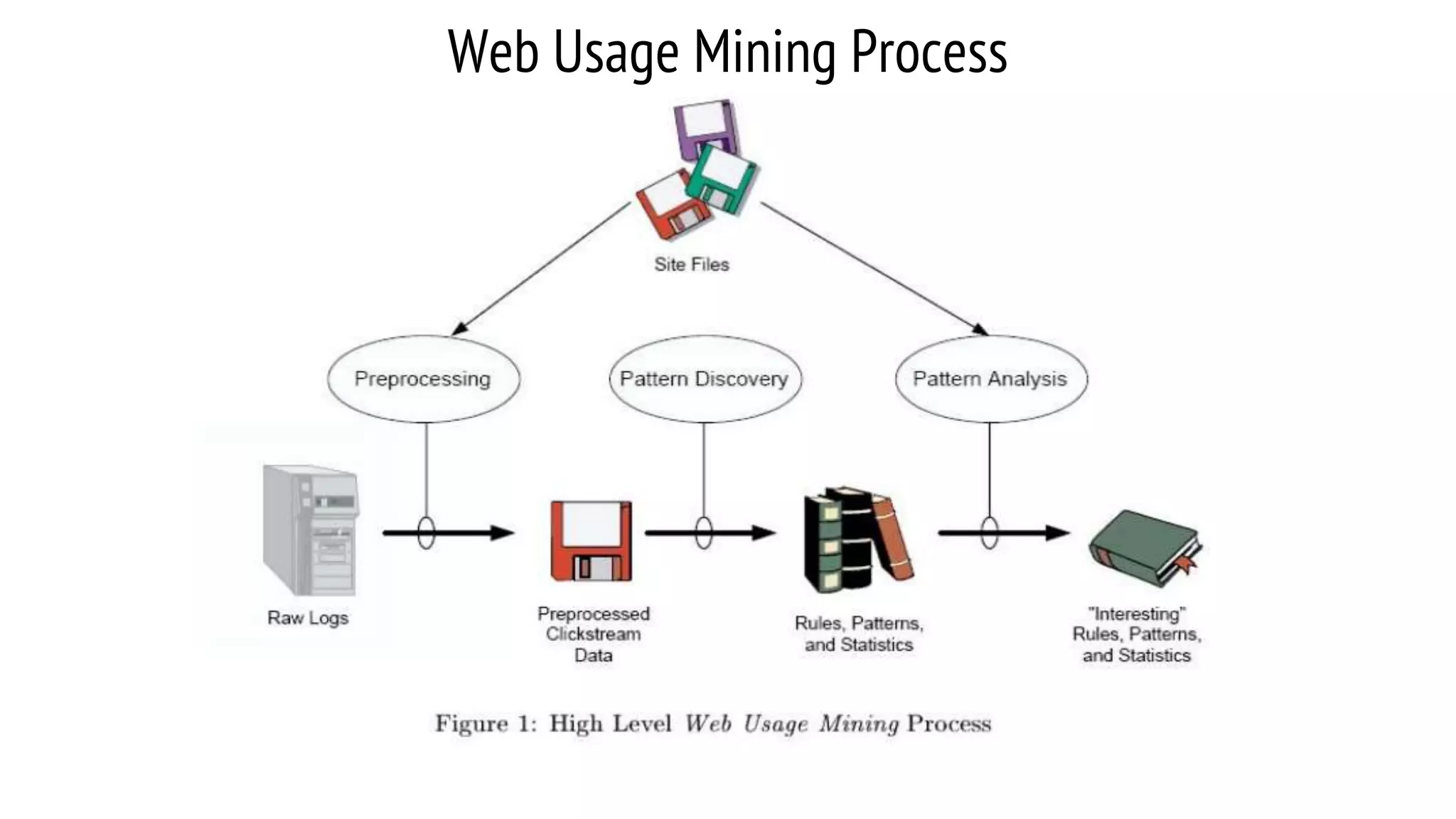
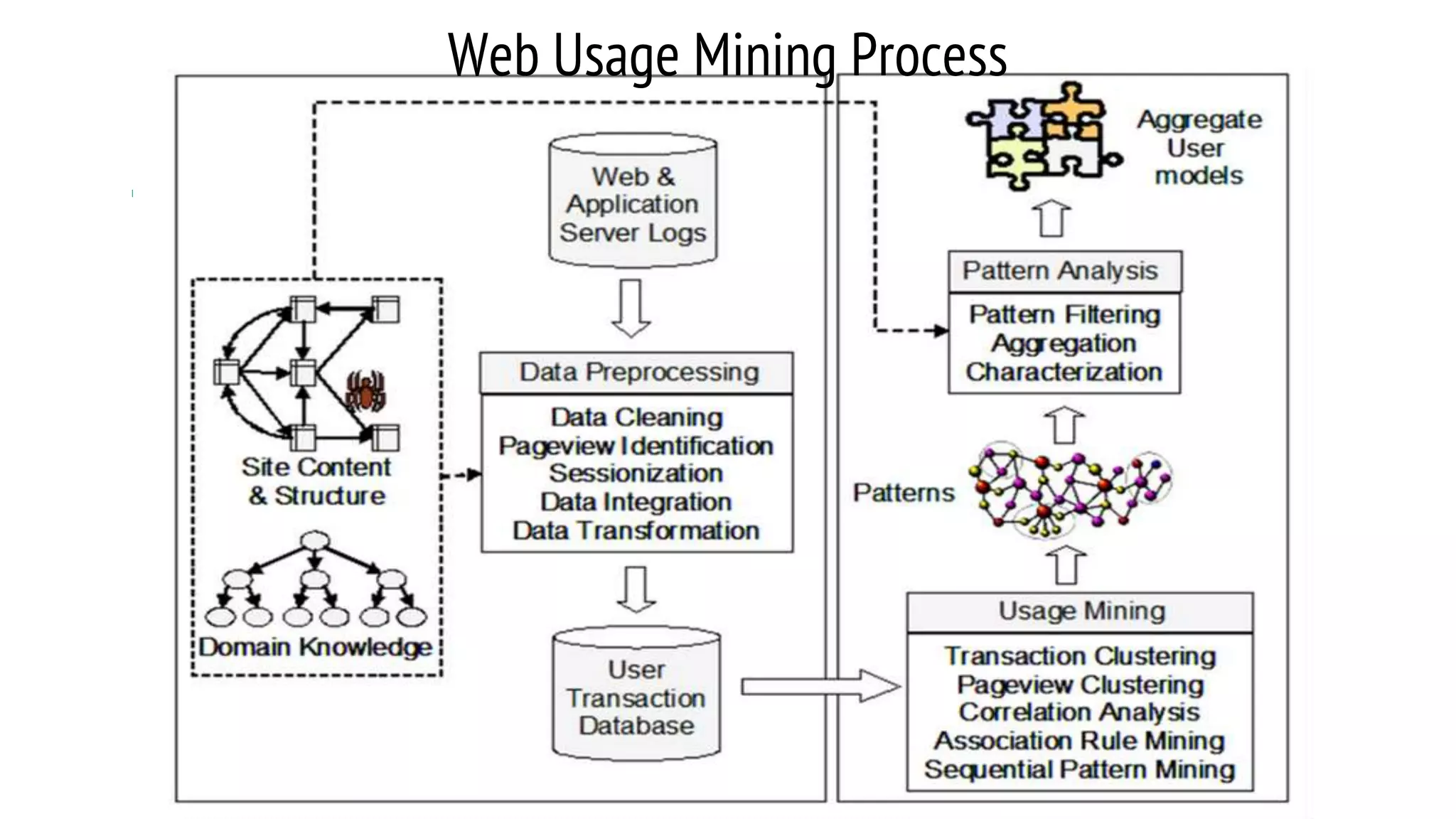
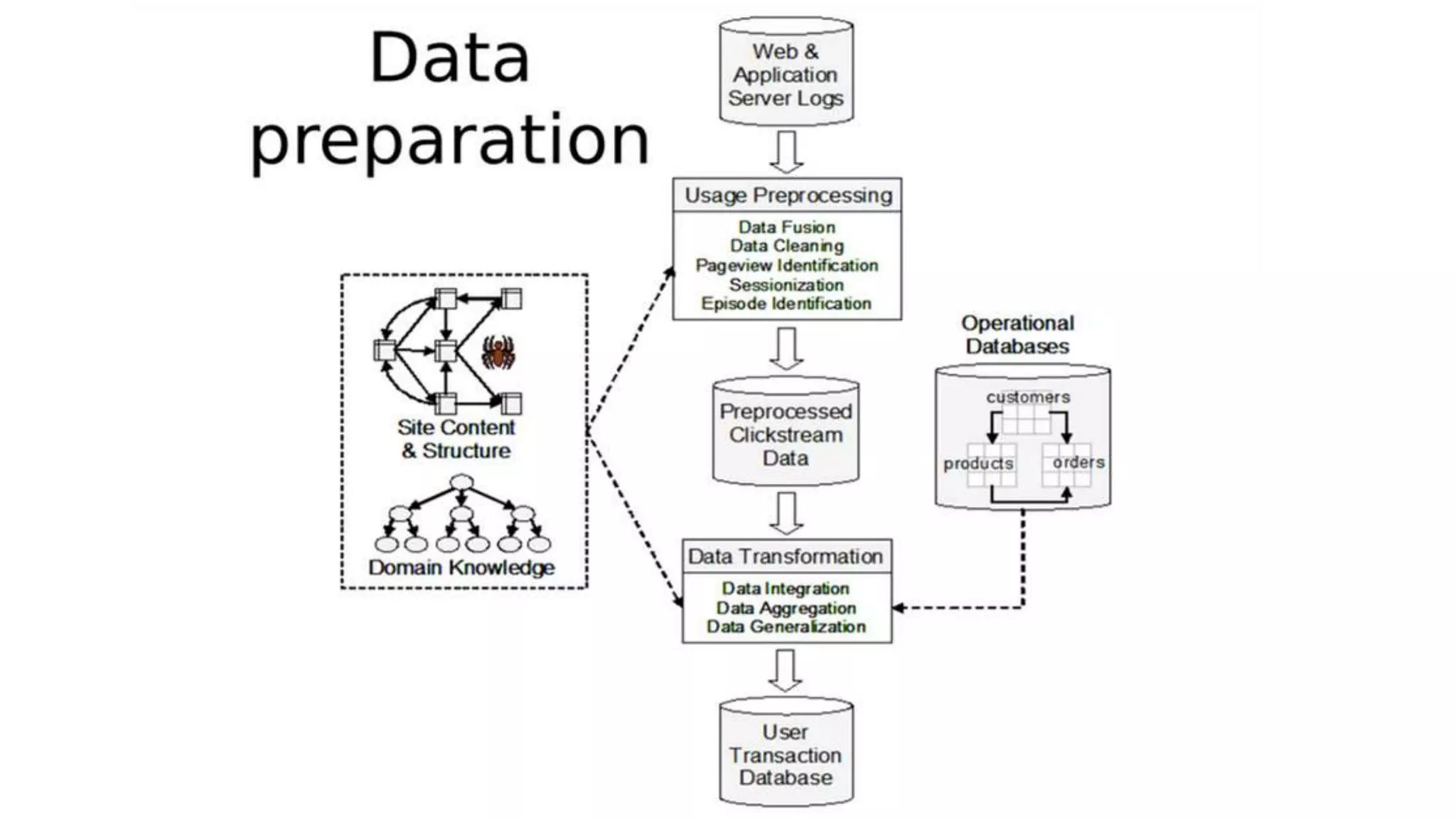
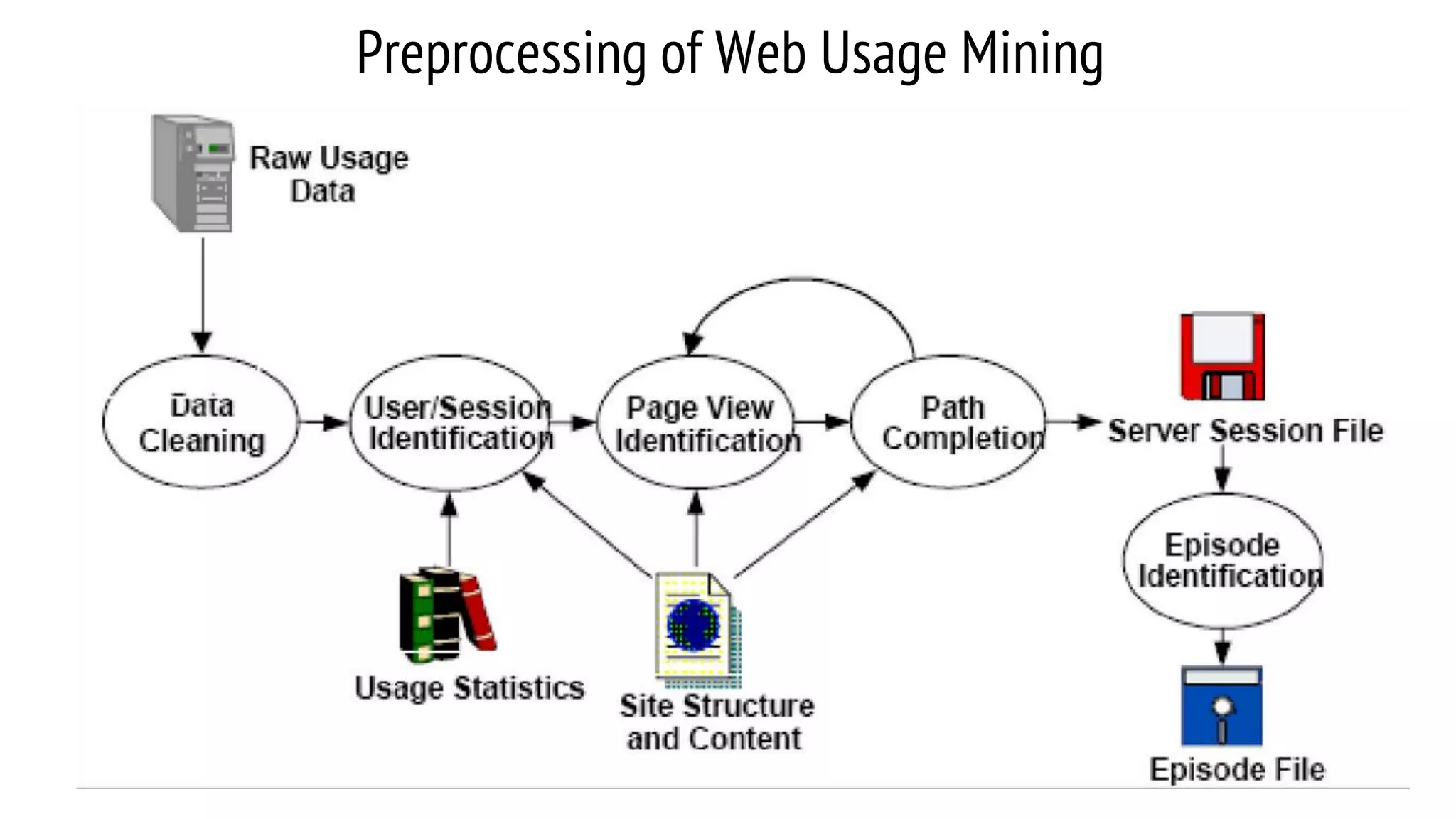
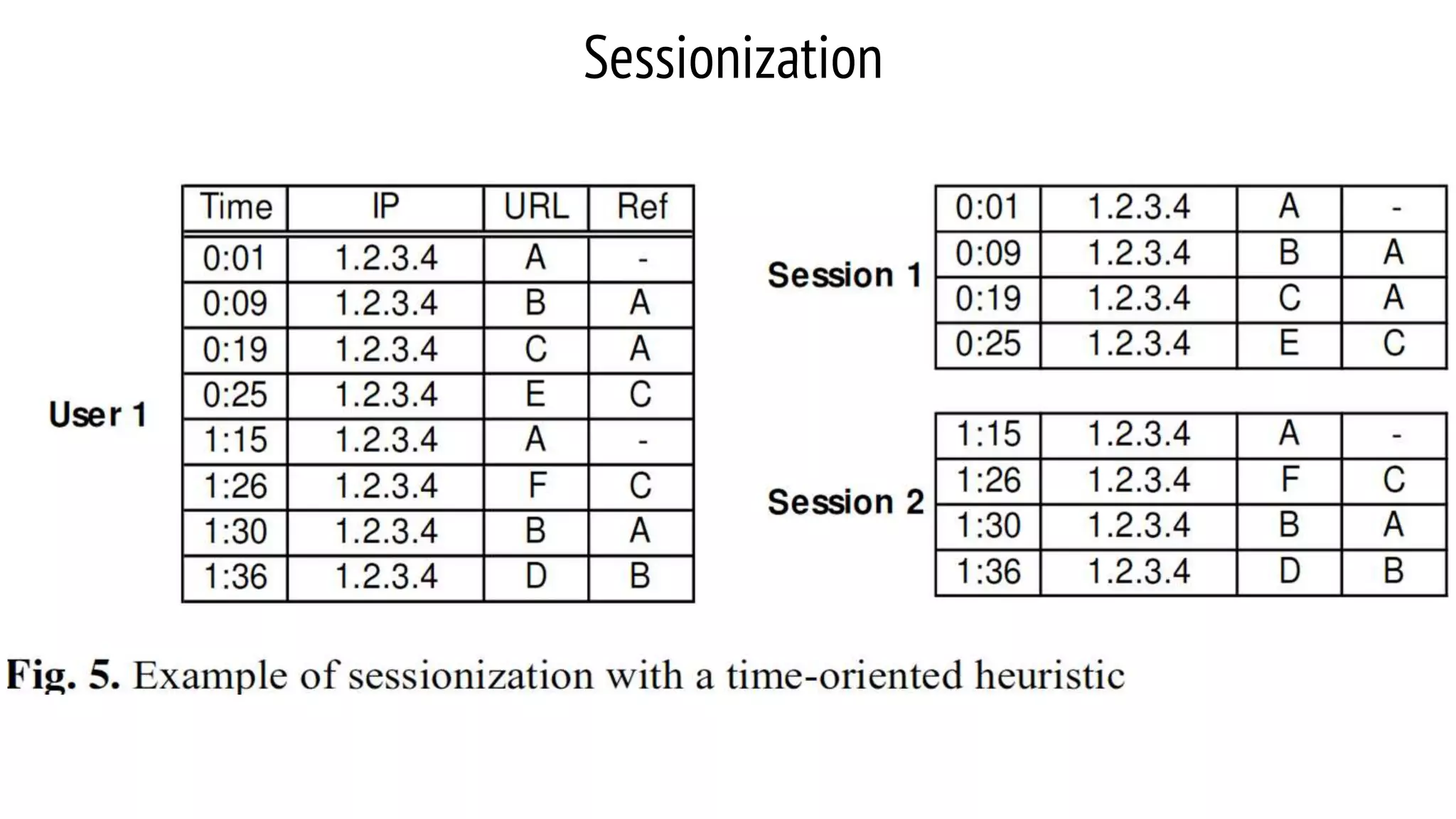
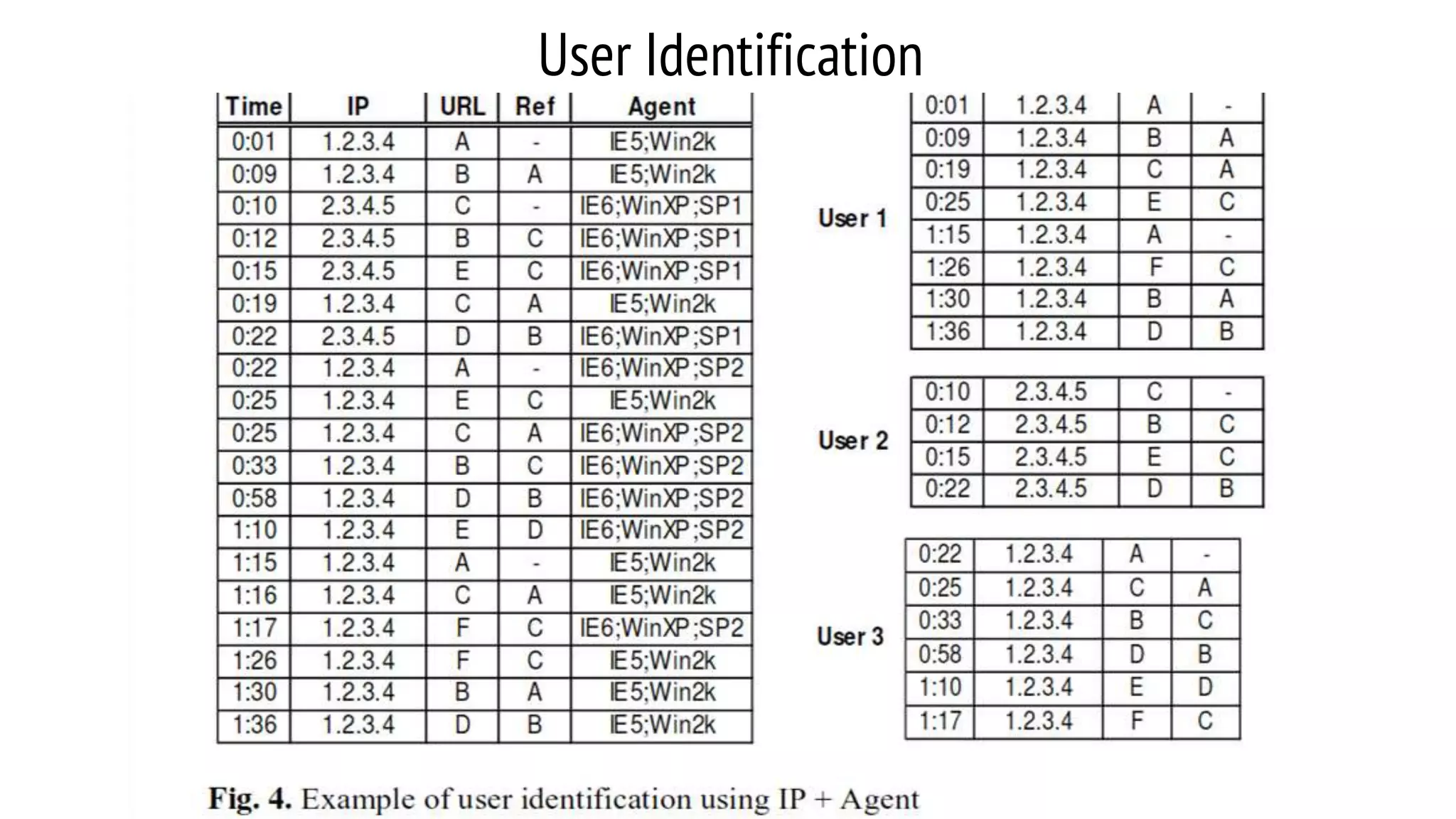
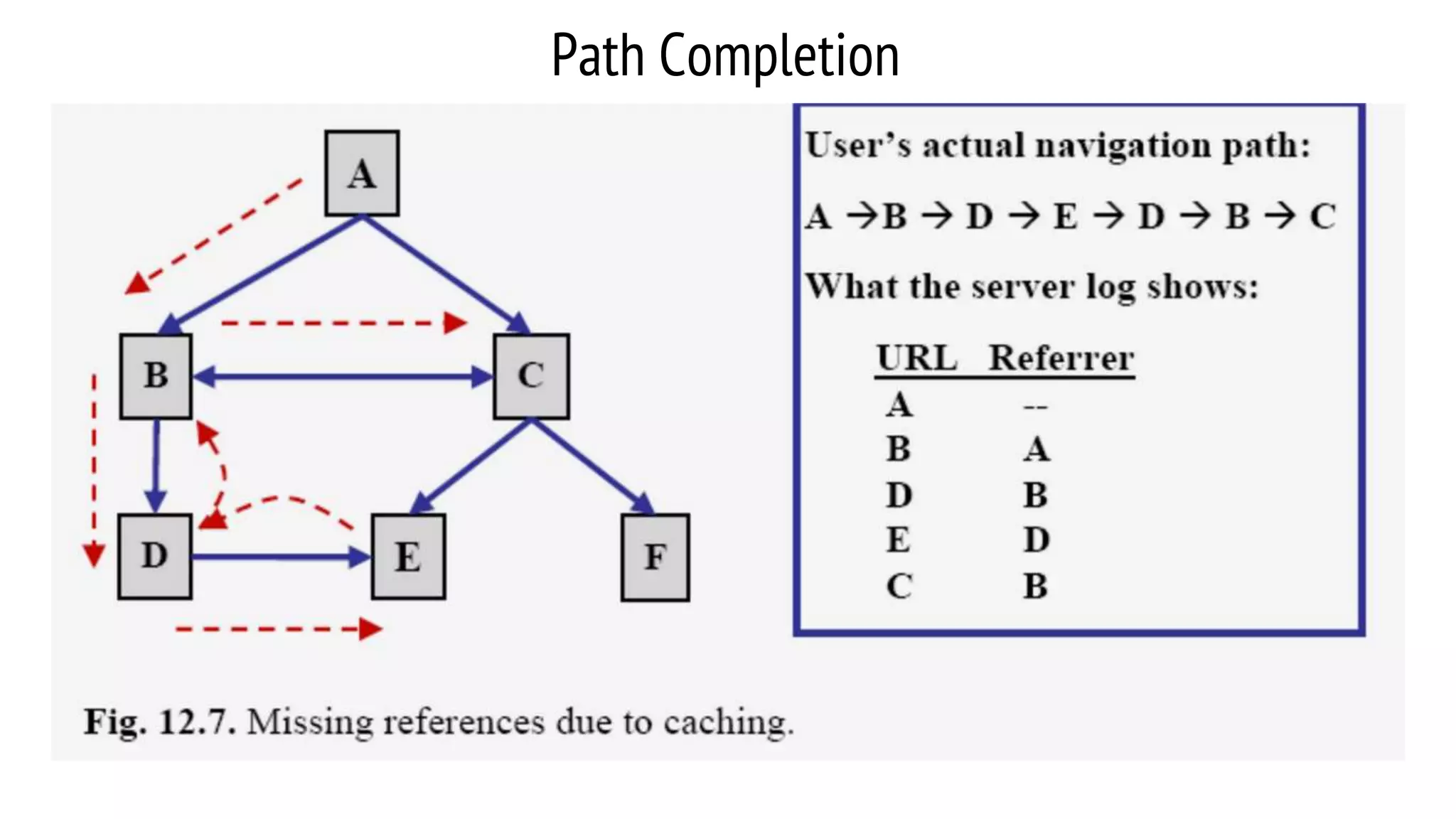
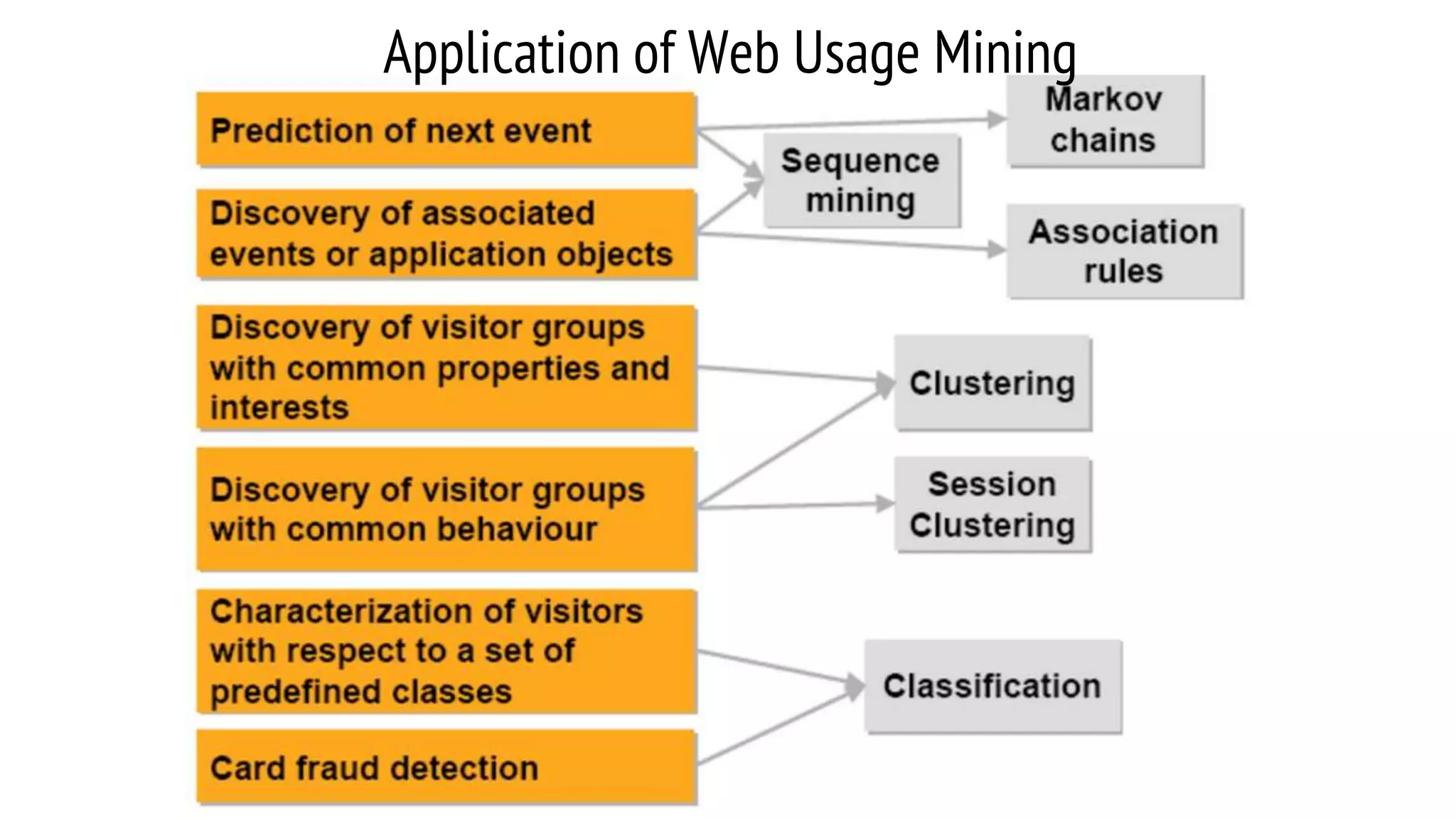
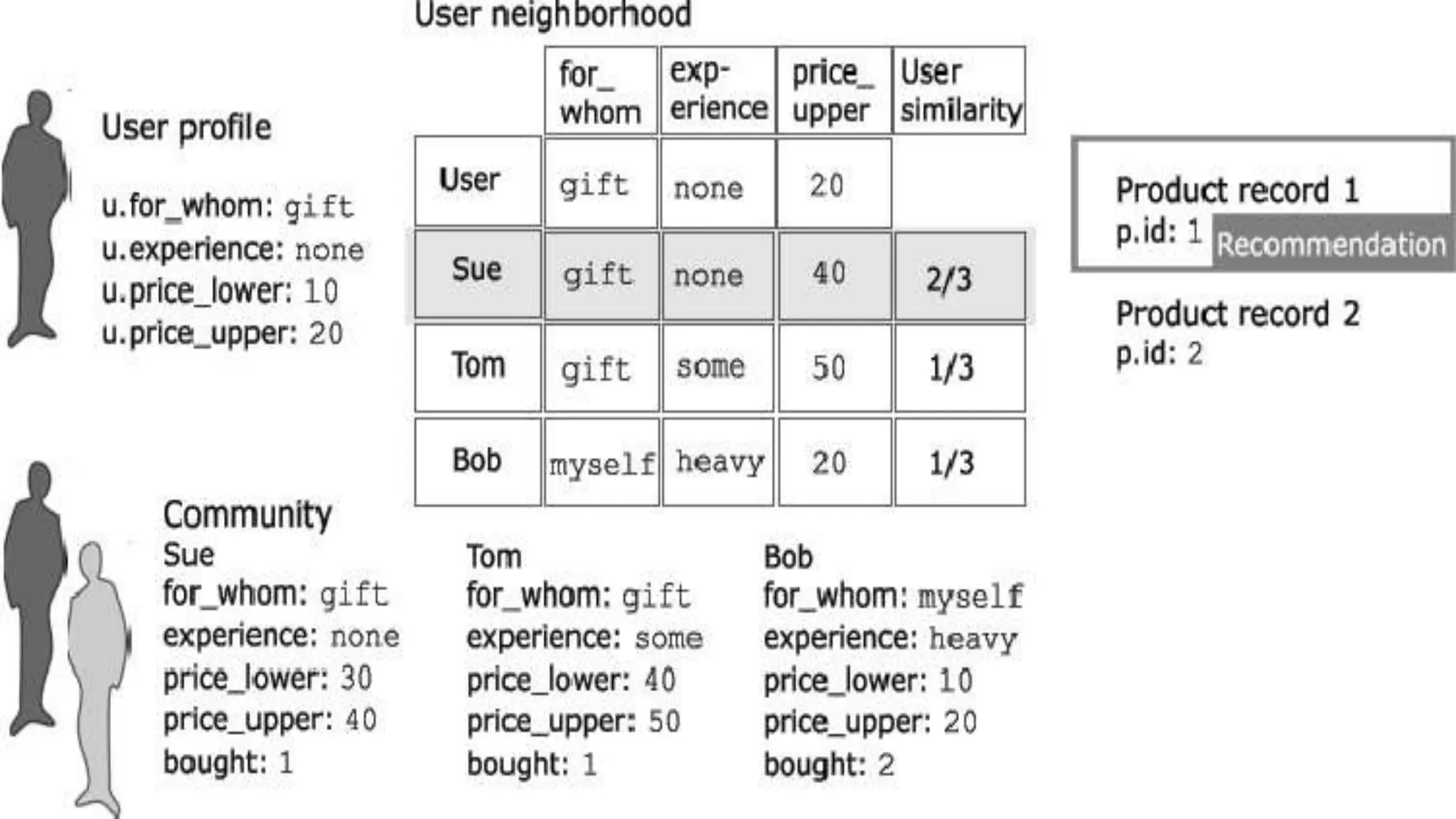
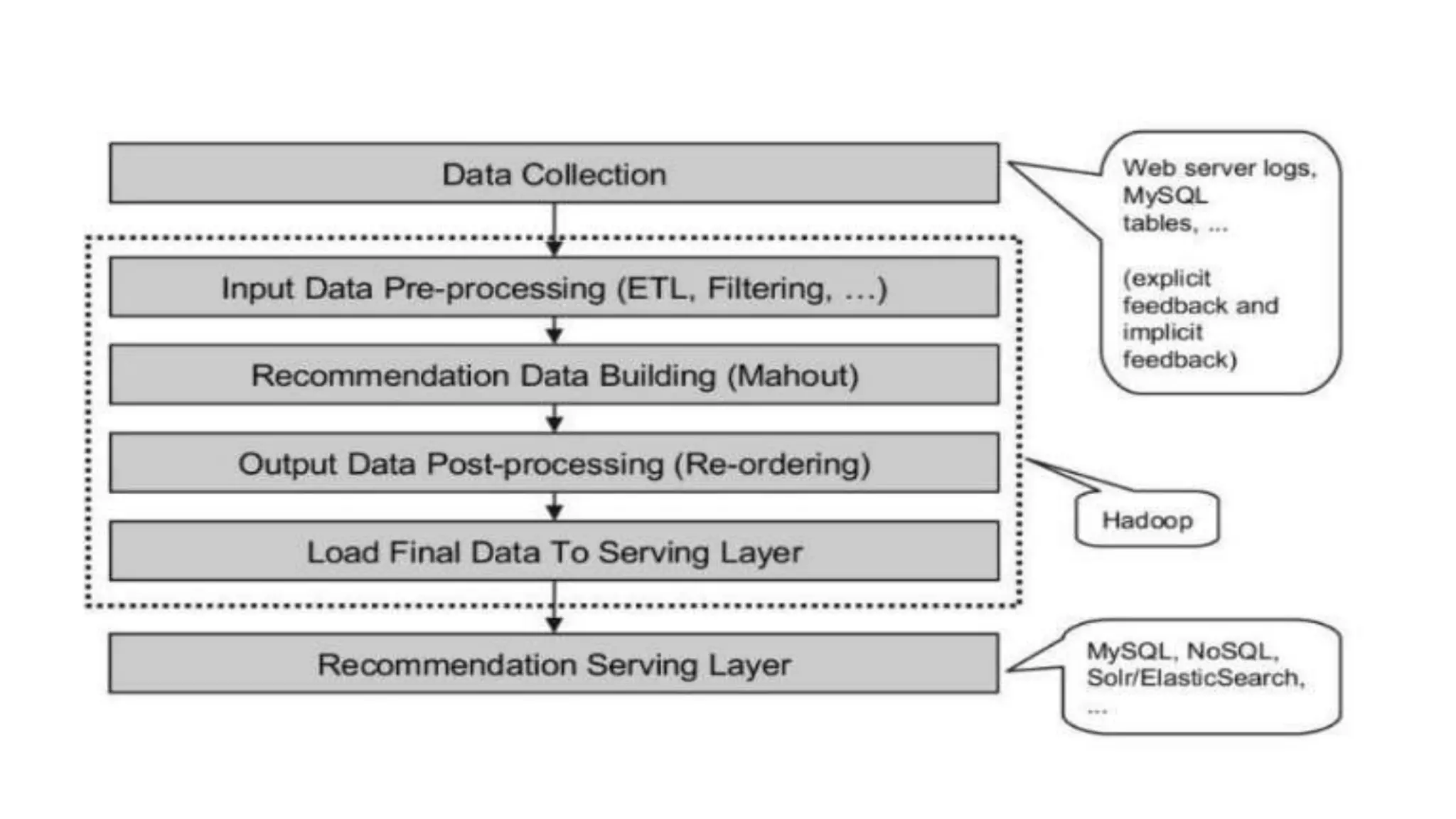
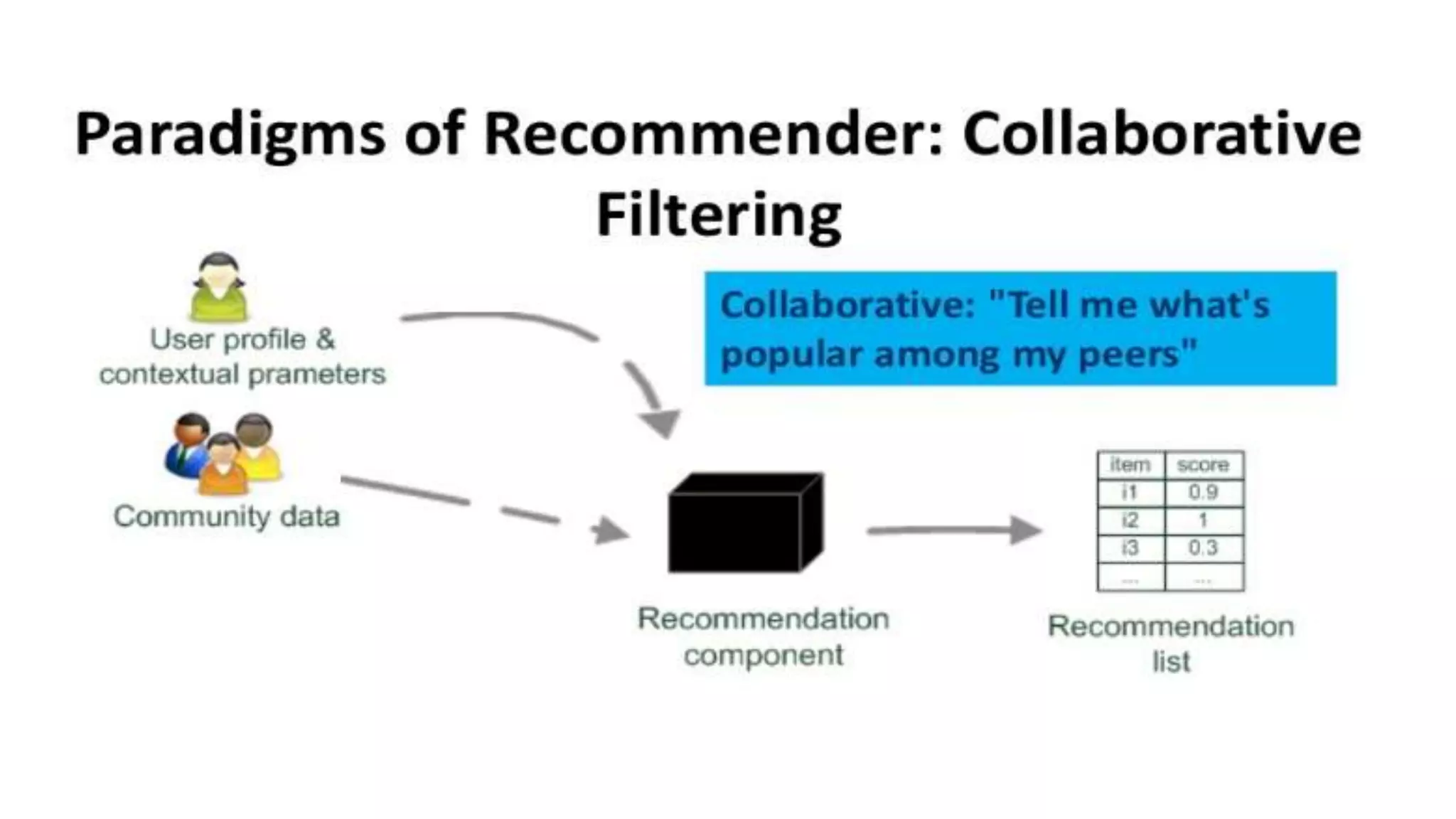
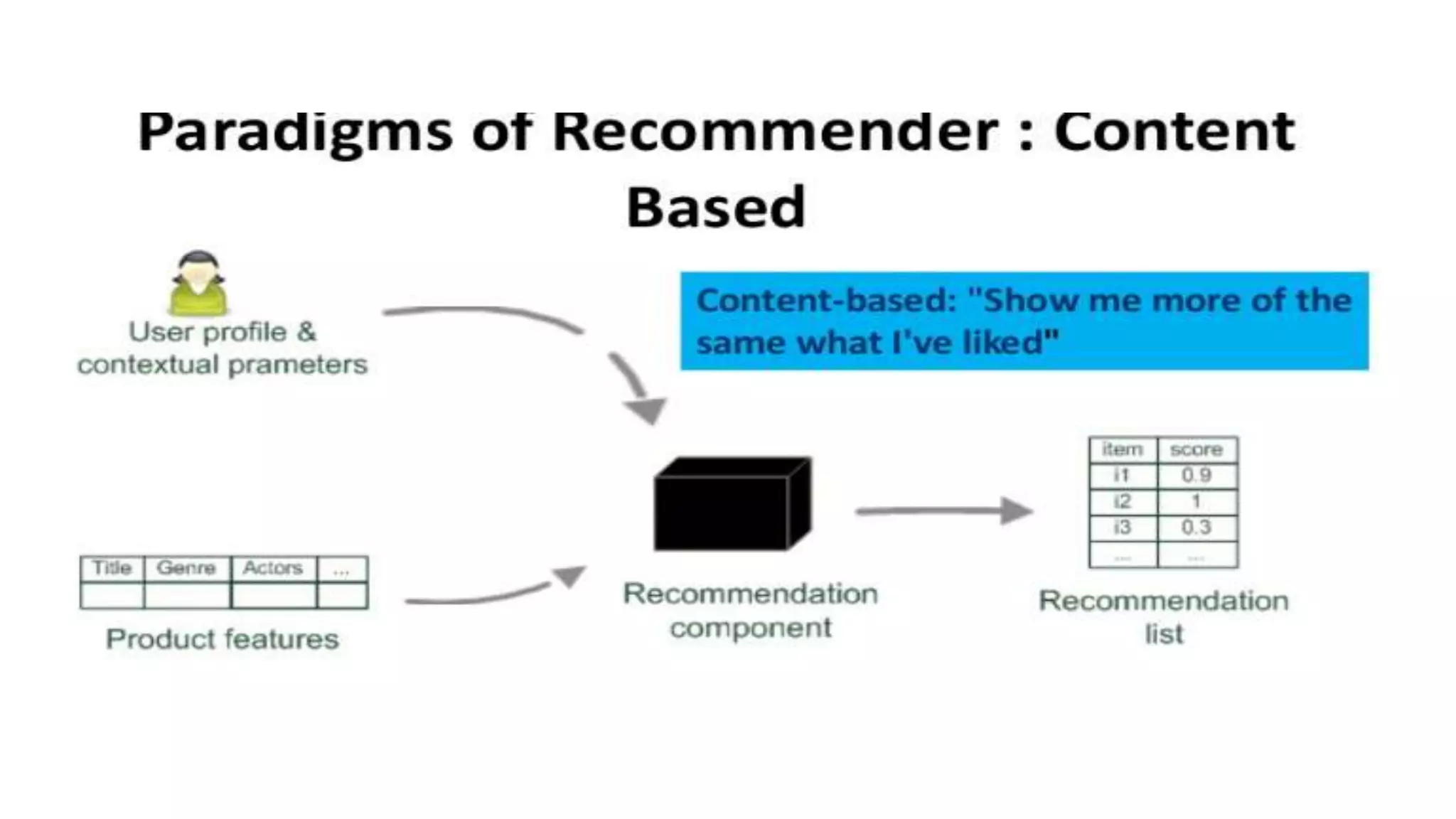
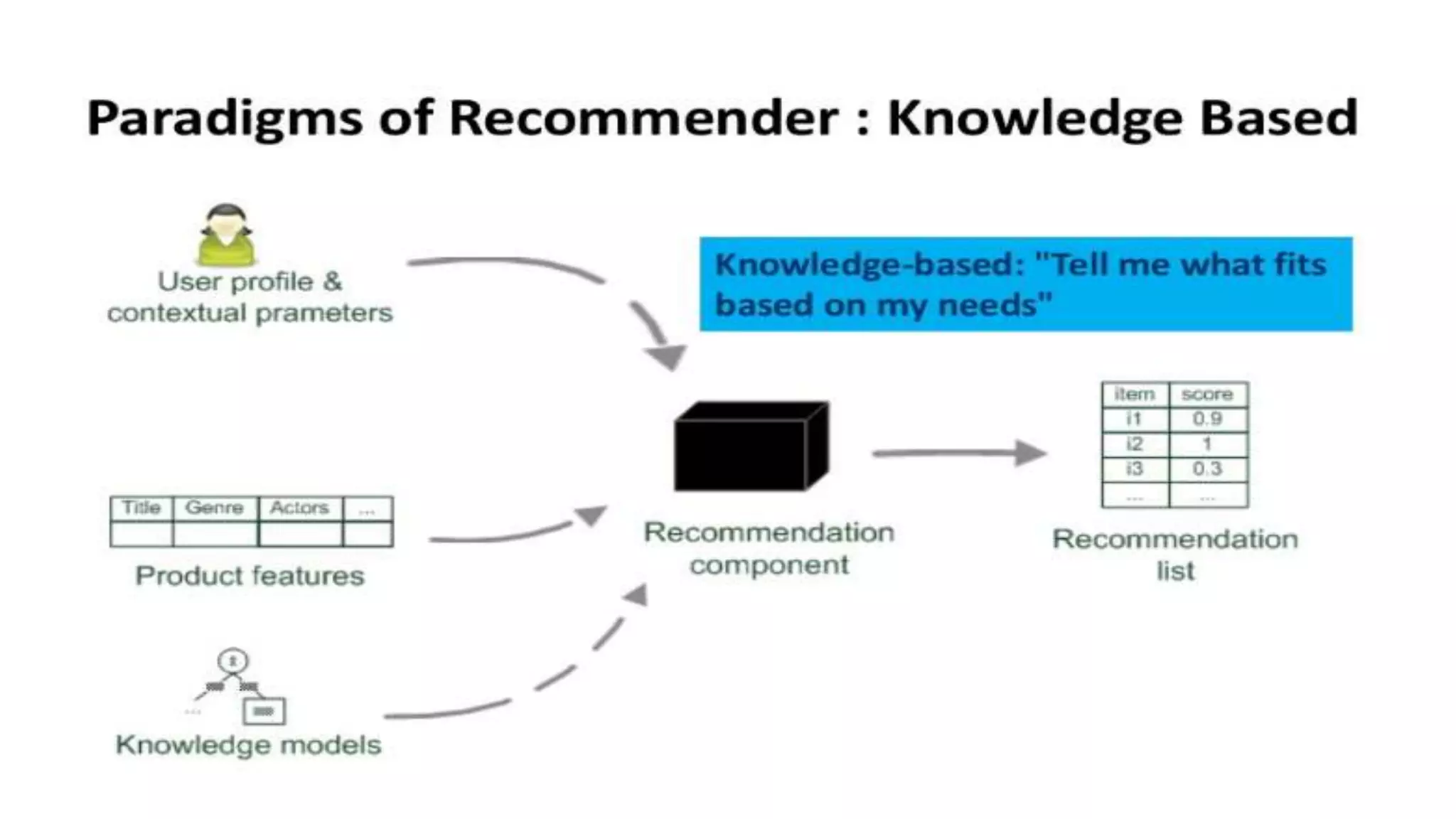
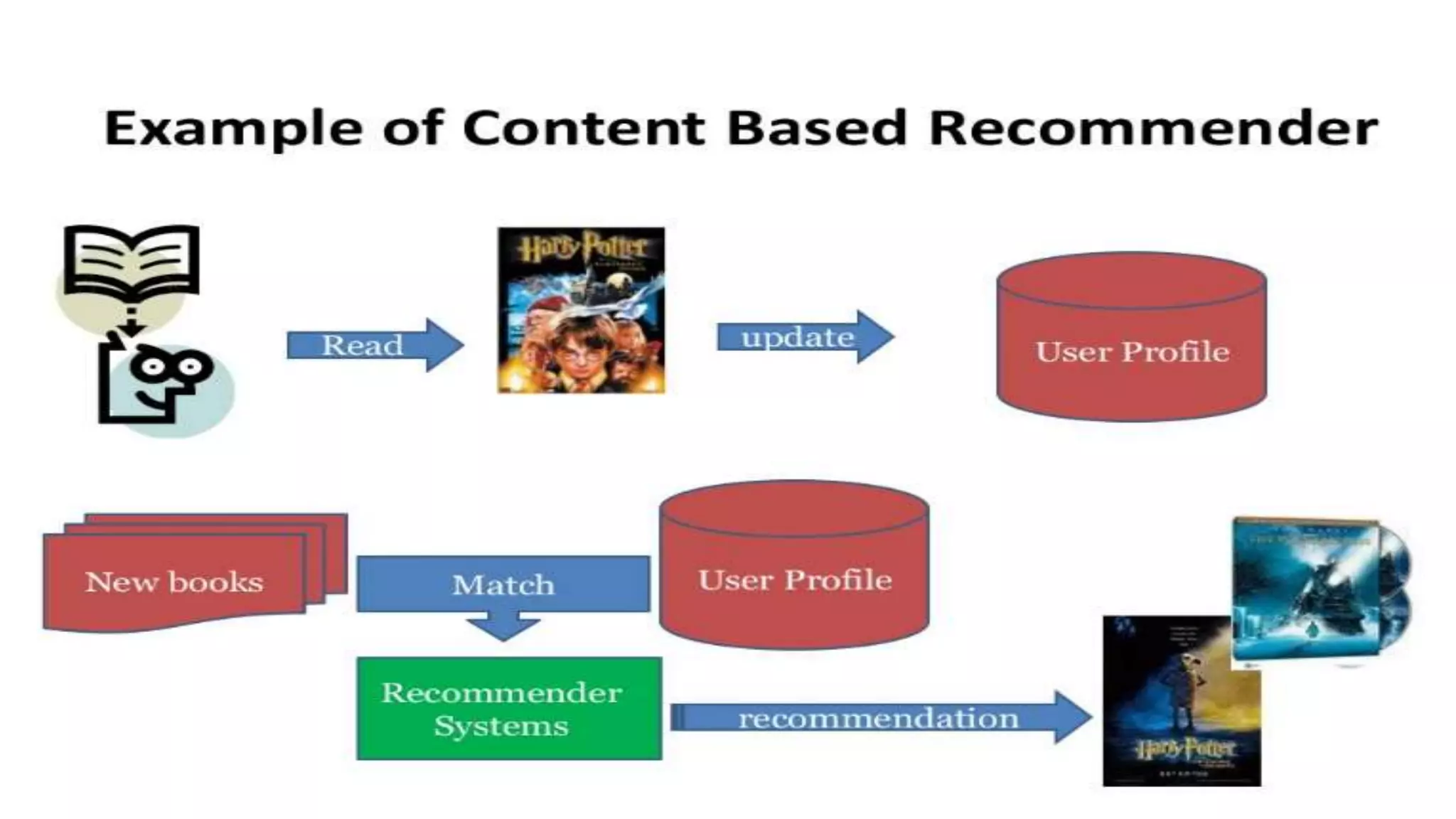
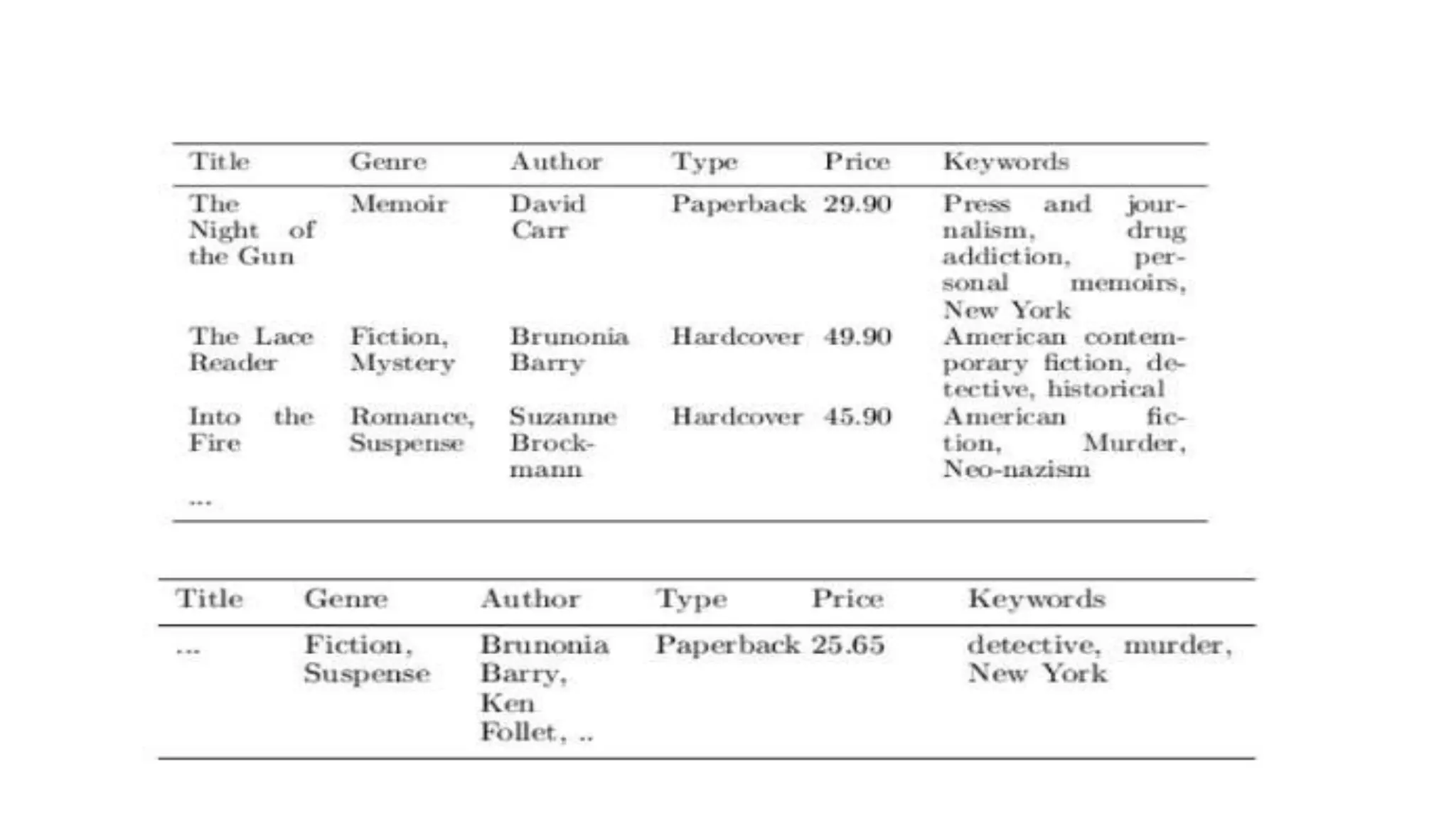
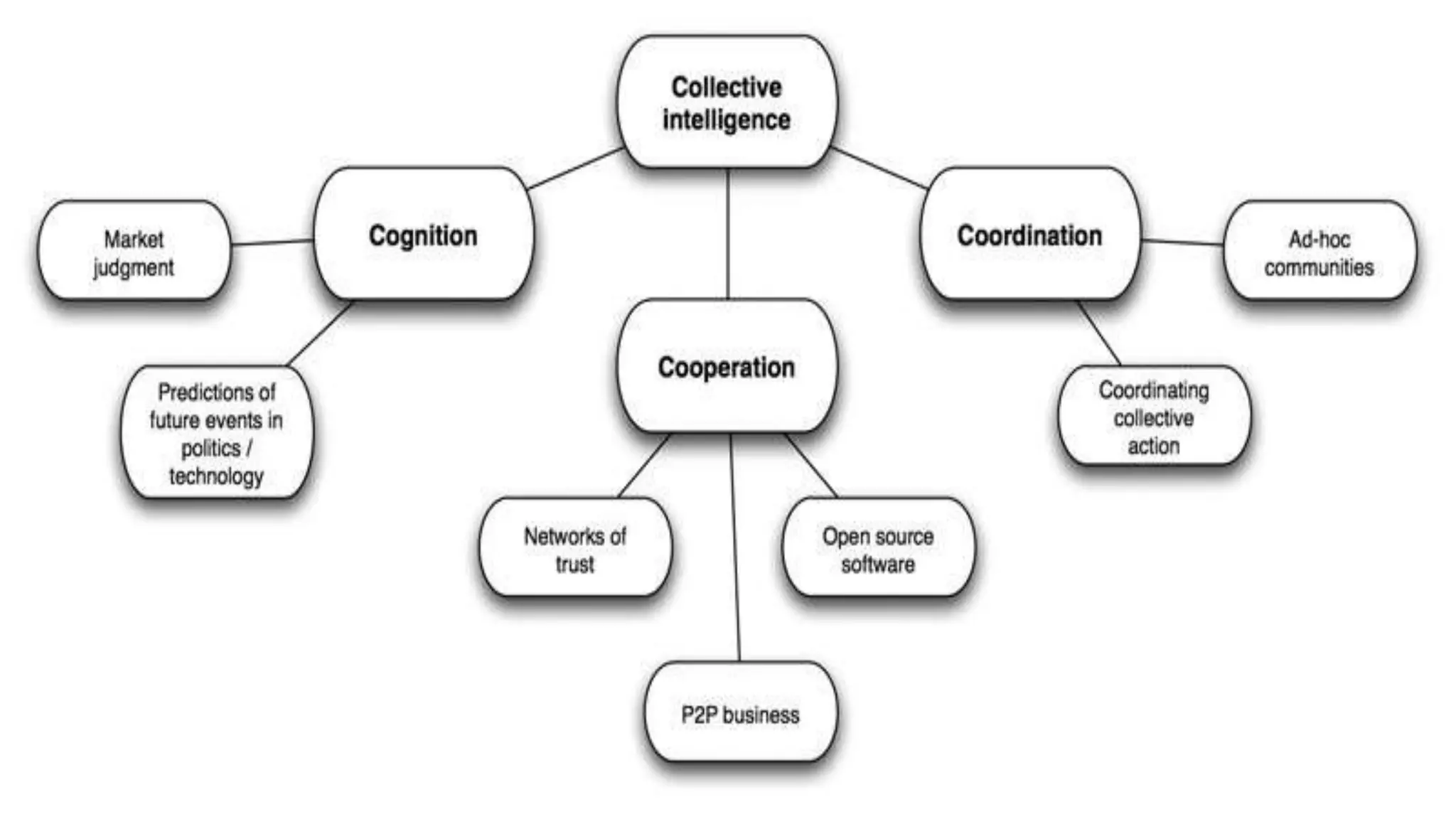
This document provides an overview of web usage mining. It discusses that web usage mining applies data mining techniques to discover usage patterns from web data. The data can be collected at the server, client, or proxy level. The goals are to analyze user behavioral patterns and profiles, and understand how to better serve web applications. The process involves preprocessing data, pattern discovery using methods like statistical analysis and clustering, and pattern analysis including filtering patterns. Web usage mining can benefit applications like personalized marketing and increasing profitability.