Downloaded 39 times




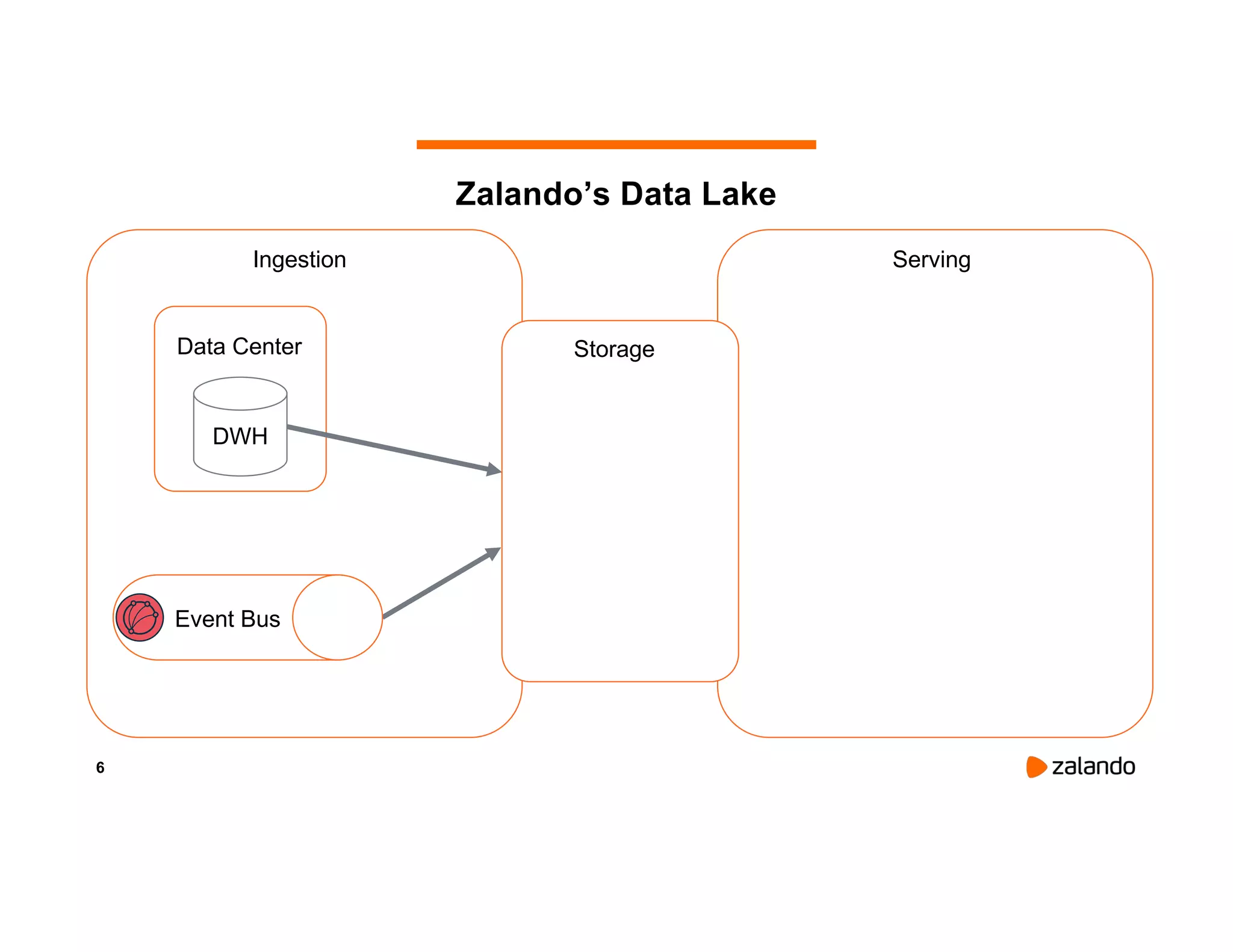
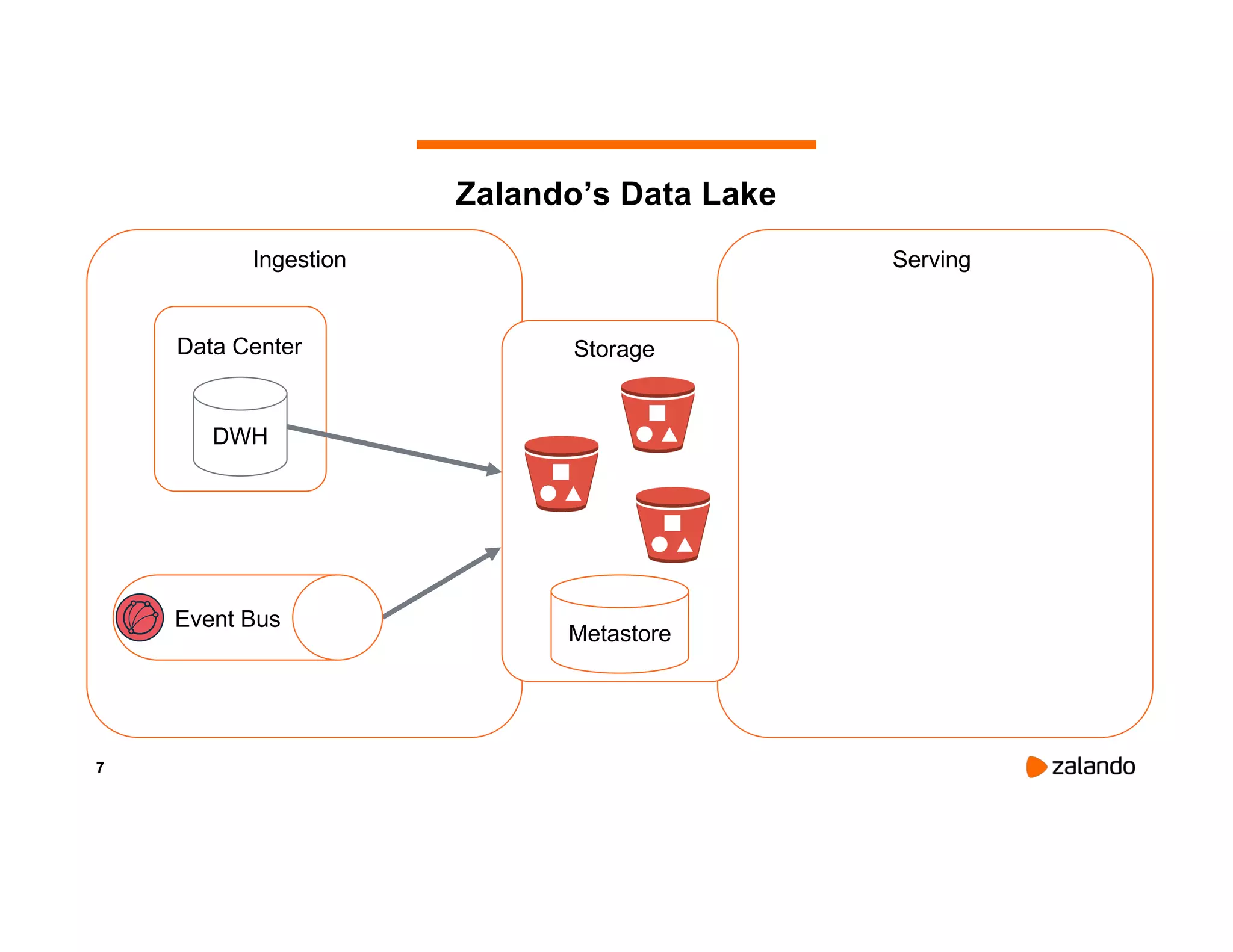
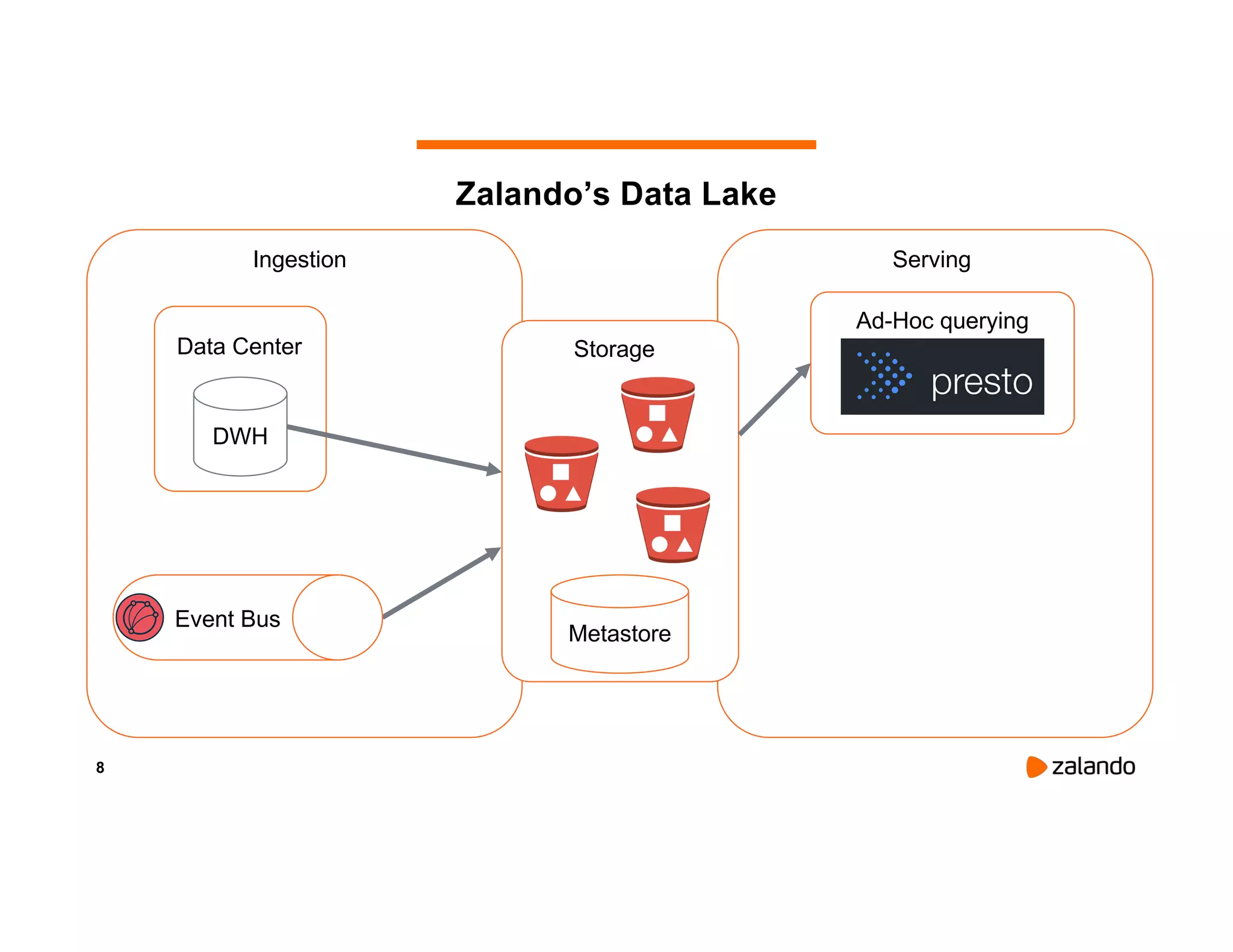
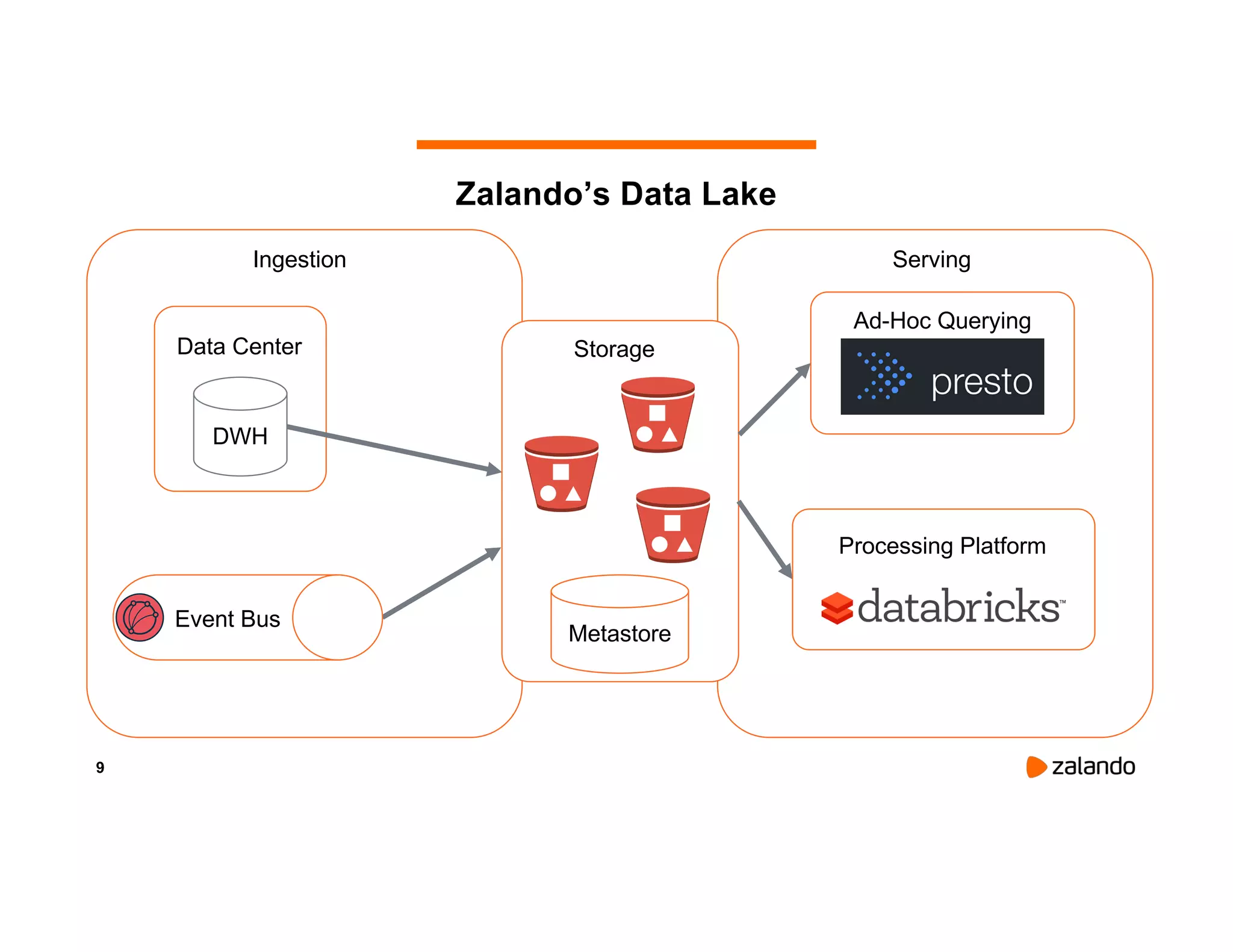
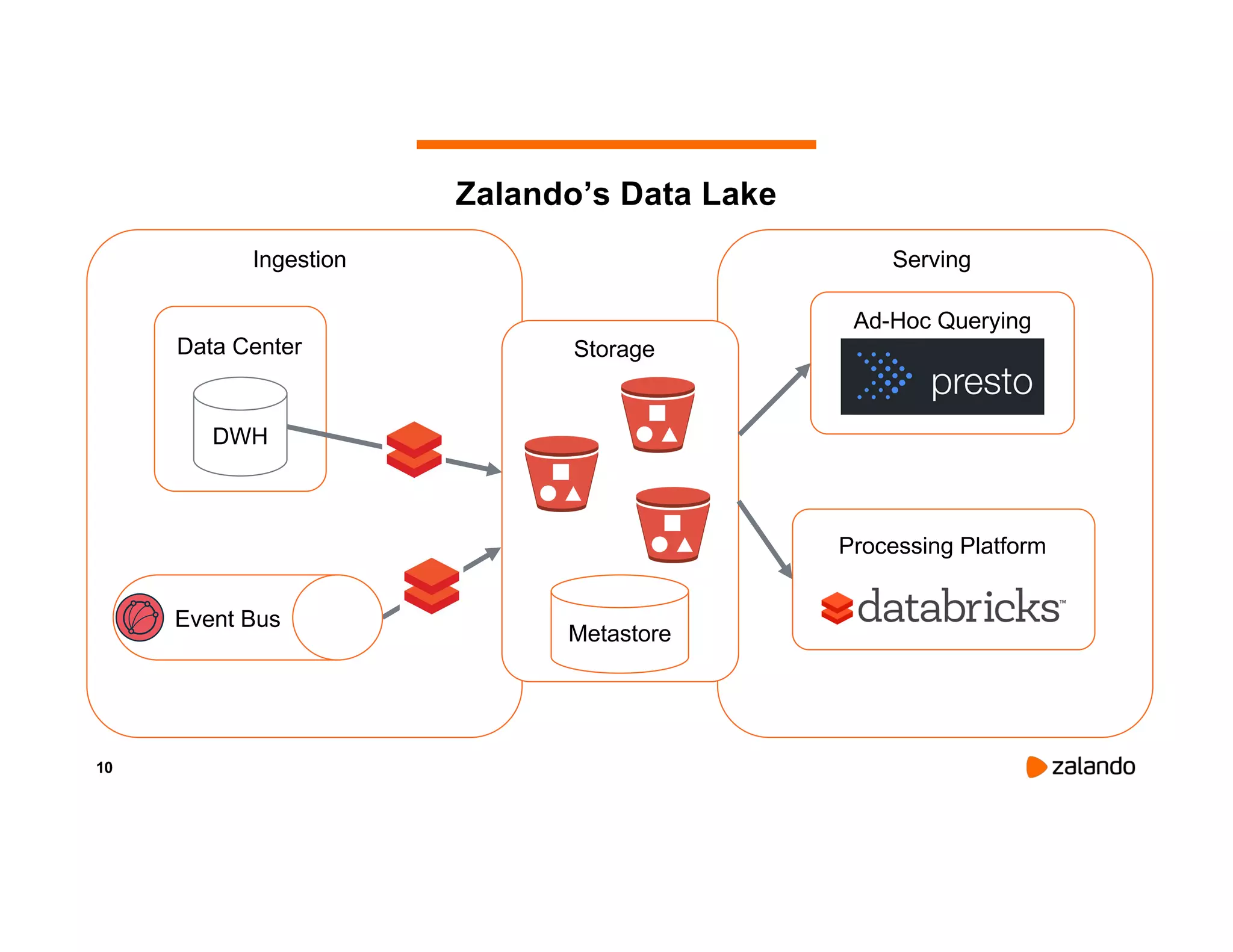

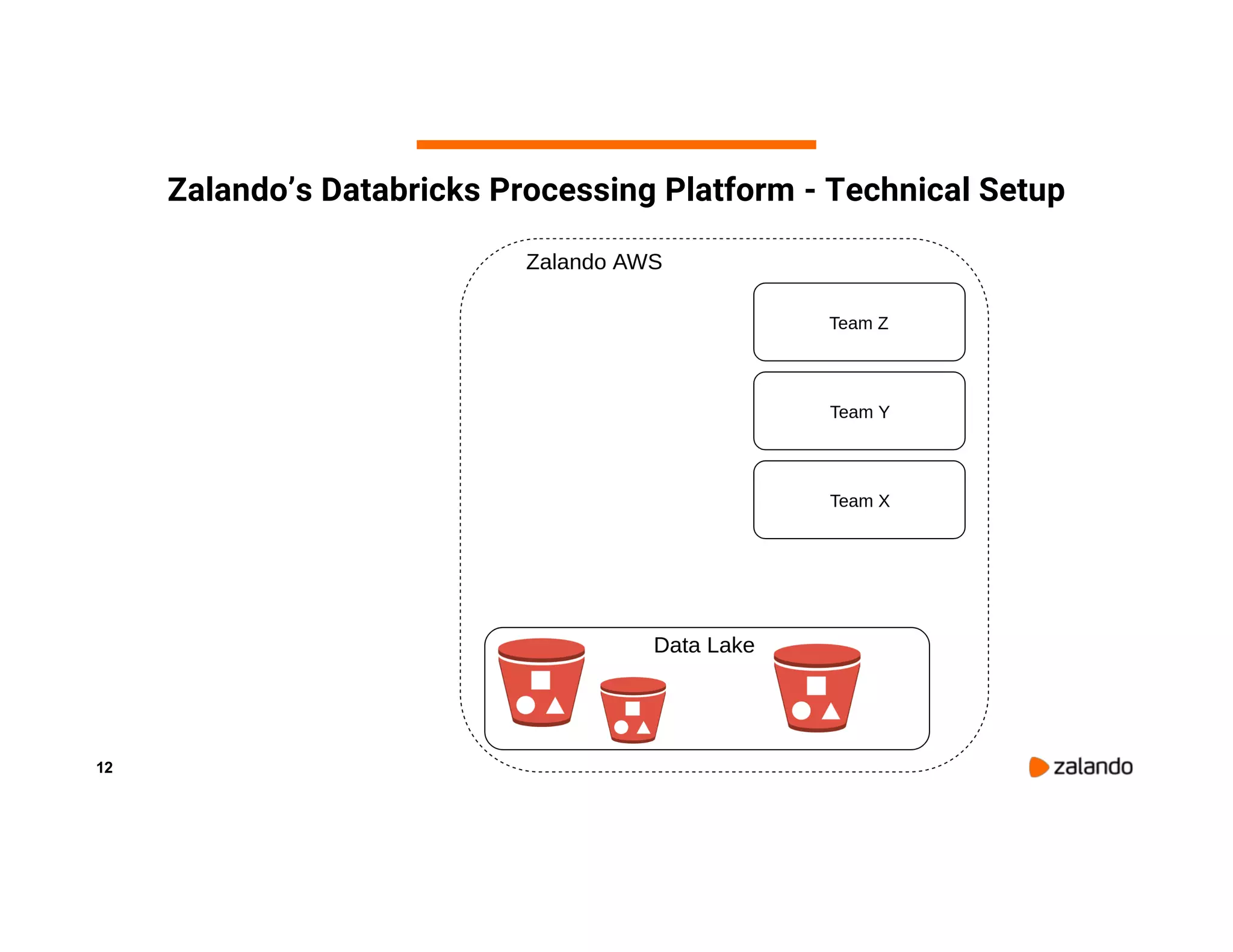
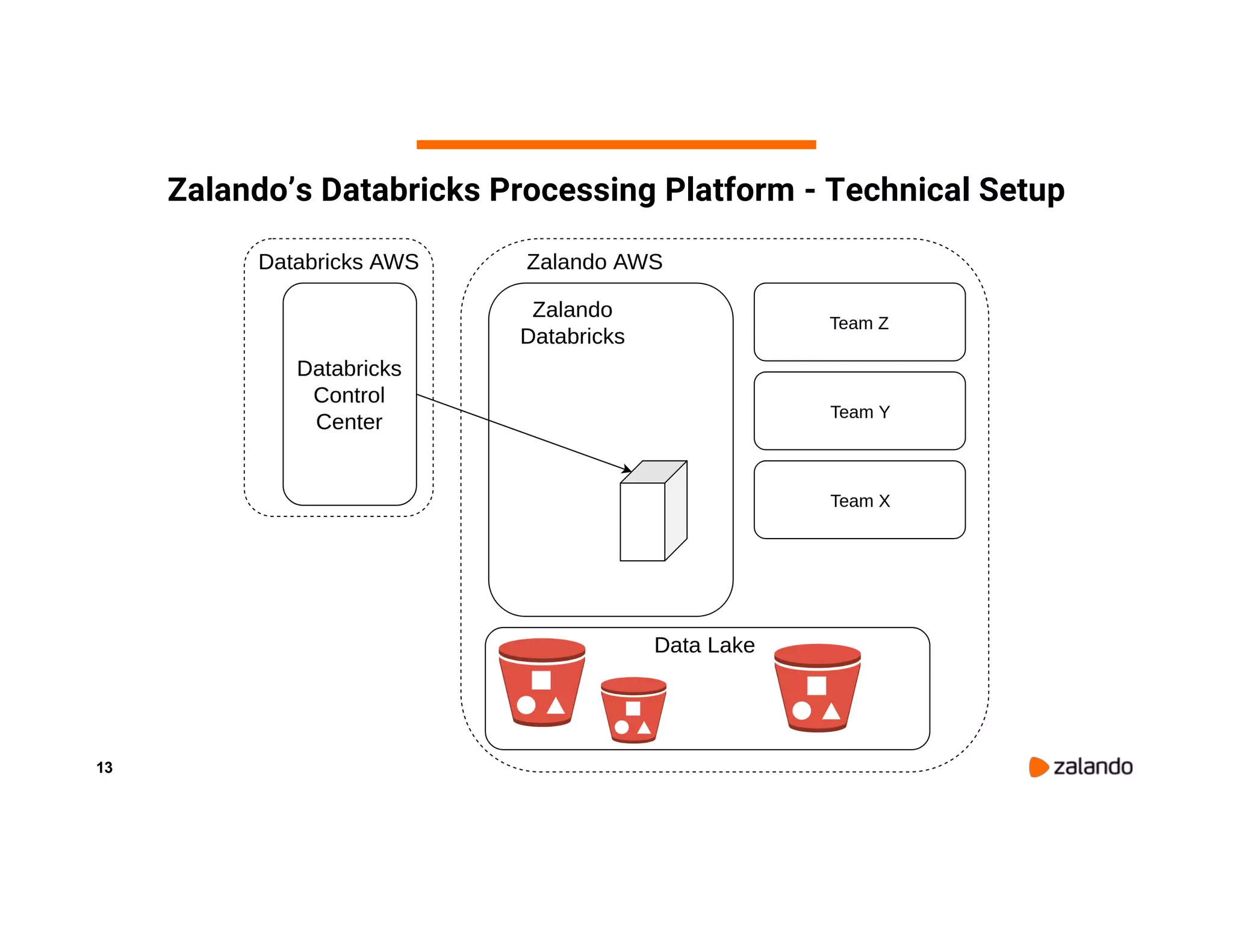
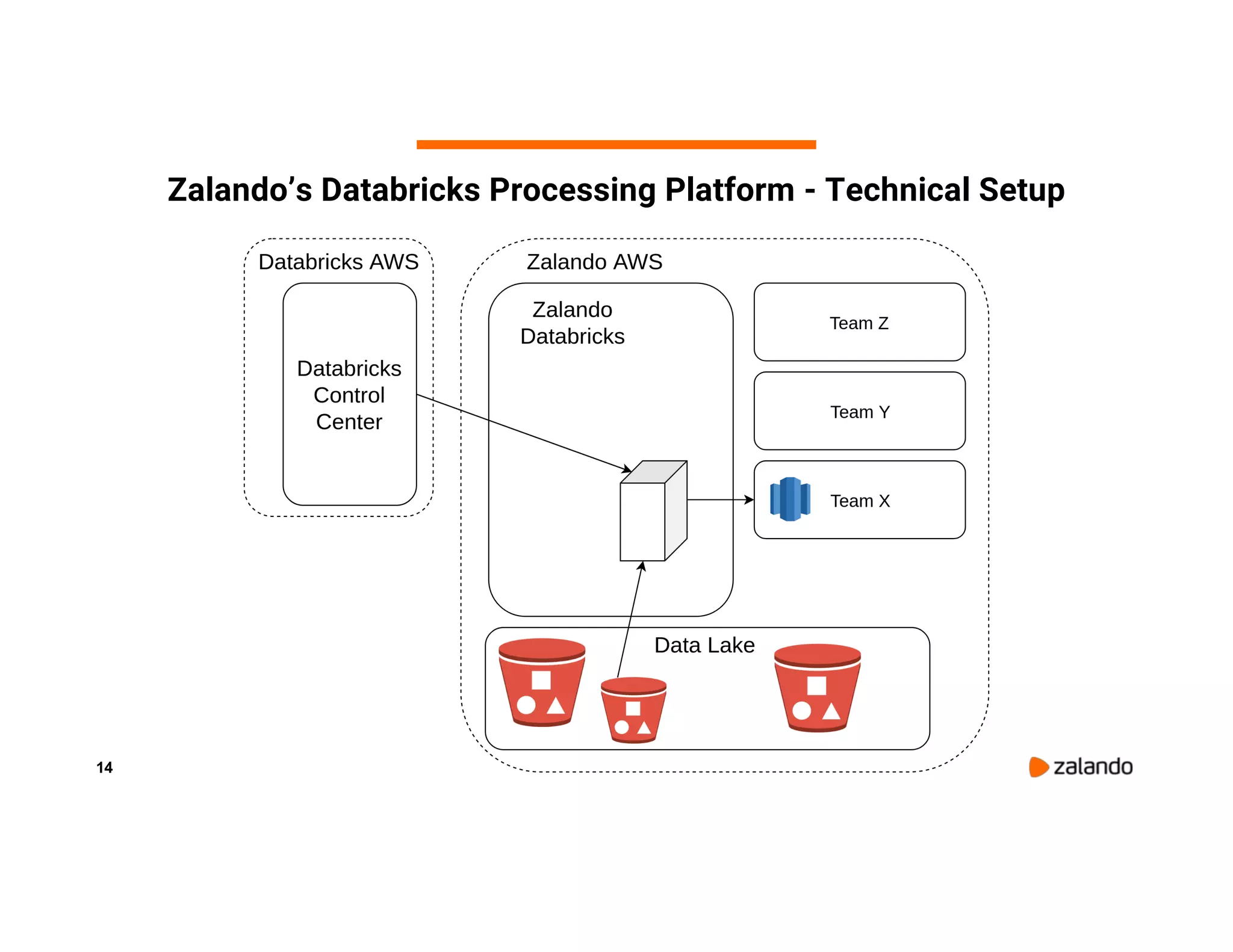
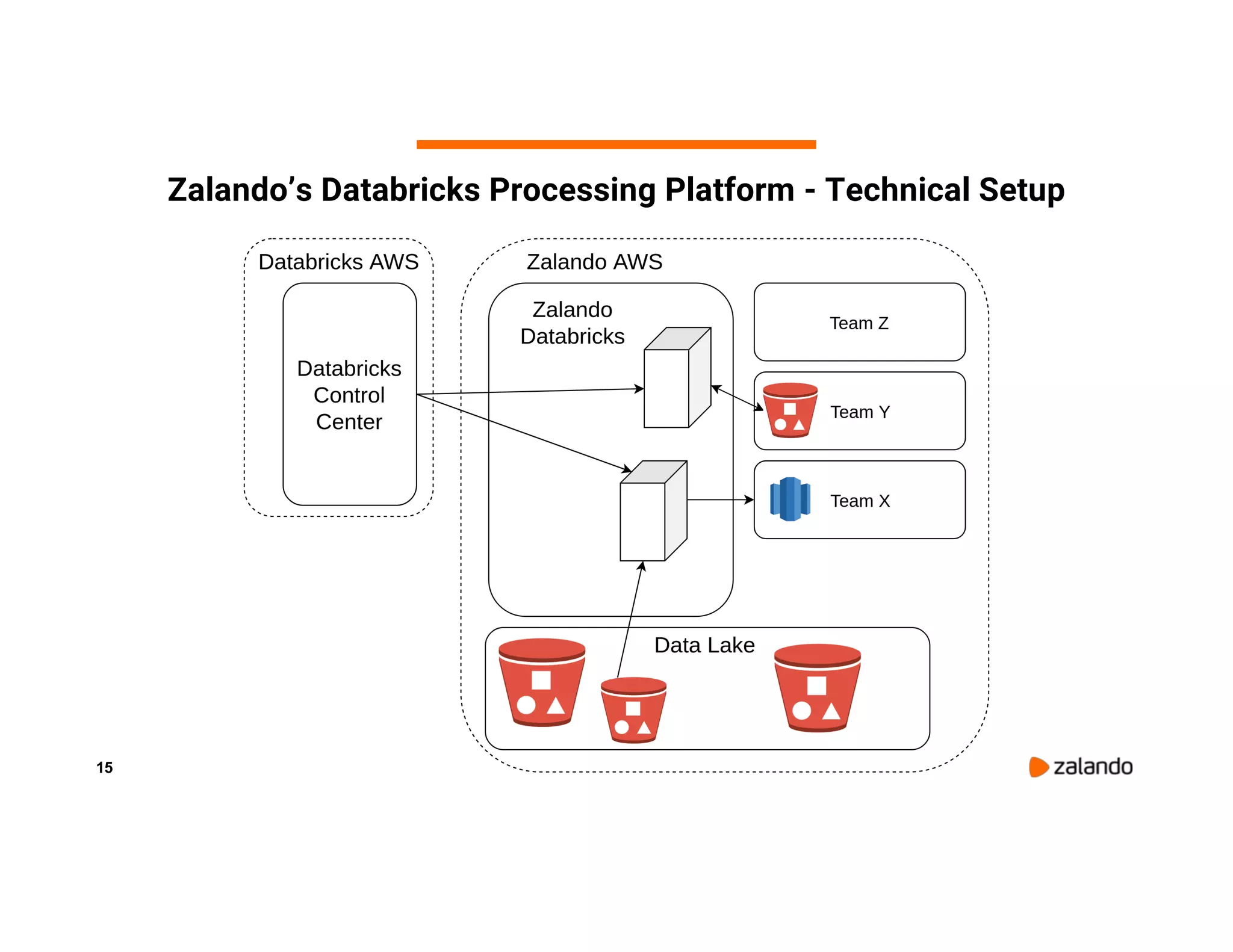
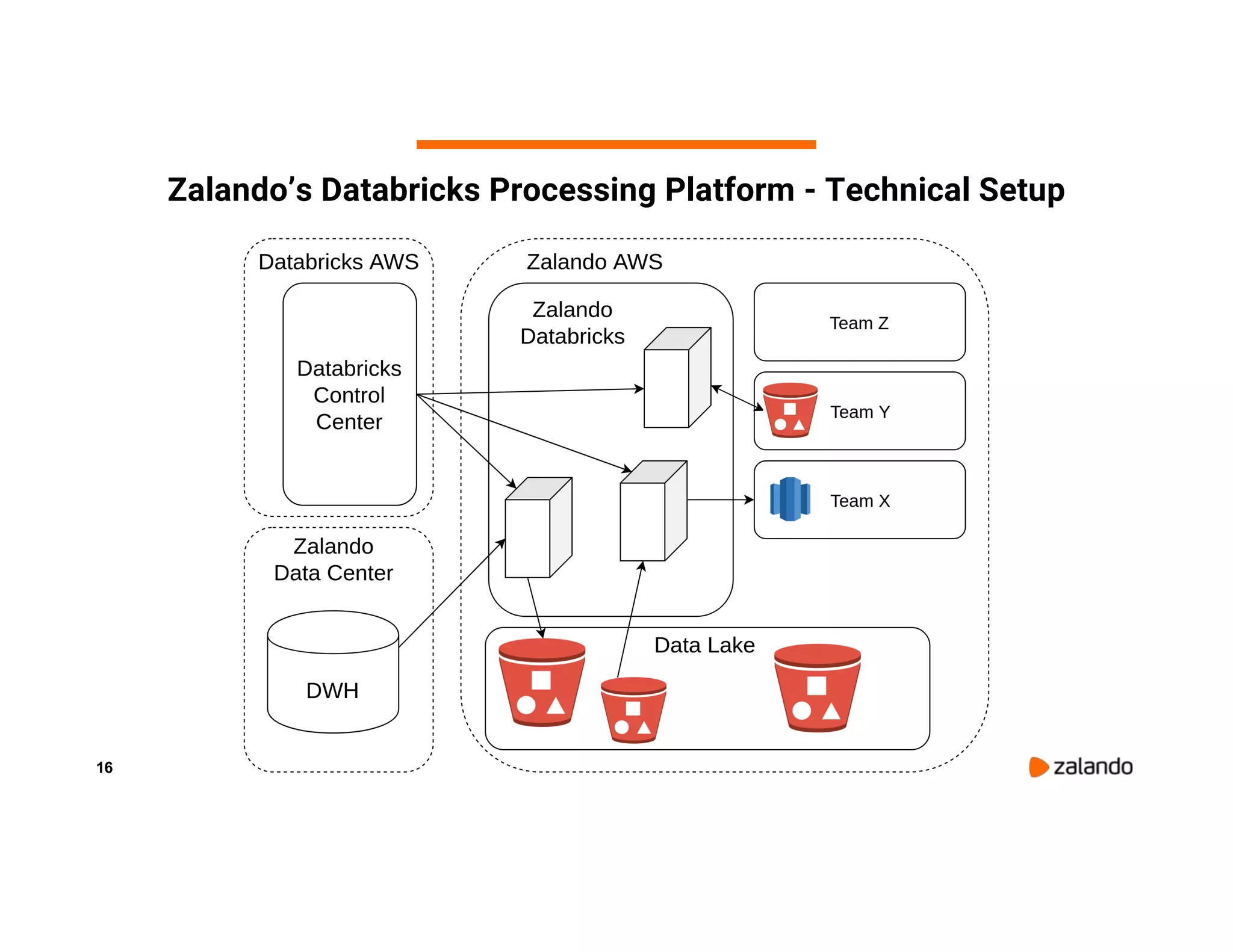


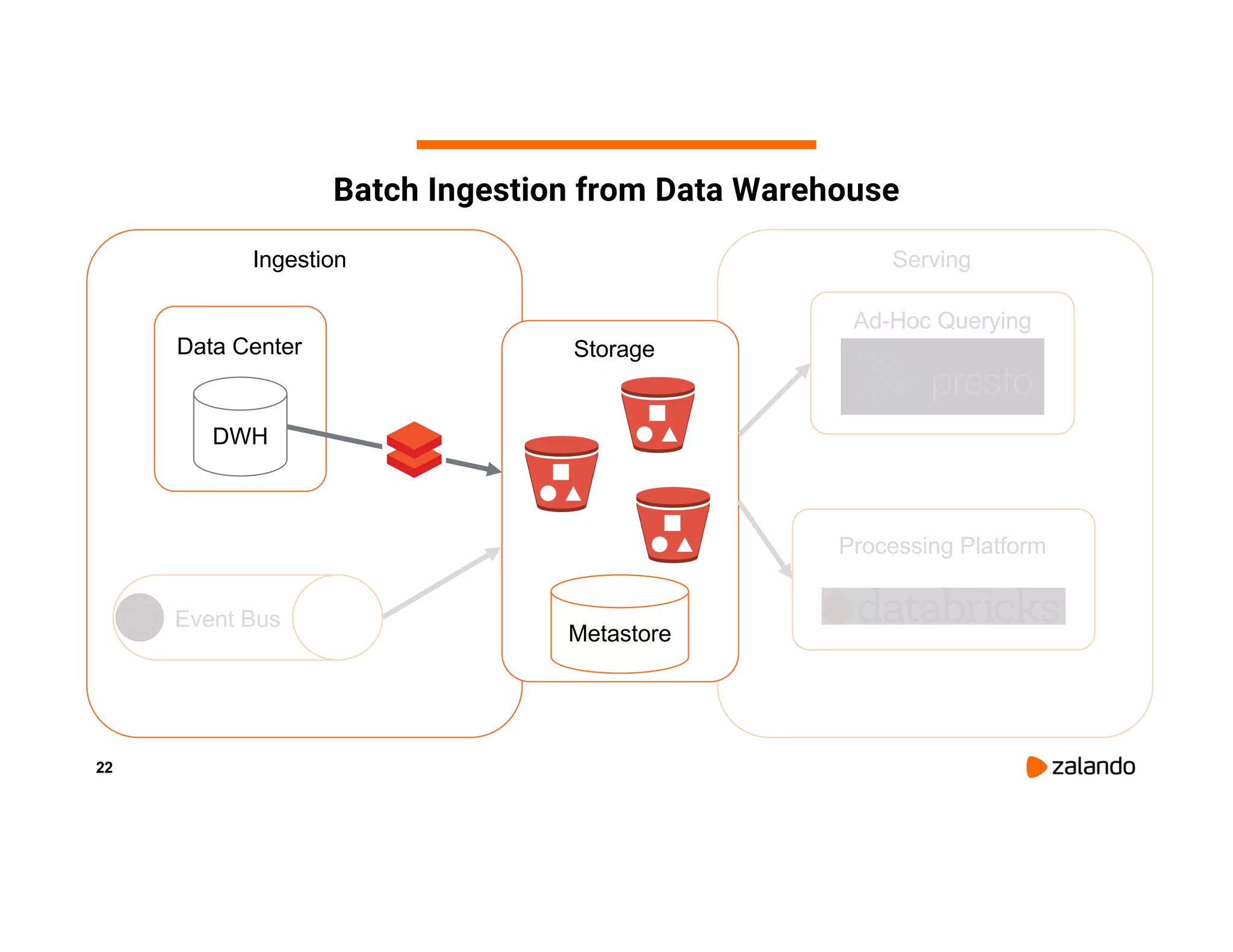
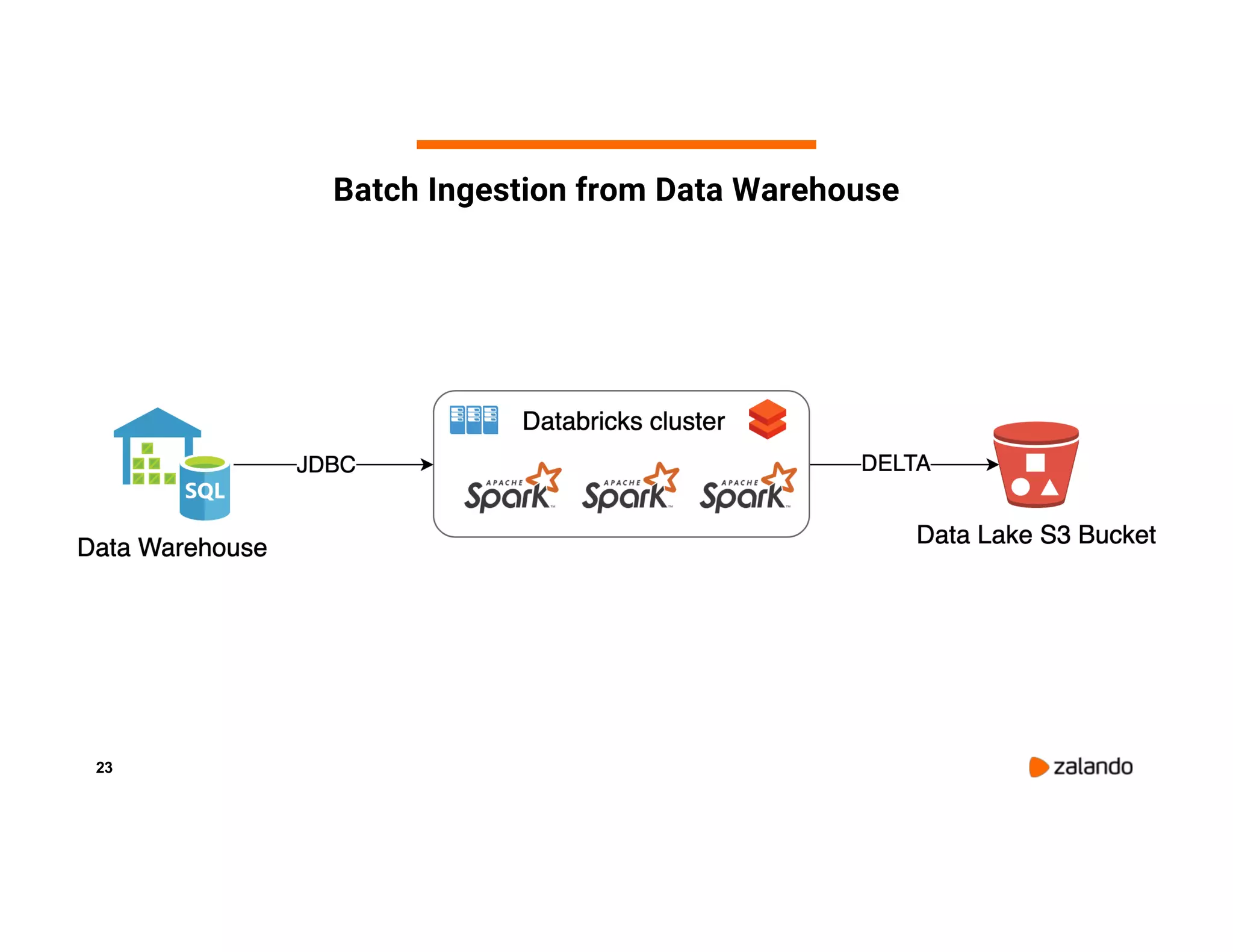






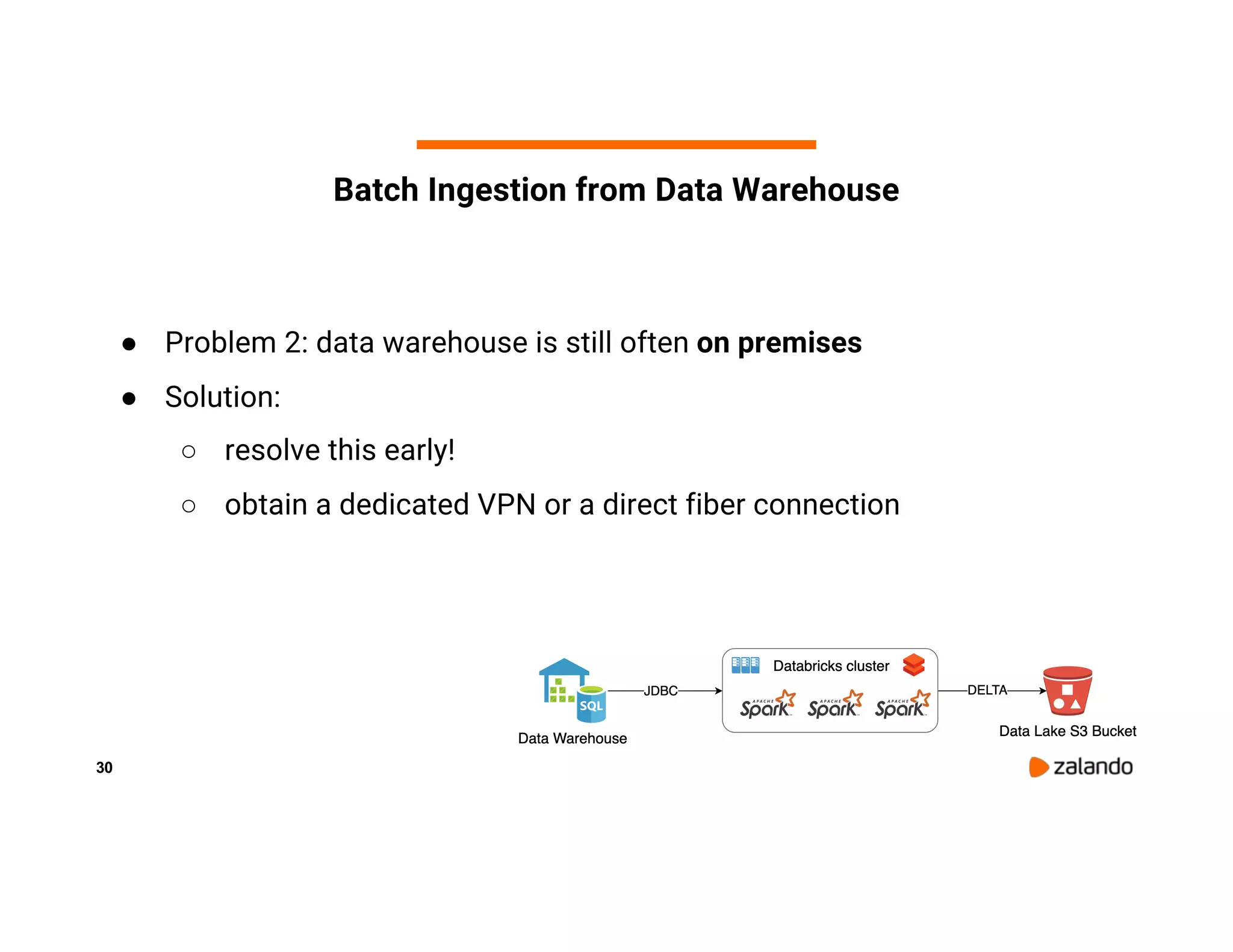
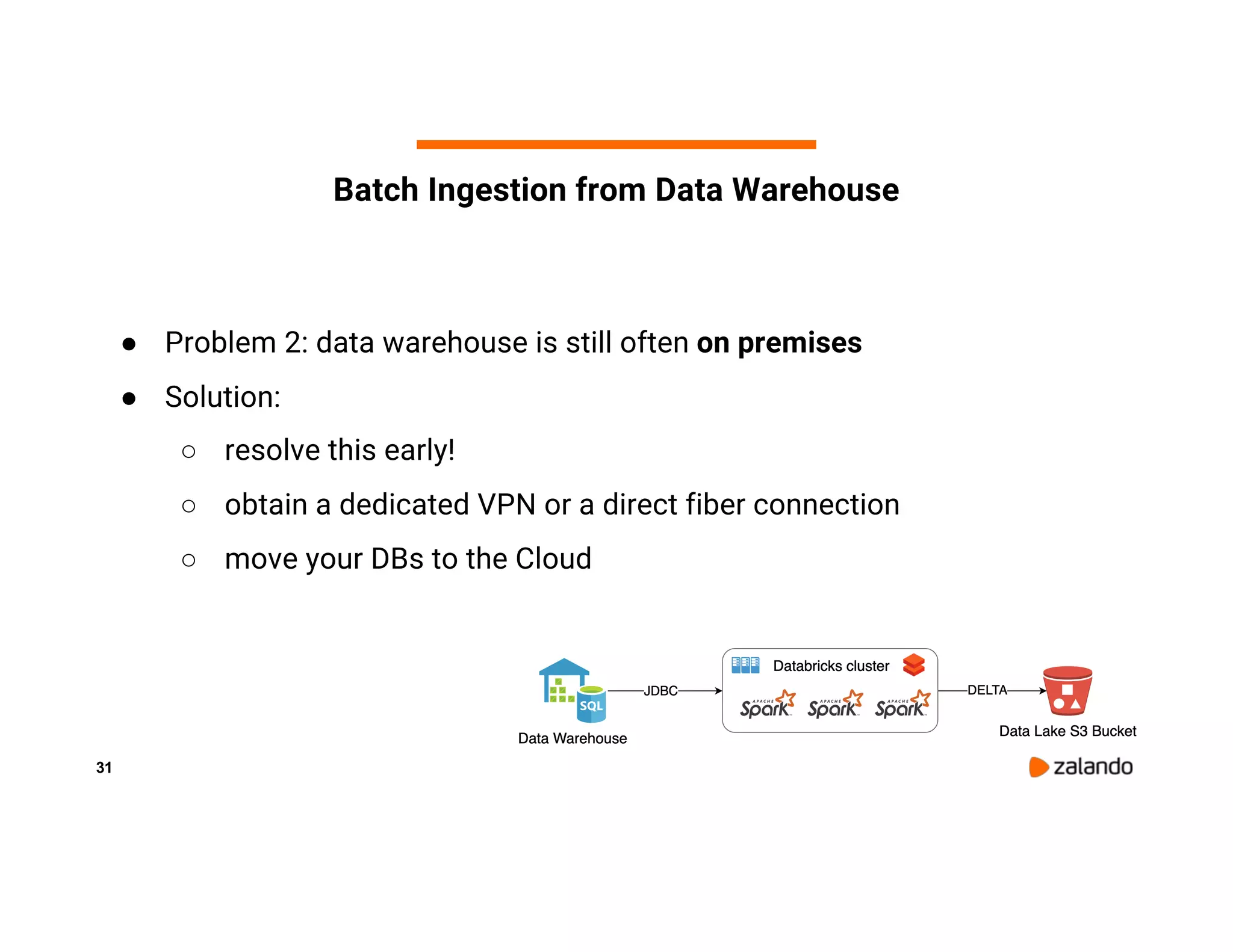



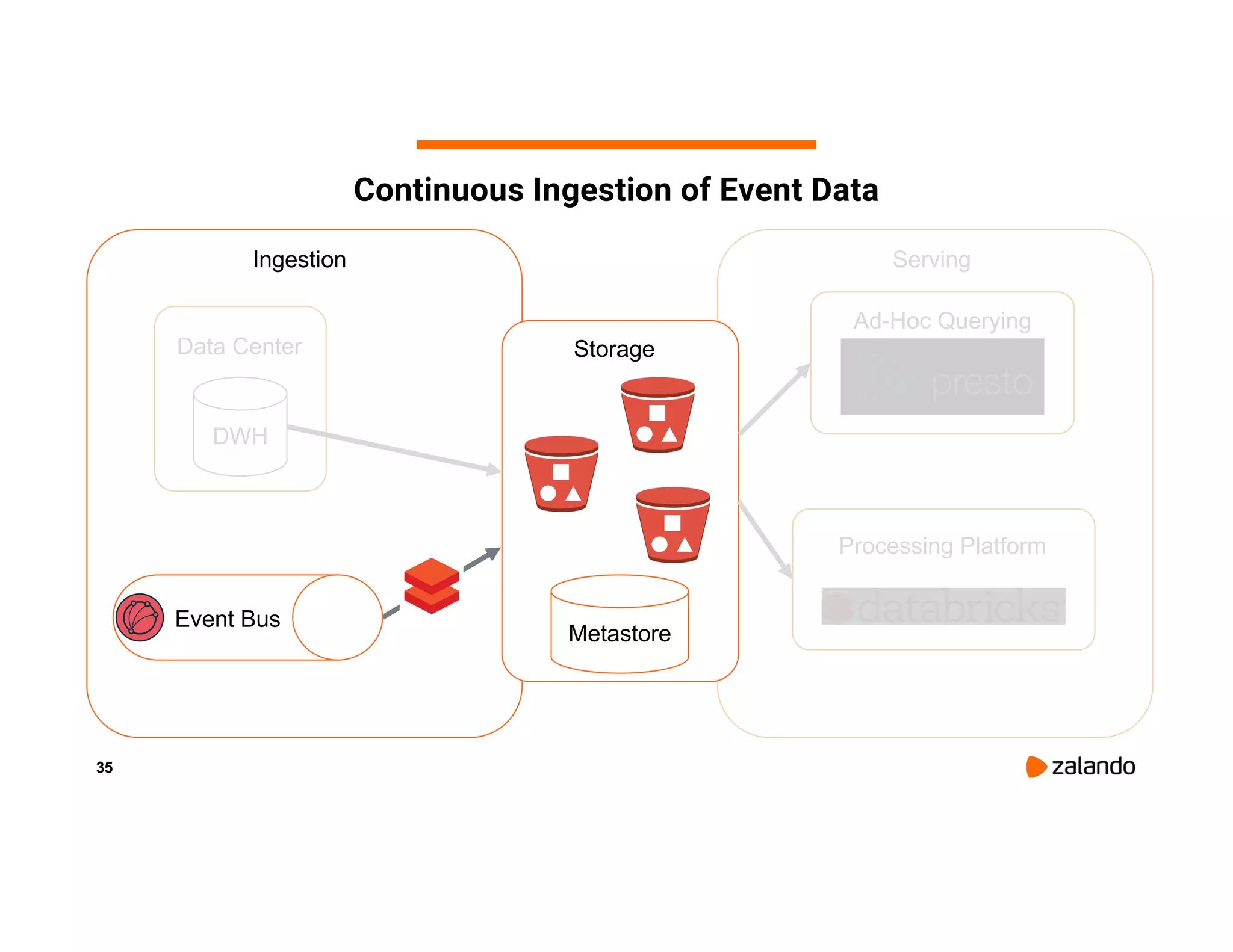
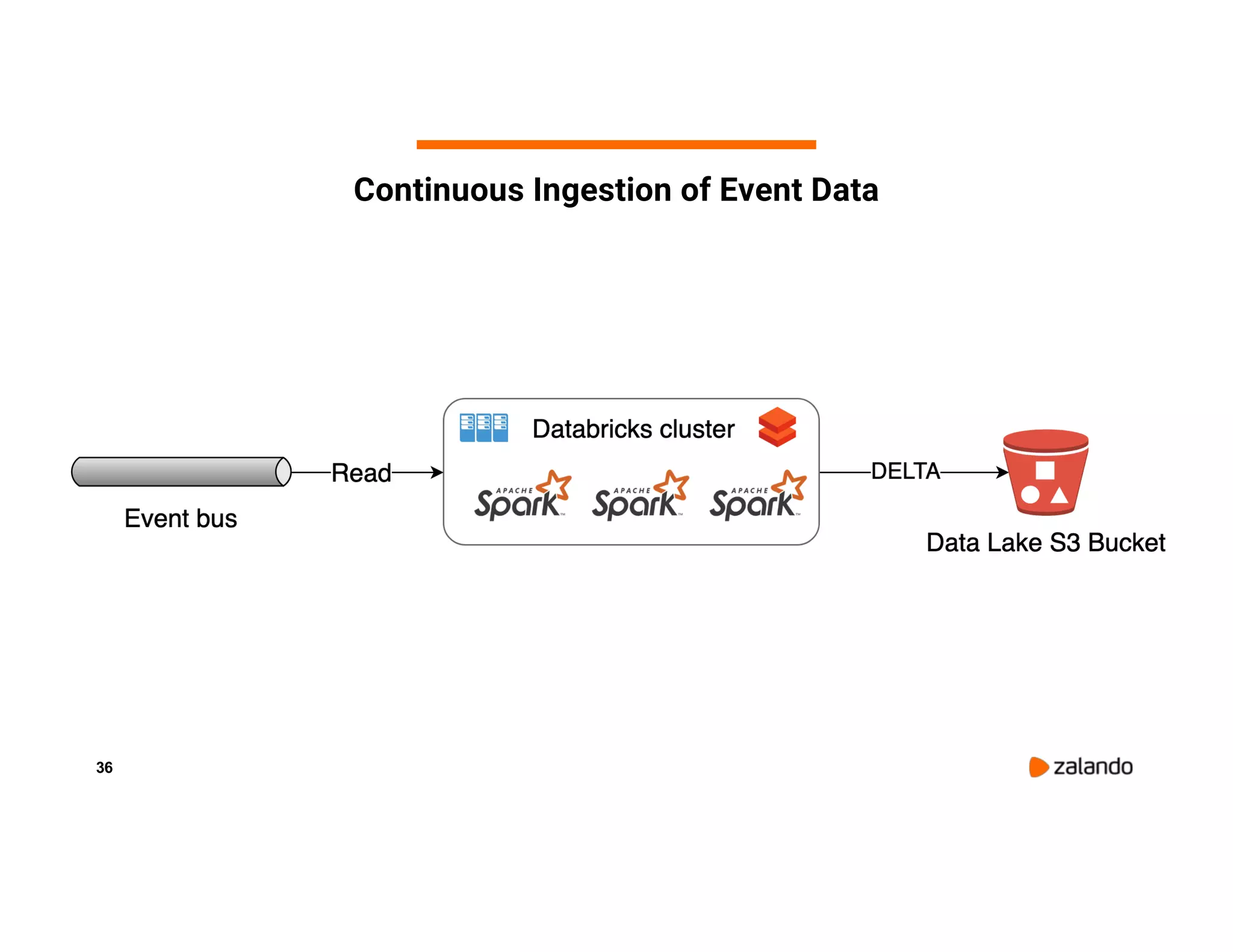

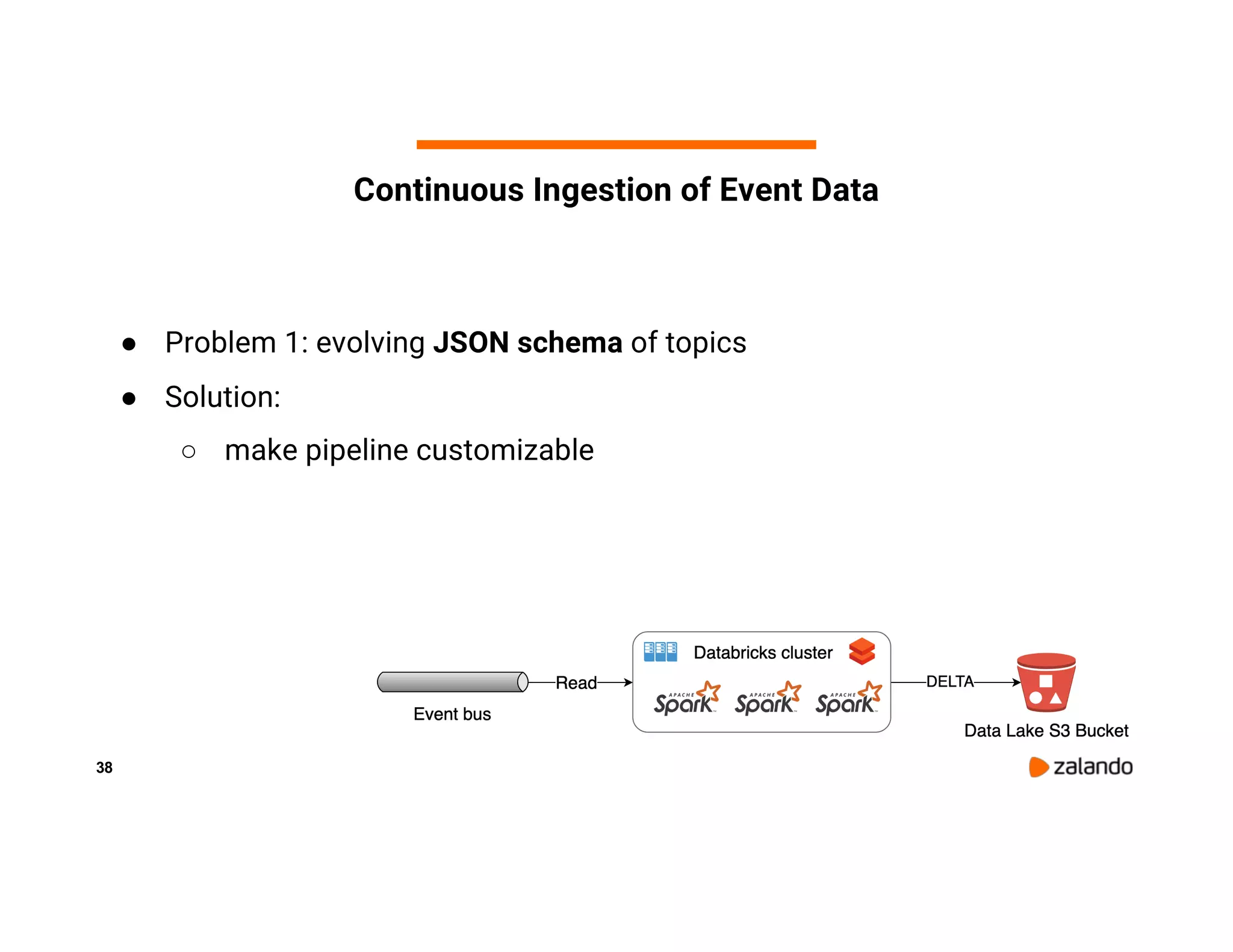

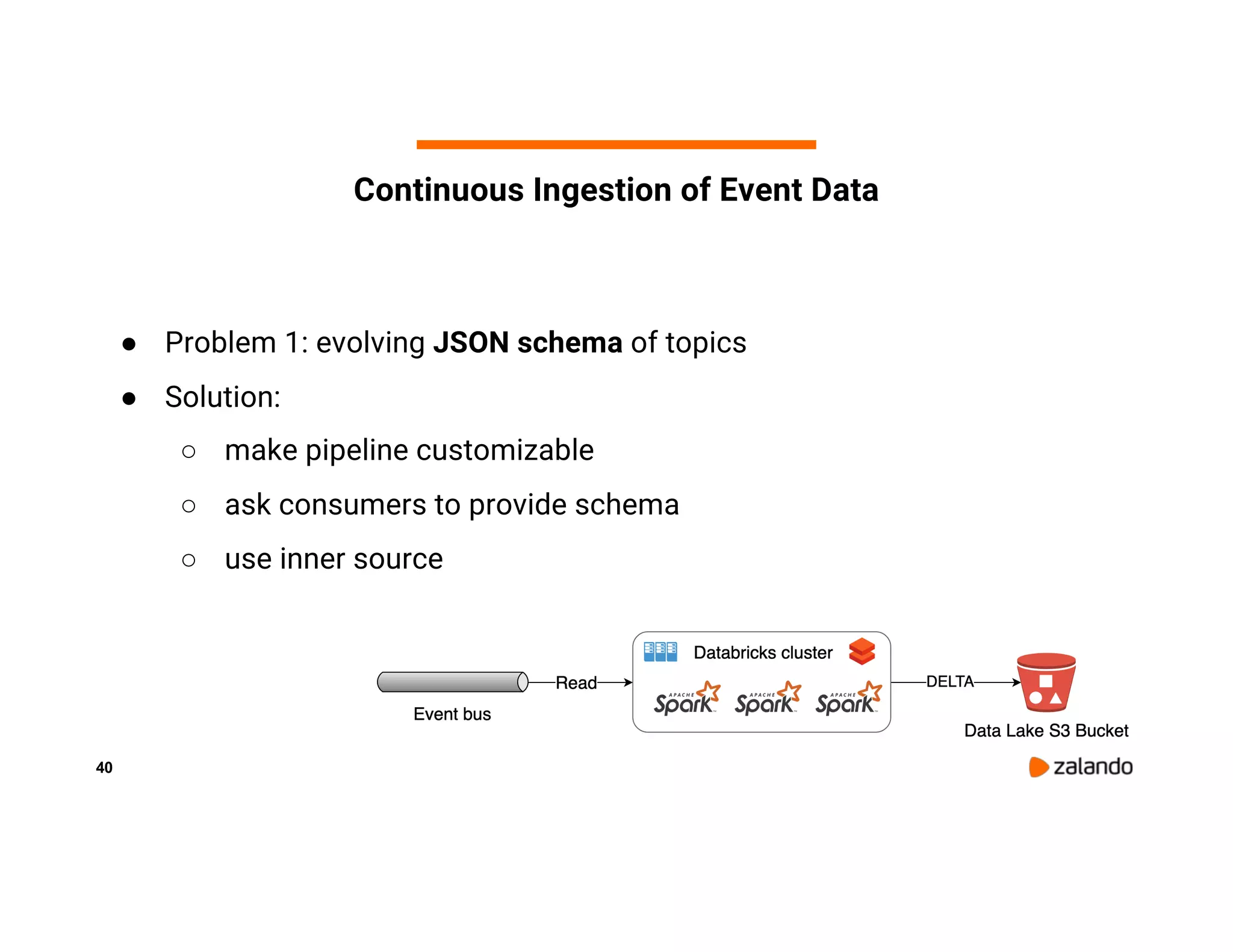



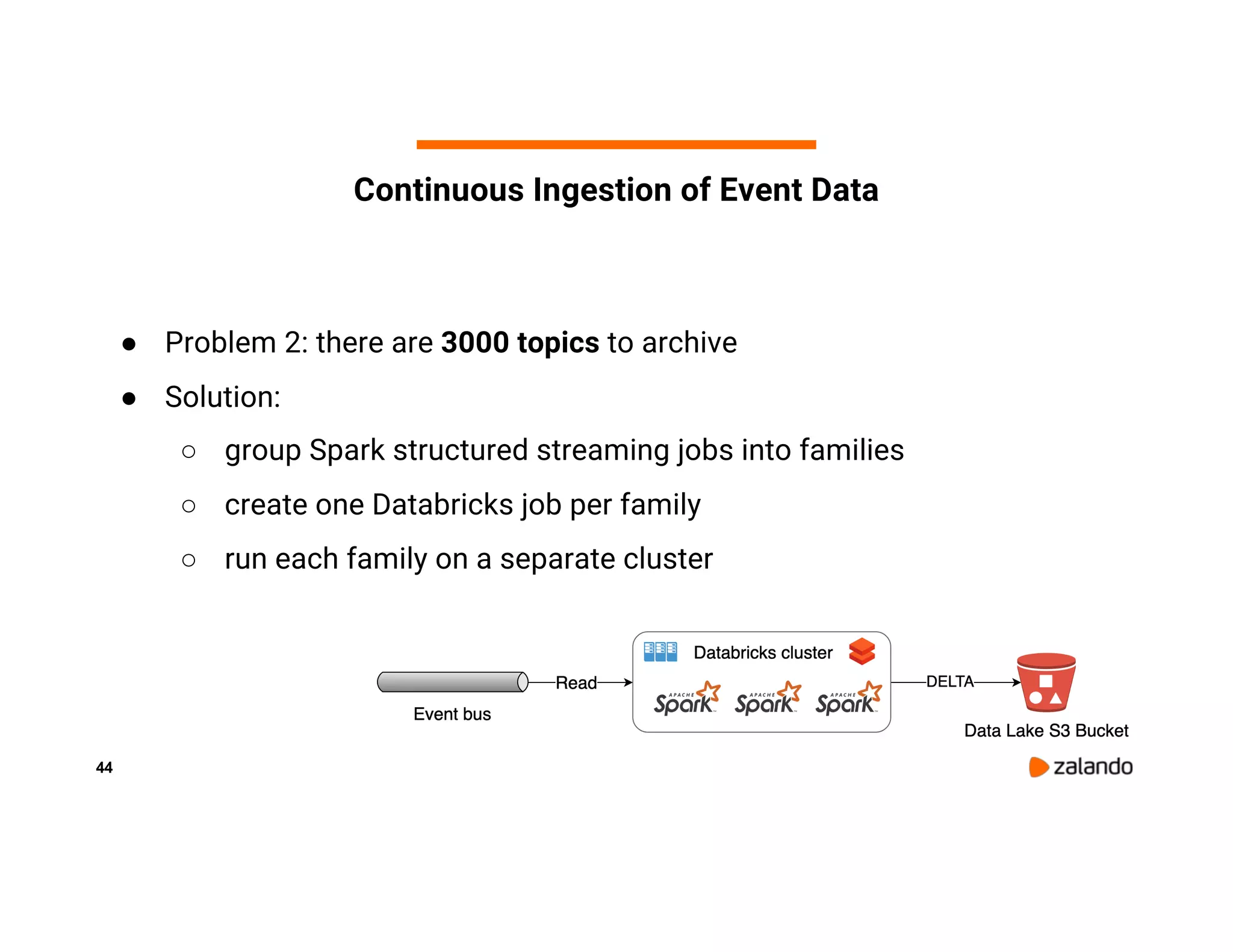



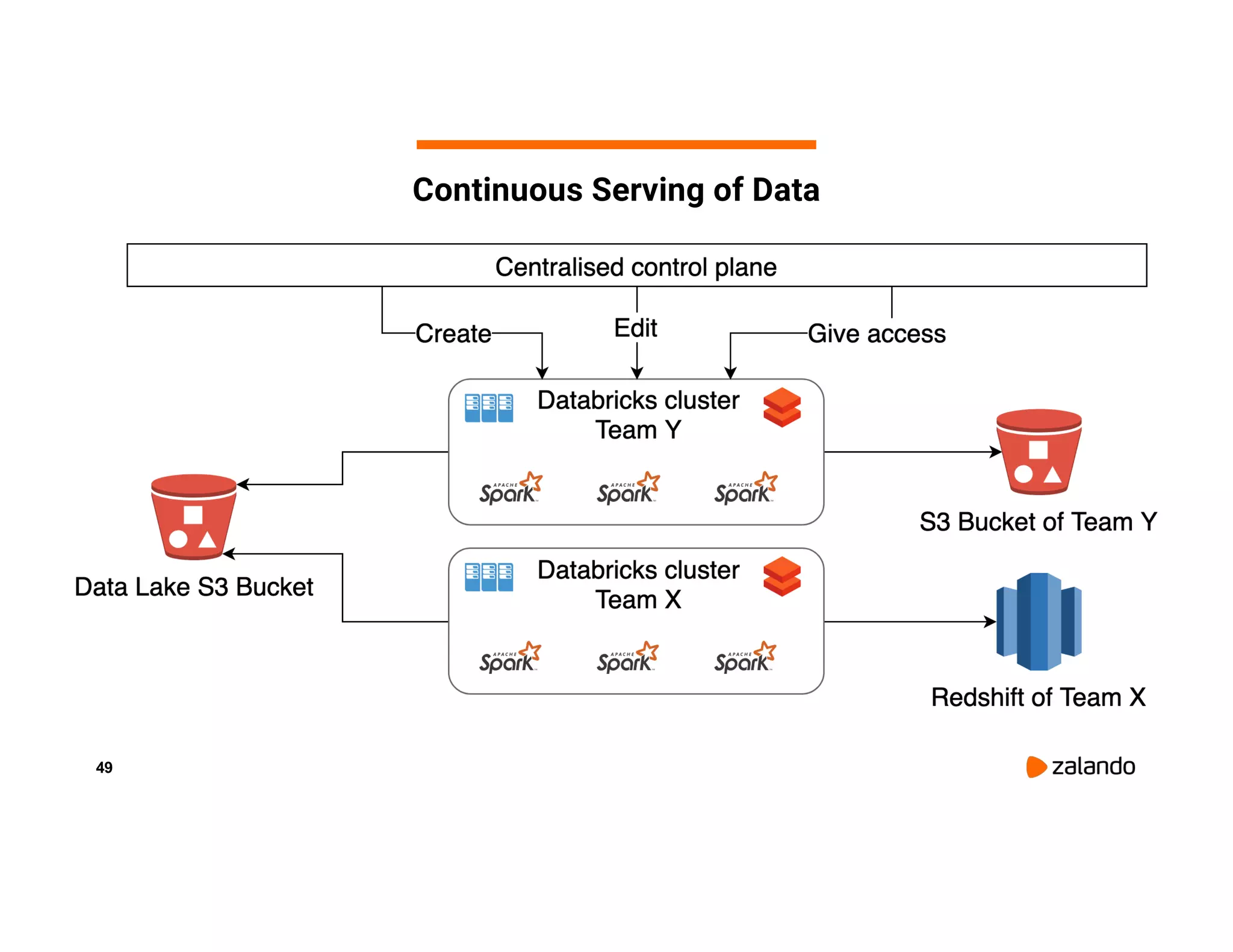
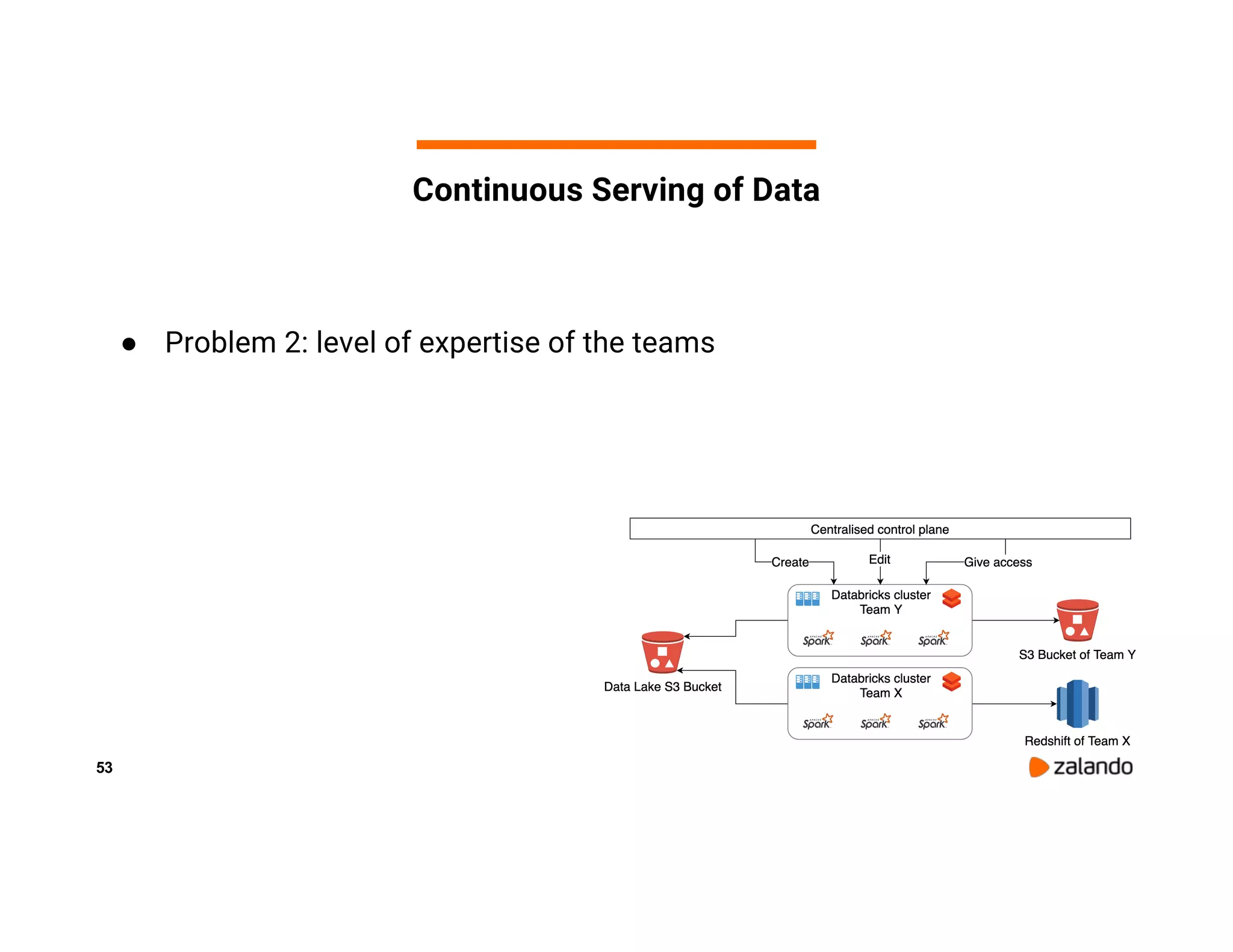
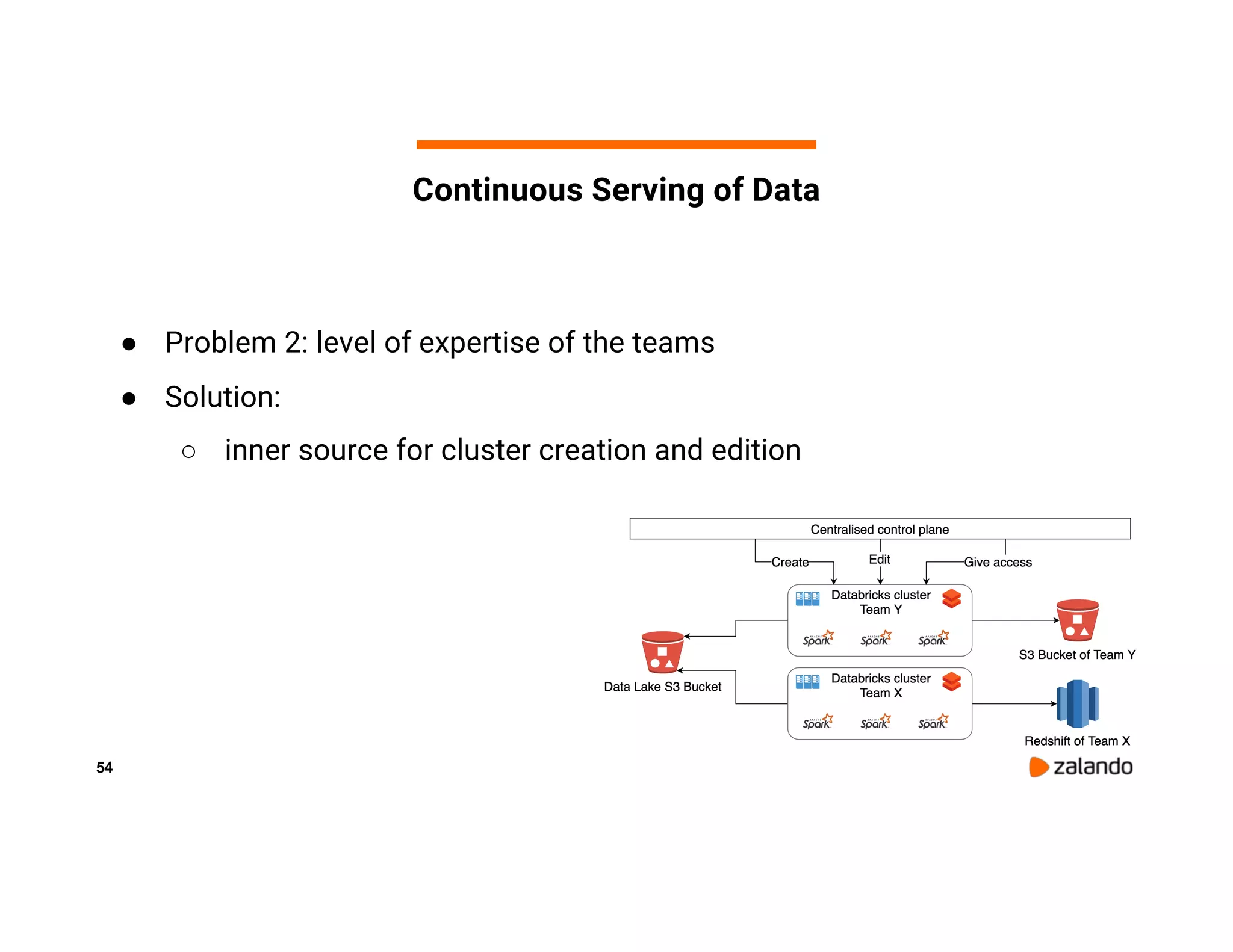
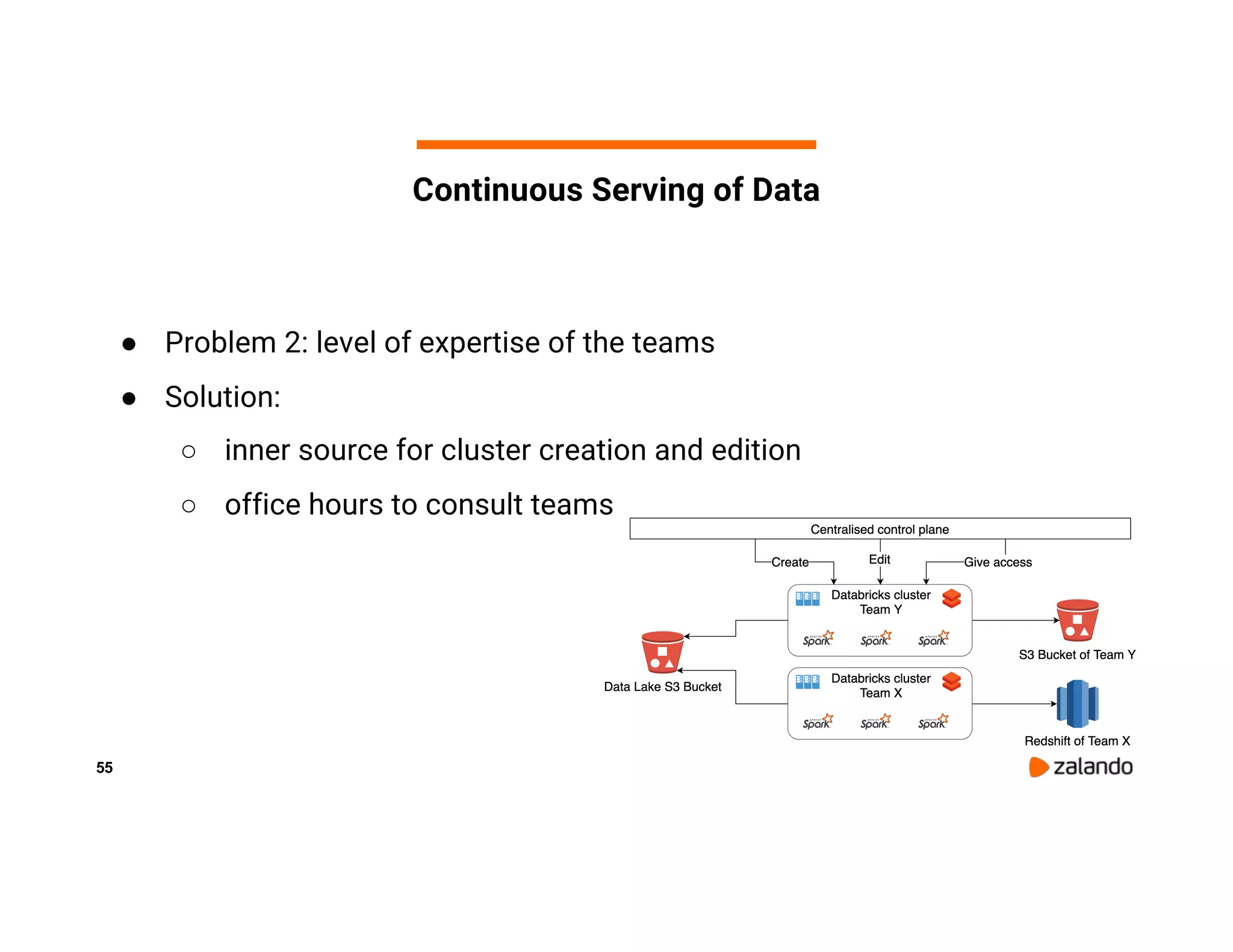
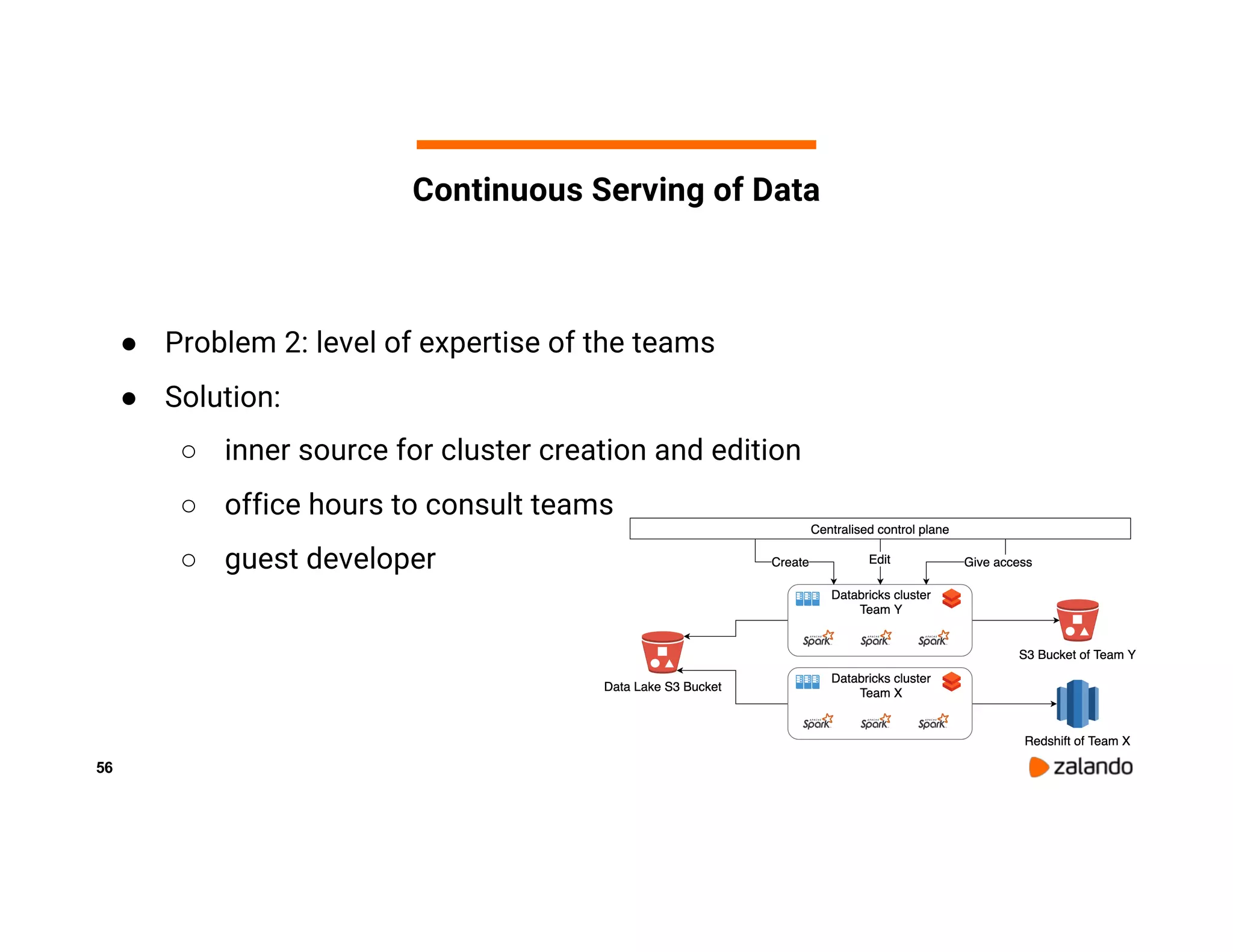
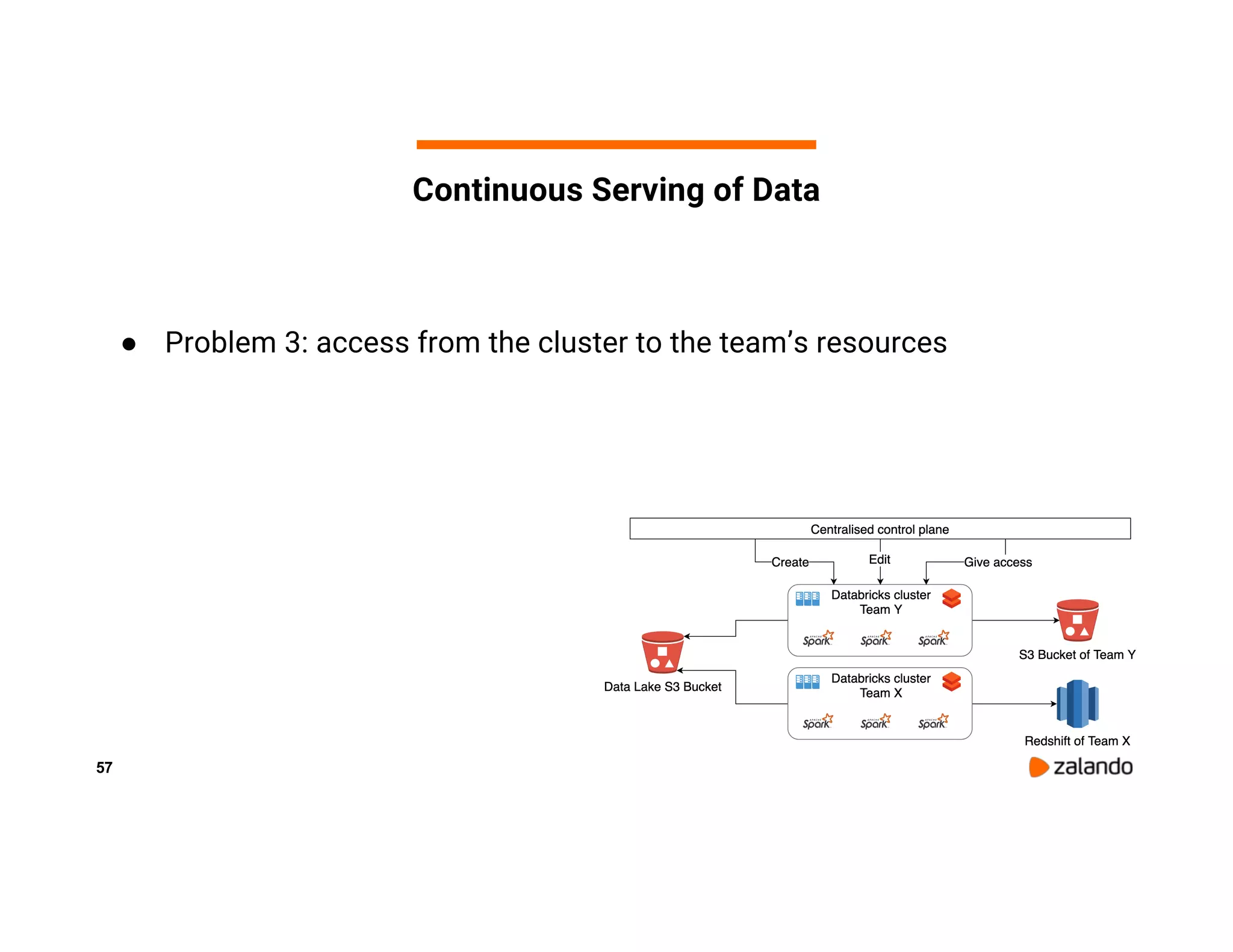
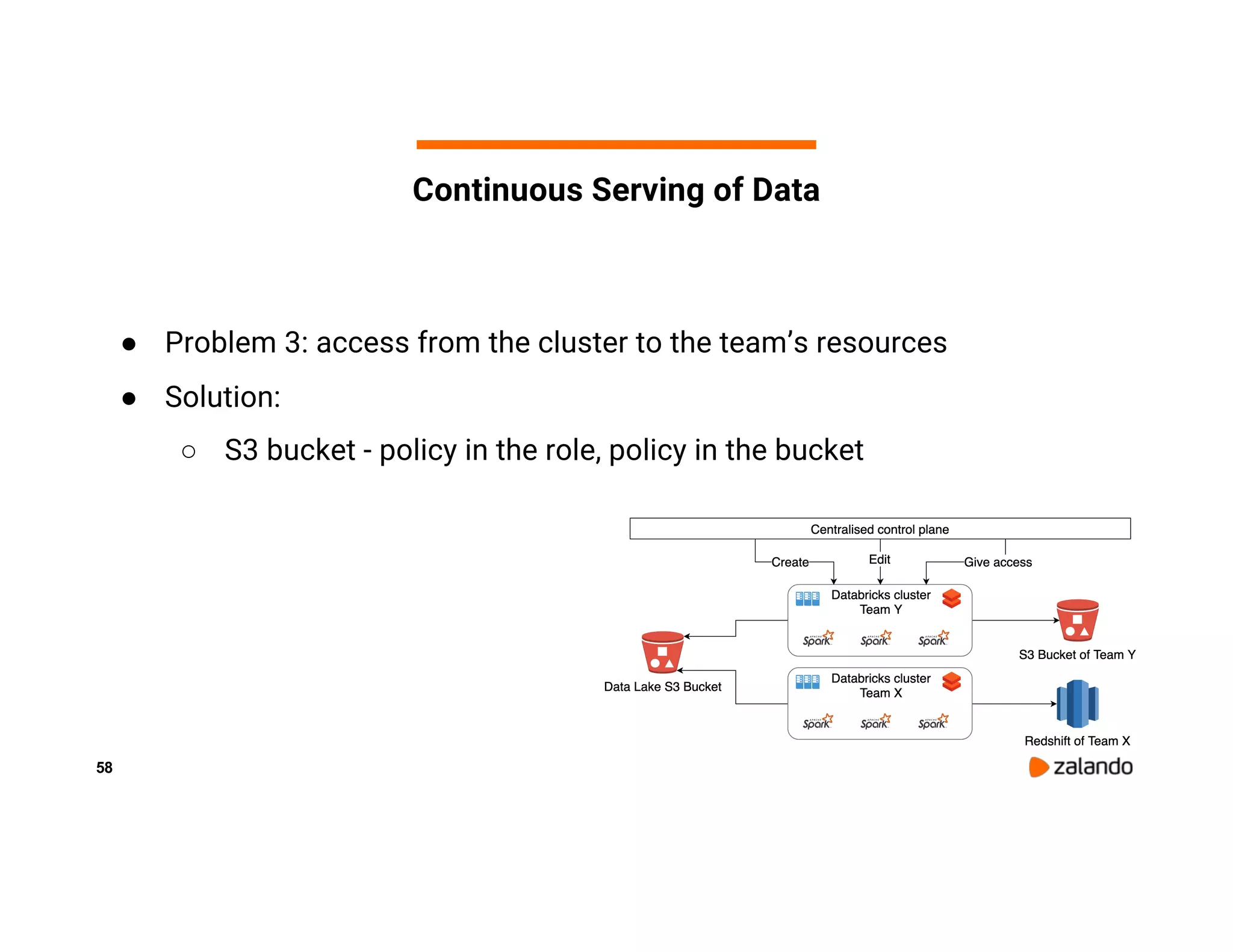
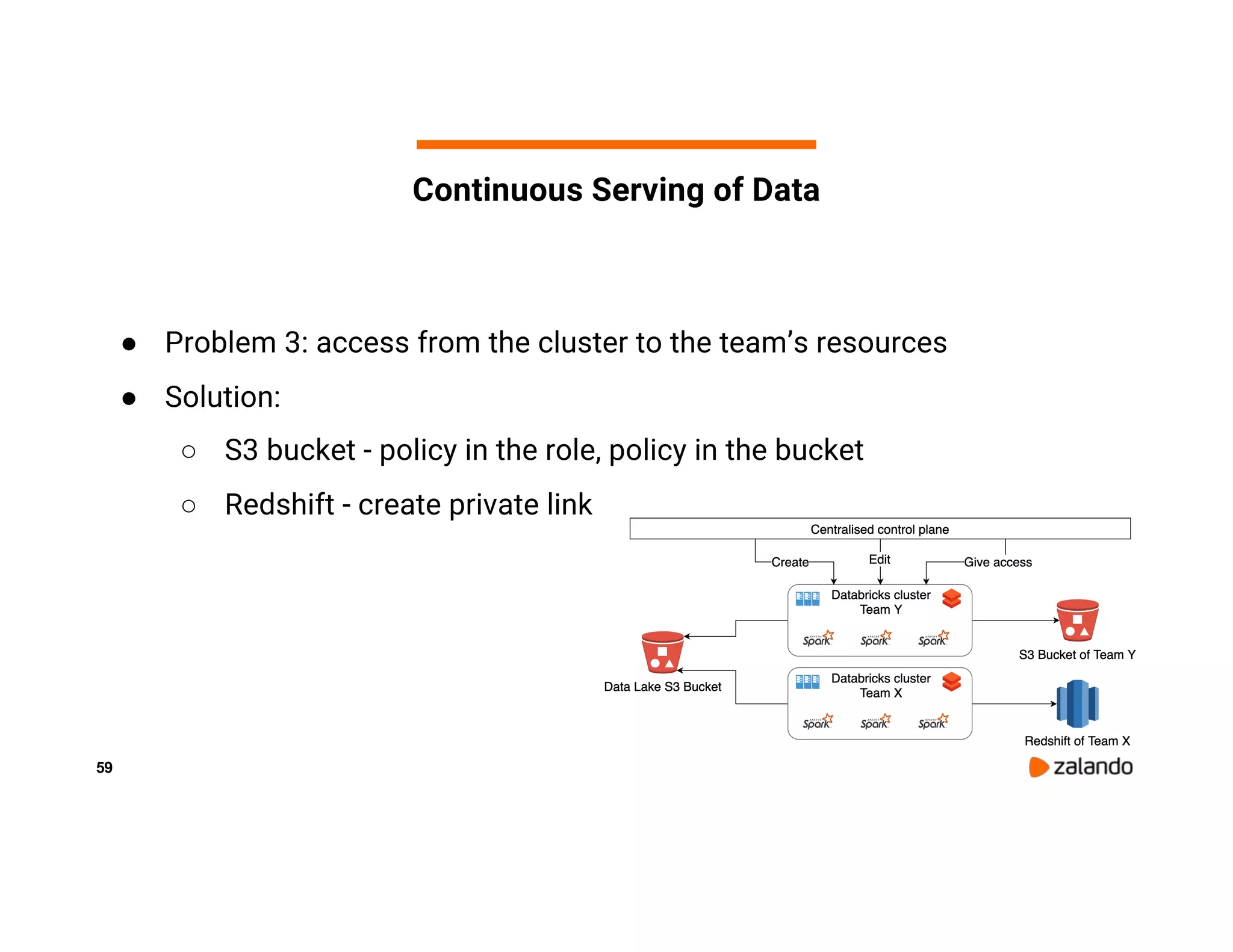




















The document discusses Zalando's implementation of continuous applications at scale using Databricks Delta and Structured Streaming, detailing their data processing platform and various use cases. It highlights challenges faced during batch ingestion, continuous event data processing, and data governance, along with proposed solutions. Key lessons learned include understanding the capabilities of Spark and Delta, automating infrastructure management, and fostering team collaboration through inner source practices.