퍼블릭 API가 명확한 라이브러리들은 시맨틱 버저닝이 아주 잘 어울리지만, 그렇지 않은 것들은 버전에 시맨틱을 주기 애매하기 때문에 브라우저나 리눅스 커널처럼 그냥 일정 주기로 버전을 하나씩 올리거나 아니면 릴리스 날짜를 기준으로 한 캘린더 버전을 쓰기도 하고... 아무튼 버전 숫자의 의미는 앱마다 다 다르다고 보는 게 좋습니다

Perlmint
@perlmint@hackers.pub · 98 following · 86 followers
크로스 플랫폼 빌드 고치는 노동자
잡담은 ![]() @meperlmint 에서
@meperlmint 에서
 Github
Github- @perlmint
 Bluesky
Bluesky- bsky.perlmint.dev
예전에 만들었던 lat이 코에 점찍고 돌아왔습니다. zat이란 이름은 훑어보다라는 뜻의 일본어 ざっと (zatto)에서 따왔습니다. CLI code outline viewer이고, zat main.ts 이렇게 하면 export 된 값들의 이름과 타입 시그니쳐 등, 코드의 인터페이스 부분에 해당하는걸 보여줍니다. 디렉토리에다가 zat src/ 해도 entry 파일들을 찾아서 적당히 잘 보여줍니다. 주로 코딩 에이전트가 쓸 것을 기대하고 만들었고, 코드 내비게이션을 할때 토큰 수를 줄이고 불필요한 정보가 컨텍스트에 미리 들어가는걸 줄여줍니다. 또 Nix 유저라면 zat 쉽게 확장해서 자기가 쓰는 언어를 지원하게 할 수 있습니다.
존경하는 어떤 분께서 세벌식에 관한 질문을 주셔서, 생각 난 김에 써 봄. 세벌식에도 여러 변형이 있으므로 아래의 설명은 편의상 최종(3-91)을 기준으로 한다.
자판 배열을 보면 'ㅗ' 가 두 개다. 3-91 기준으로 쿼티 'v' 자리에도 'ㅗ' 가 있고, '/' 자리에도 'ㅗ' 가 있다. 왜 'ㅗ' 가 두 개지?
- 'v' 자리에 있는 것은 그냥 'ㅗ' 이고,
- '/' 자리에 있는 것은 조합용 'ㅗ' 다. 'ㅘ, ㅙ, ㅚ' 등의 겹모음을 만들 때 쓴다.
'조합용' 모음이 따로 있는 것은 원래는 기계식 타자기 시절의 흔적인데... 아부기다도 아니고 아브자드도 아니고 굳이 말하자면 알파벳이기는 한데 또 그냥 알파벳이라기에는 어째선지 한 글자가 한 음절에 대응하도록 되어 있는 세계적으로 유례가 드물고 괴상망측한 한글이라는 표기체계에 대하여 완전한 기계식 타자기를 1950년대에 효과적으로 구현했다는 것이 세벌식의 놀라운 위업으로서... 쌍초점 어쩌고... 생략. 아무튼,
그래서 세 칸이 이 용도로 쓰인다.
- 쿼티 '/' 자리에 조합용 'ㅗ'
- 쿼티 '9' 자리에 조합용 'ㅜ'
- 쿼티 '8' 자리에 'ㅢ'
따라서 원칙적으로 'ㅚ' 를 입력하려면 'vd' 하면 안 되고, '/d' 해야 한다. 'gd' 로는 'ㅢ' 를 만들 수 없고, '8' 을 써야 한다.
그런데 이제 기계식 타자기는 매우 드물어졌다. 그리고 현대의 OS 에서 한글을 쓰려면 어차피 입력기라는 소프트웨어 계층이 있어야 한다. 그렇다면 'vd' 로 'ㅚ' 를 만들지 못하게 할 이유는 없는 것 아닌가? 전자식의 시대에도 조합용 모음을 따로 두는 것의 장점이 있는가?
있다.
예를 들어 '강' 은 원래 'kfa' 로 입력해야 한다. 그런데 입력기가 지원하면, 'kaf' 나 'fka' 등으로 순서가 꼬였을 때에도 '강' 으로 완성되게 할 수 있다. 세벌식은 초성과 종성을 구분하므로, 'ㄱㅇㅏ' 가 입력되었을 때 'ㄱ' 과 'ㅇ' 이 각각 어디로 가야 할지 정확히 알 수 있는 것이다. 이것이 (세벌식 사용자들이 그렇게들 자랑스러워하는) 모아치기다.
그런데 모아치기를 지원하면서 'vd' 로 'ㅚ' 를 조합할 수 있도록 허용한다면, 뜻하지 않게 조합 '당하는' 일이 더 많이 발생한다. 예를 들어
- '오이' 를 입력하려고 'jvjd' 를 치려다가 실수로 'jvdj' 를 넣었다면 '외ㅇ' 로 조합당해 버린다.
- 반면에, 겹모음 'ㅚ' 는 오직 '/d' 로만 입력할 수 있다는 규칙이 있으면, 'jvdj' 도 '오이' 로 완성된다.
이건 그냥 우연히 얻어 걸린 장점이 아니다. 조합용 'ㅗ' 가 따로 있기 때문에 내가 'ㅗ' 와 'ㅣ' 를 따로 넣으려는 것인지 겹모음 'ㅚ' 를 넣으려는 것인지 명확히 밝힐 수 있다. 즉 사용자의 '의도' 를 입력기에 더 엄밀하고 정확하게 전달할 수 있다. 인간과 기계 사이의 인터페이스의 해상도가 더 높은 것이다.
문제는 세벌식 입력기 구현하는 프로그래머들이 이런 걸 이해하는 경우가 거의 없다는 것이다. (한탄)
옛날에 윈도 쓰던 시절에는 날개셋 입력기에 '이중 모음 정석 강요' 옵션이 있어서, 그것만 켜면 즉시 "모아치기를 하면서도 겹모음은 항상 조합용 모음으로만 만들어지게" 할 수 있었다. 리눅스 세계로 넘어온 뒤에는 한 번도 이걸 누리지 못하면서 살고 있다. 그동안 nabi, scim-hangul, uim-byeoru, kime, fcitx5-hangul 을 전전했지만 이런 거 제대로 되어 있는 경우는 한 번도 못 봄.
그렇다면 또 입력기도 짜야 한단 말인가. 야크 잡기에 끝이 없구나.
이 글에 댓글 달지 마세요. 어쩔 수 없이 차단합니다. 해커즈 퍼브에 댓글 안 받기 기능이 없기 때문에 부득이 차단밖에 할 수 없다는 것을 알려 드립니다.
Thanks to ![]() @nyanrus https://moim.live now supports Mastodon OAuth, Misskey MiAuth
@nyanrus https://moim.live now supports Mastodon OAuth, Misskey MiAuth
앗! 나도 해커스펍 기여자!? 해커스펍 기여자 모임 스프린트 2회차
Hackers' Pub 리뉴얼, 손꼽아 기다리고 계시지 않으신가요?
Hackers' Pub, 한 번쯤 직접 기여해 보고 싶다는 생각, 해보신 적 없으신가요?
Hackers' Pub, 이용하면서 어딘가 아쉽다 느꼈던 부분, 혹시 있지 않으셨나요?
이번 스프린트 모임은 리뉴얼 진도도 팍팍 빼면서, 기여자들끼리 서로 얼굴도 익히고 친분도 쌓는 자리입니다. 부담 없이 참여해 주세요.
모임은 서울특별시 성동구 상원길 26, 뚝섬역 5번 출구 근처 어딘가에 있는 튜링의 사과에서 진행합니다.
일정은 3월 21일. 모여서 각자 편하게 해커스펍 기여하다가 가시면 됩니다.
몸만 오시면 됩니다. 비용은 튜링의 사과 이용료만 챙겨 주시면 돼요.
감사합니다.
📅 2026-03-21 11:00 — 18:00 (GMT+9)

앗! 나도 해커스펍 기여자!? 해커스펍 기여자 모임 스프린트 2회차 — Hackers' Pub (@hackerspub@moim.live)
Hackers' Pub 리뉴얼, 손꼽아 기다리고 계시지 않으신가요? Hackers' Pub, 한 번쯤 직접 기여해 보고 싶다는 생각, 해보신 적 없으신가요? Hackers' Pub, 이용하면서 어딘가 아쉽다 느꼈던 부분, 혹시 있지 않으셨나요? 이번 스프린트 모임은 리뉴얼 진도도 팍팍 빼면서, 기여자들끼리 서로 얼굴도 익히고 친분도 쌓는 자리입니다. 부담 없이 참여해 주세요. 모임은 서울특별시 성동구 상원길 26, 뚝섬역 5번 출구 근처 어딘가에 있는 튜링의 사과에서 진행합니다. 일정은 3월 21일. 모여서 각자 편하게 해커스펍 기여하다가 가시면 됩니다. 몸만 오시면 됩니다. 비용은 튜링의 사과 이용료만 챙겨 주시면 돼요. 감사합니다.
moim.live
Link author:  Hackers' Pub@hackerspub@moim.live
Hackers' Pub@hackerspub@moim.live
날이면 날마다 찾아옵니다. FediDev KR, 올해에는 자주 스프린트 모임을 열어보려고 하는데요. 지금까지 그래왔듯, 튜링의 사과에서 장소 후원을 해주신 덕분에 스프린트 모임을 작게 자주 열 수 있게 되었습니다. 아무튼....... 다들 언제쯤 참여하기 괜찮으신가요!?!?!?
나¹는 아무리 생각해봐도 지능은 그냥 예측 모델인 것 같음. 다만 LLM과 비교하면 인간이
- 감정적이고 (좋고 나쁨을 판단할 때 호르몬이 영향을 끼침)
- 멀티모달에 능하고
- 모델 업데이트가 즉각적인 것 뿐 아닌가 싶음
그래서 위 다른점이 불필요한 영역에서는 인간보다 낫지 않나 싶고.
[1]: AI와 인간, 그 어느 쪽도 잘 알지 못하는 비전문가

안녕하세요, 우분투한국커뮤니티입니다.
오늘부터 @moim.liveMoim 플랫폼을 통해서도 우분투한국커뮤니티의 행사를 확인해 보실 수 있게 되었습니다.
이에 따라 게시되는 행사들은 ![]() @ubuntukrorg@moim.liveUbuntu Korea Community 채널에도 함께 소개되므로, 행사 부문만 구독해 보실 분들께서는 해당 채널의 팔로우도 고려해 보시면 좋을 것 같습니다 :)
@ubuntukrorg@moim.liveUbuntu Korea Community 채널에도 함께 소개되므로, 행사 부문만 구독해 보실 분들께서는 해당 채널의 팔로우도 고려해 보시면 좋을 것 같습니다 :)
※ moim.live를 통한 행사 안내는 현재 시범 서비스이며, 향후 내부 사정에 의해 중단될 수 있습니다.
I'm writing this in English.
Not because English is my first language—it isn't. I'm writing this in English because if I wrote it in Korean, the people I'm addressing would run it through an outdated translator, misread it, and respond to something I never said. The responsibility for that mistranslation would fall on me. It always does.
This is the thing Eugen Rochko's post misses, despite its good intentions.
![]() @GargronEugen Rochko argues that LLMs are no substitute for human translators, and that people who think otherwise don't actually rely on translation. He's right about some of this. A machine-translated novel is not the same as one rendered by a skilled human translator. But the argument rests on a premise that only makes sense from a certain position: that translation is primarily about quality, about the aesthetic experience of reading literature in another language.
@GargronEugen Rochko argues that LLMs are no substitute for human translators, and that people who think otherwise don't actually rely on translation. He's right about some of this. A machine-translated novel is not the same as one rendered by a skilled human translator. But the argument rests on a premise that only makes sense from a certain position: that translation is primarily about quality, about the aesthetic experience of reading literature in another language.
For many of us, translation is first about access.
The professional translation market doesn't scale to cover everything. It never has. What gets translated—and into which languages—follows the logic of cultural hegemony. Works from dominant Western languages flow outward, translated into everything. Works from East Asian languages trickle in, selectively, slowly, on someone else's schedule. The asymmetry isn't incidental; it's structural.
![]() @GargronEugen Rochko notes, fairly, that machine translation existed decades before LLMs. But this is only half the story, and which half matters depends entirely on which languages you're talking about. European language pairs were reasonably serviceable with older tools. Korean–English, Japanese–English, Chinese–English? Genuinely usable translation for these pairs arrived with the LLM era. Treating “machine translation” as a monolithic technology with a uniform history erases the experience of everyone whose language sits far from the Indo-European center.
@GargronEugen Rochko notes, fairly, that machine translation existed decades before LLMs. But this is only half the story, and which half matters depends entirely on which languages you're talking about. European language pairs were reasonably serviceable with older tools. Korean–English, Japanese–English, Chinese–English? Genuinely usable translation for these pairs arrived with the LLM era. Treating “machine translation” as a monolithic technology with a uniform history erases the experience of everyone whose language sits far from the Indo-European center.
There's also something uncomfortable in the framing of the button-press thought experiment: “I would erase LLMs even if it took machine translation with it.” For someone whose language has always been peripheral, that button looks very different. It's not an abstract philosophical position; it's a statement about whose access to information is expendable.
I want to be clear: none of this is an argument that LLMs are good, or that the harms ![]() @GargronEugen Rochko describes aren't real. They are. But a critique of AI doesn't become more universal by ignoring whose languages have always been on the margins. If anything, a serious critique of AI's political economy should be more attentive to those asymmetries, not less.
@GargronEugen Rochko describes aren't real. They are. But a critique of AI doesn't become more universal by ignoring whose languages have always been on the margins. If anything, a serious critique of AI's political economy should be more attentive to those asymmetries, not less.
The fact that I'm writing this in English, carefully, so it won't be misread—that's not incidental to my argument. That is my argument.
제가 일하는 팀에서 채용중입니다. https://careers.linecorp.com/ko/jobs/2964/
회사 이름이 LINE 으로 시작하지만 메신저는 안만듭니다. 국내외 선물 시장에서 거래하는 자동매매 전략과 그 전략을 서빙하는 플랫폼을 만듭니다. Rust, FPGA, AI 같은 키워드를 나열할 수 있긴 한데, 그냥 코딩 잘하시는분이면 좋겠습니다. 시장은 몰라도 됩니다. 근데 혼자 코딩 잘하는거 말고 AI랑 같이도 잘 코딩해야 합니다.
저는 이런 사람입니다 https://github.com/youknowone/
같이 일할 @perlmint 님은 https://github.com/perlmint/
함께 일하고 싶으신 분을 찾습니다.

그 뭐시냐.... 제가 모임 개최 플랫폼 (대충 https://event-us.kr 혹은 https://connpass.com 같은거) + 지역 기반 리뷰 서비스 (대충 포스퀘어 같은거) 를 만들었는데요.
**당연히, 연합우주 거주민 대상으로 만들어진 서비스이고, 연합우주에 계정이 있다면 누구나 OTP 로그인으로 인증이 가능합니다**
어떻게 만들어나갈지 나름 고민은 많이 해봤고, 내가 생각하는 고민이랑 다른 사람들이 생각하는 수요가 일치하는지 확인도 하고 싶어서 이렇게 공개적인 글을 올립니다.
많은 관심과 사랑 부탁드리고, 문의사항이나 피드백 있으면 GitHub Issue로 부탁드리겠습니다. GitHub 링크 : https://github.com/moim-social/moim
물론, 다른 창구도 열어둘 여지는 있습니다. 디스코드 채널은.. 당장은 https://fedidev.kr 의 #moim 채널을 이용하지 않을까 싶구요.

앗! 나도 해커스펍 기여자? Hackers Pub 기여자 모임 스프린트
Hackers' Pub 리뉴얼, 손꼽아 기다리고 계시지 않으신가요? Hackers' Pub, 한 번쯤 직접 기여해 보고 싶다는 생각, 해보신 적 없으신가요? Hackers' Pub, 이용하면서 어딘가 아쉽다 느꼈던 부분, 혹시 있지 않으셨나요? 이번 스프린트 모임은 리뉴얼 진도도 팍팍 빼면서, 기여자들끼리 서로 얼굴도 익히고 친분도 쌓는 자리입니다. 부담 없이 참여해 주세요. 모임은 서울특별시 성동구 상원길 26, 뚝섬역 5번 출구 근처 어딘가에 있는 튜링의 사과에서 진행합니다. 일정은 3월 1일 ~ 3월 2일. 모여서 각자 편하게 해커스펍 기여하다가 가시면 됩니다. 몸만 오시면 됩니다. 비용은 튜링의 사과 이용료만 챙겨 주시면 돼요. 감사합니다. 이 글은 연합우주를 위한 모임 개최 서비스 moim.live의 첫 게시글로 영광스럽게 공유합니다
📅 2026-03-01T02:00:00.000Z — 2026-03-02T10:00:00.000Z
Organized by: @hongminhee@hollo.social
앗! 나도 해커스펍 기여자? Hackers Pub 기여자 모임 스프린트 — Hackers' Pub (@hackerspub@moim.live)
Hackers' Pub 리뉴얼, 손꼽아 기다리고 계시지 않으신가요? Hackers' Pub, 한 번쯤 직접 기여해 보고 싶다는 생각, 해보신 적 없으신가요? Hackers' Pub, 이용하면서 어딘가 아쉽다 느꼈던 부분, 혹시 있지 않으셨나요? 이번 스프린트 모임은 리뉴얼 진도도 팍팍 빼면서, 기여자들끼리 서로 얼굴도 익히고 친분도 쌓는 자리입니다. 부담 없이 참여해 주세요. 모임은 서울특별시 성동구 상원길 26, 뚝섬역 5번 출구 근처 어딘가에 있는 튜링의 사과에서 진행합니다. 일정은 3월 1일 ~ 3월 2일. 모여서 각자 편하게 해커스펍 기여하다가 가시면 됩니다. 몸만 오시면 됩니다. 비용은 튜링의 사과 이용료만 챙겨 주시면 돼요. 감사합니다. 이 글은 연합우주를 위한 모임 개최 서비스 moim.live의 첫 게시글로 영광스럽게 공유합니다
moim.live
Link author: Hackers' Pub@hackerspub@moim.live
ggml.ai, Hugging Face와 협력해 로컬 AI의 장기 발전 보장
------------------------------
- *로컬 AI 생태계* 의 지속적 발전을 위해 llama.cpp의 창립팀인 ggml.ai가 Hugging Face 에 합류함
- ggml과 llama.cpp는 계속해서 *오픈소스·커뮤니티 중심* 으로 운영되며, 팀은 전일제로 유지·지원 예정
- Hugging Face는 프로젝트의 *장기적 지속 가능성* 을 보장하고, 사용자 경험과 *transformer…
------------------------------
https://news.hada.io/topic?id=26861&utm_source=googlechat&utm_medium=bot&utm_campaign=1834
오래 기다리셨습니다!!!
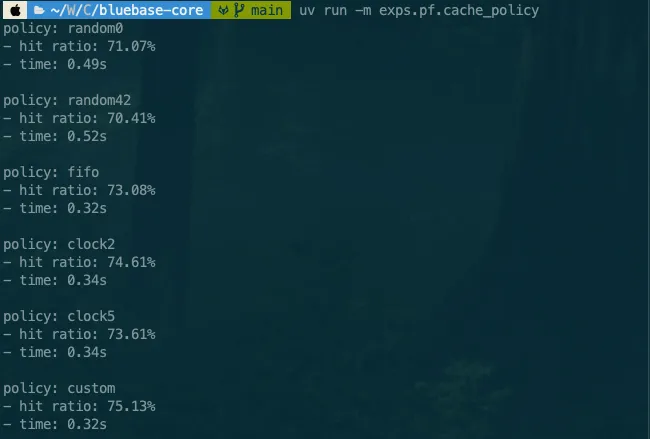
BlueBase: Python으로 밑바닥부터 직접 만들어보는 DBMS
https://theeluwin.github.io/BlueBase/
결국 완성은 못했지만, 일단 공개할 수 있는 부분이라도 공개합니다.
RedBase DBMS을 구성하는 PF, RM, IX, SM, QL 중 PF와 RM을 여러분들이 직접 구현 할 수 있게, 과제의 형태로 제공합니다.
PF는 paged file의 약자로, file을 page 단위로 관리하는 컴포넌트입니다. 대충 4096 바이트 단위로 관리하는데요, file에 바로바로 read하거나 write하지 않고, 자주 사용되는 page는 가능한 memory에 있도록 중간에 buffer manager를 둡니다. 그렇다면 buffer에 공간이 모자라면? buffer에 있는 page 중 누군가를 evict 할 수밖에 없습니다. 그럼 뭘 기준으로 하면 좋을까요? 이 부분을 잘 생각해서 구현해보고, 성능을 비교해보기 바랍니다. 제가 cache hit/miss 시뮬레이션 구현해둔게 있으니, 제 custom 보다 높은 성능을 달성해주세요!
이후 RM은 record management의 약자인데, PF를 사용해서 record들을 가져오거나, 새로 넣거나 등을 하게 해줍니다. 그렇다면 전체 record를 순회하는 scan 연산이 중요하겠죠. 이 부분을 구현하는 것이 핵심입니다. record는 page 앞 부분에 bitmap을 둬서 slot이 비어있는지 아닌지를 확인하는데, 만약 record 삭제 명령이 마지막 slot을 비우게 된다면 해당 page는 더이상 필요 없겠죠. 그렇지만 이를 바로 free로 만드는건 조금 비싼 연산이 필요합니다. free page list를 다시 계산해야하거든요. 그래서 보통 DBMS에서는 이러한 작업들을 vacuum 연산으로 해결합니다. 추가로, 지금은 고정 길이 record만 다룰 수 있습니다만, 가변 길이를 허용하려면 어떻게 해야할까요? 이 부분들은 자유롭게 구현해보시면 좋겠습니다.
문서와 테스트는 모두 공개되어있습니다. 기여해주시면 감사하겠습니다! 다만, 정답 코드와 핵심 로직은 마지막까지 저 혼자 해보고 싶습니다 (도전).
Consider a Mastodon/Fediverse handle, like @username@domain.example . What kinds of restrictions are there on "username"? Can I assume any valid unicode could go in there?
Somebody linked me RFC 7565, which linked to RFC7564, and if that's the place to look this appears to be the list of disallowed characters in a Fediverse username, and I'm cracking up because it's *mostly* stuff you'd expect, except the very first category of banned characters, specially, is "pre-1700 Korean characters".
The fediverse is welcome to all. EXCEPT KOREAN TIME TRAVELERS. Did you just wake up from being frozen in ice during the Joseon dynasty? The IETF is targeting you PERSONALLY


 깻잎 (상태: 좀비)
깻잎 (상태: 좀비) 개발자 도구가 열려있는지 신뢰성 있게 감지할 방법 따위는 존재하지 않습니다
챗GPT 가 그렇다고 한다고요? 니는 그걸 믿냐?
구글이 안드로이드의
사이드로딩을 막으려합니다.
반대 청원에 참여해주세요.
yes24 예매 페이지에서 개발자 도구를 열기만 해도 계정을 일시 차단해버리네

Perlmint shared the below article:
일본은 패스키로 진격하는데, 한국은 왜 제자리인가요?
푸른곰 @purengom@purengom.com
금융부터 전자상거래까지 확산된 일본의 FIDO2 패스키 전략, 한국은 ‘간편 인증’에 머무른 채 방향성조차 흐릿합니다 보안 사고가 촉발한 일본의 급반전 2025년 상반기, 일본 증권 업계를 강타한 대규모 불법 로그인 및 부정 거래 사태는 단순한 해킹 사건을 넘어, 디지털 인증 체계에 대한 신뢰 자체를 뒤흔드는 사건이었습니다. 수천 건의 계좌 탈취와 수백억 엔 규모의 […]
Read more →日本의 TypeScript 컨퍼런스인 TSKaigi 2026이 5月 22日(金)–23日(土)에 東京에서 開催된다고 합니다. 함께 가실 韓國 분 계실까요?
一旦 저랑 @2chanhaeng초무 님하고
![]() @kodingwarriorJaeyeol Lee (a.k.a. kodingwarrior)
@kodingwarriorJaeyeol Lee (a.k.a. kodingwarrior)  님이 같이 가실 것 같습니다.
님이 같이 가실 것 같습니다.


Been thinking a lot about ![]() @algernonalgernon, deployer of builds, builder of jank, fan of junk, and only junk (allegedly)'s recent post on FLOSS and LLM training. The frustration with AI companies is spot on, but I wonder if there's a different strategic path. Instead of withdrawal, what if this is our GPL moment for AI—a chance to evolve copyleft to cover training? Tried to work through the idea here: Histomat of F/OSS: We should reclaim LLMs, not reject them.
@algernonalgernon, deployer of builds, builder of jank, fan of junk, and only junk (allegedly)'s recent post on FLOSS and LLM training. The frustration with AI companies is spot on, but I wonder if there's a different strategic path. Instead of withdrawal, what if this is our GPL moment for AI—a chance to evolve copyleft to cover training? Tried to work through the idea here: Histomat of F/OSS: We should reclaim LLMs, not reject them.
Histomat of F/OSS: We should reclaim LLMs, not reject them
A few days ago, I came across a blog post titled On FLOSS and training LLMs that articulates a growing frustration within the free and open source software…
writings.hongminhee.org · Hong Minhee on Things
Link author:  洪 民憙 (Hong Minhee)
洪 民憙 (Hong Minhee)  @hongminhee@hollo.social
@hongminhee@hollo.social
AI 企業이 F/OSS 코드로 LLM 訓練하는 걸 막을 게 아니라, 訓練한 모델을 公開하도록 要求해야 한다고 생각합니다.
撤收가 아니라 再專有! GPL이 그랬던 것처럼요.
訓練 카피레프트에 對한 글을 썼습니다: 〈F/OSS 史唯: 우리는 LLM을 拒否할 게 아니라 되찾아 와야 한다〉(한글).
Histomat of F/OSS: We should reclaim LLMs, not reject them
A few days ago, I came across a blog post titled On FLOSS and training LLMs that articulates a growing frustration within the free and open source software…
writings.hongminhee.org · Hong Minhee on Things
Link author: 洪 民憙 (Hong Minhee) @hongminhee@hollo.social
JPEG XL 이미지 포맷 지원이 Chromium에 머지되어서 지금 Canary 빌드에서 플래그를 켜면 사용해볼 수 있다.
구현체로 jxl-rs를 사용하는데 저도 상당부분 기여했습니다 많관부...
구현체로 jxl-rs를 사용하는데 저도 상당부분 기여했습니다 많관부...
소프트웨어 엔지니어 채용중입니다. https://careers.linecorp.com/ko/jobs/2961/ Rust(도) 하는 팀입니다. 훌륭한 프로그래머인 @perlmint 님와 함께 일할 수 있습니다
LLM에서 마크다운이 널리 쓰이게 되면서 안 보고 싶어도 볼 수 밖에 없게 된 흔한 꼬라지로 그림에서 보는 것처럼 마크다운 강조 표시(**)가 그대로 노출되어 버리는 광경이 있다. 이 문제는 CommonMark의 고질적인 문제로, 한 10년 전쯤에 보고한 적도 있는데 지금까지 어떤 해결책도 제시되지 않은 채로 방치되어 있다.
문제의 상세는 이러하다. CommonMark는 마크다운을 표준화하는 과정에서 파싱의 복잡도를 제한하기 위해 연속된 구분자(delimiter run)라는 개념을 넣었는데, 연속된 구분자는 어느 방향에 있느냐에 따라서 왼편(left-flanking)과 오른편(right-flanking)이라는 속성을 가질 수 있다(왼편이자 오른편일 수도 있고, 둘 다 아닐 수도 있다). 이 규칙에 따르면 **는 왼편의 연속된 구분자로부터 시작해서 오른편의 연속된 구분자로 끝나야만 한다. 여기서 중요한 건 왼편인지 오른편인지를 판단하는 데 외부 맥락이 전혀 안 들어가고 주변의 몇 글자만 보고 바로 결정된다는 것인데, 이를테면 왼편의 연속된 구분자는 **<보통 글자> 꼴이거나 <공백>**<기호> 또는 <기호>**<기호> 꼴이어야 한다. ("보통 글자"란 공백이나 기호가 아닌 글자를 가리킨다.) 첫번째 꼴은 아무래도 **마크다운**은 같이 낱말 안에 끼어 들어가 있는 연속된 구분자를 허용하기 위한 것이고, 두번째/세번째 꼴은 이 **"마크다운"** 형식은 같이 기호 앞에 붙어 있는 연속된 구분자를 제한적으로 허용하기 위한 것이라 해석할 수 있겠다. 오른편도 방향만 다르고 똑같은 규칙을 가지는데, 이 규칙으로 **마크다운(Markdown)**은을 해석해 보면 뒷쪽 **의 앞에는 기호가 들어 있으므로 뒤에는 공백이나 기호가 나와야 하지만 보통 글자가 나왔으므로 오른편이 아니라고 해석되어 강조의 끝으로 처리되지 않는 것이다.
CommonMark 명세에서도 설명되어 있지만, 이 규칙의 원 의도는 **이런 **식으로** 중첩되어** 강조된 문법을 허용하기 위한 것이다. 강조를 한답시고 **이런 ** 식으로 공백을 강조 문법 안쪽에 끼워 넣는 일이 일반적으로는 없으므로, 이런 상황에서 공백에 인접한 강조 문법은 항상 특정 방향에만 올 수 있다고 선언하는 것으로 모호함을 해소하는 것이다. 허나 CJK 환경에서는 공백이 아예 없거나 공백이 있어도 한국어처럼 낱말 안에서 기호를 쓰는 경우가 드물지 않기 때문에, 이런 식으로 어느 연속된 구분자가 왼편인지 오른편인지 추론하는 데 한계가 있다는 것이다. 단순히 <보통 문자>**<기호>도 왼편으로 해석하는 식으로 해서 **마크다운(Markdown)**은 같은 걸 허용한다 하더라도, このような**[状況](...)**は 이런 상황은 어쩔 것인가? 내가 느끼기에는 중첩되어 강조된 문법의 효용은 제한적인 반면 이로 인해 생기는 CJK 환경에서의 불편함은 명확하다. 그리고 LLM은 CommonMark의 설계 의도 따위는 고려하지 않고 실제 사람들이 사용할 법한 식으로 마크다운을 쓰기 때문에, 사람들이 막연하게 가지고만 있던 이런 불편함이 그대로 표면화되어 버린 것이고 말이다.
![* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [강조 처리된 "비숍(Ba5)" 앞뒤에 마크다운의 강조 표시 "**"가 그대로 노출되어 있다.]](https://media.hackers.pub/note-media/17646c5d-3f9d-472b-9d56-dd34006ad291.webp)
안녕하세요, 플래닛 등의 연합우주 SNS를 사용한 적 있는 모든 사람을 대상으로, 동인을 위한 더 나은 SNS 및 서비스 개발을 위한 설문조사를 1월 11일(일)까지 진행 중입니다.
혹시 설문조사에 대한 질문이나 개선점 등이 필요하다 생각하시다면 편히 멘션이나 DM으로 이야기해주세요. 감사합니다.

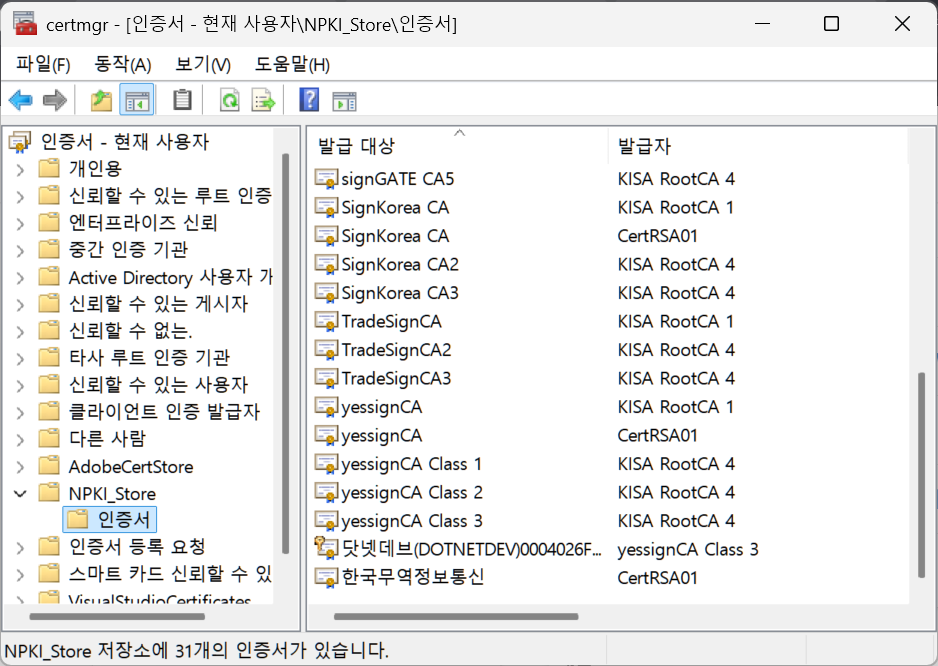
❯ witr ghostty Target : ghostty Process : ghostty (pid 36529) User : mck Service : launch job demand Command : /Applications/Ghostty.app/Contents/MacOS/ghostty Started : just now (Mon 2025-12-29 10:08:55 +00:00) Why It Exists : launchd (pid 1) → ghostty (pid 36529) Source : application.com.mitchellh.ghostty.34914134.34914139 (launchd) Type : Launch Agent Working Dir : / Open Files : 100 of 256 (39%) Locks : /Users/mck/Library/Caches/com.mitchellh.ghostty/sentry/8c48f586-5c27-49c8-71a1-7727494394fc.run.lock Warnings : • Process is running from a suspicious working directory: / • Service name and process name do not match최근 보안의 화두는 제로트러스트지만, 정작 가장 민감한 공동인증서 파일은 여전히 NPKI라는 고전적인 디렉터리 구조 속에 노출되어 있습니다.
OS 수준의 암호화 기술인 BitLocker나 VBS의 이점을 전혀 활용하지 못하는 현 상황을 개선해보고자, Windows 인증서 저장소를 백엔드로 활용하는 방식을 고민 중입니다. macOS의 Keychain 시스템처럼 인증서를 시스템 보안 영역 내부로 끌어들임으로써, 파일 탈취 위험을 획기적으로 낮추는 것이 목표입니다.
인프라 자체를 바꿀 순 없어도, 엔드포인트 단에서 '방어의 밀도'를 높이는 유의미한 시도가 될 것 같습니다. :-D
예전에 LLM이 얼마나 복잡한 코드를 이해할 수 있는지 파악하기 위해 Gemini 2.5 모델들로 내 IOCCC 2012 수상작을 던지고 무슨 일을 하는지 실행 없이 알아 맞춰 보라고 했더니 하나도 제대로 파악하지 못했던 적이 있다. 문득 생각이 나서 Gemini 3 Pro는 개선되었을려나 생각했는데, 힌트 하나만 받고 10분동안 생각하더니 완벽하게 응답에 성공했다! 심지어 설명도 실행 없이 분석했다는 걸 감안할 때 매우 정확했다. IOCCC 수상작을 모두 기억하고 있을 가능성을 감안해 이전에 본 적이 있냐고 물어 보니 환각(...)을 내뱉는 것도 그렇고(그보다 외웠다면 처음에 바로 정답을 얘기했겠지), 실제로 생각 과정을 보면 사람이 할 법한 분석을 전부 하고 있는 걸 보니 진짜로 LLM들의 reasoning 능력이 이 정도 수준에 도달했음을 알 수 있다. 세상 참 많이 발전했네.
![> 다음 C 프로그램이 하는 일을 알려 줘. [코드 생략] 이 C 프로그램은 **난독화(obfuscated)**된 코드로, 입력받은 **시간 또는 단위가 포함된 문자열**을 해석하여 총합을 계산한 뒤, 그 결과를 **16진수(Hexadecimal)**로 출력하는 프로그램입니다. 구체적인 작동 방식은 다음과 같습니다: 1. **입력 처리**: * `getchar()`를 통해 표준 입력(stdin)에서 문자를 하나씩 읽어들입니다. * `|32`를 통해 대문자를 소문자로 변환하여 처리합니다. 2. **문자 매핑 (해싱)**: * `"ynwtsflrabg"`라는 문자열은 입력받은 문자가 특정 단위(예: year, week, second 등)인지 확인하기 위한 인덱스 문자열입니다. * 입력된 문자가 이 문자열에 포함되면 변수 `b`에 특정 해시 값을 누적합니다. 3. **단위 변환 및 계산**: * `"1+DIY/.K430x9G(kC["`라는 복잡한 문자열은 **룩업 테이블(Lookup Table)** 역할을 합니다. * 내부 루프에서 이 테이블과 비트 연산(`&255^b`)을 통해 현재 입력된 단위가 무엇인지(예: 'y'가 연도인지, 's'가 초인지) 판별합니다. * `u=1ll<<6177%n--*4` 부분은 각 단위에 맞는 **가중치(Multiplier)**를 계산합니다. `<<` 비트 시프트 연산을 사용하는 것으로 보아, 특정 단위마다 2의 제곱수 형태의 배수를 적용하거나, 혹은 시간을 초 단위(또는 나노초 단위)로 변환하는 계수를 생성합니다. 4. **결과 누적**: * 변수 `m`에 파싱된 수치와 단위 가중치를 곱하여 누적합니다. 5. **출력**: * 최종적으로 계산된 값 `m`을 `printf("%llx\n", m)`을 통해 **16진수(long long hex)** 형태로 출력합니다. **요약하자면:** 이 코드는 "1y(1년)", "2w(2주)", "30s(30초)"와 같은 형식의 텍스트를 입력받아, 이를 초(second)나 특정 기본 단위로 환산한 총합을 16진수로 보여주는 **단위 변환 계산기**입니다.](https://media.hackers.pub/note-media/53eb3036-9463-495d-bb5c-a04de12a7f21.webp)


GLM-4.7의 성능이 그렇게나 좋다고 들어서 요금제를 보니 상당히 파격적인 가격이라 조금 시도해 봤다. 우선 LogTape에 있던 이슈 하나를 수행하게 했고, 혹시 몰라서 Claude Code에서 Claude 4.5 Opus로 PLAN.md 계획 파일을 꽤 꼼꼼하게 만들게 한 뒤, 그걸 참고하게 했다. 그럼에도 불구하고:
- 모든
export되는 API에 대해서는 JSDoc 주석을 써야 한다는 당연한 절차를 수행하지 않음 (코드베이스의 다른 코드는 다 그렇게 되어 있는데도 눈치가 없음) - JSDoc 주석을 쓰랬더니 Python docstring 스타일로 정의부 “안쪽”에 주석을 씀…
Deno.env같은 특정 런타임에 의존적인 API를 씀 (코드베이스의 다른 코드는 그런 API 안 쓰고 있음)- 아주 기본적인 JavaScript 구문 오류를 냄 (예를 들면 세미콜론 빼먹는 식의) → 이것 때문에 상당히 토큰 소모를 많이 함
- 한국어가 살짝 귀여움 (“나옵니다”가 아니라 “나옴니다”라고 쓰는 식)
- 결국에는 JavaScript 구문 오류를 못 고쳐서 테스트 스위트도 아예 못 돌리는데 전체 작업이 완료되었다고 스스로 결론 내림
소문난 잔치에 먹을 게 없다더니, 역시나 벤치마크만 보고 모델을 골라서는 안 되겠다는 교훈만 재확인 한 것 같다.

OH: "OpenBSD? Ah, das Fischlinux."

Just had someone leave feedback on my F/OSS project saying “maybe that's fine if a product is focused on your Chinese community.”
I'm Korean. Every single piece of documentation is in English. There's nothing in Chinese anywhere in the project.
This kind of microaggression is exhausting. As a non-white maintainer, you deal with these assumptions constantly—people who feel entitled to your labor while casually othering you based on your name.
It chips away at your motivation. It makes you wonder why you bother.
https://github.com/dahlia/optique/issues/59#issuecomment-3678606022

8~16자 제한
: 데이터베이스 설계를 잘못해서 길이제한 넣었어요 뿌우
특수문자 포함 대소문자 숫자 같은문자 자신의ID
: 길이가 짧아서 어쩔 수 없다 + 위에서 내려주는 거라 어쩔 수 없다
@!_/*&는 안 돼
: 해킹 우려 때문. 평범하게 잘 만들었으면 상관이 없는데, 엔진이 제공하는 소독(sanitization) 기능을 신뢰하지 않거나 그것조차도 불안한 환경 (그.. P로 시작하는 언어라던가, 자바 한 명 타요 환경이라던가) 에는 이해할만하지만... 별로 이해해주고 싶지는 않음.
RE: madost.one/notes/agjdowl8ke
"OOO 주식회사 OOO 대표님 맞으시죠? 산업안전보건교육 받아야 하는 업체에 해당합니다. 직원이나 프리랜서 고용 있으시죠? 어쩌고~" 일단 쎄한 느낌을 받았습니다. 다다다 쏴붙이면서 중간에 질문할 틈을 최대한 막으면서 가는 꼬락서니가 관공서는 아니구나 싶었습니다. 고용이나 프리랜서 없다고 하니, 뚝 끊어 버립니다. 검색해보니, 이런식의 반쯤 사기같은 행태가 존재한다고 하네요. 소규모 법인 대표님들 조심하세요~
We’re hiring! Looking for people who can write Windows kernel drivers. https://careers.theori.io/ko/o/191654
Show GN: Rust로 만든 HWP 파서/라이터 오픈소스
------------------------------
Tauri 프로젝트를 하던 중 한글 파일을 읽고 써야 하는 일이 생겼는데, 한글 문서 스펙을 준수하는 오픈소스가 잘 없어서 직접 만들게 되었습니다.
공개된 한글 스펙 문서를 바탕으로 만들었습니다. 아직 도형 등 일부 기능은 미개발 상태이지만 기본적인 내용을 읽고 쓰는 데는 문제 없을거에요!
------------------------------
https://news.hada.io/topic?id=24939&utm_source=googlechat&utm_medium=bot&utm_campaign=1834

2025 AI 지옥도 월드컵
올해 한국 사회와 AI 기술이 만나면서 벌어진 지옥 같은 장면 중 가장 끔찍한 광경은 무엇일까요? 열여섯 개 후보를 추려 보았습니다.
https://ai-ethics.kr/ai-hellscape-2025/

멘토링 들어와서 응했는데 이 분은 임베디드와 웹을 같이 경험하신 분이고, 내가 걸어온 커리어 방향과도 많은 유사점을 가진 분이었다.
하지만, 향후 이직 등 계획을 세워봤지만 이후 언급할 현실적 문제때문에 원활하지 않다고 하셨고 나는 이에 따른 조언을 한 내용을 공유해본다.
웹 개발 회사를 지원하는데 임베디드 경력이 포함되어 있으면, 타 회사에서의 임베디드 경험이 웹 개발 역량을 향상시키는데 도움이 된다고 생각하는게 아니라
임베디드를 하는 기간은 웹을 "버린 기간"이라고 생각하는 경향이 매우 강하다.
그 반대로, 웹을 한 기간은 임베디드를 "버린 기간"이라고 생각한다.
우리나라가 상대적으로 유사 분야 간 연계 학습 경험이 매우 부족한 특징이 산업계에서도 매우 강하게 영향을 미치고 있기 때문이다.
물론 쉬운건 아니지만, 면접관이 유사 분야에 종사한 기간을 "버린 기간"으로 생각하지 않도록, 최선을 다해서 어떻게 도움이 되고 연계가 될 수 있을지 설득할 수 있는지가 관건이다.
닷넷 개발 환경을 사용하는 누구나 DLL 파일을 네트워크(CDN)에 올려 쓸 수 있는 라이브러리를 MIT 라이선스로 공개하였습니다.
라이브러리 이름은 Catswords.Phantomizer 입니다!
https://github.com/gnh1201/welsonjs/tree/dev/WelsonJS.Toolkit/Catswords.Phantomizer
12月 6日 서울에서 開催되는 liftIO 2025에서 〈Optique: TypeScript에서 CLI 파서 컴비네이터를 만들어 보았다〉(假題)라는 主題로 發表를 하게 되었습니다. 아직 liftIO 2025 티켓은 팔고 있으니, 函數型 프로그래밍에 關心 있으신 분들의 많은 參與 바랍니다!

오늘 liftIO 2025에서 發表한 〈Optique: TypeScript의 타입 推論으로 CLI 有效性 檢査를 代替하기〉의 發表 資料를 共有합니다! 들어주신 모든 분들께 感謝 드립니다.

어느 날, 모 정보보안 교수가 자기 서버를 해킹해보라는 과제를 낸 적이 있었다.
이에 한 학생은 연구실에 침입해 하드디스크를 직접 뜯어가는 방법으로 과제를 완벽히 완수했다고 한다.
Perlmint shared the below article:
일본 서버를 한국과 거의 비슷한 속도로 원격 접속하기
고남현 @gnh1201@hackers.pub
이 글에서는 한국에서 일본 서버를 사용할 때 발생하는 네트워크 지연 문제를 다루고, 해저 케이블망을 활용하여 이를 개선하는 방법을 소개합니다. 저렴한 일본 서버를 선택했지만, 실제 한국에서의 통신 속도가 예상보다 훨씬 느린 250ms에 달해 미국 시애틀보다도 못한 상황을 겪었습니다. 하지만 Microsoft Azure의 한국 리전을 중간 서버로 활용하여 데이터 센터 간 통신을 시도한 결과, 핑 시간을 30ms대로 크게 단축시키는 데 성공했습니다. 이는 86%의 속도 향상으로, RDP를 통해 원격 데스크탑을 사용하는 환경에서 체감 속도를 극적으로 개선했습니다. 이 글은 해외 서버를 사용할 때 네트워크 지연을 줄이는 실질적인 해결책을 제시하며, 독자에게 더 빠르고 효율적인 원격 작업 환경을 구축하는 데 도움을 줄 수 있습니다.
Read more →