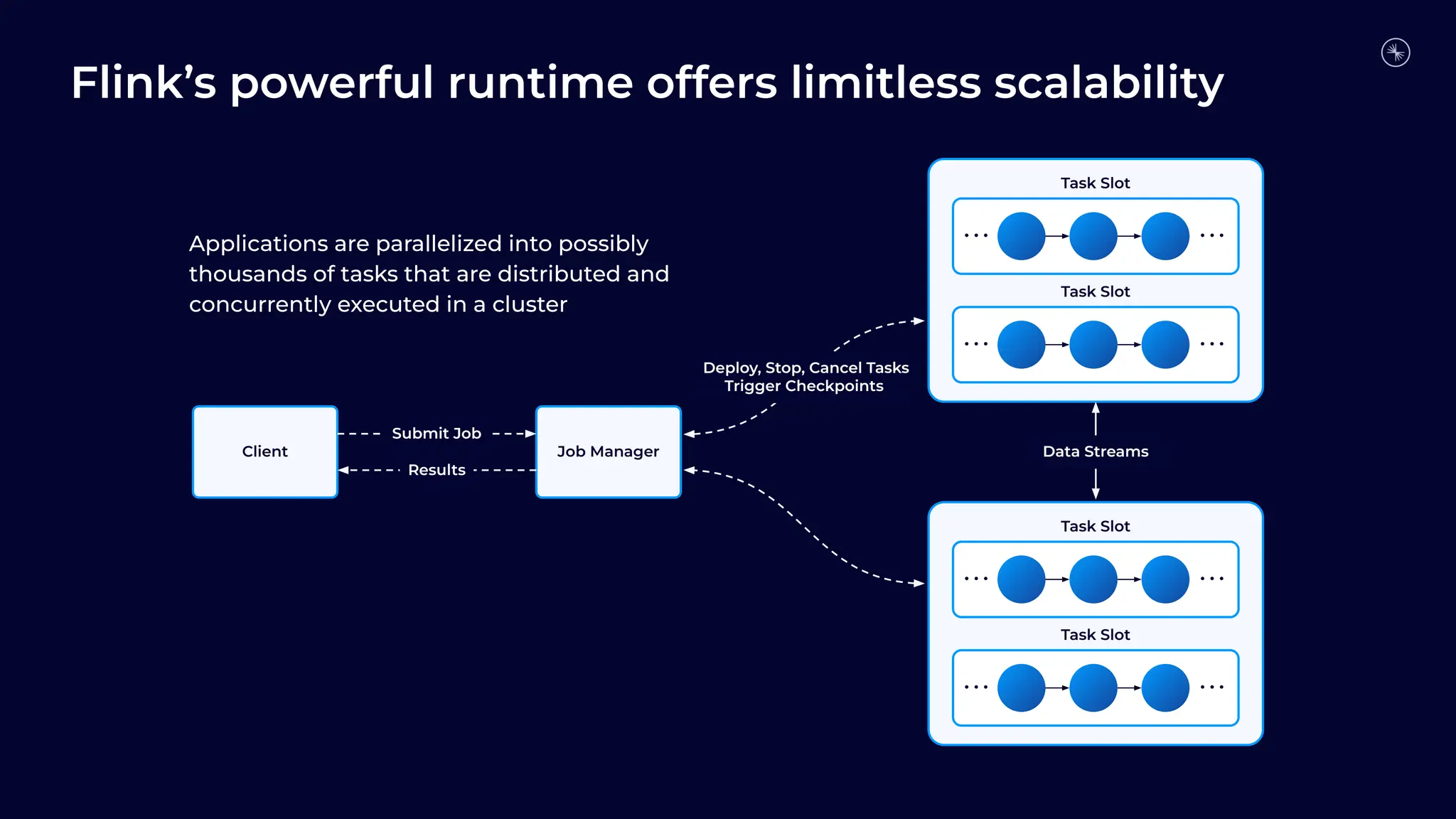
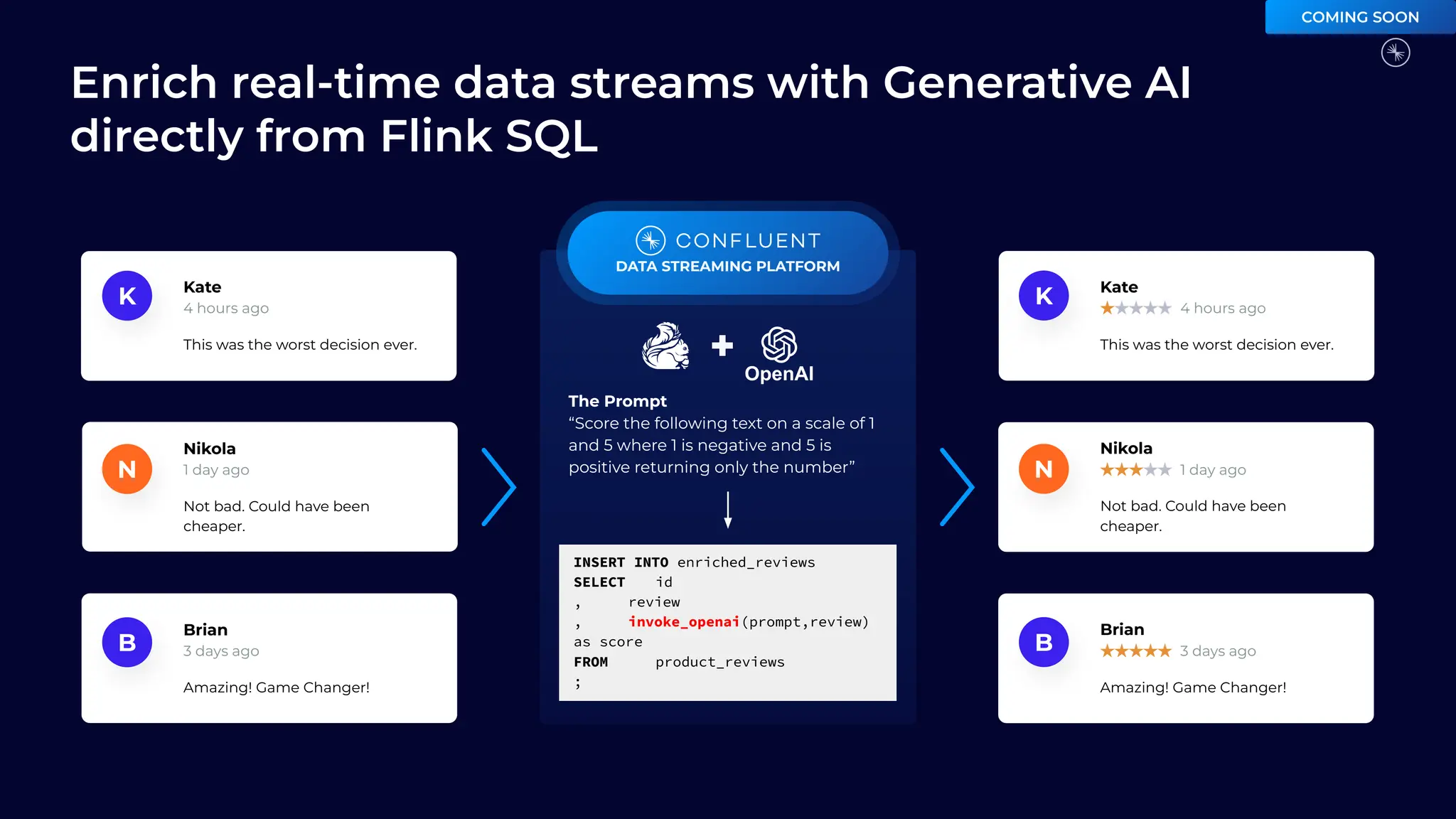
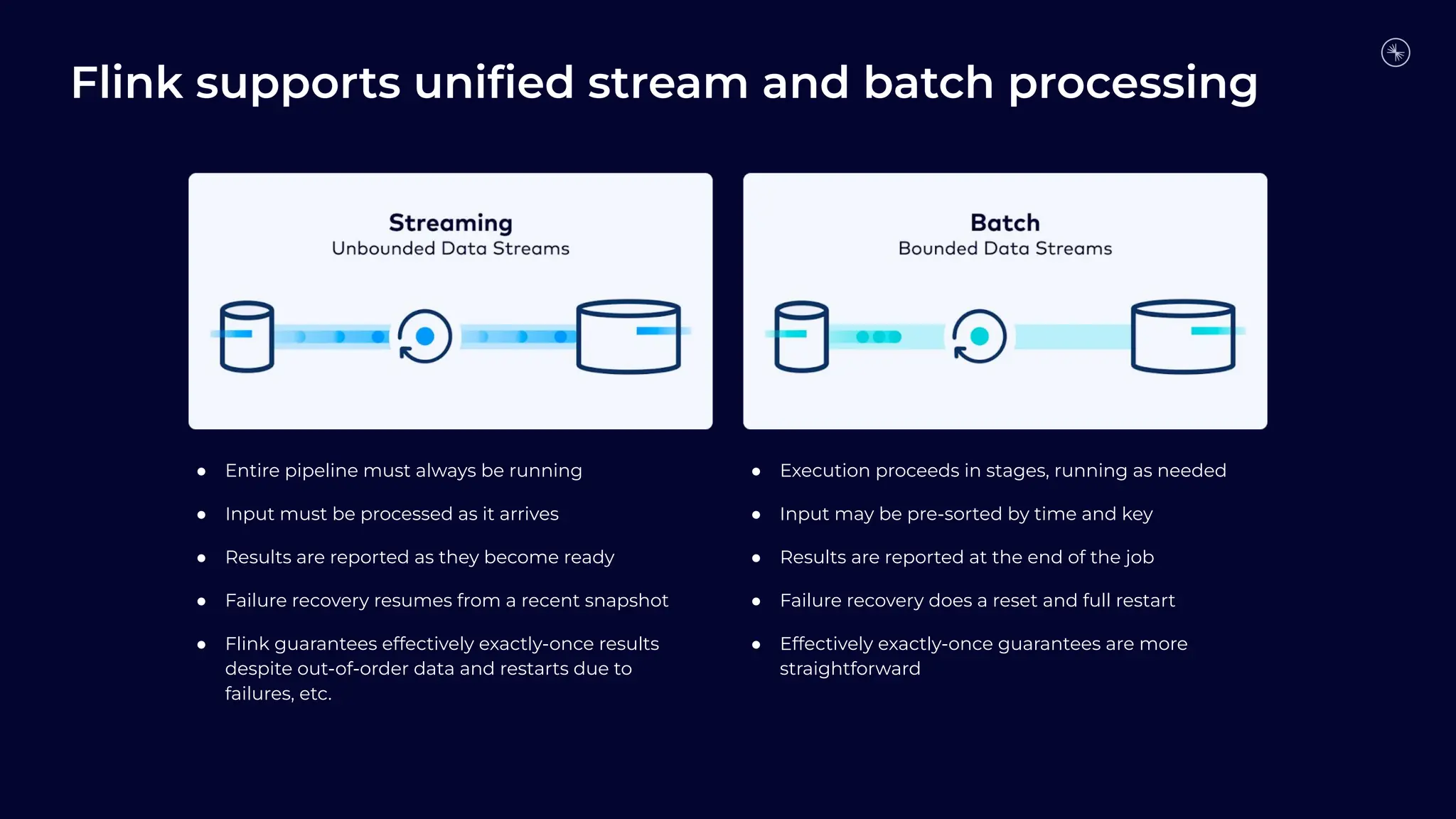
Flink is becoming the de facto standard for stream processing due to its scalability, performance, fault tolerance, and language flexibility. It supports stream processing, batch processing, and analytics through one unified system. Developers choose Flink for its robust feature set and ability to handle stream processing workloads at large scales efficiently.