Download as PDF, PPTX
























The document discusses Adaptive Query Execution (AQE) in Spark SQL, a dynamic optimization feature that improves query performance by making adjustments based on runtime statistics. Key enhancements introduced in Spark 3.0 include dynamically coalescing shuffle partitions, switching join strategies, and optimizing skew joins based on partition sizes. The effectiveness of AQE is demonstrated through performance improvements in production environments, achieving significant speedups in various queries.
Introduces Adaptive Query Execution (AQE) in Spark SQL, presenting its purpose and agenda for discussion.
Explains the background and definition of AQE, focusing on dynamic optimization during query execution.
Highlights the limitations of Cost-Based Optimization (CBO) and introduces AQE's reliance on runtime statistics for better decisions.
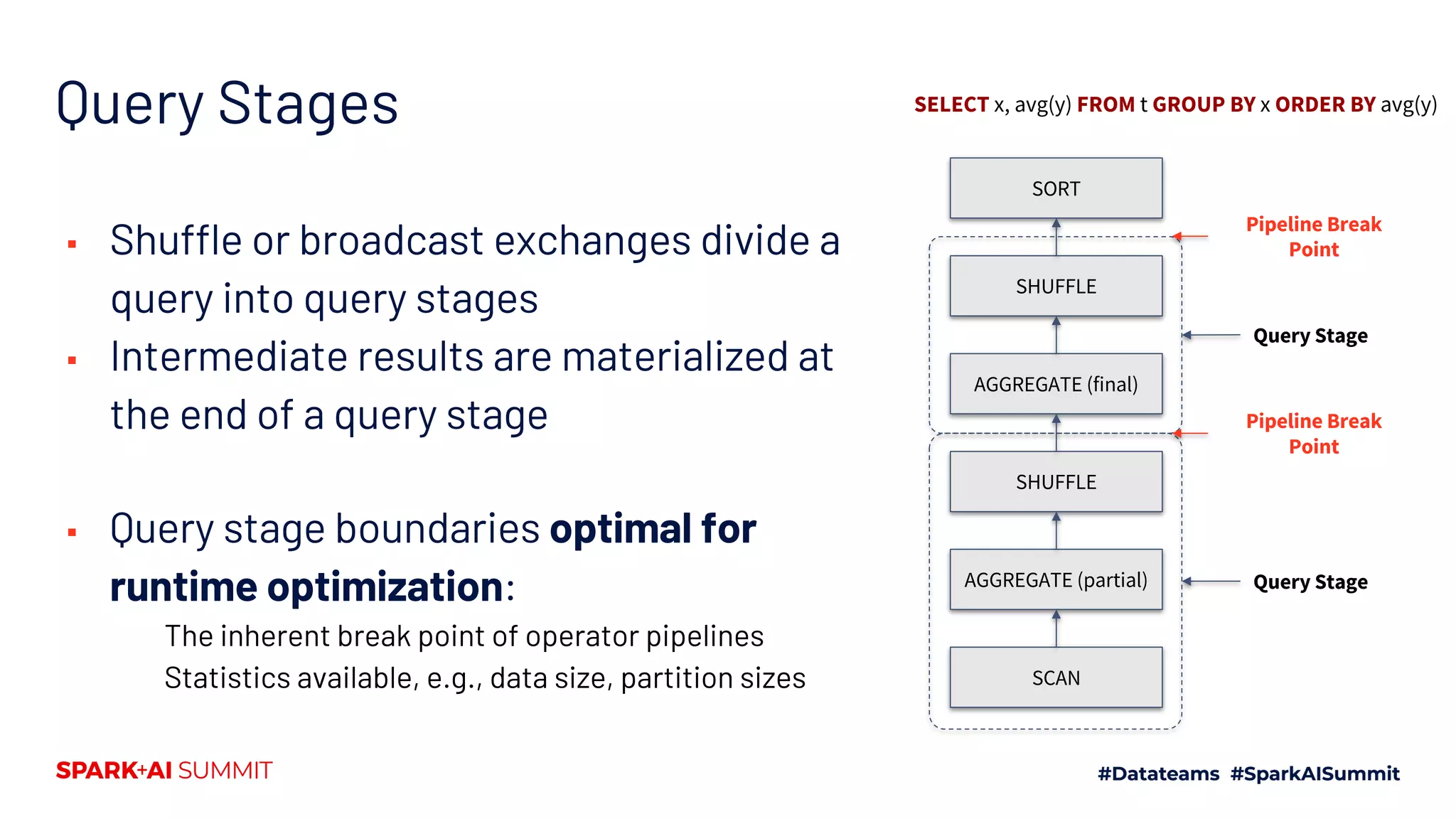
Describes how AQE works, detailing the query stages, run optimizations, and stage completions.
Lists major features of AQE including coalescing partitions, switching join strategies, and optimizing skew joins.
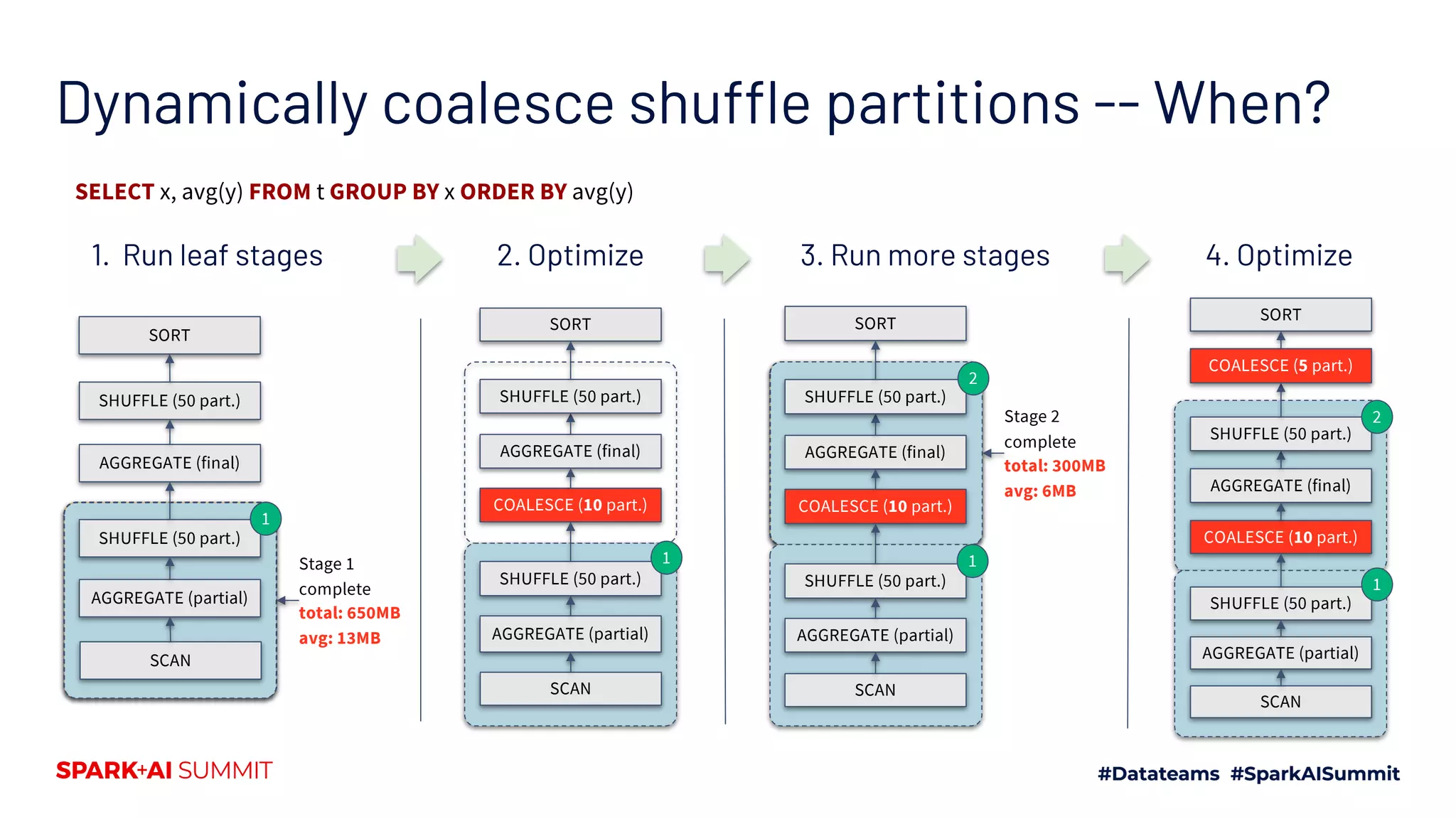
Discusses the importance of shuffle partition number and sizes, and AQE's method for optimizing partition sizes dynamically.
Illustrates how AQE combines partitions for efficiency, comparing static versus coalesced partitioning approaches.
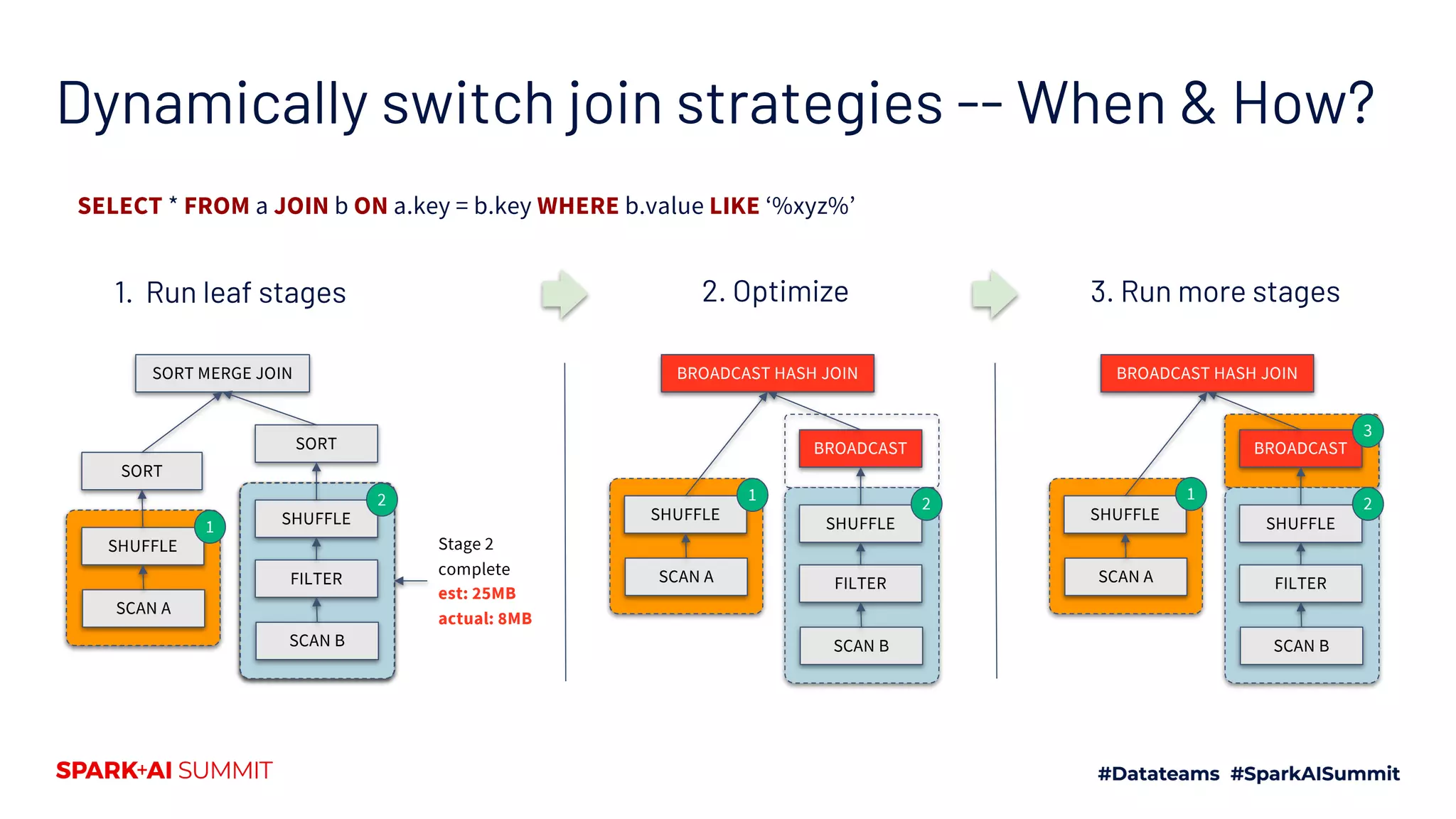
Explains the rationale for dynamically choosing join strategies through AQE using runtime data to optimize joins.
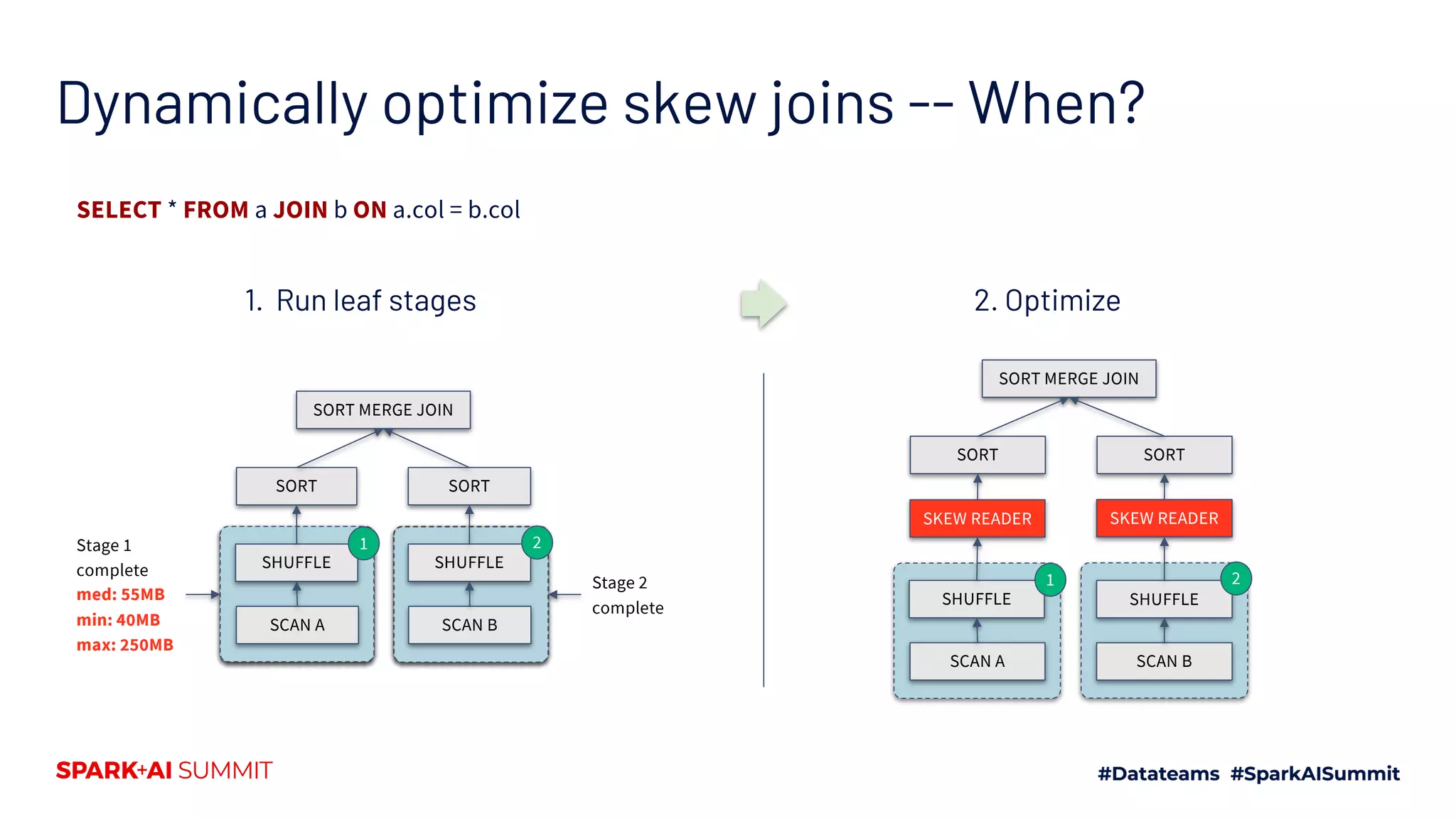
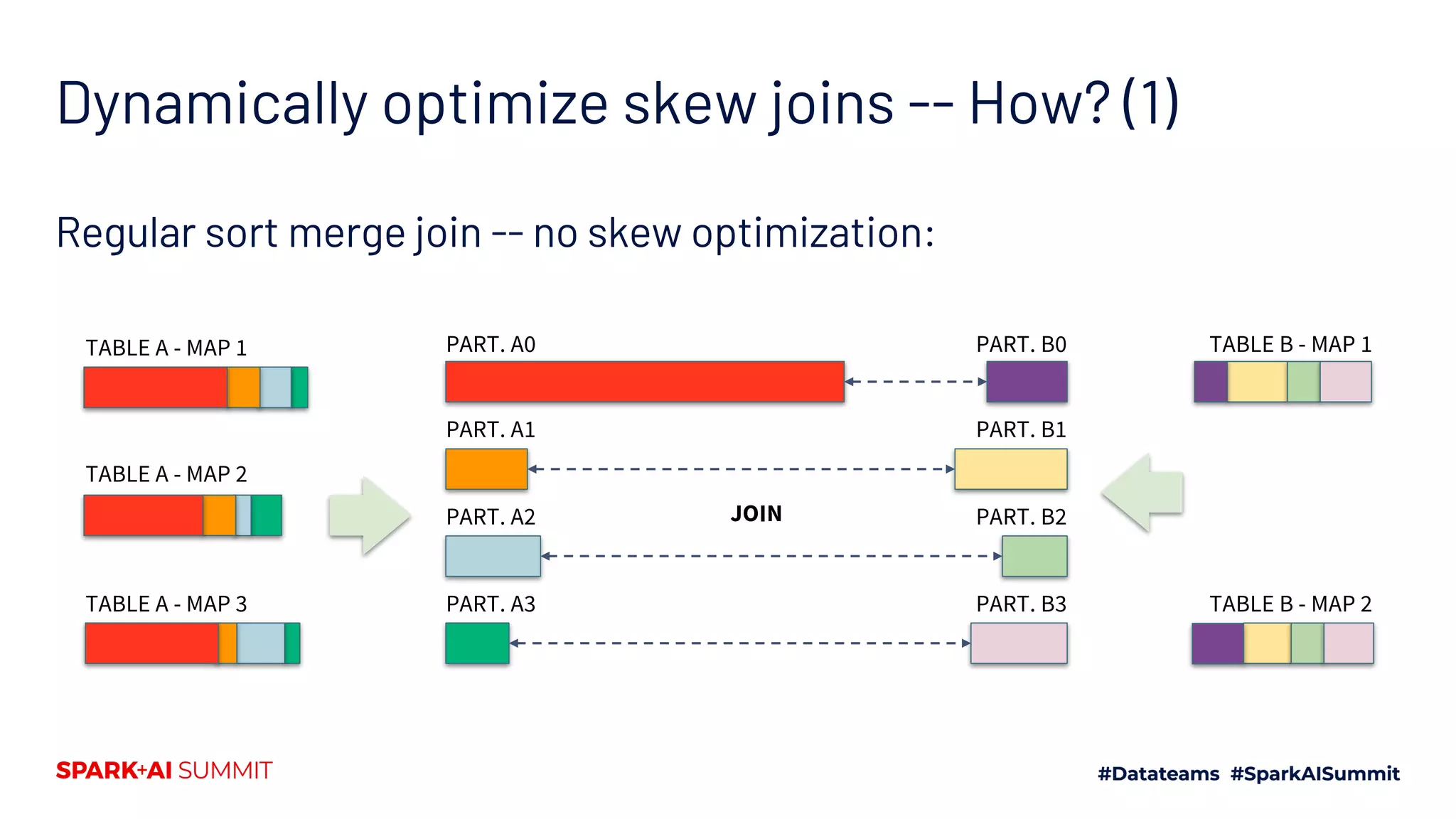
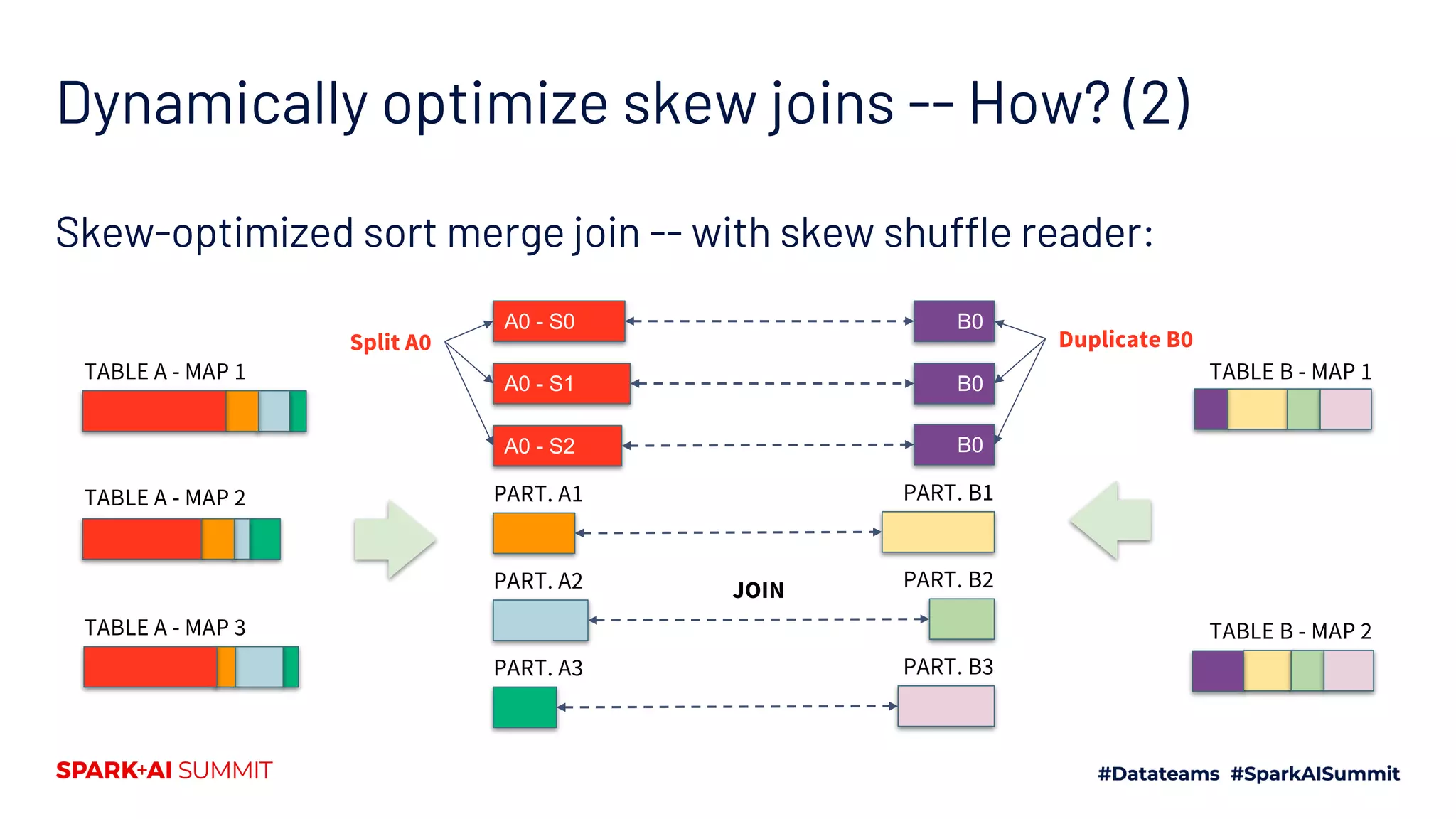
Describes data skew challenges during joins and how AQE automatically addresses skew using runtime statistics.
Presents background on the speakers, highlighting their roles in Big Data and contributions to Spark.
Encourages viewers to try the AQE features using a Databricks notebook.
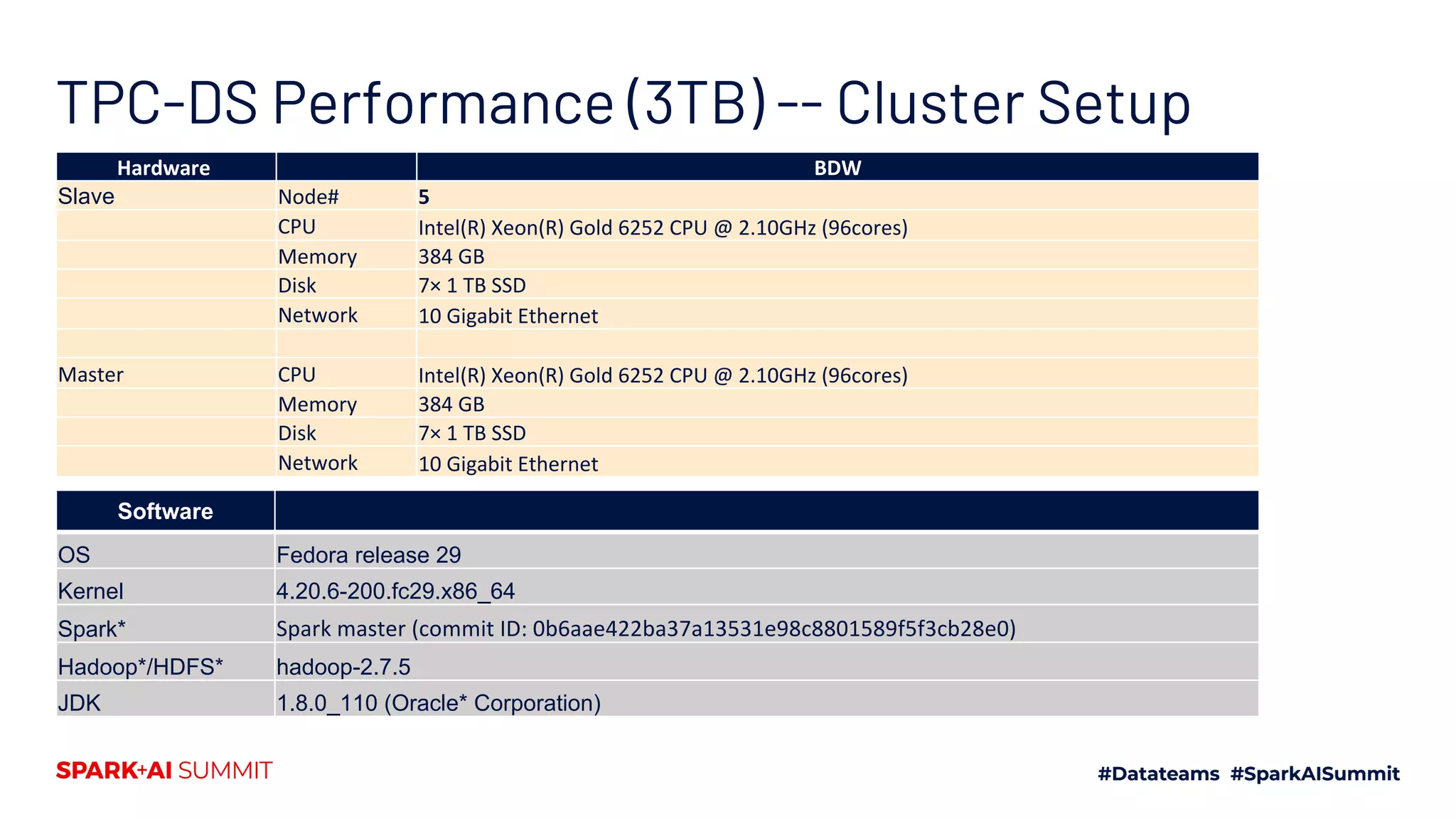
Details hardware setups, results, and performance improvements achieved with AQE over traditional methods.
Examines performance results from real-world implementations of AQE, showcasing improvements in various production environments.
Shares detailed performance metrics on skew join optimization, illustrating significant speed enhancements achieved with AQE.
Encourages audience feedback on the session, emphasizing its importance for improvement.