Download as PDF, PPTX










![Resource Allocation • Fine-grained resource specification: – {cpuMilliCores: 3000, memoryBytes: 200GB} • Constraints: – “dataCenter = dc1 & type in [1,2] & kernelVersion > 4.10” • Job Affinity: – inSameDatacenter 14#UnifiedAnalytics #SparkAISummit](https://image.slidesharecdn.com/023016ruijianhaolin-190509172856/75/Tangram-Distributed-Scheduling-Framework-for-Apache-Spark-at-Facebook-14-2048.jpg)





Tangram is a distributed scheduling framework developed by Facebook for managing various batch workloads in Apache Spark, emphasizing efficient resource management and scalability. It supports diverse scheduling policies for different job types, focusing on hierarchical queue structures and resource allocation constraints. Future enhancements include integrating mixed workloads under a single resource manager and optimizing resource utilization through automatic tuning.
Introduces the event WiFi details, presenters' names, and their backgrounds at Facebook.
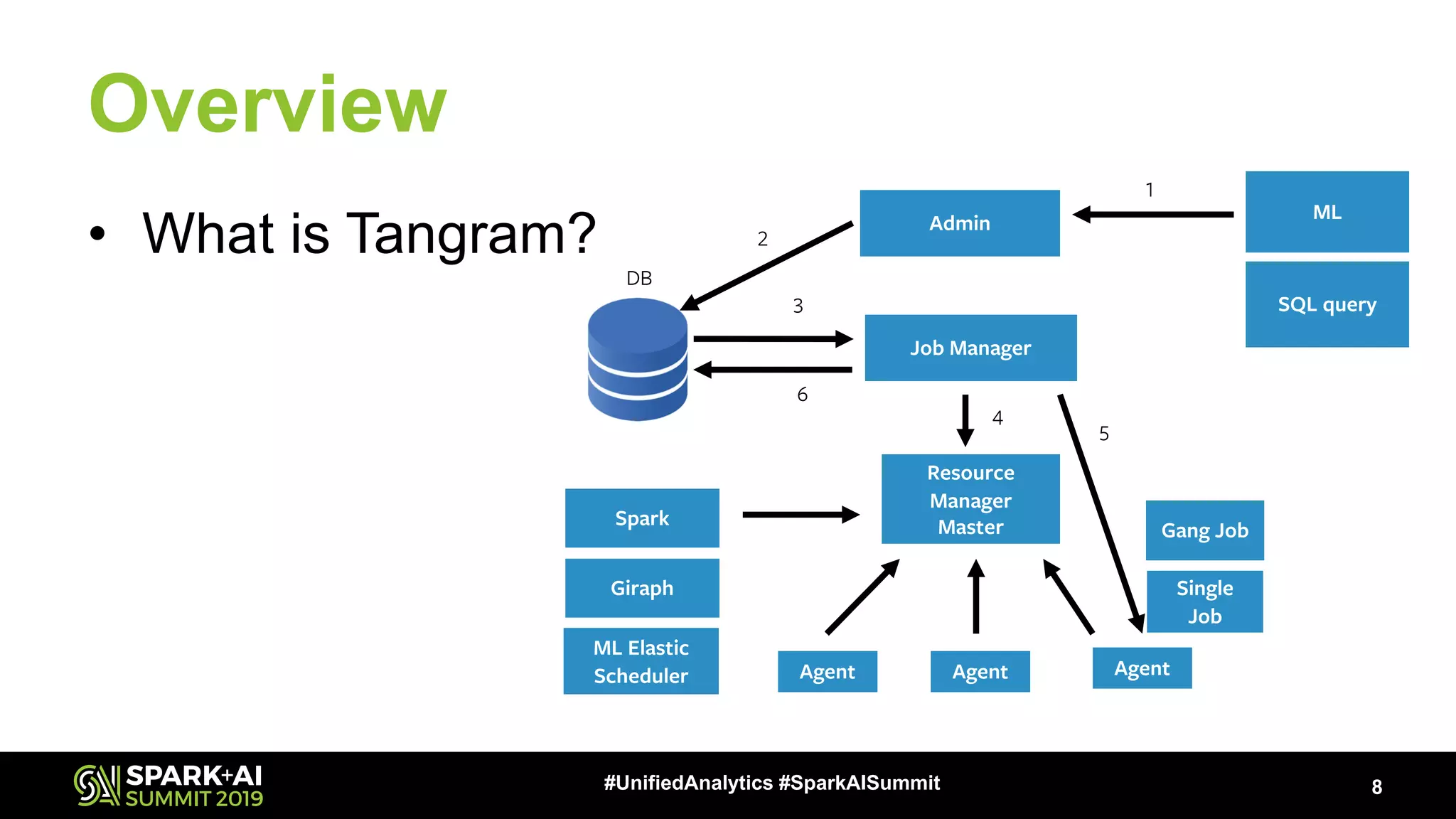
Overview of the presentation agenda and an introduction to Tangram, a distributed scheduling platform.
Details on Tangram's targets for various job types: adhoc/periodic, malleable, rigid, and long-running, showcasing its scalability.
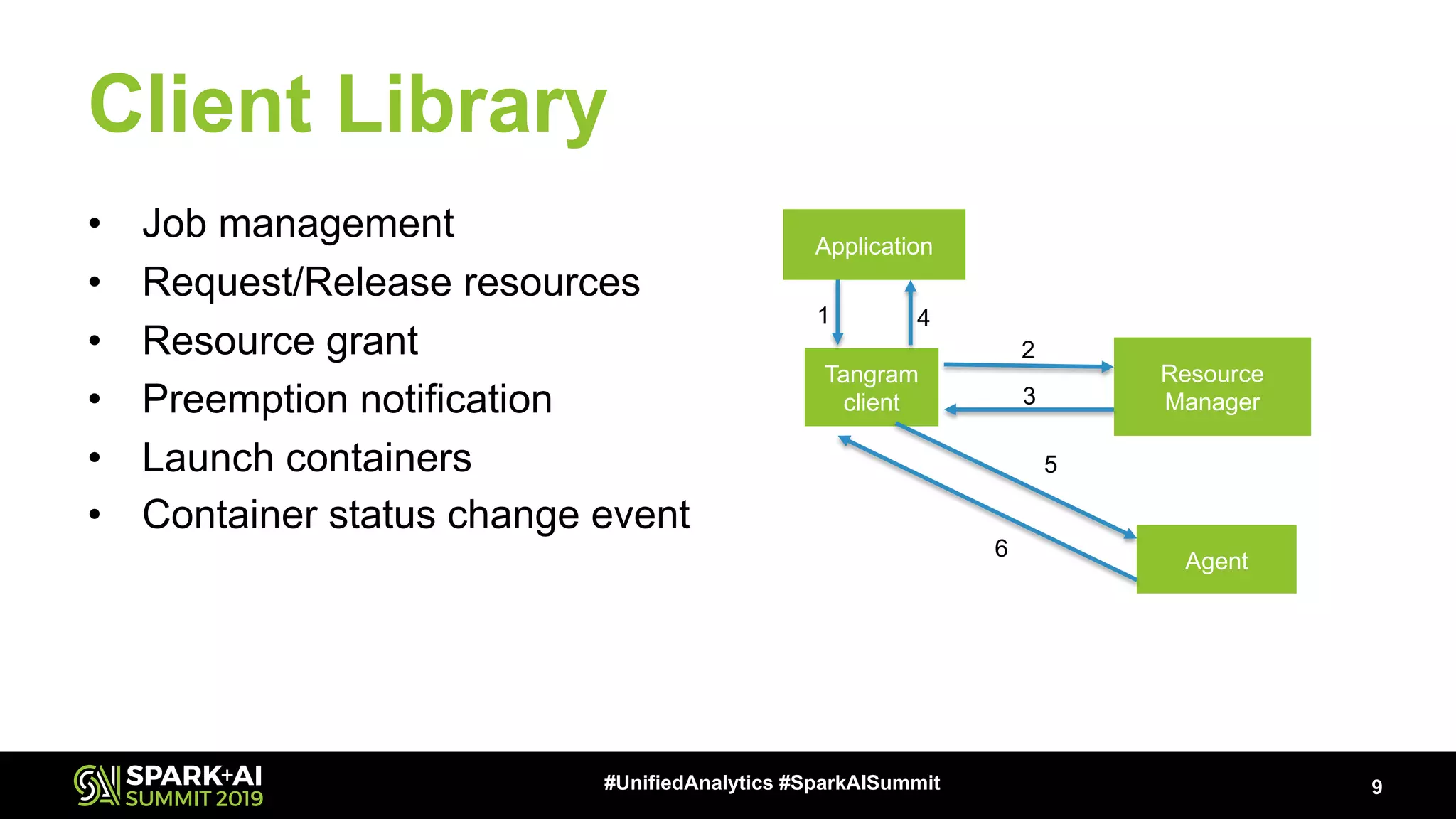
Architecture overview depicting job management and resource handling with insights into client library functionalities.
Explains recovery processes for agent and resource manager failures within the Tangram framework.
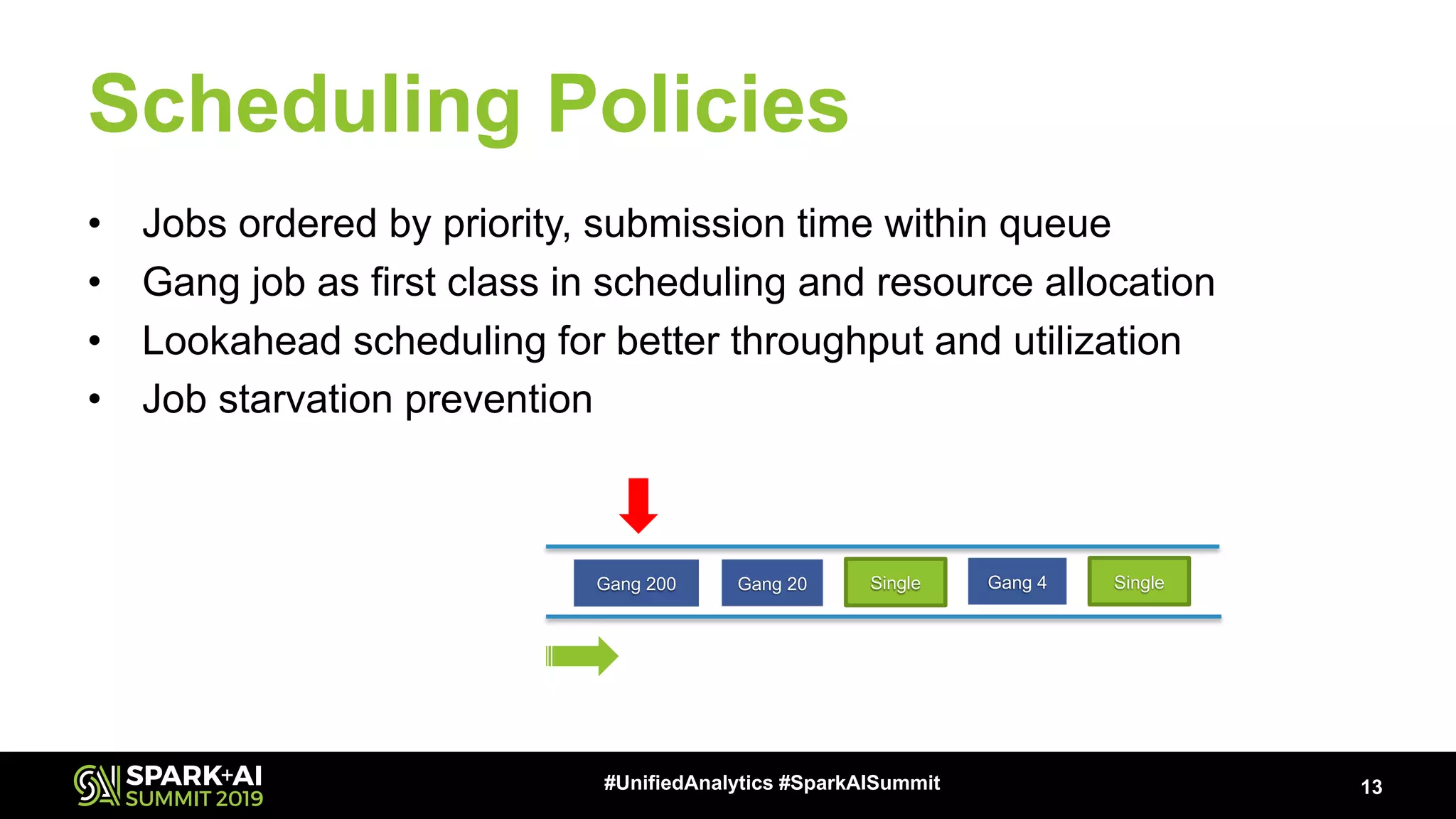
Describes the hierarchical queue structure and diverse job scheduling policies including FIFO and fairness principles.
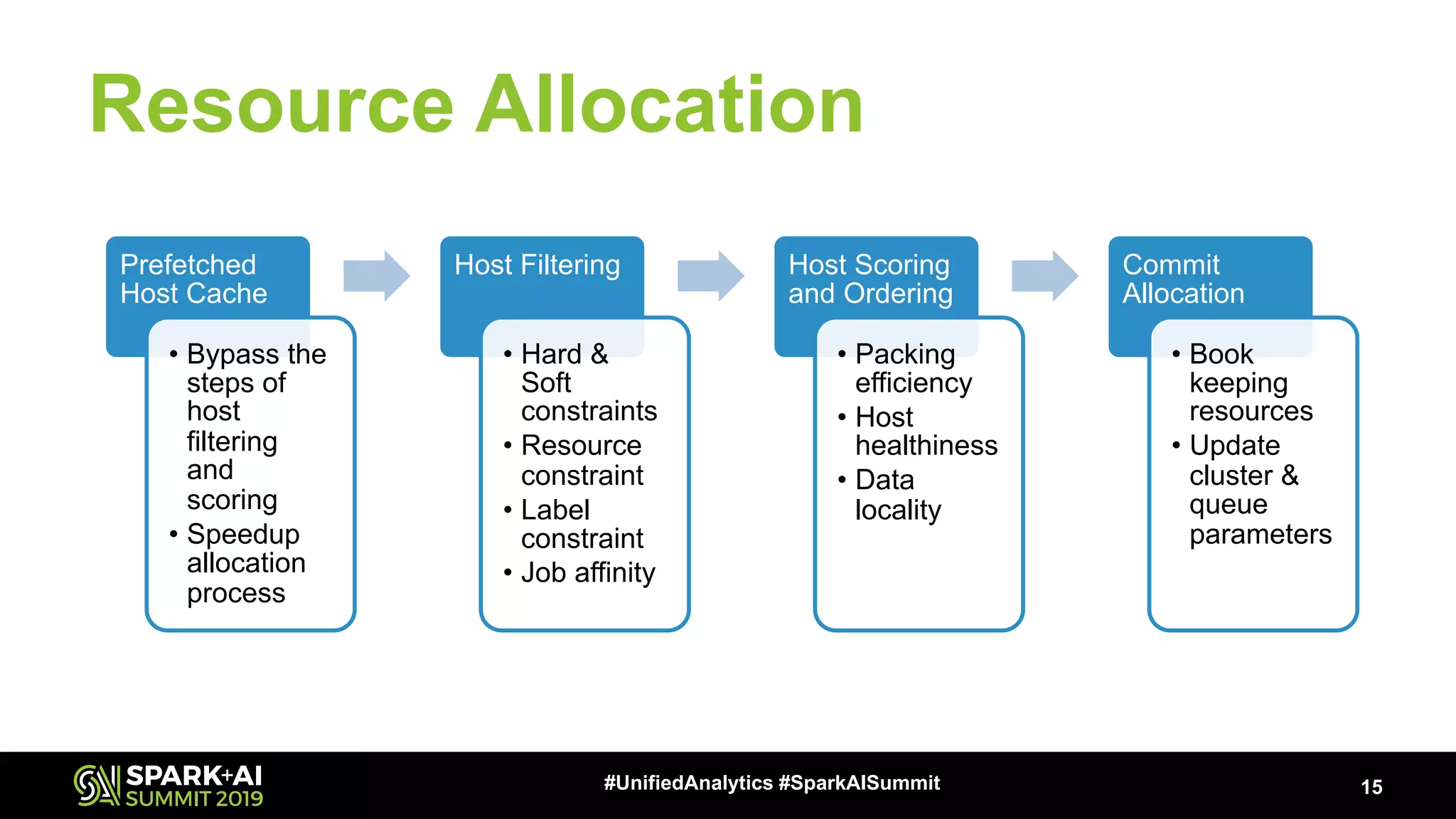
Discusses fine-grained resource specifications and host filtering/scoring processes for efficient job allocation.
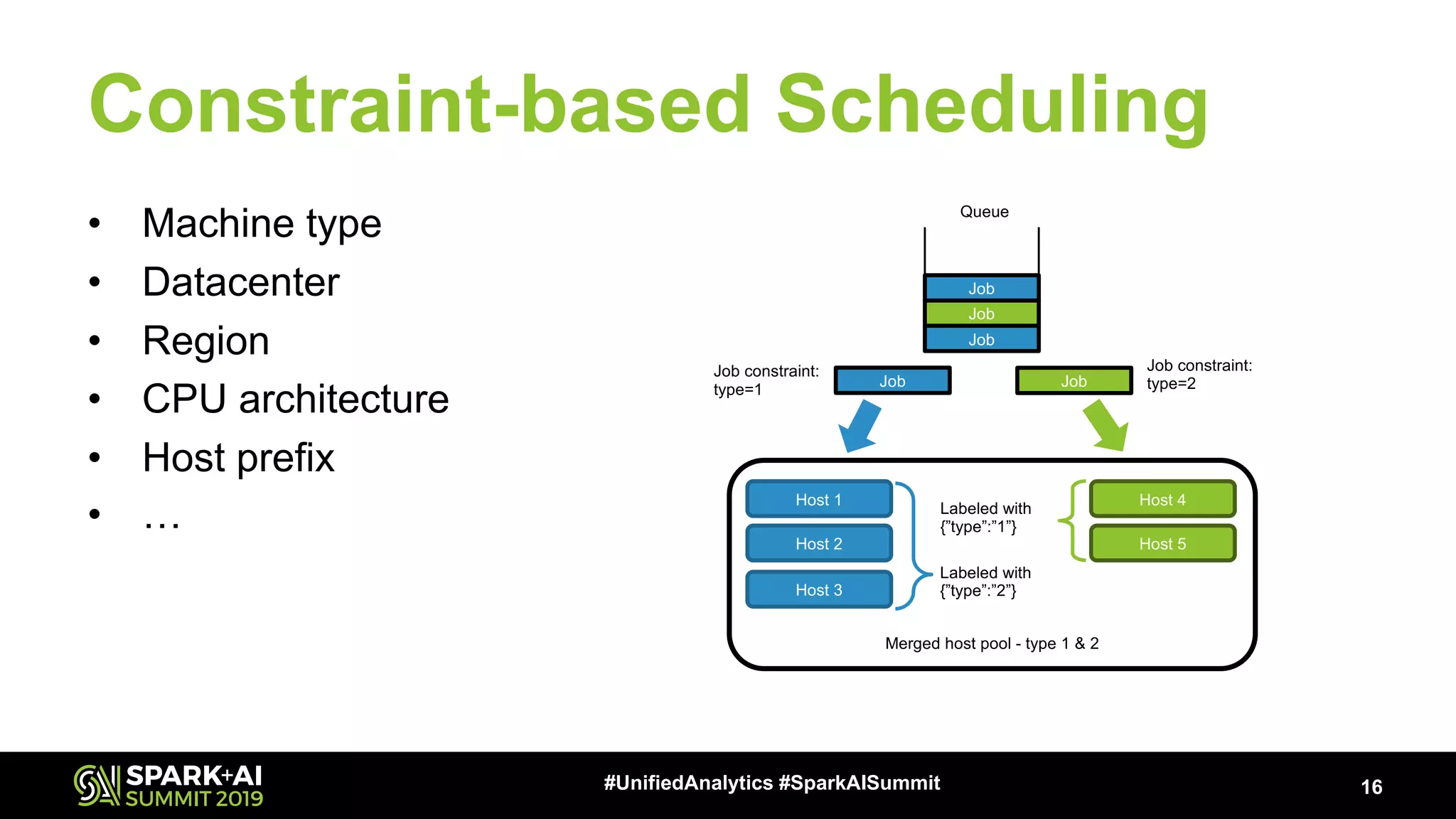
Explains job constraint-based scheduling parameters to enhance resource management across varying environments.
Overview of preemption strategies to ensure resource availability and minimize impact on scheduled jobs.
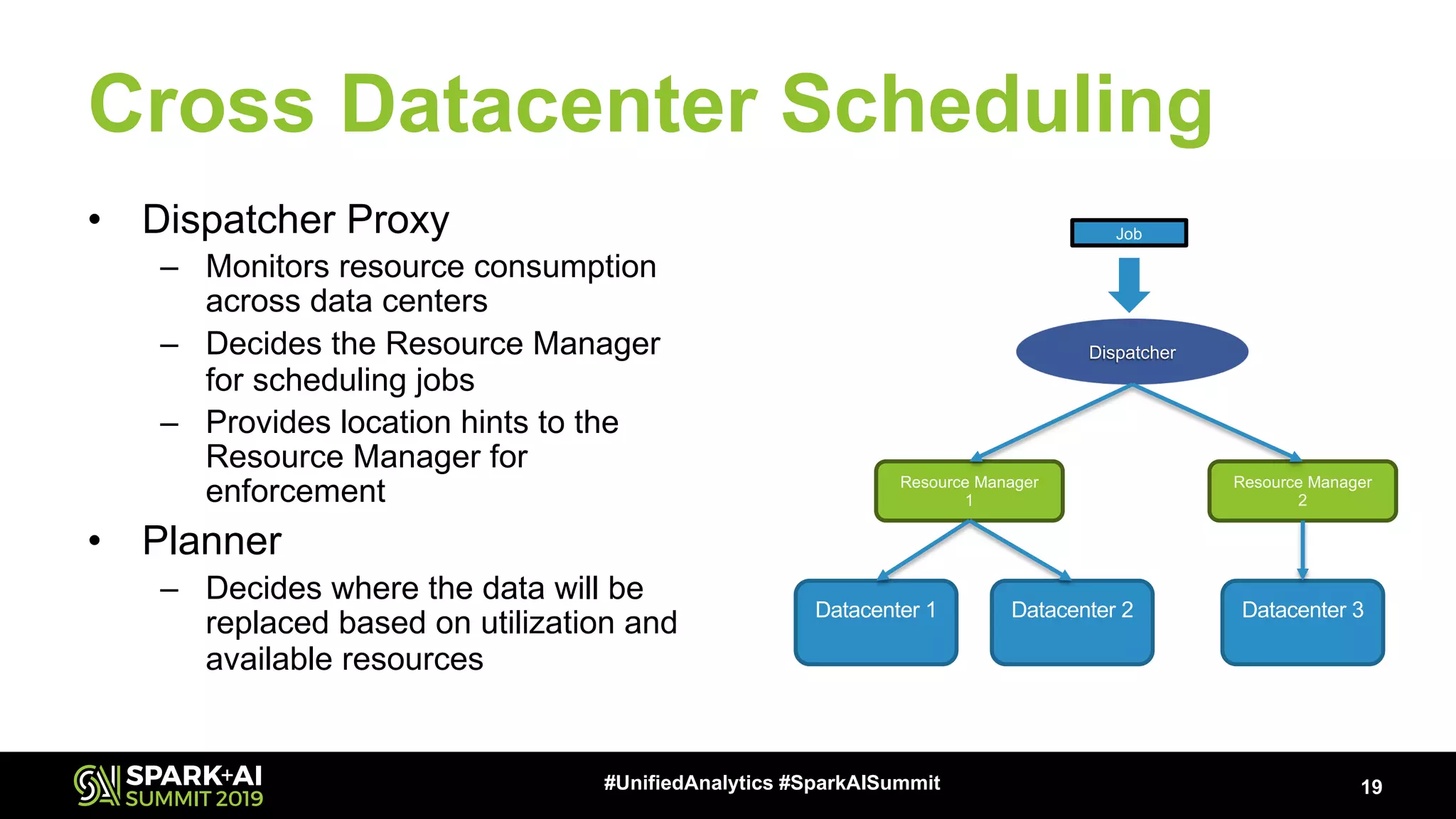
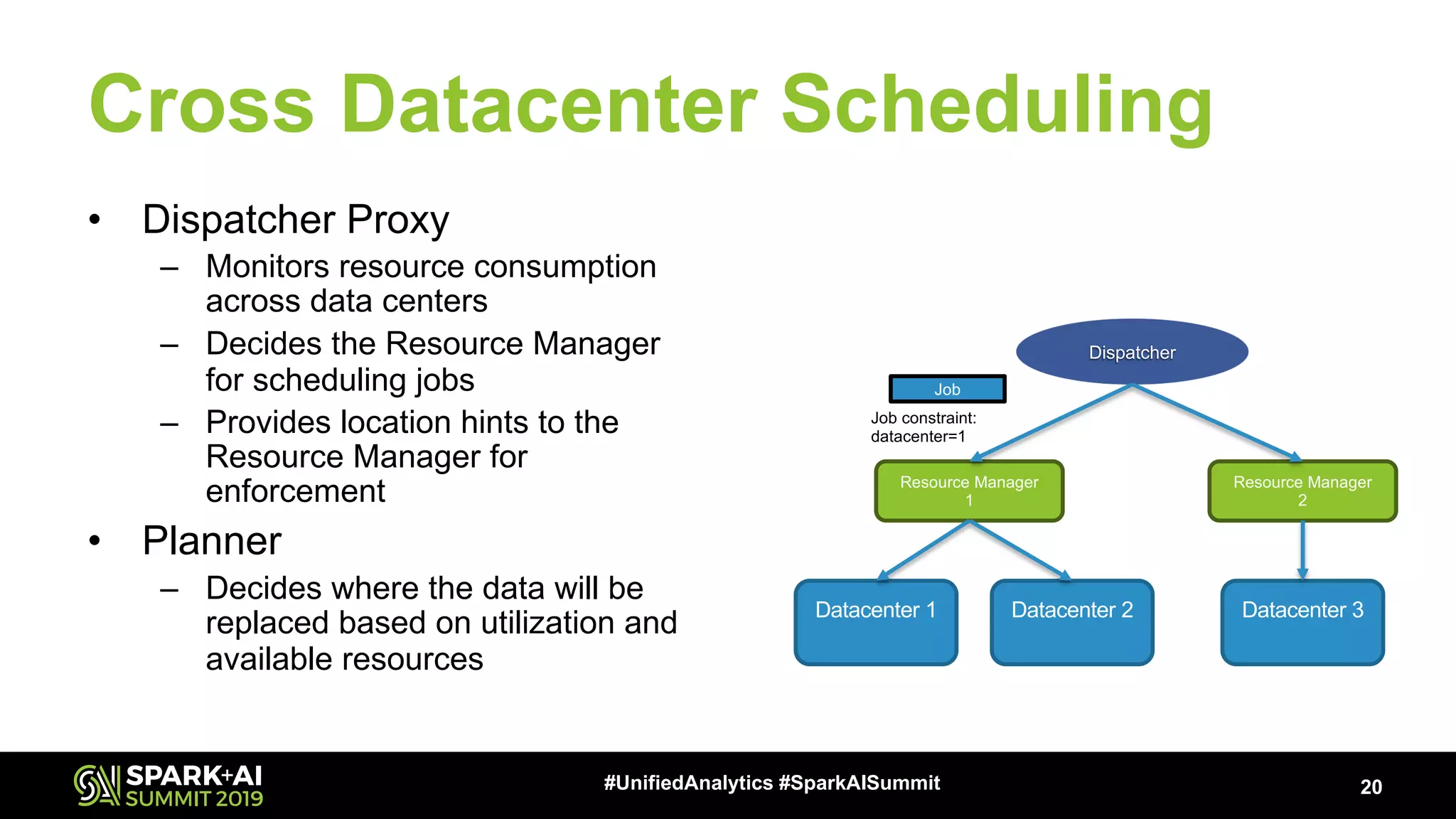
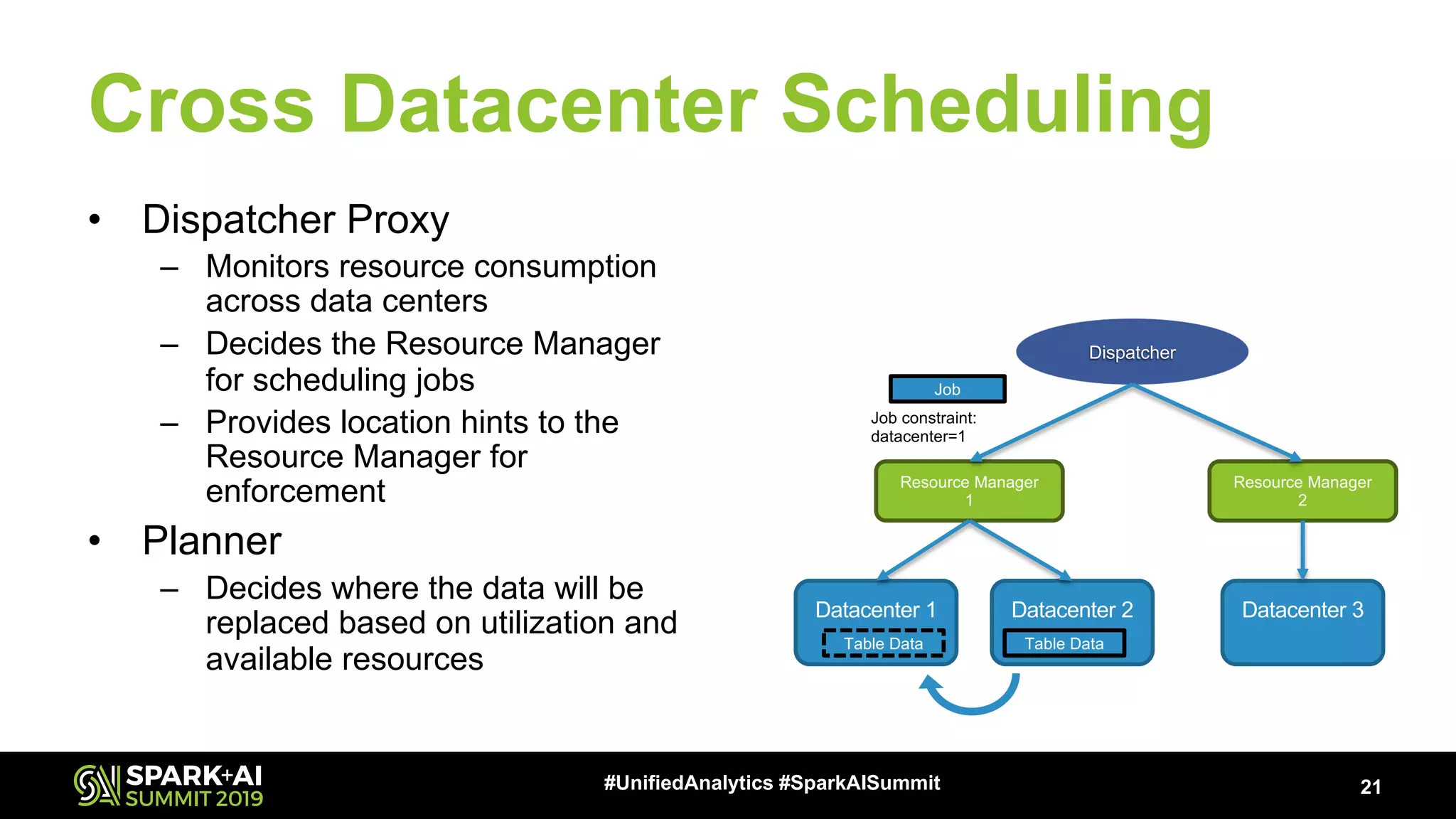
Explains the requirements and strategies for effective scheduling across multiple data centers to optimize resource use.
Proposes future enhancements for the Tangram scheduling framework and invites potential collaborators for hiring.
Encourages participants to rate and review the session offerings at the Spark + AI Summit.