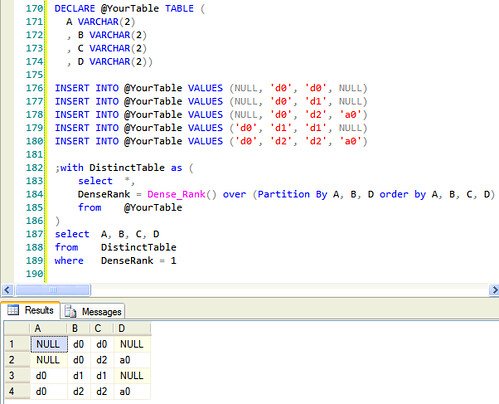
I have a query that returns a result set similar to the one below (in reality it is far bigger, thousands of rows):
A | B | C | D -----|----|----|----- 1 NULL | d0 | d0 | NULL 2 NULL | d0 | d1 | NULL 3 NULL | d0 | d2 | a0 4 d0 | d1 | d1 | NULL 5 d0 | d2 | d2 | a0
Two of the rows are considered duplicates, 1 and 2, because A, B and D are the same. To eliminate this, I could use SELECT DISTINCT A, B, D but then I do not get column C in my result set. Column C is necessary information for rows 3, 4 and 5.
So how do I come from the result set above to this one (the result appearing in C4 can also be NULL instead of d1):
A | B | C | D -----|----|------|----- 1 NULL | d0 | NULL | NULL 3 NULL | d0 | d2 | a0 4 d0 | d1 | d1 | NULL 5 d0 | d2 | d2 | a0