
Download as PDF, PPTX



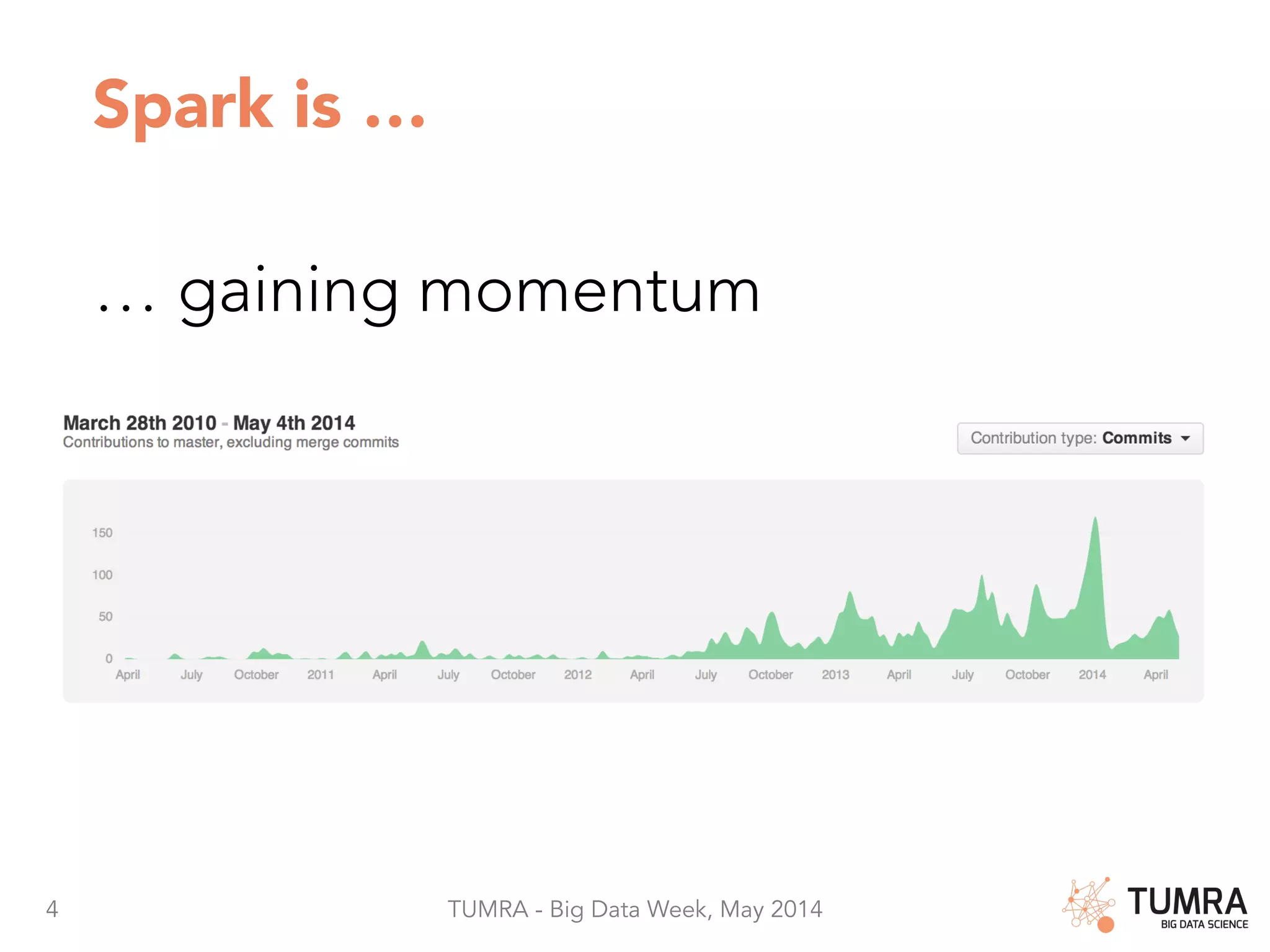
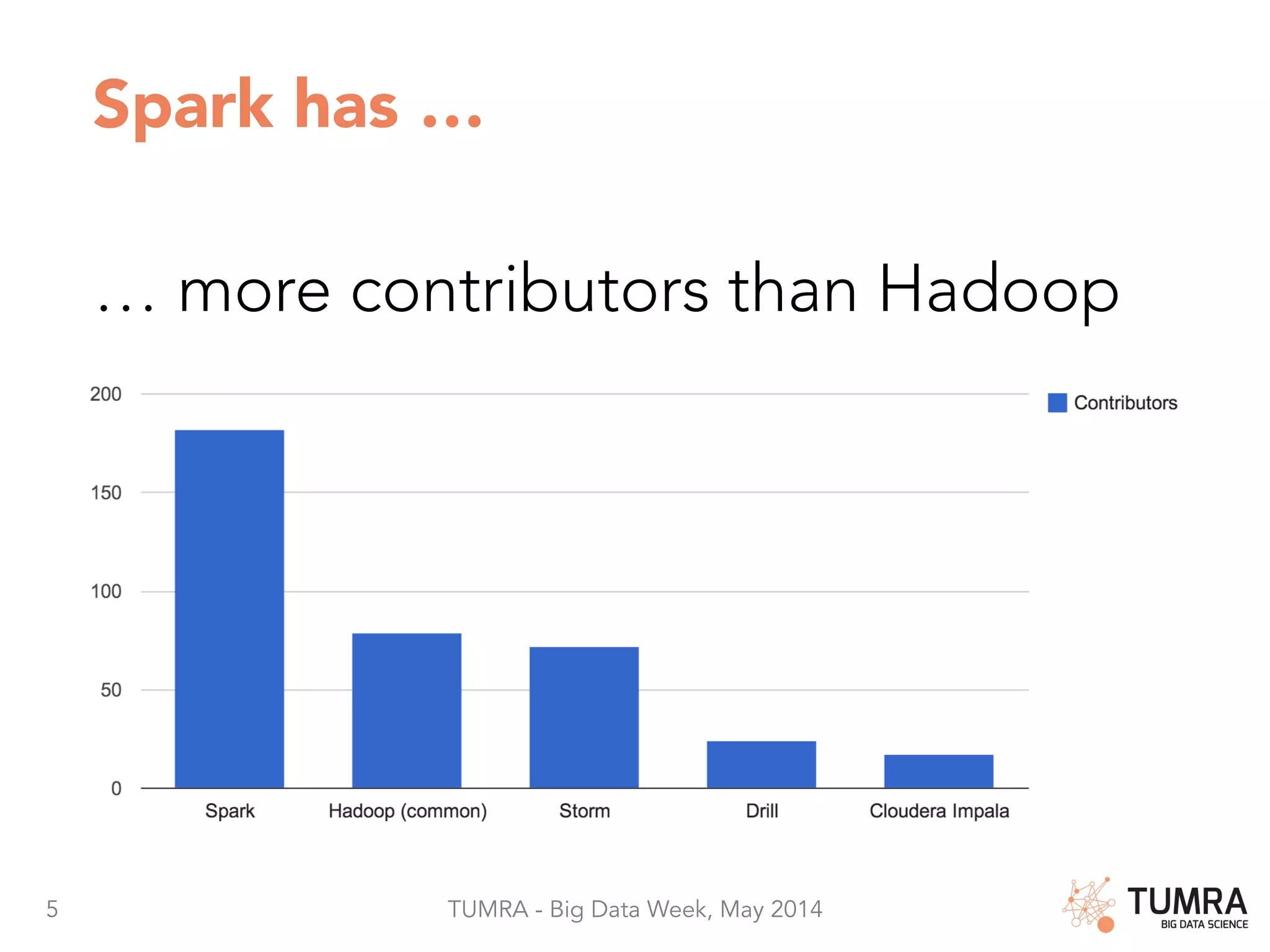

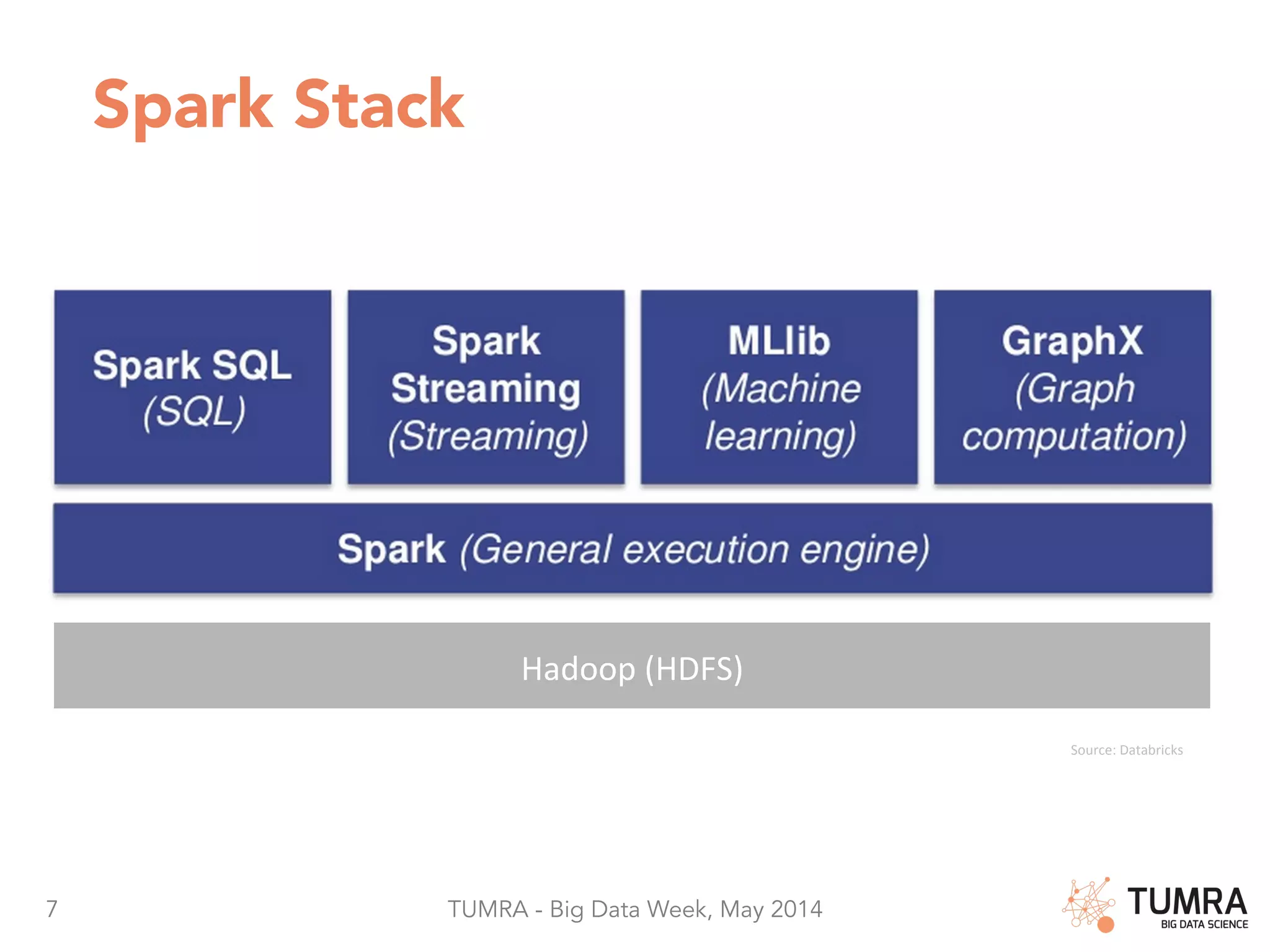







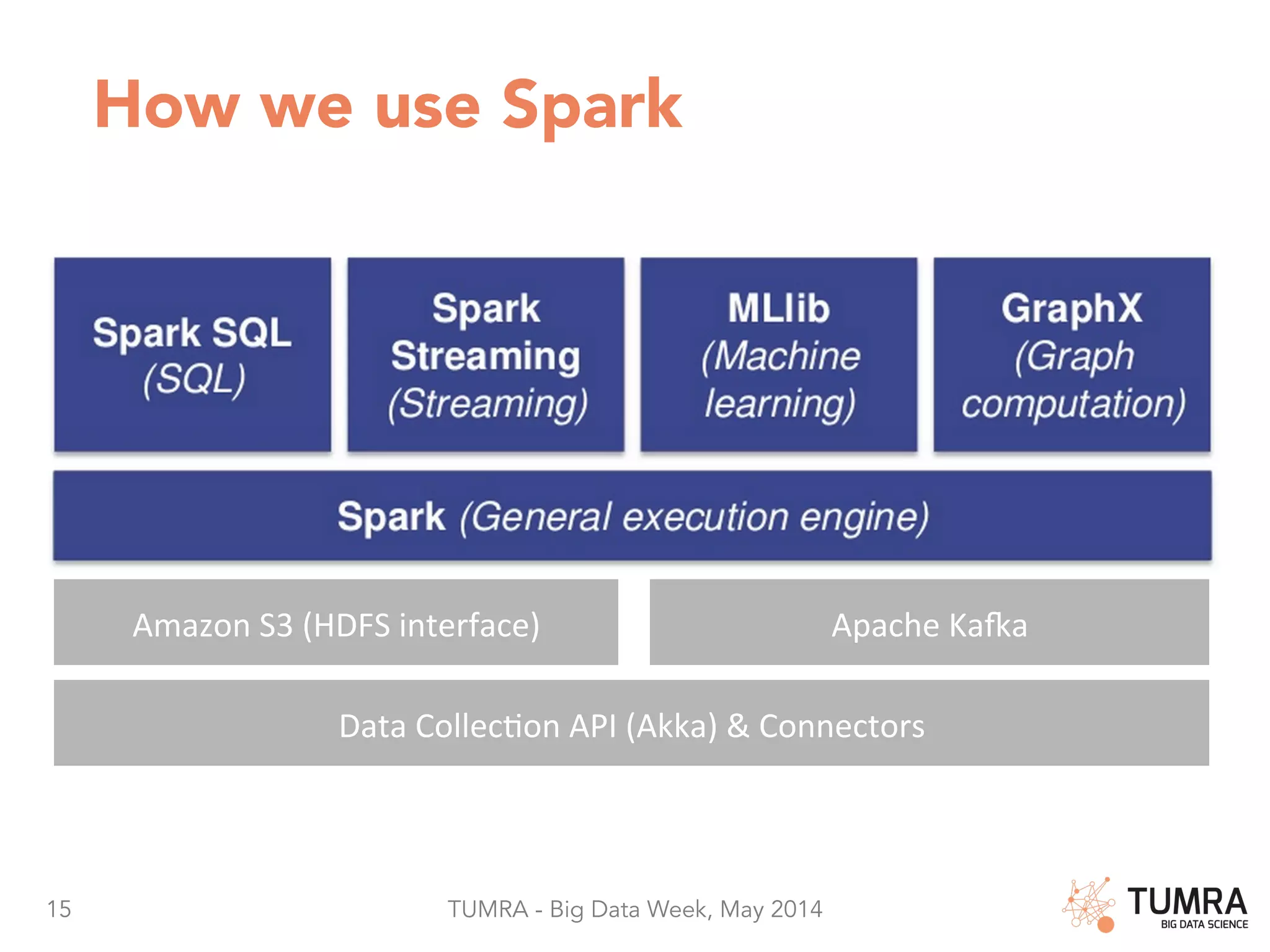







The document discusses Apache Spark as a leading platform for big data, emphasizing its capabilities in integrating SQL, machine learning, and streaming analytics. It highlights the advantages of Spark such as code reuse, fast in-memory data sharing, and extensive use cases in personalization and marketing automation. Additionally, it presents usage statistics and the transition of Spark in production since 2013, showcasing its effectiveness in handling large data volumes.