Deep Learning Basics(lecture notes) by Romain Tavenard This document serves as lecture notes for a course that is taught at Université de Rennes 2 (France) and EDHEC Lille (France). The course deals with the basics of neural networks for classification and regression over tabular data (including optimiza- tion algorithms for multi-layer perceptrons), convolutional neural networks for image classification (including notions of transfer learning) and sequence classification / forecasting. The labs for this course will use keras, hence so will these lecture notes. CONTENTS 1
CHAPTER 1 INTRODUCTION In thisintroduction chapter, we will present a first neural network called the Perceptron. This model is a neural network made of a single neuron, and we will use it here as a way to introduce key concepts that we will detail later in the course. 1.1 A first model: the Perceptron In the neural network terminology, a neuron is a parametrized function that takes a vector x as input and outputs a single value 𝑎 as follows: 𝑎 = 𝜑(wx + 𝑏 ⏟ 𝑜 ), where the parameters of the neuron are its weights stored in w and a bias term 𝑏, and 𝜑 is an activation function that is chosen a priori (we will come back to it in more details later in the course): 𝑜 𝑎 𝑥0 𝑥1 𝑥2 𝑥3 +1 𝑤 0 𝑤 1 𝑤2 𝑤 3 𝑏 𝜑 A model made of a single neuron is called a Perceptron. 3
8.
Deep Learning Basics(lecture notes) 1.2 Optimization The models presented in this book are aimed at solving prediction problems, in which the goal is to find “good enough” parameter values for the model at stake given some observed data. The problem of finding such parameter values is coined optimization and the deep learning field makes extensive use of a specific family of optimization strategies called gradient descent. 1.2.1 Gradient Descent To make one’s mind about gradient descent, let us assume we are given the following dataset about house prices: import pandas as pd boston = pd.read_csv("../data/boston.csv")[["RM", "PRICE"]] boston RM PRICE 0 6.575 24.0 1 6.421 21.6 2 7.185 34.7 3 6.998 33.4 4 7.147 36.2 .. ... ... 501 6.593 22.4 502 6.120 20.6 503 6.976 23.9 504 6.794 22.0 505 6.030 11.9 [506 rows x 2 columns] In our case, we will try (for a start) to predict the target value of this dataset, which is the median value of owner-occupied homes in $1000 "PRICE", as a function of the average number of rooms per dwelling "RM" : sns.scatterplot(data=boston, x="RM", y="PRICE"); 4 Chapter 1. Introduction
9.
Deep Learning Basics(lecture notes) A short note on this model In the Perceptron terminology, this model: • has no activation function (i.e. 𝜑 is the identity function) • has no bias (i.e. 𝑏 is forced to be 0, it is not learnt) Let us assume we have a naive approach in which our prediction model is linear without intercept, that is, for a given input 𝑥𝑖 the predicted output is computed as: ̂ 𝑦𝑖 = 𝑤𝑥𝑖 where 𝑤 is the only parameter of our model. Let us further assume that the quantity we aim at minimizing (our objective, also called loss) is: ℒ(𝑤) = ∑ 𝑖 ( ̂ 𝑦𝑖 − 𝑦𝑖) 2 where 𝑦𝑖 is the ground truth value associated with the 𝑖-th sample in our dataset. Let us have a look at this quantity as a function of 𝑤: import numpy as np def loss(w, x, y): w = np.array(w) return np.sum( (w[:, None] * x.to_numpy()[None, :] - y.to_numpy()[None, :]) ** 2, axis=1 ) w = np.linspace(-2, 10, num=100) x = boston["RM"] y = boston["PRICE"] plt.plot(w, loss(w, x, y), "r-"); 1.2. Optimization 5
10.
Deep Learning Basics(lecture notes) Here, it seems that a value of 𝑤 around 4 should be a good pick, but this method (generating lots of values for the parameter and computing the loss for each value) cannot scale to models that have lots of parameters, so we will try something else. Let us suppose we have access, each time we pick a candidate value for 𝑤, to both the loss ℒ and information about how ℒ varies, locally. We could, in this case, compute a new candidate value for 𝑤 by moving from the previous candidate value in the direction of steepest descent. This is the basic idea behind the gradient descent algorithm that, from an initial candidate 𝑤0, iteratively computes new candidates as: 𝑤𝑡+1 = 𝑤𝑡 − 𝜌 𝜕ℒ 𝜕𝑤 ∣ 𝑤=𝑤𝑡 where 𝜌 is a hyper-parameter (called the learning rate) that controls the size of the steps to be done, and 𝜕ℒ 𝜕𝑤 ∣𝑤=𝑤𝑡 is the gradient of ℒ with respect to 𝑤, evaluated at 𝑤 = 𝑤𝑡. As you can see, the direction of steepest descent is the opposite of the direction pointed by the gradient (and this holds when dealing with vector parameters too). This process is repeated until convergence, as illustrated in the following visualization: rho = 1e-5 def grad_loss(w_t, x, y): return np.sum( 2 * (w_t * x - y) * x ) ww = np.linspace(-2, 10, num=100) plt.plot(ww, loss(ww, x, y), "r-", alpha=.5); w = [0.] for t in range(10): w_update = w[t] - rho * grad_loss(w[t], x, y) w.append(w_update) plt.plot(w, loss(w, x, y), "ko-") plt.text(x=w[0]+.1, y=loss([w[0]], x, y), s="$w_{0}$") plt.text(x=w[10]+.1, y=loss([w[10]], x, y), s="$w_{10}$"); 6 Chapter 1. Introduction
11.
Deep Learning Basics(lecture notes) What would we get if we used a smaller learning rate? rho = 1e-6 ww = np.linspace(-2, 10, num=100) plt.plot(ww, loss(ww, x, y), "r-", alpha=.5); w = [0.] for t in range(10): w_update = w[t] - rho * grad_loss(w[t], x, y) w.append(w_update) plt.plot(w, loss(w, x, y), "ko-") plt.text(x=w[0]+.1, y=loss([w[0]], x, y), s="$w_{0}$") plt.text(x=w[10]+.1, y=loss([w[10]], x, y), s="$w_{10}$"); It would definitely take more time to converge. But, take care, a larger learning rate is not always a good idea: rho = 5e-5 ww = np.linspace(-2, 10, num=100) plt.plot(ww, loss(ww, x, y), "r-", alpha=.5); (continues on next page) 1.2. Optimization 7
12.
Deep Learning Basics(lecture notes) (continued from previous page) w = [0.] for t in range(10): w_update = w[t] - rho * grad_loss(w[t], x, y) w.append(w_update) plt.plot(w, loss(w, x, y), "ko-") plt.text(x=w[0]-1., y=loss([w[0]], x, y), s="$w_{0}$") plt.text(x=w[10]-1., y=loss([w[10]], x, y), s="$w_{10}$"); See how we are slowly diverging because our steps are too large? 1.3 Wrap-up In this section, we have introduced: • a very simple model, called the Perceptron: this will be a building block for the more advanced models we will detail later in the course, such as: – the Multi-Layer Perceptron – Convolutional architectures – Recurrent architectures • the fact that a task comes with a loss function to be minimized (here, we have used the mean squared error (MSE) for our regression task), which will be discussed in a dedicated chapter; • the concept of gradient descent to optimize the chosen loss over a model’s single parameter, and this will be extended in our chapter on optimization. 8 Chapter 1. Introduction
13.
CHAPTER 2 MULTI LAYERPERCEPTRONS In the previous chapter, we have seen a very simple model called the Perceptron. In this model, the predicted output ̂ 𝑦 is computed as a linear combination of the input features plus a bias: ̂ 𝑦 = 𝑑 ∑ 𝑗=1 𝑥𝑗𝑤𝑗 + 𝑏 In other words, we were optimizing among the family of linear models, which is a quite restricted family. 2.1 Stacking layers for better expressivity In order to cover a wider range of models, one can stack neurons organized in layers to form a more complex model, such as the model below, which is called a one-hidden-layer model, since an extra layer of neurons is introduced between the inputs and the output: Input layer x Hidden layer 1 h(1) Output layer ̂ y w(0) w(1) 9
14.
Deep Learning Basics(lecture notes) The question one might ask now is whether this added hidden layer effectively allows to cover a wider family of models. This is what the Universal Approximation Theorem below is all about. Universal Approximation Theorem The Universal Approximation Theorem states that any continuous function defined on a compact set can be approximated as closely as one wants by a one-hidden-layer neural network with sigmoid activation. In other words, by using a hidden layer to map inputs to outputs, one can now approximate any continuous function, which is a very interesting property. Note however that the number of hidden neurons that is necessary to achieve a given approximation quality is not discussed here. Moreover, it is not sufficient that such a good approximation exists, another important question is whether the optimization algorithms we will use will eventually converge to this solution or not, which is not guaranteed, as discussed in more details in the dedicated chapter. In practice, we observe empirically that in order to achieve a given approximation quality, it is more efficient (in terms of the number of parameters required) to stack several hidden layers rather than rely on a single one: Input layer x Hidden layer 1 h(1) Hidden layer 2 h(2) Output layer ̂ y w(0) w(1) w(2) The above graphical representation corresponds to the following model: ̂ 𝑦 = 𝜑out (∑ 𝑖 𝑤 (2) 𝑖 ℎ (2) 𝑖 + 𝑏(2) ) (2.1) ∀𝑖, ℎ (2) 𝑖 = 𝜑 (∑ 𝑗 𝑤 (1) 𝑖𝑗 ℎ (1) 𝑗 + 𝑏 (1) 𝑖 ) (2.2) ∀𝑖, ℎ (1) 𝑖 = 𝜑 (∑ 𝑗 𝑤 (0) 𝑖𝑗 𝑥𝑗 + 𝑏 (0) 𝑖 ) (2.3) To be even more precise, the bias terms 𝑏 (𝑙) 𝑖 are not represented in the graphical representation above. Such models with one or more hidden layers are called Multi Layer Perceptrons (MLP). 10 Chapter 2. Multi Layer Perceptrons
15.
Deep Learning Basics(lecture notes) 2.2 Deciding on an MLP architecture When designing a Multi-Layer Perceptron model to be used for a specific problem, some quantities are fixed by the problem at hand and other are left as hyper-parameters. Let us take the example of the well-known Iris classification dataset: import pandas as pd iris = pd.read_csv("../data/iris.csv", index_col=0) iris sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) 0 5.1 3.5 1.4 0.2 1 4.9 3.0 1.4 0.2 2 4.7 3.2 1.3 0.2 3 4.6 3.1 1.5 0.2 4 5.0 3.6 1.4 0.2 .. ... ... ... ... 145 6.7 3.0 5.2 2.3 146 6.3 2.5 5.0 1.9 147 6.5 3.0 5.2 2.0 148 6.2 3.4 5.4 2.3 149 5.9 3.0 5.1 1.8 target 0 0 1 0 2 0 3 0 4 0 .. ... 145 2 146 2 147 2 148 2 149 2 [150 rows x 5 columns] The goal here is to learn how to infer the target attribute (3 different possible classes) from the information in the 4 other attributes. The structure of this dataset dictates: • the number of neurons in the input layer, which is equal to the number of descriptive attributes in our dataset (here, 4), and • the number of neurons in the output layer, which is here equal to 3, since the model is expected to output one probability per target class. In more generality, for the output layer, one might face several situations: • when regression is at stake, the number of neurons in the output layer is equal to the number of features to be predicted by the model, • when it comes to classification 2.2. Deciding on an MLP architecture 11
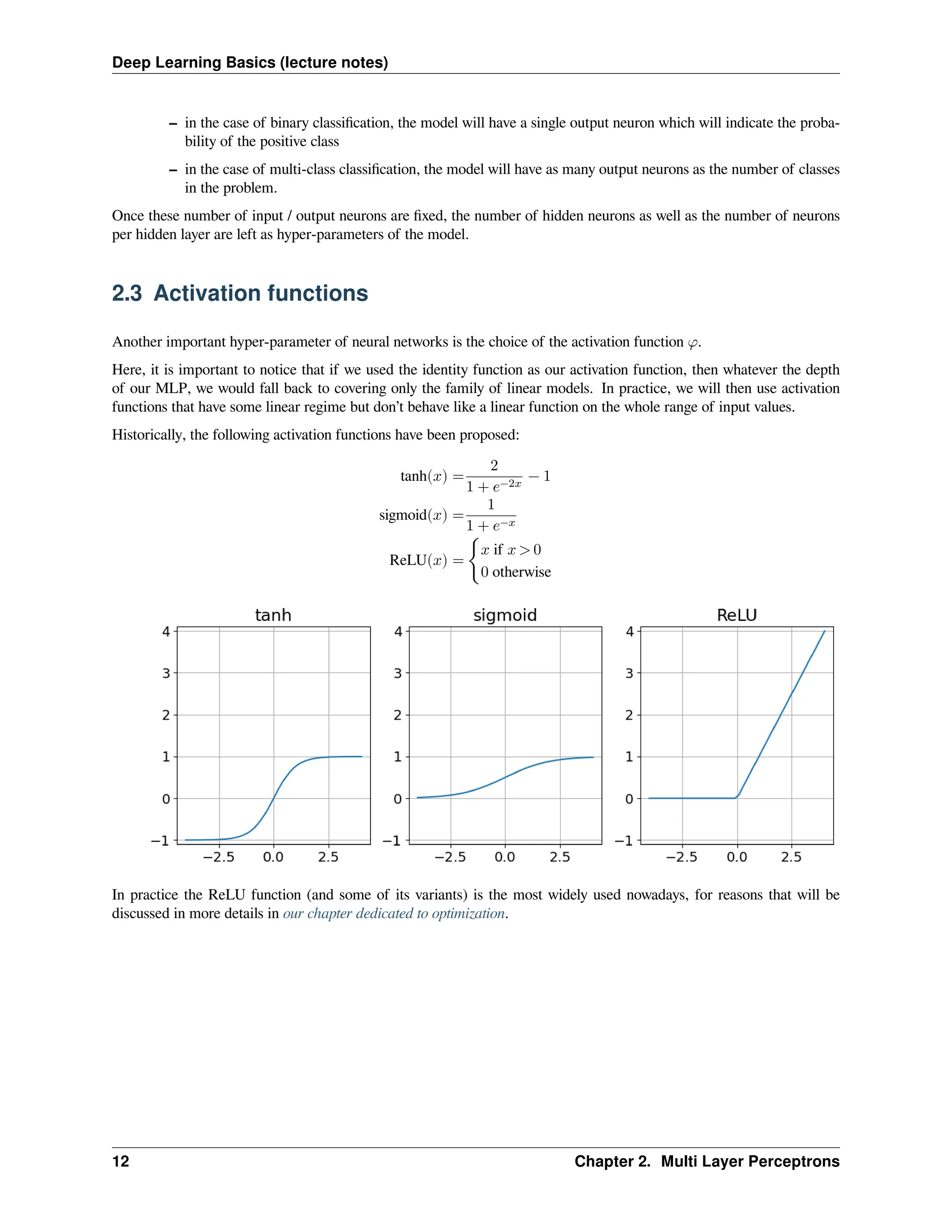
16.
Deep Learning Basics(lecture notes) – in the case of binary classification, the model will have a single output neuron which will indicate the proba- bility of the positive class – in the case of multi-class classification, the model will have as many output neurons as the number of classes in the problem. Once these number of input / output neurons are fixed, the number of hidden neurons as well as the number of neurons per hidden layer are left as hyper-parameters of the model. 2.3 Activation functions Another important hyper-parameter of neural networks is the choice of the activation function 𝜑. Here, it is important to notice that if we used the identity function as our activation function, then whatever the depth of our MLP, we would fall back to covering only the family of linear models. In practice, we will then use activation functions that have some linear regime but don’t behave like a linear function on the whole range of input values. Historically, the following activation functions have been proposed: tanh(𝑥) = 2 1 + 𝑒−2𝑥 − 1 sigmoid(𝑥) = 1 1 + 𝑒−𝑥 ReLU(𝑥) = { 𝑥 if 𝑥 > 0 0 otherwise In practice the ReLU function (and some of its variants) is the most widely used nowadays, for reasons that will be discussed in more details in our chapter dedicated to optimization. 12 Chapter 2. Multi Layer Perceptrons
17.
Deep Learning Basics(lecture notes) 2.3.1 The special case of the output layer You might have noticed that in the MLP formulation provided in Equation (1), the output layer has its own activation function, denoted 𝜑out. This is because the choice of activation functions for the output layer of a neural network is a bit specific to the problem at hand. Indeed, you might have seen that the activation functions discussed in the previous section do not share the same range of output values. It is hence of prime importance to pick an adequate activation function for the output layer such that our model outputs values that are consistent to the quantities it is supposed to predict. If, for example, our model was supposed to be used in the Boston Housing dataset we discussed in the previous chapter. In this case, the goal is to predict housing prices, which are expected to be nonnegative quantities. It would then be a good idea to use ReLU (which can output any positive value) as the activation function for the output layer in this case. As stated earlier, in the case of binary classification, the model will have a single output neuron and this neuron will output the probability associated to the positive class. This quantity is expected to lie in the [0, 1] interval, and the sigmoid activation function is then the default choice in this setting. Finally, when multi-class classification is at stake, we have one neuron per output class and each neuron is expected to output the probability for a given class. In this context, the output values should be between 0 and 1, and they should sum to 1. For this purpose, we use the softmax activation function defined as: ∀𝑖, softmax(𝑜𝑖) = 𝑒𝑜𝑖 ∑𝑗 𝑒𝑜𝑗 where, for all 𝑖, 𝑜𝑖’s are the values of the output neurons before applying the activation function. 2.4 Declaring an MLP in keras In order to define a MLP model in keras, one just has to stack layers. As an example, if one wants to code a model made of: • an input layer with 10 neurons, • a hidden layer made of 20 neurons with ReLU activation, • an output layer made of 3 neurons with softmax activation, the code will look like: import keras_core as keras from keras.layers import Dense, InputLayer from keras.models import Sequential model = Sequential([ InputLayer(input_shape=(10, )), Dense(units=20, activation="relu"), Dense(units=3, activation="softmax") ]) model.summary() Using TensorFlow backend Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # (continues on next page) 2.4. Declaring an MLP in keras 13
18.
Deep Learning Basics(lecture notes) (continued from previous page) ================================================================= dense (Dense) (None, 20) 220 dense_1 (Dense) (None, 3) 63 ================================================================= Total params: 283 (1.11 KB) Trainable params: 283 (1.11 KB) Non-trainable params: 0 (0.00 Byte) _________________________________________________________________ Note that model.summary() provides an interesting overview of a defined model and its parameters. Exercise #1 Relying on what we have seen in this chapter, can you explain the number of parameters returned by model. summary() above? Solution Our input layer is made of 10 neurons, and our first layer is fully connected, hence each of these neurons is connected to a neuron in the hidden layer through a parameter, which already makes 10 × 20 = 200 parameters. Moreover, each of the hidden layer neurons has its own bias parameter, which is 20 more parameters. We then have 220 parameters, as output by model.summary() for the layer "dense (Dense)". Similarly, for the connection of the hidden layer neurons to those in the output layer, the total number of parameters is 20 × 3 = 60 for the weights plus 3 extra parameters for the biases. Overall, we have 220 + 63 = 283 parameters in this model. Exercise #2 Declare, in keras, an MLP with one hidden layer made of 100 neurons and ReLU activation for the Iris dataset presented above. Solution model = Sequential([ InputLayer(input_shape=(4, )), Dense(units=100, activation="relu"), Dense(units=3, activation="softmax") ]) Exercise #3 Same question for the full Boston Housing dataset shown below (the goal here is to predict the PRICE feature based on the other ones). Solution 14 Chapter 2. Multi Layer Perceptrons
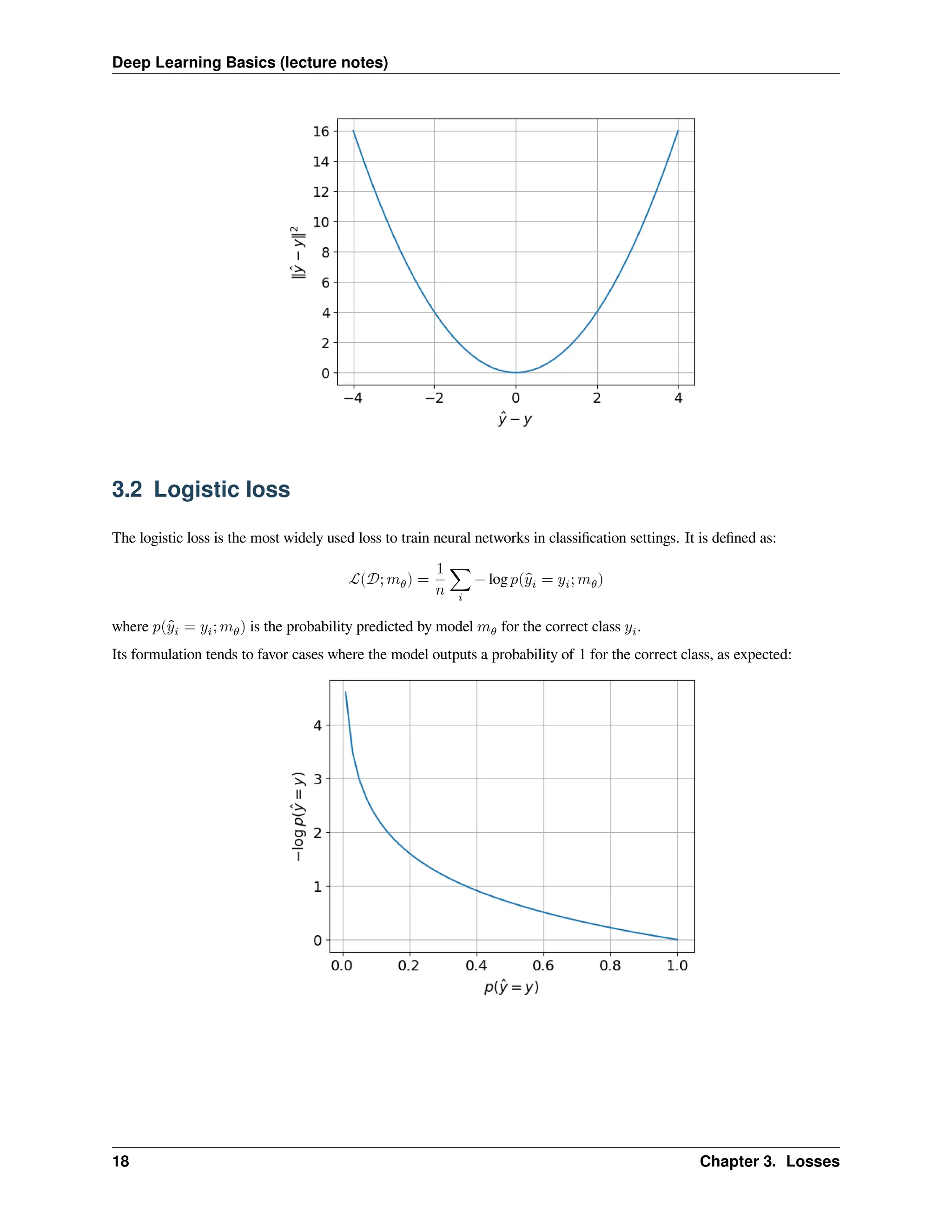
CHAPTER 3 LOSSES We havenow presented a first family of models, which is the MLP family. In order to train these models (i.e. tune their parameters to fit the data), we need to define a loss function to be optimized. Indeed, once this loss function is picked, optimization will consist in tuning the model parameters so as to minimize the loss. In this section, we will present two standard losses, that are the mean squared error (that is mainly used for regression) and logistic loss (which is used in classification settings). In the following, we assume that we are given a dataset 𝒟 made of 𝑛 annotated samples (𝑥𝑖, 𝑦𝑖), and we denote the model’s output: ∀𝑖, ̂ 𝑦𝑖 = 𝑚𝜃(𝑥𝑖) where 𝑚𝜃 is our model and 𝜃 is the set of all its parameters (weights and biases). 3.1 Mean Squared Error The Mean Squared Error (MSE) is the most commonly used loss function in regression settings. It is defined as: ℒ(𝒟; 𝑚𝜃) = 1 𝑛 ∑ 𝑖 ‖ ̂ 𝑦𝑖 − 𝑦𝑖‖2 = 1 𝑛 ∑ 𝑖 ‖𝑚𝜃(𝑥𝑖) − 𝑦𝑖‖2 Its quadratic formulation tends to strongly penalize large errors: 17
22.
Deep Learning Basics(lecture notes) 3.2 Logistic loss The logistic loss is the most widely used loss to train neural networks in classification settings. It is defined as: ℒ(𝒟; 𝑚𝜃) = 1 𝑛 ∑ 𝑖 − log 𝑝( ̂ 𝑦𝑖 = 𝑦𝑖; 𝑚𝜃) where 𝑝( ̂ 𝑦𝑖 = 𝑦𝑖; 𝑚𝜃) is the probability predicted by model 𝑚𝜃 for the correct class 𝑦𝑖. Its formulation tends to favor cases where the model outputs a probability of 1 for the correct class, as expected: 18 Chapter 3. Losses
23.
CHAPTER 4 OPTIMIZATION In thischapter, we will present variants of the Gradient Descent optimization strategy and show how they can be used to optimize neural network parameters. Let us start with the basic Gradient Descent algorithm and its limitations. Algorithm 1 (Gradient Descent) Input: A dataset 𝒟 = (𝑋, 𝑦) 1. Initialize model parameters 𝜃 2. for 𝑒 = 1..𝐸 1. for (𝑥𝑖, 𝑦𝑖) ∈ 𝒟 1. Compute prediction ̂ 𝑦𝑖 = 𝑚𝜃(𝑥𝑖) 2. Compute gradient ∇𝜃ℒ𝑖 2. Compute overall gradient ∇𝜃ℒ = 1 𝑛 ∑𝑖 ∇𝜃ℒ𝑖 3. Update parameters 𝜃 based on ∇𝜃ℒ The typical update rule for the parameters 𝜃 at iteration 𝑡 is 𝜃(𝑡+1) ← 𝜃(𝑡) − 𝜌∇𝜃ℒ where 𝜌 is an important hyper-parameter of the method, called the learning rate. Basically, gradient descent updates 𝜃 in the direction of steepest decrease of the loss ℒ. As one can see in the previous algorithm, when performing gradient descent, model parameters are updated once per epoch, which means a full pass over the whole dataset is required before the update can occur. When dealing with large datasets, this is a strong limitation, which motivates the use of stochastic variants. 19
24.
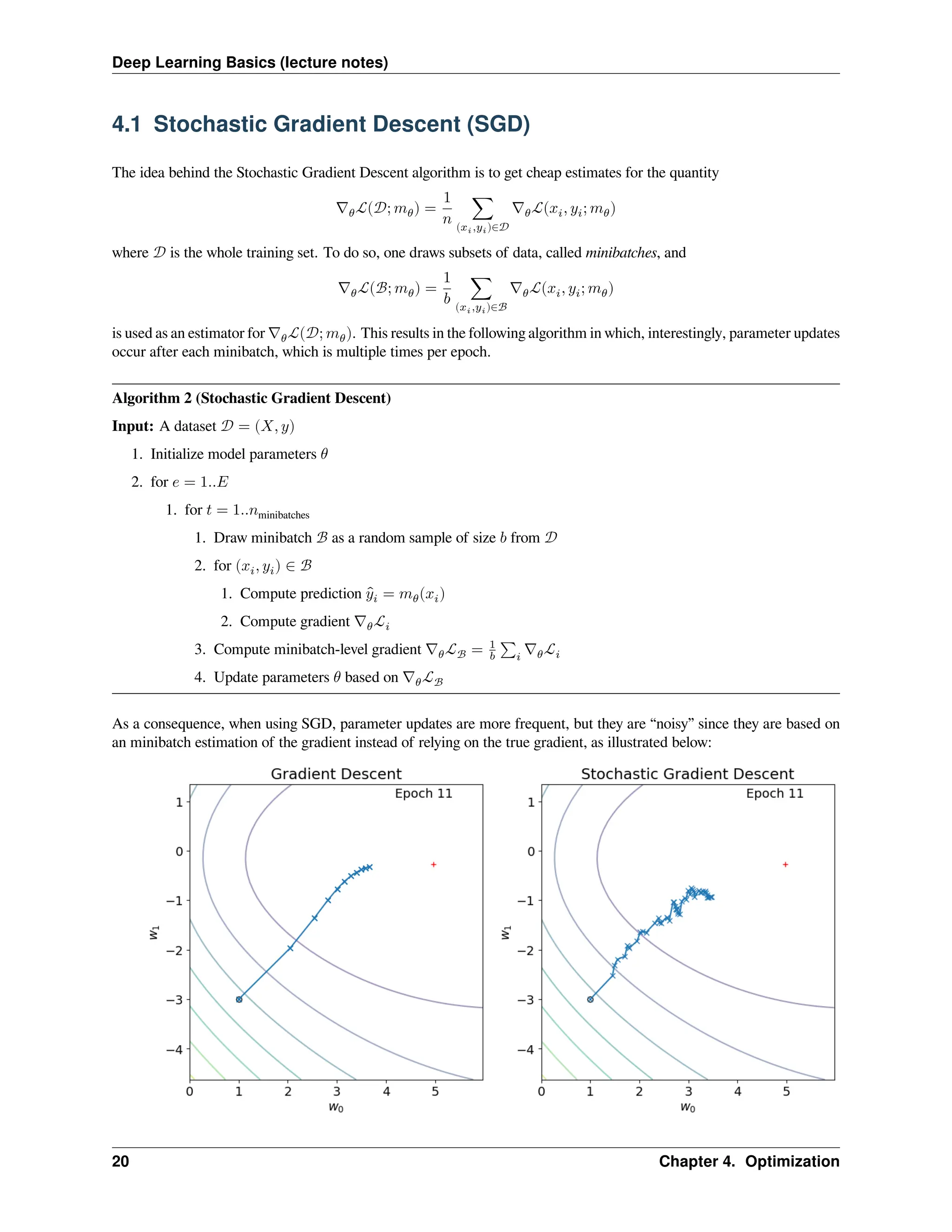
Deep Learning Basics(lecture notes) 4.1 Stochastic Gradient Descent (SGD) The idea behind the Stochastic Gradient Descent algorithm is to get cheap estimates for the quantity ∇𝜃ℒ(𝒟; 𝑚𝜃) = 1 𝑛 ∑ (𝑥𝑖,𝑦𝑖)∈𝒟 ∇𝜃ℒ(𝑥𝑖, 𝑦𝑖; 𝑚𝜃) where 𝒟 is the whole training set. To do so, one draws subsets of data, called minibatches, and ∇𝜃ℒ(ℬ; 𝑚𝜃) = 1 𝑏 ∑ (𝑥𝑖,𝑦𝑖)∈ℬ ∇𝜃ℒ(𝑥𝑖, 𝑦𝑖; 𝑚𝜃) is used as an estimator for ∇𝜃ℒ(𝒟; 𝑚𝜃). This results in the following algorithm in which, interestingly, parameter updates occur after each minibatch, which is multiple times per epoch. Algorithm 2 (Stochastic Gradient Descent) Input: A dataset 𝒟 = (𝑋, 𝑦) 1. Initialize model parameters 𝜃 2. for 𝑒 = 1..𝐸 1. for 𝑡 = 1..𝑛minibatches 1. Draw minibatch ℬ as a random sample of size 𝑏 from 𝒟 2. for (𝑥𝑖, 𝑦𝑖) ∈ ℬ 1. Compute prediction ̂ 𝑦𝑖 = 𝑚𝜃(𝑥𝑖) 2. Compute gradient ∇𝜃ℒ𝑖 3. Compute minibatch-level gradient ∇𝜃ℒℬ = 1 𝑏 ∑𝑖 ∇𝜃ℒ𝑖 4. Update parameters 𝜃 based on ∇𝜃ℒℬ As a consequence, when using SGD, parameter updates are more frequent, but they are “noisy” since they are based on an minibatch estimation of the gradient instead of relying on the true gradient, as illustrated below: 20 Chapter 4. Optimization
25.
Deep Learning Basics(lecture notes) Apart from implying more frequent parameter updates, SGD has an extra benefit in terms of optimization, which is key for neural networks. Indeed, as one can see below, contrary to what we had in the Perceptron case, the MSE loss (and the same applies for the logistic loss) is no longer convex in the model parameters as soon as the model has at least one hidden layer: Gradient Descent is known to suffer from local optima, and such loss landscapes are a serious problem for GD. On the other hand, Stochastic Gradient Descent is likely to benefit from noisy gradient estimations to escape local minima. 4.2 A note on Adam Adam [Kingma and Ba, 2015] is a variant of the Stochastic Gradient Descent method. It differs in the definition of the steps to be performed at each parameter update. First, it uses what is called momentum, which basically consists in relying on past gradient updates to smooth out the trajectory in parameter space during optimization. An interactive illustration of momentum can be found in [Goh, 2017]. The resulting plugin replacement for the gradient is: m(𝑡+1) ← 1 1 − 𝛽𝑡 1 [𝛽1m(𝑡) + (1 − 𝛽1)∇𝜃ℒ] When 𝛽1 is zero, we have m(𝑡+1) = ∇𝜃ℒ and for 𝛽1 ∈]0, 1[, m(𝑡+1) balances the current gradient estimate with infor- mation about past estimates, stored in m(𝑡) . Another important difference between SGD and the Adam variant consists in using an adaptive learning rate. In other words, instead of using the same learning rate 𝜌 for all model parameters, the learning rate for a given parameter 𝜃𝑖 is defined as: ̂ 𝜌(𝑡+1) (𝜃𝑖) = 𝜌 √𝑠(𝑡+1)(𝜃𝑖) + 𝜖 where 𝜖 is a small constant and 𝑠(𝑡+1) (𝜃𝑖) = 1 1 − 𝛽𝑡 2 [𝛽2𝑠(𝑡) (𝜃𝑖) + (1 − 𝛽2) (∇𝜃𝑖 ℒ) 2 ] Here also, the 𝑠 term uses momentum. As a result, the learning rate will be lowered for parameters which have suffered large updates in the past iterations. Overall, the Adam update rule is: 𝜃(𝑡+1) ← 𝜃(𝑡) − ̂ 𝜌(𝑡+1) (𝜃)m(𝑡+1) 4.2. A note on Adam 21
26.
Deep Learning Basics(lecture notes) 4.3 The curse of depth Let us consider the following neural network: w(0) w(1) w(2) and let us recall that, at a given layer (ℓ), the layer output is computed as 𝑎(ℓ) = 𝜑(𝑜(ℓ) ) = 𝜑(𝑤(ℓ−1) 𝑎(ℓ−1) ) where 𝜑 is the activation function for the given layer (we ignore the bias terms in this simplified example). In order to perform (stochastic) gradient descent, gradients of the loss with respect to model parameters need to be computed. By using the chain rule, these gradients can be expressed as: 𝜕ℒ 𝜕𝑤(2) = 𝜕ℒ 𝜕𝑎(3) 𝜕𝑎(3) 𝜕𝑜(3) 𝜕𝑜(3) 𝜕𝑤(2) 𝜕ℒ 𝜕𝑤(1) = 𝜕ℒ 𝜕𝑎(3) 𝜕𝑎(3) 𝜕𝑜(3) 𝜕𝑜(3) 𝜕𝑎(2) 𝜕𝑎(2) 𝜕𝑜(2) 𝜕𝑜(2) 𝜕𝑤(1) 𝜕ℒ 𝜕𝑤(0) = 𝜕ℒ 𝜕𝑎(3) 𝜕𝑎(3) 𝜕𝑜(3) 𝜕𝑜(3) 𝜕𝑎(2) 𝜕𝑎(2) 𝜕𝑜(2) 𝜕𝑜(2) 𝜕𝑎(1) 𝜕𝑎(1) 𝜕𝑜(1) 𝜕𝑜(1) 𝜕𝑤(0) There are important insights to grasp here. First, one should notice that weights that are further from the output of the model inherit gradient rules made of more terms. As a consequence, when some of these terms get smaller and smaller, there is a higher risk for those weights that their gradients collapse to 0, this is called the vanishing gradient effect, which is a very common phenomenon in deep neural networks (i.e. those networks made of many layers). Second, some terms are repeated in these formulas, and in general, terms of the form 𝜕𝑎(ℓ) 𝜕𝑜(ℓ) and 𝜕𝑜(ℓ) 𝜕𝑎(ℓ−1) are present in several places. These terms can be further developed as: 𝜕𝑎(ℓ) 𝜕𝑜(ℓ) = 𝜑′ (𝑜(ℓ) ) 𝜕𝑜(ℓ) 𝜕𝑎(ℓ−1) = 𝑤(ℓ−1) Let us inspect what the derivatives of standard activation functions look like: 22 Chapter 4. Optimization
27.
Deep Learning Basics(lecture notes) One can see that the derivative of ReLU has a wider range of input values for which it is non-zero (typically the whole range of positive input values) than its competitors, which makes it a very attractive candidate activation function for deep neural networks, as we have seen that the 𝜕𝑎(ℓ) 𝜕𝑜(ℓ) term appears repeatedly in chain rule derivations. 4.4 Wrapping things up in keras In keras, loss and optimizer information are passed at compile time: import keras_core as keras from keras.layers import Dense, InputLayer from keras.models import Sequential model = Sequential([ InputLayer(input_shape=(10, )), Dense(units=20, activation="relu"), Dense(units=3, activation="softmax") ]) model.summary() Using TensorFlow backend Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 20) 220 dense_1 (Dense) (None, 3) 63 ================================================================= Total params: 283 (1.11 KB) Trainable params: 283 (1.11 KB) Non-trainable params: 0 (0.00 Byte) _________________________________________________________________ model.compile(loss="categorical_crossentropy", optimizer="adam") In terms of losses: • "mse" is the mean squared error loss, 4.4. Wrapping things up in keras 23
28.
Deep Learning Basics(lecture notes) • "binary_crossentropy" is the logistic loss for binary classification, • "categorical_crossentropy" is the logistic loss for multi-class classification. The optimizers defined in this section are available as "sgd" and "adam". In order to get control over optimizer hyper-parameters, one can alternatively use the following syntax: from keras.optimizers import Adam, SGD # Not a very good idea to tune beta_1 # and beta_2 parameters in Adam adam_opt = Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.9) # In order to use SGD with a custom learning rate: # sgd_opt = SGD(learning_rate=0.001) model.compile(loss="categorical_crossentropy", optimizer=adam_opt) 4.5 Data preprocessing In practice, for the model fitting phase to behave well, it is important to scale the input features. In the following example, we will compare two trainings of the same model, with similar initialization and the only difference between both will be whether input data is center-reduced or left as-is. import pandas as pd from keras.utils import to_categorical iris = pd.read_csv("../data/iris.csv", index_col=0) iris = iris.sample(frac=1) y = to_categorical(iris["target"]) X = iris.drop(columns=["target"]) from keras.layers import Dense, InputLayer from keras.models import Sequential from keras.utils import set_random_seed set_random_seed(0) model = Sequential([ InputLayer(input_shape=(4, )), Dense(units=256, activation="relu"), Dense(units=256, activation="relu"), Dense(units=256, activation="relu"), Dense(units=3, activation="softmax") ]) n_epochs = 100 model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"]) h = model.fit(X, y, epochs=n_epochs, batch_size=30, verbose=0) Let us now standardize our data and compare performance: 24 Chapter 4. Optimization
29.
Deep Learning Basics(lecture notes) X -= X.mean(axis=0) X /= X.std(axis=0) set_random_seed(0) model = Sequential([ InputLayer(input_shape=(4, )), Dense(units=256, activation="relu"), Dense(units=256, activation="relu"), Dense(units=256, activation="relu"), Dense(units=3, activation="softmax") ]) n_epochs = 100 model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"]) h_standardized = model.fit(X, y, epochs=n_epochs, batch_size=30, verbose=0) 4.5. Data preprocessing 25
CHAPTER 5 REGULARIZATION As discussedin previous chapters, one of the strengths of the neural networks is that they can approximate any continuous functions when a sufficient number of parameters is used. When using universal approximators in machine learning settings, an important related risk is that of overfitting the training data. More formally, given a training dataset 𝒟𝑡 drawn from an unknown distribution 𝒟, model parameters are optimized so as to minimize the empirical risk: ℛ𝑒(𝜃) = 1 |𝒟𝑡| ∑ (𝑥𝑖,𝑦𝑖)∈𝒟𝑡 ℒ(𝑥𝑖, 𝑦𝑖; 𝑚𝜃) whereas the real objective is to minimize the “true” risk: ℛ(𝜃) = 𝔼𝑥,𝑦∼𝒟ℒ(𝑥, 𝑦; 𝑚𝜃) and both objectives do not have the same minimizer. To avoid this pitfall, one should use regularization techniques, such as the ones presented in the following. 5.1 Early Stopping As illustrated below, it can be observed that training a neural network for a too large number of epochs can lead to overfitting. Note that here, the true risk is estimated through the use of a validation set that is not seen during training. Using TensorFlow backend iris = pd.read_csv("../data/iris.csv", index_col=0) iris = iris.sample(frac=1) y = to_categorical(iris["target"]) X = iris.drop(columns=["target"]) X -= X.mean(axis=0) X /= X.std(axis=0) 27
32.
Deep Learning Basics(lecture notes) import keras_core as keras from keras.layers import Dense, InputLayer from keras.models import Sequential from keras.utils import set_random_seed set_random_seed(0) model = Sequential([ InputLayer(input_shape=(4, )), Dense(units=256, activation="relu"), Dense(units=256, activation="relu"), Dense(units=256, activation="relu"), Dense(units=3, activation="softmax") ]) n_epochs = 100 model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"]) h = model.fit(X, y, validation_split=0.3, epochs=n_epochs, batch_size=30, verbose=0) Here, the best model (in terms of generalization capabilities) seems to be the model at epoch 43. In other words, if we had stopped the learning process after epoch 43, we would have gotten a better model than if we use the model trained during 70 epochs. This is the whole idea behind the “early stopping” strategy, which consists in stopping the learning process as soon as the validation loss stops improving. As can be seen in the visualization above, however, the validation loss tends to oscillate, and one often waits for several epochs before assuming that the loss is unlikely to improve in the future. The number of epochs to wait is called the patience parameter. In keras, early stopping can be set up via a callback, as in the following example: from keras.callbacks import EarlyStopping set_random_seed(0) model = Sequential([ InputLayer(input_shape=(4, )), Dense(units=256, activation="relu"), Dense(units=256, activation="relu"), (continues on next page) 28 Chapter 5. Regularization
33.
Deep Learning Basics(lecture notes) (continued from previous page) Dense(units=256, activation="relu"), Dense(units=3, activation="softmax") ]) cb_es = EarlyStopping(monitor="val_loss", patience=10, restore_best_weights=True) n_epochs = 100 model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"]) h = model.fit(X, y, validation_split=0.3, epochs=n_epochs, batch_size=30, verbose=0, callbacks=[cb_es]) And now, even is the model was scheduled to be trained for 70 epochs, training is stopped as soon as it reaches 10 consecutive epochs without improving on the validation loss, and the model parameters are restored as the parameters of the model at epoch 43. 5.2 Loss penalization Another important way to enforce regularization in neural networks is through loss penalization. A typical instance of this regularization strategy is the L2 regularization. If we denote by ℒ𝑟 the L2-regularized loss, it can be expressed as: ℒ𝑟(𝒟; 𝑚𝜃) = ℒ(𝒟; 𝑚𝜃) + 𝜆 ∑ ℓ ‖𝜃(ℓ) ‖2 2 where 𝜃(ℓ) is the weight matrix of layer ℓ. This regularization tends to shrink large parameter values during the learning process, which is known to help improve generalization. In keras, this is implemented as: from keras.regularizers import L2 λ = 0.01 (continues on next page) 5.2. Loss penalization 29
34.
Deep Learning Basics(lecture notes) (continued from previous page) set_random_seed(0) model = Sequential([ InputLayer(input_shape=(4, )), Dense(units=256, activation="relu", kernel_regularizer=L2(λ)), Dense(units=256, activation="relu", kernel_regularizer=L2(λ)), Dense(units=256, activation="relu", kernel_regularizer=L2(λ)), Dense(units=3, activation="softmax") ]) n_epochs = 100 model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"]) h = model.fit(X, y, validation_split=0.3, epochs=n_epochs, batch_size=30, verbose=0) 5.3 DropOut Fig. 5.1: Illustration of the DropOut mechanism. In order to train a given model (left), at each mini-batch, a given proportion of neurons is picked at random to be “switched off” and the subsequent sub-network is used for the current optimization step (cf. right-hand side figure, in which 40% of the neurons – coloured in gray – are switched off). In this section, we present the DropOut strategy, which was introduced in [Srivastava et al., 2014]. The idea behind DropOut is to switch off some of the neurons during training. The switched off neurons change at each mini-batch such 30 Chapter 5. Regularization
35.
Deep Learning Basics(lecture notes) that, overall, all neurons are trained during the whole process. The concept is very similar in spirit to a strategy that is used for training random forest, which consists in randomly selecting candidate variables for each tree split inside a forest, which is known to lead to better generalization performance for random forests. The main difference here is that one can not only switch off input neurons but also hidden-layer ones during training. In keras, this is implemented as a layer, which acts by switching off neurons from the previous layer in the network: from keras.layers import Dropout set_random_seed(0) switchoff_proba = 0.3 model = Sequential([ InputLayer(input_shape=(4, )), Dropout(rate=switchoff_proba), Dense(units=256, activation="relu"), Dropout(rate=switchoff_proba), Dense(units=256, activation="relu"), Dropout(rate=switchoff_proba), Dense(units=256, activation="relu"), Dropout(rate=switchoff_proba), Dense(units=3, activation="softmax") ]) n_epochs = 100 model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"]) h = model.fit(X, y, validation_split=0.3, epochs=n_epochs, batch_size=30, verbose=0) Exercise #1 When observing the loss values in the figure above, can you explain why the validation loss is almost consistently lower than the training one? Solution In fact, the training loss is computed as the average loss over all training mini-batches during an epoch. Now, if we recall that during training, at each minibatch, 30% of the neurons are switched-off, one can see that only a subpart of the full 5.3. DropOut 31
36.
Deep Learning Basics(lecture notes) model is used when evaluating the training loss while the full model is retrieved when predicting on the validation set, which explains why the measured validation loss is lower than the training one. 32 Chapter 5. Regularization
37.
CHAPTER 6 CONVOLUTIONAL NEURALNETWORKS Convolutional Neural Networks (aka ConvNets) are designed to take advantage of the structure in the data. In this chapter, we will discuss two flavours of ConvNets: we will start with the monodimensional case and see how ConvNets with 1D convolutions can be helpful to process time series and we will then introduce the 2D case that is especially useful to process image data. 6.1 ConvNets for time series Convolutional neural networks for time series rely on the 1D convolution operator that, given a time series x and a filter f, computes an activation map as: (x ∗ f) (𝑡) = 𝐿 ∑ 𝑘=−𝐿 𝑓𝑘𝑥𝑡+𝑘 (6.1) where the filter f is of length (2𝐿 + 1). The following code illustrates this notion using a Gaussian filter: Convolutional neural networks are made of convolution blocks whose parameters are the coefficients of the filters they embed (hence filters are not fixed a priori as in the example above but rather learned). These convolution blocks are translation equivariant, which means that a (temporal) shift in their input results in the same temporal shift in the output: /tmp/ipykernel_11148/368849627.py:32: UserWarning: This figure includes Axes that␣ ↪are not compatible with tight_layout, so results might be incorrect. plt.tight_layout() /tmp/ipykernel_11148/368849627.py:23: MatplotlibDeprecationWarning: Auto-removal␣ ↪of overlapping axes is deprecated since 3.6 and will be removed two minor␣ ↪releases later; explicitly call ax.remove() as needed. fig2 = plt.subplot(2, 1, 2) /tmp/ipykernel_11148/368849627.py:32: UserWarning: The figure layout has changed␣ ↪to tight plt.tight_layout() <IPython.core.display.HTML object> 33
38.
Deep Learning Basics(lecture notes) Convolutional models are known to perform very well in computer vision applications, using moderate amounts of pa- rameters compared to fully connected ones (of course, counter-examples exist, and the term “moderate” is especially vague). Most standard time series architectures that rely on convolutional blocks are straight-forward adaptations of models from the computer vision community ([Le Guennec et al., 2016] relies on an old-fashioned alternance between convolution and pooling layers, while more recent works rely on residual connections and inception modules [Fawaz et al., 2020]). These basic blocks (convolution, pooling, residual layers) are discussed in more details in the next Section. These time series classification models (and more) are presented and benchmarked in [Fawaz et al., 2019] that we advise the interested reader to refer to for more details. 6.2 Convolutional neural networks for images We now turn our focus to the 2D case, in which our convolution filters will not slide on a single axis as in the time series case but rather on the two dimensions (width and height) of an image. 6.2.1 Images and convolutions As seen below, an image is a pixel grid, and each pixel has an intensity value in each of the image channels. Color images are typically made of 3 channels (Red, Green and Blue here). Fig. 6.1: An image and its 3 channels (Red, Green and Blue intensity, from left to right). The output of a convolution on an image x is a new image, whose pixel values can be computed as: (x ∗ f) (𝑖, 𝑗) = 𝐾 ∑ 𝑘=−𝐾 𝐿 ∑ 𝑙=−𝐿 3 ∑ 𝑐=1 𝑓𝑘,𝑙,𝑐𝑥𝑖+𝑘,𝑗+𝑙,𝑐. (6.2) In other words, the output image pixels are computed as the dot product between a convolution filter (which is a tensor of shape (2𝐾 + 1, 2𝐿 + 1, 𝑐)) and the image patch centered at the given position. Let us, for example, consider the following 9x9 convolution filter: 34 Chapter 6. Convolutional Neural Networks
39.
Deep Learning Basics(lecture notes) Then the output of the convolution of the cat image above with this filter is the following greyscale (ie. single channel) image: One might notice that this image is a blurred version of the original image. This is because we used a Gaussian filter in the process. As for time series, when using convolution operations in neural networks, the contents of the filters will be learnt, rather than set a priori. 6.2. Convolutional neural networks for images 35
40.
Deep Learning Basics(lecture notes) 6.2.2 CNNs à la LeNet In [LeCun et al., 1998], a stack of convolution, pooling and fully connected layers is introduced for an image classification task, more specifically a digit recognition application. The resulting neural network, called LeNet, is depicted below: Fig. 6.2: LeNet-5 model Convolution layers A convolution layer is made of several convolution filters (also called kernels) that operate in parallel on the same input image. Each convolution filter generates an output activation map and all these maps are stacked (in the channel dimension) to form the output of the convolution layer. All filters in a layer share the same width and height. A bias term and an activation function can be used in convolution layers, as in other neural network layers. All in all, the output of a convolution filter is computed as: (x ∗ f) (𝑖, 𝑗, 𝑐) = 𝜑 ( 𝐾 ∑ 𝑘=−𝐾 𝐿 ∑ 𝑙=−𝐿 ∑ 𝑐′ 𝑓𝑐 𝑘,𝑙,𝑐′ 𝑥𝑖+𝑘,𝑗+𝑙,𝑐′ + 𝑏𝑐) (6.3) where 𝑐 denotes the output channel (note that each output channel is associated with a filter 𝑓𝑐 ), 𝑏𝑐 is its associated bias term and 𝜑 is the activation function to be used. Tip: In keras, such a layer is implemented using the Conv2D class: import keras_core as keras from keras.layers import Conv2D layer = Conv2D(filters=6, kernel_size=5, padding="valid", activation="relu") Padding 36 Chapter 6. Convolutional Neural Networks
41.
Deep Learning Basics(lecture notes) Fig. 6.3: A visual explanation of padding (source: V. Dumoulin, F. Visin - A guide to convolution arithmetic for deep learning). Left: Without padding, right: With padding. When processing an input image, it can be useful to ensure that the output feature map has the same width and height as the input image. This can be achieved by padding the input image with surrounding zeros, as illustrated in Fig. 6.3 in which the padding area is represented in white. Pooling layers Pooling layers perform a subsampling operation that somehow summarizes the information contained in feature maps in lower resolution maps. The idea is to compute, for each image patch, an output feature that computes an aggregate of the pixels in the patch. Typical aggregation operators are average (in this case the corresponding layer is called an average pooling layer) or maximum (for max pooling layers) operators. In order to reduce the resolution of the output maps, these aggregates are typically computed on sliding windows that do not overlap, as illustrated below, for a max pooling with a pool size of 2x2: 6.2. Convolutional neural networks for images 37
42.
Deep Learning Basics(lecture notes) max Such layers were widely used in the early years of convolutional models and are now less and less used as the available amount of computational power grows. Tip: In keras, pooling layers are implemented through the MaxPool2D and AvgPool2D classes: from keras.layers import MaxPool2D, AvgPool2D max_pooling_layer = MaxPool2D(pool_size=2) average_pooling_layer = AvgPool2D(pool_size=2) Plugging fully-connected layers at the output A stack of convolution and pooling layers outputs a structured activation map (that takes the form of 2d grid with an additional channel dimension). When image classification is targeted, the goal is to output the most probable class for the input image, which is usually performed by a classification head that consists in fully-connected layers. In order for the classification head to be able to process an activation map, information from this map needs to be trans- formed into a vector. This operation is called flattening in keras, and the model corresponding to Fig. 6.2 can be implemented as: from keras.models import Sequential from keras.layers import InputLayer, Conv2D, MaxPool2D, Flatten, Dense model = Sequential([ InputLayer(input_shape=(32, 32, 1)), Conv2D(filters=6, kernel_size=5, padding="valid", activation="relu"), (continues on next page) 38 Chapter 6. Convolutional Neural Networks
CHAPTER 7 RECURRENT NEURALNETWORKS Recurrent neural networks (RNNs) proceed by processing elements of a time series one at a time. Typically, at time 𝑡, a recurrent block will take both the current input 𝑥𝑡 and a hidden state ℎ𝑡−1 that aims at summarizing the key information from past inputs {𝑥0, … , 𝑥𝑡−1}, and will output an updated hidden state ℎ𝑡: … … ℎ𝑡 𝑥𝑡 ℎ𝑡−1 𝑥𝑡−1 ℎ𝑡+1 𝑥𝑡+1 There exist various recurrent modules that mostly differ in the way ℎ𝑡 is computed. 41
46.
Deep Learning Basics(lecture notes) 7.1 “Vanilla” RNNs The basic formulation for a RNN block is as follows: ∀𝑡, ℎ𝑡 = tanh(𝑊ℎℎ𝑡−1 + 𝑊𝑥𝑥𝑡 + 𝑏) (7.1) where 𝑊ℎ is a weight matrix associated to the processing of the previous hidden state, 𝑊𝑥 is another weight matrix associated to the processing of the current input and 𝑏 is a bias term. Note here that 𝑊ℎ, 𝑊𝑥 and 𝑏 are not indexed by 𝑡, which means that they are shared across all timestamps. An important limitation of this formula is that it easily fails at capturing long-term dependencies. To better understand why, one should remind that the parameters of these networks are optimized through stochastic gradient descent algo- rithms. To simplify notations, let us consider a simplified case in which ℎ𝑡 and 𝑥𝑡 are both scalar values, and let us have a look at what the actual gradient of the output ℎ𝑡 is, with respect to 𝑊ℎ (which is then also a scalar): ∇𝑊ℎ (ℎ𝑡) = tanh ′ (𝑜𝑡) ⋅ 𝜕𝑜𝑡 𝜕𝑊ℎ (7.2) where 𝑜𝑡 = 𝑊ℎℎ𝑡−1 + 𝑊𝑥𝑥𝑡 + 𝑏, hence: 𝜕𝑜𝑡 𝜕𝑊ℎ = ℎ𝑡−1 + 𝑊ℎ ⋅ 𝜕ℎ𝑡−1 𝜕𝑊ℎ . (7.3) Here, the form of 𝜕ℎ𝑡−1 𝜕𝑊ℎ will be similar to that of ∇𝑊ℎ (ℎ𝑡) above, and, in the end, one gets: ∇𝑊ℎ (ℎ𝑡) = tanh ′ (𝑜𝑡) ⋅ [ℎ𝑡−1 + 𝑊ℎ ⋅ 𝜕ℎ𝑡−1 𝜕𝑊ℎ ] (7.4) = tanh ′ (𝑜𝑡) ⋅ [ℎ𝑡−1 + 𝑊ℎ ⋅ tanh ′ (𝑜𝑡−1) ⋅ [ℎ𝑡−2 + 𝑊ℎ ⋅ [… ]]] (7.5) = ℎ𝑡−1tanh ′ (𝑜𝑡) + ℎ𝑡−2𝑊ℎtanh ′ (𝑜𝑡)tanh ′ (𝑜𝑡−1) + … (7.6) = 𝑡−1 ∑ 𝑡′=1 ℎ𝑡′ [𝑊𝑡−𝑡′ −1 ℎ tanh ′ (𝑜𝑡′+1) ⋅ ⋯ ⋅ tanh ′ (𝑜𝑡)] (7.7) In other words, the influence of ℎ𝑡′ will be mitigated by a factor 𝑊𝑡−𝑡′ −1 ℎ tanh ′ (𝑜𝑡′+1) ⋅ ⋯ ⋅ tanh ′ (𝑜𝑡). Now recall what the tanh function and its derivative look like: 42 Chapter 7. Recurrent Neural Networks
47.
Deep Learning Basics(lecture notes) One can see how quickly gradients gets close to 0 for inputs larger (in absolute value) than 2, and having multiple such terms in a computation chain will likely make the corresponding terms vanish. In other words, the gradient of the hidden state at time 𝑡 will only be influenced by a few of its predecessors {ℎ𝑡−1, ℎ𝑡−2, … } and long-term dependencies will be ignored when updating model parameters through gradient descent. This is an occurrence of a more general phenomenon known as the vanishing gradient effect. 7.2 Long Short-Term Memory The Long Short-Term Memory (LSTM, [Hochreiter and Schmidhuber, 1997]) blocks have been designed as an alternative recurrent block that aims at mitigating this vanishing gradient effect through the use of gates that explicitly encode pieces of information that should (resp. should not) be kept in computations. Gates in neural networks In the neural networks terminology, a gate 𝑔 ∈ [0, 1]𝑑 is a vector that is used to filter out information from an incoming feature vector 𝑣 ∈ ℝ𝑑 such that the result of applying the gate is: 𝑔 ⊙ 𝑣 where ⊙ is the element-wise product. The gate 𝑔 will hence tend to remove part of the features in 𝑣 (those corresponding to very low values in 𝑔). In these blocks, an extra state is used, referred to as the cell state 𝐶𝑡. This state is computed as: 𝐶𝑡 = 𝑓𝑡 ⊙ 𝐶𝑡−1 + 𝑖𝑡 ⊙ ̃ 𝐶𝑡 (7.8) where 𝑓𝑡 is the forget gate (which pushes the network to forget about useless parts of the past cell state), 𝑖𝑡 is the input gate and ̃ 𝐶𝑡 is an updated version of the cell state (which, in turn, can be partly censored by the input gate). Let us delay for now the details about how these 3 terms are computed, and rather focus on how the formula above is significantly different from the update rule of the hidden state in vanilla RNNs. Indeed, in this case, if the network learns 7.2. Long Short-Term Memory 43
48.
Deep Learning Basics(lecture notes) so (through 𝑓𝑡), the full information from the previous cell state 𝐶𝑡−1 can be recovered, which would allow gradients to flow through time (and not vanish anymore). Then, the link between the cell and hidden states is: ℎ𝑡 = 𝑜𝑡 ⊙ tanh(𝐶𝑡) . (7.9) In words, the hidden state is the tanh-transformed version of the cell state, further censored by an output gate 𝑜𝑡. All gates used in the formulas above are defined similarly: 𝑓𝑡 = 𝜎(𝑊𝑓 ⋅ [ℎ𝑡−1, 𝑥𝑡] + 𝑏𝑓) (7.10) 𝑖𝑡 = 𝜎(𝑊𝑖 ⋅ [ℎ𝑡−1, 𝑥𝑡] + 𝑏𝑖) (7.11) 𝑜𝑡 = 𝜎(𝑊𝑜 ⋅ [ℎ𝑡−1, 𝑥𝑡] + 𝑏𝑜) (7.12) where 𝜎 is the sigmoid activation function (which has values in [0, 1]) and [ℎ𝑡−1, 𝑥𝑡] is the concatenation of ℎ𝑡−1 and 𝑥𝑡 features. Finally, the updated cell state ̃ 𝐶𝑡 is computed as: ̃ 𝐶𝑡 = tanh(𝑊𝐶 ⋅ [ℎ𝑡−1, 𝑥𝑡] + 𝑏𝐶) . (7.13) Many variants over these LSTM blocks exist in the literature that still rely on the same basic principles. 7.3 Gated Recurrent Unit A slightly different parametrization of a recurrent block is used in the so-called Gatted Recurrent Unit (GRU, [Cho et al., 2014]). GRUs also rely on the use of gates to (adaptively) let information flow through time. A first significant difference between GRUs and LSTMs, though, is that GRUs do not resort to the use of a cell state. Instead, the update rule for the hidden state is: ℎ𝑡 = (1 − 𝑧𝑡) ⊙ ℎ𝑡−1 + 𝑧𝑡 ⊙ ̃ ℎ𝑡 (7.14) where 𝑧𝑡 is a gate that balances (per feature) the amount of information that is kept from the previous hidden state with the amount of information that should be updated using the new candidate hidden state ̃ ℎ𝑡, computed as: ̃ ℎ𝑡 = tanh(𝑊 ⋅ [𝑟𝑡 ⊙ ℎ𝑡−1, 𝑥𝑡] + 𝑏) , (7.15) where 𝑟𝑡 is an extra gate that can hide part of the previous hidden state. Formulas for gates 𝑧𝑡 and 𝑟𝑡 are similar to those provided for 𝑓𝑡, 𝑖𝑡 and 𝑜𝑡 in the case of LSTMs. A graphical study of the ability of these variants of recurrent networks to learn long-term dependencies is provided in [Madsen, 2019]. 7.4 Conclusion In this chapter, we have reviewed neural network architectures that are used to learn from time series datasets. Because of time constraints, we have not tackled attention-based models in this course. We have presented convolutional models that aim at extracting discriminative local shapes in the series and recurrent models that rather leverage the notion of sequence. Concerning the latter, variants that aim at facing the vanishing gradient effect have been introduced. Note that recurrent models are known to require more training data than their convolutional counterparts in order to learn meaningful representations. 44 Chapter 7. Recurrent Neural Networks
49.
BIBLIOGRAPHY [Goh17] Gabriel Goh.Why momentum really works. Distill, 2017. URL: http://distill.pub/2017/momentum. [KB15] Diederik P. Kingma and Jimmy Ba. Adam: a method for stochastic optimization. In Yoshua Bengio and Yann LeCun, editors, ICLR. 2015. [SHK+14] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. Journal of Machine Learning Research, 15(56):1929–1958, 2014. URL: http://jmlr.org/papers/v15/srivastava14a.html. [FFW+19] Hassan Ismail Fawaz, Germain Forestier, Jonathan Weber, Lhassane Idoumghar, and Pierre-Alain Muller. Deep learning for time series classification: a review. Data Mining and Knowledge Discovery, 33(4):917– 963, 2019. [FLF+20] Hassan Ismail Fawaz, Benjamin Lucas, Germain Forestier, Charlotte Pelletier, Daniel F Schmidt, Jonathan Weber, Geoffrey I Webb, Lhassane Idoumghar, Pierre-Alain Muller, and François Petitjean. Inception- time: finding alexnet for time series classification. Data Mining and Knowledge Discovery, 34(6):1936–1962, 2020. [LGMT16] Arthur Le Guennec, Simon Malinowski, and Romain Tavenard. Data Augmentation for Time Series Clas- sification using Convolutional Neural Networks. In ECML/PKDD Workshop on Advanced Analytics and Learning on Temporal Data. Riva Del Garda, Italy, September 2016. [LBBH98] Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to docu- ment recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998. [CVMerrienboerBB14] Kyunghyun Cho, Bart Van Merriënboer, Dzmitry Bahdanau, and Yoshua Bengio. On the prop- erties of neural machine translation: encoder-decoder approaches. 2014. arXiv:1409.1259. [HS97] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997. [Mad19] Andreas Madsen. Visualizing memorization in rnns. Distill, 2019. URL: https://distill.pub/2019/ memorization-in-rnns. 45








![Deep Learning Basics (lecture notes) 1.2 Optimization The models presented in this book are aimed at solving prediction problems, in which the goal is to find “good enough” parameter values for the model at stake given some observed data. The problem of finding such parameter values is coined optimization and the deep learning field makes extensive use of a specific family of optimization strategies called gradient descent. 1.2.1 Gradient Descent To make one’s mind about gradient descent, let us assume we are given the following dataset about house prices: import pandas as pd boston = pd.read_csv("../data/boston.csv")[["RM", "PRICE"]] boston RM PRICE 0 6.575 24.0 1 6.421 21.6 2 7.185 34.7 3 6.998 33.4 4 7.147 36.2 .. ... ... 501 6.593 22.4 502 6.120 20.6 503 6.976 23.9 504 6.794 22.0 505 6.030 11.9 [506 rows x 2 columns] In our case, we will try (for a start) to predict the target value of this dataset, which is the median value of owner-occupied homes in $1000 "PRICE", as a function of the average number of rooms per dwelling "RM" : sns.scatterplot(data=boston, x="RM", y="PRICE"); 4 Chapter 1. Introduction](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-8-2048.jpg)
![Deep Learning Basics (lecture notes) A short note on this model In the Perceptron terminology, this model: • has no activation function (i.e. 𝜑 is the identity function) • has no bias (i.e. 𝑏 is forced to be 0, it is not learnt) Let us assume we have a naive approach in which our prediction model is linear without intercept, that is, for a given input 𝑥𝑖 the predicted output is computed as: ̂ 𝑦𝑖 = 𝑤𝑥𝑖 where 𝑤 is the only parameter of our model. Let us further assume that the quantity we aim at minimizing (our objective, also called loss) is: ℒ(𝑤) = ∑ 𝑖 ( ̂ 𝑦𝑖 − 𝑦𝑖) 2 where 𝑦𝑖 is the ground truth value associated with the 𝑖-th sample in our dataset. Let us have a look at this quantity as a function of 𝑤: import numpy as np def loss(w, x, y): w = np.array(w) return np.sum( (w[:, None] * x.to_numpy()[None, :] - y.to_numpy()[None, :]) ** 2, axis=1 ) w = np.linspace(-2, 10, num=100) x = boston["RM"] y = boston["PRICE"] plt.plot(w, loss(w, x, y), "r-"); 1.2. Optimization 5](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-9-2048.jpg)
![Deep Learning Basics (lecture notes) Here, it seems that a value of 𝑤 around 4 should be a good pick, but this method (generating lots of values for the parameter and computing the loss for each value) cannot scale to models that have lots of parameters, so we will try something else. Let us suppose we have access, each time we pick a candidate value for 𝑤, to both the loss ℒ and information about how ℒ varies, locally. We could, in this case, compute a new candidate value for 𝑤 by moving from the previous candidate value in the direction of steepest descent. This is the basic idea behind the gradient descent algorithm that, from an initial candidate 𝑤0, iteratively computes new candidates as: 𝑤𝑡+1 = 𝑤𝑡 − 𝜌 𝜕ℒ 𝜕𝑤 ∣ 𝑤=𝑤𝑡 where 𝜌 is a hyper-parameter (called the learning rate) that controls the size of the steps to be done, and 𝜕ℒ 𝜕𝑤 ∣𝑤=𝑤𝑡 is the gradient of ℒ with respect to 𝑤, evaluated at 𝑤 = 𝑤𝑡. As you can see, the direction of steepest descent is the opposite of the direction pointed by the gradient (and this holds when dealing with vector parameters too). This process is repeated until convergence, as illustrated in the following visualization: rho = 1e-5 def grad_loss(w_t, x, y): return np.sum( 2 * (w_t * x - y) * x ) ww = np.linspace(-2, 10, num=100) plt.plot(ww, loss(ww, x, y), "r-", alpha=.5); w = [0.] for t in range(10): w_update = w[t] - rho * grad_loss(w[t], x, y) w.append(w_update) plt.plot(w, loss(w, x, y), "ko-") plt.text(x=w[0]+.1, y=loss([w[0]], x, y), s="$w_{0}$") plt.text(x=w[10]+.1, y=loss([w[10]], x, y), s="$w_{10}$"); 6 Chapter 1. Introduction](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-10-2048.jpg)
![Deep Learning Basics (lecture notes) What would we get if we used a smaller learning rate? rho = 1e-6 ww = np.linspace(-2, 10, num=100) plt.plot(ww, loss(ww, x, y), "r-", alpha=.5); w = [0.] for t in range(10): w_update = w[t] - rho * grad_loss(w[t], x, y) w.append(w_update) plt.plot(w, loss(w, x, y), "ko-") plt.text(x=w[0]+.1, y=loss([w[0]], x, y), s="$w_{0}$") plt.text(x=w[10]+.1, y=loss([w[10]], x, y), s="$w_{10}$"); It would definitely take more time to converge. But, take care, a larger learning rate is not always a good idea: rho = 5e-5 ww = np.linspace(-2, 10, num=100) plt.plot(ww, loss(ww, x, y), "r-", alpha=.5); (continues on next page) 1.2. Optimization 7](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-11-2048.jpg)
![Deep Learning Basics (lecture notes) (continued from previous page) w = [0.] for t in range(10): w_update = w[t] - rho * grad_loss(w[t], x, y) w.append(w_update) plt.plot(w, loss(w, x, y), "ko-") plt.text(x=w[0]-1., y=loss([w[0]], x, y), s="$w_{0}$") plt.text(x=w[10]-1., y=loss([w[10]], x, y), s="$w_{10}$"); See how we are slowly diverging because our steps are too large? 1.3 Wrap-up In this section, we have introduced: • a very simple model, called the Perceptron: this will be a building block for the more advanced models we will detail later in the course, such as: – the Multi-Layer Perceptron – Convolutional architectures – Recurrent architectures • the fact that a task comes with a loss function to be minimized (here, we have used the mean squared error (MSE) for our regression task), which will be discussed in a dedicated chapter; • the concept of gradient descent to optimize the chosen loss over a model’s single parameter, and this will be extended in our chapter on optimization. 8 Chapter 1. Introduction](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-12-2048.jpg)


![Deep Learning Basics (lecture notes) 2.2 Deciding on an MLP architecture When designing a Multi-Layer Perceptron model to be used for a specific problem, some quantities are fixed by the problem at hand and other are left as hyper-parameters. Let us take the example of the well-known Iris classification dataset: import pandas as pd iris = pd.read_csv("../data/iris.csv", index_col=0) iris sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) 0 5.1 3.5 1.4 0.2 1 4.9 3.0 1.4 0.2 2 4.7 3.2 1.3 0.2 3 4.6 3.1 1.5 0.2 4 5.0 3.6 1.4 0.2 .. ... ... ... ... 145 6.7 3.0 5.2 2.3 146 6.3 2.5 5.0 1.9 147 6.5 3.0 5.2 2.0 148 6.2 3.4 5.4 2.3 149 5.9 3.0 5.1 1.8 target 0 0 1 0 2 0 3 0 4 0 .. ... 145 2 146 2 147 2 148 2 149 2 [150 rows x 5 columns] The goal here is to learn how to infer the target attribute (3 different possible classes) from the information in the 4 other attributes. The structure of this dataset dictates: • the number of neurons in the input layer, which is equal to the number of descriptive attributes in our dataset (here, 4), and • the number of neurons in the output layer, which is here equal to 3, since the model is expected to output one probability per target class. In more generality, for the output layer, one might face several situations: • when regression is at stake, the number of neurons in the output layer is equal to the number of features to be predicted by the model, • when it comes to classification 2.2. Deciding on an MLP architecture 11](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-15-2048.jpg)
![Deep Learning Basics (lecture notes) 2.3.1 The special case of the output layer You might have noticed that in the MLP formulation provided in Equation (1), the output layer has its own activation function, denoted 𝜑out. This is because the choice of activation functions for the output layer of a neural network is a bit specific to the problem at hand. Indeed, you might have seen that the activation functions discussed in the previous section do not share the same range of output values. It is hence of prime importance to pick an adequate activation function for the output layer such that our model outputs values that are consistent to the quantities it is supposed to predict. If, for example, our model was supposed to be used in the Boston Housing dataset we discussed in the previous chapter. In this case, the goal is to predict housing prices, which are expected to be nonnegative quantities. It would then be a good idea to use ReLU (which can output any positive value) as the activation function for the output layer in this case. As stated earlier, in the case of binary classification, the model will have a single output neuron and this neuron will output the probability associated to the positive class. This quantity is expected to lie in the [0, 1] interval, and the sigmoid activation function is then the default choice in this setting. Finally, when multi-class classification is at stake, we have one neuron per output class and each neuron is expected to output the probability for a given class. In this context, the output values should be between 0 and 1, and they should sum to 1. For this purpose, we use the softmax activation function defined as: ∀𝑖, softmax(𝑜𝑖) = 𝑒𝑜𝑖 ∑𝑗 𝑒𝑜𝑗 where, for all 𝑖, 𝑜𝑖’s are the values of the output neurons before applying the activation function. 2.4 Declaring an MLP in keras In order to define a MLP model in keras, one just has to stack layers. As an example, if one wants to code a model made of: • an input layer with 10 neurons, • a hidden layer made of 20 neurons with ReLU activation, • an output layer made of 3 neurons with softmax activation, the code will look like: import keras_core as keras from keras.layers import Dense, InputLayer from keras.models import Sequential model = Sequential([ InputLayer(input_shape=(10, )), Dense(units=20, activation="relu"), Dense(units=3, activation="softmax") ]) model.summary() Using TensorFlow backend Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # (continues on next page) 2.4. Declaring an MLP in keras 13](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-17-2048.jpg)
![Deep Learning Basics (lecture notes) (continued from previous page) ================================================================= dense (Dense) (None, 20) 220 dense_1 (Dense) (None, 3) 63 ================================================================= Total params: 283 (1.11 KB) Trainable params: 283 (1.11 KB) Non-trainable params: 0 (0.00 Byte) _________________________________________________________________ Note that model.summary() provides an interesting overview of a defined model and its parameters. Exercise #1 Relying on what we have seen in this chapter, can you explain the number of parameters returned by model. summary() above? Solution Our input layer is made of 10 neurons, and our first layer is fully connected, hence each of these neurons is connected to a neuron in the hidden layer through a parameter, which already makes 10 × 20 = 200 parameters. Moreover, each of the hidden layer neurons has its own bias parameter, which is 20 more parameters. We then have 220 parameters, as output by model.summary() for the layer "dense (Dense)". Similarly, for the connection of the hidden layer neurons to those in the output layer, the total number of parameters is 20 × 3 = 60 for the weights plus 3 extra parameters for the biases. Overall, we have 220 + 63 = 283 parameters in this model. Exercise #2 Declare, in keras, an MLP with one hidden layer made of 100 neurons and ReLU activation for the Iris dataset presented above. Solution model = Sequential([ InputLayer(input_shape=(4, )), Dense(units=100, activation="relu"), Dense(units=3, activation="softmax") ]) Exercise #3 Same question for the full Boston Housing dataset shown below (the goal here is to predict the PRICE feature based on the other ones). Solution 14 Chapter 2. Multi Layer Perceptrons](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-18-2048.jpg)
![Deep Learning Basics (lecture notes) model = Sequential([ InputLayer(input_shape=(6, )), Dense(units=100, activation="relu"), Dense(units=1, activation="relu") ]) RM CRIM INDUS NOX AGE TAX PRICE 0 6.575 0.00632 2.31 0.538 65.2 296.0 24.0 1 6.421 0.02731 7.07 0.469 78.9 242.0 21.6 2 7.185 0.02729 7.07 0.469 61.1 242.0 34.7 3 6.998 0.03237 2.18 0.458 45.8 222.0 33.4 4 7.147 0.06905 2.18 0.458 54.2 222.0 36.2 .. ... ... ... ... ... ... ... 501 6.593 0.06263 11.93 0.573 69.1 273.0 22.4 502 6.120 0.04527 11.93 0.573 76.7 273.0 20.6 503 6.976 0.06076 11.93 0.573 91.0 273.0 23.9 504 6.794 0.10959 11.93 0.573 89.3 273.0 22.0 505 6.030 0.04741 11.93 0.573 80.8 273.0 11.9 [506 rows x 7 columns] 2.4. Declaring an MLP in keras 15](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-19-2048.jpg)



![Deep Learning Basics (lecture notes) Apart from implying more frequent parameter updates, SGD has an extra benefit in terms of optimization, which is key for neural networks. Indeed, as one can see below, contrary to what we had in the Perceptron case, the MSE loss (and the same applies for the logistic loss) is no longer convex in the model parameters as soon as the model has at least one hidden layer: Gradient Descent is known to suffer from local optima, and such loss landscapes are a serious problem for GD. On the other hand, Stochastic Gradient Descent is likely to benefit from noisy gradient estimations to escape local minima. 4.2 A note on Adam Adam [Kingma and Ba, 2015] is a variant of the Stochastic Gradient Descent method. It differs in the definition of the steps to be performed at each parameter update. First, it uses what is called momentum, which basically consists in relying on past gradient updates to smooth out the trajectory in parameter space during optimization. An interactive illustration of momentum can be found in [Goh, 2017]. The resulting plugin replacement for the gradient is: m(𝑡+1) ← 1 1 − 𝛽𝑡 1 [𝛽1m(𝑡) + (1 − 𝛽1)∇𝜃ℒ] When 𝛽1 is zero, we have m(𝑡+1) = ∇𝜃ℒ and for 𝛽1 ∈]0, 1[, m(𝑡+1) balances the current gradient estimate with infor- mation about past estimates, stored in m(𝑡) . Another important difference between SGD and the Adam variant consists in using an adaptive learning rate. In other words, instead of using the same learning rate 𝜌 for all model parameters, the learning rate for a given parameter 𝜃𝑖 is defined as: ̂ 𝜌(𝑡+1) (𝜃𝑖) = 𝜌 √𝑠(𝑡+1)(𝜃𝑖) + 𝜖 where 𝜖 is a small constant and 𝑠(𝑡+1) (𝜃𝑖) = 1 1 − 𝛽𝑡 2 [𝛽2𝑠(𝑡) (𝜃𝑖) + (1 − 𝛽2) (∇𝜃𝑖 ℒ) 2 ] Here also, the 𝑠 term uses momentum. As a result, the learning rate will be lowered for parameters which have suffered large updates in the past iterations. Overall, the Adam update rule is: 𝜃(𝑡+1) ← 𝜃(𝑡) − ̂ 𝜌(𝑡+1) (𝜃)m(𝑡+1) 4.2. A note on Adam 21](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-25-2048.jpg)

![Deep Learning Basics (lecture notes) One can see that the derivative of ReLU has a wider range of input values for which it is non-zero (typically the whole range of positive input values) than its competitors, which makes it a very attractive candidate activation function for deep neural networks, as we have seen that the 𝜕𝑎(ℓ) 𝜕𝑜(ℓ) term appears repeatedly in chain rule derivations. 4.4 Wrapping things up in keras In keras, loss and optimizer information are passed at compile time: import keras_core as keras from keras.layers import Dense, InputLayer from keras.models import Sequential model = Sequential([ InputLayer(input_shape=(10, )), Dense(units=20, activation="relu"), Dense(units=3, activation="softmax") ]) model.summary() Using TensorFlow backend Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 20) 220 dense_1 (Dense) (None, 3) 63 ================================================================= Total params: 283 (1.11 KB) Trainable params: 283 (1.11 KB) Non-trainable params: 0 (0.00 Byte) _________________________________________________________________ model.compile(loss="categorical_crossentropy", optimizer="adam") In terms of losses: • "mse" is the mean squared error loss, 4.4. Wrapping things up in keras 23](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-27-2048.jpg)
![Deep Learning Basics (lecture notes) • "binary_crossentropy" is the logistic loss for binary classification, • "categorical_crossentropy" is the logistic loss for multi-class classification. The optimizers defined in this section are available as "sgd" and "adam". In order to get control over optimizer hyper-parameters, one can alternatively use the following syntax: from keras.optimizers import Adam, SGD # Not a very good idea to tune beta_1 # and beta_2 parameters in Adam adam_opt = Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.9) # In order to use SGD with a custom learning rate: # sgd_opt = SGD(learning_rate=0.001) model.compile(loss="categorical_crossentropy", optimizer=adam_opt) 4.5 Data preprocessing In practice, for the model fitting phase to behave well, it is important to scale the input features. In the following example, we will compare two trainings of the same model, with similar initialization and the only difference between both will be whether input data is center-reduced or left as-is. import pandas as pd from keras.utils import to_categorical iris = pd.read_csv("../data/iris.csv", index_col=0) iris = iris.sample(frac=1) y = to_categorical(iris["target"]) X = iris.drop(columns=["target"]) from keras.layers import Dense, InputLayer from keras.models import Sequential from keras.utils import set_random_seed set_random_seed(0) model = Sequential([ InputLayer(input_shape=(4, )), Dense(units=256, activation="relu"), Dense(units=256, activation="relu"), Dense(units=256, activation="relu"), Dense(units=3, activation="softmax") ]) n_epochs = 100 model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"]) h = model.fit(X, y, epochs=n_epochs, batch_size=30, verbose=0) Let us now standardize our data and compare performance: 24 Chapter 4. Optimization](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-28-2048.jpg)
![Deep Learning Basics (lecture notes) X -= X.mean(axis=0) X /= X.std(axis=0) set_random_seed(0) model = Sequential([ InputLayer(input_shape=(4, )), Dense(units=256, activation="relu"), Dense(units=256, activation="relu"), Dense(units=256, activation="relu"), Dense(units=3, activation="softmax") ]) n_epochs = 100 model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"]) h_standardized = model.fit(X, y, epochs=n_epochs, batch_size=30, verbose=0) 4.5. Data preprocessing 25](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-29-2048.jpg)

![CHAPTER 5 REGULARIZATION As discussed in previous chapters, one of the strengths of the neural networks is that they can approximate any continuous functions when a sufficient number of parameters is used. When using universal approximators in machine learning settings, an important related risk is that of overfitting the training data. More formally, given a training dataset 𝒟𝑡 drawn from an unknown distribution 𝒟, model parameters are optimized so as to minimize the empirical risk: ℛ𝑒(𝜃) = 1 |𝒟𝑡| ∑ (𝑥𝑖,𝑦𝑖)∈𝒟𝑡 ℒ(𝑥𝑖, 𝑦𝑖; 𝑚𝜃) whereas the real objective is to minimize the “true” risk: ℛ(𝜃) = 𝔼𝑥,𝑦∼𝒟ℒ(𝑥, 𝑦; 𝑚𝜃) and both objectives do not have the same minimizer. To avoid this pitfall, one should use regularization techniques, such as the ones presented in the following. 5.1 Early Stopping As illustrated below, it can be observed that training a neural network for a too large number of epochs can lead to overfitting. Note that here, the true risk is estimated through the use of a validation set that is not seen during training. Using TensorFlow backend iris = pd.read_csv("../data/iris.csv", index_col=0) iris = iris.sample(frac=1) y = to_categorical(iris["target"]) X = iris.drop(columns=["target"]) X -= X.mean(axis=0) X /= X.std(axis=0) 27](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-31-2048.jpg)
![Deep Learning Basics (lecture notes) import keras_core as keras from keras.layers import Dense, InputLayer from keras.models import Sequential from keras.utils import set_random_seed set_random_seed(0) model = Sequential([ InputLayer(input_shape=(4, )), Dense(units=256, activation="relu"), Dense(units=256, activation="relu"), Dense(units=256, activation="relu"), Dense(units=3, activation="softmax") ]) n_epochs = 100 model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"]) h = model.fit(X, y, validation_split=0.3, epochs=n_epochs, batch_size=30, verbose=0) Here, the best model (in terms of generalization capabilities) seems to be the model at epoch 43. In other words, if we had stopped the learning process after epoch 43, we would have gotten a better model than if we use the model trained during 70 epochs. This is the whole idea behind the “early stopping” strategy, which consists in stopping the learning process as soon as the validation loss stops improving. As can be seen in the visualization above, however, the validation loss tends to oscillate, and one often waits for several epochs before assuming that the loss is unlikely to improve in the future. The number of epochs to wait is called the patience parameter. In keras, early stopping can be set up via a callback, as in the following example: from keras.callbacks import EarlyStopping set_random_seed(0) model = Sequential([ InputLayer(input_shape=(4, )), Dense(units=256, activation="relu"), Dense(units=256, activation="relu"), (continues on next page) 28 Chapter 5. Regularization](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-32-2048.jpg)
![Deep Learning Basics (lecture notes) (continued from previous page) Dense(units=256, activation="relu"), Dense(units=3, activation="softmax") ]) cb_es = EarlyStopping(monitor="val_loss", patience=10, restore_best_weights=True) n_epochs = 100 model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"]) h = model.fit(X, y, validation_split=0.3, epochs=n_epochs, batch_size=30, verbose=0, callbacks=[cb_es]) And now, even is the model was scheduled to be trained for 70 epochs, training is stopped as soon as it reaches 10 consecutive epochs without improving on the validation loss, and the model parameters are restored as the parameters of the model at epoch 43. 5.2 Loss penalization Another important way to enforce regularization in neural networks is through loss penalization. A typical instance of this regularization strategy is the L2 regularization. If we denote by ℒ𝑟 the L2-regularized loss, it can be expressed as: ℒ𝑟(𝒟; 𝑚𝜃) = ℒ(𝒟; 𝑚𝜃) + 𝜆 ∑ ℓ ‖𝜃(ℓ) ‖2 2 where 𝜃(ℓ) is the weight matrix of layer ℓ. This regularization tends to shrink large parameter values during the learning process, which is known to help improve generalization. In keras, this is implemented as: from keras.regularizers import L2 λ = 0.01 (continues on next page) 5.2. Loss penalization 29](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-33-2048.jpg)
![Deep Learning Basics (lecture notes) (continued from previous page) set_random_seed(0) model = Sequential([ InputLayer(input_shape=(4, )), Dense(units=256, activation="relu", kernel_regularizer=L2(λ)), Dense(units=256, activation="relu", kernel_regularizer=L2(λ)), Dense(units=256, activation="relu", kernel_regularizer=L2(λ)), Dense(units=3, activation="softmax") ]) n_epochs = 100 model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"]) h = model.fit(X, y, validation_split=0.3, epochs=n_epochs, batch_size=30, verbose=0) 5.3 DropOut Fig. 5.1: Illustration of the DropOut mechanism. In order to train a given model (left), at each mini-batch, a given proportion of neurons is picked at random to be “switched off” and the subsequent sub-network is used for the current optimization step (cf. right-hand side figure, in which 40% of the neurons – coloured in gray – are switched off). In this section, we present the DropOut strategy, which was introduced in [Srivastava et al., 2014]. The idea behind DropOut is to switch off some of the neurons during training. The switched off neurons change at each mini-batch such 30 Chapter 5. Regularization](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-34-2048.jpg)
![Deep Learning Basics (lecture notes) that, overall, all neurons are trained during the whole process. The concept is very similar in spirit to a strategy that is used for training random forest, which consists in randomly selecting candidate variables for each tree split inside a forest, which is known to lead to better generalization performance for random forests. The main difference here is that one can not only switch off input neurons but also hidden-layer ones during training. In keras, this is implemented as a layer, which acts by switching off neurons from the previous layer in the network: from keras.layers import Dropout set_random_seed(0) switchoff_proba = 0.3 model = Sequential([ InputLayer(input_shape=(4, )), Dropout(rate=switchoff_proba), Dense(units=256, activation="relu"), Dropout(rate=switchoff_proba), Dense(units=256, activation="relu"), Dropout(rate=switchoff_proba), Dense(units=256, activation="relu"), Dropout(rate=switchoff_proba), Dense(units=3, activation="softmax") ]) n_epochs = 100 model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"]) h = model.fit(X, y, validation_split=0.3, epochs=n_epochs, batch_size=30, verbose=0) Exercise #1 When observing the loss values in the figure above, can you explain why the validation loss is almost consistently lower than the training one? Solution In fact, the training loss is computed as the average loss over all training mini-batches during an epoch. Now, if we recall that during training, at each minibatch, 30% of the neurons are switched-off, one can see that only a subpart of the full 5.3. DropOut 31](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-35-2048.jpg)


![Deep Learning Basics (lecture notes) Convolutional models are known to perform very well in computer vision applications, using moderate amounts of pa- rameters compared to fully connected ones (of course, counter-examples exist, and the term “moderate” is especially vague). Most standard time series architectures that rely on convolutional blocks are straight-forward adaptations of models from the computer vision community ([Le Guennec et al., 2016] relies on an old-fashioned alternance between convolution and pooling layers, while more recent works rely on residual connections and inception modules [Fawaz et al., 2020]). These basic blocks (convolution, pooling, residual layers) are discussed in more details in the next Section. These time series classification models (and more) are presented and benchmarked in [Fawaz et al., 2019] that we advise the interested reader to refer to for more details. 6.2 Convolutional neural networks for images We now turn our focus to the 2D case, in which our convolution filters will not slide on a single axis as in the time series case but rather on the two dimensions (width and height) of an image. 6.2.1 Images and convolutions As seen below, an image is a pixel grid, and each pixel has an intensity value in each of the image channels. Color images are typically made of 3 channels (Red, Green and Blue here). Fig. 6.1: An image and its 3 channels (Red, Green and Blue intensity, from left to right). The output of a convolution on an image x is a new image, whose pixel values can be computed as: (x ∗ f) (𝑖, 𝑗) = 𝐾 ∑ 𝑘=−𝐾 𝐿 ∑ 𝑙=−𝐿 3 ∑ 𝑐=1 𝑓𝑘,𝑙,𝑐𝑥𝑖+𝑘,𝑗+𝑙,𝑐. (6.2) In other words, the output image pixels are computed as the dot product between a convolution filter (which is a tensor of shape (2𝐾 + 1, 2𝐿 + 1, 𝑐)) and the image patch centered at the given position. Let us, for example, consider the following 9x9 convolution filter: 34 Chapter 6. Convolutional Neural Networks](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-38-2048.jpg)

![Deep Learning Basics (lecture notes) 6.2.2 CNNs à la LeNet In [LeCun et al., 1998], a stack of convolution, pooling and fully connected layers is introduced for an image classification task, more specifically a digit recognition application. The resulting neural network, called LeNet, is depicted below: Fig. 6.2: LeNet-5 model Convolution layers A convolution layer is made of several convolution filters (also called kernels) that operate in parallel on the same input image. Each convolution filter generates an output activation map and all these maps are stacked (in the channel dimension) to form the output of the convolution layer. All filters in a layer share the same width and height. A bias term and an activation function can be used in convolution layers, as in other neural network layers. All in all, the output of a convolution filter is computed as: (x ∗ f) (𝑖, 𝑗, 𝑐) = 𝜑 ( 𝐾 ∑ 𝑘=−𝐾 𝐿 ∑ 𝑙=−𝐿 ∑ 𝑐′ 𝑓𝑐 𝑘,𝑙,𝑐′ 𝑥𝑖+𝑘,𝑗+𝑙,𝑐′ + 𝑏𝑐) (6.3) where 𝑐 denotes the output channel (note that each output channel is associated with a filter 𝑓𝑐 ), 𝑏𝑐 is its associated bias term and 𝜑 is the activation function to be used. Tip: In keras, such a layer is implemented using the Conv2D class: import keras_core as keras from keras.layers import Conv2D layer = Conv2D(filters=6, kernel_size=5, padding="valid", activation="relu") Padding 36 Chapter 6. Convolutional Neural Networks](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-40-2048.jpg)


![Deep Learning Basics (lecture notes) (continued from previous page) MaxPool2D(pool_size=2), Conv2D(filters=16, kernel_size=5, padding="valid", activation="relu"), MaxPool2D(pool_size=2), Flatten(), Dense(120, activation="relu"), Dense(84, activation="relu"), Dense(10, activation="softmax") ]) model.summary() Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 28, 28, 6) 156 max_pooling2d (MaxPooling2 (None, 14, 14, 6) 0 D) conv2d_1 (Conv2D) (None, 10, 10, 16) 2416 max_pooling2d_1 (MaxPoolin (None, 5, 5, 16) 0 g2D) flatten (Flatten) (None, 400) 0 dense (Dense) (None, 120) 48120 dense_1 (Dense) (None, 84) 10164 dense_2 (Dense) (None, 10) 850 ================================================================= Total params: 61706 (241.04 KB) Trainable params: 61706 (241.04 KB) Non-trainable params: 0 (0.00 Byte) _________________________________________________________________ 6.2. Convolutional neural networks for images 39](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-43-2048.jpg)


![Deep Learning Basics (lecture notes) 7.1 “Vanilla” RNNs The basic formulation for a RNN block is as follows: ∀𝑡, ℎ𝑡 = tanh(𝑊ℎℎ𝑡−1 + 𝑊𝑥𝑥𝑡 + 𝑏) (7.1) where 𝑊ℎ is a weight matrix associated to the processing of the previous hidden state, 𝑊𝑥 is another weight matrix associated to the processing of the current input and 𝑏 is a bias term. Note here that 𝑊ℎ, 𝑊𝑥 and 𝑏 are not indexed by 𝑡, which means that they are shared across all timestamps. An important limitation of this formula is that it easily fails at capturing long-term dependencies. To better understand why, one should remind that the parameters of these networks are optimized through stochastic gradient descent algo- rithms. To simplify notations, let us consider a simplified case in which ℎ𝑡 and 𝑥𝑡 are both scalar values, and let us have a look at what the actual gradient of the output ℎ𝑡 is, with respect to 𝑊ℎ (which is then also a scalar): ∇𝑊ℎ (ℎ𝑡) = tanh ′ (𝑜𝑡) ⋅ 𝜕𝑜𝑡 𝜕𝑊ℎ (7.2) where 𝑜𝑡 = 𝑊ℎℎ𝑡−1 + 𝑊𝑥𝑥𝑡 + 𝑏, hence: 𝜕𝑜𝑡 𝜕𝑊ℎ = ℎ𝑡−1 + 𝑊ℎ ⋅ 𝜕ℎ𝑡−1 𝜕𝑊ℎ . (7.3) Here, the form of 𝜕ℎ𝑡−1 𝜕𝑊ℎ will be similar to that of ∇𝑊ℎ (ℎ𝑡) above, and, in the end, one gets: ∇𝑊ℎ (ℎ𝑡) = tanh ′ (𝑜𝑡) ⋅ [ℎ𝑡−1 + 𝑊ℎ ⋅ 𝜕ℎ𝑡−1 𝜕𝑊ℎ ] (7.4) = tanh ′ (𝑜𝑡) ⋅ [ℎ𝑡−1 + 𝑊ℎ ⋅ tanh ′ (𝑜𝑡−1) ⋅ [ℎ𝑡−2 + 𝑊ℎ ⋅ [… ]]] (7.5) = ℎ𝑡−1tanh ′ (𝑜𝑡) + ℎ𝑡−2𝑊ℎtanh ′ (𝑜𝑡)tanh ′ (𝑜𝑡−1) + … (7.6) = 𝑡−1 ∑ 𝑡′=1 ℎ𝑡′ [𝑊𝑡−𝑡′ −1 ℎ tanh ′ (𝑜𝑡′+1) ⋅ ⋯ ⋅ tanh ′ (𝑜𝑡)] (7.7) In other words, the influence of ℎ𝑡′ will be mitigated by a factor 𝑊𝑡−𝑡′ −1 ℎ tanh ′ (𝑜𝑡′+1) ⋅ ⋯ ⋅ tanh ′ (𝑜𝑡). Now recall what the tanh function and its derivative look like: 42 Chapter 7. Recurrent Neural Networks](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-46-2048.jpg)
![Deep Learning Basics (lecture notes) One can see how quickly gradients gets close to 0 for inputs larger (in absolute value) than 2, and having multiple such terms in a computation chain will likely make the corresponding terms vanish. In other words, the gradient of the hidden state at time 𝑡 will only be influenced by a few of its predecessors {ℎ𝑡−1, ℎ𝑡−2, … } and long-term dependencies will be ignored when updating model parameters through gradient descent. This is an occurrence of a more general phenomenon known as the vanishing gradient effect. 7.2 Long Short-Term Memory The Long Short-Term Memory (LSTM, [Hochreiter and Schmidhuber, 1997]) blocks have been designed as an alternative recurrent block that aims at mitigating this vanishing gradient effect through the use of gates that explicitly encode pieces of information that should (resp. should not) be kept in computations. Gates in neural networks In the neural networks terminology, a gate 𝑔 ∈ [0, 1]𝑑 is a vector that is used to filter out information from an incoming feature vector 𝑣 ∈ ℝ𝑑 such that the result of applying the gate is: 𝑔 ⊙ 𝑣 where ⊙ is the element-wise product. The gate 𝑔 will hence tend to remove part of the features in 𝑣 (those corresponding to very low values in 𝑔). In these blocks, an extra state is used, referred to as the cell state 𝐶𝑡. This state is computed as: 𝐶𝑡 = 𝑓𝑡 ⊙ 𝐶𝑡−1 + 𝑖𝑡 ⊙ ̃ 𝐶𝑡 (7.8) where 𝑓𝑡 is the forget gate (which pushes the network to forget about useless parts of the past cell state), 𝑖𝑡 is the input gate and ̃ 𝐶𝑡 is an updated version of the cell state (which, in turn, can be partly censored by the input gate). Let us delay for now the details about how these 3 terms are computed, and rather focus on how the formula above is significantly different from the update rule of the hidden state in vanilla RNNs. Indeed, in this case, if the network learns 7.2. Long Short-Term Memory 43](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-47-2048.jpg)
![Deep Learning Basics (lecture notes) so (through 𝑓𝑡), the full information from the previous cell state 𝐶𝑡−1 can be recovered, which would allow gradients to flow through time (and not vanish anymore). Then, the link between the cell and hidden states is: ℎ𝑡 = 𝑜𝑡 ⊙ tanh(𝐶𝑡) . (7.9) In words, the hidden state is the tanh-transformed version of the cell state, further censored by an output gate 𝑜𝑡. All gates used in the formulas above are defined similarly: 𝑓𝑡 = 𝜎(𝑊𝑓 ⋅ [ℎ𝑡−1, 𝑥𝑡] + 𝑏𝑓) (7.10) 𝑖𝑡 = 𝜎(𝑊𝑖 ⋅ [ℎ𝑡−1, 𝑥𝑡] + 𝑏𝑖) (7.11) 𝑜𝑡 = 𝜎(𝑊𝑜 ⋅ [ℎ𝑡−1, 𝑥𝑡] + 𝑏𝑜) (7.12) where 𝜎 is the sigmoid activation function (which has values in [0, 1]) and [ℎ𝑡−1, 𝑥𝑡] is the concatenation of ℎ𝑡−1 and 𝑥𝑡 features. Finally, the updated cell state ̃ 𝐶𝑡 is computed as: ̃ 𝐶𝑡 = tanh(𝑊𝐶 ⋅ [ℎ𝑡−1, 𝑥𝑡] + 𝑏𝐶) . (7.13) Many variants over these LSTM blocks exist in the literature that still rely on the same basic principles. 7.3 Gated Recurrent Unit A slightly different parametrization of a recurrent block is used in the so-called Gatted Recurrent Unit (GRU, [Cho et al., 2014]). GRUs also rely on the use of gates to (adaptively) let information flow through time. A first significant difference between GRUs and LSTMs, though, is that GRUs do not resort to the use of a cell state. Instead, the update rule for the hidden state is: ℎ𝑡 = (1 − 𝑧𝑡) ⊙ ℎ𝑡−1 + 𝑧𝑡 ⊙ ̃ ℎ𝑡 (7.14) where 𝑧𝑡 is a gate that balances (per feature) the amount of information that is kept from the previous hidden state with the amount of information that should be updated using the new candidate hidden state ̃ ℎ𝑡, computed as: ̃ ℎ𝑡 = tanh(𝑊 ⋅ [𝑟𝑡 ⊙ ℎ𝑡−1, 𝑥𝑡] + 𝑏) , (7.15) where 𝑟𝑡 is an extra gate that can hide part of the previous hidden state. Formulas for gates 𝑧𝑡 and 𝑟𝑡 are similar to those provided for 𝑓𝑡, 𝑖𝑡 and 𝑜𝑡 in the case of LSTMs. A graphical study of the ability of these variants of recurrent networks to learn long-term dependencies is provided in [Madsen, 2019]. 7.4 Conclusion In this chapter, we have reviewed neural network architectures that are used to learn from time series datasets. Because of time constraints, we have not tackled attention-based models in this course. We have presented convolutional models that aim at extracting discriminative local shapes in the series and recurrent models that rather leverage the notion of sequence. Concerning the latter, variants that aim at facing the vanishing gradient effect have been introduced. Note that recurrent models are known to require more training data than their convolutional counterparts in order to learn meaningful representations. 44 Chapter 7. Recurrent Neural Networks](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-48-2048.jpg)
![BIBLIOGRAPHY [Goh17] Gabriel Goh. Why momentum really works. Distill, 2017. URL: http://distill.pub/2017/momentum. [KB15] Diederik P. Kingma and Jimmy Ba. Adam: a method for stochastic optimization. In Yoshua Bengio and Yann LeCun, editors, ICLR. 2015. [SHK+14] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. Journal of Machine Learning Research, 15(56):1929–1958, 2014. URL: http://jmlr.org/papers/v15/srivastava14a.html. [FFW+19] Hassan Ismail Fawaz, Germain Forestier, Jonathan Weber, Lhassane Idoumghar, and Pierre-Alain Muller. Deep learning for time series classification: a review. Data Mining and Knowledge Discovery, 33(4):917– 963, 2019. [FLF+20] Hassan Ismail Fawaz, Benjamin Lucas, Germain Forestier, Charlotte Pelletier, Daniel F Schmidt, Jonathan Weber, Geoffrey I Webb, Lhassane Idoumghar, Pierre-Alain Muller, and François Petitjean. Inception- time: finding alexnet for time series classification. Data Mining and Knowledge Discovery, 34(6):1936–1962, 2020. [LGMT16] Arthur Le Guennec, Simon Malinowski, and Romain Tavenard. Data Augmentation for Time Series Clas- sification using Convolutional Neural Networks. In ECML/PKDD Workshop on Advanced Analytics and Learning on Temporal Data. Riva Del Garda, Italy, September 2016. [LBBH98] Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to docu- ment recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998. [CVMerrienboerBB14] Kyunghyun Cho, Bart Van Merriënboer, Dzmitry Bahdanau, and Yoshua Bengio. On the prop- erties of neural machine translation: encoder-decoder approaches. 2014. arXiv:1409.1259. [HS97] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997. [Mad19] Andreas Madsen. Visualizing memorization in rnns. Distill, 2019. URL: https://distill.pub/2019/ memorization-in-rnns. 45](https://image.slidesharecdn.com/deeplearningbasicslecturenotes-250708052047-fb12d57c/75/Deep-Learning-Basics-lecture-notes-pdf-49-2048.jpg)