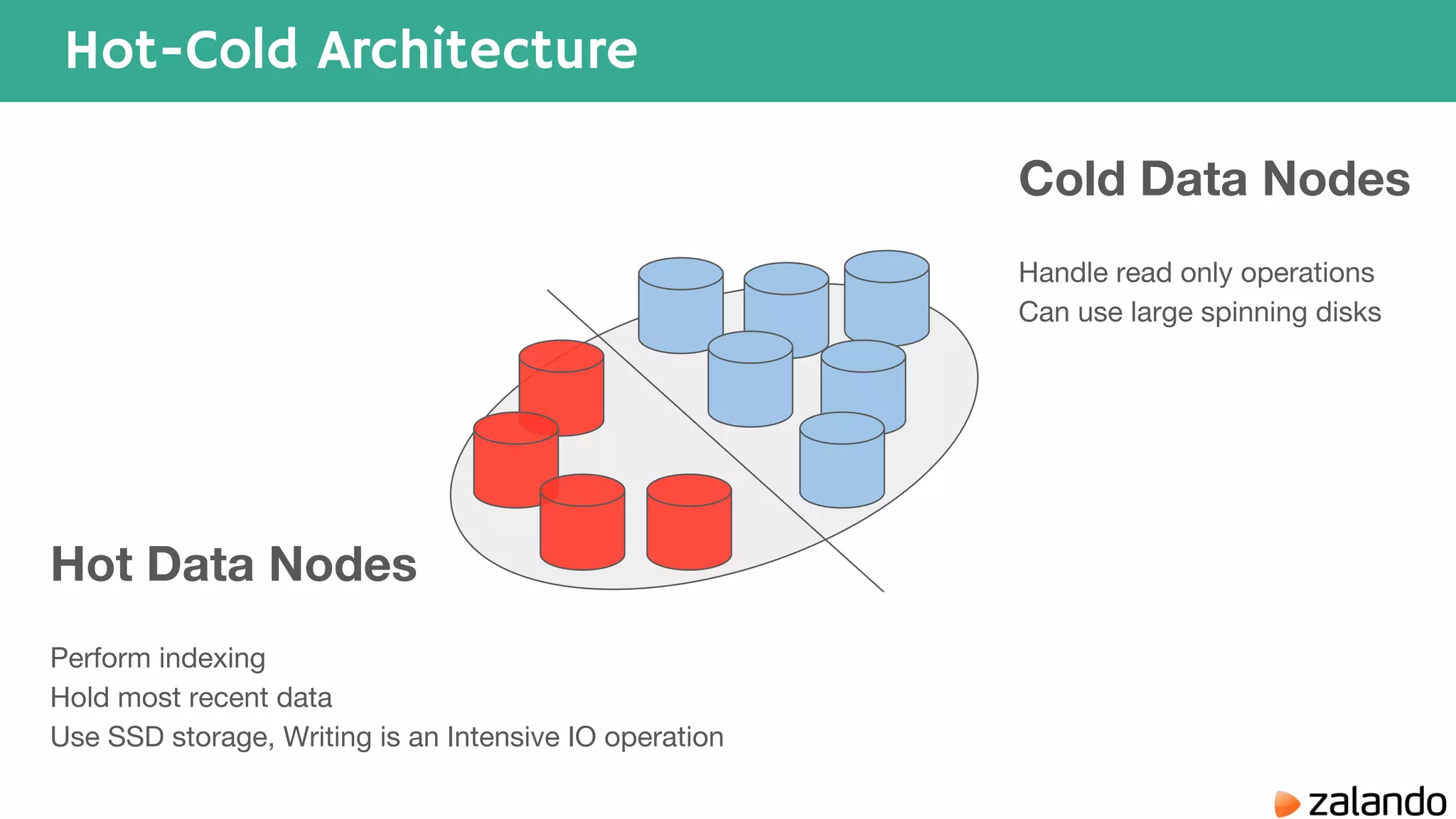
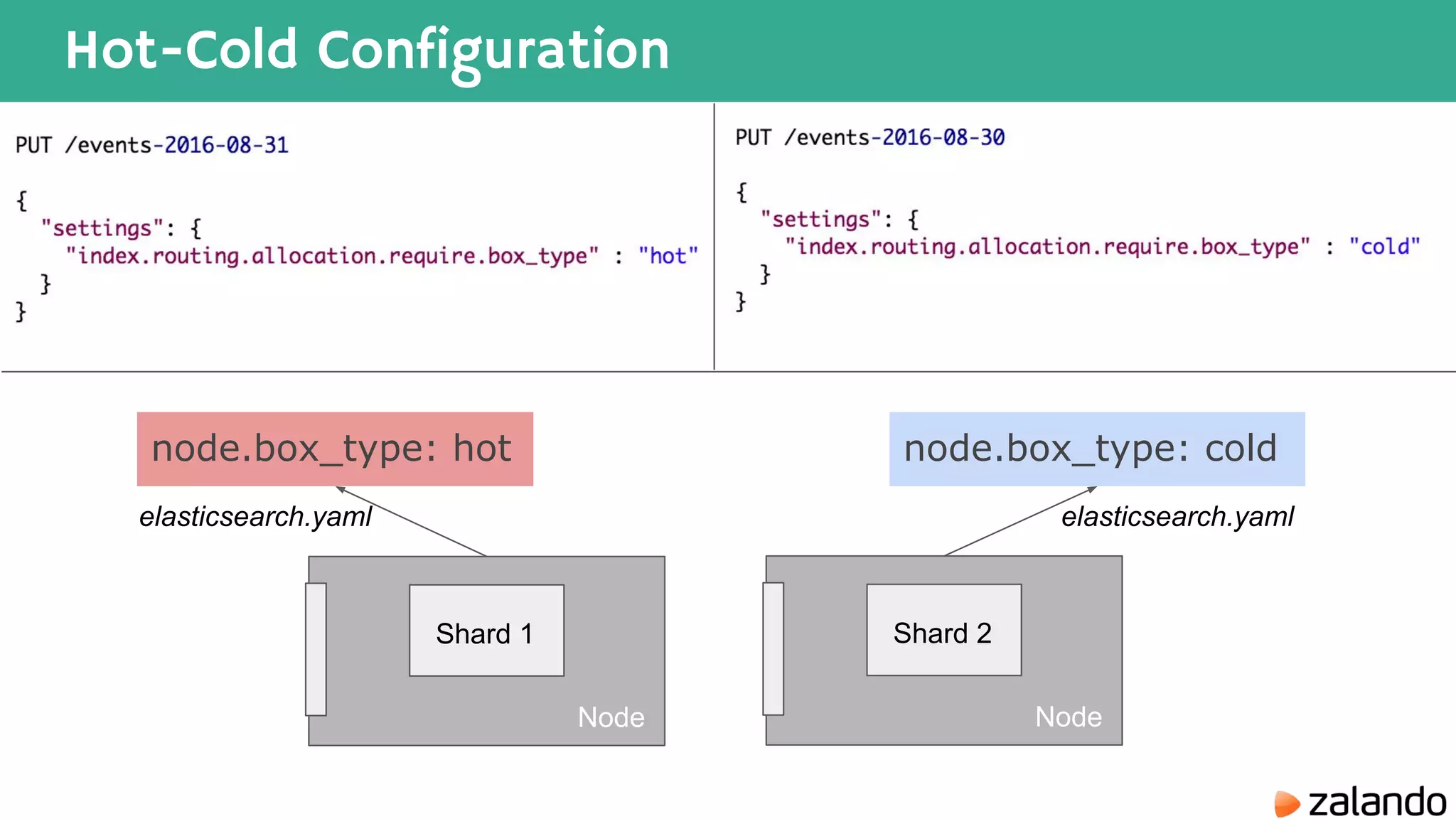
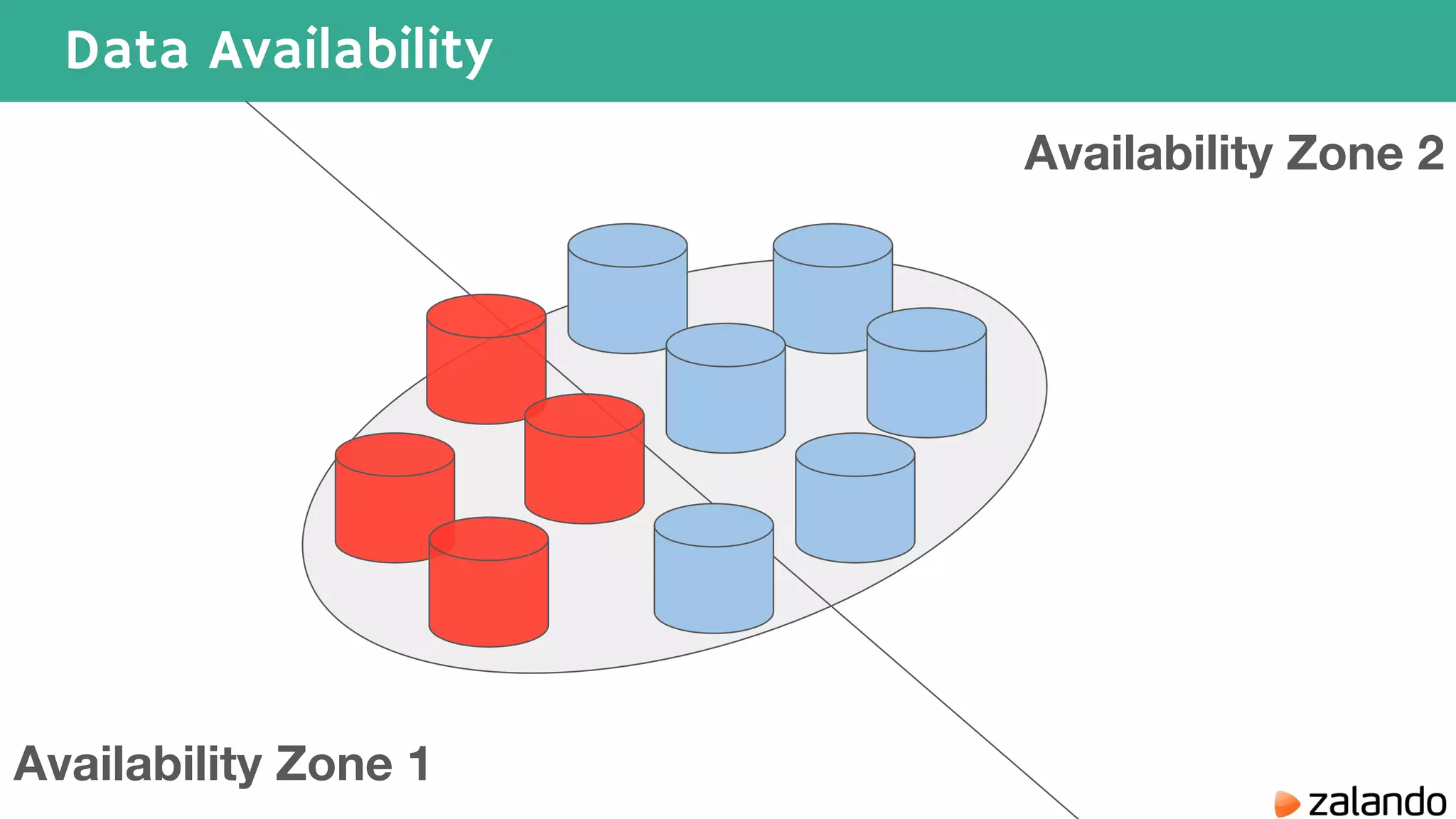
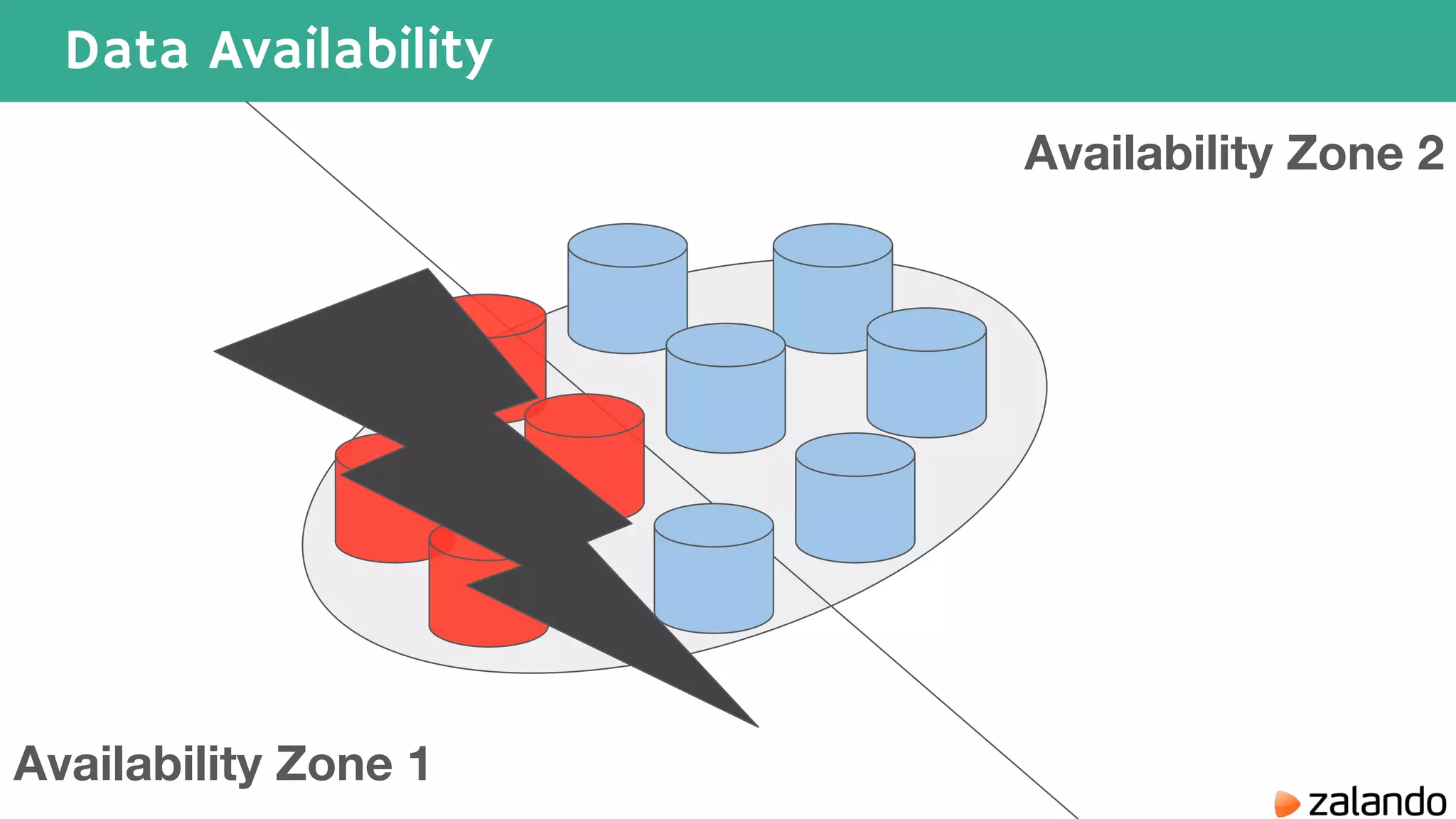
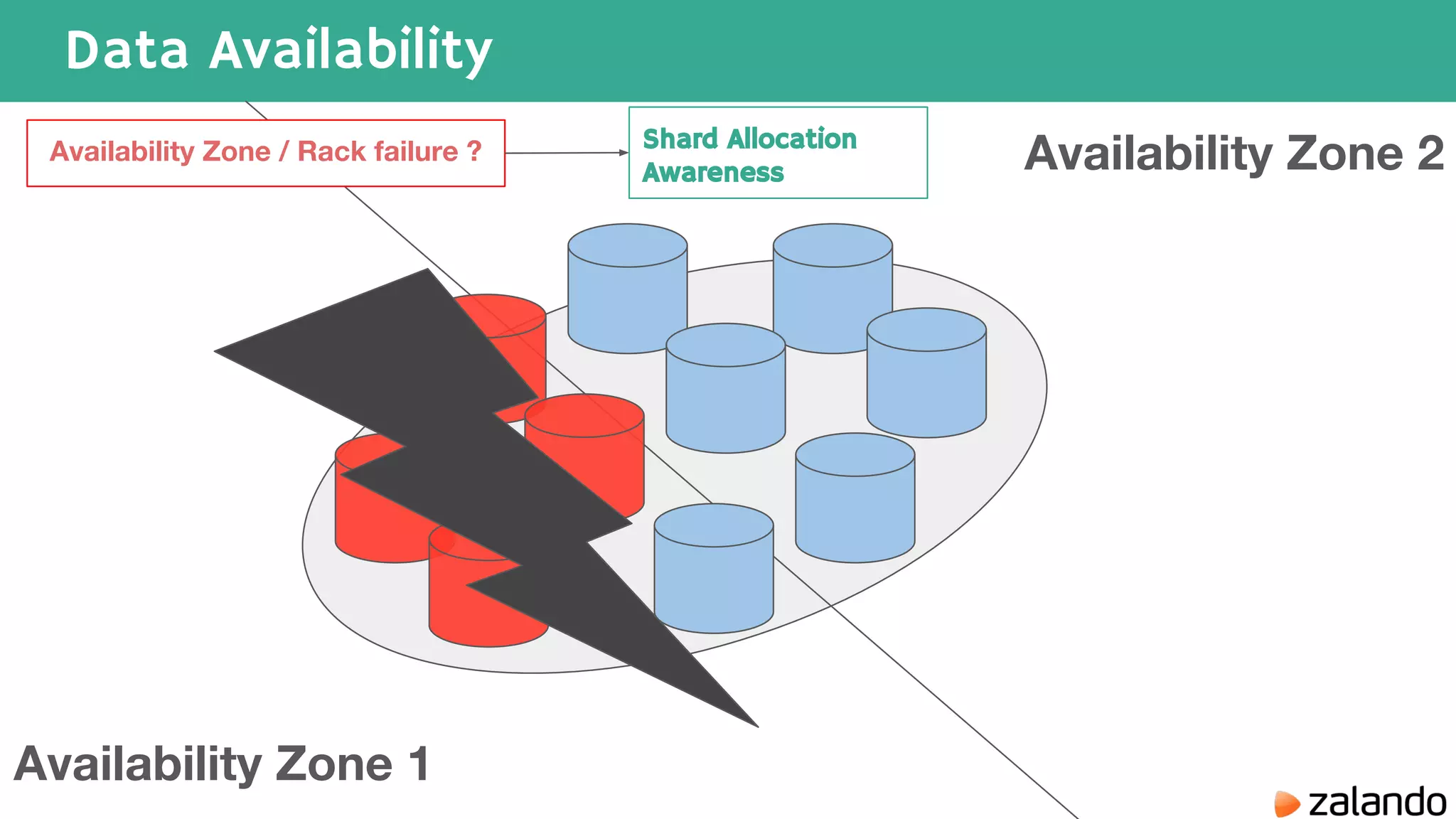
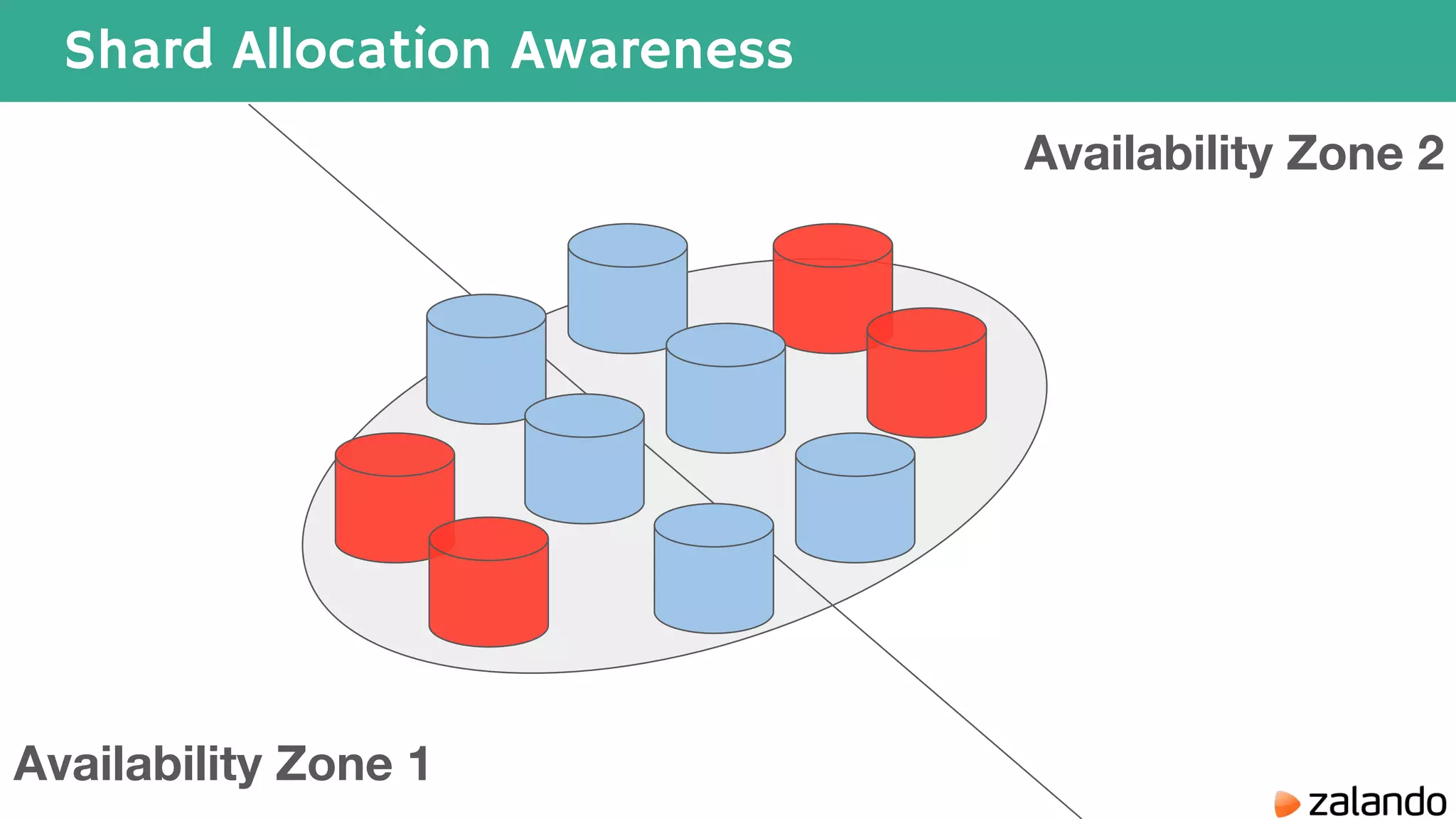
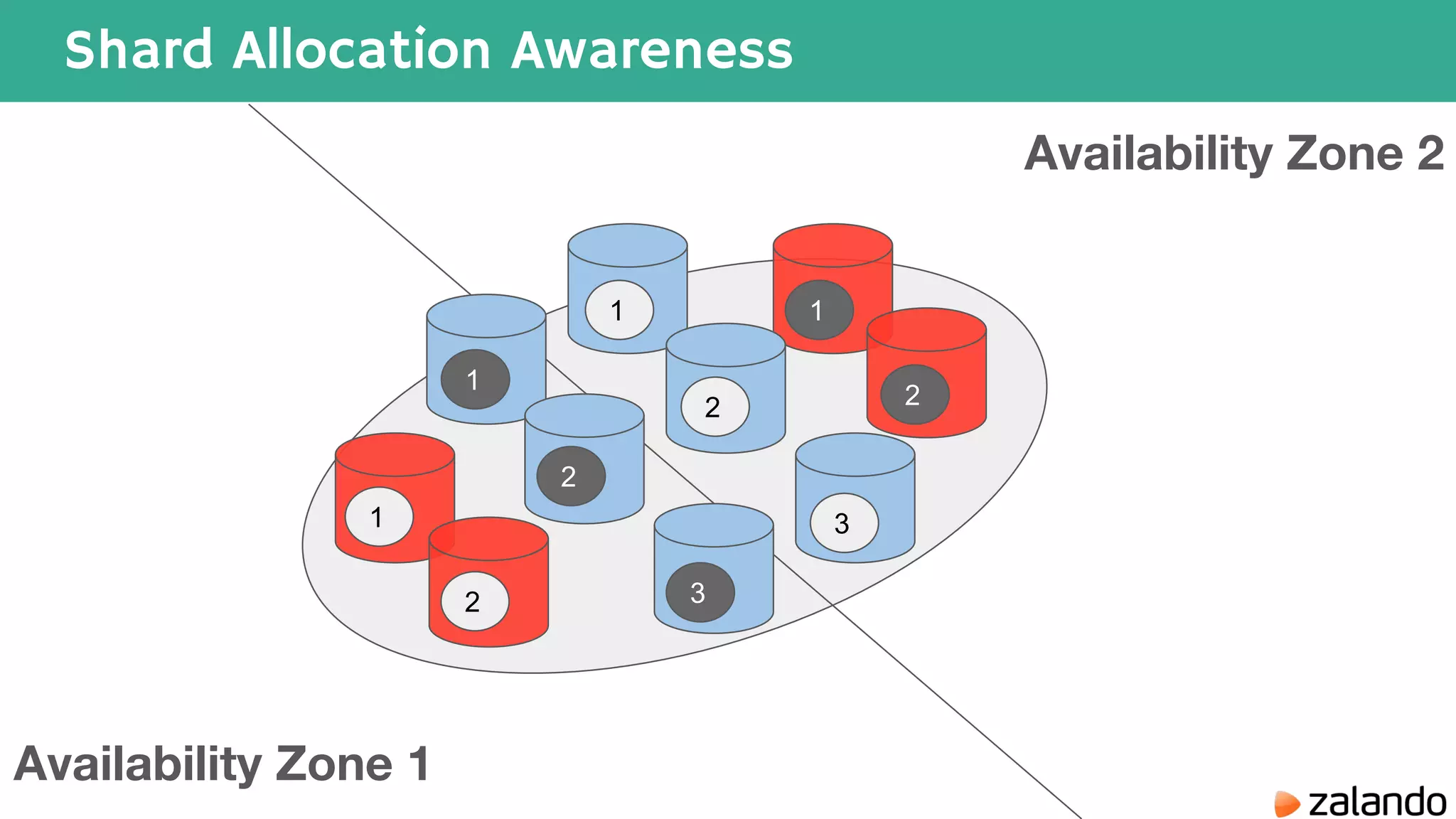
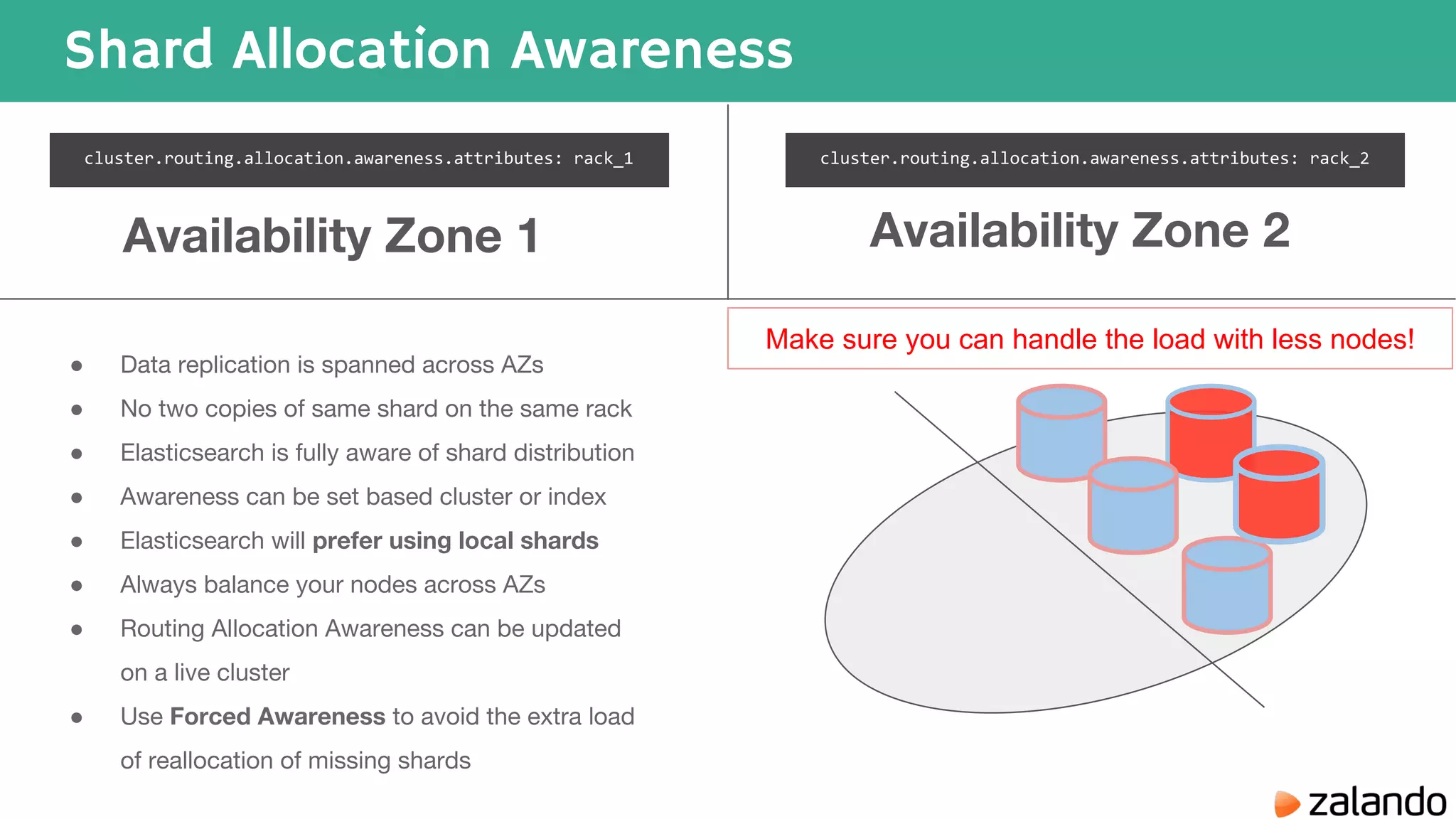
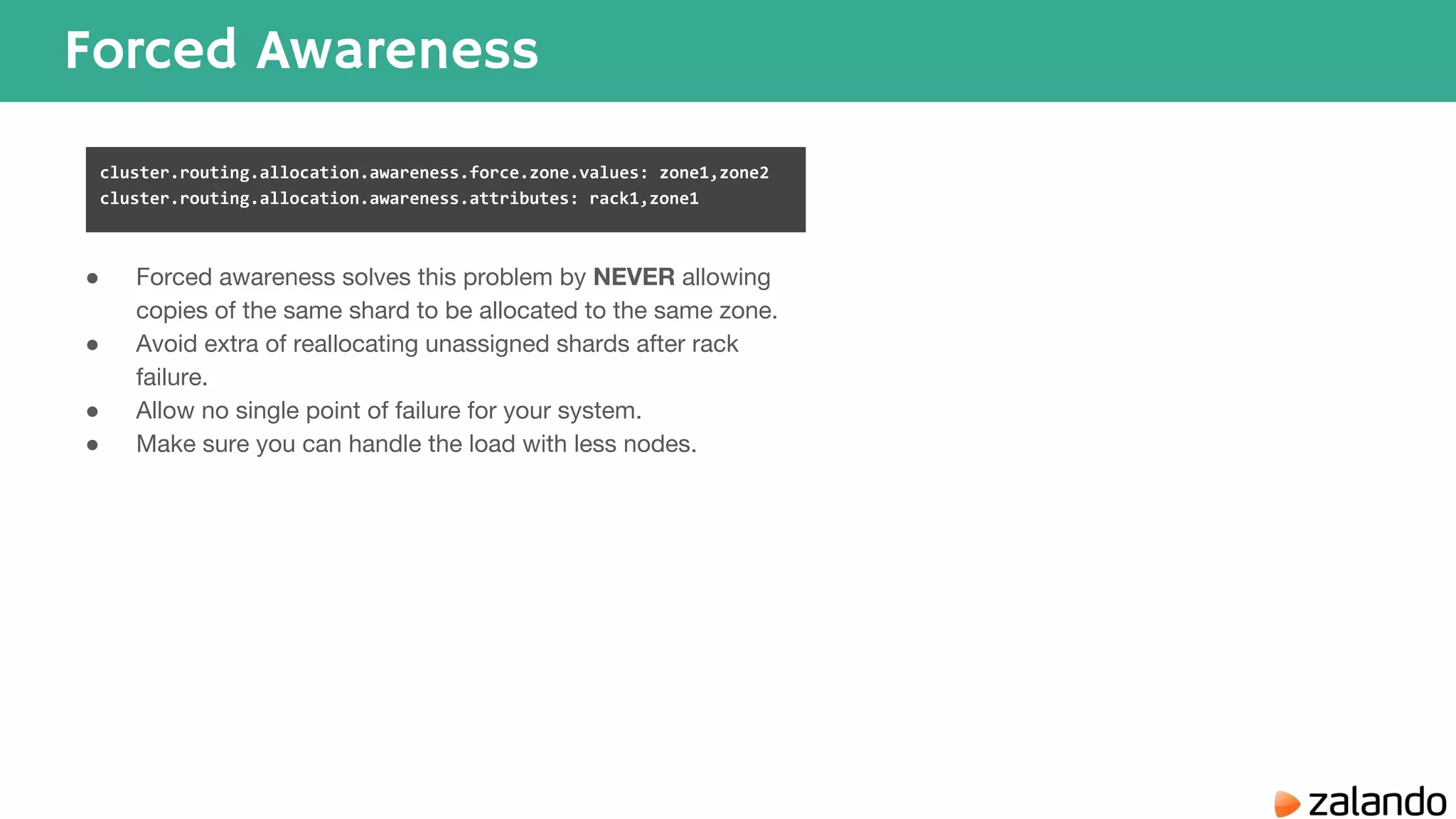
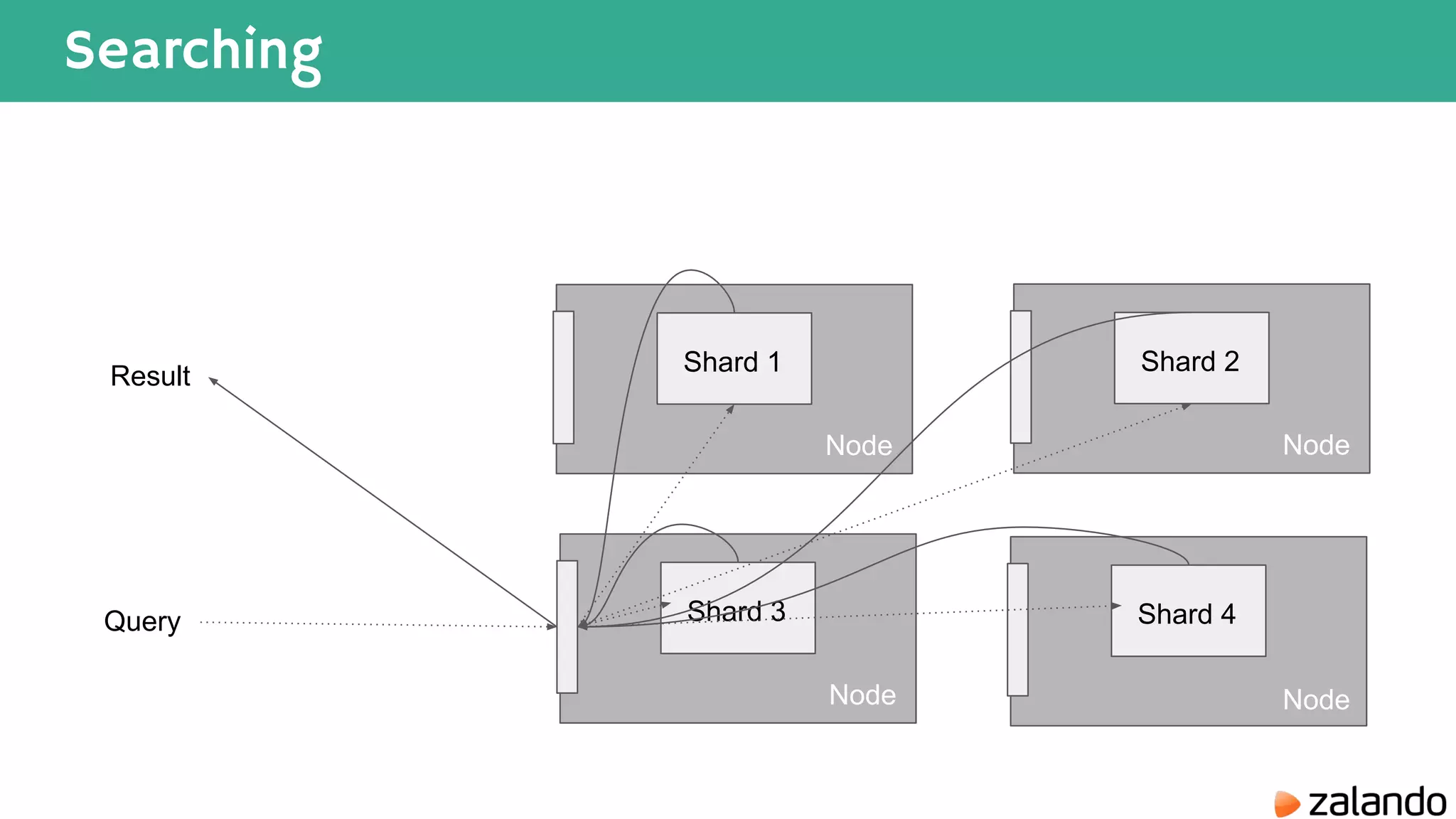
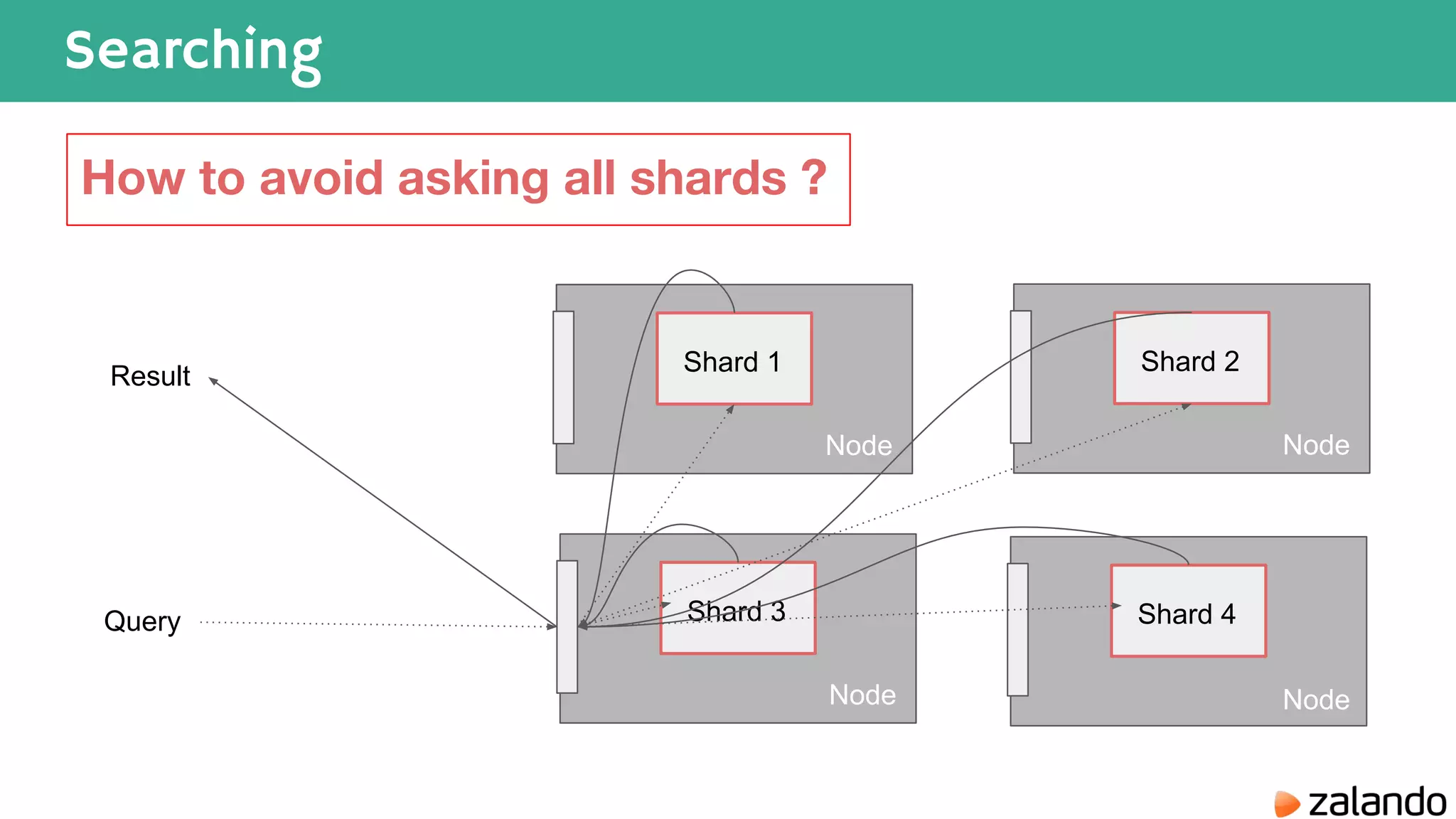
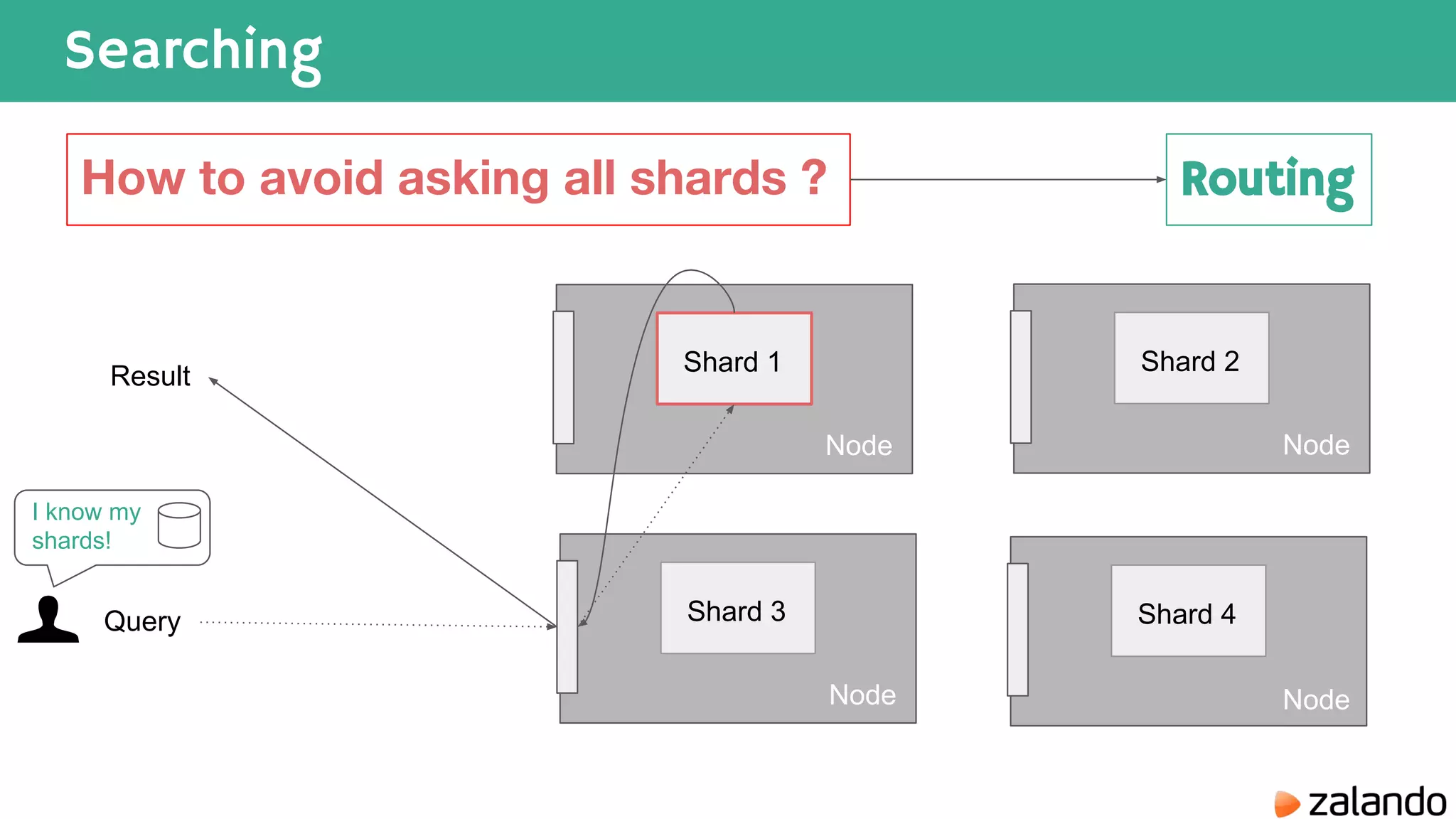
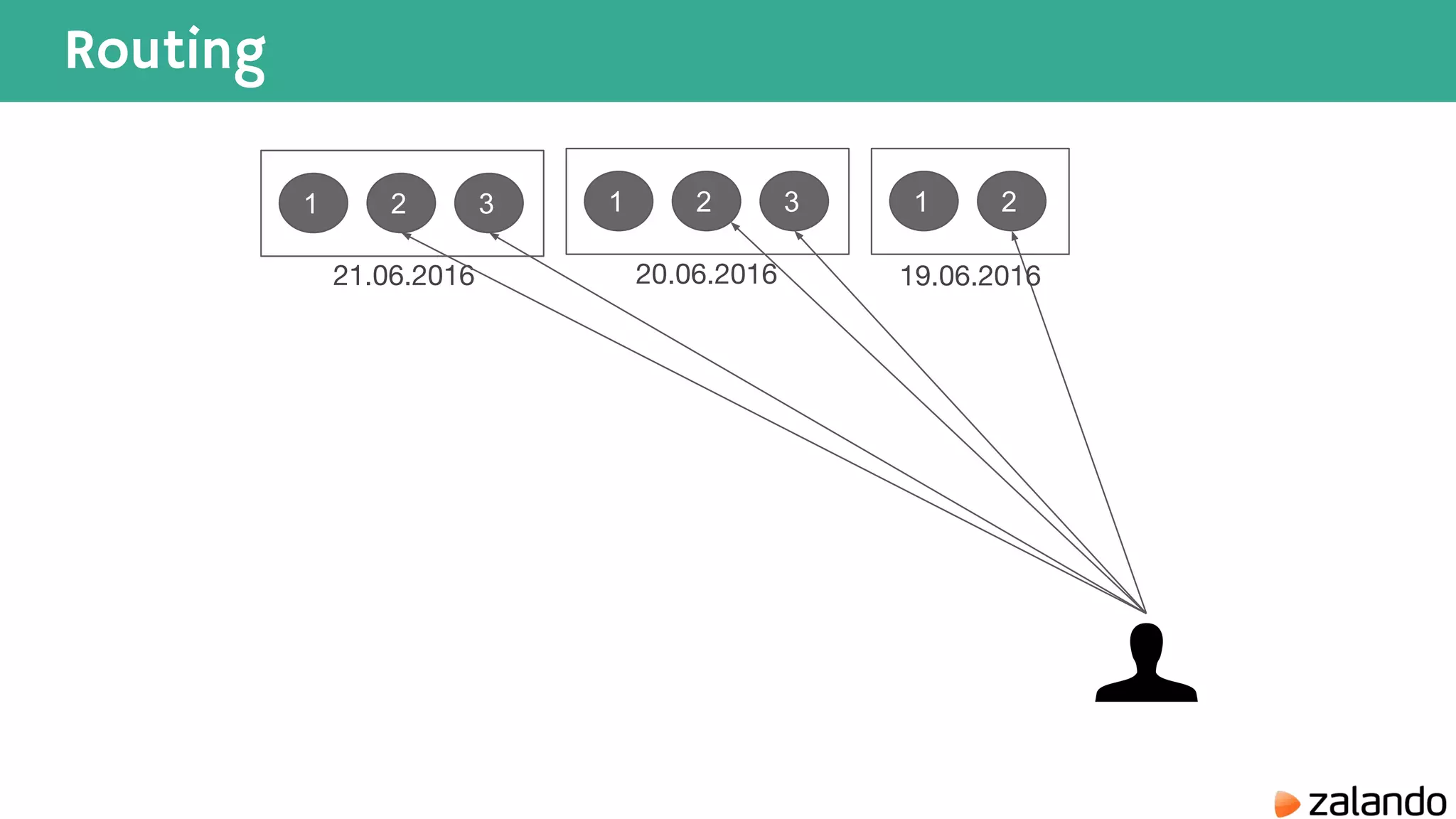
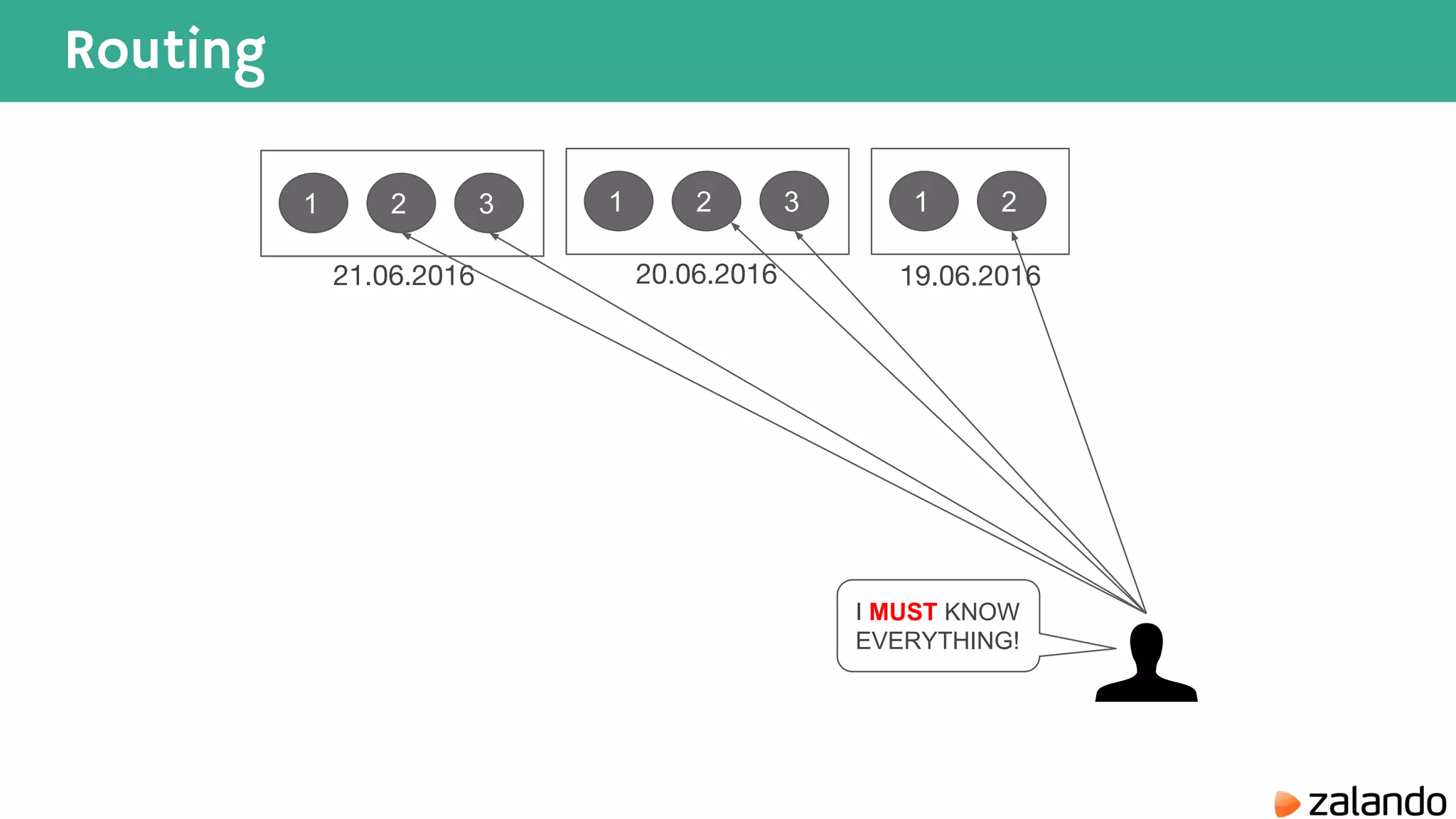
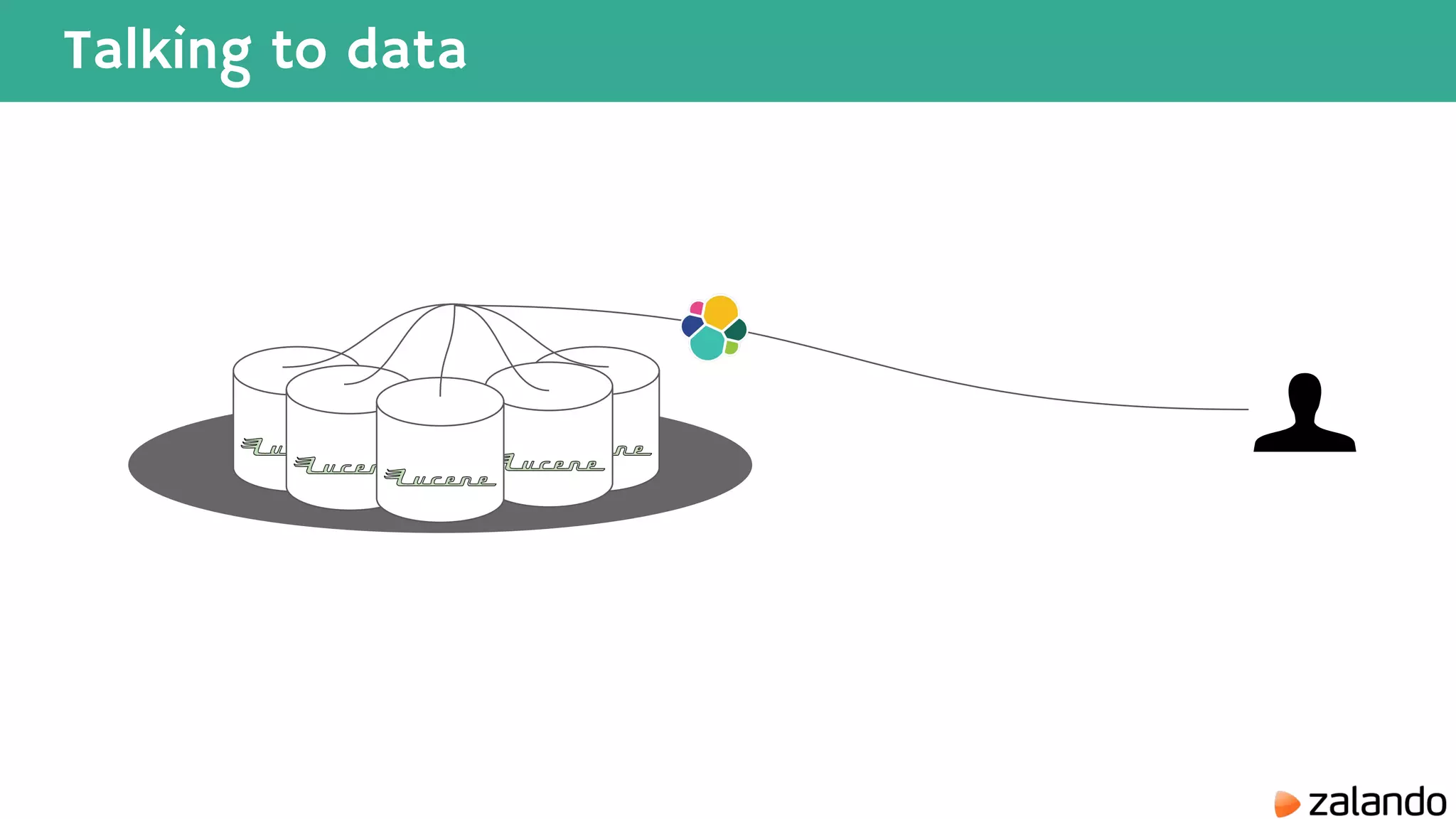
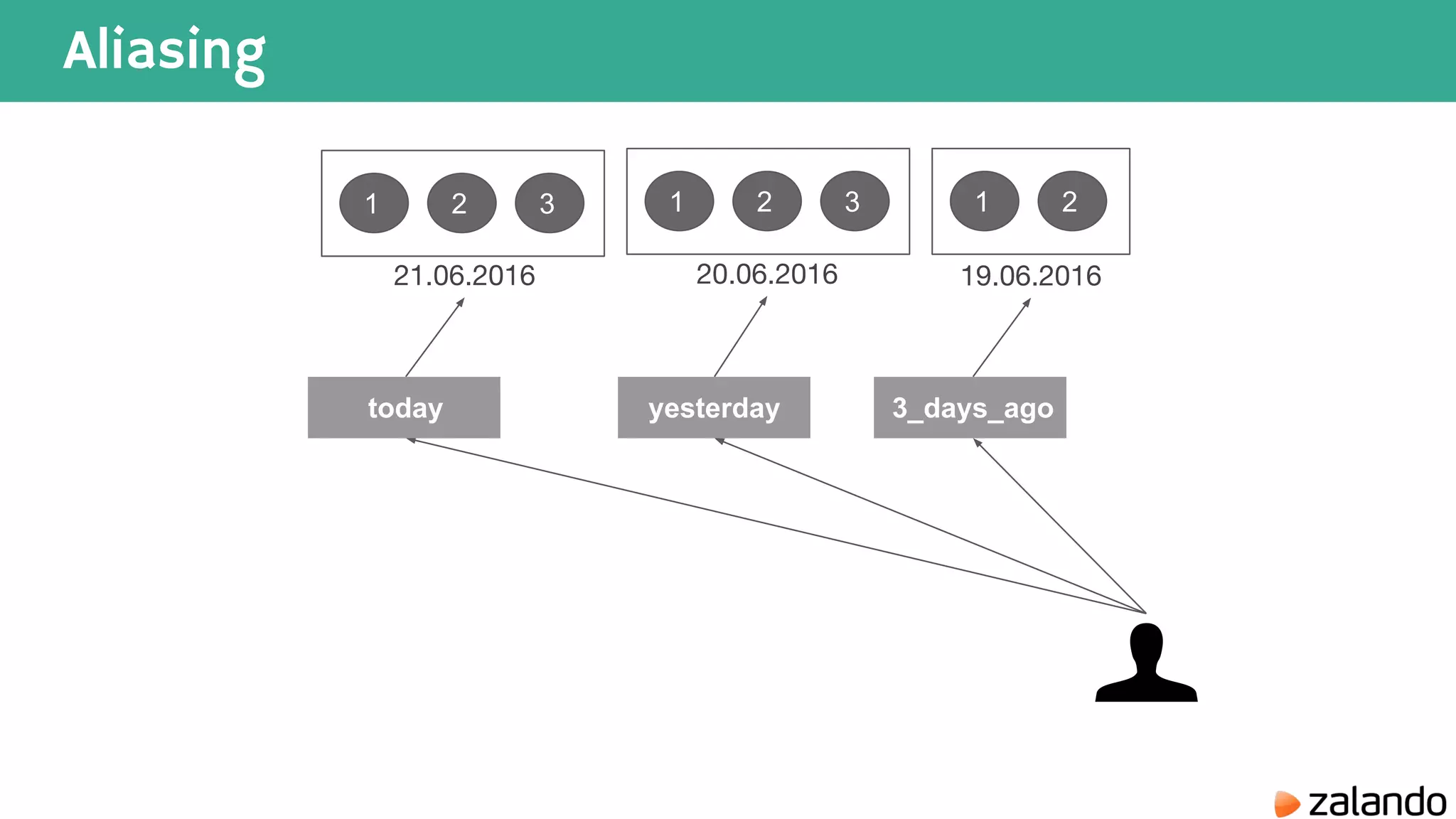
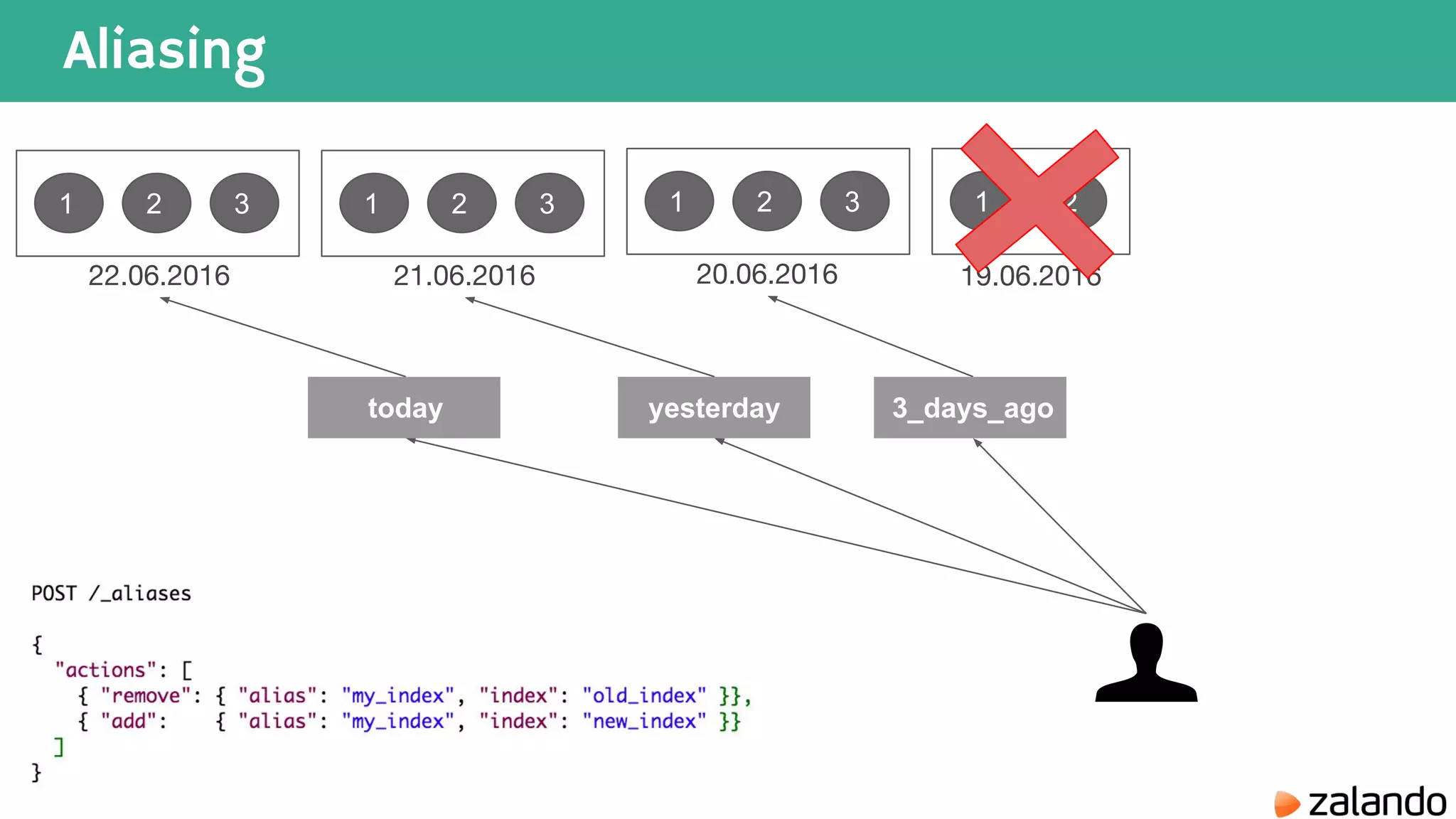
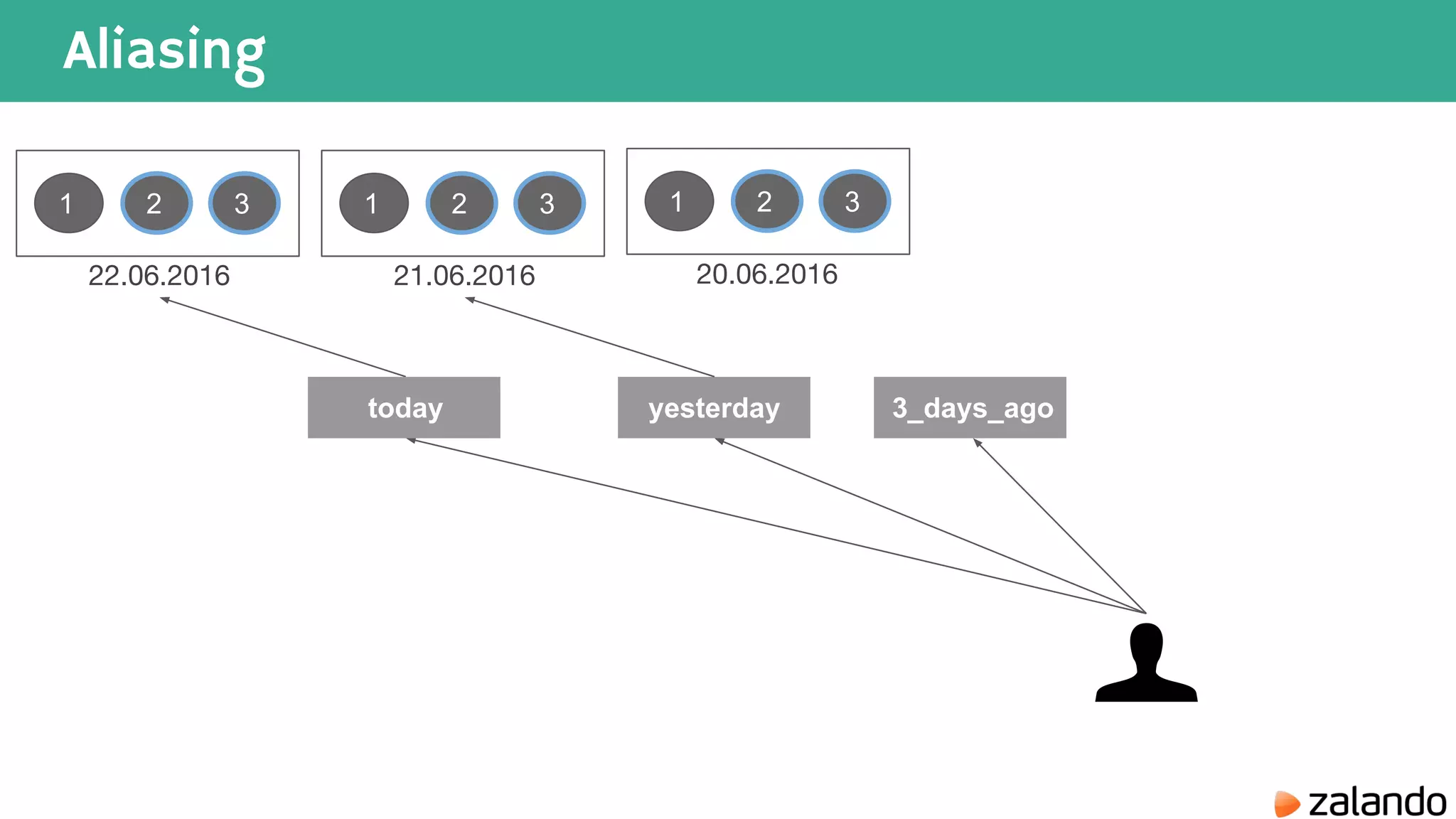
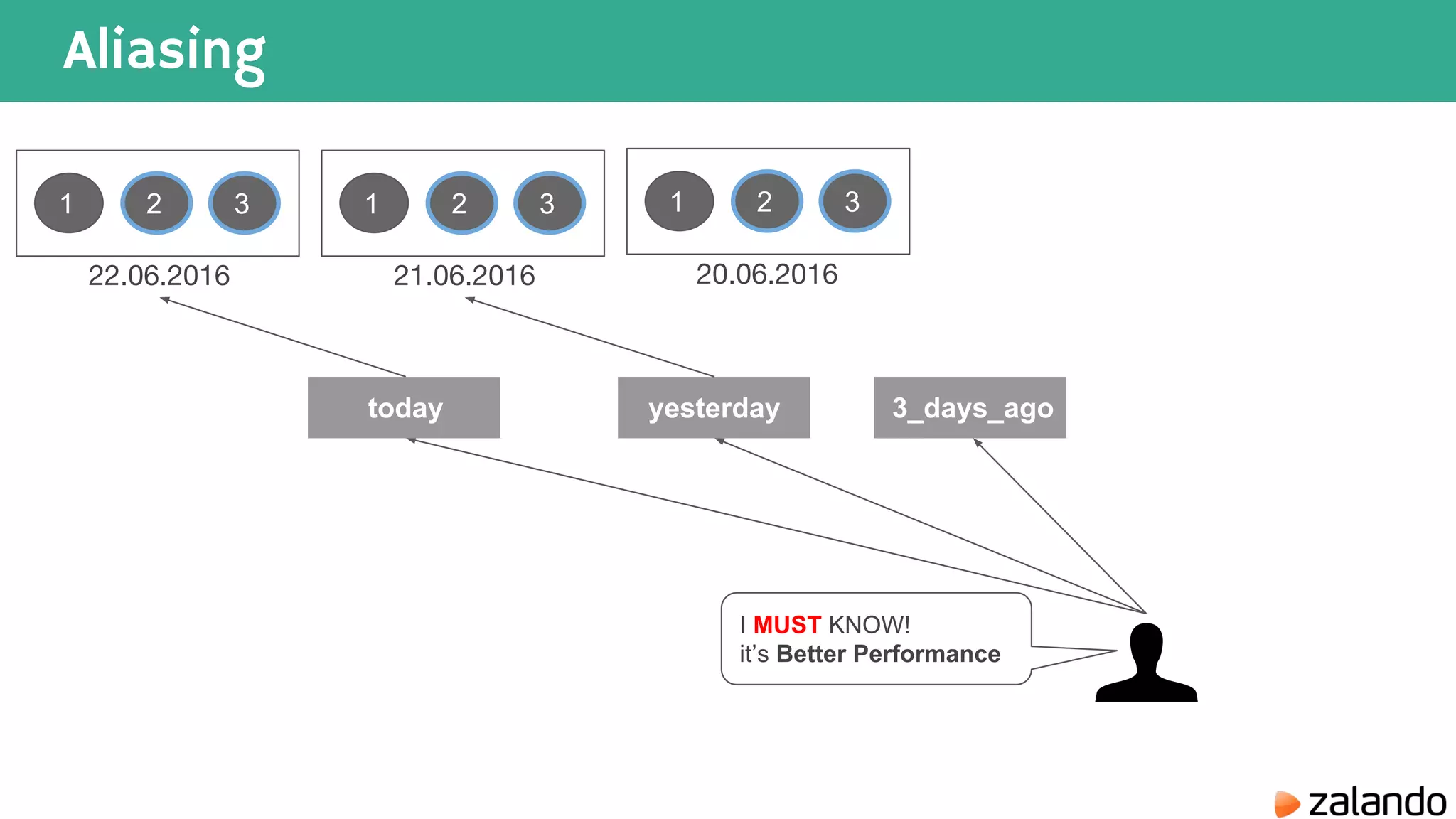
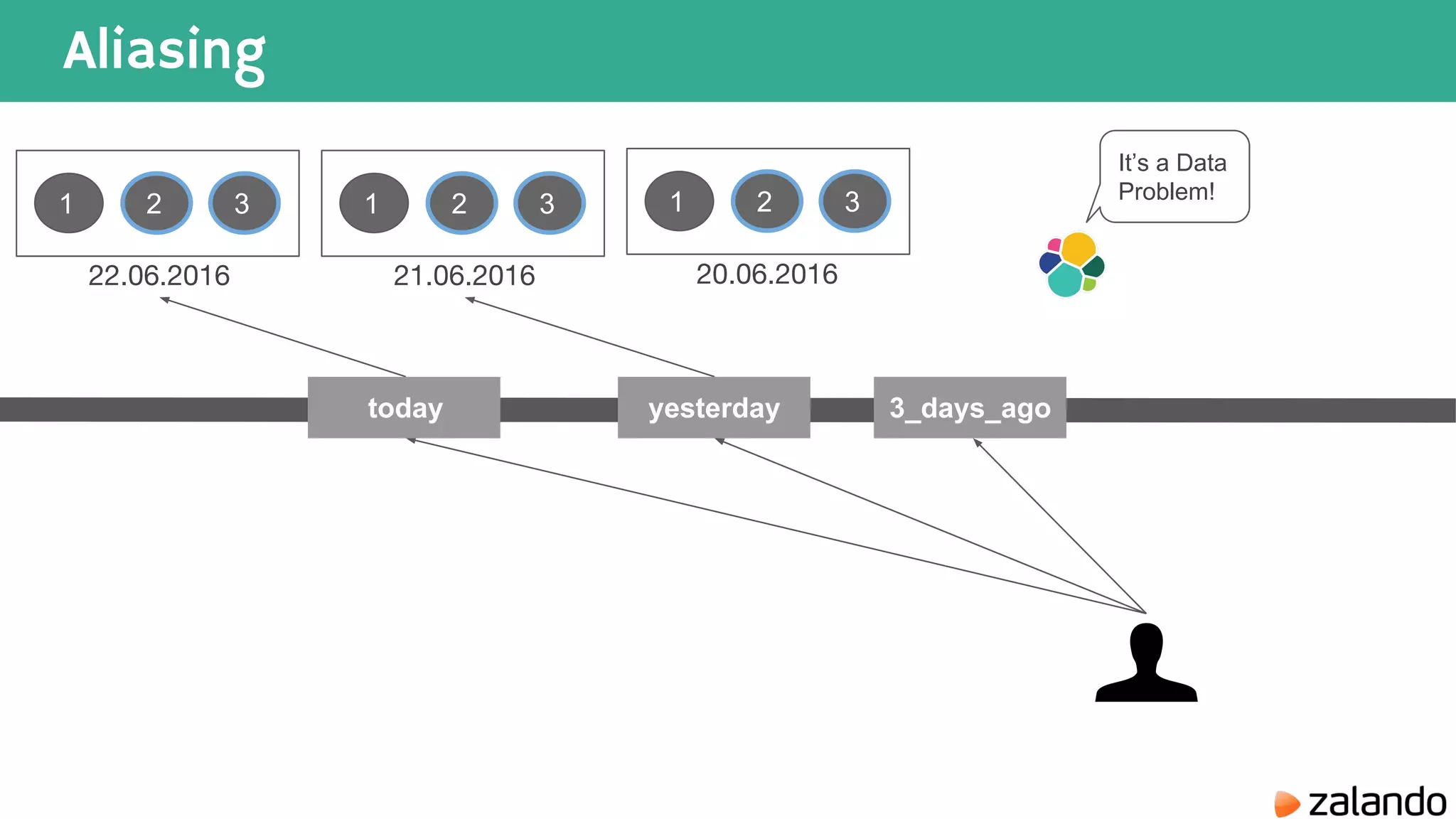
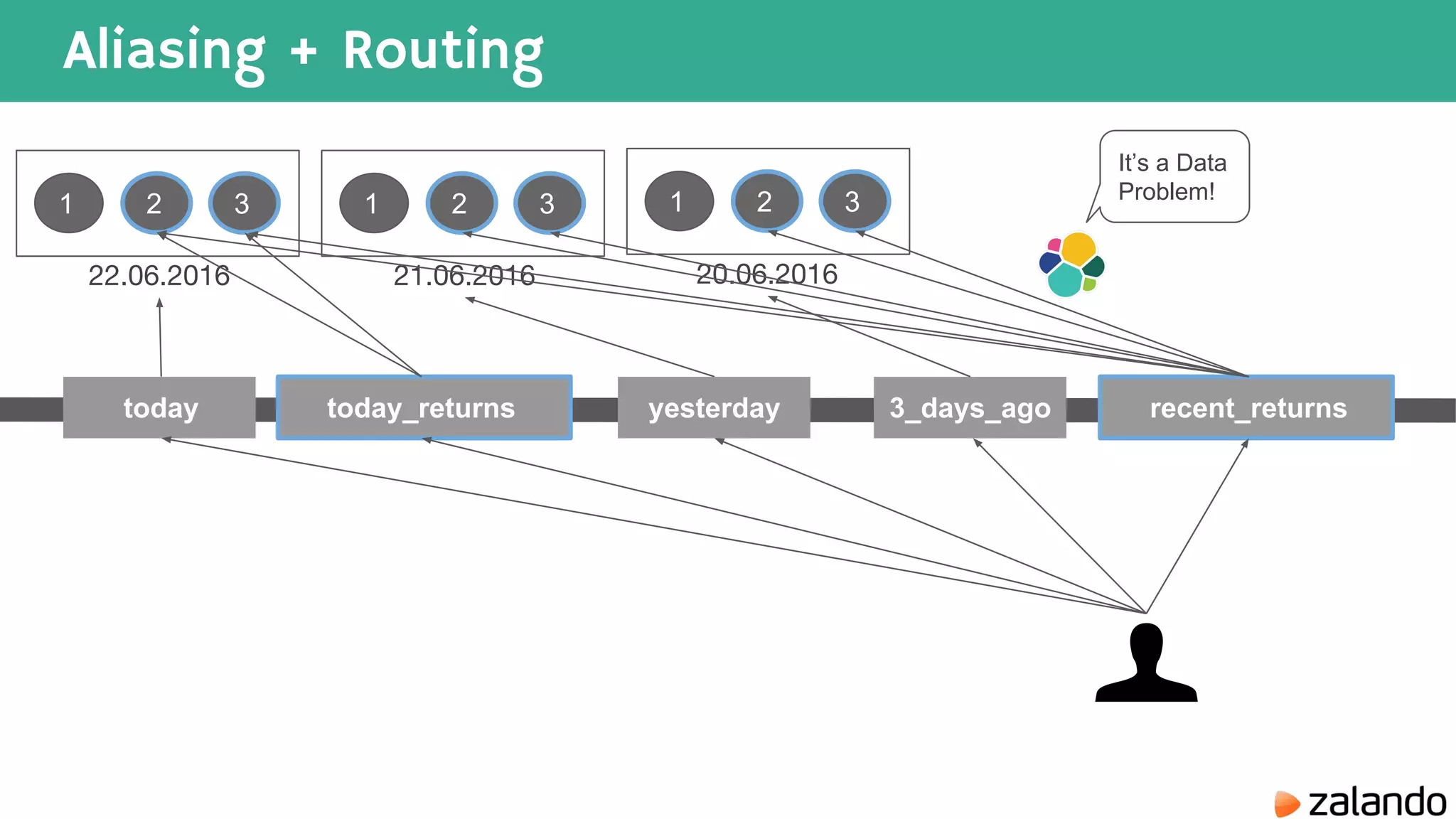
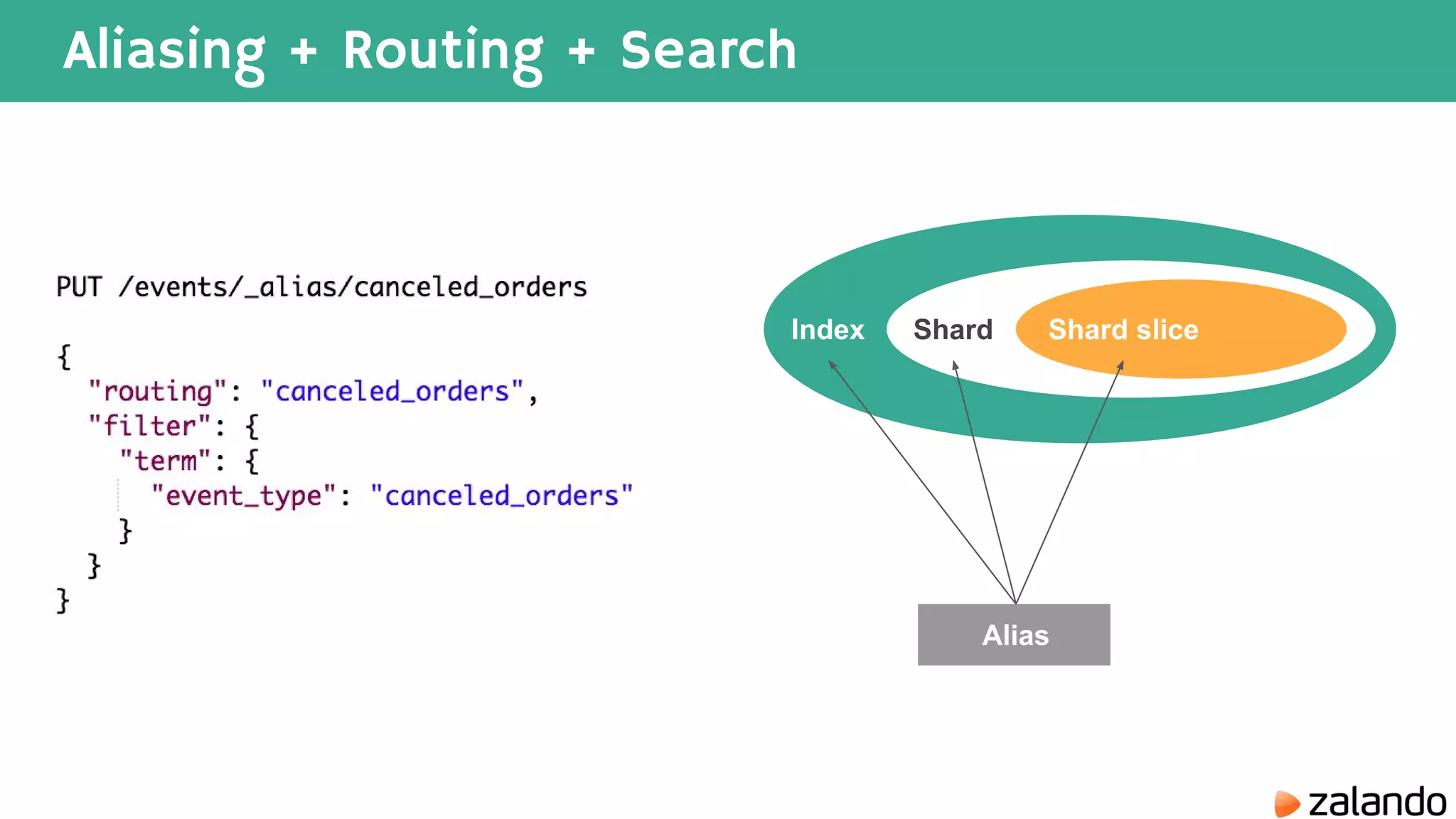
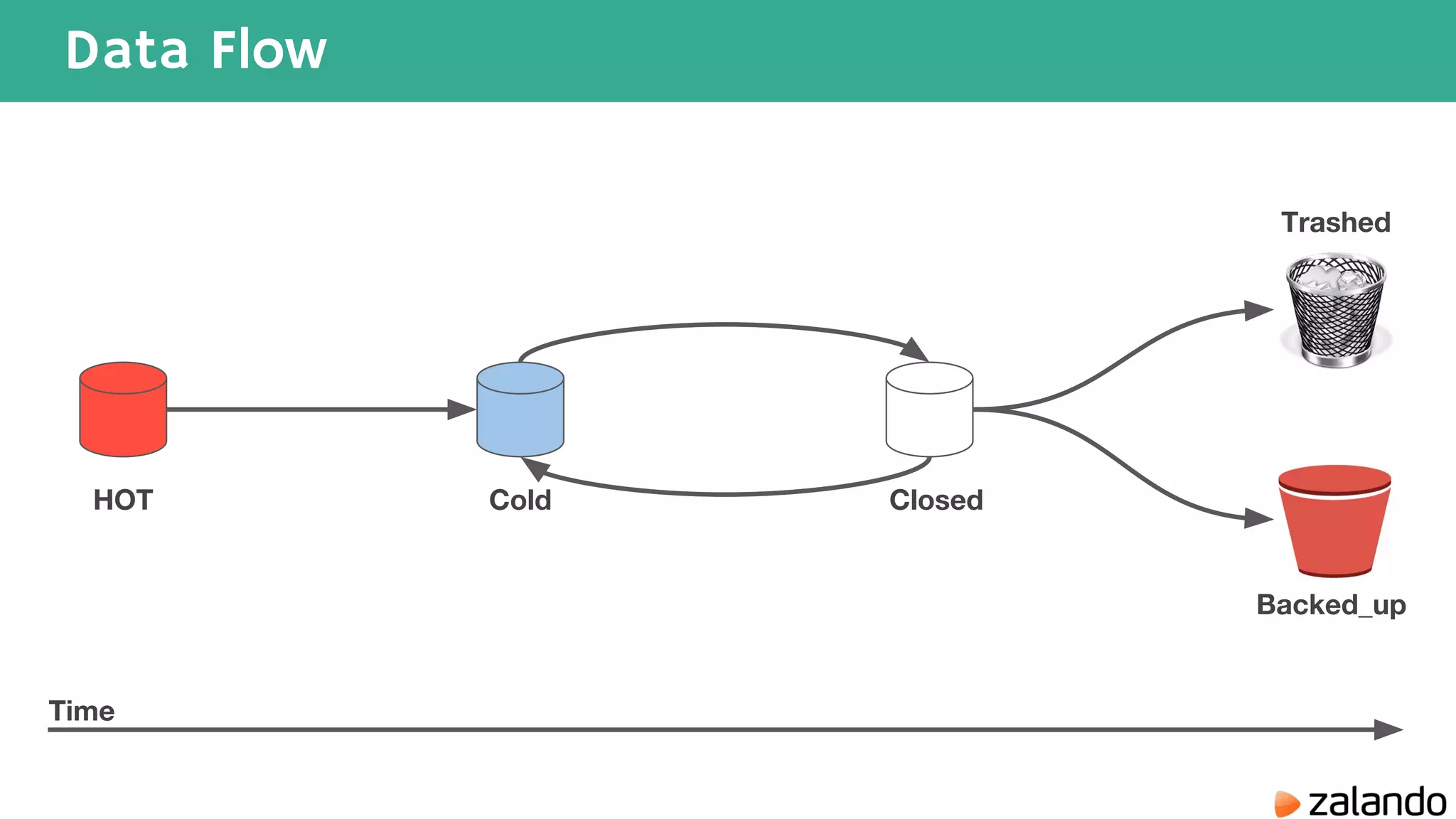
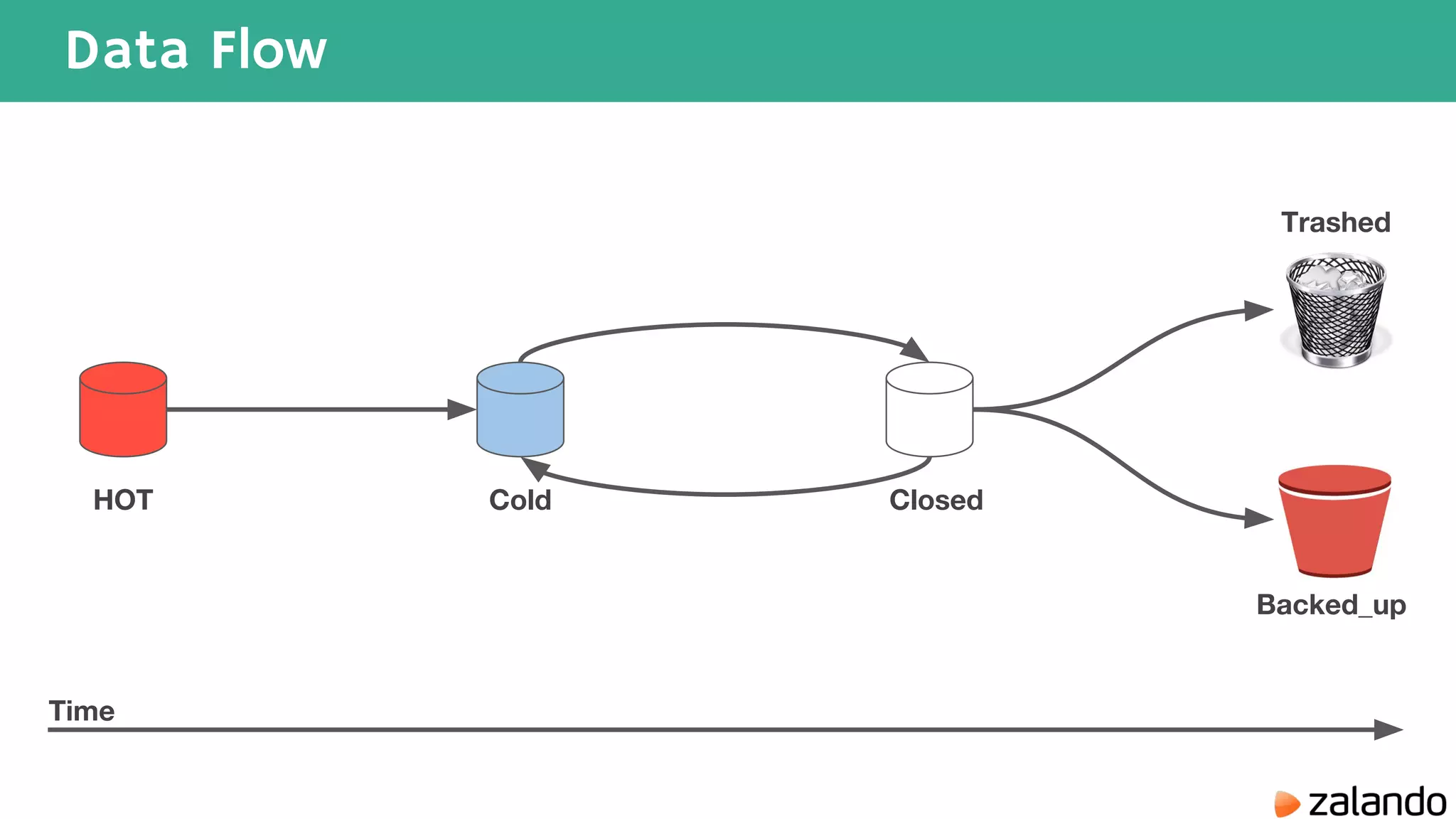
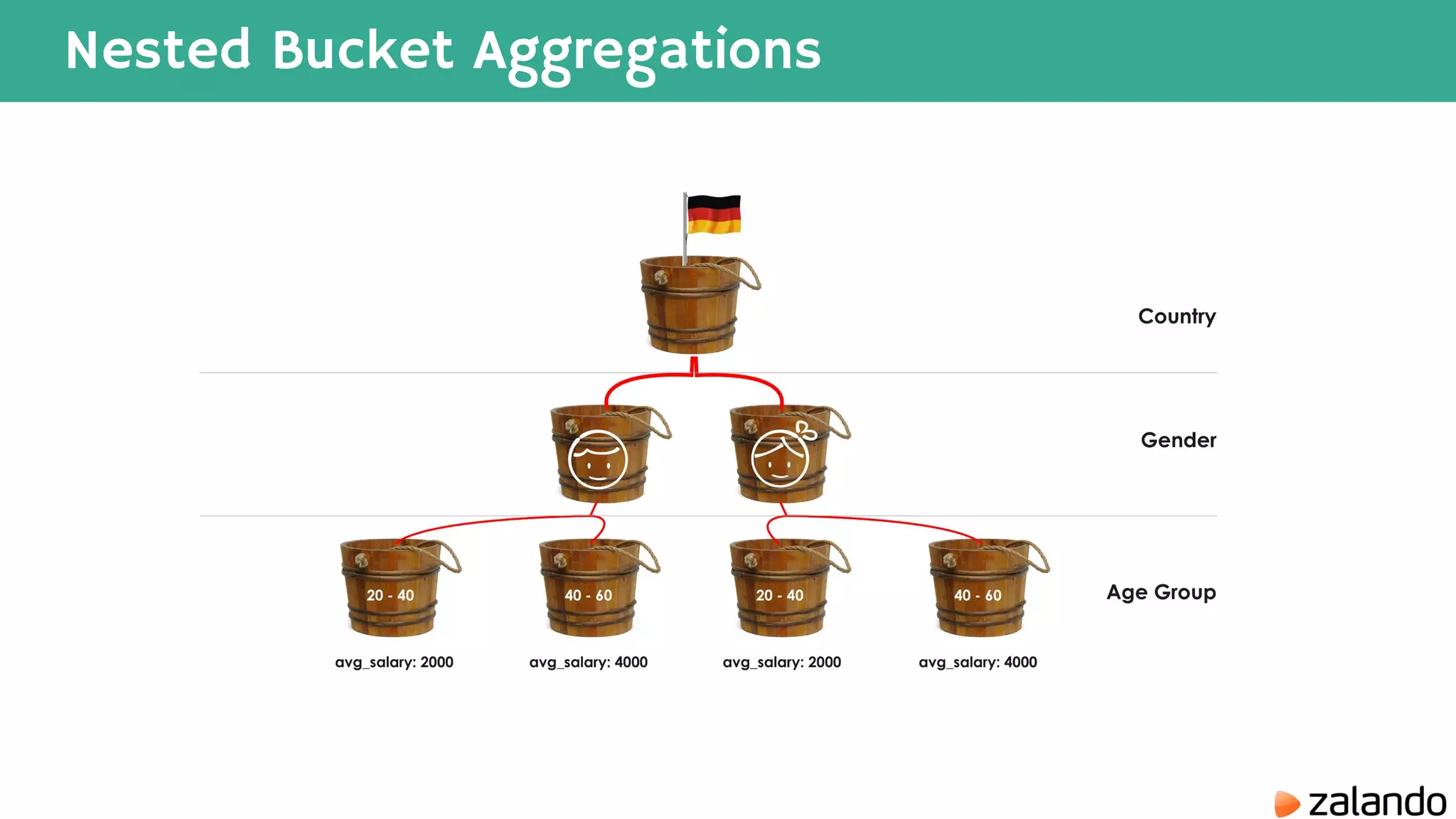
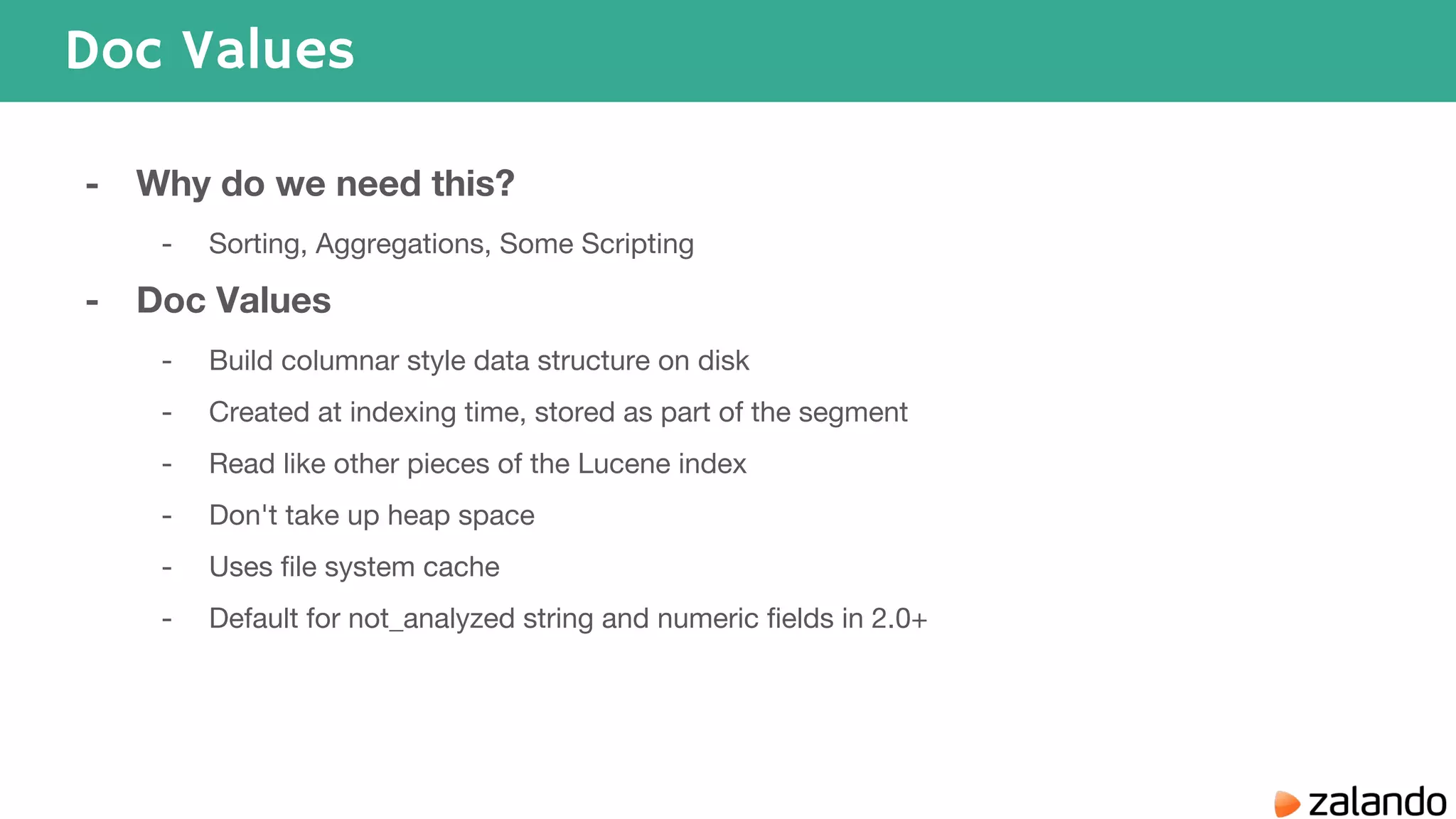
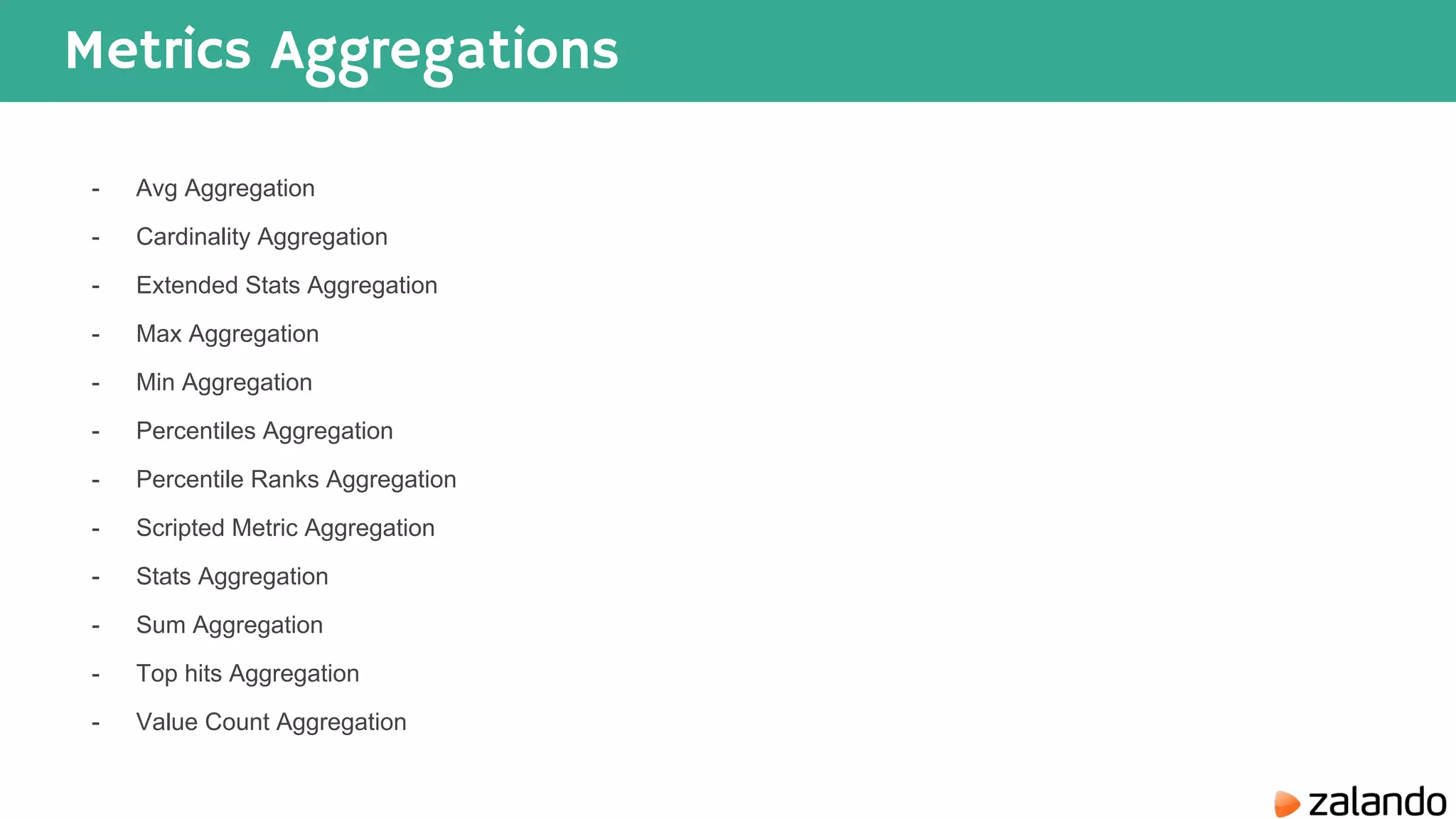
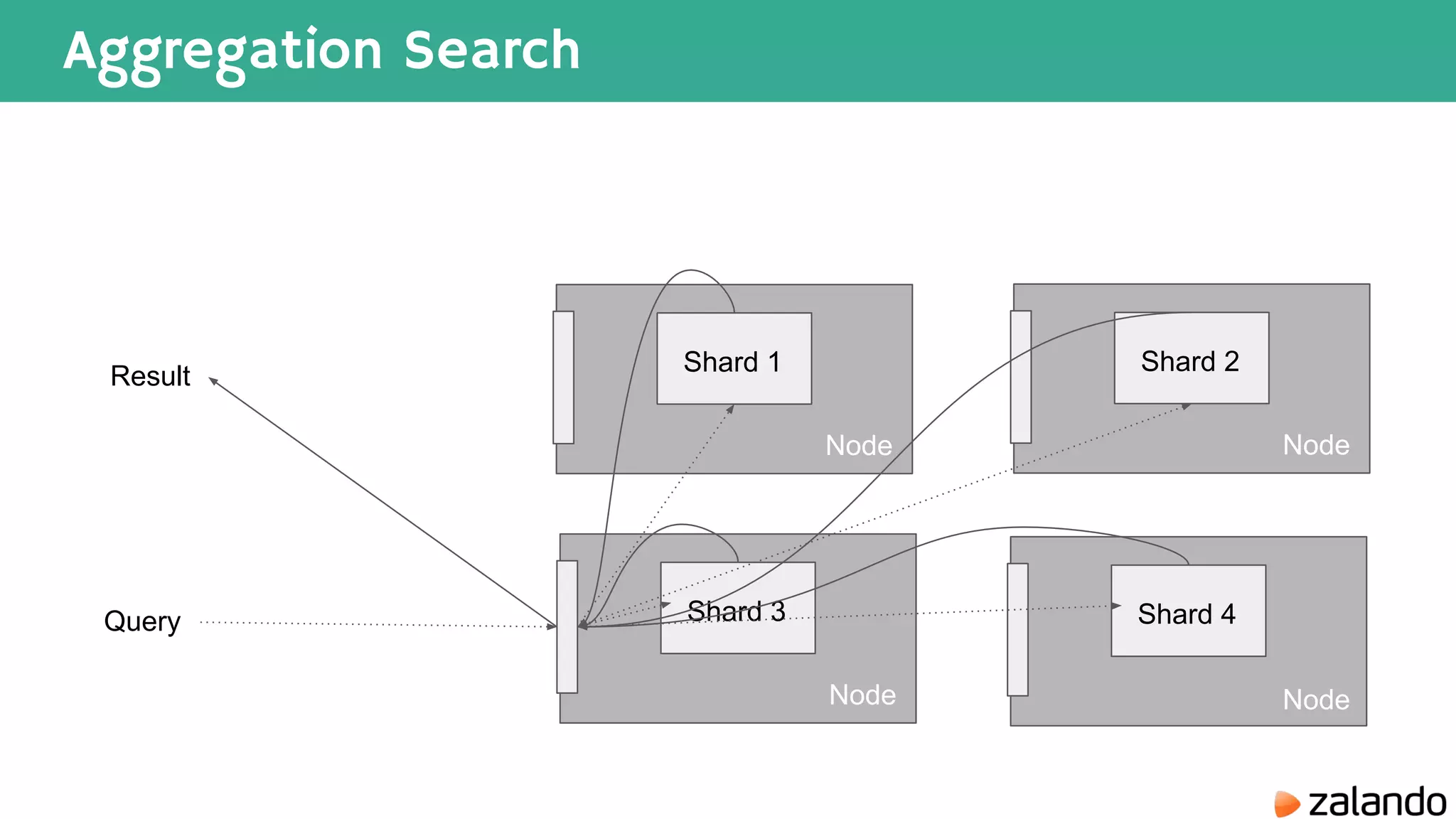
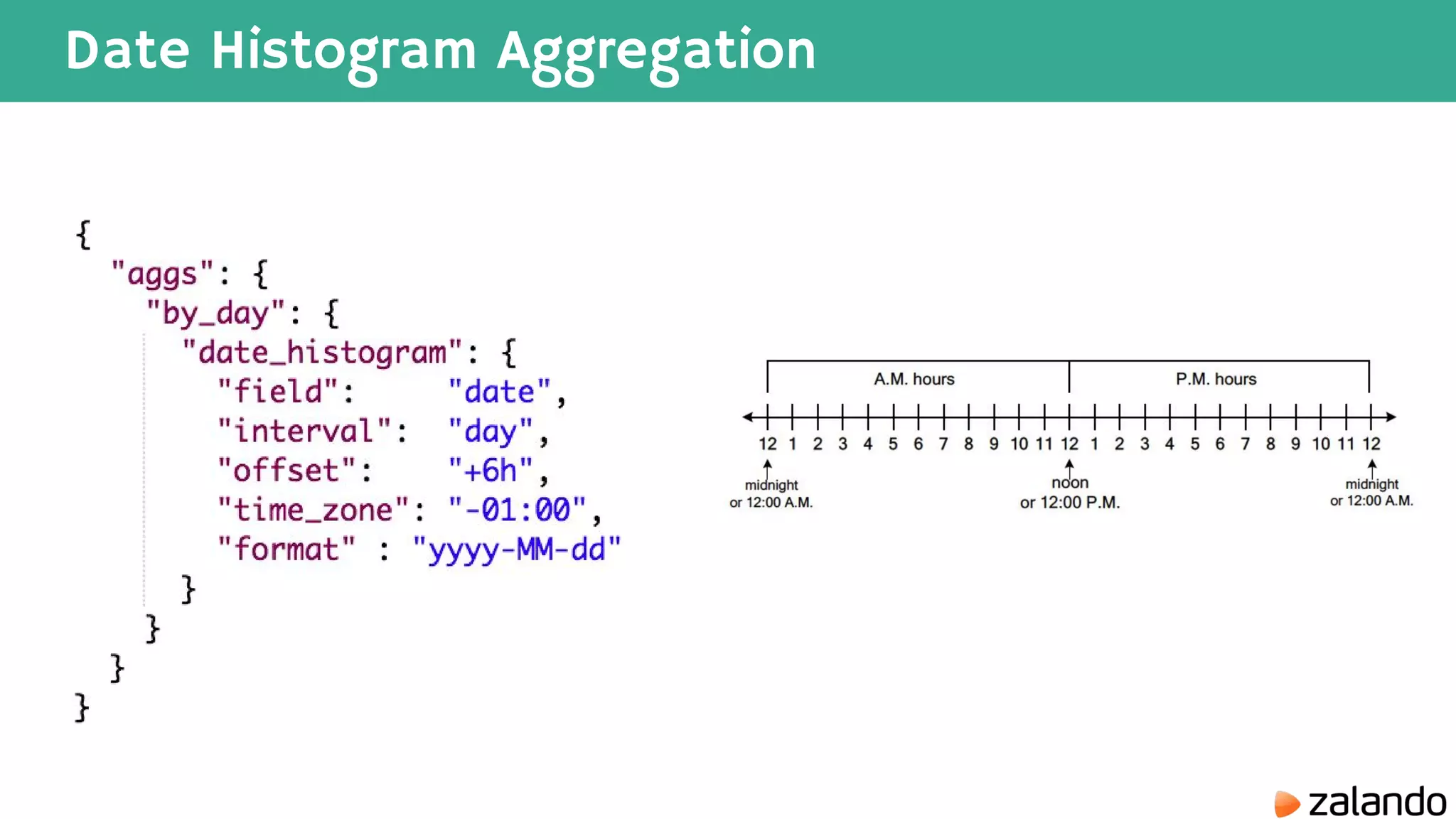
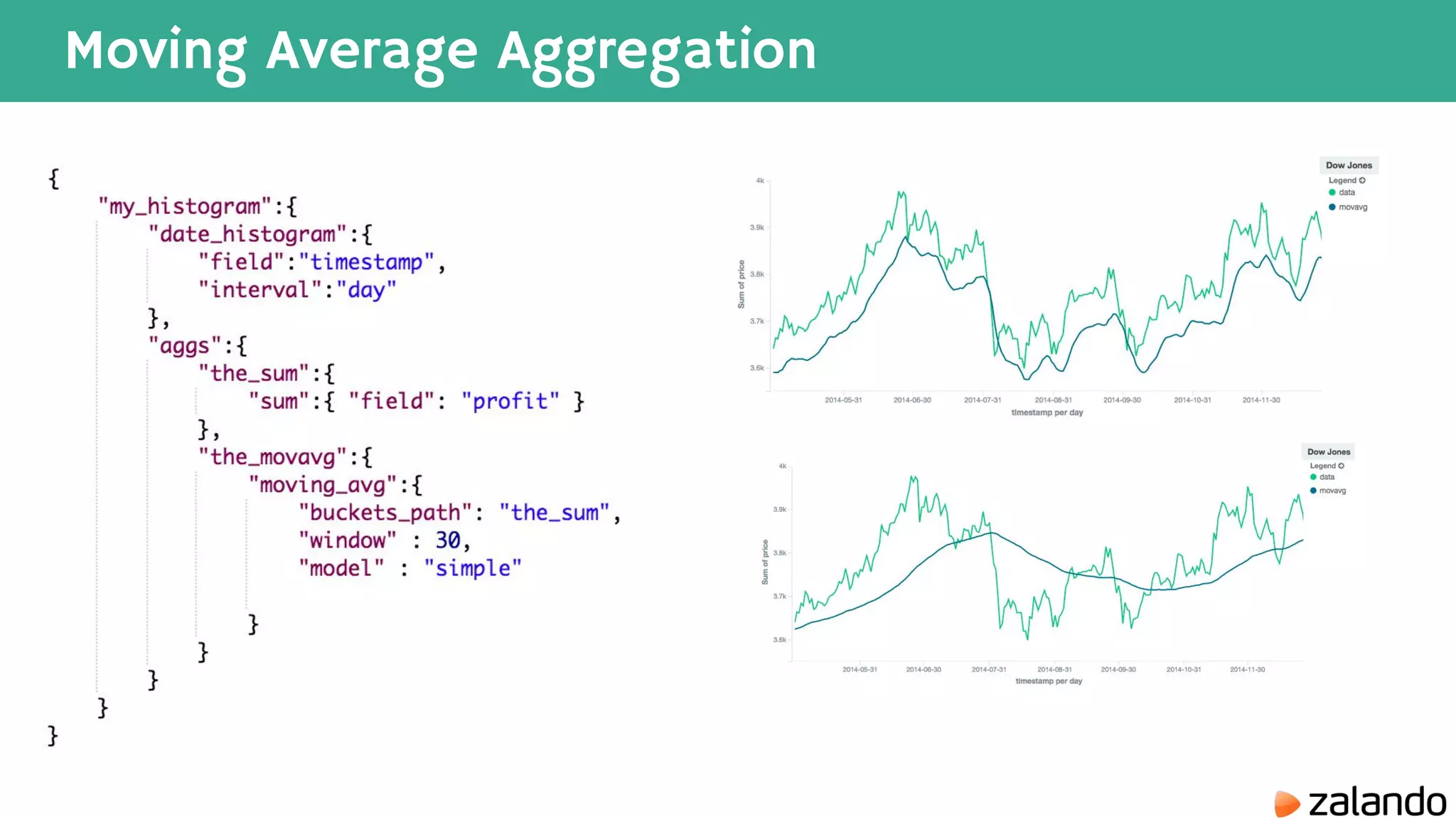
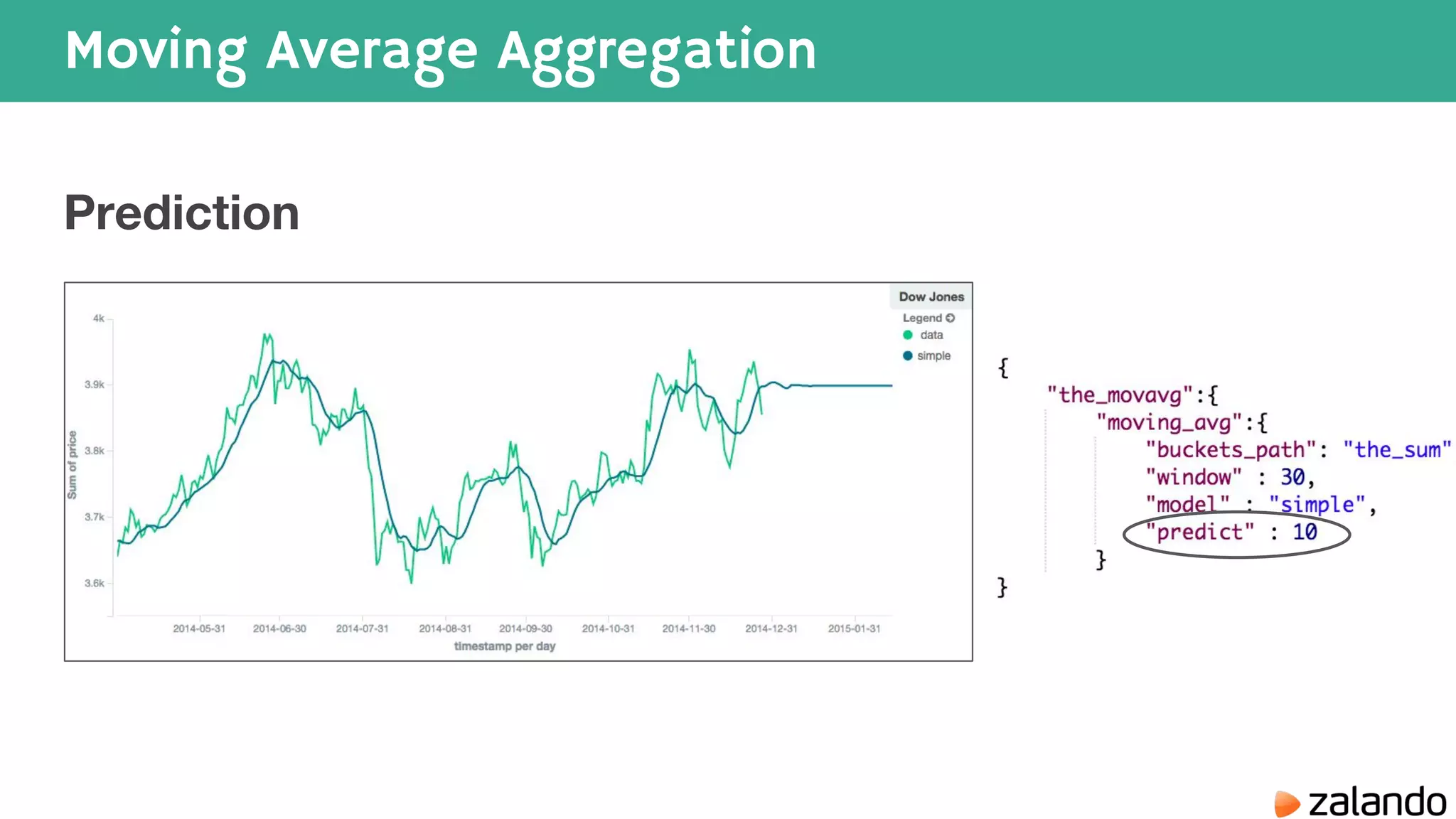
The document discusses various techniques for analyzing time series data in Elasticsearch including: 1) Using a hot-cold architecture to separate indexing and query nodes for optimized performance. 2) Implementing shard allocation awareness to distribute shards across availability zones for high availability. 3) Employing time framed indices, index templates, and aliases to easily manage indices for different time periods. 4) Leveraging aggregations, metrics, buckets, and pipeline aggregations to analyze and summarize large volumes of time series data.