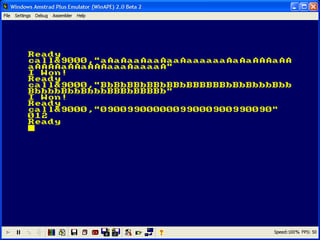
This is my first challenge on ppcg!
Input
A string consisting of two different ascii characters. For example
ABAABBAAAAAABBAAABAABBAABA Challenge
The task is to decode this string following these rules:
- Skip the first two characters
- Split the rest of the string into groups of 8 characters
- In each group, replace each character with
0if that character is the same as the first character of the original string, and with1otherwise - Now each group represents a byte. Convert each group to character from byte char code
- Concatenate all characters
Example
Let's decode the above string.
AB AABBAAAA AABBAAAB AABBAABA ^^ ^ ^ ^ | | | | | \---------|---------/ | | Skip Convert to binary Notice that A is the first character in the original string and B is the second. Therefore, replace each A with 0 and each B with 1. Now we obtain:
00110000 00110001 00110010 which is [0x30, 0x31, 0x32] in binary. These values represent characters ["0", "1", "2"] respectively, so the final output should be 012.
Scoring
This is, of course, code-golf, which means make your code as short as possible. Score is measured in bytes.
Constraints and IO format
Standard rules apply. Here are some additional rules:
- You can assume valid input
- Input string consists of exactly two different characters
- The first two characters are different
- The minimal length of the input string is 2 characters
- The length will always give 2 modulo 8
- You can assume the string will always consist only of printable ASCII characters
- Both in the input and in the decoded string
- Leading and trailing whitespace are allowed in the output (everything that matches
/\s*/)