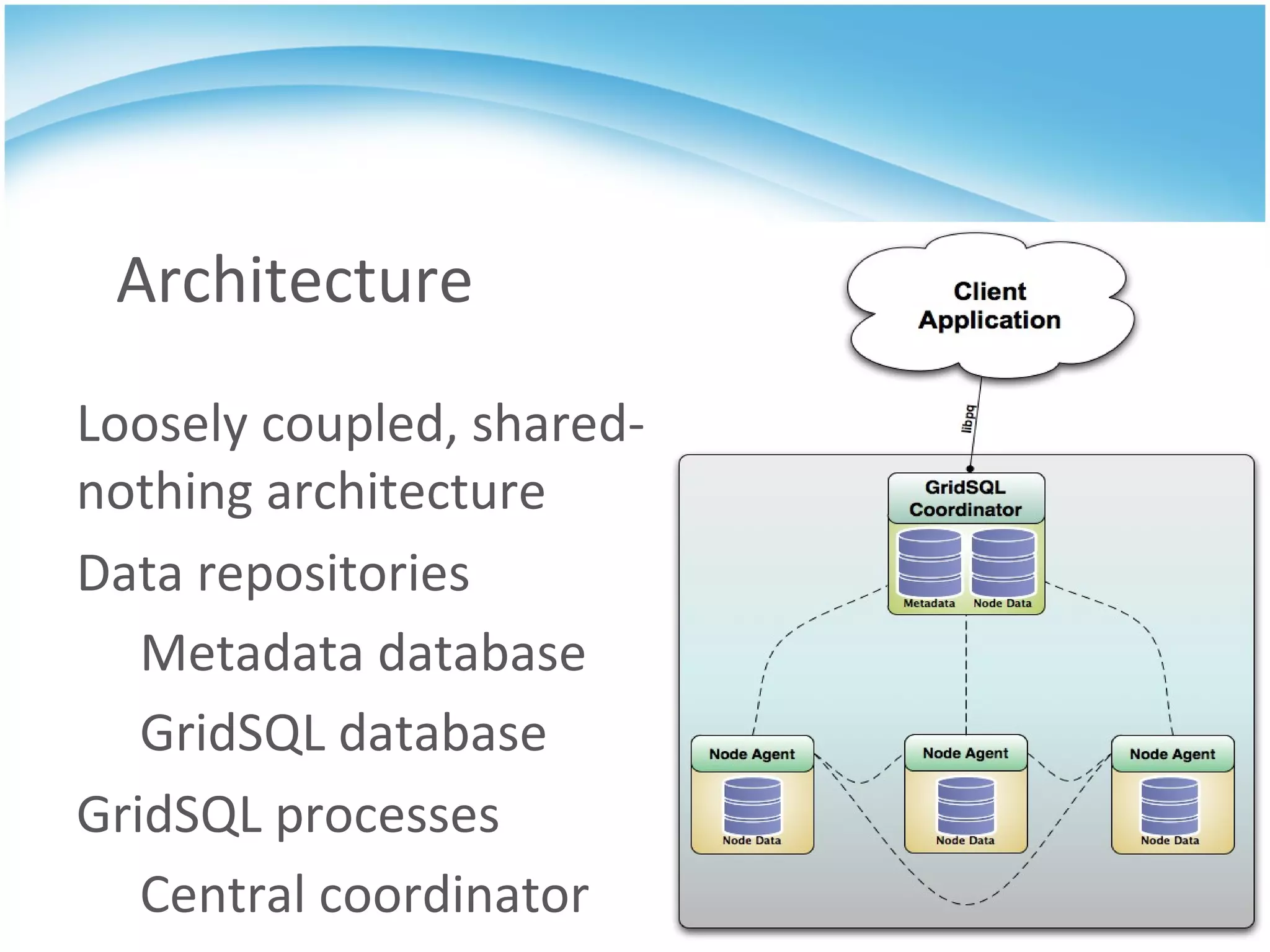
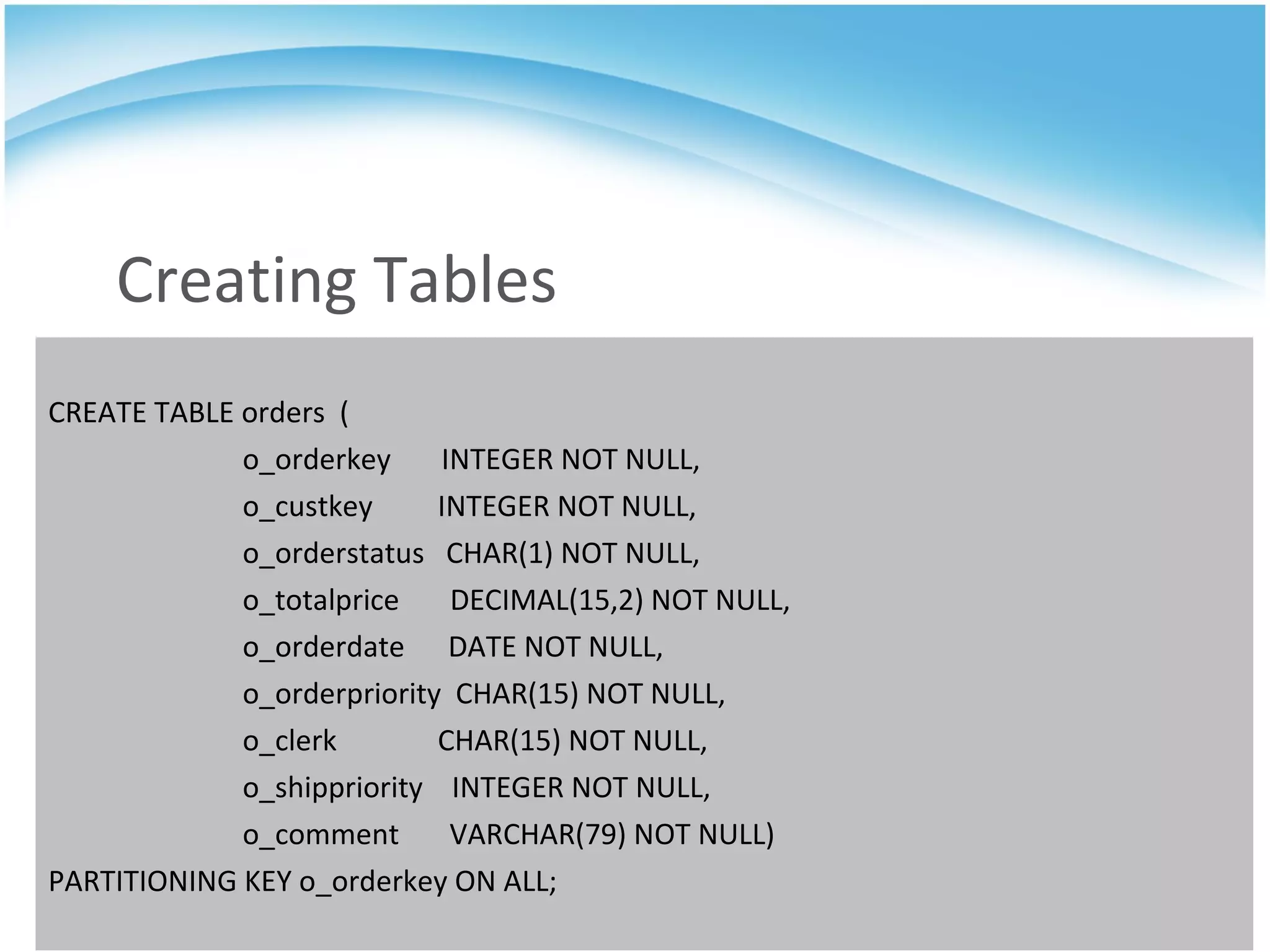
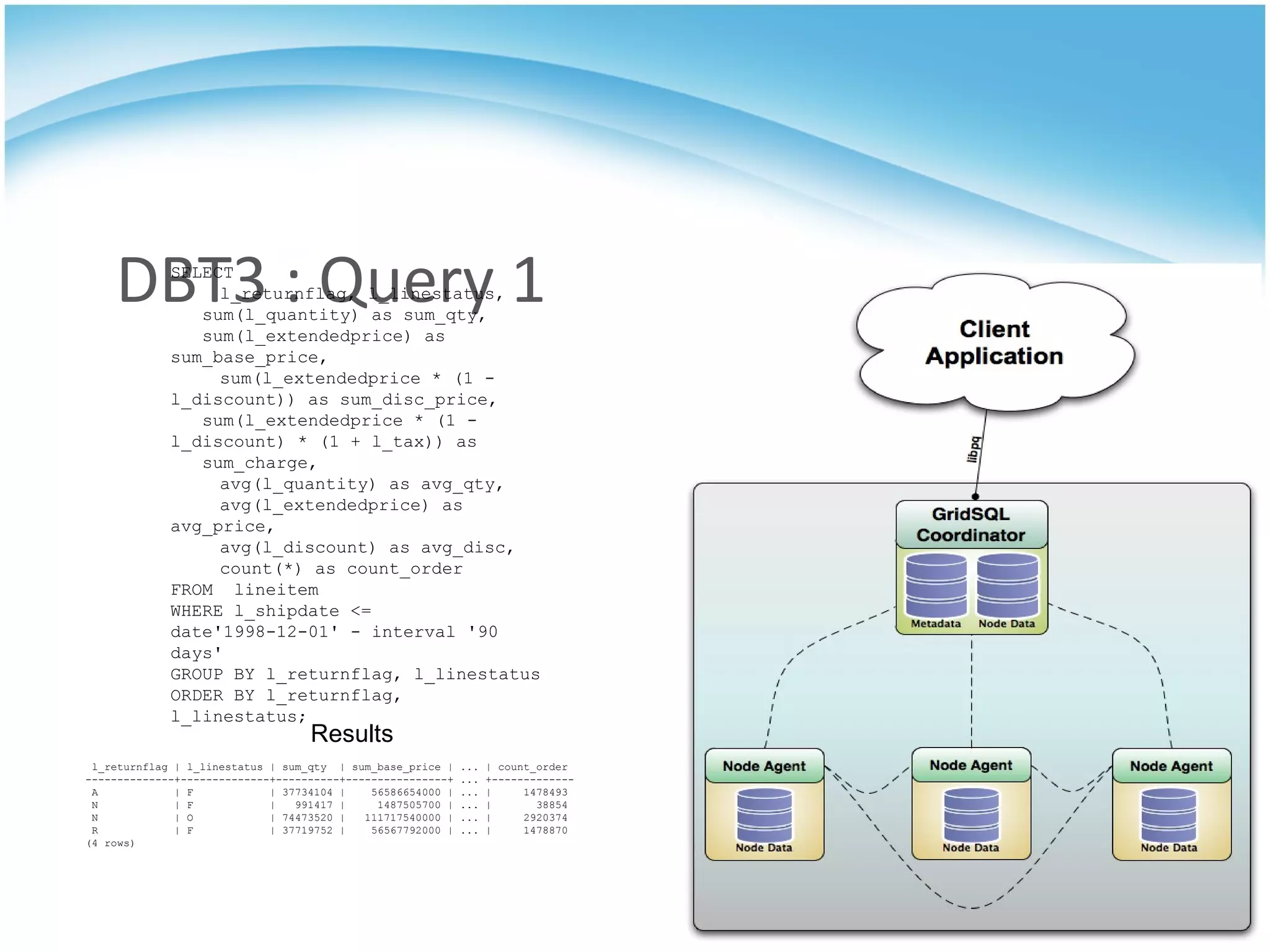
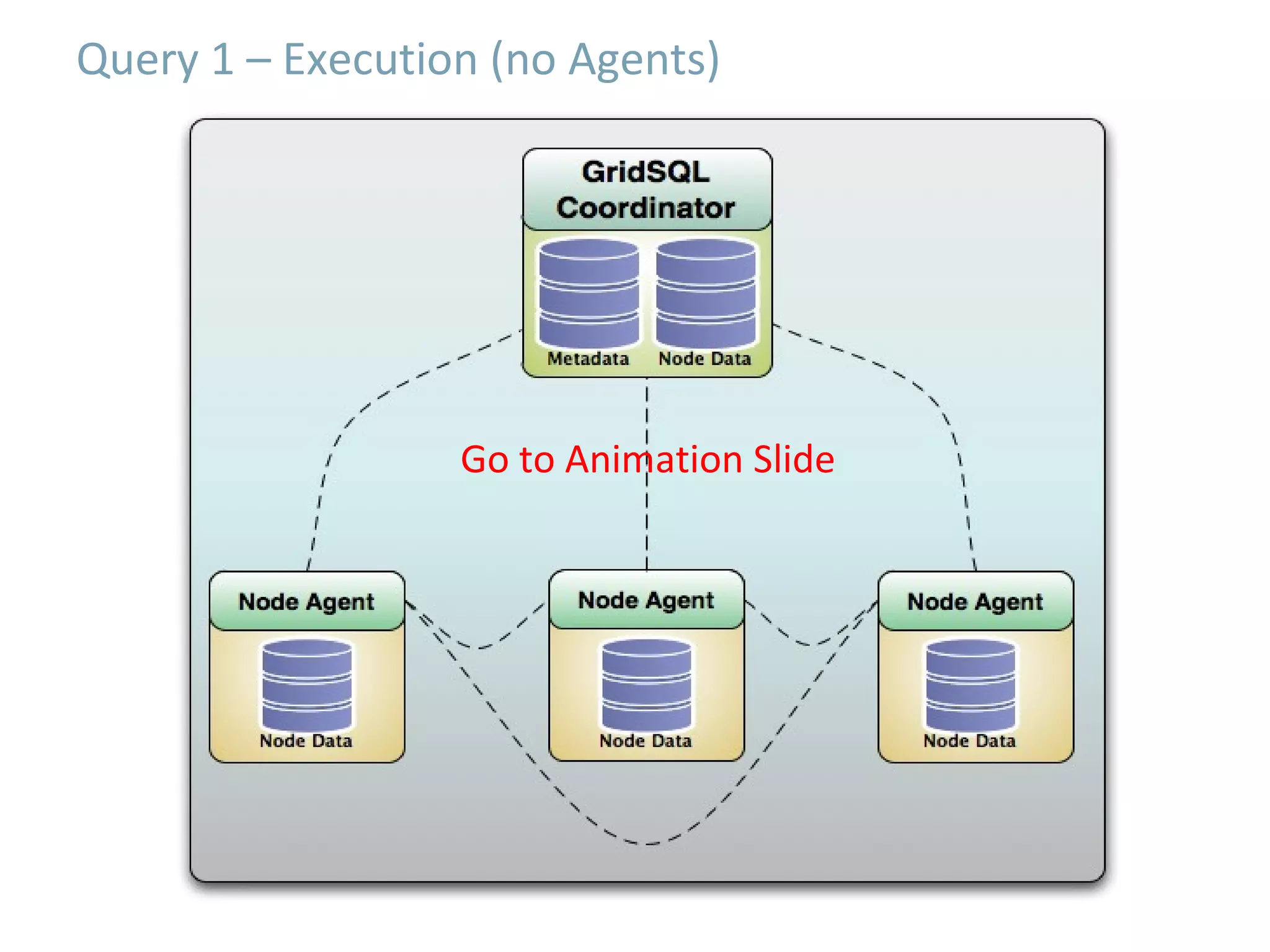
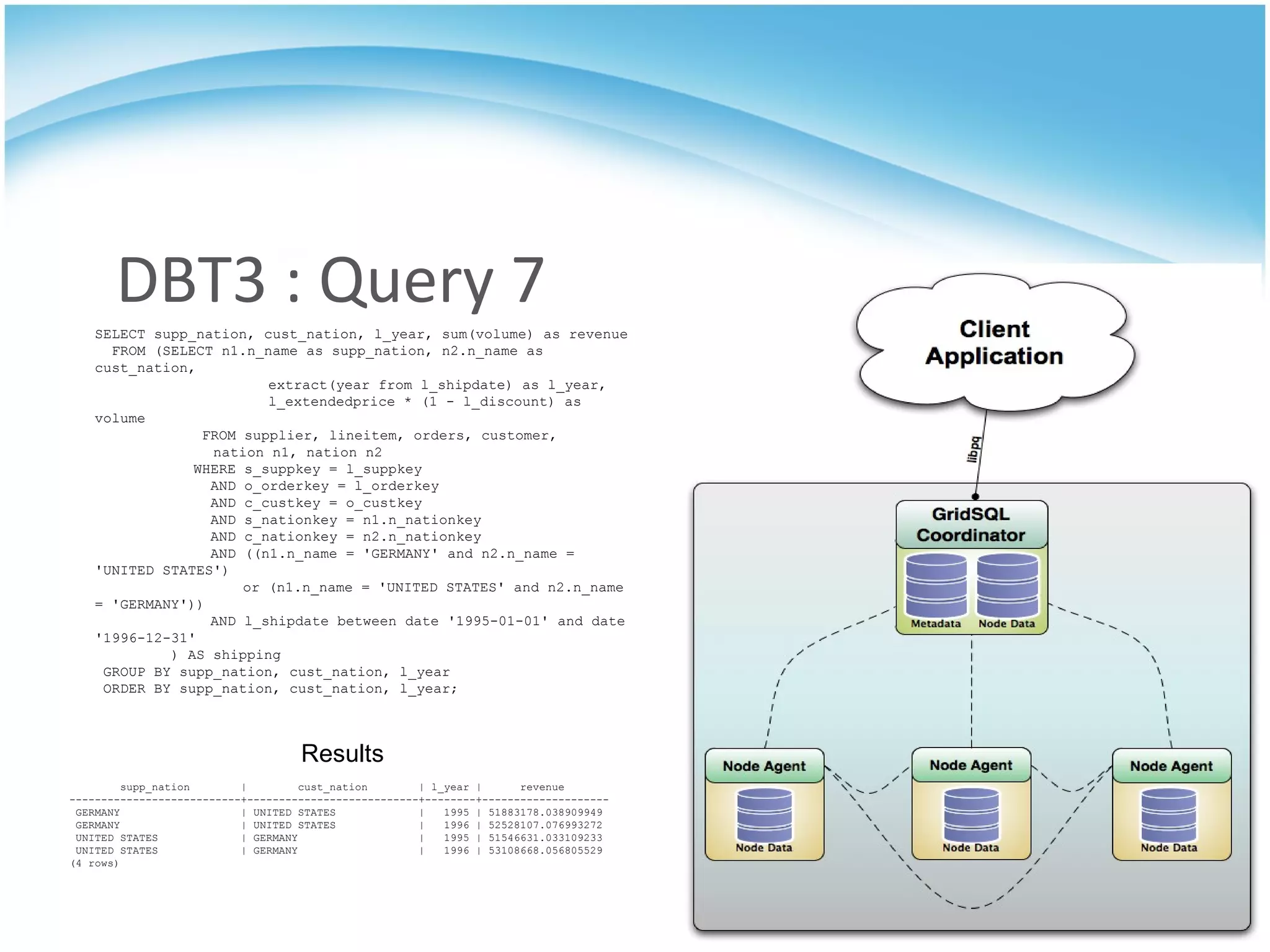
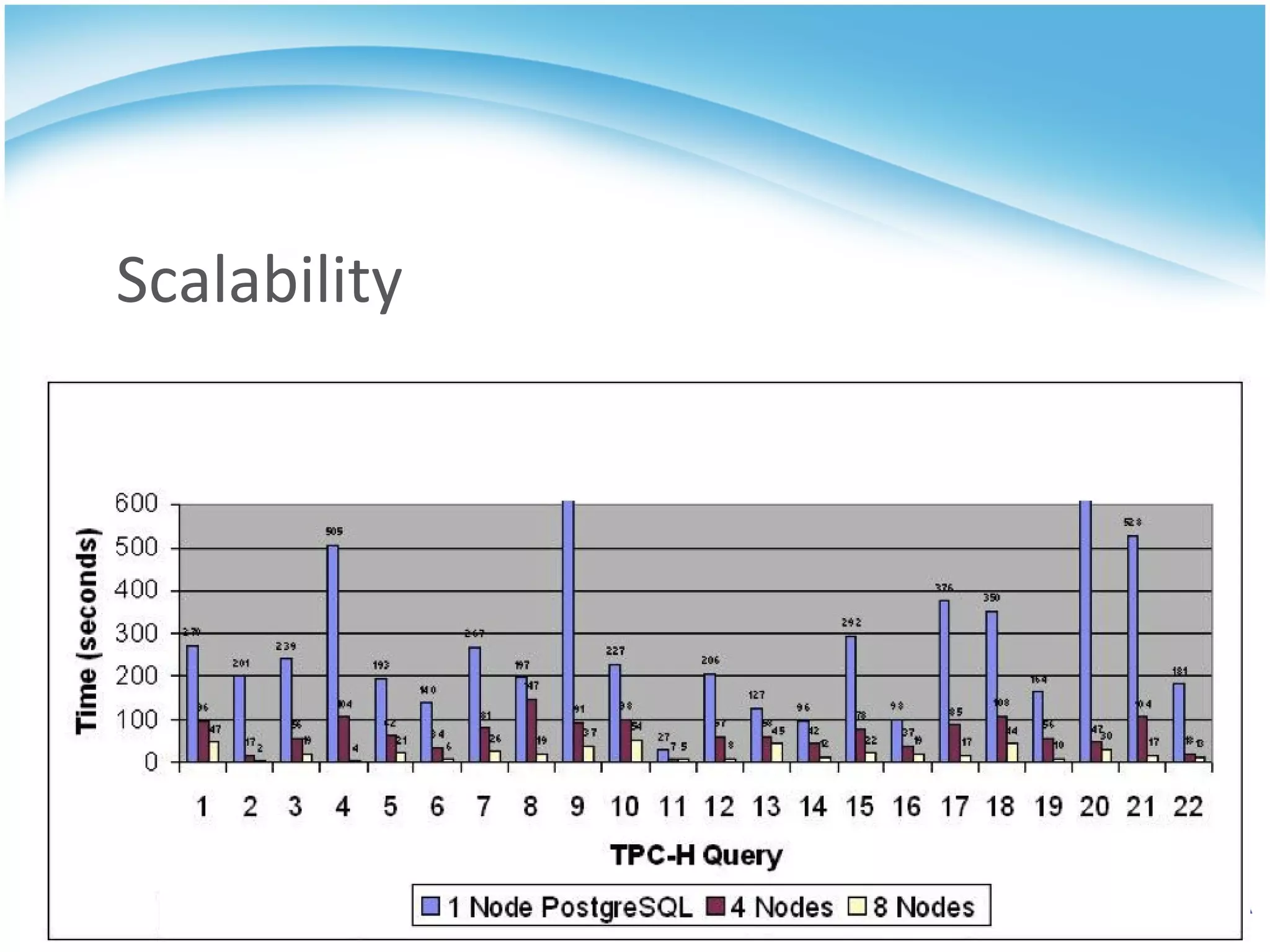
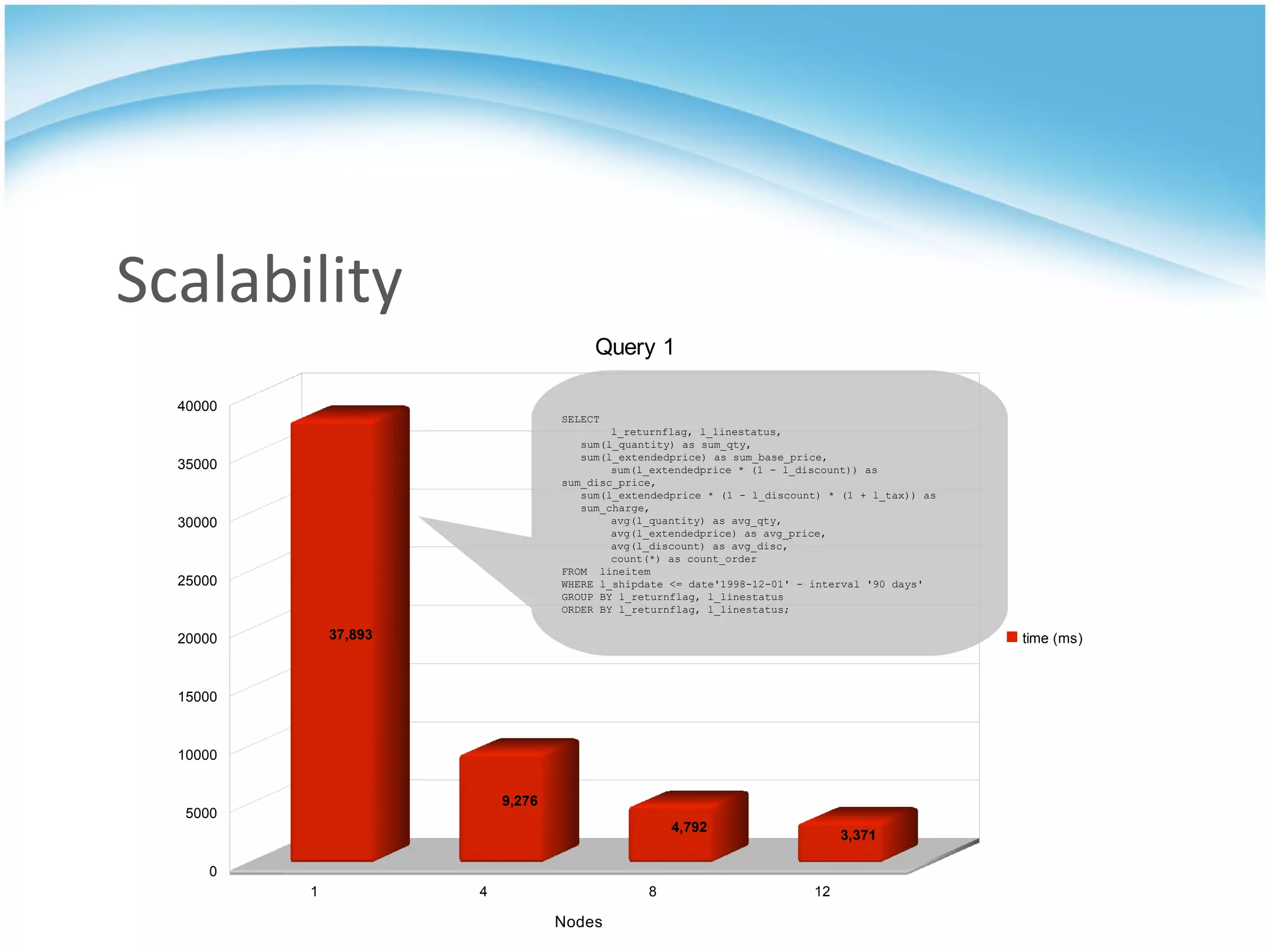
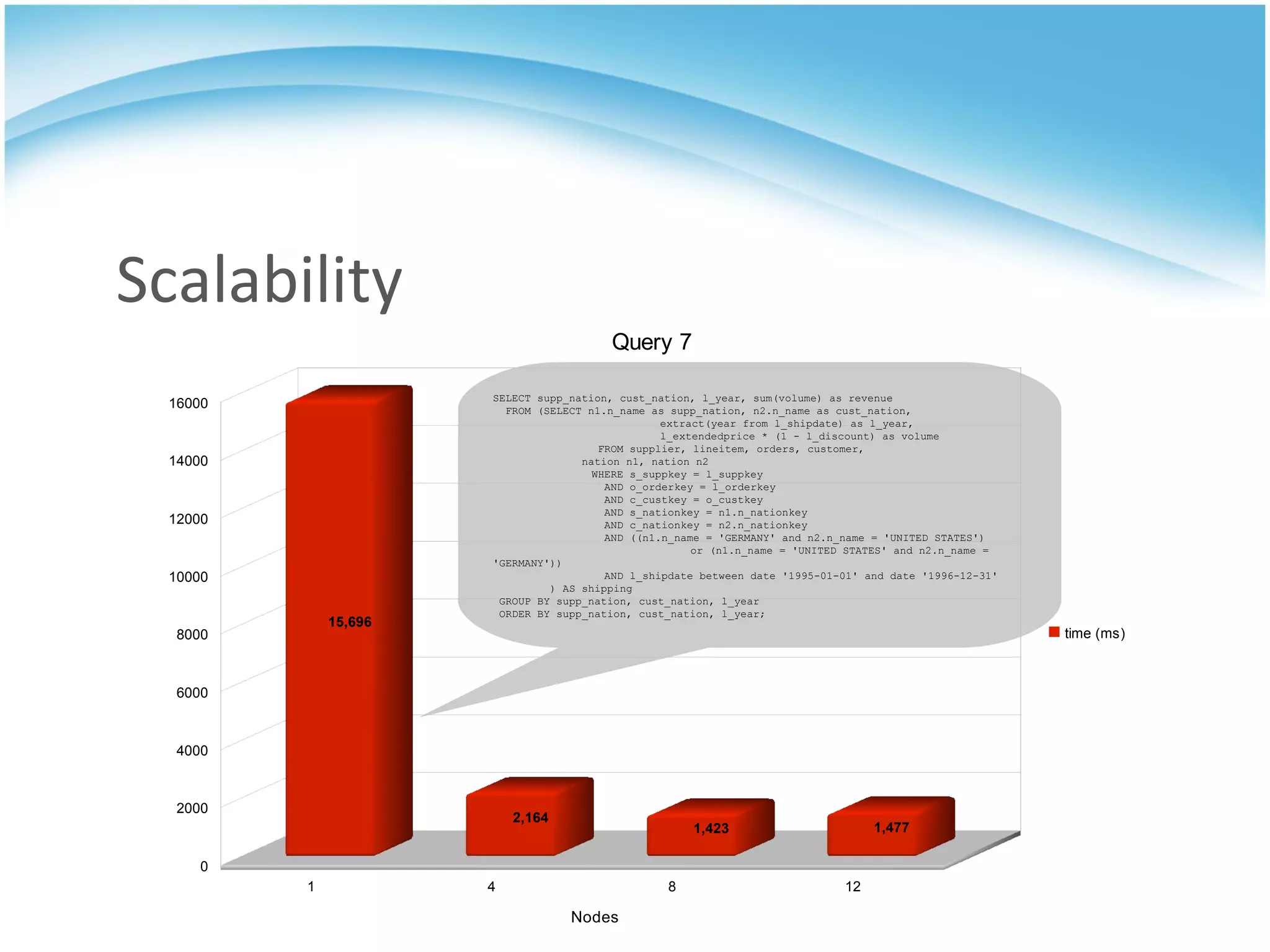
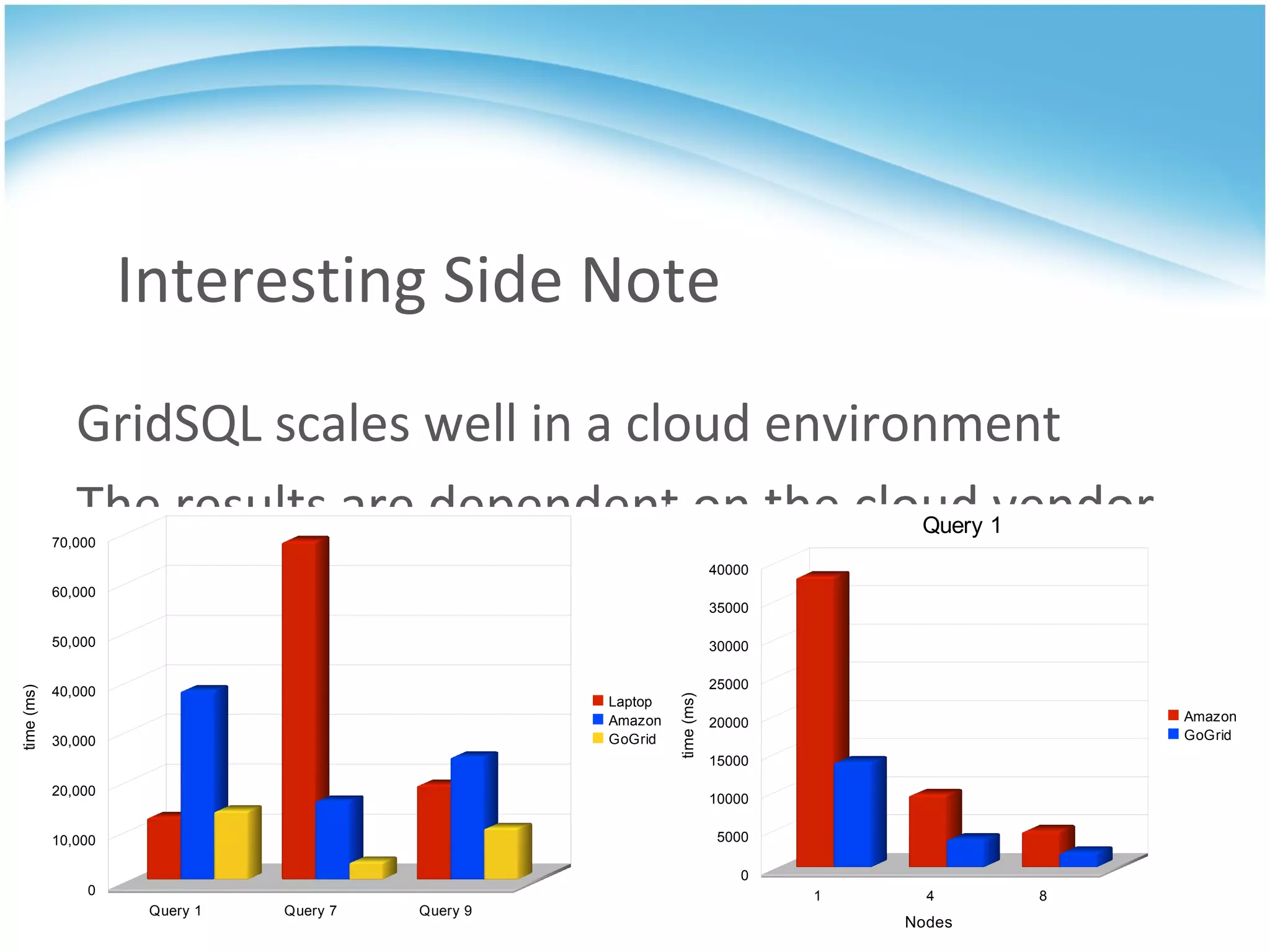
GridSQL is an open source distributed database built on PostgreSQL that allows it to scale horizontally across multiple servers by partitioning and distributing data and queries. It provides significantly improved performance over a single PostgreSQL instance for large datasets and queries by parallelizing processing across nodes. However, it has some limitations compared to PostgreSQL such as lack of support for advanced SQL features, slower transactions, and need for downtime to add nodes.