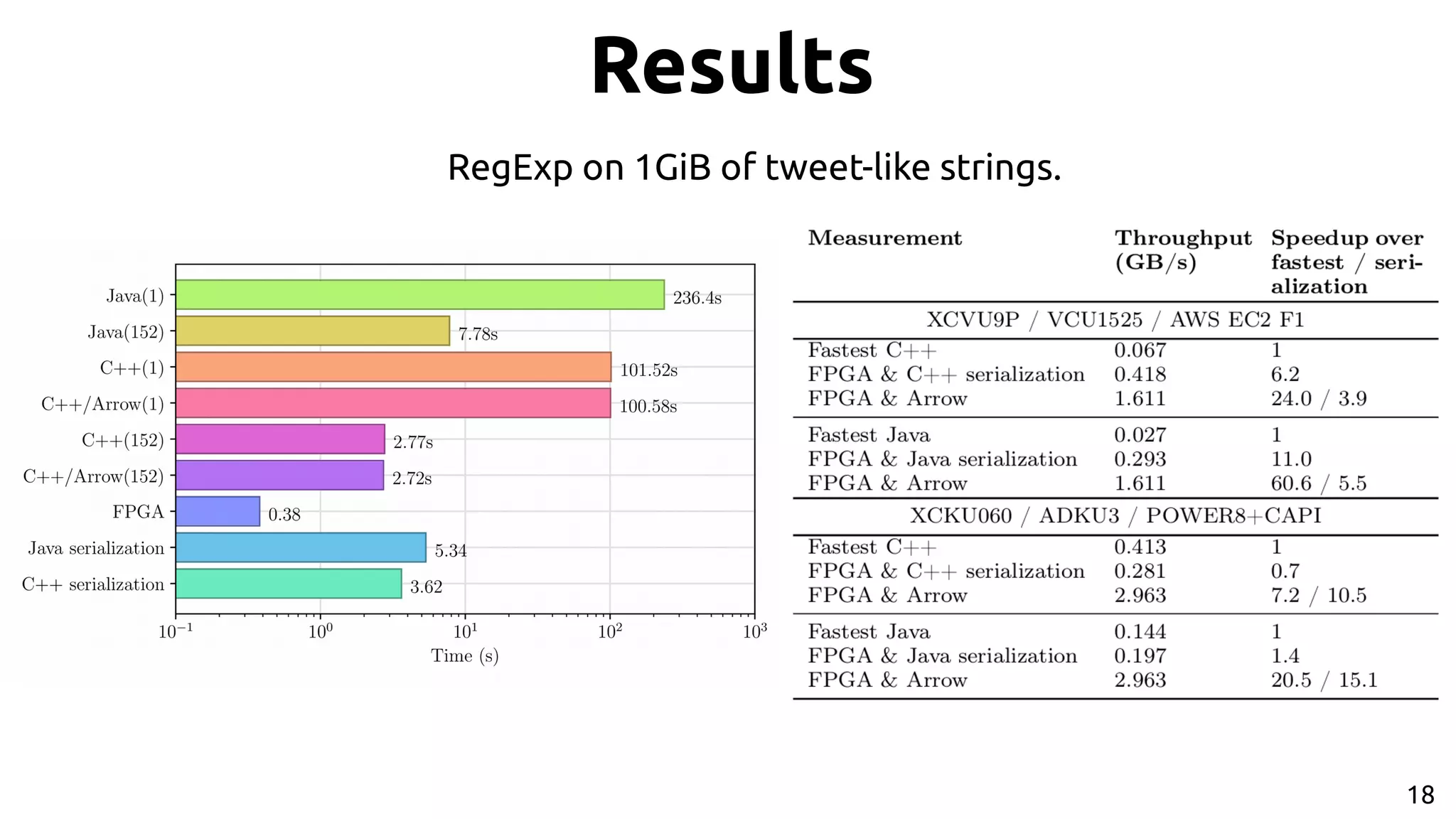
1. The Fletcher Framework provides a standardized way to integrate FPGAs into heterogeneous computing systems using the Apache Arrow in-memory data format. 2. Arrow avoids serialization overhead by using a standardized columnar format that allows for efficient data movement and hardware interfacing. 3. Fletcher generates hardware interfaces from Arrow schemas and provides runtime interfaces for languages like C++ and Python to accelerate algorithms on FPGAs using the Arrow data format.



![4 Heterogeneous computing ● Big data systems are becoming increasingly heterogeneous. – Many diferent “types” of processes in both SW and HW. ● Example: TensorFlowOnSpark[1] – You can run a Python program ● That uses NumPy (Python bindings on top of a C core) – Interfacing with TensorFlow, programmed in CUDA ● Running on a GPU – On top of Spark, written in Scala/Java ● Running on a Java Virtual Machine ● That runs on your CPU ● What challenges does this bring? [1] https://github.com/yahoo/TensorFlowOnSpark](https://image.slidesharecdn.com/johan-peltenburg-190417155441/75/Fletcher-Framework-for-Programming-FPGA-4-2048.jpg)
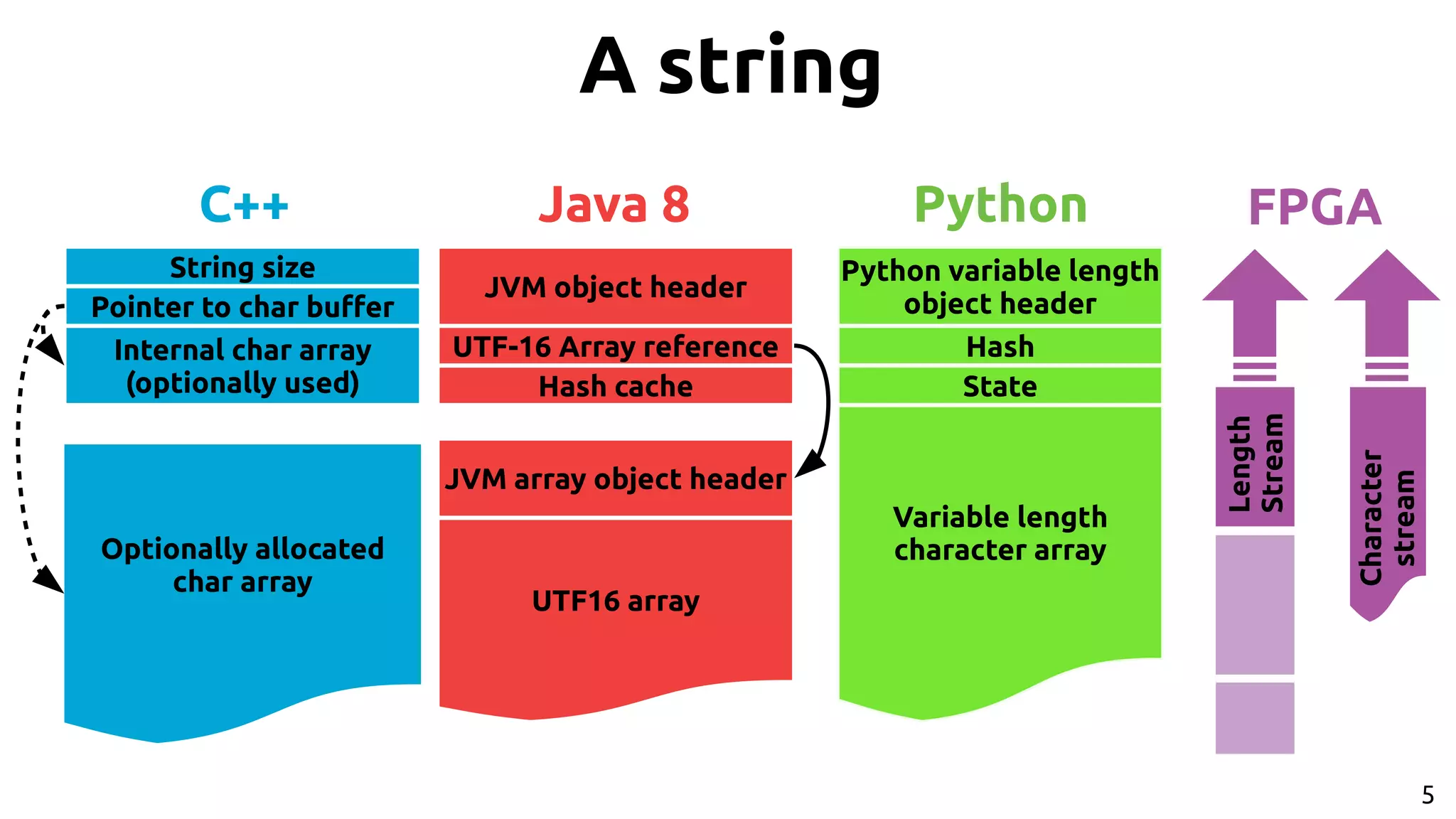
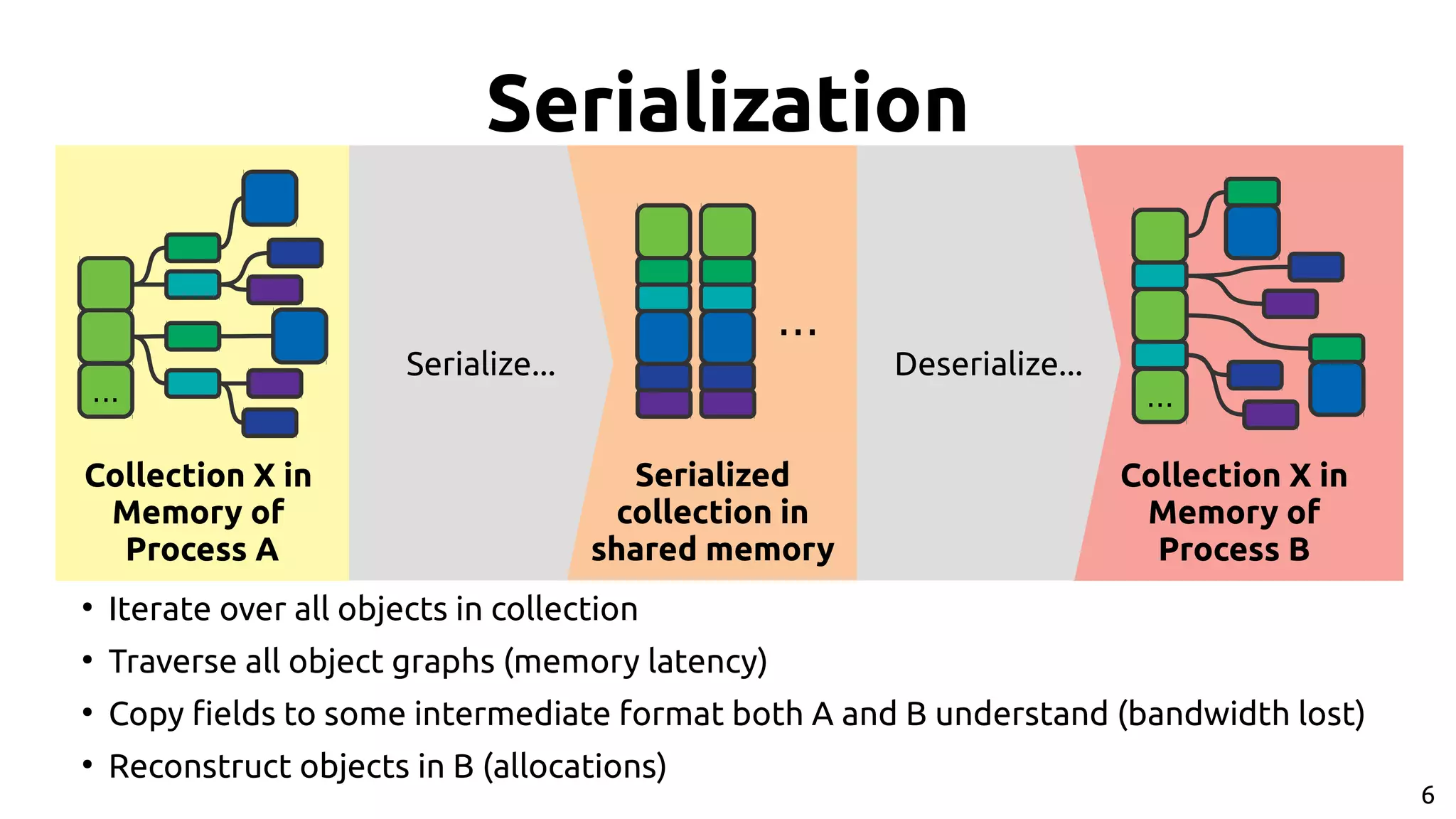
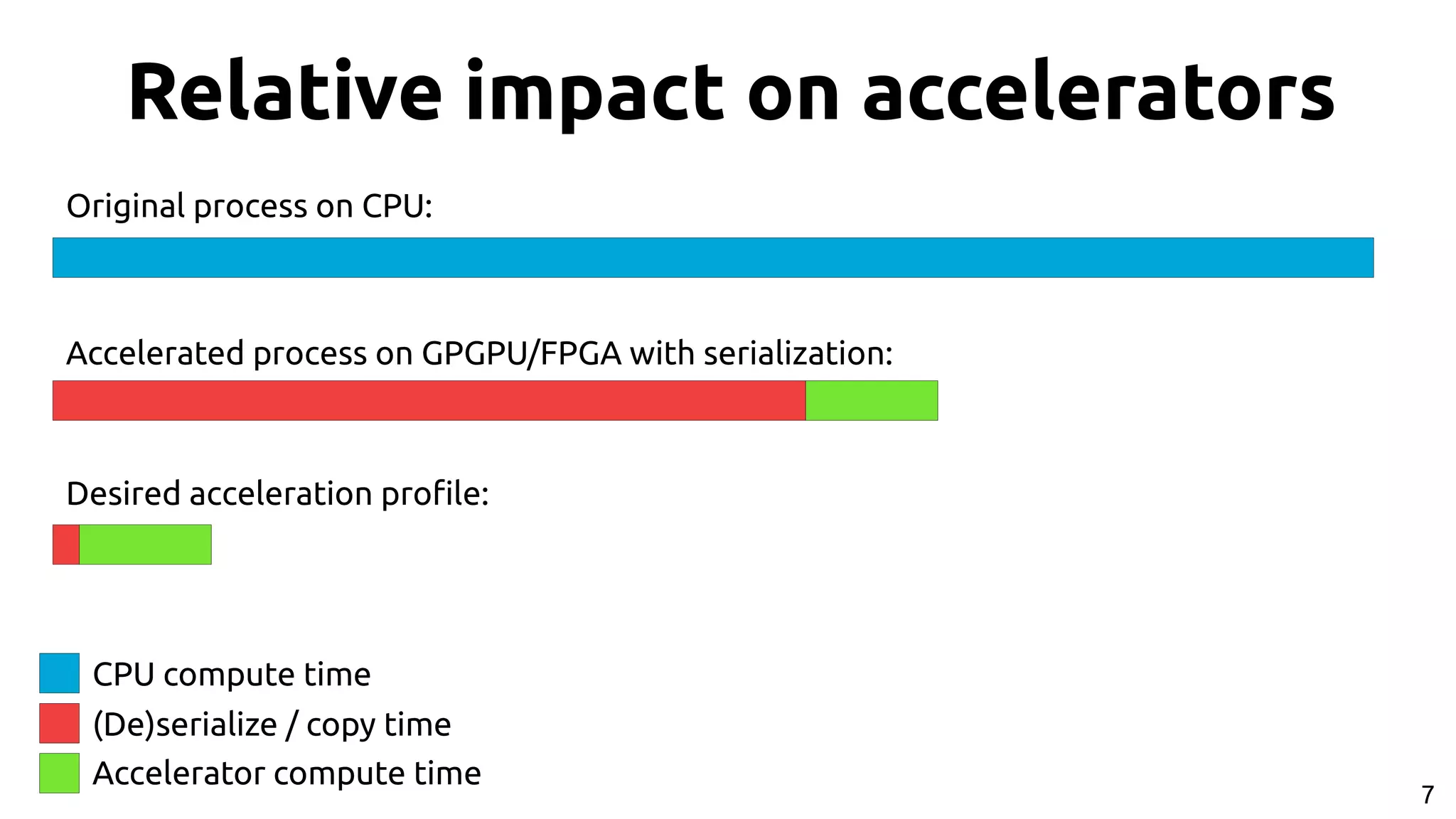

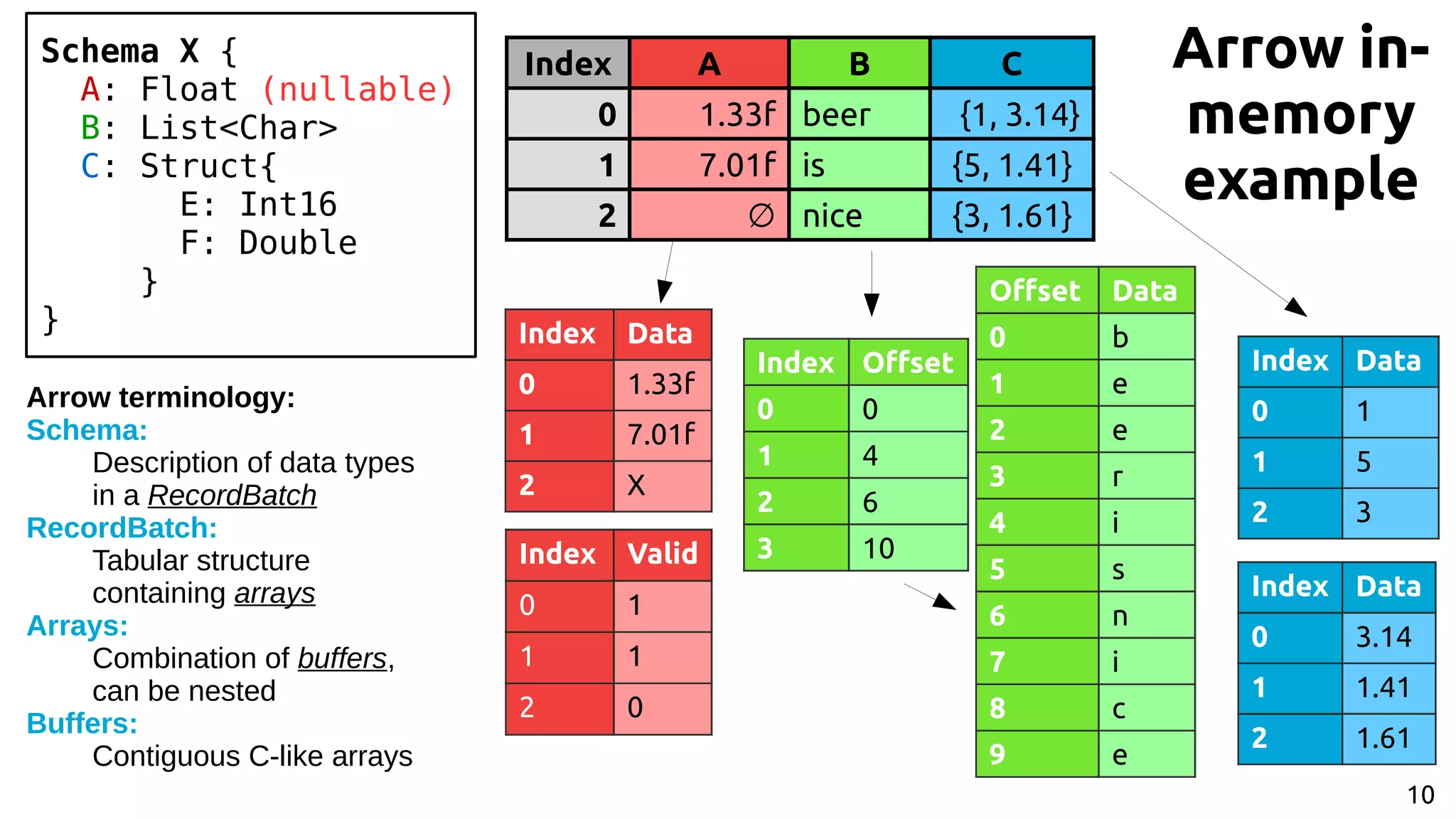
![9 Apache Arrow[2] ● Standardized representation in-memory: Common Data Layer ● Columnar format – Hardware friendly while iterating over data (SIMD, caches, etc…) ● Libraries and APIs for various languages to build and access data [2] https://arrow.apache.org/](https://image.slidesharecdn.com/johan-peltenburg-190417155441/75/Fletcher-Framework-for-Programming-FPGA-9-2048.jpg)

![12 Fletcher[3] architecture: [3] https://github.com/johanpel/fetcher](https://image.slidesharecdn.com/johan-peltenburg-190417155441/75/Fletcher-Framework-for-Programming-FPGA-12-2048.jpg)

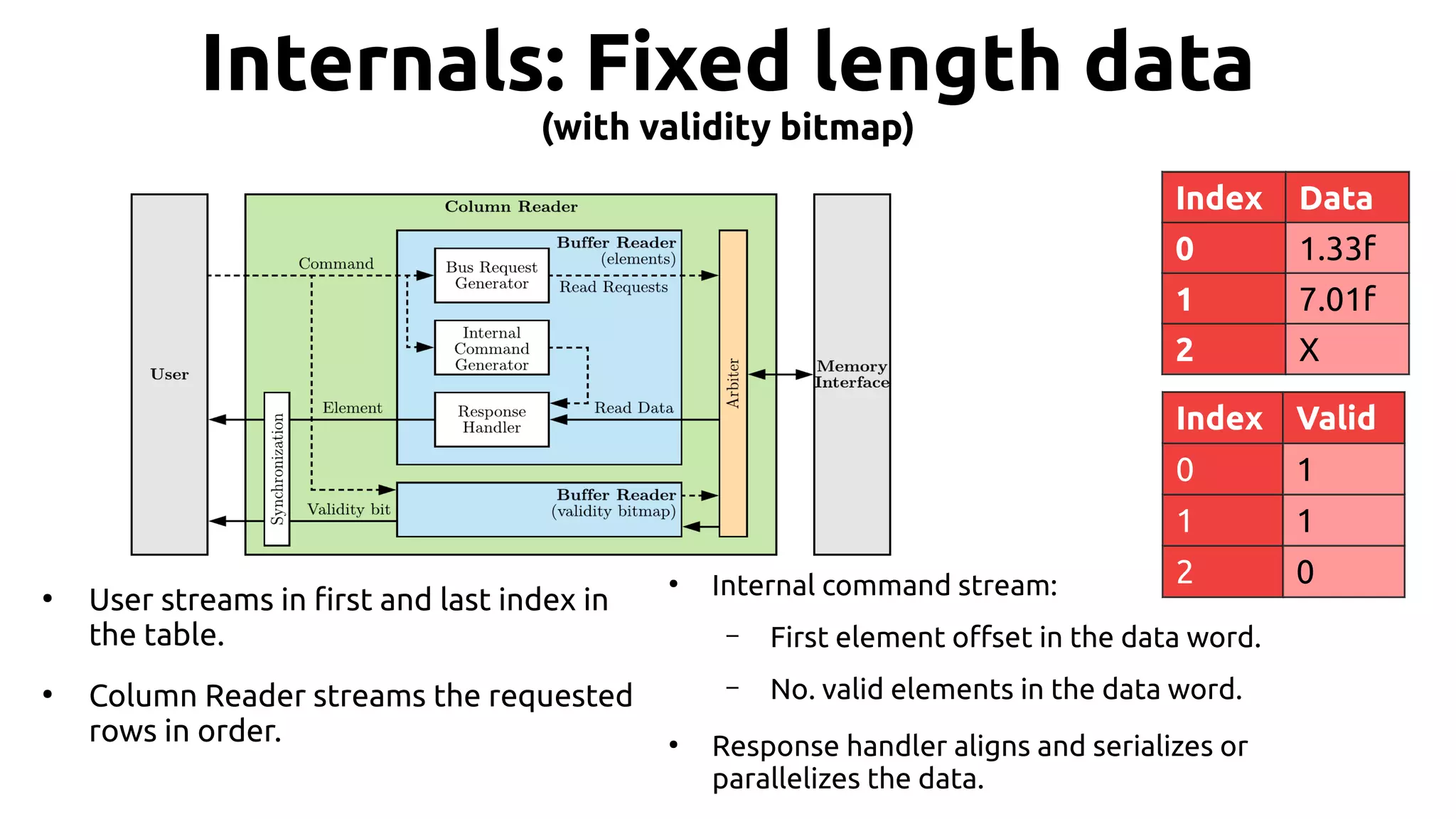
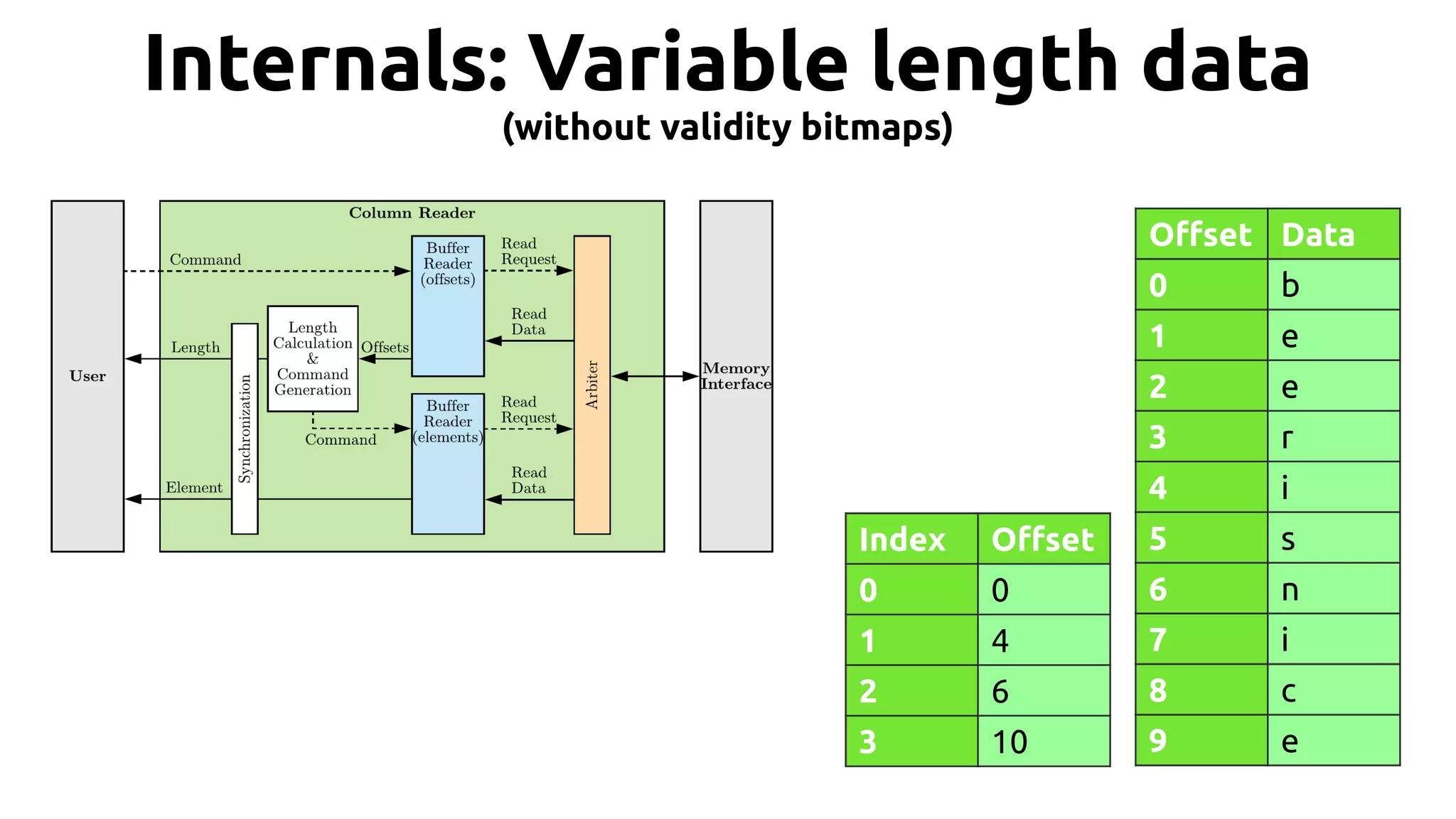
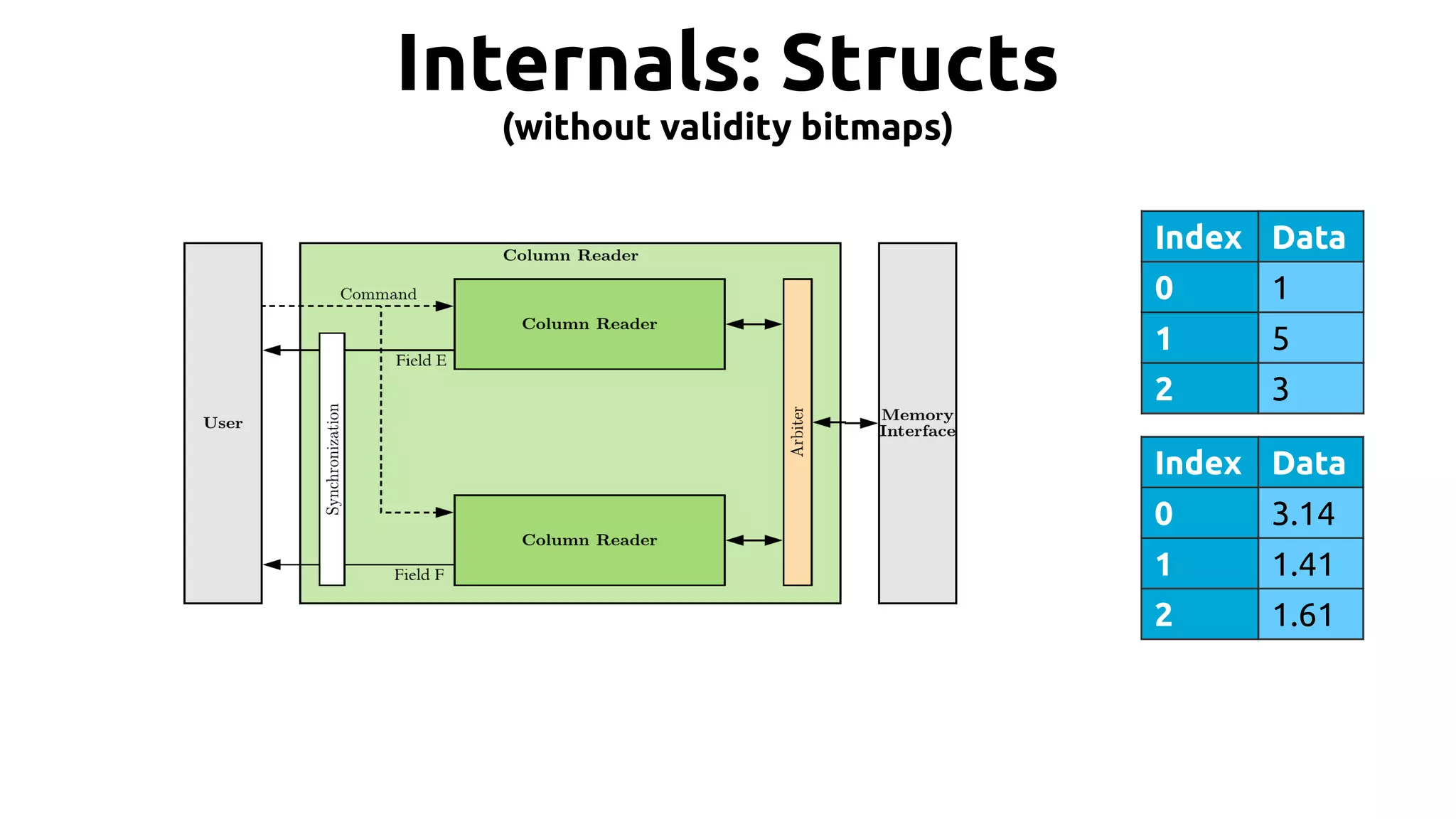
![19 Hands on: sum example ● Suppose we want to add all integers in a column. …, weight[2], weight[1], weight[0] Accumulate result](https://image.slidesharecdn.com/johan-peltenburg-190417155441/75/Fletcher-Framework-for-Programming-FPGA-19-2048.jpg)






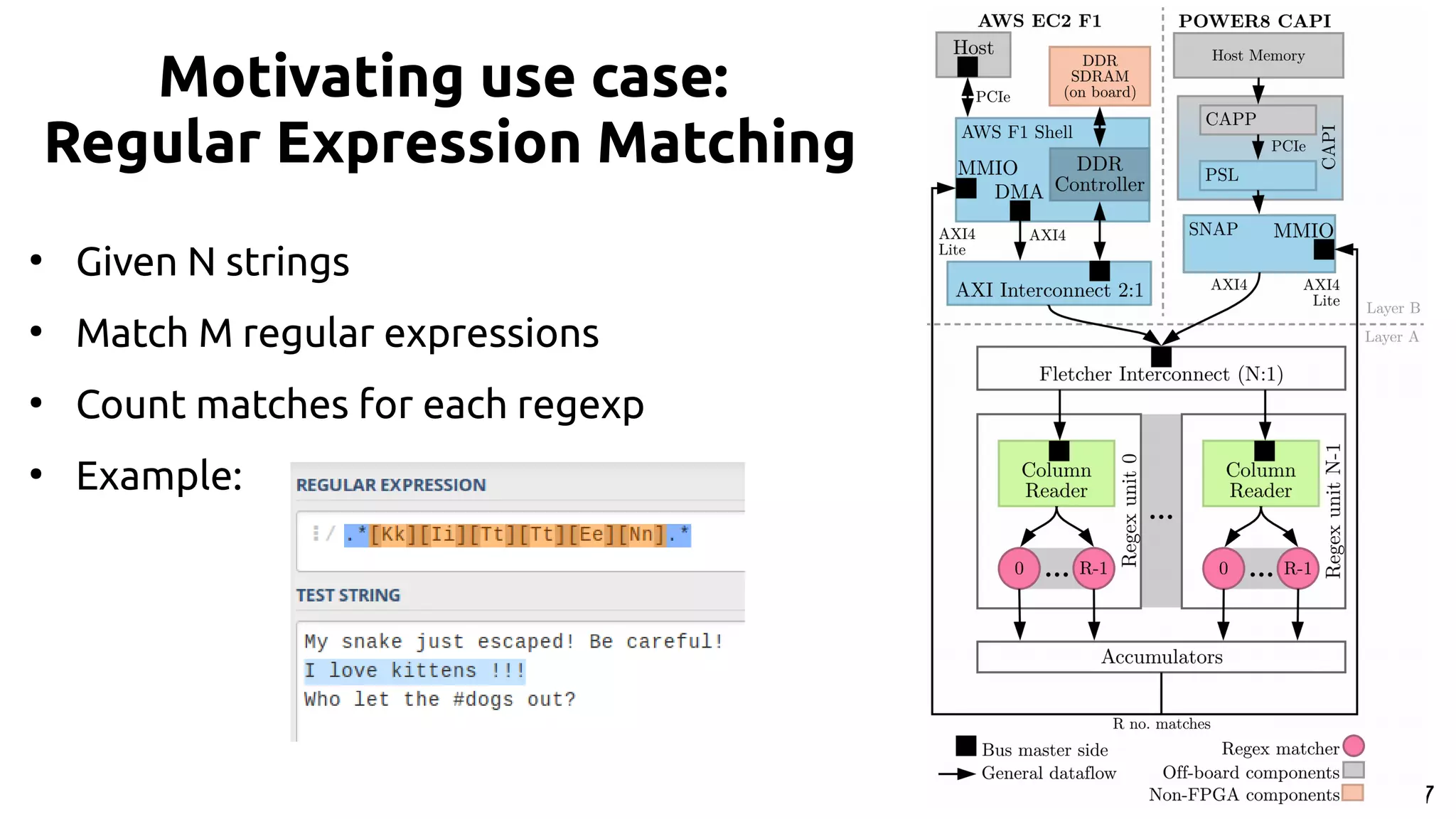
![26 References [1] https://github.com/yahoo/TensorFlowOnSpark [2] https://arrow.apache.org/ [3] https://github.com/johanpel/fetcher ● Regular Expression matching example: https://github.com/johanpel/fetcher/tree/master/examples/regexp ● Writing strings to Arrow format using CAPI 2.0 and SNAP @ 11 GB/s: ● https://github.com/johanpel/fetcher/tree/master/examples/stringwrite ● Posit arithmetic on FPGA, accelerated through Fletcher/SNAP by Laurens van Dam: ● https://github.com/lvandam/posit_blas_hdl ● PairHMM accelerator with posit arithmetic by Laurens van Dam & Johan Peltenburg: ● https://github.com/lvandam/pairhmm_posit_hdl_arrow Example projects / existing applications:](https://image.slidesharecdn.com/johan-peltenburg-190417155441/75/Fletcher-Framework-for-Programming-FPGA-26-2048.jpg)