Download as PDF, PPTX

















![Aggregations - terms ● Query: { "query": { "match_all": {} }, "aggregations": { "per_city": { "terms": { "field": "city" } } } } 22 ● Results: [ { "key": "ny", "doc_count": 3 }, { "key": "dc", "doc_count": 1 }, { "key": "london", "doc_count": 1 }, { "key": "sf", "doc_count": 1 }]](https://image.slidesharecdn.com/elasticsearchfordataanalytics-161109010057/75/Elasticsearch-for-Data-Analytics-22-2048.jpg)












![Aggregations - histogram ● Query: { "query": { "match_all": {} }, "aggregations": { "distrib": { "histogram": { "field": "age", "interval": 10 } } } } 35 ● Result: [ { "key": 20, "doc_count": 2 }, { "key": 30, "doc_count": 1 }, { "key": 40, "doc_count": 3 } ]](https://image.slidesharecdn.com/elasticsearchfordataanalytics-161109010057/75/Elasticsearch-for-Data-Analytics-35-2048.jpg)






![Nested aggregations ● Query: { "query": { "match_all": {} }, "aggregations": { "cities": { "terms": { "field": "city" }, "aggregations": { "distrib": { "histogram": { "field": "age", "interval": 10 } } } } } } 42 ● Result (partial) [ { "key": "ny", "doc_count": 3, "distrib": { "buckets": [{ "key": 20, "doc_count": 1 }, { "key": 30, "doc_count": 1 }, { "key": 40, "doc_count": 1 }] } }, { "key": "dc", "doc_count": 1, "distrib": { "buckets": [ {](https://image.slidesharecdn.com/elasticsearchfordataanalytics-161109010057/75/Elasticsearch-for-Data-Analytics-42-2048.jpg)







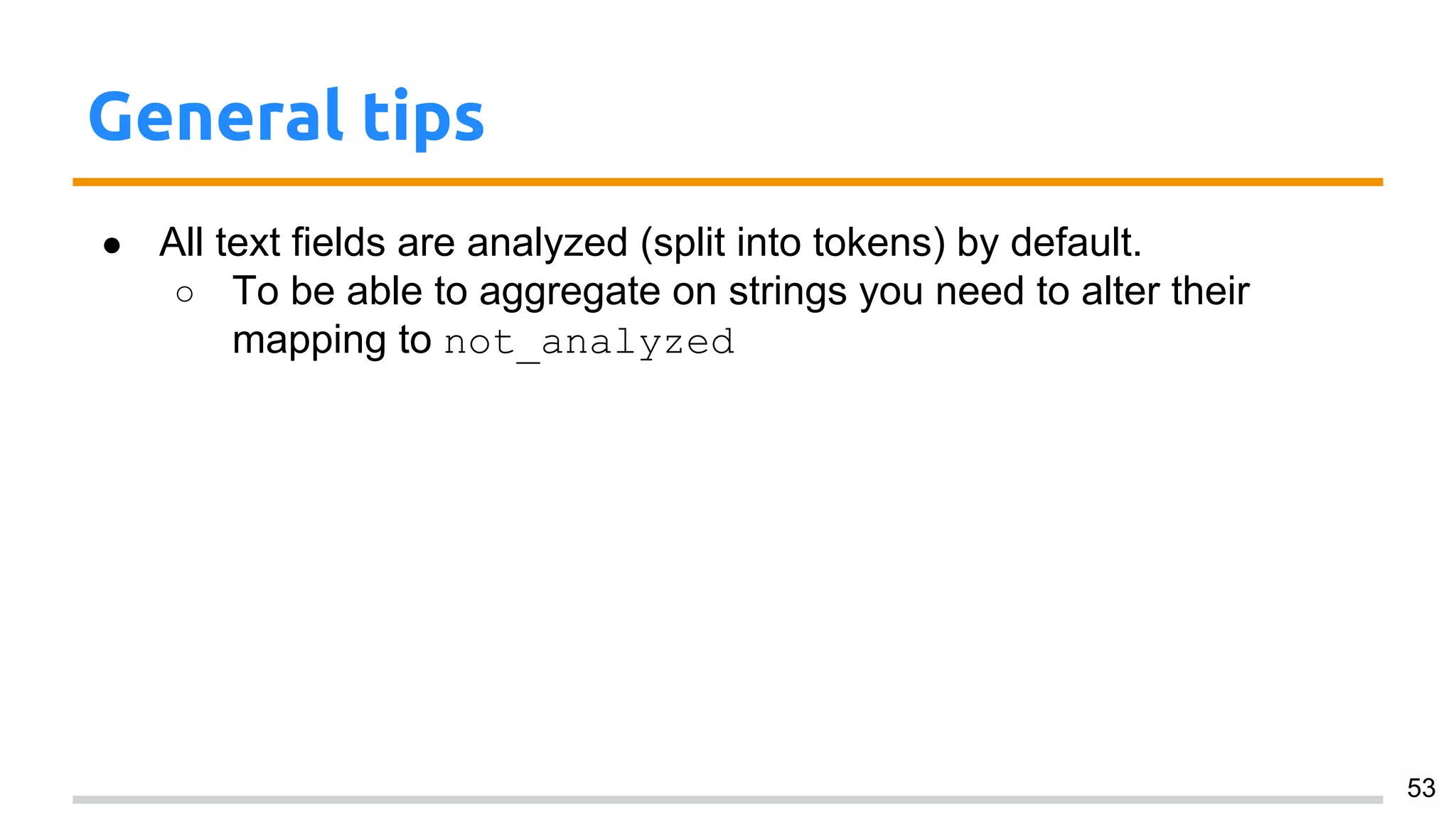











This document provides an overview of using Elasticsearch for data analytics. It discusses various aggregation techniques in Elasticsearch like terms, min/max/avg/sum, cardinality, histogram, date_histogram, and nested aggregations. It also covers mappings, dynamic templates, and general tips for working with aggregations. The main takeaways are that aggregations in Elasticsearch provide insights into data distributions and relationships similarly to GROUP BY in SQL, and that mappings and templates can optimize how data is indexed for aggregation purposes.