Download as PDF, PPTX












![Getting Started with Scrapy $ pip install scrapy $ cat > myspider.py <<EOF import scrapy class BlogSpider(scrapy.Spider): name = 'blogspider' start_urls = ['http://blog.scrapinghub.com'] def parse(self, response): for url in response.css('ul li a::attr("href")').re(r'.*/dddd/dd/$'): yield scrapy.Request(response.urljoin(url), self.parse_titles) def parse_titles(self, response): for post_title in response.css('div.entries > ul > li a::text').extract(): yield {'title': post_title} EOF $ scrapy runspider myspider.py http://scrapy.org/Requirements: Python 2.7, libxml2 and libxslt](https://image.slidesharecdn.com/webscrapinginpythonwithscrapy-150908111619-lva1-app6892/75/Web-Scraping-in-Python-with-Scrapy-14-2048.jpg)


![Generate a Spider $ cd sushibot $ scrapy genspider sushi api.flickr.com $ cat sushibot/spiders/sushi.py # -*- coding: utf-8 -*- import scrapy class SushiSpider(scrapy.Spider): name = "sushi" allowed_domains = ["api.flickr.com"] start_urls = ( 'http://www.api.flickr.com/', ) def parse(self, response): pass](https://image.slidesharecdn.com/webscrapinginpythonwithscrapy-150908111619-lva1-app6892/75/Web-Scraping-in-Python-with-Scrapy-17-2048.jpg)

![Construct Photo's URL <photo id="4794344495" owner="38553162@N00" secret="d907790937" server="4093" farm="5" title="Sushi!" ispublic="1" isfriend="0" isfamily="0" /> https://farm{farm-id}.staticflickr.com/{server-id}/{id}_{secret} _[mstzb].jpg https://farm5.staticflickr.com/4093/4794344495_d907790937_b.jpg https://www.flickr.com/services/api/misc.urls.html Photo element: Photo's URL template: Result:](https://image.slidesharecdn.com/webscrapinginpythonwithscrapy-150908111619-lva1-app6892/75/Web-Scraping-in-Python-with-Scrapy-19-2048.jpg)
![spider/sushi.py (Modified) # -*- coding: utf-8 -*- import os import scrapy from sushibot.items import SushibotItem class SushiSpider(scrapy.Spider): name = "sushi" allowed_domains = ["api.flickr.com", "staticflickr.com"] start_urls = ( 'https://api.flickr.com/services/rest/?method=flickr.photos.search&api_key=' + os.environ['FLICKR_KEY'] + '&text=sushi&sort=relevance', ) def parse(self, response): for photo in response.css('photo'): yield scrapy.Request(photo_url(photo), self.handle_image) def handle_image(self, response): return SushibotItem(url=response.url, body=response.body) def photo_url(photo): return 'https://farm{farm}.staticflickr.com/{server}/{id}_{secret}_{size}.jpg'.format( farm=photo.xpath('@farm').extract_first(), server=photo.xpath('@server').extract_first(), id=photo.xpath('@id').extract_first(), secret=photo.xpath('@secret').extract_first(), size='b', )](https://image.slidesharecdn.com/webscrapinginpythonwithscrapy-150908111619-lva1-app6892/75/Web-Scraping-in-Python-with-Scrapy-20-2048.jpg)
![items.py # -*- coding: utf-8 -*- from pprint import pformat import scrapy class SushibotItem(scrapy.Item): url = scrapy.Field() body = scrapy.Field() def __str__(self): return pformat({ 'url': self['url'], 'body': self['body'][:10] + '...', })](https://image.slidesharecdn.com/webscrapinginpythonwithscrapy-150908111619-lva1-app6892/75/Web-Scraping-in-Python-with-Scrapy-22-2048.jpg)
![pipelines.py # -*- coding: utf-8 -*- import os class SaveImagePipeline(object): def process_item(self, item, spider): output_dir = 'images' if not os.path.exists(output_dir): os.makedirs(output_dir) filename = item['url'].split('/')[-1] with open(os.path.join(output_dir, filename), 'wb') as f: f.write(item['body']) return item](https://image.slidesharecdn.com/webscrapinginpythonwithscrapy-150908111619-lva1-app6892/75/Web-Scraping-in-Python-with-Scrapy-23-2048.jpg)




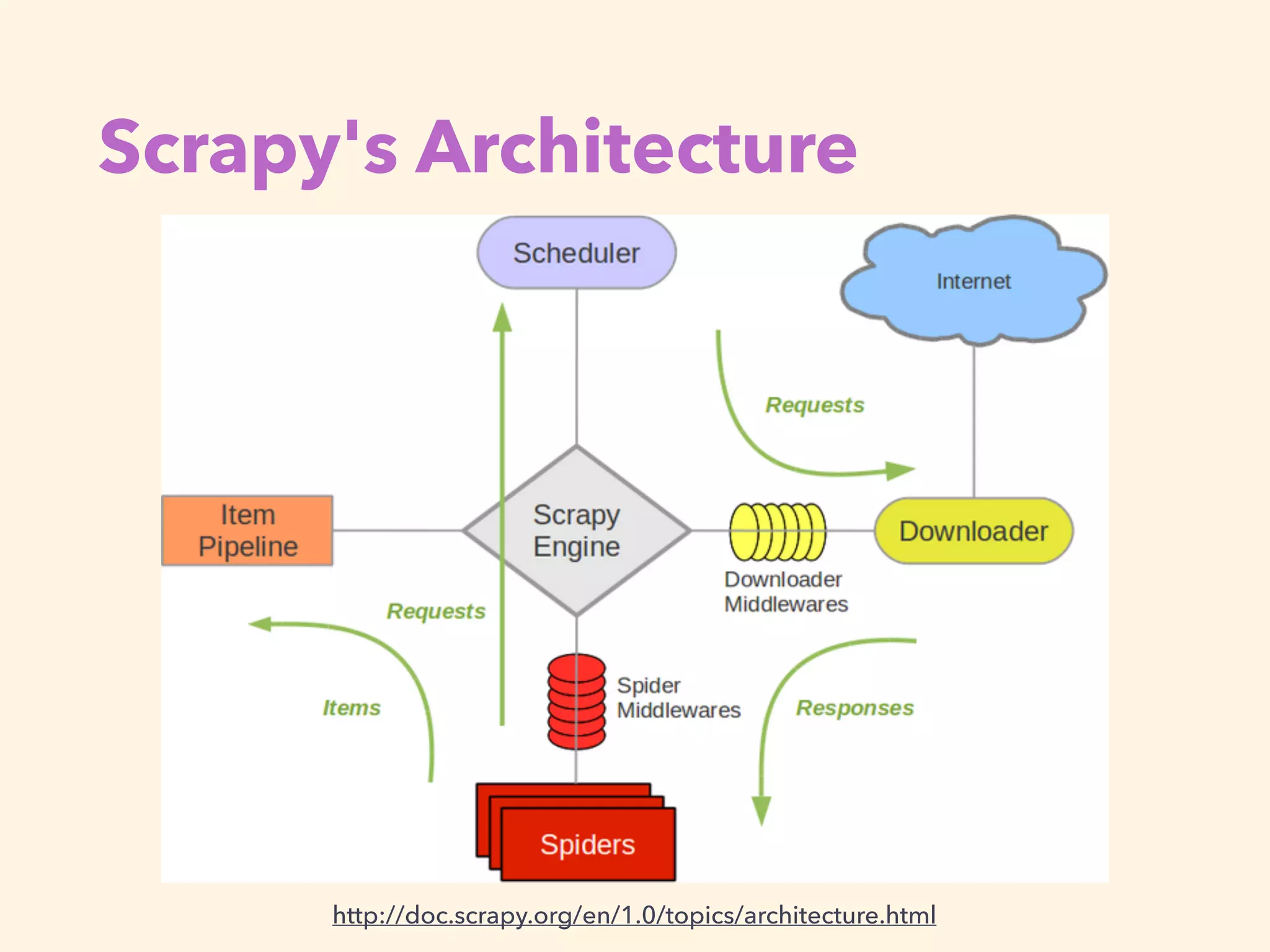
The document discusses using the Scrapy framework in Python for web scraping. It begins with an introduction to web scraping and why Python is useful for it. It then provides an overview of Scrapy, including what problems it solves and how to get started. Specific examples are shown for scraping sushi images from Flickr using Scrapy spiders, items, pipelines, and settings. The spider constructs URLs for each image from Flickr API data and yields requests to download the images via the pipeline into an images folder.